14 模糊检索:支持模糊检索,让RAG应用如虎添翼
你好,我是叶伟民。
现在我们已经讲解过两个实战案例了,相信你对RAG的应用也更加熟悉了。但是这两个实战案例都只支持精确检索,不支持模糊检索。
以实战案例1为例,我们输入“客户广州神机妙算有限公司的款项到账了多少?”,此时系统能够根据关键词“广州神机妙算有限公司”精确检索到相关数据。
但是如果不输入公司全名,只输入“广州神机妙算的款项到账了多少?”。那么系统则无法根据“广州神机妙算”模糊检索到相关数据。
实战案例2也同样,目前我们只能查看今天、昨天、前天的IT新闻,还不能只查看AI类的新闻。其中按日期检索IT新闻属于精确检索,而按类别,比如检索AI类的新闻则属于模糊检索。
但是在现实工作中,需要支持模糊检索的场景很多。因此仅仅掌握精确检索知识的技术是不够的,还需要掌握模糊检索知识的技术。我们从这节课开始就来学习模糊检索。
为了帮你更全面地了解模糊检索知识的技术,我们这一章的实战案例选择了工单辅助系统,这个案例将会以模糊检索知识为核心。
实战案例3成果展示
我们先来看看实战案例3的成果。在案例界面呈现这个部分,我们将沿用实战案例1的代码。也就是说实战案例3的界面跟实战案例1是一样的。
然后在它的基础上,再添加三块功能。
第一块功能我们从前端是看不见的,但却是最关键的,就是支持模糊检索功能。
第二块功能是我们经常看见的,给出参考链接的功能。具体效果如下图所示。
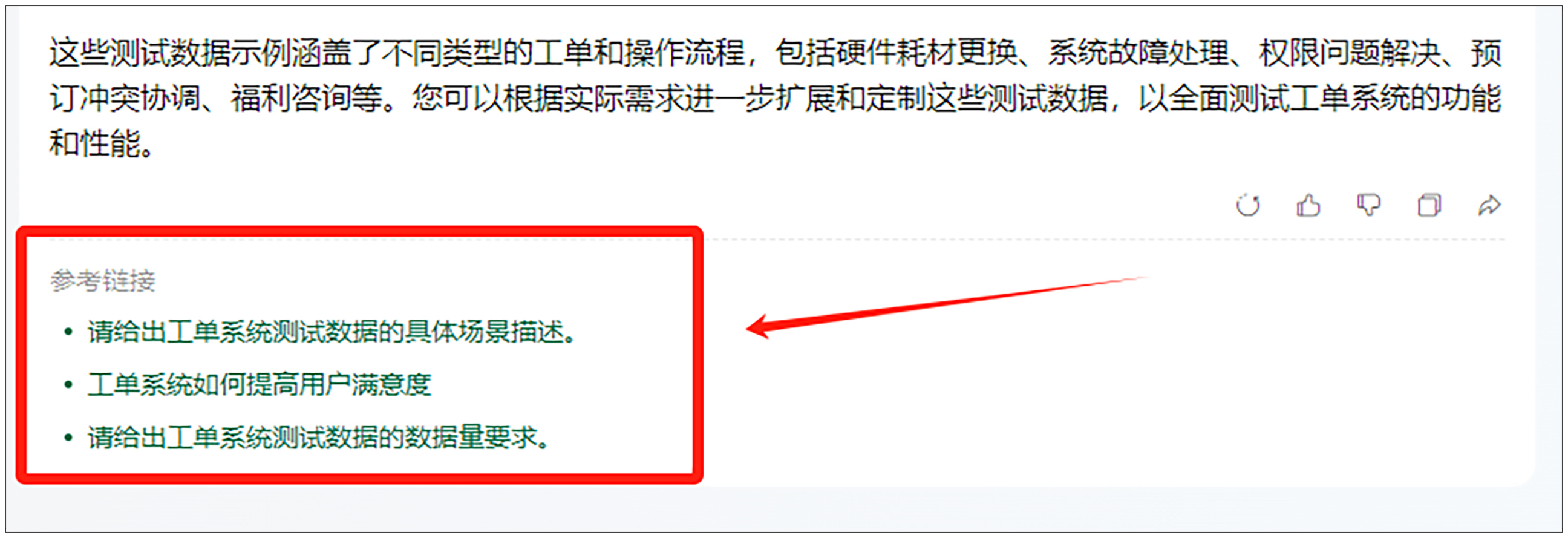
第三块功能也是我们经常看见的,用户可以点击按钮给予反馈,另外还提供了复制功能,具体效果如下图所示。
知识点拆解
了解了要实现的功能,我们再来看看实战案例3要用到的知识点有哪些。
模糊检索知识主要分三步,分别是:
- 将知识编码成向量,并且保存起来。(第15节课 向量与嵌入模型)
- 将用户问题编码成向量。(第16节课 向量数据库)
- 然后根据两者的相似度进行检索。(第17节课 通过相似度来检索知识)
首先我们会讲解一下什么是向量,以及如何将知识和用户问题编码成向量。然后我们会讲解如何保存和检索向量。了解了这两个基础概念之后,我们就可以根据知识和用户问题的向量相似度进行检索了。
之后,我们就能开始动手实战。我们首先会基于学到的基础概念改造实战案例1,以支持模糊检索。然后完成实战案例3。
选择合适自己的RAG应用立项
目前来讲,网络上讲得最多的RAG应用是客服系统。那么,为什么我们选择工单辅助系统而不是客服系统做为实战案例呢?主要是后面这几点考量。
首先,其实这个工单辅助系统本质上就是客服系统。相比于面向大众用户,一旦出错就会带来较大影响的客服系统,我们这个工单辅助系统面向企业内部用户,一旦出错,影响较小,最多就是企业内部矛盾。
其次,因为模糊检索知识想做到十分精确,需要花很多功夫。这些功夫仅仅通过一门课是远远不能涵盖的。那在此之前,我们就不做RAG应用了吗?
当然不是,学习学习,既要学也要习。结合我的RAG应用开发路径,推荐你用边学边做的方法来稳步推进。
因此我们采用以下思路——就像任何程序都会有bug一样,RAG应用也是程序,同样也会有bug,检索知识不精确也是bug的一种。我们所能做到的,就是将bug带来的影响降到最小。
因此在学习的早期阶段,我们先选择一旦出错,影响更小的工单辅助系统作为同学们的学习案例,而没有选择一旦出错,影响比较大的客服系统。等你的RAG能力到了一定水平,我们再考虑技术难度高的RAG应用。
这里就引申出一个话题,在现实工作中,如何选择合适自己的RAG应用立项?
结合我的经验,主要有四个基础和一个原则。
我们先来看四个基础。
第一,要明白所使用的大模型的能力边界。知道自己所使用的大模型能干什么,不能干什么。这一点可能对于目前的你还有点难,但是下一点就比较容易做到了。
第二,要明白自己当前的能力边界。同学们可以根据自己所掌握的技术点,还有这门课里提供的三个实战案例实现的RAG应用,来评估自己能做什么样的RAG应用,不能做什么样的RAG应用。
第三,从实用和业务角度出发。业务价值比较大的RAG应用技术难度不一定高,说不定还很容易实现。技术难度高的RAG应用,业务价值不一定高。我们先前讲实战案例1的时候,就讨论过用RAG改造系统所带来的收益,这种思路在你推动其他RAG项目的时候也可以借鉴。
第四,求稳为上。如果对大模型和自己的能力没有信心,那么选择一旦出错,影响更小的RAG应用会更稳妥。
结合这四个基础,就得到了RAG理想的一个原则——我们要根据自己当前的能力边界,选择技术难度低、业务价值高的RAG应用立项,而且要尽量选择一旦出错,影响更小的RAG应用。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了三件事情。
第一件事情是如果要针对更多的场景开发RAG应用,我们仅仅会精确检索知识是不够的,很多场景需要模糊检索知识。以实战案例1为例,如果用户没有输入客户公司全名,我们也能根据简称从数据库里面模糊检索出对应的数据。
第二件事情是模糊检索知识主要分三步。分别是将知识编码成向量,将用户问题编码成向量,然后根据两者的相似度进行检索。
第三件事情是在现实工作中,建议根据四个基础和一个原则选择合适自己的RAG应用立项。我们要根据自己当前的能力边界,选择技术难度低、业务价值高的RAG应用立项,而且要尽量选择一旦出错,影响更小的RAG应用。
下一节课我们将会学习向量与嵌入模型,这是把知识和用户问题编码成向量的重要概念,敬请期待。
思考题
请同学们发挥自己的想象力,想象一下自己工作中有哪些RAG应用场景会是业务价值比较大,技术难度比较低的?业务价值具体是什么,会有多大?会用到哪些技术点,会有多难?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- 花花Binki 👍(1) 💬(1)
CMS吧,快速检索文档和知识库对于创作者来说,很有帮助。
2024-10-11 - 峰回路转 👍(0) 💬(1)
叶老师 加密后的数据 可以使用向量数据库进行模糊搜索吗
2024-10-10 - 痴痴笑笑(Bruce) 👍(0) 💬(1)
还有更新吗?
2024-10-06 - kevin 👍(0) 💬(0)
各种家用电器的操作小助手,比如说路由器助手就可以回答用户提出的任何操作问题。
2024-11-09