21 持续优化:改进应用检索质量有哪些诀窍?
你好,我是叶伟民。
上一节课,我们通过收集反馈和使用质量评估库Ragas,找到了改进RAG应用的正确方向。找到正确的方向之后,我们还需要真正去改进检索质量。
改进检索质量的方法相当多,很难面面俱到。因此接下来的几节课里,我精心挑选了初学者也能轻松上手,而且是比较典型和重要的一些方法和原则,希望能够帮助你在这方面实现0到1的突破。
这节课你需要牢记的改进原则就是,尽量将模糊检索转化为精确检索。
这个原则由两部分组成:
- 将模糊检索转化为精确检索。我们可以看到,第1章的精确检索质量比第3章的模糊检索高很多。
- 尽量转化,而非绝对的非此即彼。之所以说尽量,是因为要完全将模糊检索转化为精确检索是很难做到的。所以我们只能从多个层面入手,尽量地提高转化率。
根据这个原则,我们就能推导出改进RAG应用质量的两种方法:
- 在用户交互层面提供精确信息。
- 在业务逻辑层面提供精确信息(后面将以关键词为例讲解)。
在用户交互层面提供精确信息
我们沿用上一节课的思想,先确定我们的目标。我们的目标是,在用户提问时提供具体模块的信息。在达成这个目标的前提下,我们还要注意,这个修改不能对用户体验造成很大影响。
根据以上目标和注意事项,我们可以在原来的对话界面加上各个模块的标签栏。
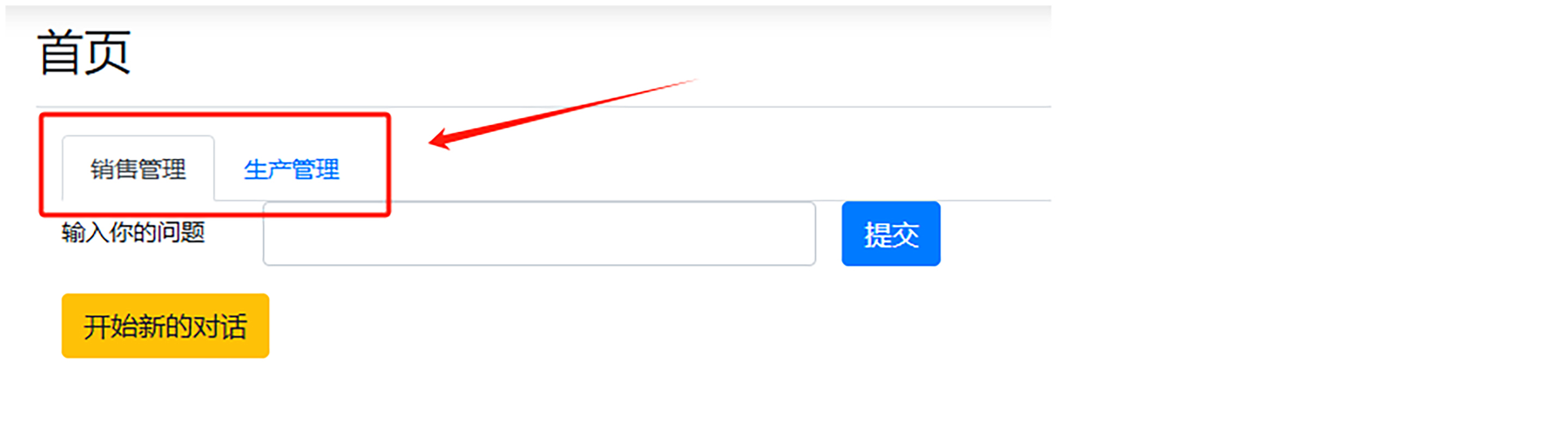
这样用户点击具体标签栏后,再进行提问时,我们将把这个信息传给后台,后台将根据这个信息将知识检索范围缩小到对应模块。
方案定好了,现在我们开始动手实战。我们先在页面添加精确的模块信息。
页面添加精确信息
我们打开 index.html 文件,在表单顶部添加以下代码。
<ul class="nav nav-tabs" id="myTab" role="tablist">
<li class="nav-item" role="presentation">
{% if module == 1 %}
<a class="nav-link active" id="profile-tab" data-bs-toggle="tab" type="button" role="tab" aria-selected="false" href="/?module=1">销售管理</a>
{% else %}
<a class="nav-link" id="profile-tab" data-bs-toggle="tab" type="button" role="tab" aria-selected="false" href="/?module=1">销售管理</a>
{% endif %}
</li>
<li class="nav-item" role="presentation">
{% if module == 2 %}
<a class="nav-link active" id="contact-tab" data-bs-toggle="tab" type="button" role="tab" aria-selected="false" href="/?module=2">生产管理</a>
{% else %}
<a class="nav-link" id="contact-tab" data-bs-toggle="tab" type="button" role="tab" aria-selected="false" href="/?module=2">生产管理</a>
{% endif %}
</li>
</ul>
然后在表单里面加入上面的活跃tab信息,也就是精确的模块信息
完整的html代码参见这里。
在提交提问的时候,我们把精确的模块信息传给后端。那么后端拿到这个精确信息之后需要怎么处理呢?
首先我们需要获取前端传递过来的精确模块信息,我们在views.py文件添加以下代码。
try:
module = request.GET['module']
if module is None:
module = 1
else:
module = int(module)
except:
module = 1
完整的.py代码参见这里。
接下来是重点部分了,如何根据精确信息检索呢?
根据精确信息检索
同学们现在先停一下,深呼吸一口气,思考一下应该要修改哪个环节,修改哪个文件的哪个函数。
3,2,1。好,现在揭晓答案。我们打开 rag.py 文件,修改构造解析用户输入并返回结构化数据用的messages 函数的代码。
def 构造解析用户输入并返回结构化数据用的messages(之前的用户输入,用户输入,module):
if 之前的用户输入 is not None and len(之前的用户输入.strip()) > 0:
用户输入 = 之前的用户输入 + 用户输入
if module == 1:
messages=[
{"role": "user", "content": f"""
请根据用户的输入返回json格式结果,除此之外不要返回其他内容。
示例1:
用户:客户北京极客邦有限公司的款项到账了多少?
系统:
{{'模块':1,'客户名称':'北京极客邦有限公司'}}
用户:{用户输入}
系统:
"""},
]
return messages
return None
我们可以看到,修改之前,我们是靠大模型猜测用户想在哪个模块查询信息。但让大模型来猜测这种做法不但很耗时,而且还有可能猜错。
修改之后,因为获得了精确的模块信息,检索更精确了。除此之外,我们的提示语,也就是messages部分也变得简短了很多。
重构
然而这里有个问题,我们修改了核心的 rag.py 文件代码!正如前面课程所讲的,我们只是增强了检索知识的部分,至于整个RAG流程,其实是没有做任何改变的。所以我们不应该修改核心的 rag.py 文件代码。
发现了这个矛盾 ,就说明我们的设计很可能有问题!我们需要重构一下。
我们把刚才的函数从 rag.py 文件抽离到 prompt.py 文件。整个 prompt.py 文件就变成了后面这样。
def 构造解析用户输入并返回结构化数据用的messages(之前的用户输入,用户输入,module):
if 之前的用户输入 is not None and len(之前的用户输入.strip()) > 0:
用户输入 = 之前的用户输入 + 用户输入
if module == 1:
messages=[
{"role": "user", "content": f"""
请根据用户的输入返回json格式结果,除此之外不要返回其他内容。
示例1:
用户:客户北京极客邦有限公司的款项到账了多少?
系统:
{{'模块':1,'客户名称':'北京极客邦有限公司'}}
用户:{用户输入}
系统:
"""},
]
return messages
return None
通过这样的修改,以后再做类似操作,我们就不需要修改 rag.py 文件了,只需要修改 prompt.py 文件即可。
然后我们再在 rag.py 文件传递精确模块信息。
注意,这里我们还更新了相关的调用,这些小细节这里我们就不铺开了。同学们可以在这里查看完整的代码。
现在我们已经讲了一个在用户交互层面提供精确信息的例子。接下来,我们再来看一个在业务逻辑层面提供精确信息的例子。我就以目前最常见的关键词为例。
关键词
在有些用户场景里面,有些事物是必须要精确检索而不能模糊检索的。
比如在一个金融类的RAG应用里面,用户提问:300498昨天有什么新闻?这里的300498是一个股票代码。很显然,这时候根据300498去模糊检索肯定效果不理想,那样可能会返回300497或300499的内容,只能精确检索300498相关的内容。
再比如说,在我们的实战案例1里面,用户提问:配件sh-d32还有多少?这里的sh-d32是一个配件型号,同样不能根据它去模糊检索,那样可能会返回其他型号的数据,只能精确检索sh-d32相关的数据。
明确了这类用户场景的特点,我们来给RAG应用添加一些代码,实现靠关键词精准检索的功能。
我们先来设计数据库表结构。
数据库表结构设计
对于实战案例1,我们不需要专门建表。
对于实战案例3,我们需要专门新建一个表来存储关键词表,它具有如下字段。
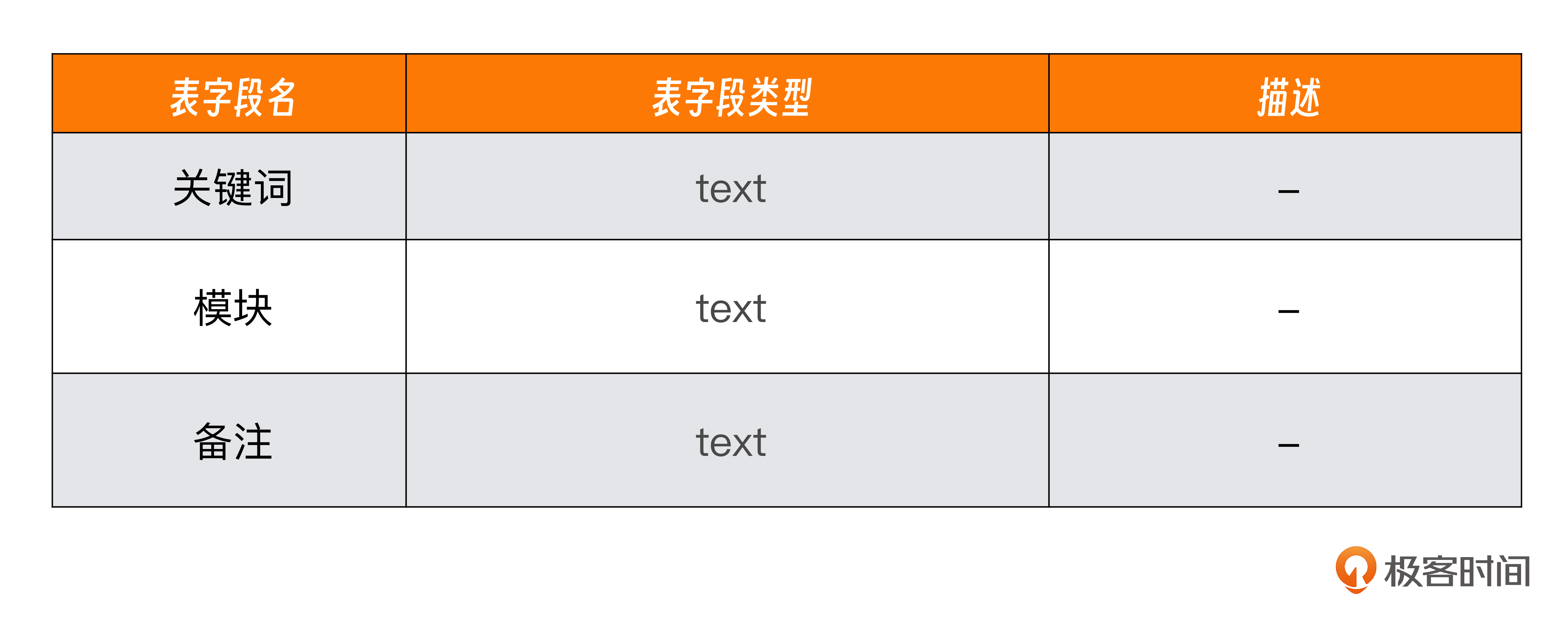
我们打开 models.py 文件,在尾部加入以下代码。
class 关键词(models.Model):
id = models.IntegerField(
primary_key = True,
editable = False)
created_time = models.DateTimeField(auto_now_add=True)
lastmodified_time = models.DateTimeField(auto_now=True)
关键词 = models.TextField()
模块 = models.TextField()
备注 = models.TextField()
然后我们切换到 Anaconda Powershell Prompt,输入以下命令更新数据库。
这时候应该提示数据库更新成功。然后我们需要打开数据库确认操作无误。
我们使用第16节课讲过的 pgadmin,打开 home_关键词表。这时我们应该看到已经成功添加了相关列。
这里为了简单起见,我们直接在 pgadmin 的 home_关键词表新增两条记录。
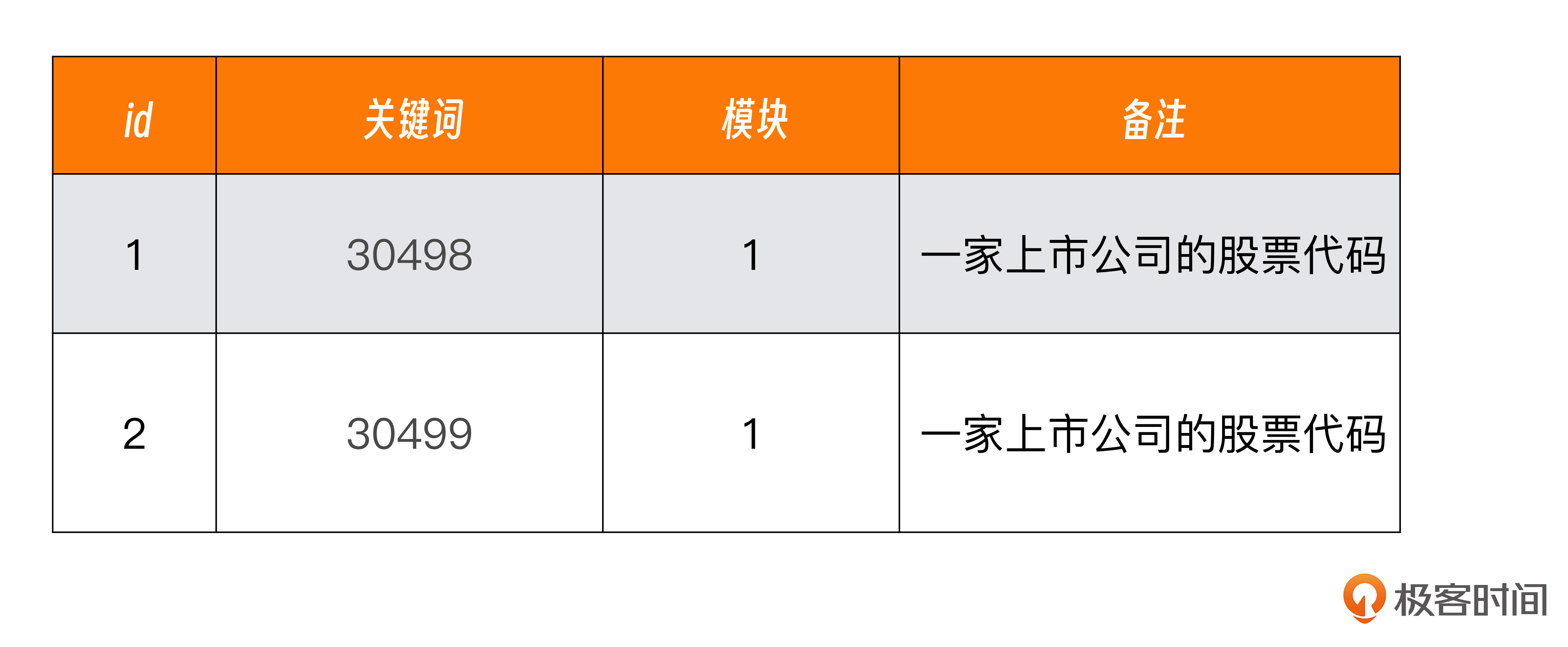
在现实工作中,home_关键词这个表应该用程序导入。
home_关键词这个表只提供关键词检索,不提供更详细业务数据。所以我们还需要在 home_销售入账记录 这个表添加业务数据。

根据关键词检索
我们打开 views.py 文件,在 index 函数的获取用户输入之后,获取查询参数之前添加代码。
def index(request):
...之前没有变的的代码
用户输入 = request.POST['question']
# 加入关键词检索代码
关键词RawQuerySet = 关键词.objects.raw("SELECT id, 关键词, 模块, 备注 FROM public.home_关键词 where 模块='" + str(module) + "' and position(关键词 in '" + 用户输入 + "') > 0;")
if 关键词RawQuerySet is not None and len(关键词RawQuerySet) > 0:
if module == 1:
查询参数 = {'模块':1,'客户名称':关键词RawQuerySet[0].关键词}
else:
查询参数 = 获取结构化数据查询参数(用户输入,module)
# 加入关键词检索代码
查询结果 = None
if 查询参数 is not None:
...之前没有变的的代码
我们可以看到,现在如果命中了关键词,我们完全就不需要通过大模型去获取查询参数了,我们的查询参数更准确,速度也更快了。
注意,这里我们还更新了相关的引用,还fix了一个bug,这些小细节这里我们就不铺开了。同学们可以在这里查看完整的代码。
至此,我们通过在页面添加模块信息实现了模块部分的精确检索,在业务逻辑层面通过关键词实现了业务部分的精确检索。
现在我们学到了两种改进RAG质量的技术。但是仅仅靠这两种技术是不够的,那么我们如何去学习其他改进RAG质量的技术呢?下一节课我们将介绍一种很实用的方法,就是查看Langchain、Llamdindex源码,学习改进RAG质量的技术。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了两件事情。
第一件事情是在用户交互层面提供精确信息。我们可以在不对用户体验造成很大影响的前提下,增加更多精确信息,从而缩小知识检索范围,改进知识检索质量,例如在首页添加各个模块的标签栏。
第二件事情是尽量扩大精确检索的范围。本质上说,这也是通过各种精确信息缩小知识检索范围,目前最流行的方法是通过关键词精确检索。
思考题
发挥你的想象力,想象一下还有什么方法能够将模糊检索转化为精确检索?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- kevin 👍(1) 💬(1)
期待老师把代码补全了。
2024-10-24 - 坤 👍(0) 💬(0)
降低信息熵,消除不确定性
2024-11-25