18 动手实战:改造实战案例1
你好,我是叶伟民。
学习了模糊检索知识最基本的概念之后,这节课我们开始动手实战,改造前面的实战案例1。目前实战案例1不支持模糊检索,也就是说用户只有输入公司全名,才能检索到该公司的相关数据。
等我们完成改造之后,用户在提问时即使没有输入公司全名,系统也能够模糊检索到相关数据。例如用户输入“广州神机妙算的款项到账了多少?”,系统将会检索到“广州神机妙算有限公司”的数据。
搭建向量编码服务
在改造之前,我们需要先打造一个基础设施,就是搭建向量编码服务。
看到这你可能有个疑问,为什么需要搭建向量编码服务,而不是直接在MIS系统里面进行向量编码呢?因为加载向量模型很耗时间和内存资源,将这部分代码单独拆分出一个服务更容易扩展和维护。
安装依赖
我们新建一个 Anaconda Prompt Powershell 激活实战案例1的虚拟环境。然后输入以下命令安装相关依赖。
pip install sentence_transformers
pip install langchain==0.0.306
pip install fastapi
pip install uvicorn
需要注意的是,以上命令的第二行需要指定LangChain的版本,不然会导致配套代码跑不通。LangChain改得太频繁了,这不是重点,重点是不向前兼容。这也是我诟病LangChain,不选择LangChain作为这门课基础框架的原因。
下载向量模型
然后我们新增一个目录,命名为嵌入模型服务。在目录下新建 download.py 文件,输入以下代码。
from langchain.embeddings import HuggingFaceBgeEmbeddings
向量编码模型本地存放路径 = "F:\LLAMA_INDEX_CACHE_DIR\models\embeddings"
向量编码本地所使用的device = "cpu" # "cuda"
model_name = "BAAI/bge-large-zh-v1.5"
cache_folder=向量编码模型本地存放路径
model_kwargs = {'device': 向量编码本地所使用的device} #{'device': 'cuda'} # {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
HuggingFaceBgeEmbeddings(model_name=model_name,cache_folder=cache_folder,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs)
注意,你需要把第3行代码的本地存放路径改为你的实际路径。
这个 download.py 文件的目的是将向量模型下载到本地。
接下来我们在 Anaconda Prompt Powershell 运行以下命令将向量模型下载到本地。
如果一切顺利,将会出现以下结果。

对外公开向量编码服务
之后我们新增一个文件,命名为 main.py,输入以下代码。
from fastapi import FastAPI, Request
import uvicorn
from 向量编码器 import 向量编码器
app = FastAPI()
@app.get("/")
async def read_root():
return {"hello word":"这里是向量编码服务"}
app.向量编码器instance = None
@app.on_event('startup')
def init_data():
app.向量编码器instance = 向量编码器()
@app.post("/api/embedding/encode")
async def 向量编码(request: Request):
data = await request.json()
print(data)
input_str= data["input"]
return_result = app.向量编码器instance.向量编码(input_str)
return return_result
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8902)
其中第13行到16行代码是服务初始化代码。接下来的第17到23行是向量编码函数。其中第19行和21行代码的作用是接收输入字符串,第22行代码负责对输入字符串进行向量编码,然后通过第23行代码返回编码结果。
从第3行代码可以看到,我们导入了一个向量编码器类,因此我们需要新增一个文件,命名为向量编码器.py,输入以下代码。
# coding=utf-8
from langchain.embeddings import HuggingFaceBgeEmbeddings
class 向量编码器:
def __init__(self):
向量编码模型本地存放路径 = "F:\LLAMA_INDEX_CACHE_DIR\models\embeddings"
向量编码本地所使用的device = "cpu"
model_name = "BAAI/bge-large-zh-v1.5"
cache_folder=向量编码模型本地存放路径
model_kwargs = {'device': 向量编码本地所使用的device} #{'device': 'cuda'} # {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
self.embed_model = HuggingFaceBgeEmbeddings(model_name=model_name,cache_folder=cache_folder,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs)
def 向量编码(self,query: str):
embed_result = self.embed_model.embed_query(query)
return {'向量编码':embed_result}
注意,你需要把第6行代码的本地存放路径改为你的实际路径。
测试向量编码服务
这时候我们可以测试一下向量编码服务是否运作正常。
我们先在 Anaconda Prompt Powershell 输入以下命令把向量编码服务运行起来。
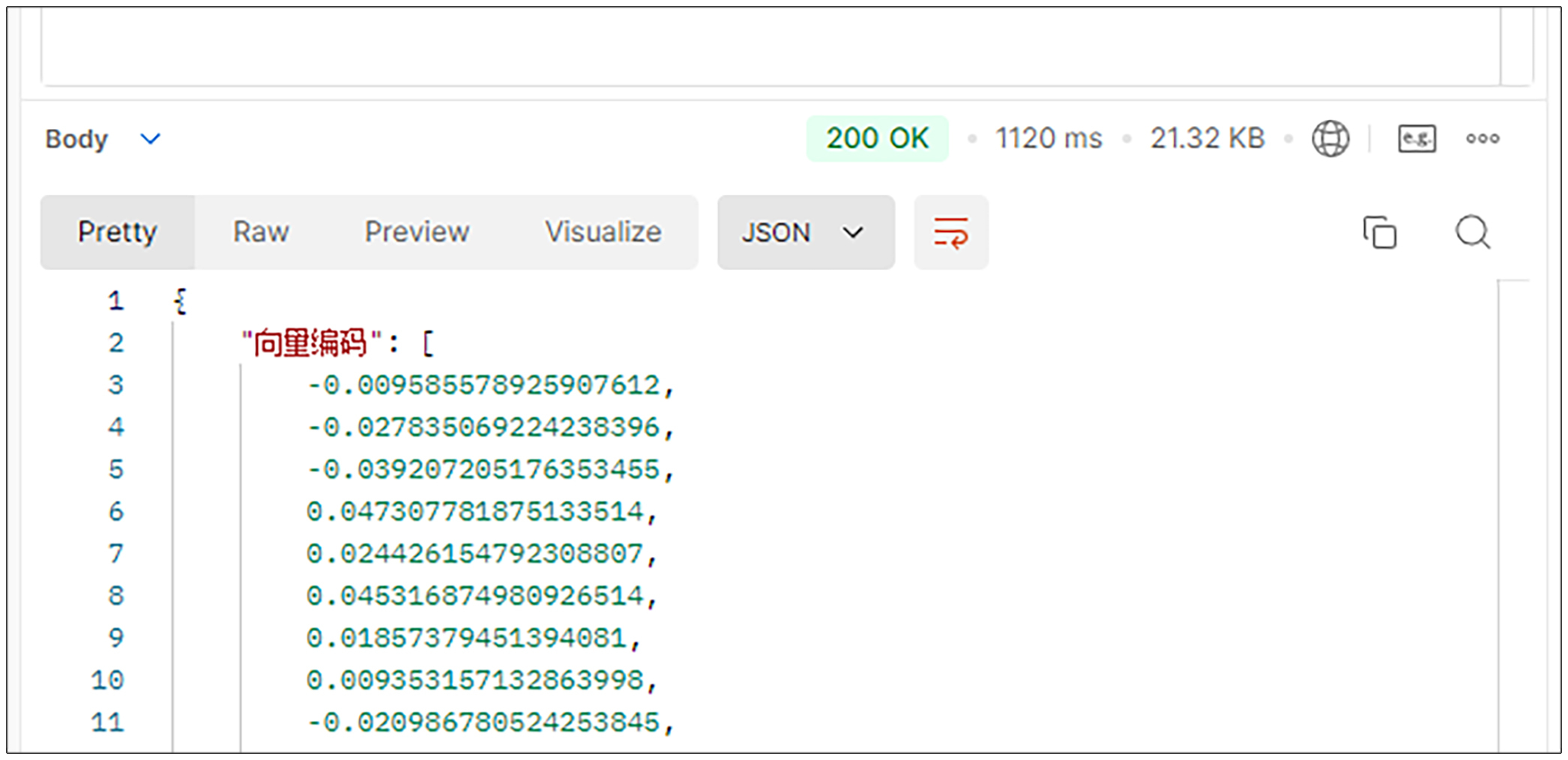
然后打开postman,以POST方式调用http://127.0.0.1:8902/api/embedding/encode。
其中在body处以json格式输入以下内容。
然后将返回后面的json结果。
搭建向量数据库
搭建完向量服务之后,我们还需要搭建向量数据库。我们同样需要先安装依赖。
安装依赖
我们新开一个 Anaconda Prompt Powershell 激活实战案例1的虚拟环境。然后输入以下命令安装相关依赖。
第1行的psycopg2是Python操作pgsql的库,第2行的pgvector是Django专门用于操作向量列的库。
将数据库从sqlite改为pgsql
安装完依赖之后,我们需要将Django从默认使用的sqlite数据库改为使用pgsql数据库。
我们打开实战案例1 mysite 目录下的 setting.py 文件,找到以下代码。
# Database
# https://docs.djangoproject.com/en/4.2/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
我们需要把这段代码做个修改,改成以下代码。
# Database
# https://docs.djangoproject.com/en/4.2/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'geekrag-1',
'USER': 'postgres',
'PASSWORD': '1234567Abc',
'HOST': 'localhost',
'PORT': '5432',
}
}
其中第6行是指定使用pgsql数据库,第7行是数据库名字,第8行是pgsql的用户名,第9行是pgsql的密码,第10行是pgsql的端口。
将id字段改为pgsql支持的格式
目前我们ORM的id字段是pgsql不支持的,因此我们需要改为pgsql支持的格式,我们打开 home目录下的 models.py 文件,找到id字段,改为以下形式。
做好前面这些准备,现在我们可以改造实战案例1了。
整个改造过程包括以下步骤:
- 添加向量编码列和嵌入模型列。
- 对知识进行向量编码并将编码结果保存进数据库。
- 对查询参数进行向量编码。
- 根据查询参数的向量编码按相似度进行检索。
添加向量编码和嵌入模型列
我们首先开始第一步,在数据表中添加向量编码列。
关于这一步,我们可以通过数据库管理工具 pgadmin 的UI进行操作,这是我们第16节课学过的内容。但是比较幸运的是,我们的MIS系统在ORM层面就支持添加向量编码列,因此操作起来比前面所讲的还要方便。
这里需要注意,在你的现实工作中,如果你的系统在ORM层面不支持添加向量编码列,那么你仍然可以通过 pgadmin 的UI添加向量编码列。
在ORM层面添加列
我们打开 home 文件夹下面的 models.py 文件。在文件的顶部加入以下代码。
然后在客户这一行代码下面加入以下两行代码。
客户向量编码 = VectorField(dimensions=1024,null=True,blank=True)
客户向量编码模型 = models.TextField(default="bge-large-zh-v1.5")
其中第2行代码用于设置我们希望使用的向量编码模型,这里我们设置为智谱向量编码模型的大型中文版本。
第1行代码的 VectorField 表示向量编码字段。与其他字段相比,它具有维度概念(如果印象不深可以回顾第15、16节课),这里设置为我们所使用的向量编码模型的维度,也就是1024维。
现在整个销售入账记录 ORM模型类代码就会变成后面这样。
class 销售入账记录(models.Model):
id = models.AutoField(primary_key=True)
客户 = models.CharField(max_length=255)
客户向量编码 = VectorField(dimensions=1024,null=True,blank=True)
客户向量编码模型 = models.TextField(default="bge-large-zh-v1.5")
入账日期 = models.DateTimeField()
入账金额 = models.TextField(null=True)
已到账款项 = models.IntegerField(null=True)
剩余到账款项 = models.IntegerField(null=True)
执行命令更新数据库
然后我们切换到 Anaconda Powershell Prompt,输入以下命令更新数据库。
这时候如果一切顺利的话,应该提示数据库更新成功。然后我们需要打开数据库确认操作无误。
打开数据库确认操作无误
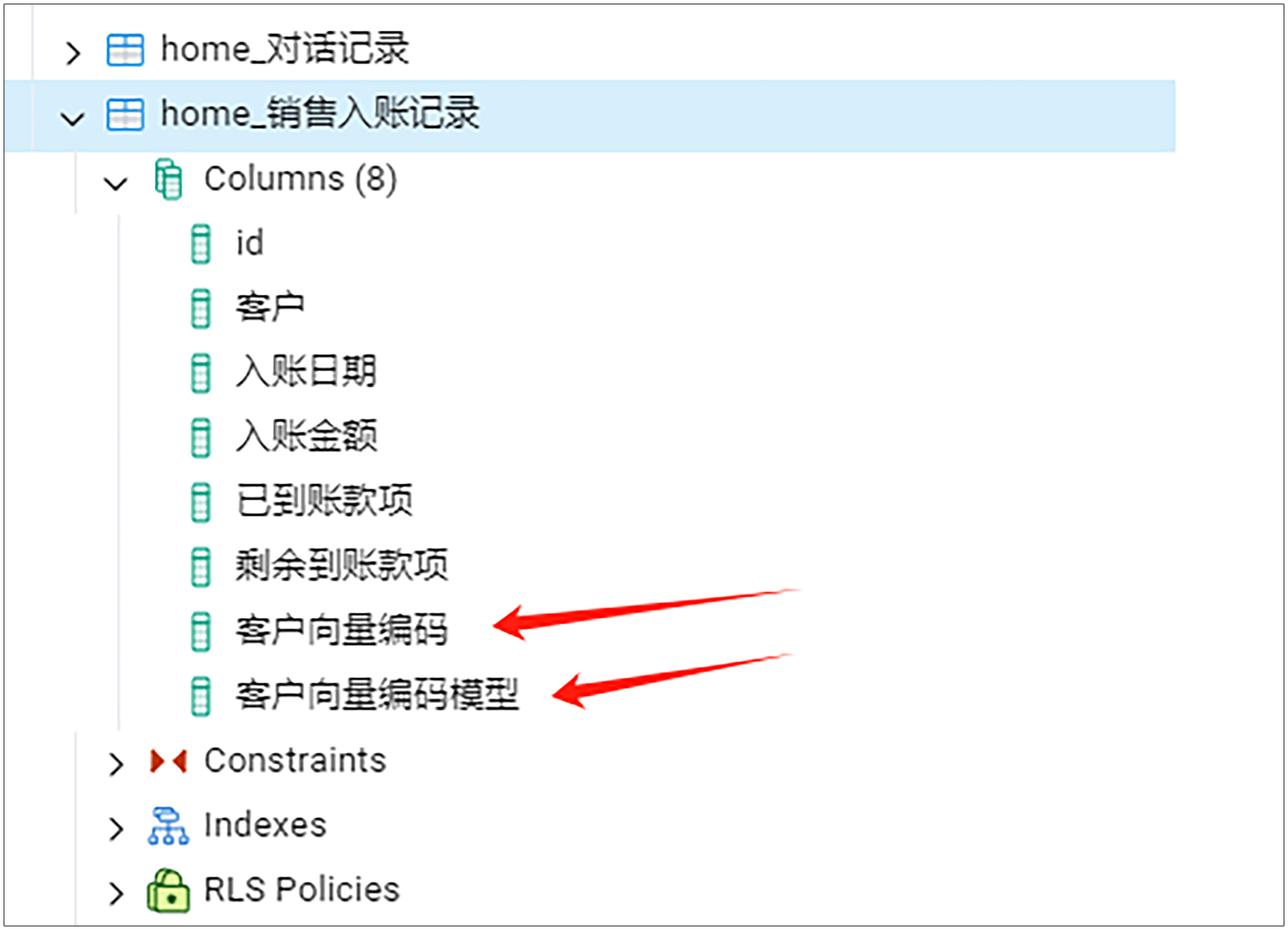
现在我们需要通过UI打开数据库验证操作无误,这是我们第16节课学过的内容。
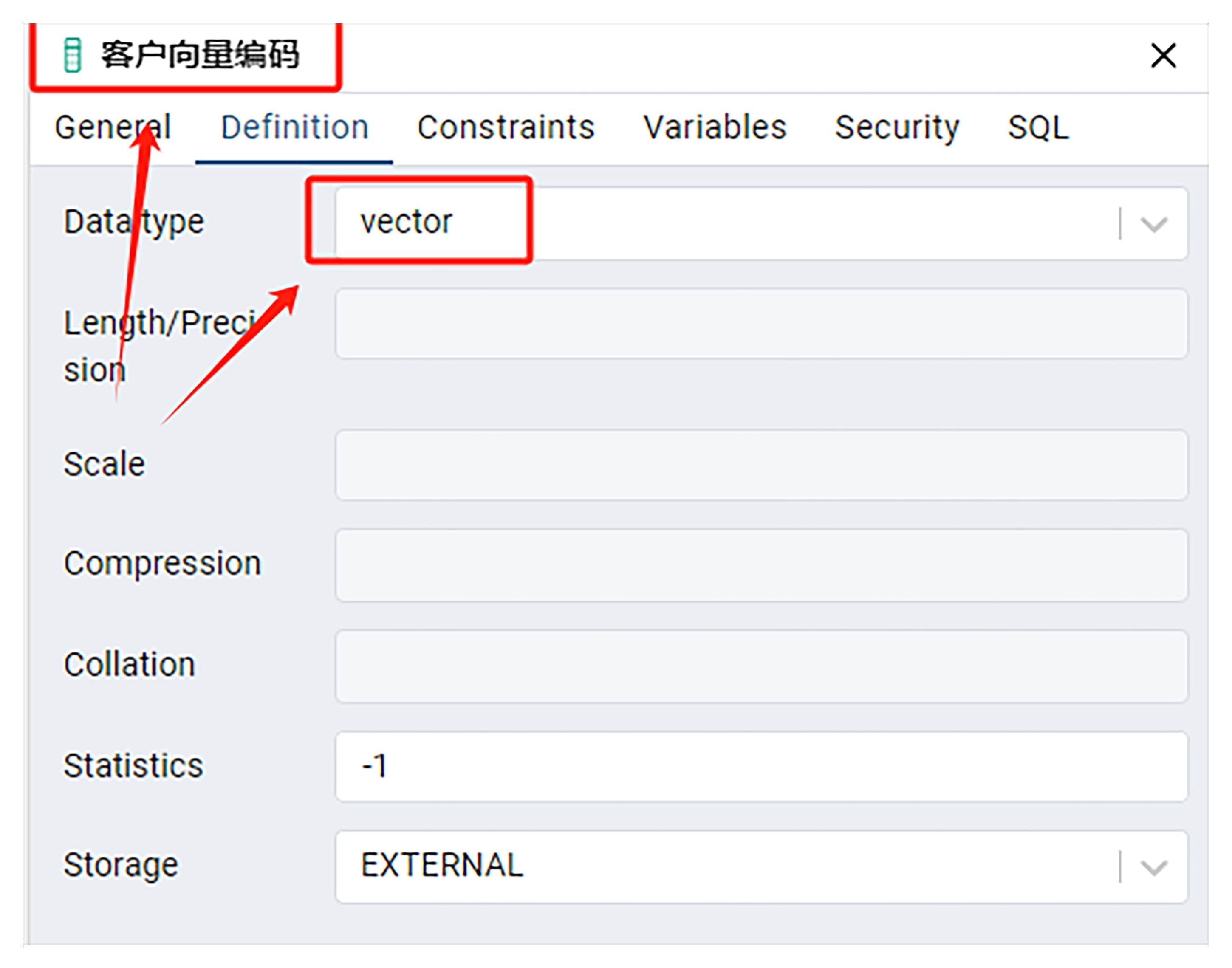
我们使用 pgadmin,打开销售入账记录表。这时我们应该看到已经成功添加了客户向量编码和客户向量编码模型这两列。其中客户向量编码的数据类型就是 vector 类型(pgadmin和vector你同样可以回顾第16节课)。
 }{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"
对知识批量编码并存进数据库
我们在 api.py 文件尾部加入以下代码。
def 对知识批量进行向量编码(request):
未编码的知识list = 销售入账记录.objects.filter(客户向量编码__isnull=True)
for current in 未编码的知识list:
current.客户向量编码= 调用向量编码服务(current.客户)
current.save()
result = {'code':200}
return JsonResponse(result)
这段代码也很好理解,首先获取尚未编码的知识列表(对应代码第2行)。然后遍历这个列表(对应代码第3行)。接着知识进行向量编码(代码第4行)。最后将向量保存进数据库(代码第5行)。
然后我们在 home/urls.py 文件尾部加入以下代码。
接着我们在postman调用http://127.0.0.1:8902/api/knowledge-embedding-batch即可批量编码并将其保存进数据库。
除此之外,我们还可以在数据入库的时候就调用以上函数进行向量编码。由于目前实战案例1还没有数据新增时的代码,因此我们跳过这一块。同学们可以在自己的MIS系统里面自行添加这一块代码。
对查询参数进行向量编码
对查询参数进行向量编码的代码和对知识进行向量编码的代码类似,因为过程是一样的,都是调用向量编码服务输入字符串返回向量编码,只不过输入字符串从知识变成了查询参数而已。
我们打开 search.py 文件,找到查询函数,然后添加以下第8行代码。
from .models import 销售入账记录
from .api import 调用向量编码服务
def 查询(查询参数):
if '模块' in 查询参数:
if 查询参数['模块'] == 1: #'销售对账'
if '客户名称' in 查询参数:
客户 = 查询参数['客户名称'].strip()
精确搜索结果 = 销售入账记录.objects.filter(客户=客户).values('客户', '入账日期', '入账金额', '已到账款项', '剩余到账款项')
if 精确搜索结果 is not None and len(精确搜索结果) > 0:
return 精确搜索结果
else:
查询字符串向量编码 = 调用向量编码服务(客户)
return 模糊搜索结果
这里要注意的是,我们并没有对用户提问进行向量编码,而是对用户提问解析之后的查询参数里面的客户名称进行向量编码。为什么这么做呢?
因为无论是精确检索还是模糊检索,实际上都是基于查询参数进行的,而不是基于最原始的提问进行的。
现在我们获得了查询参数的向量编码,我们通过这个向量编码,就可以根据相似度检索出最相似的数据了。
根据查询参数的向量编码按相似度进行检索
接下来,我们继续往 search.py 文件的查询函数添加代码。
from .models import 销售入账记录
from .api import 调用向量编码服务
def 查询(查询参数):
if '模块' in 查询参数:
if 查询参数['模块'] == 1: #'销售对账'
if '客户名称' in 查询参数:
客户 = 查询参数['客户名称'].strip()
精确搜索结果 = 销售入账记录.objects.filter(客户=客户).values('客户', '入账日期', '入账金额', '已到账款项', '剩余到账款项')
if 精确搜索结果 is not None and len(精确搜索结果) > 0:
return 精确搜索结果
else:
查询字符串向量编码 = 调用向量编码服务(客户)
模糊搜索结果RawQuerySet = 销售入账记录.objects.raw('SELECT *, 1 - (客户向量编码 <=> %s) AS 余弦相似度,客户 FROM public."home_销售入账记录" order by 余弦相似度 desc;',[str(查询字符串向量编码),])
模糊搜索结果 = []
for item in 模糊搜索结果RawQuerySet:
模糊搜索结果.append({
'客户': item.客户,
'入账日期': str(item.入账日期),
'入账金额': item.入账金额,
'已到账款项': item.已到账款项,
'剩余到账款项': item.剩余到账款项
})
return 模糊搜索结果
其中第13到14行是我们新增的代码,就是相似度检索代码。我们可以看到,我们用到了第17节课所讲的余弦距离来计算相似度。
现在我们找到了与查询参数最相似的客户了,那么就可以将检索出来的结果整合进大模型了。
这一块我们甚至不需要修改任何代码,是不是觉得有点吃惊?
仔细想想,其实很合理,因为模糊检索知识与精确检索知识相比,我们只是增强了检索知识的部分,至于将检索出来的结果喂给大模型这块,其实是没有做任何改变的。
除此之外,细心的同学们还会发现,我们修改了很多代码文件,就是没有修改 rag.py 文件。粗看一下,好像也有些不合理,但是仔细想想同样也是合理的。因为模糊检索知识与精确检索知识相比,我们只是增强了检索知识的部分,至于整个RAG流程,其实是没有做任何改变的。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了五件事情,还了解了一个本质。
第一件事情是搭建向量编码服务。因为加载向量模型很耗时间和内存资源,将这部分代码单独拆分出一个服务更容易扩展和维护。
第二件事情是添加向量编码列和嵌入模型列。我们将在ORM层面添加向量编码列和嵌入模型列。如果你的系统在ORM层面不支持,则可以使用第16节课的方法通过UI添加。
第三件事情是对知识批量编码并将结果存进数据库。我们首先获取尚未编码的知识,然后遍历进行编码,并将结果存进数据库。
第四件事情是对查询参数进行向量编码。对查询参数进行向量编码的代码和对知识进行向量编码的代码类似,因为过程是一样的。
第五件事情是根据查询参数的向量编码按相似度进行检索。我们修改了查询函数。
我们可以看到,模糊检索知识与精确检索知识相比,本质上只是增强了检索知识的部分。至于整个RAG流程,其实是没有做任何改变的。
既然整个RAG流程其实是没有做任何改变的,这里也建议同学们回顾和巩固一下整个RAG流程。下节课,我们将基于类似的概念和代码实现实战案例3:工单辅助系统,敬请期待。
思考题
今天这节课里,我们并没有将查询参数的向量编码保存进数据库。那么是否有必要将查询参数的向量编码保存进数据库呢?如果有必要,这么做的意义是什么呢?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- kevin 👍(0) 💬(1)
我们并没有将查询参数的向量编码保存进数据库。那么是否有必要将查询参数的向量编码保存进数据库呢?如果有必要,这么做的意义是什么呢? 如果要把查询参数的向量编码保存下来,是否可以帮助下次的查询更精确匹配。下次的搜索可能和本次搜索语义很相近,就容易配备了。
2024-11-10 - 悟远 👍(0) 💬(1)
OSError: We couldn't connect to 'https://huggingface.co' to load this file 模型下载不下来,一般怎么配置代理或镜像?
2024-11-01 - kevin 👍(0) 💬(3)
我运行api/knowledge-embedding-batch建立客户向量编码时总是报如下错误 Max retries exceeded with url: /api/embedding/encode (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000001FE31D3CC10>: Failed to establish a new connection: [WinError 10061] 由于目标计算机积极拒绝,无法连接。'))
2024-10-23 - Geek_0a887e 👍(0) 💬(3)
老师有个疑问:按照前一章节的内容话,1 - (字段<=>向量) 得到的是余弦距离,距离越小越相似,为什么还需要desc,不是应该asc吗,
2024-10-15 - 公号-技术夜未眠 👍(0) 💬(1)
老师好,想请教一个问题,目前正在做一个知识问答智能AI助手,虽然这个助手是长在自己的产品系统中,但是现在要集成客户环境内部署的各类其它异构系统,和系统数据,包括各类非结构化与结构化数据,用于满足企业知识问答需求。 请问该需求有实现的可能性吗?请教具体的实现思路以及所需要重要注意的事项,谢谢
2024-10-15