10 调优一筹莫展,配置项速查手册让你事半功倍!(下)
你好,我是吴磊。
上一讲,我们讲了硬件资源类的配置项。这一讲,我们继续说说Shuffle类和Spark SQL大类都有哪些配置项,它们的含义和作用,以及它们能解决的问题。同时,和上一讲一样,我们今天讲到的配置项也全部会围绕Executors展开。
Shuffle类配置项
首先,我们来说说Shuffle类。纵观Spark官网的Configuration页面,你会发现能调节Shuffle执行性能的配置项真是寥寥无几。其实这也很好理解,因为一旦Shuffle成为应用中不可或缺的一环,想要优化Shuffle本身的性能,我们能做的微乎其微。
不过,我们也不是完全束手无策。我们知道,Shuffle的计算过程分为Map和Reduce这两个阶段。其中,Map阶段执行映射逻辑,并按照Reducer的分区规则,将中间数据写入到本地磁盘;Reduce阶段从各个节点下载数据分片,并根据需要实现聚合计算。
那么,我们就可以通过spark.shuffle.file.buffer和spark.reducer.maxSizeInFlight这两个配置项,来分别调节Map阶段和Reduce阶段读写缓冲区的大小。具体该怎么做呢?我们一一来看。

首先,在Map阶段,计算结果会以中间文件的形式被写入到磁盘文件系统。同时,为了避免频繁的I/O操作,Spark会把中间文件存储到写缓冲区(Write Buffer)。这个时候,我们可以通过设置spark.shuffle.file.buffer来扩大写缓冲区的大小,缓冲区越大,能够缓存的落盘数据越多,Spark需要刷盘的次数就越少,I/O效率也就能得到整体的提升。
其次,在Reduce阶段,因为Spark会通过网络从不同节点的磁盘中拉取中间文件,它们又会以数据块的形式暂存到计算节点的读缓冲区(Read Buffer)。缓冲区越大,可以暂存的数据块越多,在数据总量不变的情况下,拉取数据所需的网络请求次数越少,单次请求的网络吞吐越高,网络I/O的效率也就越高。这个时候,我们就可以通过spark.reducer.maxSizeInFlight配置项控制Reduce端缓冲区大小,来调节Shuffle过程中的网络负载。
事实上,对Shuffle计算过程的优化牵扯到了全部的硬件资源,包括CPU、内存、磁盘和网络。因此,我们上一讲汇总的关于CPU、内存和硬盘的配置项,也同样可以作用在Map和Reduce阶段的内存计算过程上。
除此之外,Spark还提供了一个叫做spark.shuffle.sort.bypassMergeThreshold的配置项,去处理一种特殊的Shuffle场景。

自1.6版本之后,Spark统一采用Sort shuffle manager来管理Shuffle操作,在Sort shuffle manager的管理机制下,无论计算结果本身是否需要排序,Shuffle计算过程在Map阶段和Reduce阶段都会引入排序操作。
这样的实现机制对于repartition、groupBy这些操作就不太公平了,这两个算子一个是对原始数据集重新划分分区,另一个是对数据集进行分组,压根儿就没有排序的需求。所以,Sort shuffle manager实现机制引入的排序步骤反而变成了一种额外的计算开销。
因此,在不需要聚合,也不需要排序的计算场景中,我们就可以通过设置spark.shuffle.sort.bypassMergeThreshold的参数,来改变Reduce端的并行度(默认值是200)。当Reduce端的分区数小于这个设置值的时候,我们就能避免Shuffle在计算过程引入排序。
Spark SQL大类配置项
接下来,我们再来说说Spark SQL的相关配置项。在官网的Configuration页面中,Spark SQL下面的配置项还是蛮多的,其中对执行性能贡献最大的,当属AQE(Adaptive query execution,自适应查询引擎)引入的那3个特性了,也就是自动分区合并、自动数据倾斜处理和Join策略调整。因此,关于Spark SQL的配置项,咱们围绕着这3个特性去汇总。
首先我们要知道,AQE功能默认是禁用的,想要使用这些特性,我们需要先通过配置项spark.sql.adaptive.enabled来开启AQE,具体的操作如下:

因为这3个特性的原理我们在开发原则那一讲说过,这里我会先带你简单回顾一下,然后我们重点来讲,这些环节对应的配置项有哪些。
哪些配置项与自动分区合并有关?
分区合并的场景用一句概括就是,在Shuffle过程中,因为数据分布不均衡,导致Reduce阶段存在大量的小分区,这些小分区的数据量非常小,调度成本很高。
那么问题来了,AQE是如何判断某个分区是不是足够小,到底需不需要合并的呢?另外,既然是对多个分区进行合并,自然就存在一个收敛条件的问题,如果一直不停地合并下去,整个分布式数据集最终就会合并为一个超级大的分区。简单来说,就是:“分区合并从哪里开始,又到哪里结束呢?”

我们一起来看一下AQE分区合并的工作原理。如上图所示,对于所有的数据分区,无论大小,AQE按照分区编号从左到右进行扫描,边扫描边记录分区尺寸,当相邻分区的尺寸之和大于“目标尺寸”时,AQE就把这些扫描过的分区进行合并。然后,继续向右扫描,并采用同样的算法,按照目标尺寸合并剩余分区,直到所有分区都处理完毕。
总的来说就是,AQE事先并不判断哪些分区足够小,而是按照分区编号进行扫描,当扫描量超过“目标尺寸”时,就合并一次。我们发现,这个过程中的关键就是“目标尺寸”的确定,它的大小决定了合并之后分布式数据集的分散程度。
那么,“目标尺寸”由什么来决定的呢?Spark提供了两个配置项来共同决定分区合并的“目标尺寸”,它们分别是spark.sql.adaptive.advisoryPartitionSizeInBytes和spark.sql.adaptive.coalescePartitions.minPartitionNum。

其中,第一个参数advisoryPartitionSizeInBytes是开发者建议的目标尺寸,第二个参数minPartitionNum的含义是合并之后的最小分区数,假设它是200,就说明合并之后的分区数量不能小于200。这个参数的目的就是避免并行度过低导致CPU资源利用不充分。
结合Shuffle后的数据集尺寸和最小分区数限制,我们可以反推出来每个分区的平均大小,咱们暂且把它记为#partitionSize。分区合并的目标尺寸取advisoryPartitionSizeInBytes与#partitionSize之间的最小值。
这么说比较抽象,我们来举个例子。假设,Shuffle过后数据大小为20GB,minPartitionNum设置为200,反推过来,每个分区的尺寸就是20GB / 200 = 100MB。再假设,advisoryPartitionSizeInBytes设置为200MB,最终的目标分区尺寸就是取(100MB,200MB)之间的最小值,也就是100MB。因此你看,并不是你指定了advisoryPartitionSizeInBytes是多少,Spark就会完全尊重你的意见,我们还要考虑minPartitionNum的设置。
哪些配置项与自动数据倾斜处理有关?
再来说说数据倾斜,在数据关联(Data Joins)的场景中,当AQE检测到倾斜的数据分区时,会自动进行拆分操作,把大分区拆成多个小分区,从而避免单个任务的数据处理量过大。不过,Spark 3.0版本发布的AQE,暂时只能在Sort Merge Join中自动处理数据倾斜,其他的Join实现方式如Shuffle Join还有待支持。
那么,AQE如何判定数据分区是否倾斜呢?它又是怎么把大分区拆分成多个小分区的?

首先,分区尺寸必须要大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes参数的设定值,才有可能被判定为倾斜分区。然后,AQE统计所有数据分区大小并排序,取中位数作为放大基数,尺寸大于中位数一定倍数的分区会被判定为倾斜分区,中位数的放大倍数也是由参数spark.sql.adaptive.skewJoin.skewedPartitionFactor控制。
接下来,我们还是通过一个例子来理解。假设数据表A有3个分区,分区大小分别是80MB、100MB和512MB。显然,这些分区按大小个排序后的中位数是100MB,因为skewedPartitionFactor的默认值是5倍,所以大于100MB * 5 = 500MB的分区才有可能被判定为倾斜分区。在我们的例子中,只有最后一个尺寸是512MB的分区符合这个条件。
这个时候,Spark还不能完全判定它就是倾斜分区,还要看skewedPartitionThresholdInBytes配置项,这个参数的默认值是256MB。对于那些满足中位数条件的分区,必须要大于256MB,Spark才会把这个分区最终判定为倾斜分区。假设skewedPartitionThresholdInBytes设定为1GB,那在我们的例子中,512MB那个大分区,Spark也不会把它看成是倾斜分区,自然也就不能享受到AQE对于数据倾斜的优化处理。
检测到倾斜分区之后,接下来就是对它拆分,拆分的时候还会用到advisoryPartitionSizeInBytes参数。假设我们将这个参数的值设置为256MB,那么,刚刚那个512MB的倾斜分区会以256MB为粒度拆分成多份,因此,这个大分区会被拆成 2 个小分区( 512MB / 256MB =2)。拆分之后,原来的数据表就由3个分区变成了4个分区,每个分区的尺寸都不大于256MB。
哪些配置项与Join策略调整有关?
最后,咱们再来说说数据关联(Joins)。数据关联可以说是数据分析领域中最常见的操作,Spark SQL中的Join策略调整,它实际上指的是,把会引入Shuffle的Join方式,如Hash Join、Sort Merge Join,“降级”(Demote)为Broadcast Join。
Broadcast Join的精髓在于“以小博大”,它以广播的方式将小表的全量数据分发到集群中所有的Executors,大表的数据不需要以Join keys为基准去Shuffle,就可以与小表数据原地进行关联操作。Broadcast Join以小表的广播开销为杠杆,博取了因消除大表Shuffle而带来的巨大性能收益。可以说,Broadcast Join把“杠杆原理”应用到了极致。
在Spark发布AQE之前,开发者可以利用spark.sql.autoBroadcastJoinThreshold配置项对数据关联操作进行主动降级。这个参数的默认值是10MB,参与Join的两张表中只要有一张数据表的尺寸小于10MB,二者的关联操作就可以降级为Broadcast Join。为了充分利用Broadcast Join“以小博大”的优势,你可以考虑把这个参数值调大一些,2GB左右往往是个不错的选择。

不过,autoBroadcastJoinThreshold这个参数虽然好用,但是有两个让人头疼的短板。
一是可靠性较差。尽管开发者明确设置了广播阈值,而且小表数据量在阈值以内,但Spark对小表尺寸的误判时有发生,导致Broadcast Join降级失败。
二来,预先设置广播阈值是一种静态的优化机制,它没有办法在运行时动态对数据关联进行降级调整。一个典型的例子是,两张大表在逻辑优化阶段都不满足广播阈值,此时Spark SQL在物理计划阶段会选择Shuffle Joins。但在运行时期间,其中一张表在Filter操作之后,有可能出现剩余的数据量足够小,小到刚好可以降级为Broadcast Join。在这种情况下,静态优化机制就是无能为力的。
AQE很好地解决了这两个头疼的问题。首先,AQE的Join策略调整是一种动态优化机制,对于刚才的两张大表,AQE会在数据表完成过滤操作之后动态计算剩余数据量,当数据量满足广播条件时,AQE会重新调整逻辑执行计划,在新的逻辑计划中把Shuffle Joins降级为Broadcast Join。再者,运行时的数据量估算要比编译时准确得多,因此AQE的动态Join策略调整相比静态优化会更可靠、更稳定。

不过,启用动态Join策略调整还有个前提,也就是要满足nonEmptyPartitionRatioForBroadcastJoin参数的限制。这个参数的默认值是0.2,大表过滤之后,非空的数据分区占比要小于0.2,才能成功触发Broadcast Join降级。
这么说有点绕,我们来举个例子。假设,大表过滤之前有100个分区,Filter操作之后,有85个分区内的数据因为不满足过滤条件,在过滤之后都变成了没有任何数据的空分区,另外的15个分区还保留着满足过滤条件的数据。这样一来,这张大表过滤之后的非空分区占比是 15 / 100 = 15%,因为15%小于0.2,所以这个例子中的大表会成功触发Broadcast Join降级。
相反,如果大表过滤之后,非空分区占比大于0.2,那么剩余数据量再小,AQE也不会把Shuffle Joins降级为Broadcast Join。因此,如果你想要充分利用Broadcast Join的优势,可以考虑把这个参数适当调高。
小结
今天这一讲,我们深入探讨了Shuffle类和Spark SQL大类两类配置项,以及每个配置项可以解决的问题。
对于Shuffle类我们要知道,在Shuffle过程中,对于不需要排序和聚合的操作,我们可以通过控制spark.shuffle.sort.bypassMergeThreshold参数,来避免Shuffle执行过程中引入的排序环节,从而避免没必要的计算开销。
对于Spark SQL大类我们首先要知道,AQE默认是禁用状态,要充分利用AQE提供的3个特性,就是自动分区合并、数据倾斜处理和Join策略调整,我们需要把spark.sql.adaptive.enabled置为true。
除此之外,AQE的3个特性各自都有相对应的配置项,需要我们单独调整。
- AQE中的自动分区合并过程与我们预想的不太一样。QE事先并不判断哪些分区足够小,而是按照分区编号进行扫描,当扫描量超过“目标尺寸”时就合并一次。目标尺寸由advisoryPartitionSizeInBytes和coalescePartitions.minPartitionNum两个参数共同决定。
- AQE能够自动处理Sort Merge Join场景中的数据倾斜问题。首先根据所有分区大小的中位数,以及放大倍数skewedPartitionFactor来检测倾斜分区,然后以advisoryPartitionSizeInBytes为粒度对倾斜分区进行拆分。
- AQE动态Join策略调整可以在运行时将Shuffle Joins降级为Broadcast Join,同时,运行时的数据量估算要比编译时准确得多,因此相比静态优化会更可靠。不过,需要我们注意的是,Shuffle过后非空分区占比要小于nonEmptyPartitionRatioForBroadcastJoin才能触发Broadcast Join的降级优化。
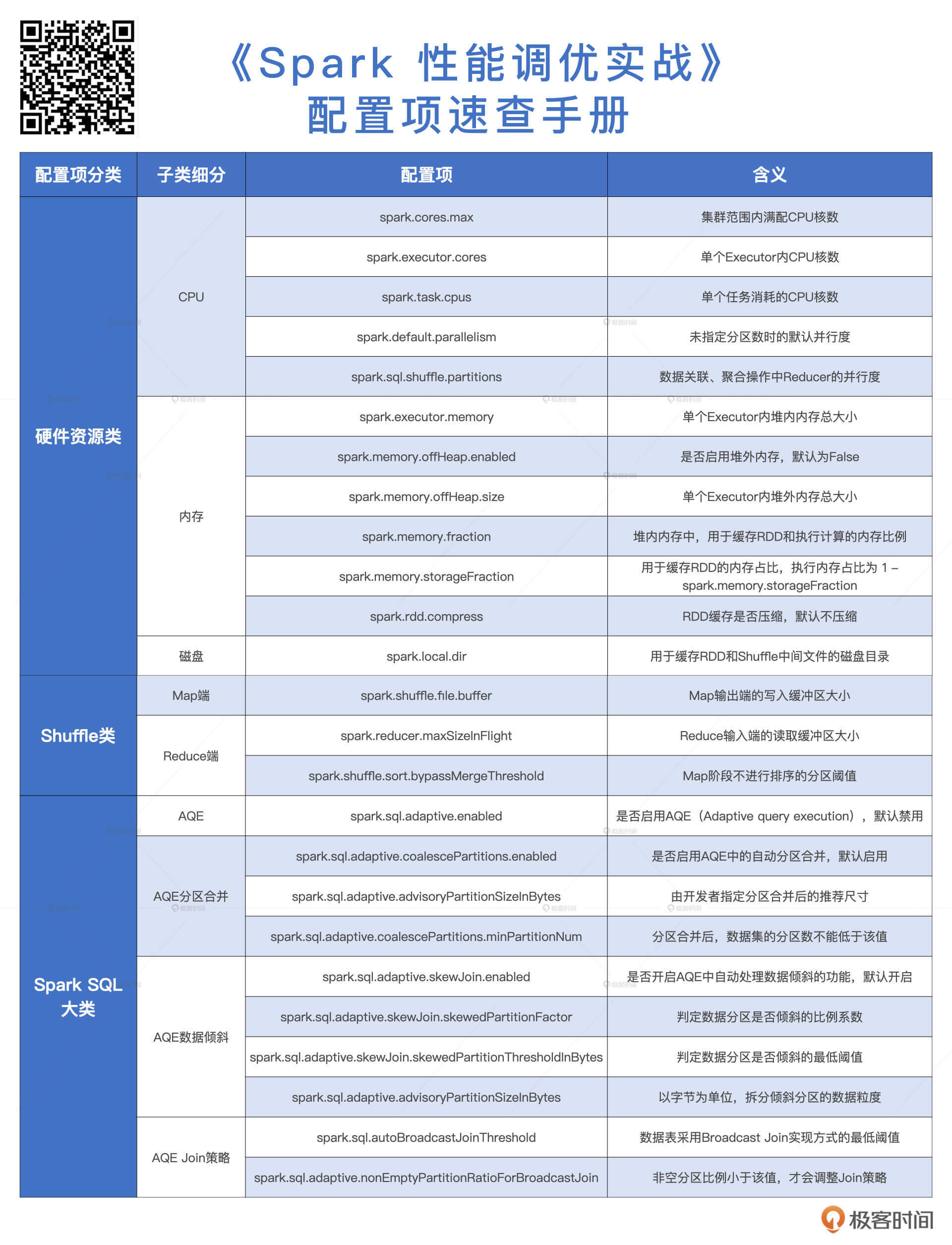
好啦,经过这两讲的学习,我们一起汇总出了Spark中与性能调优息息相关的所有配置项,为了方便你快速查阅,我把它们合并在了一张文稿的表格中,希望你能在工作中好好利用起来。
每日一练
- AQE的分区合并算法略显简单粗暴,如果让你来重新实现分区合并特性的话,你都有哪些思路呢?
- AQE中数据倾斜的处理机制,你认为有哪些潜在的隐患?
期待在留言区看到你的思考和答案,也欢迎你把这份调优手册分享给你的朋友们,我们下一讲见!
- 来世愿做友人 A 👍(23) 💬(6)
请教老师一个问题,对于小文件合并,上边说的是某个 executor 的大小排序后合并。比如两个 executorA 和 B,分别有两个 task 运行,groupby 并且各自产生了3个分区,分别是 a.0,a.1,a.2 和 b.0,b.1,b.2,在没有合并小分区的情况下,reduce端会有三个任务拉取各自的012分区。但是,打开小分区合并,在满足合并的条件下,a.0和a.1合并成 a.01,b.1和b.2合并成b.12。这时候两个 task 各有两个分区,但是他们的分区 key 相当于混在一起了。shuffle的 reduce 是怎么拉取。因为目前只看过 raw rdd的相关,目前没想到是怎么解决这个问题的?比如又会多引入一层 shuffle?或者有其它判断,最终判断这次的 reduce 只能有一个 task,然后拉取所有 map 端的分区?
2021-04-07 - CRT 👍(21) 💬(2)
spark.shuffle.sort.bypassMergeThreshold 这个阈值为什么是跟Reduce 端的分区数有关,Reduce 端的分区数过大的话,取消排序会有不好的影响吗?
2021-05-11 - kingcall 👍(11) 💬(2)
其实我们的调优很多都是发生在数据规模比较大的情况下,对于比较大的shuffle 可以对下面的参数进行调节,提高整个shuffle 的健壮性 spark.shuffle.compress 是否对shuffle 的中间结果进行压缩,如果压缩的话使用`spark.io.compression.codec` 的配置进行压缩 spark.shuffle.io.maxRetries io 失败的重试次数,在大型shuffle遇到网络或者GC 问题的时候很有用。 spark.shuffle.io.retryWait io 失败的时候的等待时间
2021-04-09 - 苏子浩 👍(7) 💬(2)
老师好!我想讨论一下文中“自动数据倾斜处理”部分。其中我们提到“advisoryPartitionSizeInBytes”这个参数。我通过查看源代码发现:拆分的时候我们具体使用的拆分粒度(targetSize)不仅会考虑该参数的数值,同时会考虑非倾斜的分区(non-skewedPartition)的平均大小。用数学表示的话应该是“Math.max(advisortSize, nonSkewSizes.sum / nonSkewSizes.length)”。其中nonSkewSizes表示“所有分区中过滤掉倾斜分区后所剩余分区,其分区大小所构成的列表”。 我想表达的是:在‘自动倾斜处理’中所用到的思想与‘自动分区合并’中相似! 并不是指定了 advisoryPartitionSizeInBytes 是多少,Spark 就会完全尊重开发者的意见,还要考虑非倾斜分区的平均大小。 那么这样来看的话,文中所举的例子“检测到倾斜分区之后,接下来就是对它拆分,拆分的时候还会用到 advisoryPartitionSizeInBytes 参数。假设我们将这个参数的值设置为 256MB,那么,刚刚那个 512MB 的倾斜分区会以 256MB 为粒度拆分成多份,因此,这个大分区会被拆成 2 个小分区( 512MB / 256MB =2)。拆分之后,原来的数据表就由 3 个分区变成了 4 个分区,每个分区的尺寸都不大于 256MB。“其实在这里其实是比较了Math( ((80+100) / 2), 256) = 256后,我们才最终确定以 256MB 为粒度拆分存在倾斜的分区。 接着是我的一点看法,AQE中对于认定倾斜分区的条件看起来非常苛刻,首先要满足该分区的大小高于 spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 参数的设定值。同时,取所有数据分区大小排序后的中位数作为放大基数,尺寸大于中位数指定倍数的分区才会被判定为倾斜分区。那么是不是可以看到其实做倾斜分区处理这件事的成本还是很高的。因为在数据关联场景中,如果两边的表都存在数据倾斜的话,会出现笛卡尔积的显现。哪怕是只有一边的表存在数据倾斜,另外一边的分区复制也是不小的开销。在关联场景中涉及到更多的网络开销。以及需要涉及到reducer任务从一个分区中读取部分数据,其中涉及到的数据划分成本很高? 其实我看到的第一反应是想到了Shuffle Hash Join激活的先决条件,感觉激活的条件都非常苛刻。
2021-05-26 - 天翼 👍(6) 💬(2)
老师,请问一下,spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin 这个配置在官网的 Configuration 中没有找到,是改名了吗?
2021-05-03 - 木子中心 👍(5) 💬(1)
老师好,有一个问题:文章里面说建议设置spark.sql.autoBroadcastJoinThreshold为2G,如果数据是parquet格式的话,将数据加载到内存中会膨胀比较大,这个时候,driver端内存应该配置多少才能不oom呢?
2021-09-08 - 斯盖丸 👍(5) 💬(1)
老师,我看Spark 3.1.1的文档,spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin这个参数已经被去除了。。由此想到一个重大问题:像这种重大的参数配置变更老师是怎么第一时间获悉的并跟上版本更新的节奏,而不像我们这样没人告知,只能被动地获悉呢?
2021-06-15 - 木子中心 👍(3) 💬(1)
吴老师好!有个问题想请教下: spark广播join经常造成driver oom,spark.sql.autoBroadcastJoinThreshold使用默认值,driver为4-5G左右,文件存储格式为parquet。查阅资料发现spark是直接通过扫描文件的总大小及多少列来判断是否小于阈值,进行广播。由于使用了parquet格式,在扫描少数列的情况下,由于压缩率较高,在某些情况下,上百万数据的结果集也进行广播,造成driver段oom。
2021-09-08 - 耳东 👍(3) 💬(2)
问下老师,如果某个表的大小是10m,但是它的条数超过了1千万条,这种表属不属于小表
2021-04-16 - 辰 👍(3) 💬(1)
这个aqe规则是在3.0版本才有的,但是我公司目前用的版本是2.2,有什么其他的参数设置吗
2021-04-13 - 斯盖丸 👍(3) 💬(2)
spark.shuffle.file.buffer 和 spark.reducer.maxSizeInFlight 这两个配置项听起来应该越大越好,这样可以降低落盘的频次和数据shuffle的频次。请问老师这两个参数如果调太大会有什么副作用呢?
2021-04-06 - 续费专用 👍(2) 💬(1)
老师好,动态分区裁剪和AQE哪个对spark的优化性能更大呢?AQE默认是关闭的,是不是说明spark更推荐用户使用动态分区裁剪功能呢?
2021-06-07 - Alan 👍(1) 💬(2)
2、看似AQE 数据倾斜策略确实不错,但是数据倾斜优化后的sort merge join,使用skew Shuffle reader,也就是存在shuffle的操作,会影响总体的性能,所以skewedPartitionFactor、spark.sql.adaptive.advisoryPartitionSizeInBytes 和 spark.sql.adaptive.coalescePartitions.minPartitionNum两项值设置的合理性,非常重要,最好数据量刚好适用,整数倍最好!
2021-05-06 - 西南偏北 👍(1) 💬(2)
1. AQE的自动分区合并算法目前的实现,可能会造成合并之后,各分区数据不均衡,从而导致后续计算出现小的数据倾斜?合并算法是不是可以在得出合并前各分区大小之后,进行均衡的组合合并? 2. 因为AQE数据倾斜处理机制,是取中位数,那比如有10个分区:80MB 100 100 100 100 512 512 512 512MB,skewedPartitionFactor为5,skewedPartitionThresholdInBytes为256MB。那么这样一来的话,就会造成将近一半的分区被判定为倾斜分区,这种情况下,后续的分区拆分处理是不是代价就比较大了
2021-05-04 - 小灵芝 👍(1) 💬(2)
老师您好呀! 请教2个问题: “因此,在不需要聚合,也不需要排序的计算场景中,我们就可以通过设置 spark.shuffle.sort.bypassMergeThreshold 的参数,来改变 Reduce 端的并行度” 1. 请问还有哪些类似于repartition, groupby 这种“不需要聚合,也不需要排序的计算场景”呢? 2. groupby 不是需要聚合的吗?
2021-04-29