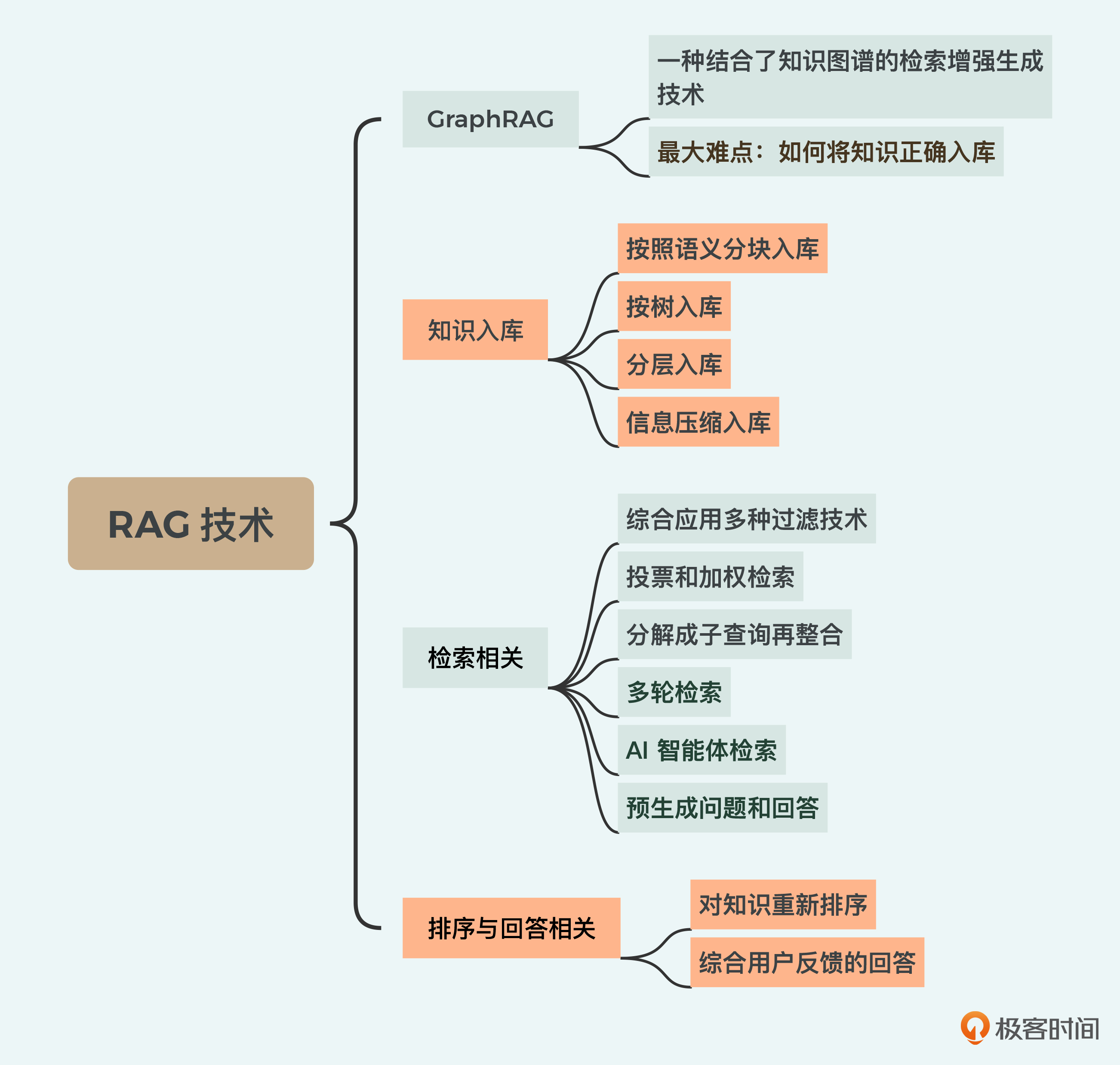
23 他山之石:GraphRAG等13种RAG前沿技术
你好,我是叶伟民。
上一节课我们学习了如何查看LangChain、LlamaIndex源码学习改进RAG质量的技术。然而LangChain、LlamaIndex并没有囊括所有RAG技术,所以同学们看完这些技术的所有文档可能还是找不到解决自己问题的方法。
那该怎么办呢?这时候我们就需要看看其他RAG技术能否解决我们的问题了。这里我会列出我接触、研究过的13种RAG前沿技术。我们首先从最近大火的GraphRAG开始。
GraphRAG
GraphRAG是一种结合了知识图谱的检索增强生成技术,旨在通过构建知识图谱和社区检测算法,提升大模型在理解和生成复杂信息方面的能力。它通过图结构信息,能够更精确地检索和生成与上下文相关的回答,从而在处理大规模数据集时展现出显著的性能提升。
原理
从上面这段描述里我们看到,GraphRAG是基于知识图谱的,因此它是基于图的方式去检索知识的。
而传统RAG多采用简单直接的方式——将文档简化为文本字符串,切割成零碎段落,再映射到向量空间,实现语义相似度的展现,这也是我们在第3章所讲过的内容。然而,这种方式有一个明显的缺陷,就是偏重局部文本匹配,忽略了整体数据的全面理解。
这样讲还是很抽象,我们举个简单的例子。假设我们要问RAG应用这么一个问题:菩提祖师和唐僧之间的关系是什么?
由于在西游记里面,菩提祖师和唐僧并没有直接的关系,而且关于他们的描述分布在不同的章节,他们并没有出现在同一个章节里面。所以使用传统RAG知识入库方式的话,他们将会分布在不同的段落。因此使用传统RAG检索方法,我们只能检索出菩提祖师的相关知识,以及唐僧的相关知识,但是并没有办法推断出他们之间的关系。
如果使用GraphRAG情况就不一样了,菩提祖师、唐僧、孙悟空会在入库的时候被提取成三个实体,然后将建立两段关系:菩提祖师是孙悟空的师傅,唐僧是孙悟空的师傅。在检索知识的时候,将会检索到这三个实体和两段关系,然后喂给大模型。这样一来,大模型就能够回答:菩提祖师和唐僧都是孙悟空的师傅。
优点
从上面这个例子看出,GraphRAG擅长处理针对超长文档的复杂提问,例如西游记这种大部头图书。GraphRAG能够挖掘出超长文档里面的实体和关系,所以就能回答涉及到关系的提问,并且关系越多,越复杂,越能体现出GraphRAG的优势。
例如我们提问:菩提祖师和唐太宗之间的关系是什么?这个问题与刚才的问题相比,跨越的关系更多了。传统RAG基本无法回答好,而GraphRAG仍然可以处理。
缺点
那么GraphRAG有什么缺点呢?
GraphRAG的门槛、算力成本、时间成本、人力成本都很高。正如我在开篇词里面说到的,确实有公司将GraphRAG实现得很好,其产品能够月入几千万,然而他们花了8个月的时间和无数的技术人力,才得到这个好结果。从“8个月”和“无数“这两个词不难看出,这个技术不适合初学者入门,GraphRAG相当于RAG里面的专业马拉松,价值虽然高,但难度也很高。
GraphRAG最大的难点在于如何将知识正确入库,我举一个例子来帮你理解,假设有以下内容:
- 孙悟空在火焰山面前无法前进,喊出了土地公公,询问个究竟。
- 孙悟空在小雷音寺面前无法前进,喊出了土地公公,询问个究竟。
以上两句话里面的土地公公并非是同一个土地公公,如何识别出是不同的两个实体,这是一个难点。
适用场景
从刚才的讲解我们了解了,GraphRAG适用于处理超长文档和复杂关系,难点在于知识正确入库。因此如果知识入库很简单,例如像实战案例1一样,知识已经人工精确入库了,是可以应用GraphRAG的。在现实工作中,GraphRAG最适合的应用场景是基于社交关系的风控系统,因为这些社交关系已经正确入库了。
除了最近大火的GraphRAG,还有很多RAG技术,这里仅列出我接触和研究过的12种RAG技术,希望能在同学们遇到问题时提供灵感。
其他12种RAG技术
首先我们来看知识入库相关的技术。
知识入库相关技术
- 按照语义分块入库
传统的文本拆分方法经常在任意点切分文档,可能破坏信息和上下文的流动。语义分块通过尝试在更自然的断点处拆分文本来解决这个问题,保持每个块内的语义连贯性。
- 按树入库
我们可以将知识按树入库。我们可以这样想象,我们像整理一本书那样将知识入库,例如按章、节、小节、段这样把内容整理成一棵树,其中每章包括哪些节,每节包括哪些小节,每小节包括哪些段。
3.分层入库
我们可以将知识分成多层,然后再入库。例如我们可以建立一个两层系统,一层是文本摘要,一层是详细内容,然后两者都包含指向数据中相同位置的元数据。
- 信息压缩入库
有些业务场景下,我们不需要把所有信息都入库,只需要把关键的信息入库,这时候我们可以使用大模型将与业务场景无关或者次要的信息先剔除掉,然后再入库。
检索相关技术
接下来是几种典型的检索技术。
- 综合应用多种过滤技术
我们可以综合应用多种过滤技术来改进检索结果的质量。例如我们可以综合应用元数据、相似度、关键词、内容过滤(删除不符合特定内容标准或基本关键词的结果)、多样性过滤(通过过滤掉近似重复的条目来确保结果的多样性)
- 投票和加权检索
我们可以在上一种方法“综合应用多种过滤技术”之后,再加上投票和加权机制来确定最终检索到的知识。
- 分解成子查询再整合
我们可以将复杂的查询分解为更简单的子查询去检索知识,然后再整合在一起。
- 多轮检索
我们可以检索出一轮之后用大模型分析结果并生成后续查询,这样循环迭代,直到生成最终的结果。不过这种方法只能用在对实时性要求不高的业务场景里,例如实战案例2这种每日生成报告的场景。
- AI智能体检索
我们可以设置一个工作流,这个工作流包含多个AI智能体。每个AI智能体充当不同的角色,使用不同的提示语去检索知识,然后走完整个工作流,得出最终的问答。这种方法也只能用在对实时性要求不高的业务场景。
- 预生成问题和回答
我们可以按照一些模式去预先生成问题,然后使用前面的一些高级但是比较耗时的方法,例如AI智能体检索和多轮检索的方式来生成回答。然后把这些问题和回答存进知识库,当用户提问时,我们根据用户提问检索对应的问题,并返回对应的回答。
排序与回答相关技术
接下来是两种排序和回答的相关技术
- 对知识重新排序
当检索完相关知识之后,我们可以对这些知识的相关性进行重新排序。具体包括:
- 使用专门的重排模型,例如bge-reranker-large。
- 使用语言模型对每个检索到的文本块的相关性进行评分,评分高的排前面。
- 将查询和检索到的文档共同重新编码以进行相似性评分,评分高的排前面。
- 将元数据纳入评分过程,以实现更细致的排序。
- 结合用户反馈的回答
我们可以把用户反馈也整理成一种知识,然后结合这些知识去让大模型生成回答,这项技术也是普遍适用的,比如ChatGPT就采用了这种技术。
RAG技术远远不止以上这些,而且随着时间的发展,RAG技术只会越来越多。那么如何学习更多、更新的RAG技术呢?
授人以鱼不如授人以渔。我们只需要像本节课GraphRAG一节那样,了解清楚一种RAG技术的原理、优点、缺点、适用场景和注意事项,然后再像上节课那样整合进我们的项目里面即可。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了两件事情。
第一件事情是最近大火的GraphRAG。GraphRAG擅长处理针对超长文档的复杂提问,但是门槛、算力成本、时间成本、人力成本都很高。
第二件事情是了解了其他12种RAG技术。我们可以根据自己的实际业务情况决定使用哪种RAG技术。
思考题
如果要对实战案例1应用GraphRAG,应该如何整理出实体和关系,请讲出你的思路。
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- kevin 👍(0) 💬(0)
供应商名称,带出到账金额,总额,未到帐金额,到帐时间。
2024-11-10