20 找准方向:如何有效评估与改进RAG应用
你好,我是叶伟民。
前面三章我们讲述了三个实战案例,实现了0到1的突破,但是它们都很简陋,需要持续改进。最后一章我们就来学习如何改进RAG应用的检索质量。
改进质量的第一步是找到正确的方向。那么如何找到正确的方向呢?
首先我们要明确业务目标,然后根据业务目标制定指标,再根据实际的指标值改进检索技术。这种方法一步到位,但是相当理想,现实中很难实现,因为我们很难马上找到完全吻合自己业务的指标实现。
于是就有了接下来这种做法——先明确业务目标,然后找到现成的指标实现库,再根据实际的指标值改进检索技术和修改指标实现。你可能要在调整了N轮之后,才能得出完全吻合自己业务的指标实现,但这个方式胜在接地气,而且很符合软件工程师所熟悉的迭代作业模式。
那么都有哪些现成的指标实现库呢?
评估指标实现库
评估指标实现库有不少,经过比较、研究、实践,目前我比较推荐Ragas(Ragas的网址是 https://docs.ragas.io)。
推荐它的理由有三条:
- 与竞品相比,文档相对较完备。
- 专业度比较高,专注于做RAG评测。
- 支持与LLamaIndex、LangChain等11种RAG框架集成。
Ragas目前实现了十项评估指标,我们挨个来看看。
忠实度(Faithfulness)指标用于衡量生成答案与给定上下文的事实一致性。如果生成答案中的所有声明都可以从给定的上下文中推断出来,则认为该答案是忠实的。
答案相关性(Answer Relevance)侧重于评估生成答案与给定提示的相关性。对于不完整或包含冗余信息的答案,会给出较低的分数,而较高的分数表示更好的相关性。这个指标是通过问题、上下文和答案来计算的。答案相关性定义为原始问题与基于答案生成(逆向工程)的若干人工问题之间的平均余弦相似度。
上下文查准率(Context Precision)用于判断上下文中存在的所有真实相关项,是否都排在了较高的位置。理想情况下,所有相关的信息块都应该出现在顶部排名。这个指标是通过问题、真实答案和上下文来计算的,其值范围在0到1之间,分数越高表示查准率越高。
上下文利用率(Context utilization):上下文利用就像是上下文查准率指标的无参考版本。也就是关注是否利用了所有可用的信息块,而忽略掉它们的顺序如何。
上下文查全率(Context Recall),它衡量的是检索到的上下文与作为真实答案的标注答案的一致程度。该指标是通过问题、真实答案和检索到的上下文来计算的,其值范围在0到1之间,数值越高表示性能越好。为了从真实答案中估计上下文召回率,会分析真实答案中的每个声明,以确定它是否可以归因于检索到的上下文。在理想情况下,真实答案中的所有声明都应该可以归因于检索到的上下文。
上下文实体查全率(Context entities Recall),衡量从真实答案中召回的实体比例的一个指标。具体就是根据真实答案和上下文中存在的实体数量相对于单独在真实答案中存在的实体数量,来衡量检索到的上下文的召回率。
这个指标在有事实依据的用例中很有用,比如旅游咨询台、历史问答等。这个指标可以帮助评估基于与真实答案中实体的比较的实体检索机制,因为在实体重要的情况下,我们需要覆盖这些实体的上下文。
答案语义相似度(Answer semantic similarity),用于评估生成答案与真实答案之间的语义相似度。这个评估是基于真实答案和答案进行的,其值在0到1的范围内。分数越高,表示生成的答案与真实答案间的一致性越好。
答案正确度(Answer Correctness),用衡量生成的答案与真实答案相比的准确性。这个评估依赖于真实答案和答案,分数范围从0到1。分数越高表示生成的答案与真实答案之间的一致性越好,意味着正确度更高。
答案正确度包括两个关键方面:生成答案与真实答案之间的语义相似度以及事实相似度。这些方面通过加权方案结合起来,形成答案正确性分数。用户还可以选择使用一个“阈值”值将结果分数四舍五入为二进制(如果需要)。
特定领域评估(Domain Specific Evaluation),特定领域评估指标用于评估模型在特定领域的性能。评分标准包含了每个分数的描述,通常范围在从1到5分。
摘要分数(Summarization Score),这个指标衡量摘要在捕捉上下文重要信息方面的表现如何。这个指标背后的直觉是,一个好的摘要应该包含上下文所有重要信息。我们首先从上下文中提取一组重要的关键词。然后使用这些关键词生成一组问题。接着我们向摘要提出这些问题,并计算摘要得分为正确回答的问题数与问题总数的比率。
现如果你想直接把刚刚这些Ragas指标用到我们前面实战案例的评估,就会发现门槛还是有点高,难度比较大。为什么呢?因为我们没有评估所需要的基础数据,所以我们需要先采集相关数据。
那如何采集评估所需要的基础数据呢?一种方法是让数据标注员人工提问和标注,这种方法成本很高。目前最常见,也是最容易的方法是让用户直接提供反馈,然后收集这些结果,再让数据标注员分析和标注。
收集用户反馈结果
我们先看看用户提供反馈的界面:
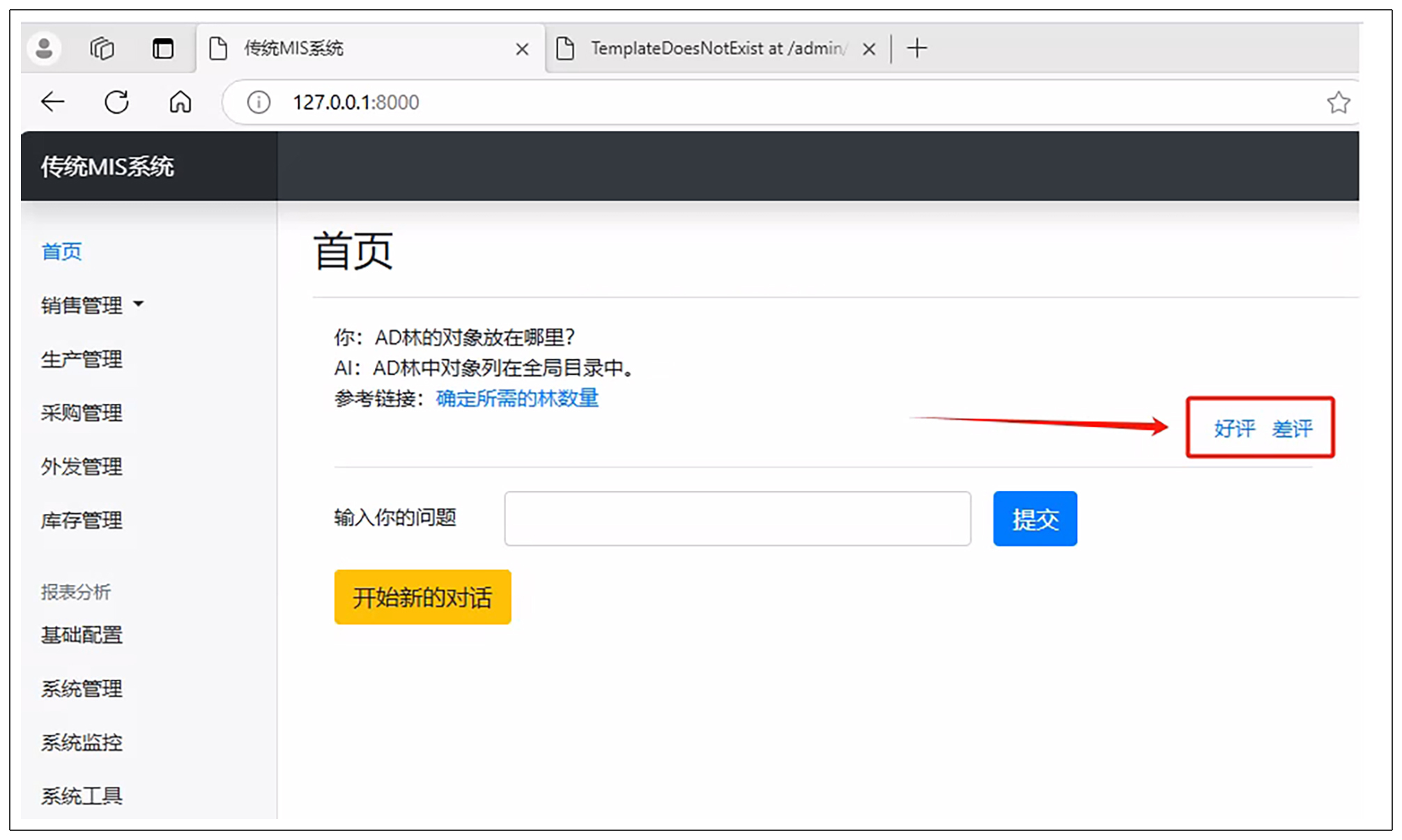
用户提供反馈主要有两个按钮,就是上图红色部分的按钮。
实现起来也相当简单。我们首先实现界面。
实现界面
我们打开 index.html 文件,在底部添加以下代码。
<div class="text-right">
<a href="review?conversationid={{current_obj.id}}&review=positive">好评</a>
<a href="review?conversationid={{current_obj.id}}&review=negative">差评</a>
</div>
实现ORM模型
完成界面之后,我们还需要添加ORM模型。我们打开 models.py 文件,添加以下代码。
positive_review = models.BooleanField(default=False, verbose_name='好评')
negative_review = models.BooleanField(default=False, verbose_name='差评')
需要注意的是,我们并没有将好评和差评数据整合成一个字段,而是分成两个字段,这么做是为了方便管理员在后台查看。你不妨根据你自己的实际情况来决定是使用一个字段还是两个字段。
注册到管理员后台
然后我们打开 admin.py 文件,添加以下代码。
from django.contrib import admin
from .models import Product
@admin.register(对话记录)
class 对话记录Admin(admin.ModelAdmin):
list_display = ('name', 'positive_review', 'negative_review') # 显示的字段列表
search_fields = ('name',) # 可搜索的字段列表
list_filter = ('positive_review', 'negative_review') # 可过滤的字段列表
数据标注员通过管理员后台下载数据
现在开发人员可以通过管理员后台分析数据。我们打开http://localhost:8000/admin,找到对话记录管理页面,我们可以点击右边面板的好评或差评按钮来过滤数据。
不过,数据标注员如果也用开发人员这种方式来获取数据就太慢了。
所以我们提供了另一种方式给数据标注员获取数据,就是直接批量下载所有数据。
实现起来也并不复杂。首先,我们回到 Anaconda Powershell Prompt,按ctrl+c停止运行。然后输入以下命令安装Django管理员数据导入导出库。
接下来,我们打开 settings.py 文件,并在 INSTALLED_APPS 列表中添加 import_export。(已经有同学因为遗漏这一步导致出错,所以当代码运行不了的时候,请同学们仔细检查一下是否遗漏了步骤)
这时候我们回到刚才的管理员界面,我们会看到右上角多出了导入和导出两个按钮。

现在我们就可以通过点击导出按钮来下载数据。
这里我提示一下,现在我们也可以将以上类似操作应用在第7节课诊断调试部分,这样开发人员也可以批量下载数据来诊断调试RAG应用了。
这节课的完整源代码你可以从这里获取。
(更详细的步骤参见这节课配套代码的如何运行本节课程序.md 文件。)
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了两件事情。
第一件事情是如何评估RAG应用的质量。比较接地气的做法是先明确业务目标,然后找现成的指标实现库,再根据实际的指标值改进检索技术和修改指标实现,在调整了N轮之后才得出完全吻合自己业务的指标实现。我们重点学习了Ragas这个RAG评估库,并学习了它所支持的评估指标。
第二件事情是如何收集评估RAG应用所需要的数据。我们在用户界面提供了好评和差评按钮,然后在管理员界面添加了相应模块,开发人员可以根据这些数据分析和改进应用,数据标注员可以下载这些数据进行标注加工以评估RAG应用。
下一节课开始,我们将继续学习一些用于改进RAG应用质量的知识:用LLM分类、知识分块、关键词。
思考题
Ragas实现了这么多指标,我们是否全部都需要关心呢?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- kevin 👍(0) 💬(1)
请问老师,用户反馈的界面我加了相应的代码,没起作用呀。
2024-10-24