11 动手实战:让简报助手每日自动获取最新数据
你好,我是叶伟民。
上节课,我们看到“AI读报小助手”这个案例,由此大致了解了新开一个全新RAG项目的整体过程。通过学习不难发现,实现一个全新的RAG项目,并非遥不可及。不过,这种方式因为没有使用传统MIS系统的代码,对于有些同学来说比较陌生,从而望而生畏。
不用担心,具体实现起来并没有想象中的那么难!这节课我们就进入动手环节,学完今天这一讲,对于如何实现这样一个项目,你就会了然于胸了。
如何获取我们所需要的数据
我们前面提到,AI应用有三大支柱——算法、算力、数据。算法就是我们所采用的大模型,算力我们使用百度文心大模型API。
上一章的案例里,我们使用了MIS系统里的现有数据。在这个实战案例里面,我们并没有现有数据可用,所以需要录入数据。
那么如何录入数据呢?
如果像上一个实战案例MIS系统那样一条一条录入,速度太慢,周期太长。等数据积累到可以跑大模型应用的程度,黄花菜都凉了。所以我们需要加快数据录入速度,最好是马上能用的那种。这样的话靠人工录入肯定是不可能的,只能靠机器自动录入。
那么如何靠机器自动录入呢?一般来说有两种方式。
- 通过调用数据提供方提供的API获取。
- 通过爬虫爬取网页进行解析。
一般来说,对于同一家数据提供方,我建议先采取第一种方法。只有在第一种方法不可行的前提下,我们再考虑采取第二种方法。这是因为和第一种方法相比,第二种方法的难度、工作量要高上一个甚至几个数量级,甚至很多时候是不可行的(比如数据提供方采取了反爬措施)。
就第一种方法而言,一般又有以下几种接口供我们选择。
- 数据提供方提供的RSS接口。
- Web服务接口,如RESTful API。
结合 “AI读报小助手”这个实战案例而言,我们的数据提供方CNET提供了RSS接口,所以我们直接调用CNET提供的RSS接口就可以获取数据了。
那么如何通过RSS接口获取数据呢?
Python提供了一个叫 feedparser 的库,专门用来解析RSS和Atom订阅源。它能够将这些订阅源转换成Python对象,方便开发者进行处理和分析。使用 feedparser 这个库,我们只需要几行代码就可以实现获取数据这项功能。
不过在开始编写代码之前,我们还需要像上一个实战案例一样先创建项目,搭建好虚拟环境。
创建项目和搭建虚拟环境
我们像上一个实战案例一样打开 Anaconda Powershell Prompt,输入后面的命令创建项目。
接着进入项目目录。
创建虚拟环境(注意,这里的python环境最好选定3.9版本不要改,因为其他版本可能会导致 feedparser 安装失败)。
这里的rag2是虚拟环境的名称。
然后激活虚拟环境。
就像后面图里展示的这样,当命令行开头的括号内容从 base 变成了 rag2,就说明我们已经成功切换了虚拟环境。

之后我们还需要安装相关依赖。
当出现以下界面时,则说明该依赖已经安装成功了。

进行到这里,我们就创建好了这个章节实战案例的项目和虚拟环境。
获取数据
现在我们就来完成获取数据的代码。使用 feedparser 从RSS数据源获取数据相当简单,只需要两三行代码就能搞定。
首先导入 feedparser 。
然后调用 feedparser.parse 函数,设置RSS数据源参数即可。
# 定义要获取的RSS源
rss源 = "https://www.cnet.com/rss/news/"
#region 使用feedparser解析RSS源
feed = feedparser.parse(rss源)
不过为了确认程序无误,一切正常,这里我们还是获取到的数据打印出来看一看。
#region 这段代码纯粹是为了确认我们获取成功,调试用,可以删除
for entry in feed.entries:
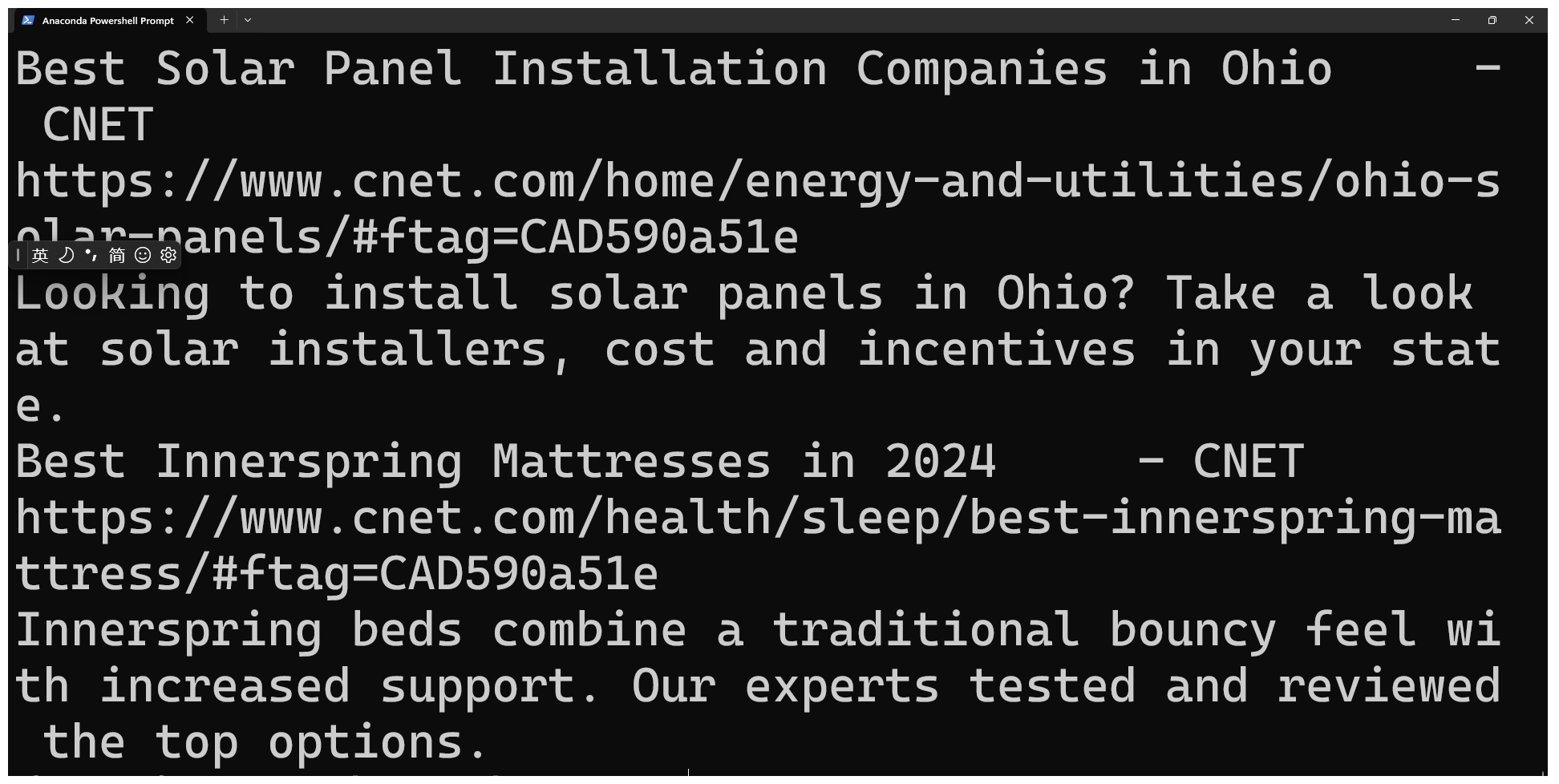
print(entry.title) # 打印标题
print(entry.link) # 打印链接
print(entry.description) # 打印描述
#endregion
程序运行后,就会输出获取的结果。
如何保存我们所获取的数据
现在我们解决了获取数据的问题,那么如何保存我们所获取的数据呢?
上一个实战案例的数据保存在数据库,这里我们同样也可以选择保存在数据库。不过这节课为了简化操作,我们先简单地保存为本地json文件,然后在第13节课再保存进数据库。
因此我们保存数据的代码相当简单,只有两行。
#region 将feed.entries保存到本地json文件
with open('feed.json', 'w', encoding='utf-8') as f:
json.dump(feed.entries, f, ensure_ascii=False, indent=4)
#endregion
完整的源代码
创建项目、搭建环境以及获取数据是我们这个项目里最核心的部分,理解了这些,我们就可以从头到尾完整实现一下了。
完整的源代码如下。
# -*- coding: utf-8 -*-
import json
import feedparser
def 获取数据():
# 定义要获取的RSS源
rss源 = "https://www.cnet.com/rss/news/"
#region 使用feedparser解析RSS源
feed = feedparser.parse(rss源)
#region 这段代码纯粹是为了确认我们获取成功,调试用,可以删除
for entry in feed.entries:
print(entry.title) # 打印标题
print(entry.link) # 打印链接
print(entry.description) # 打印描述
#endregion
#endregion
#region 将feed.entries保存到本地json文件
with open('feed.json', 'w', encoding='utf-8') as f:
json.dump(feed.entries, f, ensure_ascii=False, indent=4)
#endregion
return feed.entries
if __name__ == "__main__":
新闻列表 = 获取数据()
我们在项目目录下创建 feed.py 文件,复制粘贴前面这段代码。
之后,我们就可以在 Anaconda Powershell Prompt 输入以下命令来运行程序。
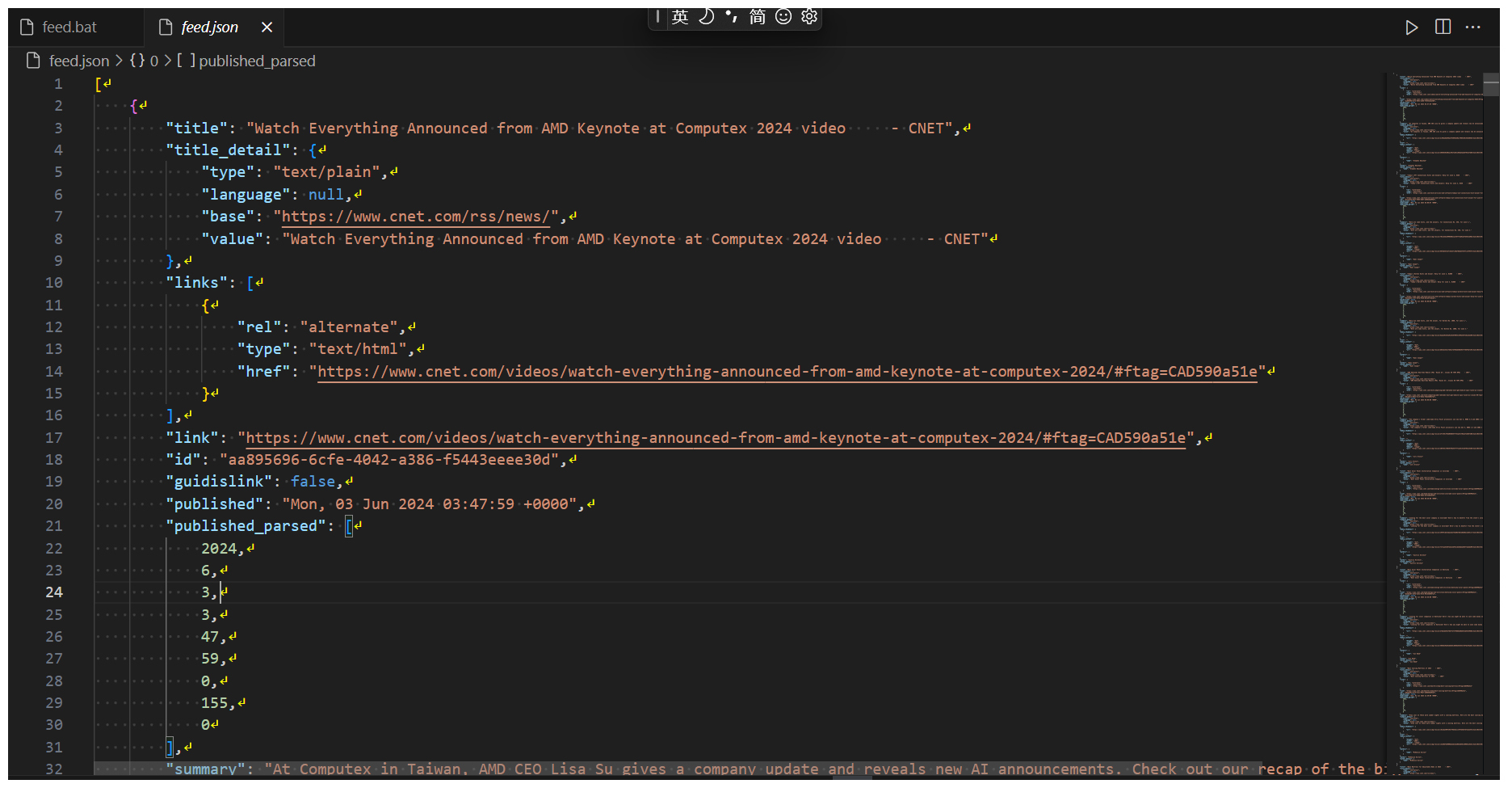
程序成功运行后,会在同级目录下生成 feed.json 文件。
为了确认程序正常运行无误,我们还是应该打开 feed.json 文件看看。如果一切正常,它的模样应该是后面这样。
每日获取最新数据
现在我们只获取了一次数据,但是我们每日都需要获取最新数据,对此我们可以通过任务计划来实现这一点。
创建bat文件
在创建任务计划之前,我们需要创建一个bat文件,因为我们的任务计划就是要运行这个bat文件。
我们进入项目目录,新建文件 feed.bat。然后输入以下内容:
call F:\miniconda3\Scripts\activate.bat F:\miniconda3
call conda activate rag2
call cd /d F:\temp\rag2\
call python feed.py
注意,这里有两处内容需要你结合自己的情况修改。
- 将第一行的
F:\miniconda3替换为你的Anaconda安装路径。 - 将第三行的
F:\temp\rag2\替换为你的项目路径。
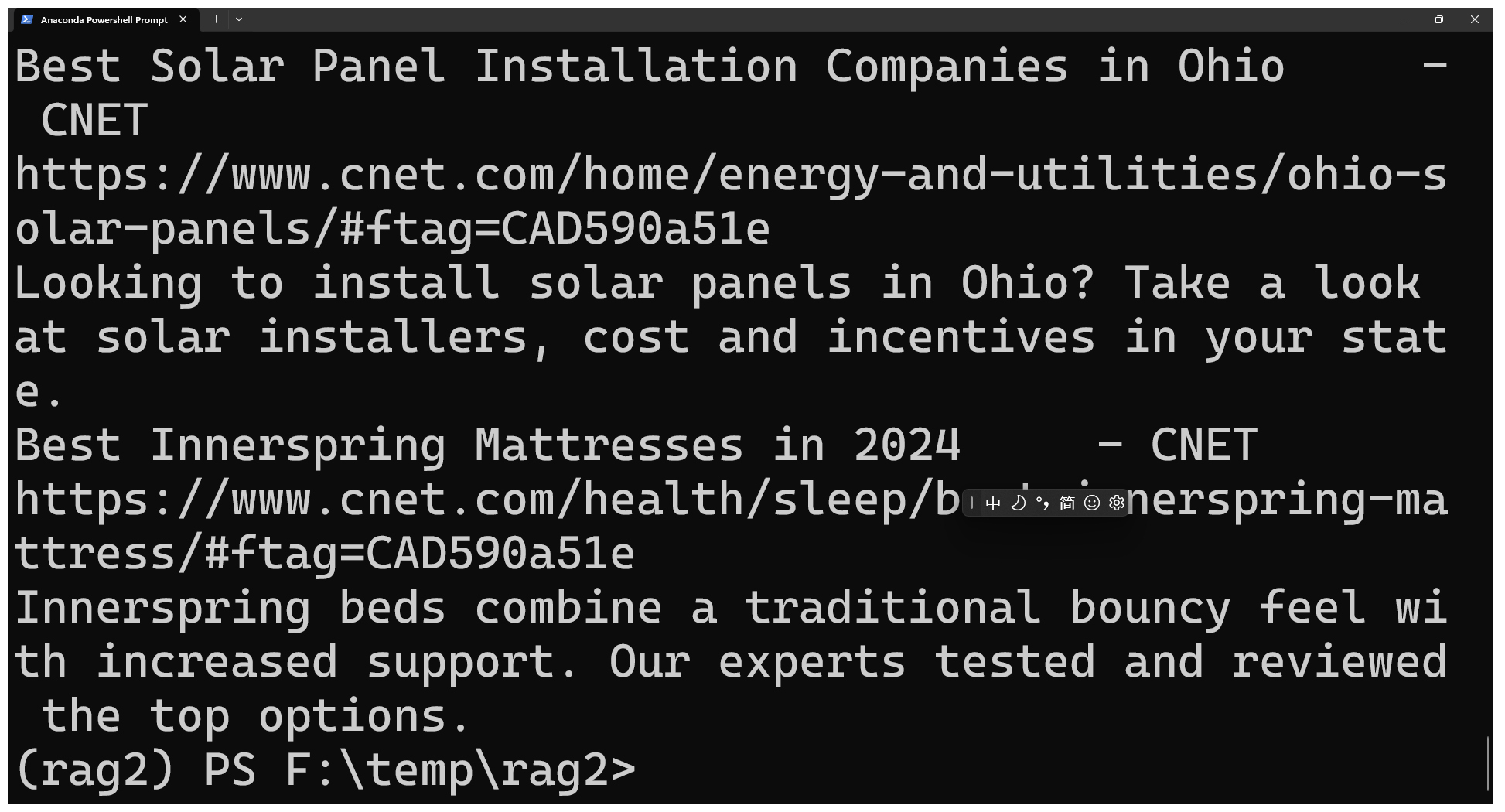
保存了feed.bat之后,打开命令行,运行一下这个 feed.bat 文件。注意后面的文件名里应该是你替换后的项目路径,可能和我这里展示的不一样。

如果出现类似后面这样的结果,就说明操作成功了。
创建任务计划
现在一切都准备好了,我们可以创建任务计划了,按照下面的操作一步步完成即可。
第1步,点击Windows开始菜单,输入“任务计划程序”。
第2步,点击右边面板的“创建基本任务”。
第3步,名称输入“AI读报小助手”,然后点击“下一页”。
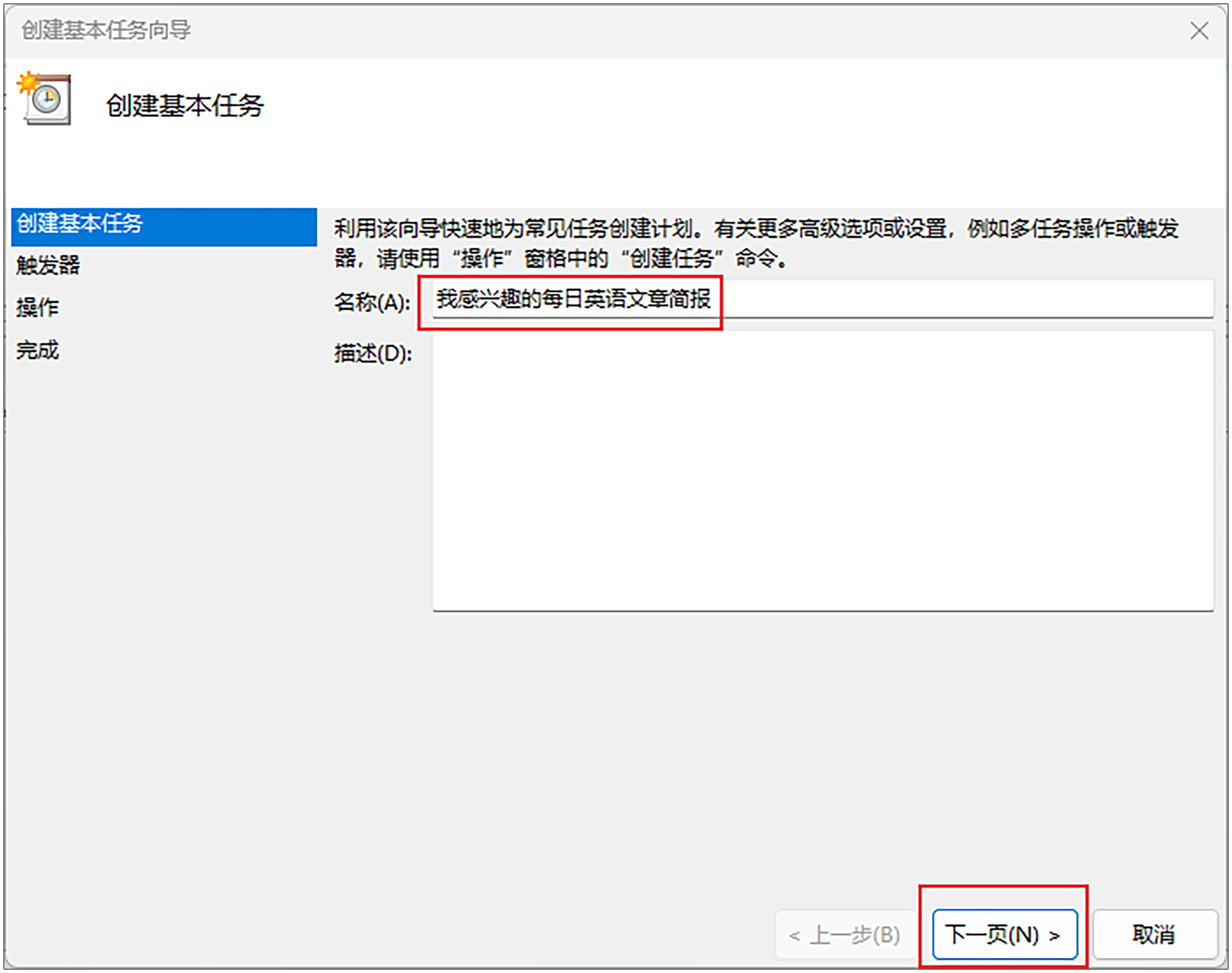
第4步,在触发器选项里,选择“每天”,然后点击“下一页”。
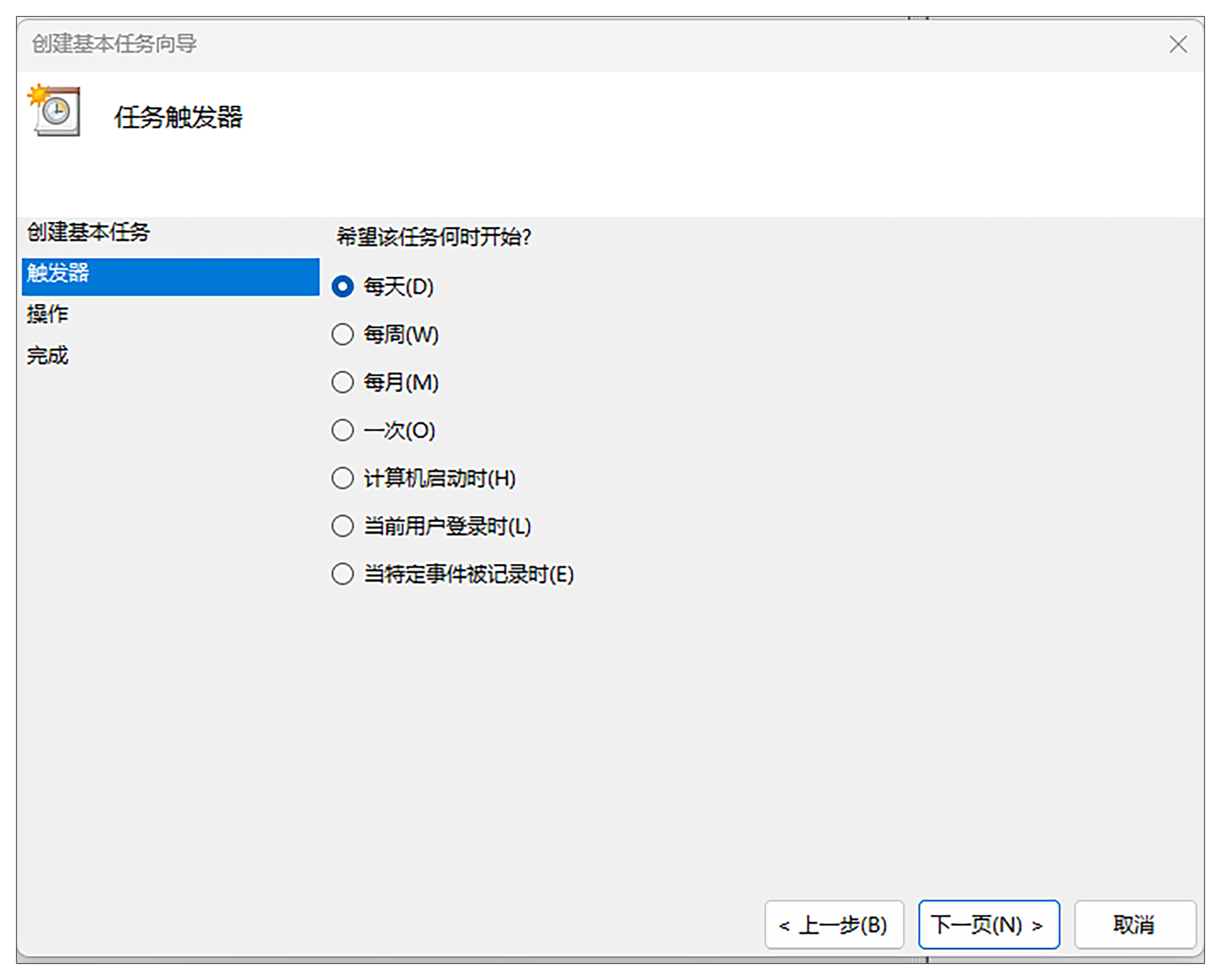
第5步,时间设置为“9:00:00”,然后点击“下一页”。
第6步,选择“启动程序”,然后点击“下一页”。
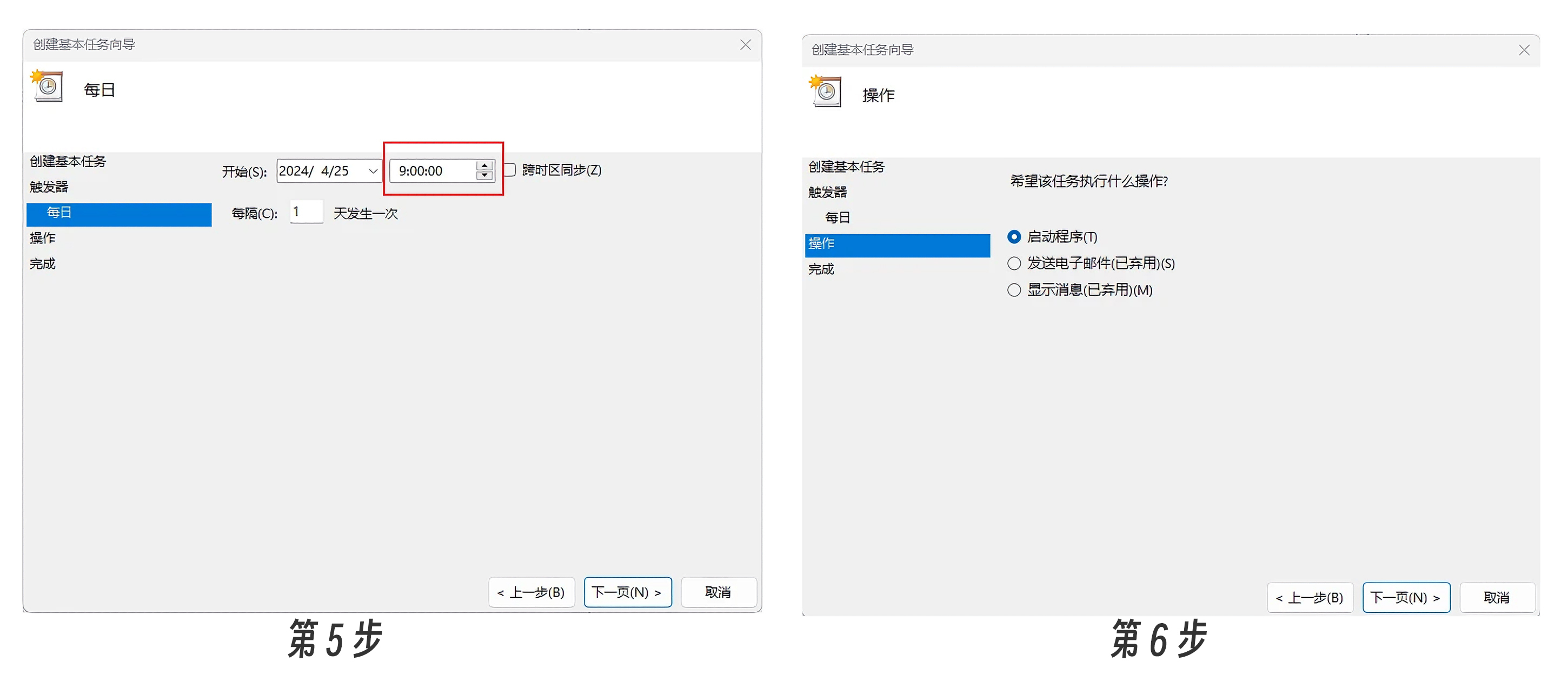
接下来是第7步,设置“操作”部分。“程序或脚”一栏本选择我们刚才创建的feed.bat,然后点击“下一页”。
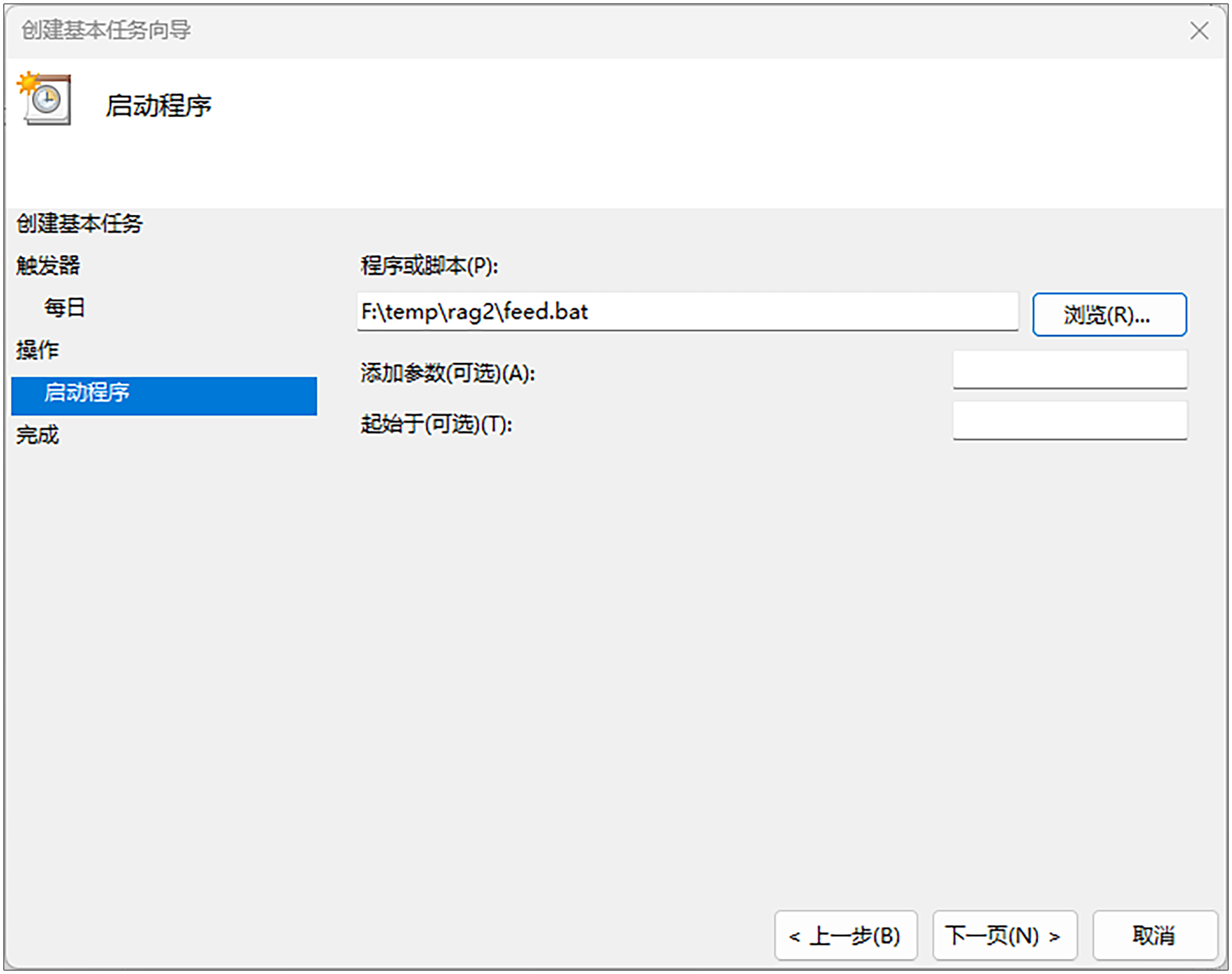
第8步,点击“完成”。
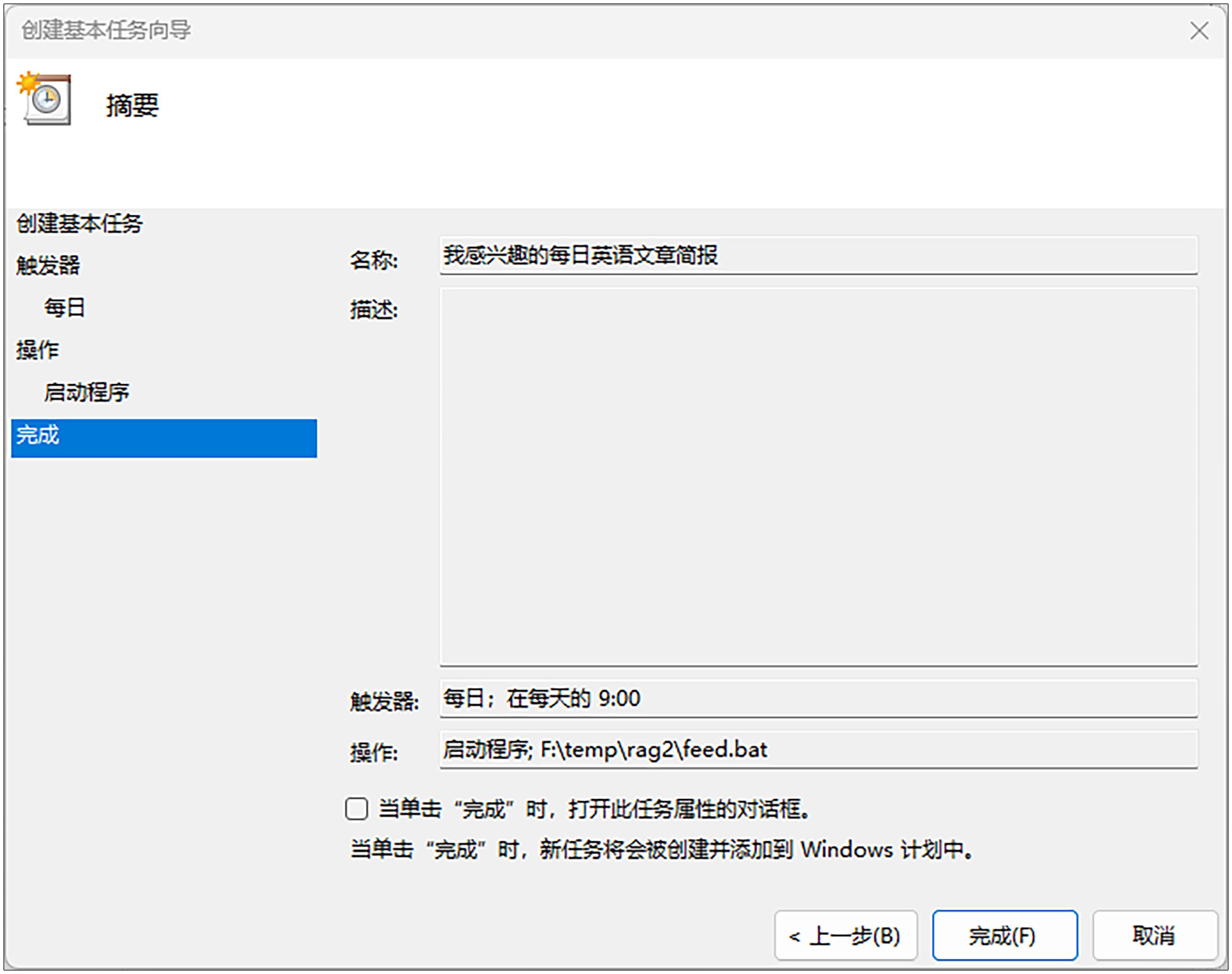
最后,我们在中间的任务计划程序面板中找到这个任务,鼠标右键点击“运行”。

此时应该弹出上一小节的命令行窗口,然后我们回到项目目录,确认一下 feed.json 文件是否已经更新。如果已经更新,则表示运行正常。
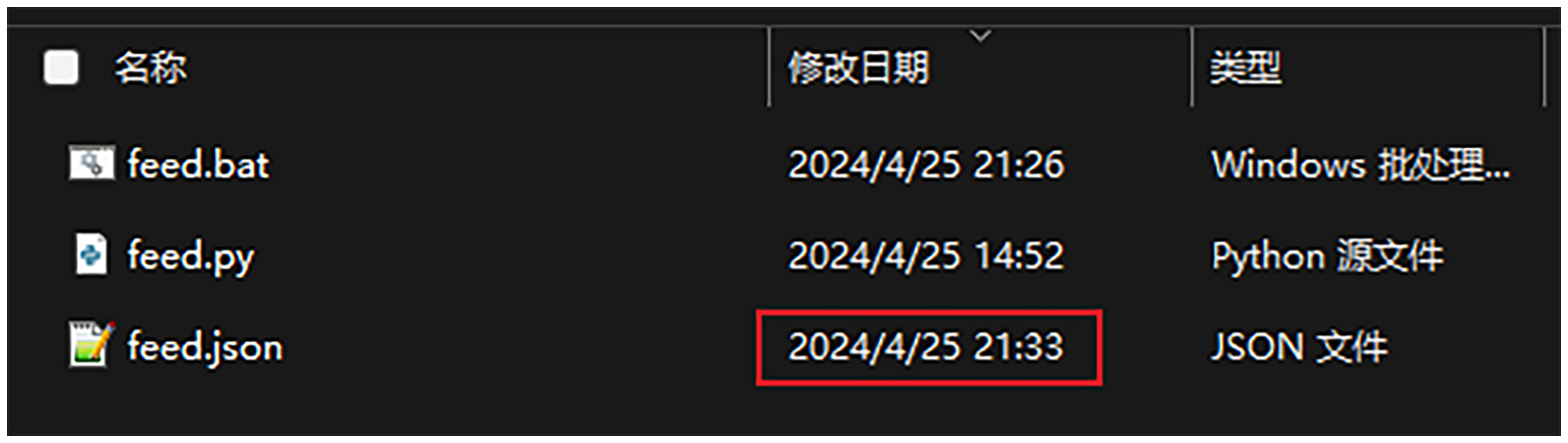
设置完毕之后,每日上午9点Windows系统将会自动获取最新数据。
在此,我强烈建议你按照课程的讲解亲自上手操作一下,因为只有把这个实战案例真正用起来,你才有兴趣和动力去改进这个实战案例,才能有兴趣、有针对性地持续学习、研究下去。
现在,我们实战案例2的主干已经完成,下一节课我们将读取元数据,抓取新闻内容,对新闻进行摘要,翻译标题,翻译全文内容,最后整合成简报。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。
这一讲我们学会了三件事情。
第一件事情,怎么获取我们所需要的数据。要马上获得足够的可以用于AI应用的数据,靠人工录入太过繁琐,因此需要靠机器自动录入。MIS系统使用UI来录入数据,我们这个案例并没有UI,而是通过使用 Python现成的 feedparser 包 去爬取数据。
第二件事情,是如何保存我们所获取的数据。跟实战案例1一样,我们可以把所获取的数据保存到数据库表里面,但本节课我们先简单地保存为本地json文件。
第三件事情,是如何设置我们的程序每天运行。实战案例1的MIS系统是通过Web形式运行,我们这个案例并没有Web UI,所以选择做成了一个bat文件,然后通过任务计划运行。
思考题
在实际工作中,这一讲里“如何获取我们所需要的数据”部分的程序,有很大概率是可以重用的,你只需要修改里面的RSS数据源即可。而“如何保存我们所获取的数据”这个部分则需要替换。
为了帮助你学以致用,建议你课后做两个练习。
- 选择你想获取的RSS数据源。
- 将获取下来的数据保存进你自己的系统。
如果很不幸,你想获取的数据提供方没有RSS数据源,那么你可以看看对方有没有提供Restful API。
如果对方有提供Restful API,一般都会提供相应文档,你照着相应文档获取即可。如果对方没有提供Restful API,那我建议你换一个数据提供方继续我们的课后练习。
如果你觉得有收获的话,欢迎你把这节课分享出去,让更多的人了解将数据获取进RAG应用的方法。
- 秋天 👍(0) 💬(1)
call F:\miniconda3\Scripts\activate.bat F:\miniconda3 call conda activate rag2 call cd /d F:\temp\rag2\ call python feed.py 这个命令在上一行进入到rag2里面就已经不执行了???
2024-10-29 - 肖遥 👍(0) 💬(0)
创建虚拟环境的命令 `conda create --n rag2 python=3.9` 多了一个 “-”
2025-01-03