19 动手实战 实现实战案例3
你好,我是叶伟民。
上一节课我们使用模糊检索知识最基本的概念改造了实战案例1。这节课我们趁热打铁,继续动手实战,使用模糊检索知识最基本的概念实现实战案例3。
在动手操作之前,我们先梳理一下整体的流程。实现实战案例3主要包括五个步骤:
- 搭建向量编码服务(复用实战案例1已经搭建好的服务)
- 设计数据库(可参考实战案例1)
- 知识入库(可参考实战案例2)
- 检索知识(可参考实战案例1和2)
- 显示相关链接
考虑到我们已经进入第四章,所以从这节课开始,前面讲过的基础(例如激活虚拟环境)将不再重复了,更具体的步骤会列在这节课配套代码的如何运行本节课程序.md 文件里面,配套代码你可以从这里获取。
好,我们正式开始今天的学习吧。
设计数据库
第1步搭建向量编码服务完全复用实战案例1已经搭建好的服务,所以我们就不重复讲解了,如果不熟悉的话,你可以回顾第一章的内容。我们从第2步设计数据库开始讲起。
表结构设计
我们先来思考这样一个问题,纯知识类RAG应用的数据库结构与基于MIS系统的RAG应用(也就是实战案例1)有什么区别呢?
答案是纯知识类RAG应用的数据库至少要有两个表。第一个表是主表,由元数据组成,这个表我们直接参考实战案例2,也就是第9节课的内容。于是我们得出了后面这个表。
class 知识主表(models.Model):
id = models.IntegerField(
primary_key = True,
editable = False)
模块 = models.TextField(null=True,blank=True)
标题 = models.TextField(null=True,blank=True)
url = models.TextField(null=True,blank=True)
向量编码 = VectorField(dimensions=1024,null=True,blank=True)
向量编码模型 = models.TextField(default="bge-large-zh-v1.5")
第二个表是详细表,由文本和对应的向量编码组成,这个表我们直接参考实战案例1,也就是第18节课的内容。于是我们得出了后面这个知识详细表。
class 知识详细表(models.Model):
id = models.IntegerField(
primary_key = True,
editable = False)
文本内容 = models.TextField()
内容在分段中的顺序 = models.IntegerField(null=True,blank=True)
向量编码 = VectorField(dimensions=1024,null=True,blank=True)
向量编码模型 = models.TextField(default="bge-large-zh-v1.5")
知识主表 = models.ForeignKey(知识主表, on_delete=models.CASCADE)
执行命令更新数据库
然后我们切换到 Anaconda Powershell Prompt,输入以下命令更新数据库。
这时候应该提示数据库更新成功。然后我们需要打开数据库确认操作无误。
打开数据库确认操作无误
我们使用第16节课讲过的 pgadmin,打开知识主表表。这时我们应该看到已经成功添加了所有元数据列。
我们再打开知识详细表表做个检查。这时我们应该看到已经成功添加了向量编码和向量编码模型这两列。其中向量编码的数据类型为我们在第16节课讲过的 vector 类型。
知识入库
设计完数据库之后,我们可以知识入库了。
实战案例1的数据早就在数据库里面了,所以不需要这一步。实战案例2包含了知识入库步骤,于是我们可以参考实战案例2,也就是第11节课的内容来完成知识入库。
导入原始内容
这里我们重申第11节课的精神,也就是尽量选择最容易的知识入库方法。
然后结合第14节课“选择合适自己的RAG应用立项”一节的精神,建议同学们在项目立项阶段尽量不考虑必须从PDF和Word导入知识的项目,这些项目所耗费的时间精力会远比你想象中的高,会是个大坑。
回到我们今天节课,这里我们直接通过Excel导入,我们运行 import_data_from_excel.py 文件即可,它会把 data.xlsx 的数据导入到数据库。
对知识批量编码并存进数据库
现在原始内容已经入库,我们还需要对知识进行编码。
我们继续在 api.py 文件尾部添加后面的代码。
def 对知识批量进行向量编码(request):
未编码的知识list = 销售入账记录.objects.filter(客户向量编码__isnull=True)
for current in 未编码的知识list:
current.客户向量编码= 调用向量编码服务(current.客户)
current.save()
result = {'code':200}
return JsonResponse(result)
这段代码与第18节课相关代码类似,同学们可以直接参考,我们就不浪费时间重复了。
然后我们在 postman 调用http://127.0.0.1:8000/api/knowledge-embedding-batch 即可批量编码并将其保存进数据库。
除此之外,我们还可以在数据入库的时候就调用以上函数进行向量编码。
检索知识
现在知识已经入库,我们可以检索知识了。检索知识由两部分组成,其中根据元数据检索部分可以参考实战案例1,其他部分可以参考实战案例2。
我们打开 search.py 文件,往查询函数里添加后面这段代码。
else:
查询字符串 = 查询参数.strip()
查询字符串向量编码 = 调用向量编码服务(查询字符串)
模糊搜索结果RawQuerySet = 知识详细表.objects.raw('SELECT *, 1 - (向量编码 <=> %s) AS 余弦相似度,文本内容 FROM public."home_知识详细表" order by 余弦相似度 desc;',[str(查询字符串向量编码),])
选取的结果 = 模糊搜索结果RawQuerySet[0]
模糊搜索结果 = {
'知识内容': 选取的结果.文本内容,
'url': 选取的结果.知识主表.url,
'标题': 选取的结果.知识主表.标题
}
return 模糊搜索结果
这段代码与第18节课相关代码类似,相信结合注释你很容易就能理解。
显示相关链接
我们打开 index.html 文件,在底部添加以下代码。
{% if link_text is not None %}
<div>
参考链接:<a href="{{link_url}}" target="_blank">{{link_text}}</a>
</div>
然后我们打开 http://localhost:8000, 我们将看到如下界面。
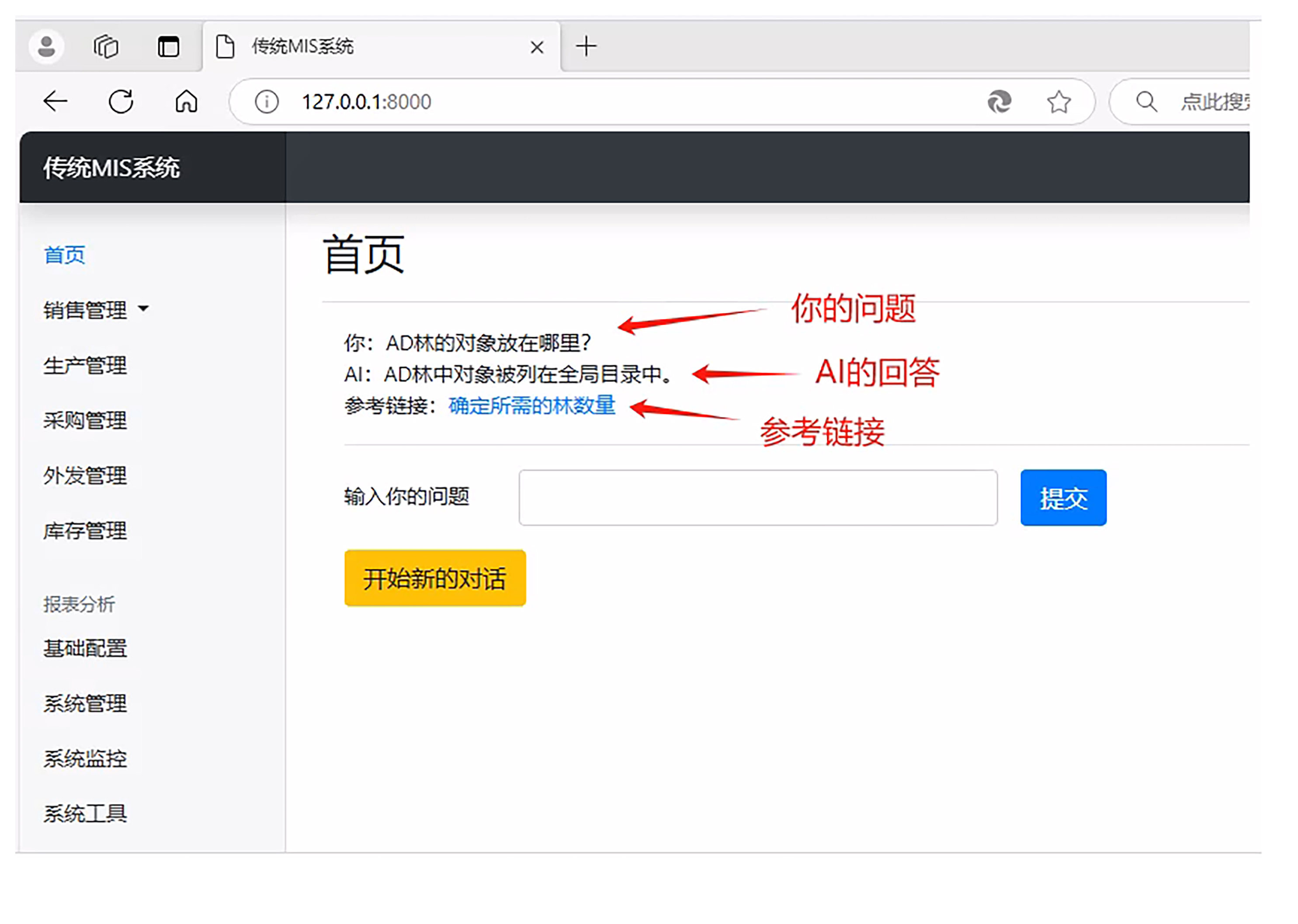
与实战案例1(也就是第18节课)所讲的类似,我们修改了很多代码文件,就是没有修改rag.py 文件。因为我们只是增强了检索知识的部分,至于整个RAG流程,其实没做任何改变。这是本节课甚至这门专栏的重点,RAG只有一个核心,提升检索知识的质量,更通俗地说,就是保证检索到的第一条知识是最匹配用户提问的,然后喂给大模型。如果能够做到这点,根本就不需要重排了(rerank)。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了四件事情。
第一件事情是设计纯知识类RAG应用的数据库结构。纯知识类RAG应用的数据库结构至少由两个表组成。第一个表称为主表,由元数据组成。第二个表是详细表,由具体文本和向量编码组成。
第二件事情是知识入库。我们直接从excel表导入。需要提醒的是,在项目立项阶段尽量不考虑必须从PDF和Word导入知识的项目,这些项目所耗费的时间精力会远比你想象中的高,会是个大坑。
第三件事情是检索知识。与实战案例1相比,实战案例3基本靠模糊检索,所以严重依赖于前面所讲的基础概念。你也可以借机复习巩固一下之前所学。
第四件事情是显示相关链接。RAG本质上是搜索应用,只不过因为大模型的发展,大幅提升了摘要和检索的质量,从而提升了用户体验。显示相关链接其实就是传统搜索应用所具备的功能。
下一节课开始,我们将学习如何评估和改进RAG应用的检索质量。
思考题
发挥你的想象力,想象一下自己企业有哪些RAG应用是不需要从PDF和Word导入知识的。请认真想想,根据我的经验,实际上这些RAG应用还是有的,甚至不少。
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- 悟远 👍(0) 💬(1)
"然后我们在 postman 调用 http://127.0.0.1:8902/api/knowledge-embedding-batch 即可批量编码并将其保存进数据库。" —— 这里端口错了,应用是 Django 的服务端口 8000
2024-11-04 - kevin 👍(0) 💬(1)
import_data_from_excel.py,data.xlsx这两个文件在github是没有下载,请问在哪里下载。
2024-10-24 - Geek_0a887e 👍(0) 💬(2)
这个章节是啥?文章的代码是不是漏了什么东西,确定是这么写的吗?没头没尾的
2024-10-16 - narsil的梦 👍(0) 💬(0)
中级篇看完了,没看到讲解工单辅助系统的地方😭
2024-12-08 - kevin 👍(0) 💬(0)
class 知识主表(models.Model):中的这段代码和19节课中的代码并不一致,如果把这段代码拷贝到程序中去执行,会出错,大家要注意了。
2024-11-13