13 动手实战 :项目整合,实现知识入库与知识检索
你好,我是叶伟民。
上一节课我们生成了简报。但是如果我们不仅仅想看当天的简报,我们还想看前天甚至最近一周的简报,那该怎么办呢?
其中一种方法就是把每天的简报整合进我们的实战案例1,然后在实战案例1首页提问框里面提问:前天有哪些CNET新闻?
最终效果
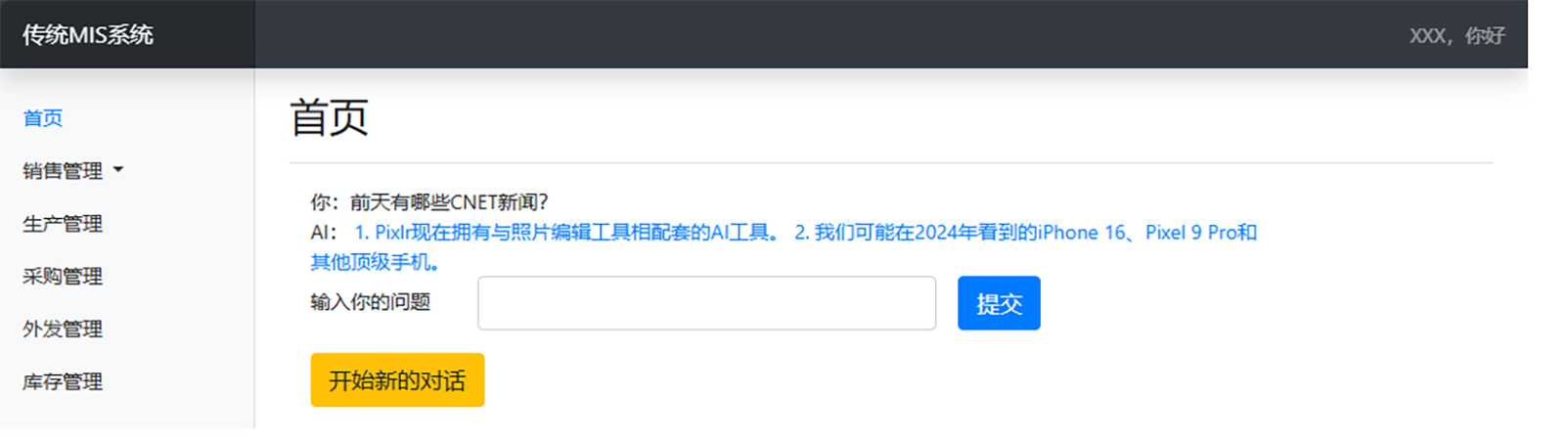
我们先来看看最终的效果。
我们在首页输入你的问题对话框输入:前天有哪些CNET新闻?然后点击提交按钮,AI将会回答前天的CNET新闻简报。
接下来我们进入实战环节,编写相应的代码。结合前面学过的实战案例1,其实无非是完成知识入库和知识检索两个部分。
所以接下来的讲解,我们会用到很多前面学过的知识,建议你先关注整合的步骤和用到了哪些知识点,然后再自己动手操作演练。
另外,我也把每个知识点具体对应的链接给你列出来了,方便你复习回顾。
修改测试数据
上一节课我们知识入库在 result.json 文件。这节课我们将从这个文件读取知识入库到数据库。
因为我们这节课要检索前天的知识,而当同学们第一次按照上一节课实战的时候,可能获取不到前天的知识。出于教学和测试目的,我们需要修改一下这个文件里面的知识。把知识的创建日期改成前天的。
我们打开 result.json 文件,将每条数据以下红线框部分都改成前天的日期。
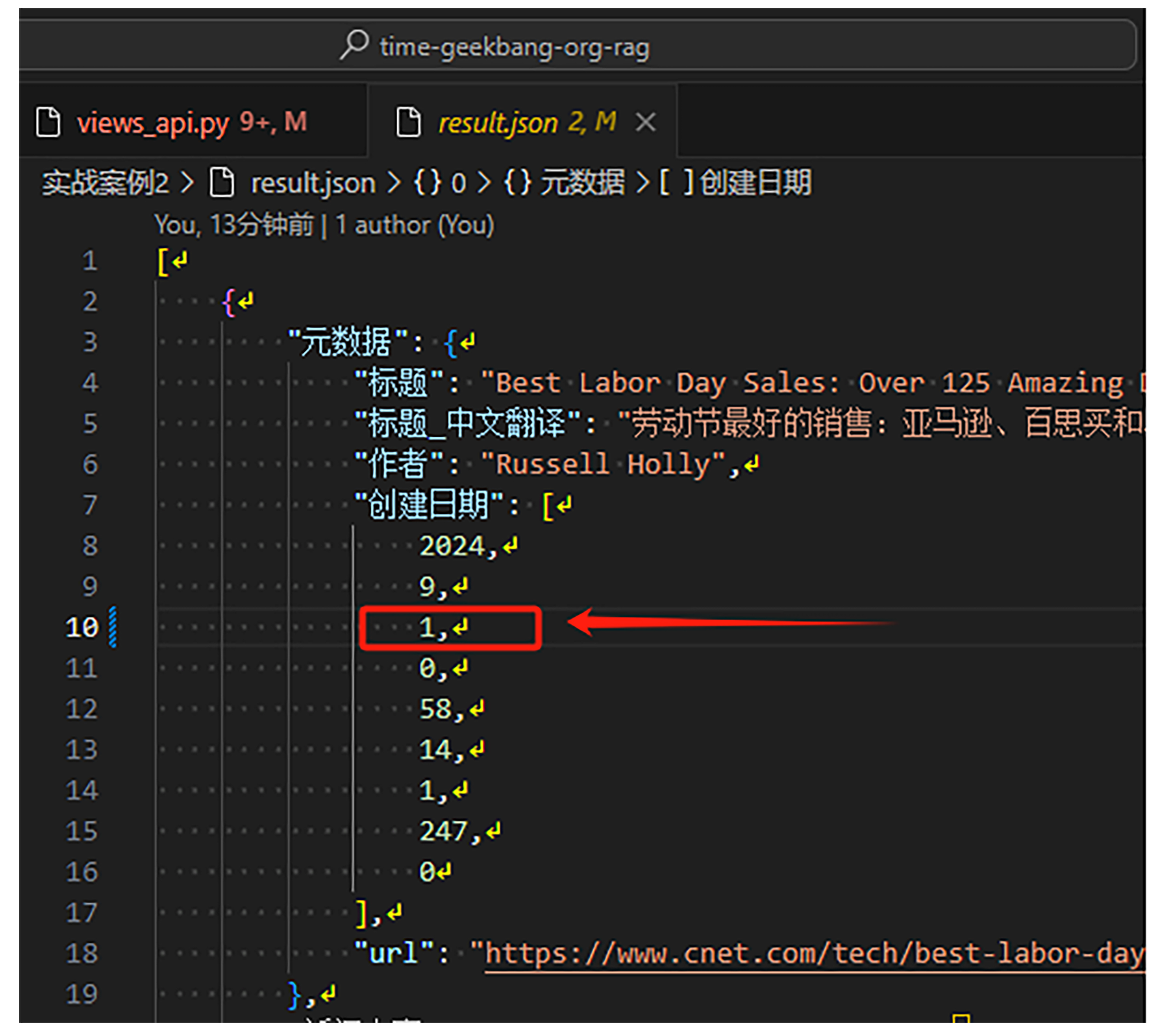
然后保存。完成这一基础步骤之后,我们可以把知识保存进数据库了。
将知识存进数据库
将知识存进数据库的代码主要分以下几部分。
- 建立ORM模型。
- 将知识存进数据库。
- 管理数据库里面的知识。
建立ORM模型
我们先来建立ORM模型。这里只需要按照第九节课所讲的元数据表结构设计,建立ORM模型。我们打开实战案例1 home 目录下的 feed.py 文件,在底部加入以下代码。
class CNET新闻(models.Model):
id = models.IntegerField(
primary_key = True,
editable = False)
标题 = models.TextField()
url = models.TextField(null=True)
作者 = models.TextField(null=True)
权限 = models.TextField(null=True)
文本摘要原文 = models.TextField(default=False)
全文原文 = models.TextField(default=False)
文本摘要中文翻译 = models.TextField(default=False)
全文中文翻译 = models.TextField(default=False)
创建时间 = models.DateTimeField(auto_now_add=True)
lastmodified_time = models.DateTimeField(auto_now=True)
然后我们按照第一节课所讲的方式,另外开一个 Anaconda Powershell Prompt,激活 rag1 虚拟环境,进入实战案例1的目录,然后运行以下命令更新数据库。
以上代码第1和第2行更新数据库,第3行顺便把实战案例1运行起来。
建立完ORM模型之后,更新完数据库之后,我们可以将知识存进数据库了。
将知识存进数据库
将知识存进数据库的方式有很多种,为了尽可能通用,我们将知识入库方法封装成一个http API,并对外开放。
我们打开 home 文件夹下面的 views_api.py 文件,在最底部加入以下代码。
@csrf_exempt
def 知识入库api(request):
知识 = request.POST['knowledge']
知识入库(知识)
return JsonResponse({"code":200,"message":"已经成功将知识入库"})
然后打开 home 文件夹下面的 urls.py 文件,在最底部的 ] 前面插入以下代码。
接下来我们把上节课爬到的CNET新闻导入数据库。
导入知识
然后我们回到实战案例2,新建将新闻导入数据库.py 文件,输入以下代码。
import json
import requests
if __name__ == "__main__":
# 读取result.json文件,
with open("result.json", "r", encoding="utf-8") as f:
data = json.load(f)
url = "http://127.0.0.1:8000/api/add-cnet-news"
# 将data做为form-data以post形式发给url
headers = {'Content-Type': "application/json"}
response = requests.post(url, json=data,headers=headers)
# 打印response的结果
print(response.text)
然后回到实战案例2的 Anaconda Powershell Prompt(也就是虚拟环境为 rag2 的那个),运行以下命令将知识导入数据库。
如果一切顺利,我们会看到以下截图。

将知识存进数据库之后,我们还需要管理数据库里面的知识。
管理数据库里面的知识
我们打开 home 文件夹下面的 admin.py 文件,在最底部加入以下代码。
from .models import CNET新闻
class CNET新闻Admin(admin.ModelAdmin):
pass
admin.site.register(CNET新闻, CNET新闻Admin)
然后我们打开浏览器,输入 http://127.0.0.1:8000/admin ,登录之后将跳回管理员界面。如果一切顺利,我们应该看到如下界面。
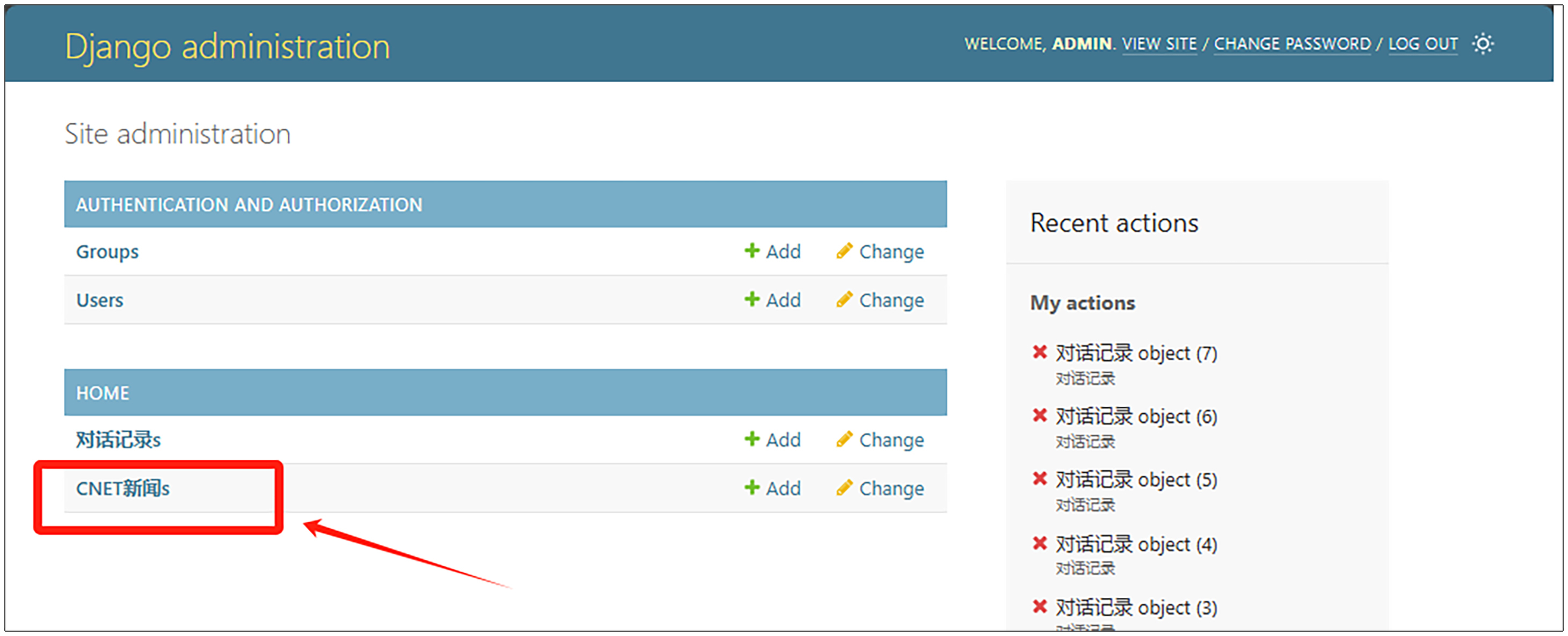
然后点击以上链接之后,将会看到刚才导入的CNET新闻。
现在我们可以在管理员界面管理数据库里面的知识了。
接下来,我们还要编写根据问题检索知识部分的代码。
根据问题检索知识
根据问题检索知识主要包括三个步骤。
- 大模型根据用户提问得出查询参数。
- 根据查询参数检索出对应的知识。
- 将检索到的知识与用户提问一起提交给大模型。
我们依次来实现它们。
根据用户提问得出查询参数
首先,我们打开 home 文件夹下面的 rag.py 文件,找到构造解析用户输入并返回结构化数据用的 messages 函数,把它修改成如下代码。
def 构造解析用户输入并返回结构化数据用的messages(用户输入):
messages=[
{"role": "user", "content": f"""
请根据用户的输入返回json格式结果,除此之外不要返回其他内容。注意,模块部分请按以下选项返回对应序号:
1. 销售对账
2. 报价单
3. 销售订单
4. 送货单
5. 退货单
6. 从CNET新闻表里面检索知识
7. 其他
示例1:
用户:客户北京极客邦有限公司的款项到账了多少?
系统:
{{'模块':1,'客户名称':'北京极客邦有限公司'}}
示例2:
用户:你好
系统:
{{'模块':7,'其他数据',None}}
示例3:
用户:最近一年你过得如何?
系统:
{{'模块':7,'其他数据',None}}
示例4:
用户:前天的CNET新闻有哪些?
系统:
{{'模块':6,'日期',-3}}
用户:{用户输入}
系统:
"""},
]
return messages
与之前相比,我们添加了第28到31行代码。这几行代码十分容易懂,使用了第五节课根据用户发问查询数据的知识点,具体就是加了一个示例,指导大模型根据问题指出正确的模块序号6(也就是CNET新闻),同时得出正确的日期。
将查询参数转化为程序可识别的日期
现在通过大模型会获得以下查询参数:
注意,这里日期的值是前天,这个值只能被人类识别,程序不可识别和计算。那么我们如何将前天换算成具体的日期呢?
我一开始跟其他网络文章一样,是使用大模型得出前天的具体日期。结果掉进坑里面了,发现不稳定。经过思考研究,我认为:得出前天的具体日期是数学计算。在大模型不擅长数学计算的段子满天飞的今天,做为一名工程师,我们应该实事求是,尊重这个事实,不要强大模型所难,让大模型去做数学计算。我们要知人善用,让大模型去做它擅长的事情。
另外,实事求是和精益求精并不冲突。我们工程师实事求是把AI应用落地,AI科学家们精益求精解决大模型做数学计算的问题。工程师和科学家都是为AI、为社会、为人类做贡献,我们只是分工不同而已。
既然不使用大模型得出前天的具体日期,那么如何获得呢?我们可以使用传统代码。
我们打开 rag.py 文件里面的对AI结果进一步处理函数,添加多一行代码。
def 对AI结果进一步处理(AI结果):
处理后结果 = AI结果.replace("```json", '').replace("```", '') # 去掉json格式之外无关的内容
处理后结果 = 处理后结果.replace("根据您所提供的信息,","") # 去掉开头的提示
处理后结果 = 将日期换算成实际日期(处理后结果)# 针对实战案例2的处理
return 处理后结果
其中第5行就是我们新添加的代码,专门用于获得实际日期。
然后我们在对AI结果进一步处理函数前面加上将日期换算成实际日期函数的具体实现。
def 将日期换算成实际日期(input_str):
if "日期" in input_str:
try:
# 将输入的 JSON 字符串转换为字典
input_data = json.loads(input_str.strip())
# 检查模块是否为6
if input_data.get("模块") == 6:
# 检查是否存在日期字段
if "日期" in input_data:
if input_data["日期"] == "前天":
# 获取当前日期并计算前天的日期
yesterday = datetime.now() - timedelta(days=2)
input_data["日期"] = yesterday.strftime("%Y-%m-%d")
return json.dumps(input_data)
except:
return input_str
以后我们可以根据需要扩展第11行到14行代码。随着扩展越来越多,我们肯定是要提取出类和设计模式的,这里我们可以应用这门课最后一节课的知识,用AI帮助我们规范化和工程化。
根据查询参数检索出对应的知识
这一步使用了第六节课的知识点,我们找到 rag.py 文件里面的查询函数,把这个函数改成后面的样子。
def 查询(查询参数):
if '模块' in 查询参数:
if 查询参数['模块'] == 1: #'销售对账'
if '客户名称' in 查询参数:
客户 = 查询参数['客户名称'].strip()
return 销售入账记录.objects.filter(客户__icontains=客户)
if 查询参数['模块'] == 6: #'CNET新闻'
if '日期' in 查询参数:
日期 = 查询参数['日期'].strip()
print(f'日期={日期}')
# 定义日期字符串
date_str = '2024-09-14'
# 定义日期格式
date_format = '%Y-%m-%d'
# 将字符串转换为日期对象
date_obj = datetime.strptime(date_str, date_format)
查询结果 = CNET新闻.objects.filter(新闻发布日期__date=date_obj).values_list('标题中文翻译', flat=True)
return 查询结果
从数据库检索出对应知识之后,我们还需要将检索到的知识与用户提问一起提交给大模型。这里可以重用之前的代码。
然后我们打开浏览器,输入 http://127.0.0.1:8000/, 在首页输入你的问题对话框输入:前天有哪些CNET新闻?然后点击提交按钮。如果一切顺利,AI将会回答前天的CNET新闻简报。
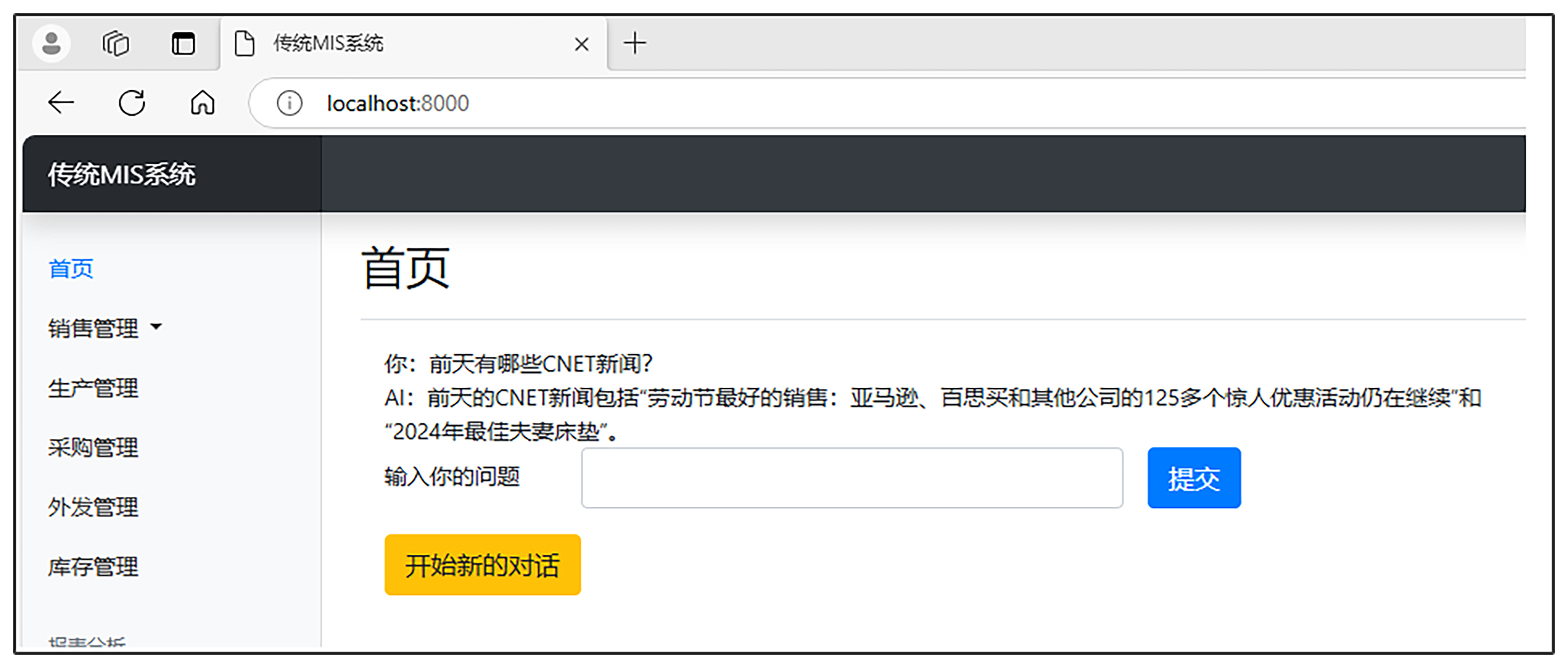
好了,现在我们很容易就可以查看前天有哪些CNET新闻了。
实战案例2到此结束了。实战案例2的完整源代码放在这里。
通过实战案例1和2,同学们能够从0到1打造自己的RAG应用。接下来我们将目标转到检索知识的质量上。接下来的十几节课里,我们将继续学习基础概念,并通过对应的动手实战代码来提升知识检索质量。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。
这一讲我们学会了一件事情和一个重点。
一件事情是如何将实战案例2整合进实战案例1。将实战案例2整合进实战案例1之后,我们就可以提问前天有哪些CNET新闻了。这节课讲完后,现在我们的实战案例1除了包含知识检索部分,还包含了知识入库部分了。
一个重点是我们要知人善用,不要强大模型所难,知道大模型的能力边界,知道大模型擅长干什么,不擅长干什么。在大模型不擅长数学计算的段子满天飞的今天,做为一名工程师,我们应该实事求是,尊重这个事实,不要强大模型所难,让大模型去做数学计算。我们要知人善用,让大模型去做它擅长的事情。
思考题
学习学习,既要学又要习,才能真正掌握一项技能。现在动起手来吧,基于这节课代码去完善你上一节的课后练习代码。
如果你觉得有收获的话,欢迎你把这节课分享出去,让更多的人了解将数据获取进RAG应用的方法。
- kevin 👍(0) 💬(4)
老师请问定位到前天的代码是写死在代码中的,如果我要查询上个星期,上个月的怎么办呢?
2024-10-19 - 亚林 👍(0) 💬(0)
这里就是靠LLM理解出——ORM框架需要的过滤日期吧
2025-02-18