08 RAG简报助手:打造读报小助手,每天为你节约半小时
你好,我是叶伟民。
实战案例1存在一个问题,并非所有同学都有一个现成的MIS系统可以改造。对于这部分同学,没有办法深入研究实战案例1。
针对这一点,我推出了实战案例2,它就是“AI读报小助手”。这个实战案例最终的效果是,让大模型每天从国外著名的IT新闻网站CNET获取当天的IT新闻,然后进行摘要和翻译成中文,整理成一份简报,并自动打开给你查阅。
相比实战案例1,这个实战案例可能绝大部分同学都感兴趣,而且比较实用。这样一来,你动手实践,甚至在使用中改进项目的动力也更强,这样也距离我们提升自身RAG能力的目标更进一步。毕竟师傅带进门,修行在个人。
好,我们这就开始今天的内容。
效果展示
现在我们来看看这个实战案例的效果。
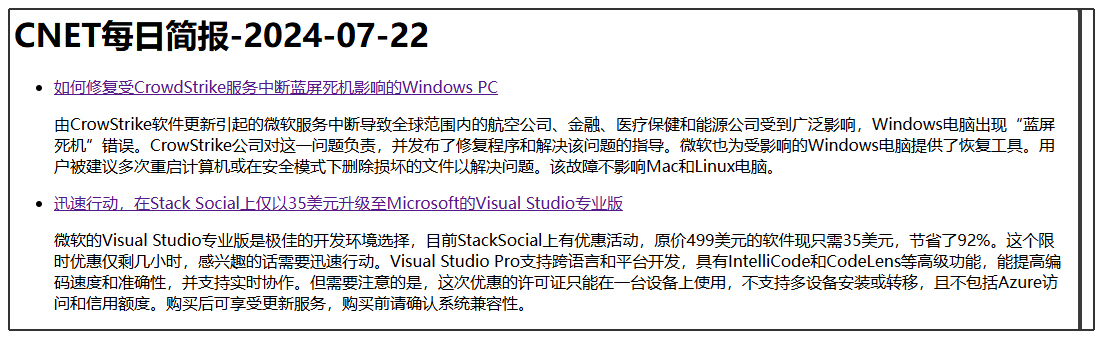 这个实战案例会通过Windows任务计划每天运行一次Python脚本。在本地电脑上生成一份CNET当天新闻的简报,并通过浏览器自动打开。
这个实战案例会通过Windows任务计划每天运行一次Python脚本。在本地电脑上生成一份CNET当天新闻的简报,并通过浏览器自动打开。
这个实战案例的业务价值主要有三点。
第一,没有AI读报小助手的话,我们需要每天打开CNET网站。完成这个案例以后,我们就可以把这一步时间省了。
第二,CNET新闻是英文的,有些同学看起来会比较费劲。这个案例将内容翻译成中文,看起来轻松多了。
第三,CNET新闻是很长的一整篇文章,而且还夹有广告,阅读体验不好。这个案例将对整篇的文章做摘要。这样同学们可以先看摘要,确认文章是自己感兴趣的,然后再点击新闻链接,查看详细内容。
如何将该实战案例代码用在自己的工作或生活中?
这个实战案例其实脱胎于我过往工作中的两个项目。所以我很容易就想到了一些可以用在同学们工作中的地方。
比方说,让AI读报小助手每天定时抓取国外同行的新闻,摘要并翻译成中文供我们查阅,使用者除了自己,还可以提供给领导、同事等等。以金融行业为例,每日可以定时抓取美股新闻,摘要并翻译成中文供用户查阅。
也可以用在同学们生活中,比如说每天定时抓取自己感兴趣的英文网站新闻,摘要并翻译成中文供自己查阅。
看到这里,是不是对这个案例更有兴趣了?我们这就梳理一下完成这个项目,都需要哪些RAG相关的知识点。
知识点拆解
这个实战案例会用到以下知识点:
- 知识入库
- 元数据
- 文本摘要
- 机器翻译
这些知识点是很多RAG应用都会用到的。我们先从知识入库讲起。
知识入库
就像数据需要保存进数据库才能让检索查询到,知识同样也需要保存进知识库才能让RAG应用检索到。这个步骤称为知识入库。
我们实战案例1里面的知识来自于MIS系统,所以没有知识入库这部分内容。然而现实工作中,很多RAG应用都需要知识入库。
元数据
实战案例2需要我们提取和保存知识的元数据。
元数据在RAG应用里面是相当重要的一个知识点。元数据是指知识相关的一些信息,包括作者、创建日期、链接等等。
我举个例子你会更好理解。比方说,我们想查看前天的CNET新闻,就会向RAG应用提问:前天的CNET新闻有哪些?
这时候RAG应用就需要根据创建日期这一个元数据,去知识库里面搜索相关知识了。
讲到这里,顺嘴提一下,每个RAG应用都是由用户提问和系统检索知识交给AI回答这两部分组成。在这个实战案例中,用户的提问实际就是:今天的CNET有哪些新闻?请把这些新闻摘要并翻译成中文发给我。
收到提问后,系统将会把当天抓取到的所有知识交给AI去摘要,并翻译成中文返回给用户。换句话说,就是从知识库里面检索所有知识,而不是像实战案例1那样检索局部知识。
文本摘要
前面我们提到,这个案例我们会每篇CNET新闻进行文本摘要。文本摘要同样是RAG应用中的一个重要知识点。
文本摘要的优点很明显,它能帮我们节约不少阅读时间,确认对摘要内容感兴趣,再去查阅全文。RAG应用也可以跟人类类似,先通过摘要判断知识是否是用户想要的,然后再去获取知识全文。具体过程我们会在下一节讲解。
机器翻译
前面提到CNET上的信息都是英文的,但是用户通常是用中文向系统提问的。如果不对用户的提问或者知识进行翻译,那么系统将很难检索出跟用户提问相关的知识。
除此之外,设想一下,在一个RAG应用中,既有中文的知识也有英文的知识。用户用中文问了一个问题,系统能够检索中文和英文相关知识,自然比只检索中文相关知识更有优势。
拆解完这些知识点之后,我们开始讲第一个知识点——知识入库。
知识入库
在实战案例1中,知识来自于MIS系统,是之前人工一条一条录入的。但是在实战案例2中,这种方法明显不可取。很多RAG应用的知识入库方式都是自动的。
自动知识入库的方式有很多,包括:
- 通过调用数据提供方提供的API获取
- 通过爬虫爬取网页获取
- 从第三方系统导入
- 从Excel文件读取
- 从Word文件读取
- 从PDF文件读取
实战案例2用到了前两种。
一般来说,对于同一家数据提供方,我建议先采取第一种方法。只有在第一种方法不可行的前提下,我们再考虑采取第二种方法。
这是因为和第一种方法相比,第二种方法的难度、工作量要高上一个甚至几个数量级,甚至很多时候是不可行的(比如数据提供方采取了反爬措施)。
就第一种方法而言,一般又有以下几种接口供我们选择。
- 数据提供方提供的RSS接口。
- Web服务接口,如RESTful API。
结合实战案例2的需求,我们的数据提供方CNET提供了RSS接口,所以我们直接调用CNET提供的RSS接口就可以获取数据了。然后在读取每篇新闻具体内容这一步,因为CNET没有提供相关接口或API,这时候我们再考虑使用爬虫爬取网页再解析的方式。
总体而言,RSS和RESTful API这种方式比较稳定,不会经常变。爬虫的方式会变,但是难度不高,只要不反爬的话。
第三种方式是从第三方系统导入。与前两种方式不同的是,这种方式特指需要第三方系统配合,专门开发一个接口的情况,这种方式也比较稳定。
第四种方式,从Excel文件读取,这种在金融行业相当常见。需要注意的是,Excel文件的字段和长度很可能会超出Excel本身的限制,这时候就需要分成多份Excel文件了。其原理有点类似于分表分库。但是归根到底,Excel的结构是很稳定的。
从Word文件读取、从PDF文件读取,这两种方法是相对比较困难的,特别是从PDF读取。从目前的情况来看,虽然市面上已经有不少PDF解析服务,但是要想把PDF入库这一块做好,基本上是一件很困难并且很累的定制化体力活。
综合前面这些分析,我建议同学们,只要有选择,就选最容易的知识入库方法。相信同学们从我这门课程里也感受到了,RAG应用的形式有很多种,我们完全可以选最容易实现的那种入门,等到巩固、掌握了基础形式之后,再去挑战难度更高更复杂的方法。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了三件事情。
第一件事情是我们展示了实战案例2的成果。与实战案例1相比,对于大部分同学来说,实战案例2更实用,从而也更有动力去学习和改进。
第二件事情是我们对实战案例2所用的知识点进行拆解。实战案例2用到了如下知识点:知识入库、元数据、文本摘要、机器翻译。这些知识点也是很多RAG应用常用的知识点。
第三件事情是知识入库的方式。我们讲解了知识入库的6种方式:API、爬虫、第三方系统导入、从Excel读取、从Word读取、从PDF读取。实战案例2将使用API和爬虫这两种知识入库方式。结合我之前的项目经验,我推荐你尽量使用前四种方式入库。
思考题
前面说到,在这个实战案例中,用户提问实际就是:今天的CNET有哪些新闻?请把这些新闻摘要并翻译成中文发给我。那么如果CNET每天的新闻有很多,有上千条的新闻,那么用户提问改成什么会比较合适呢?我们的实战案例又需要添加什么步骤呢?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- ティア(Erlin Ma) 👍(1) 💬(1)
可以根据需求,只获取感兴趣的类别的文章,或者按照类别分多次获取。 同意类别内的文章,也可以按照喜好或者基于特定指标进行排序后去top##。 说到底,感觉就是信息提供方的推荐策略的反向应用。不知大家是否同意,欢迎讨论。
2024-09-18 - jfdghb 👍(0) 💬(1)
老师,这个爬虫需自己要去学吗
2024-09-26 - 石云升 👍(0) 💬(1)
根据自己的喜好,设置不同维度,然后让AI去评分,总分10分,让AI筛选出评分高于8分的文章。这块可以做的简单,也可以很复杂。
2024-09-25 - 小韩爱学习 👍(0) 💬(0)
催更+++
2024-09-18