16 概念详解:使用向量数据库管理向量值
你好,我是叶伟民。
上一节课我们讲解了如何通过嵌入模型来获取知识的向量编码表示。
但是你可能有这样的疑惑——我们每次查询知识的时候,都必须调用嵌入模型来获取所有知识的向量编码表示吗?
显然是不合理的。一般来说,我们会在获取了向量编码表示之后,将它保存起来。这节课,我们就来解决这个问题。
保存向量编码的工具选择
能够保存向量编码的工具有很多。这里我仅列出我研究过的:
- Faiss
- Pinecone
- Chroma
- Milvus
- LanceDB
- PostgreSQL
研究过以上这么多工具之后,我依次在项目中应用过这三个向量编码保存工具。
- FAISS
- Milvus
- PostgreSQL
在掉过N次坑之后,最终我选择安装了pgvector插件之后的PostgreSQL,到今天(2024/10/09)为止,已经在实际项目中稳定运行12个月了,所以现在我才敢推荐给大家使用。为了和默认的Postgres区分开来,在这门课的后续内容中,我将把安装了pgvector插件之后的PostgreSQL 简称为pgvector。
PostgreSQL和pgvector
PostgreSQL 是与MySQL齐名的开源关系数据库。PostgreSQL 默认是不支持存储向量的。只有安装了pgvector插件之后,PostgreSQL 才能支持存储向量,才能变成向量数据库。
安装与运行
我们先从最简单的安装和运行开始今天的探索之旅。
安装pgvector
安装pgvector的方式有好几种,最快的方式是使用docker安装。
首先我们需要安装docker。安装完docker之后,我们打开命令行工具,运行以下命令:
这条命令会从Docker Hub下载pgvector的最新版本(对应PostgreSQL 16版本)的镜像。如果你需要其他版本的PostgreSQL,可以通过更改镜像标签来拉取相应的版本。
运行pgvector
拉取完镜像后,我们就可以运行pgvector的容器了。在命令行工具中运行以下命令:
docker run --name pgvector --restart=always -e POSTGRES_USER=pgvector -e POSTGRES_PASSWORD=pass@word1234567 -v D:\dockermount\pgvector\pgdata:/var/lib/postgresql/data -p 5432:5432 -d pgvector/pgvector:pg16
你可能要根据你的实际情况修改以上命令中的具体参数值:
- –name:容器的名称。
- -e POSTGRES_USER:PostgreSQL的用户名,以后登录数据库时要使用它。
- -e POSTGRES_PASSWORD:PostgreSQL的密码,以后登录数据库时要使用它。
- -v:冒号前面的值是Windows宿主机里你想要保存数据库数据的目录,冒号后面的值是容器的数据目录。以上示例中的值是将容器的数据目录映射到了你的Windows宿主机的
D:\dockermount\pgvector\pgdata目录。一般来说,你需要将冒号前面的值修改为Windows宿主机你想要保存数据库数据的目录。 - -p:PostgreSQL的端口。如果你的Windows宿主机没有安装PostgreSQL,则不需要修改这个值。否则你需要将以上示例中冒号前面的值修改一下,例如改成
-p 54321:5432。
安装pgadmin
把pgvector运行起来之后,我们还需要一个数据库管理工具来使用它,这里我们使用pgadmin。pgadmin是一个管理PostgreSQL的图形化管理工具。因为是图形化管理工具,使用起来自然比PostgreSQL自带的pgsql命令行工具方便多了。
前面提到我有从FAISS换成Milvus和PostgreSQL,其中一个很重要的原因就是FAISS没有提供图形化管理工具。我不得不在Jupyter里面使用LangChain来操作FAISS、Chroma的数据,操作起来比较繁琐。
现在我们来安装pgadmin。我们打开浏览器访问https://www.pgadmin.org/download/。下载Windows版本,然后按默认设置安装。
运行pgadmin
我们打开开始菜单,输入 pgadmin,将会看到如下界面。
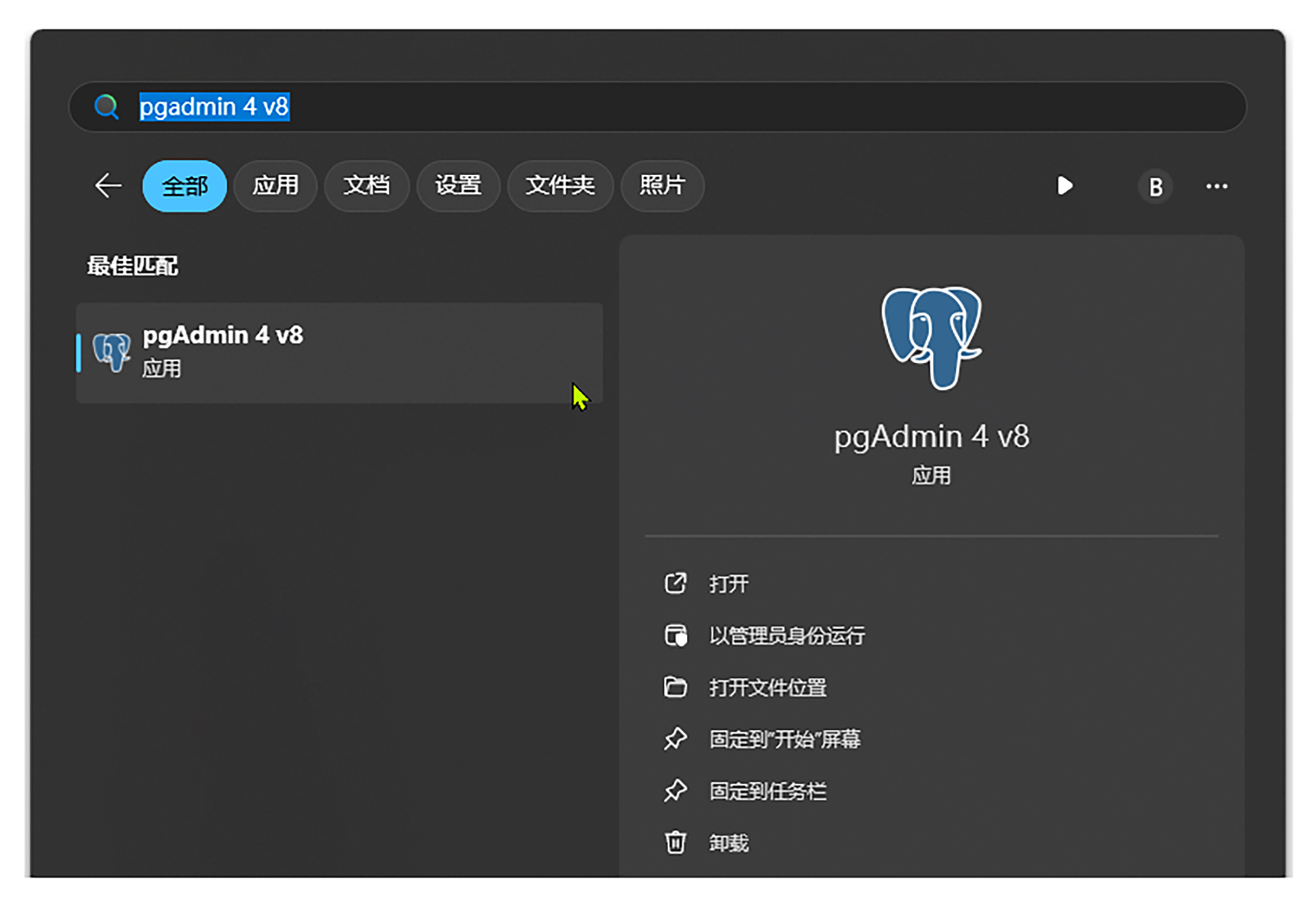
接着点击蓝色的大象图标,将会打开pgadmin。之后我们按下图所示,选中左侧的Server,鼠标右键点Register,再点Server。
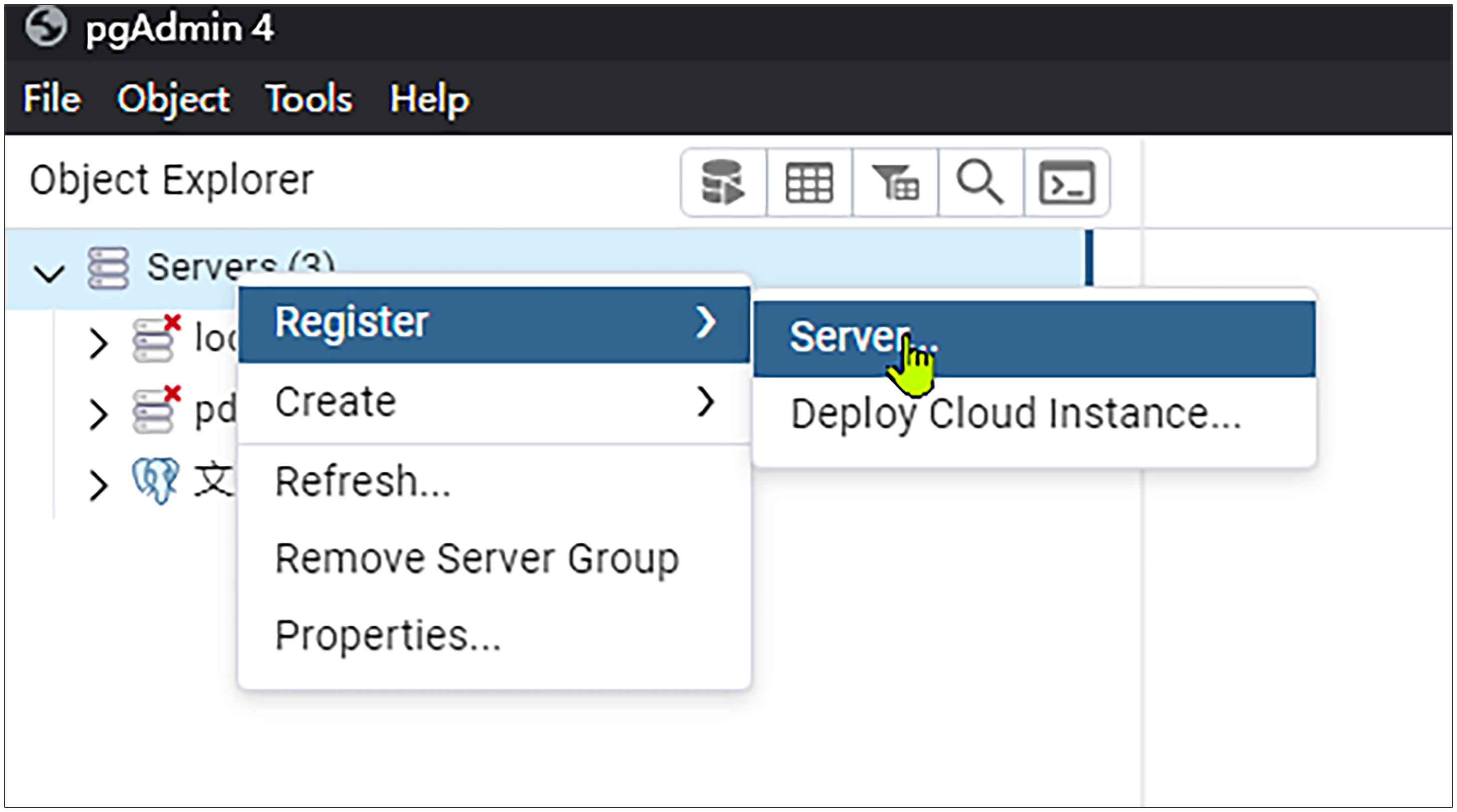
这时将会弹出如下界面。如果前面你没有修改PostgreSQL的端口,可以直接按照以下界面填写。如果前面你修改了PostgreSQL的端口,则需要修改Port里面的值。
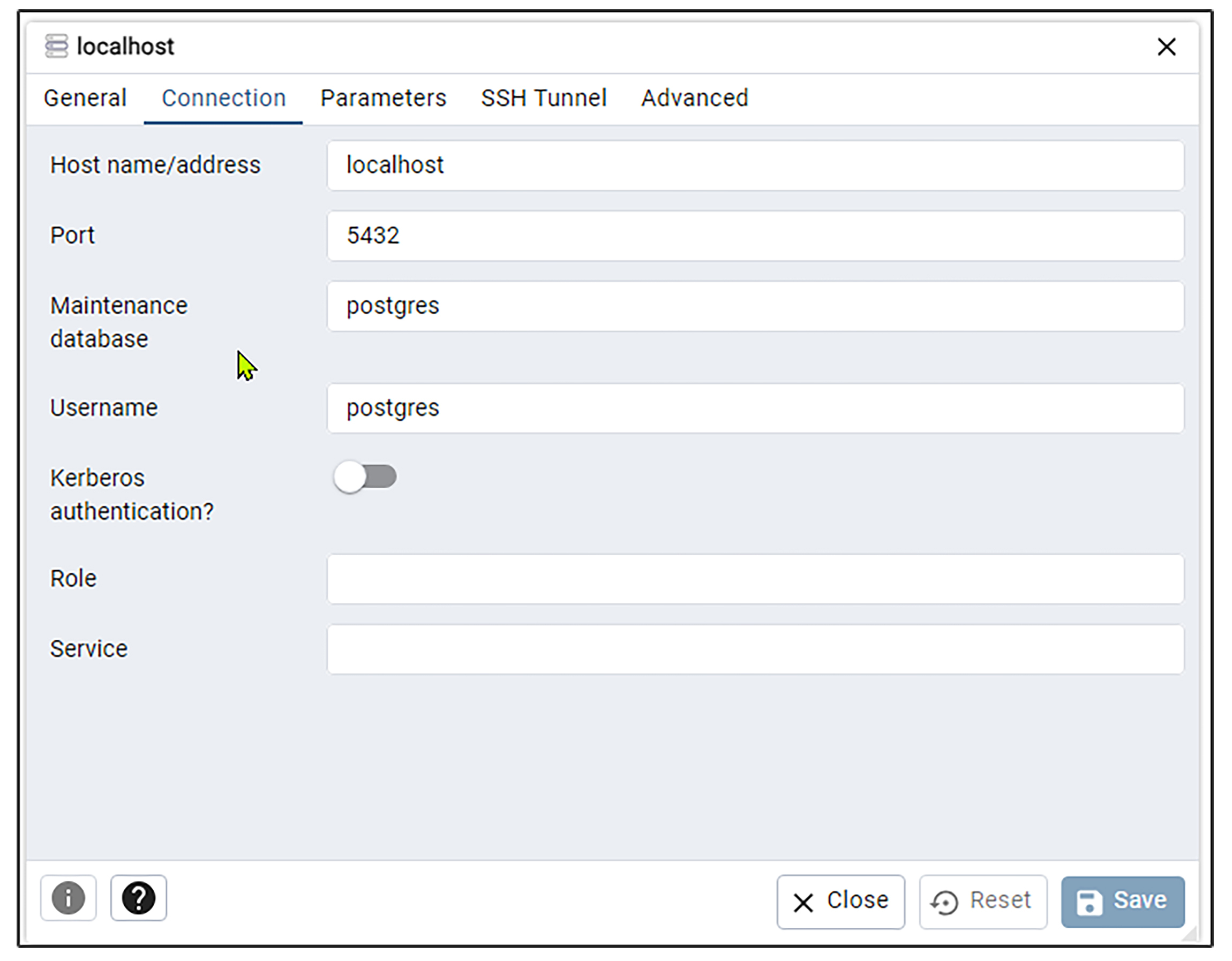
填写好以后,我们点Save按钮。如果一切正常,此时pgadmin的左侧应该会出现以下界面。
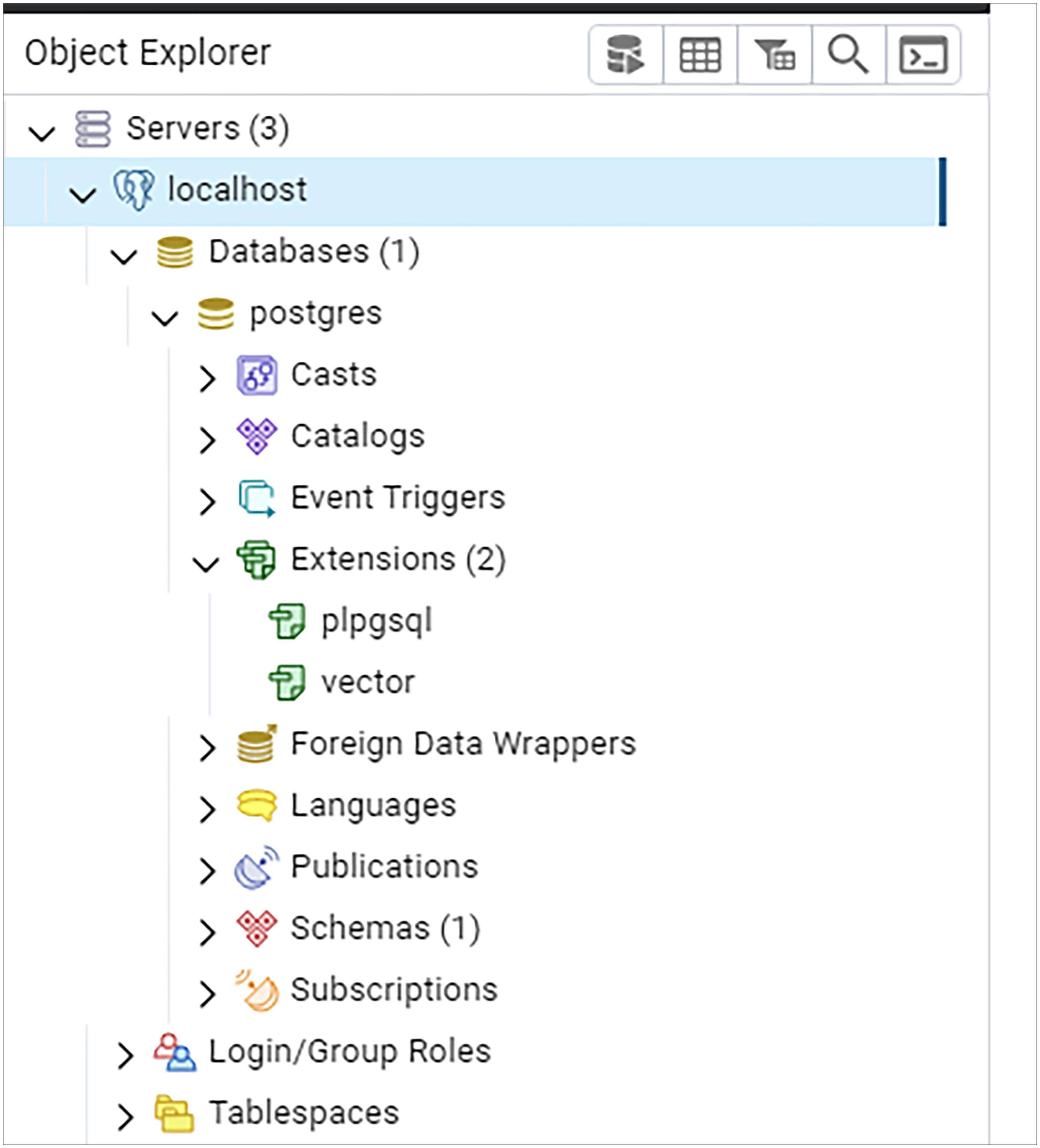
现在我们完成了pgadmin的安装,接下来还需要安装pgvector扩展。
给数据库安装pgvector扩展
然后我们选中刚才添加的服务器,点database,再点postgres,再点Extensions,鼠标右键create,然后点Extension菜单。
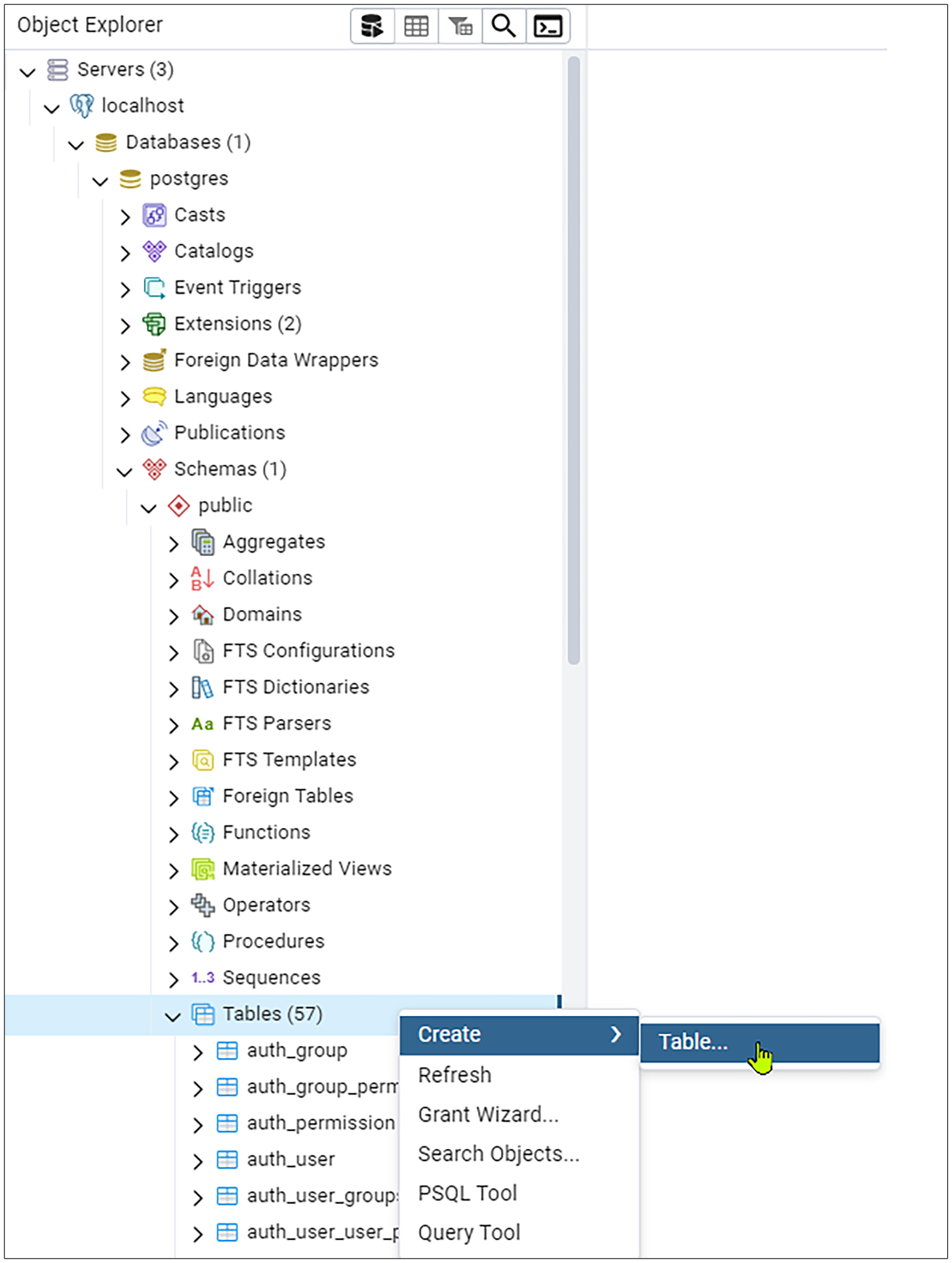
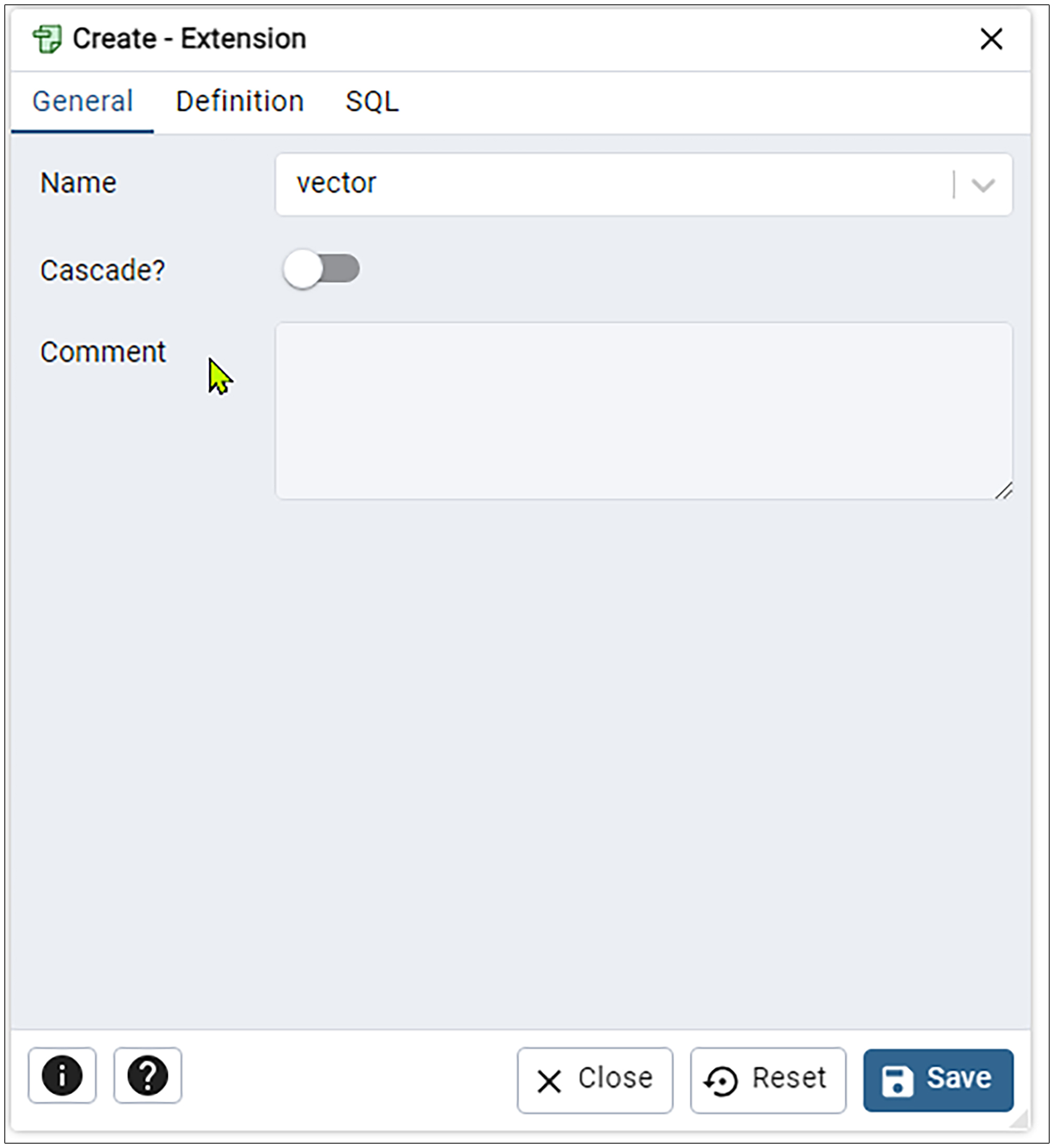
然后在弹出的窗口里面的Name下拉列表中选择vector,然后再点击Save按钮。
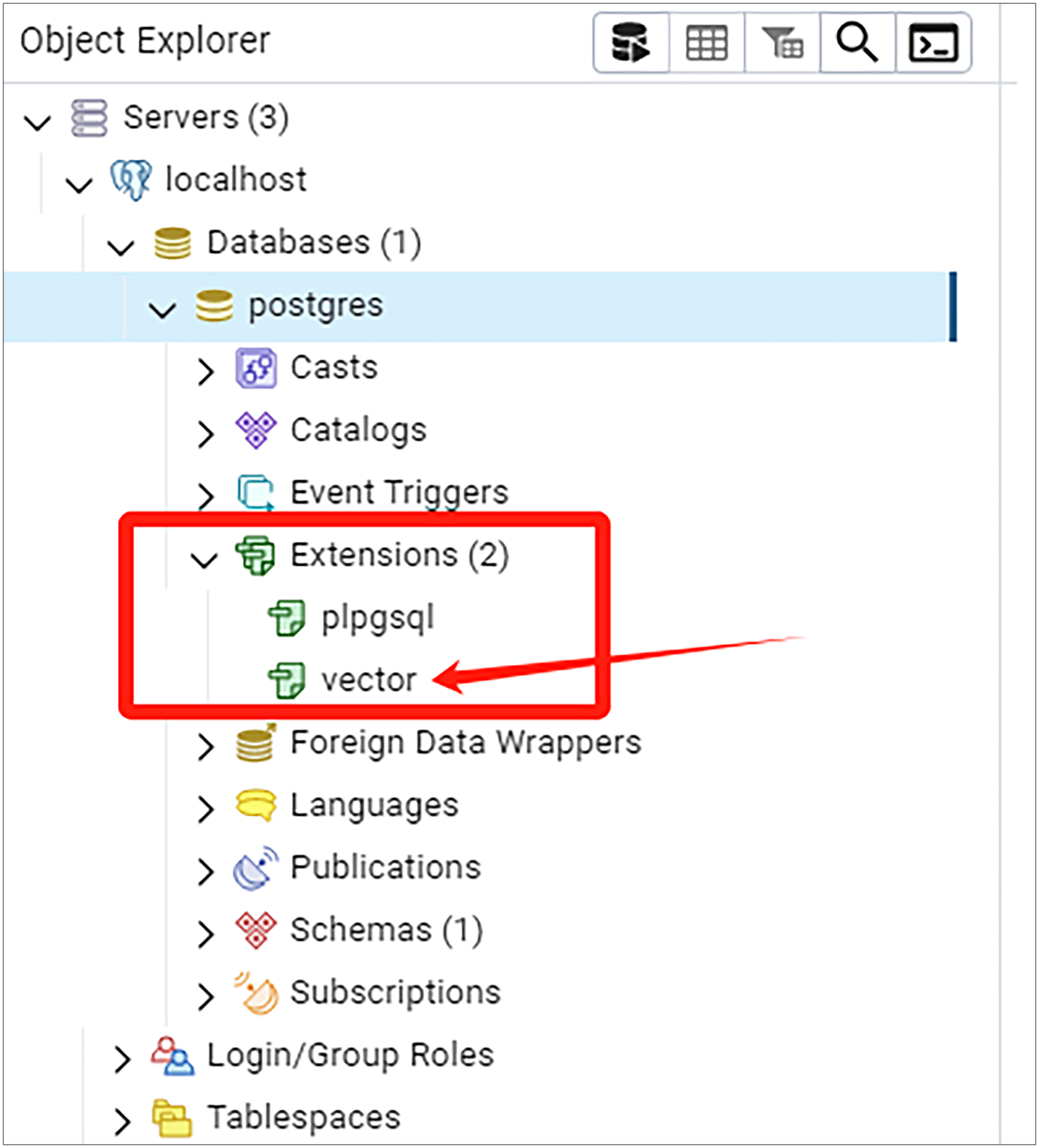
如果一切正常,此时pgadmin的左侧应该会出现以下界面。Extensions节点下面应该显示有vector节点。
创建表
现在我们可以创建表来存储向量编码数据了。
我们还是选择刚才的database,依次点击postgres-Schemas-public-Tables,鼠标右键Create,然后点Table菜单,就可以开始创建表了。
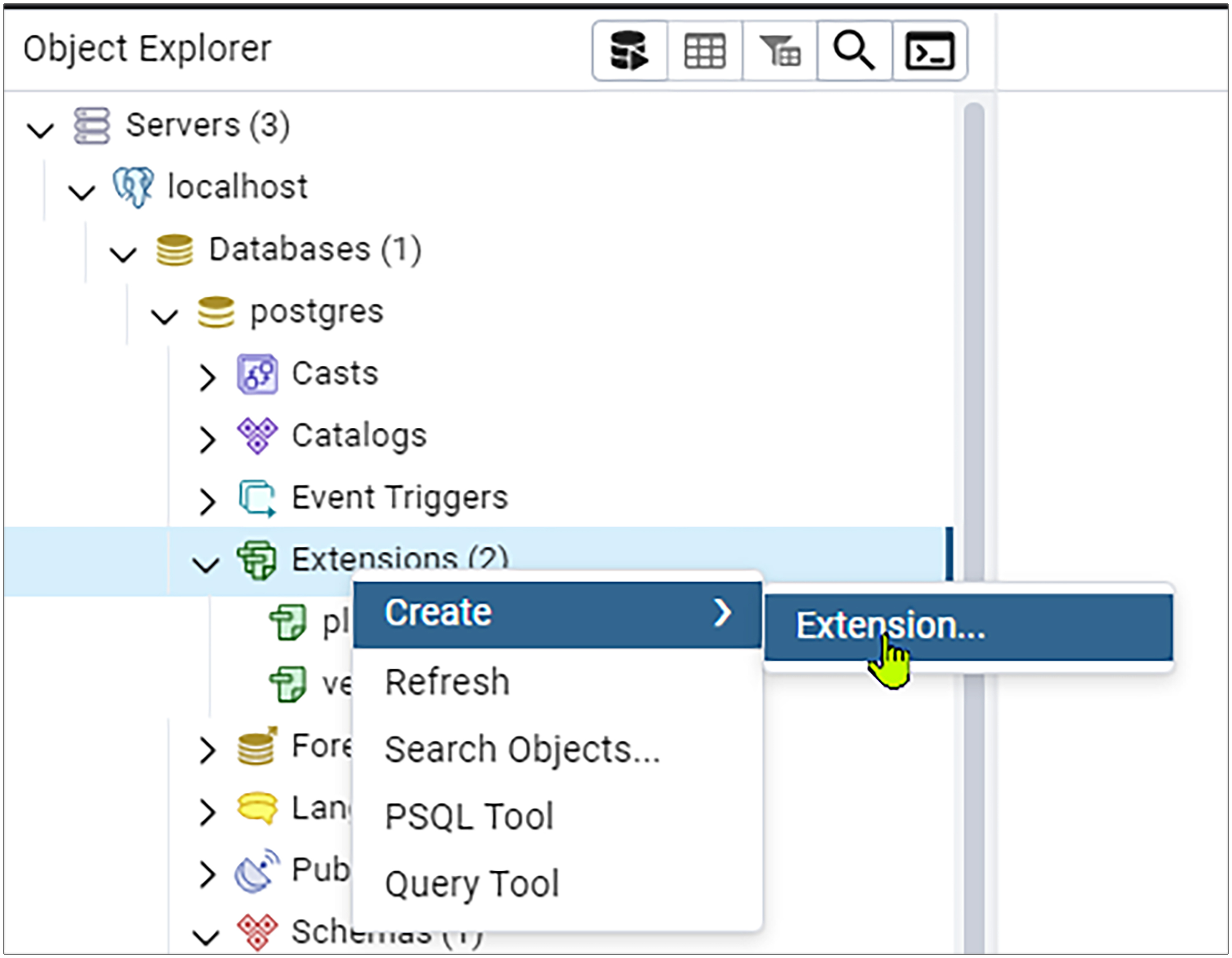
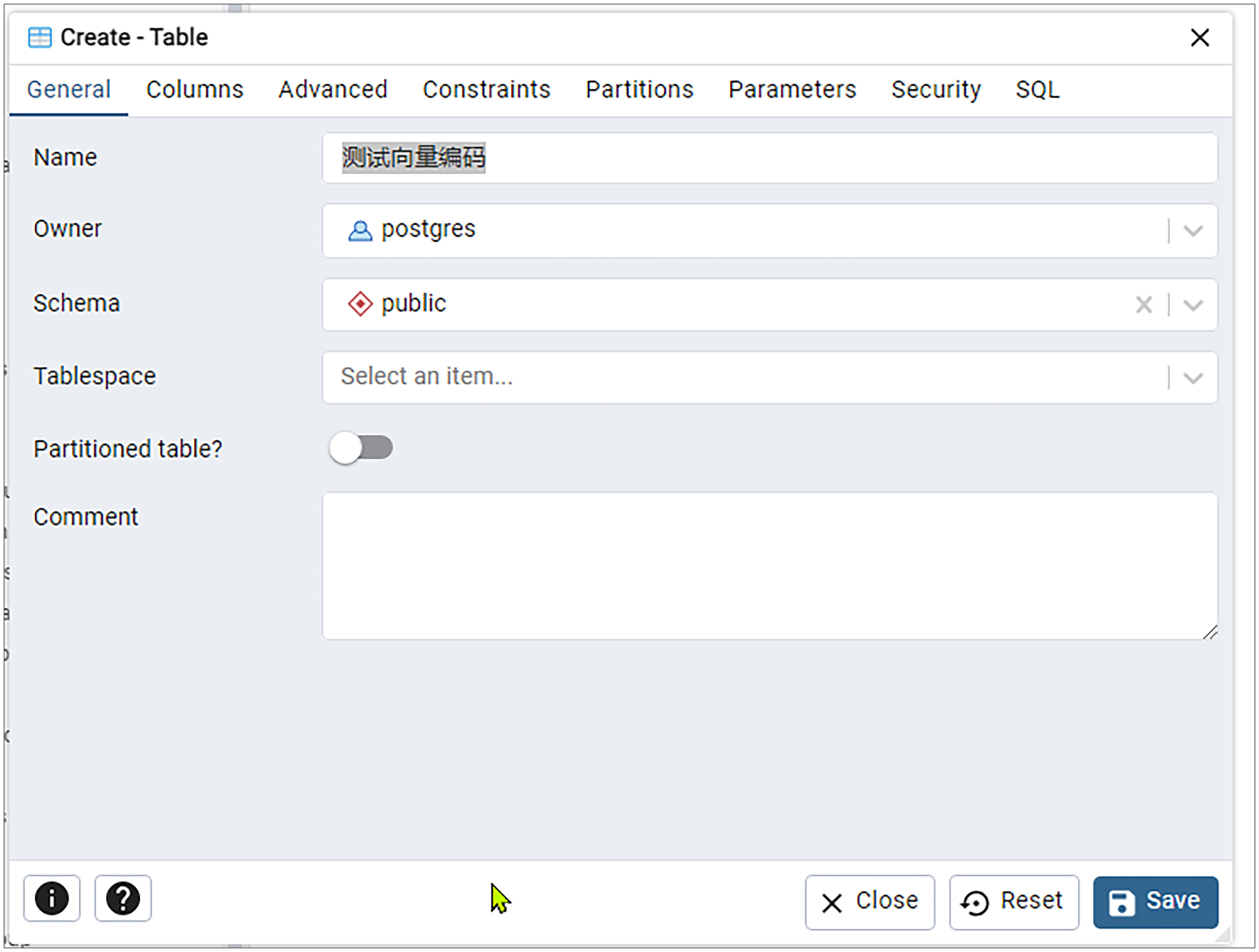
接下来,我们在General这个Tab里面的Name填入表名,这里就叫测试向量编码。这里的表名你可以改为任何符合你业务场景的表名。
创建输入文本列
然后切换到Columns这个Tab,点击最右边的+图标。
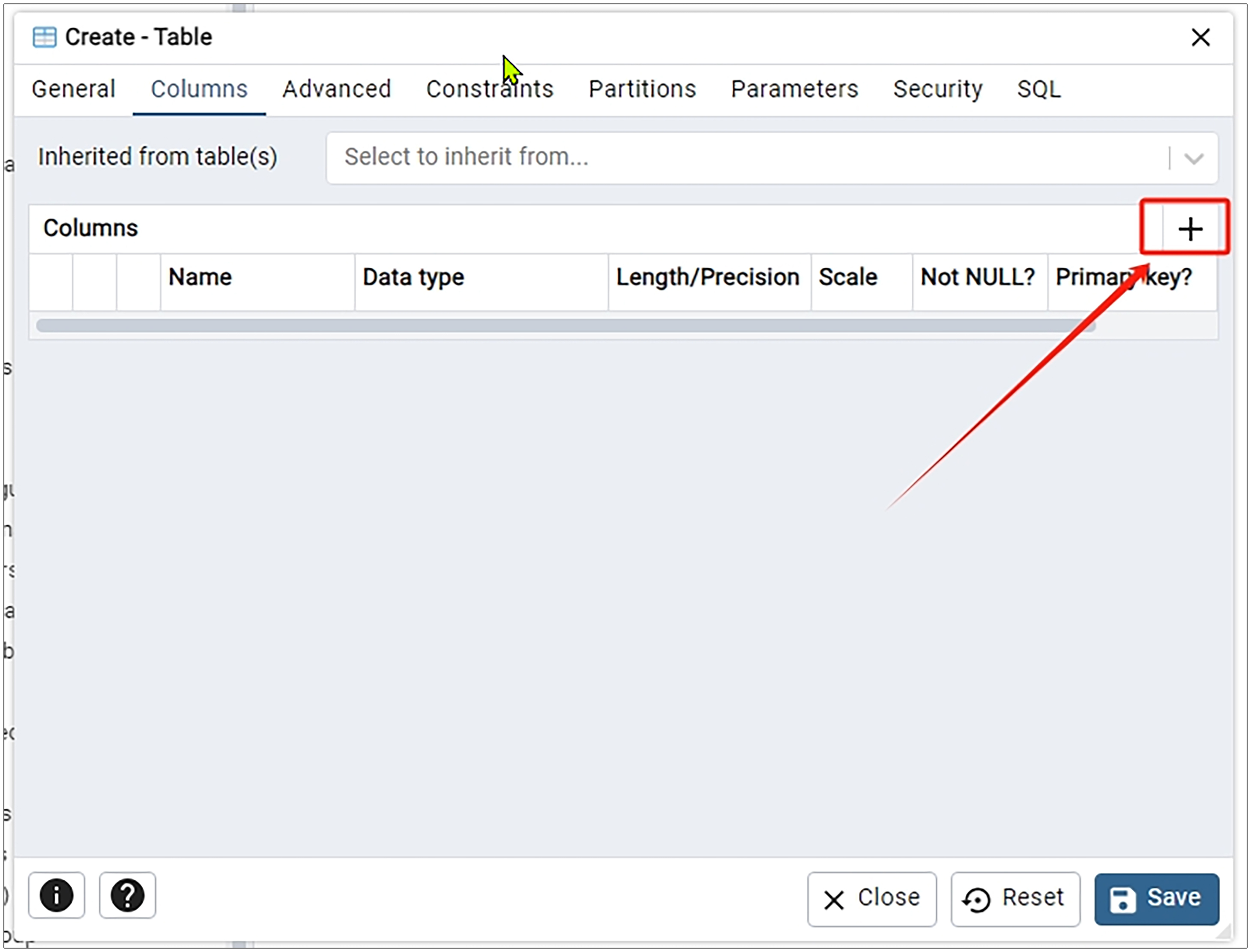
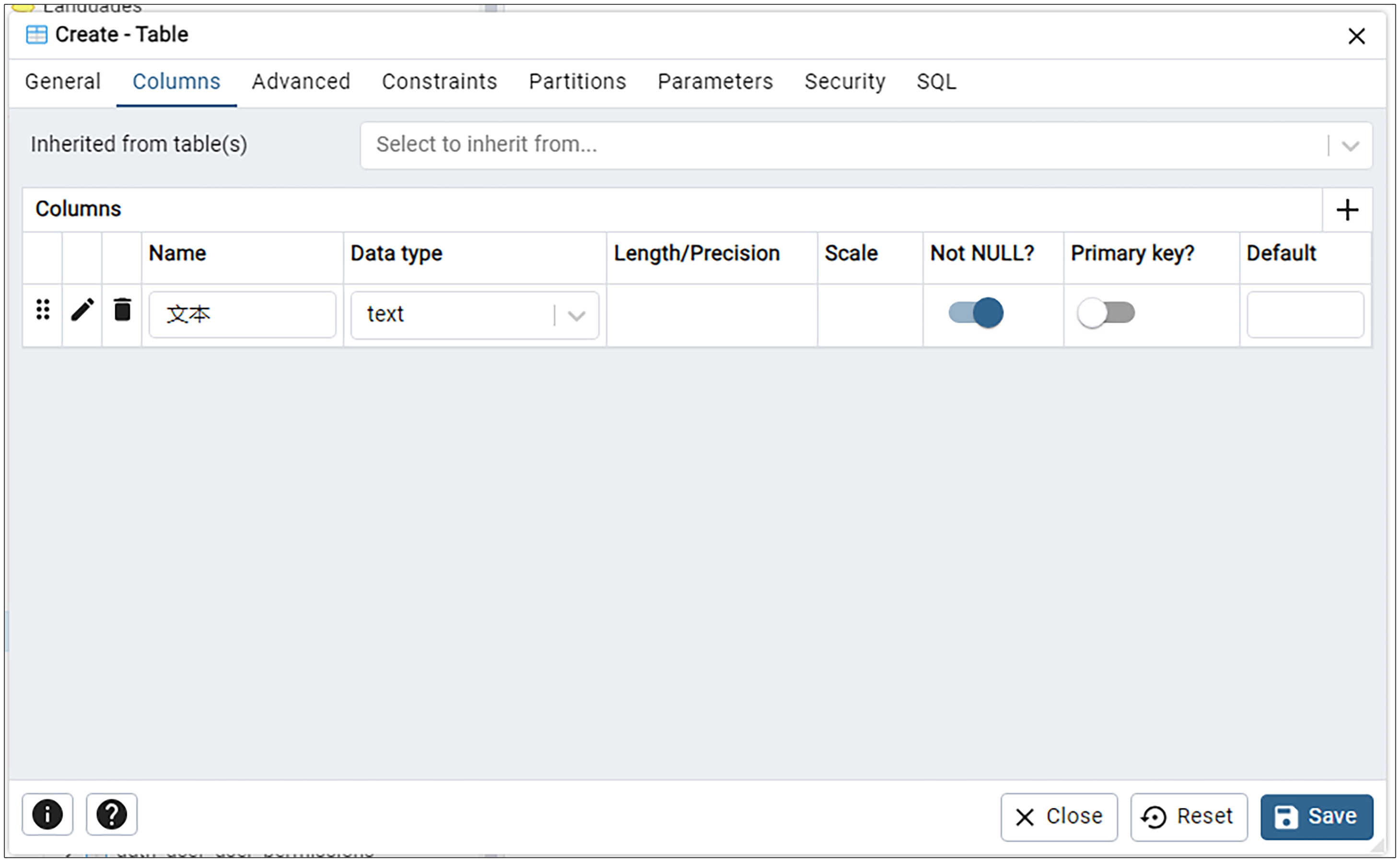
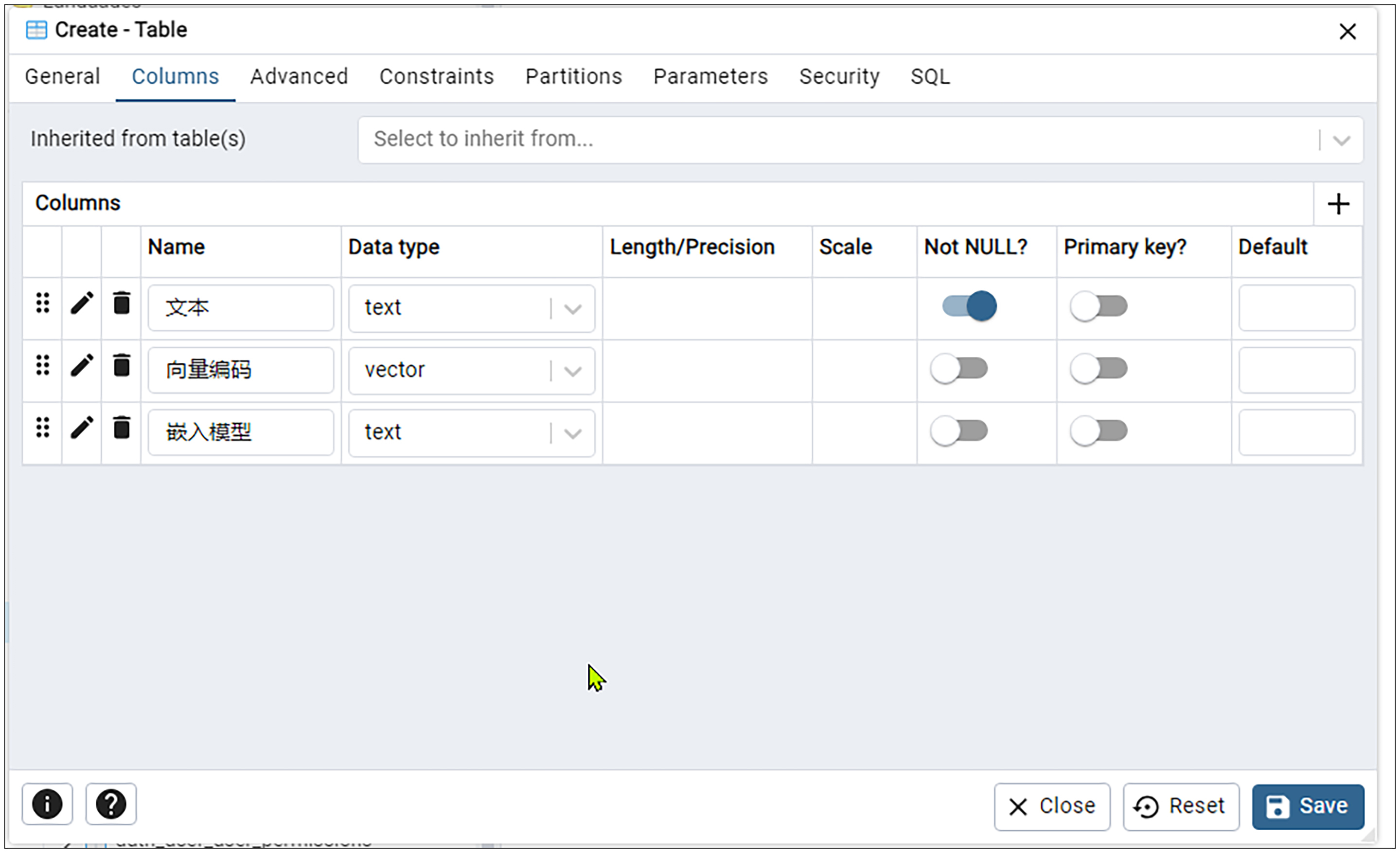
之后我们在 Name 里面输入列名文本,在 Data type 输入 text,并将 “Not NULL?” 这一项设置为开启。这里的列名你可以改为任何符合你业务场景的列名,后面添加其他列的时候也一样如此,我就不重复提示了。
创建向量编码列
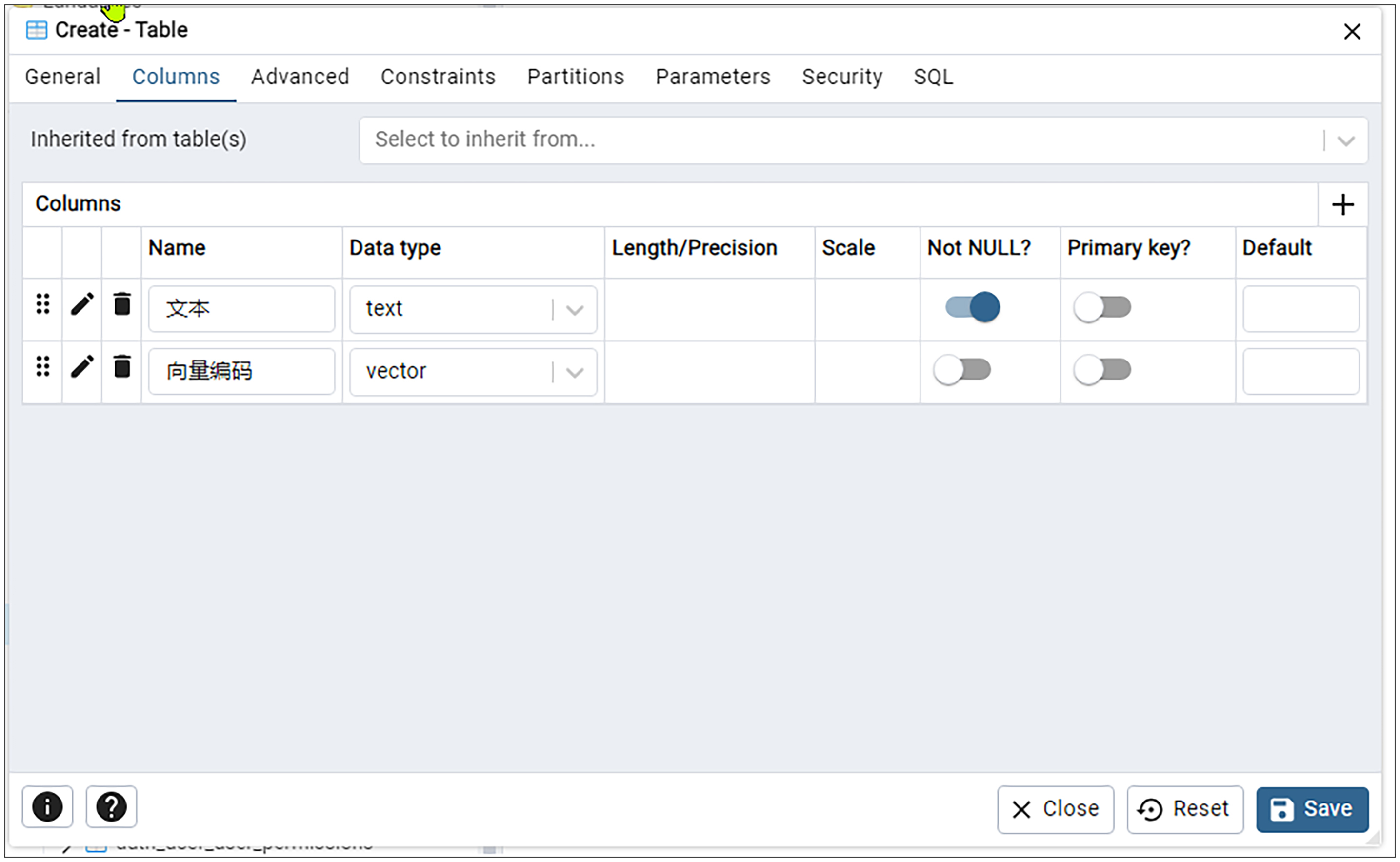
然后我们继续点击刚才的最右边的+图标。
在新一列(第二列)的Name输入向量编码,在Data type输入vector。
创建嵌入模型列
不知道你是否记得第10节课里我们提到过,不同嵌入模型、甚至同一嵌入模型的不同版本计算出的向量编码都是不通用的。所以这里我们需要添加一列嵌入模型列。这样我们在增删改查数据的时候,就可以通过这一列获知向量值来自于哪一个嵌入模型的哪一个版本。
我们还是继续点击刚才的最右边的+图标。在新一列(第三列)的Name输入嵌入模型,然后在Data type输入text,并点击Save按钮保存。
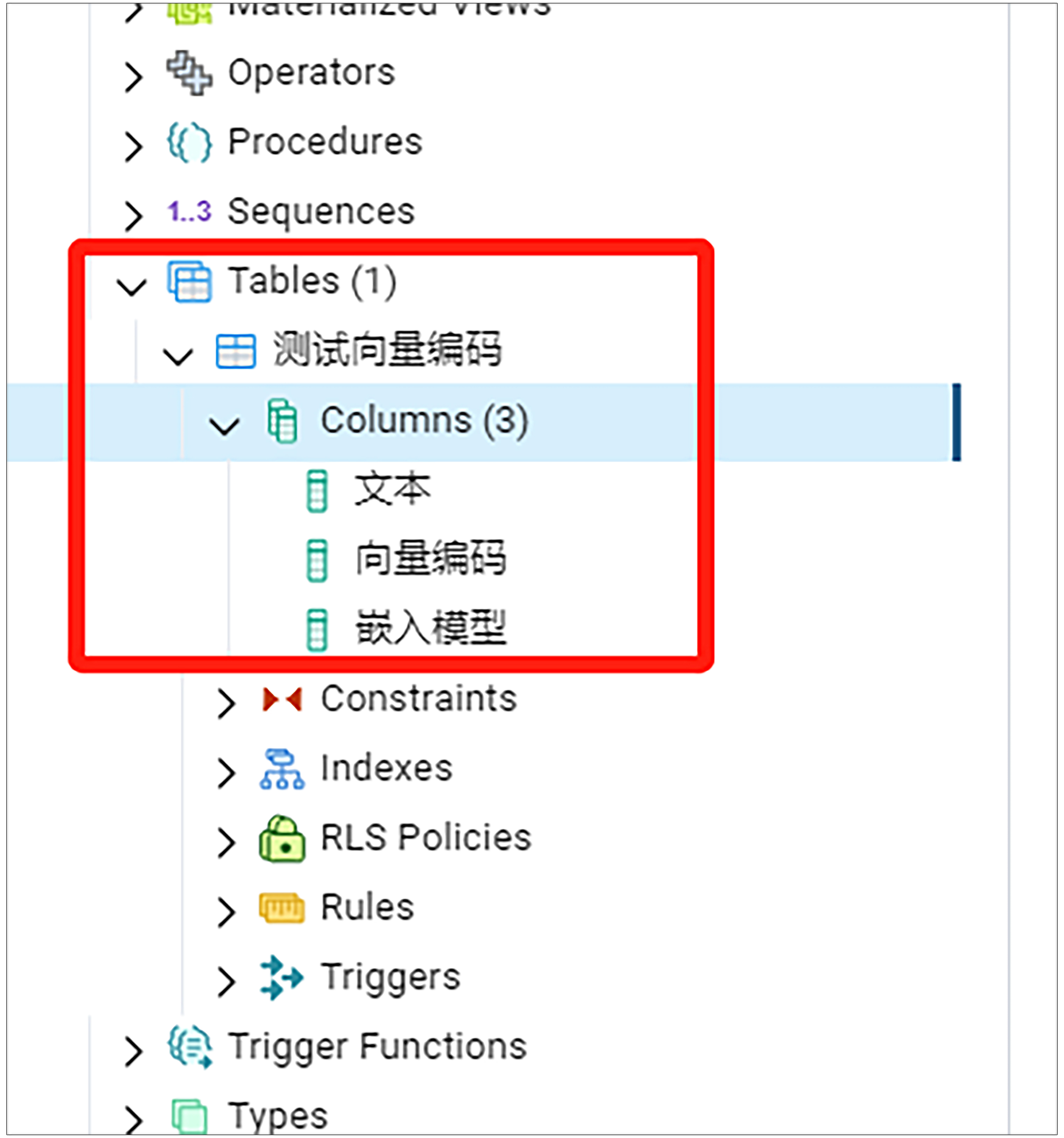
如果一切正常,以上窗口关闭之后,我们应该在pgadmin左侧的Tables看到刚才新建的表。展开这个表的Columns节点之后,应该可以看到刚才新建的三列内容。
增删改查数据
接下来,我们来搞定各类数据操作。
虽然在pgadmin里,我们确实可以通过图形化的方法来增删改查数据。但是这里我们将使用SQL语句的方法,因为这样一旦测试成功,我们可以将这段SQL复制到Python代码中使用。 那么如何编写这些SQL语句呢?我们固然可以按照PostgreSQL的文档,一个一个字符敲出来,但是这样的方法太慢了,而且也容易出错,所以我们会使用图形化界面的方式来生成这些SQL语句。
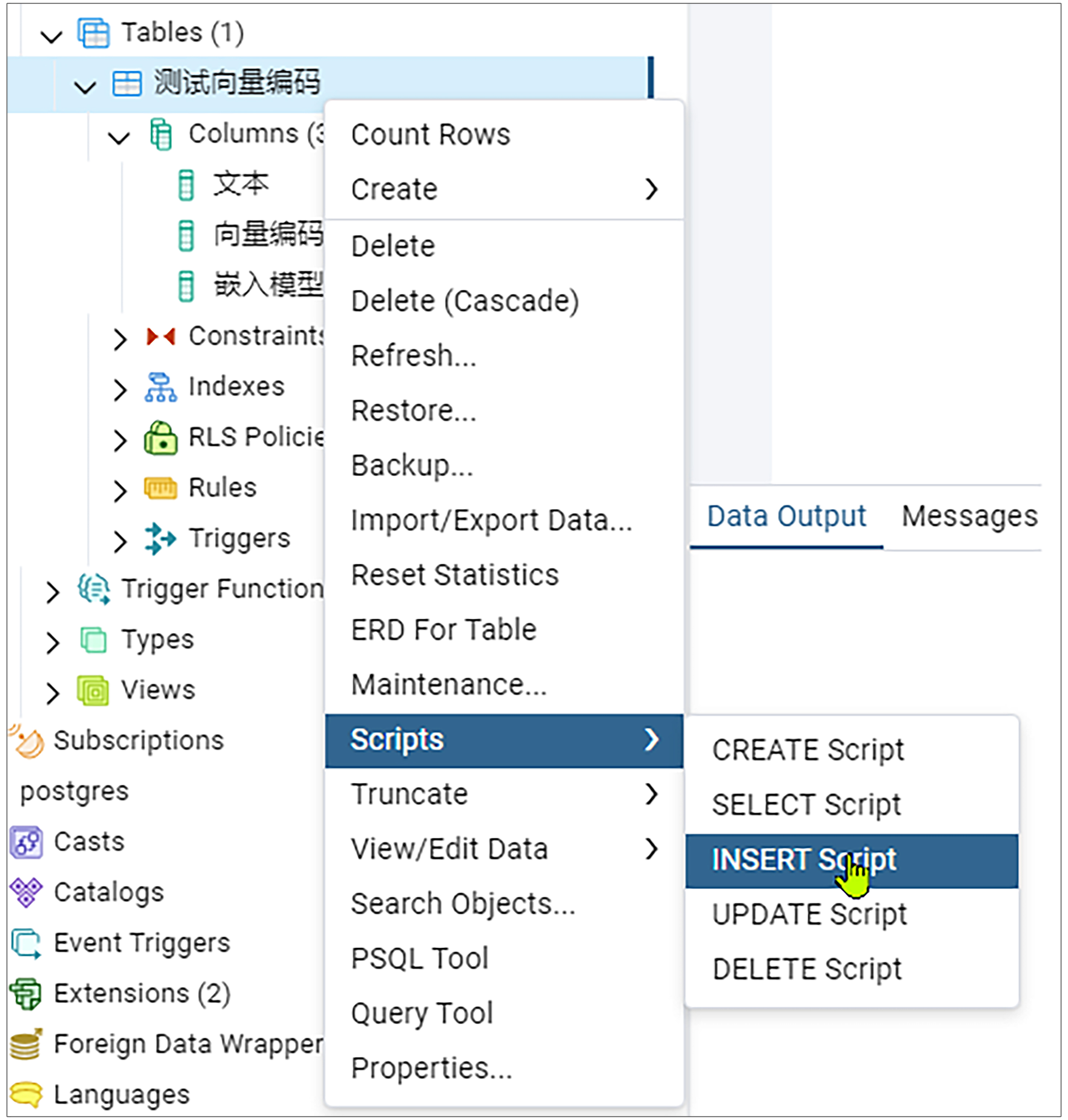
现在我们选中刚才新建的表,鼠标右键点击Scripts菜单,然后点击INSERT Script。
然后右边的主要脚本窗格将会出现后面这样的的插入数据脚本。
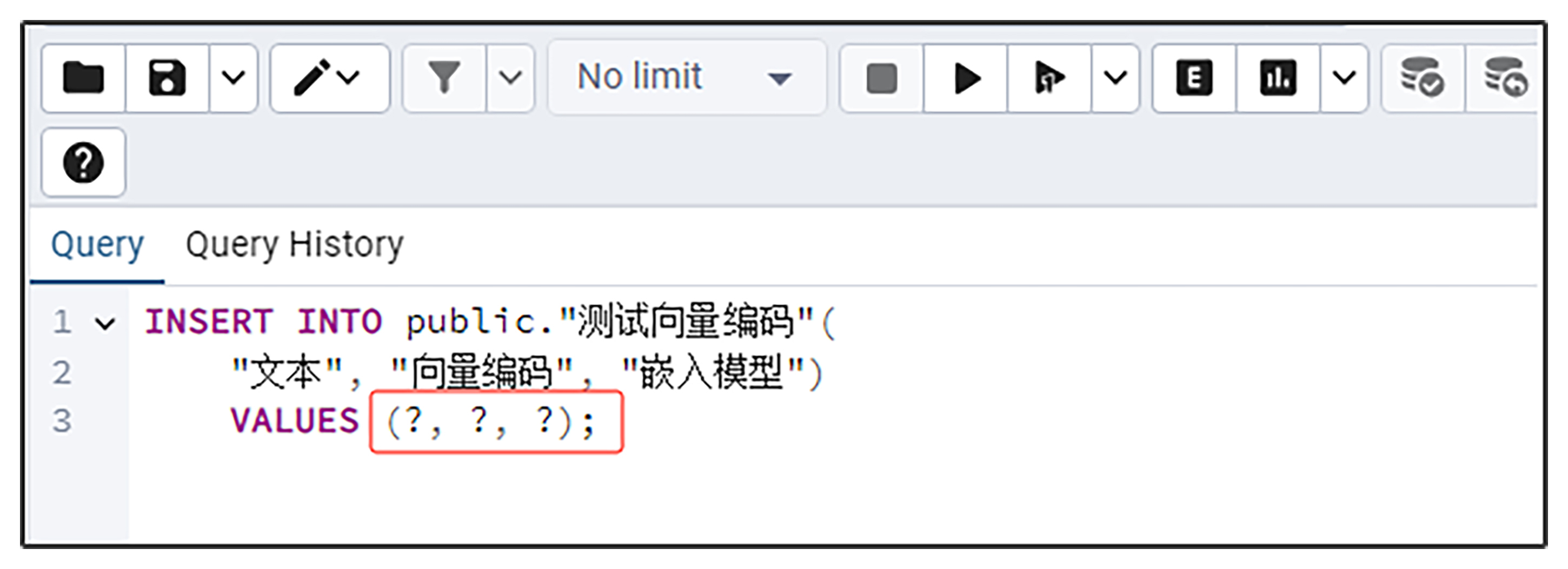
我们把里面的 “?” 部分替换成我们想要插入的实际数据即可。没错,这里跟关系数据库里,插入输入的SQL脚本完全一模一样。
修改好SQL脚本之后,我们可以按F5键或者主窗格最上面的箭头来执行SQL。
至于修改、删除、查询向量编码数据的方法与增加数据的方法类似,只不过换了一个子菜单而已:
- 修改数据的子菜单是UPDATE Script
- 删除数据的子菜单是DELETE Script
- 查询数据的子菜单是SELECT Script
我要提醒你注意的是,如果要获取某一文本的向量编码数据,我们需要在SELECT Script生成的SQL语句里面添加where查询子句。
例如查询”老婆饼“的向量编码数据的最终SQL语句是这样的:
讲到这里,同学们会发现,除了需要安装扩展、指定不同的数据类型,以及使用不同的关键字,使用pgvector来管理向量编码数据与使用关系数据库管理其他数据没有什么不同。
是的,你的发现是对的!向量数据库并没有什么神秘的。
不过进行到这里,我们仍然有个问题没能解决——虽然现在通过SELECT Script,我们可以根据指定文本查询到对应的向量编码,但是还不能根据指定文本找到最相似的文本,例如根据”老婆饼“查询出最相似的文本”菠萝包“,这就是我们下一节课要讲的内容,敬请期待。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了四件事情。
第一件,如何安装pgvector。
第二件,如何安装图形化界面工具pgadmin。
第三件,如何使用pgadmin通过图形化的方式创建表和列来保存向量编码数据。
第四件,如何使用pgadmin通过SQL查询语句的方式增删改查向量编码数据。
看到这里,同学们会发现我强调多次图形化。是的!我的口号是——能用图形化界面解决的,就不要用代码。你可能也在其他文章里看到命令行的方式,但为了降低学习门槛,让你更快上手,所以我们选择了图形化界面的方式来操作。
思考题
问题1:增删改查数据的时候,为什么不直接选择LangChain里提供的pgvector API,而是使用SQL语句完成呢?
问题2:既然换一个嵌入模型就需要全部重新计算一遍向量编码,为什么要添加嵌入模型列,直接更新所有向量编码列的值不就好了吗?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- 亚林 👍(0) 💬(0)
问题1:不想被LangChain限制住; 问题2:可能需要在不同嵌入模型之间做测试和对比。
2025-02-19 - 无处不在 👍(0) 💬(0)
问题一:虽然没用过python版的langchain,但是用过java版本的langchain4j,在langchain4j中默认定义了一个固定表结构的向量表,如果是单纯搜索词的场景够用了,但是个性化的业务场景还需要定制开发 问题二:应该是为将来的不同模型的不同维度的向量的搜索精度做准备吧
2024-10-28 - 言十年 👍(0) 💬(0)
问题一:直接用sql比较零活吧。并且不依赖组件。 问题二:加上嵌入列,多一个选择。可以a模型也可以用b模型。而且,不影响之前的向量结果。类似于接口分v1版本v2版本,平滑升级。
2024-10-14