06 动手实战:回答用户问题
你好,我是叶伟民。
上一节课,我们已经可以根据用户的提问从数据库里面检索出数据了。那么这节课,我们继续动手实战,根据这些数据去回答用户的提问。
虽然我们的例子是用RAG改造MIS系统,但今天的内容很多RAG的场景里都是适用的。好,我们直接开始吧。
从数据库查不到相关数据时的操作
我们先回到实战案例1\改造前\home\views.py 文件的 index 函数。第5行到第8行的代码,我们上一节课讲过了。这节课主要讲第10行到第13行的代码。
def index(request):
if request.method == 'POST':
用户输入 = request.POST['question']
查询参数 = 获取结构化数据查询参数(用户输入)
查询结果 = None
if 查询参数 is not None:
查询结果 = 查询(查询参数)
if 查询结果 is None:
从数据库查不到相关数据时的操作()
else:
根据查询结果回答用户输入(查询结果,用户输入)
conversation_list = 对话记录.objects.filter(已结束=False).order_by('created_time')
return render(request, "home/index.html",{"object_list":conversation_list})
先看第10行代码,它的作用是判断有没有从数据库找到相关数据。如果没有找到的话,我们将通过第11行代码,调用从数据库查不到相关数据时的操作函数。
这个函数实现在 rag.py 文件。我们打开实战案例1\改造前\home\rag.py 文件,添加以下代码。
def 从数据库查不到相关数据时的操作():
record = 对话记录()
record.role = "assistant"
record.处理后content = "抱歉,数据库里面没有你需要的信息。"
record.不带入大模型对话中 = False
record.save()
这段代码很简单,就是直接创建一条AI角色的对话记录。不同的是,它实际上并没有调用大模型,而是我们直接指定了这条对话记录的内容,也就是第4行代码。
根据检索结果回答用户输入
如果我们从数据库检索到结果,那么将调用根据检索结果回答用户输入函数。
这个函数实现在 rag.py 文件。我们打开实战案例1\改造前\home\rag.py 文件,添加以下代码。
def 根据查询结果回答用户输入(查询结果,用户输入):
当前messages = 构造查询结果用的messages(查询结果,用户输入)
之前的messages = 对话记录.objects.filter(已结束=False).order_by('created_time')
全部messages = 构造全部messages(之前的messages,当前messages)
对话模式(全部messages)
我们逐行来看一下这段代码做了哪些工作。第1行接受查询结果和用户输入。然后第2行根据查询结果和用户输入构造messages。第3行从对话记录里面获取前面的对话记录构造messages。
接着第4行根据之前的messages和当前的messsages,构造全部messages。最后,在第5行把全部messages传给对话模式函数。
我们首先把第2行用到的函数加到 rag.py 文件的末尾。
def 构造查询结果用的messages(查询结果,用户输入):
return [{"role": "user", "content": f"""
您已经知道以下信息:
{将查询结果转为字符串(查询结果)}
请根据以上您所知道的信息回答用户的问题,注意,请简单和直接的回答,不要返回其他内容,不要提“根据您所提供的信息”之类的话。
:{用户输入}
"""}]
我们看到第5行出现了一个新函数——将查询结果转为字符串。这个函数有什么用呢?解决了什么问题呢?我们继续往下看。
将查询结果转为字符串
从数据库里面查询出来的结果,要么是json格式要么是字典格式,我们需要将它转换为大模型更容易识别的人类语言。这就是刚才这个新函数的意义了。
这个函数会将json格式的查询结果转换为以下格式。
这个函数的具体代码如下。我们把它加到 rag.py 文件末尾。
from django.core import serializers
def 将查询结果转为字符串(查询结果):
json_str = serializers.serialize("json", list(查询结果))
return_str = ""
data = json.loads(json_str)
for current in data:
for key, value in current['fields'].items():
return_str += f"{key}:{value}\n"
return return_str
其中第7行到第9行就是将json数据转换为人类语言的代码。其他代码在不同的MIS系统会不一样,并且与RAG无关,所以我们暂时可以忽略。
构造全部messages
下一步我们来构造全部messages函数,我们把它加到 rag.py 文件末尾。
def 构造全部messages(之前的messages,当前messages):
if 之前的messages is not None and len(之前的messages) >= 2:
适配大模型的messages = []
for current in list(之前的messages)[:-1]: # 使用-1是为了去掉当前messages
适配大模型的messages.append({"role":current.role, "content":current.content})
return [*适配大模型的messages,*当前messages]
else:
return 当前messages
这里有两个地方需要你留意。首先通过第2行判断是否有之前的messages,之所以要大于等于2,是因为从数据库里面读到的messages会包含当前message。
如果有之前的messages,以上函数将通过第5行提取其中的role和content属性,整合成适配大模型的messages。
保存对话记录
到目前为止,我们还没有把对话记录保存到数据库里面,我们这就来完成这项工作。
我们先在 rag.py 文件末尾加上保存对话记录函数。
def 保存对话记录(role,content,处理后content,提交给大模型的playload,不带入大模型对话中):
record = 对话记录()
record.role = role
if content is not None:
record.content = content
if 处理后content is not None:
record.处理后content = 处理后content
if 提交给大模型的playload is not None:
record.提交给大模型的playload = 提交给大模型的playload
record.save()
然后在对话模式函数里面添加调用代码。第19行和第20行就是调用代码。
def 对话模式(messages):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-lite-8k?access_token=" + get_access_token()
json_obj = {
"messages": messages,
}
playload= json.dumps(json_obj)
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=playload)
json_result = json.loads(response.text)
if "error_code" in json_result:
return json_result["error_msg"] + ":" + playload
else:
处理后结果 = 对AI结果进一步处理(json_result["result"])
保存对话记录(messages[-1]["role"],messages[-1]["content"])
保存对话记录("assistant",处理后结果)
return 处理后结果
运行起来看看效果
好了,现在一切最基本的代码都具备了,我们先运行起来看看效果。
我们还是先按照第1节所讲的步骤把MIS系统运行起来。不过我们会遇到以下错误。

这时候我们需要以下命令安装requests包。
然后我们继续输入以下命令来更新数据库结构。也就是第4节课新加的对话记录表。
如果一切顺利,我们应该会看到如下截图里面的提示。

然后输入以下命令运行起来。
然后打开浏览器,跳转到 http://127.0.0.1:8000/。
输入以下问题。
我们会看到类似后面的回答。
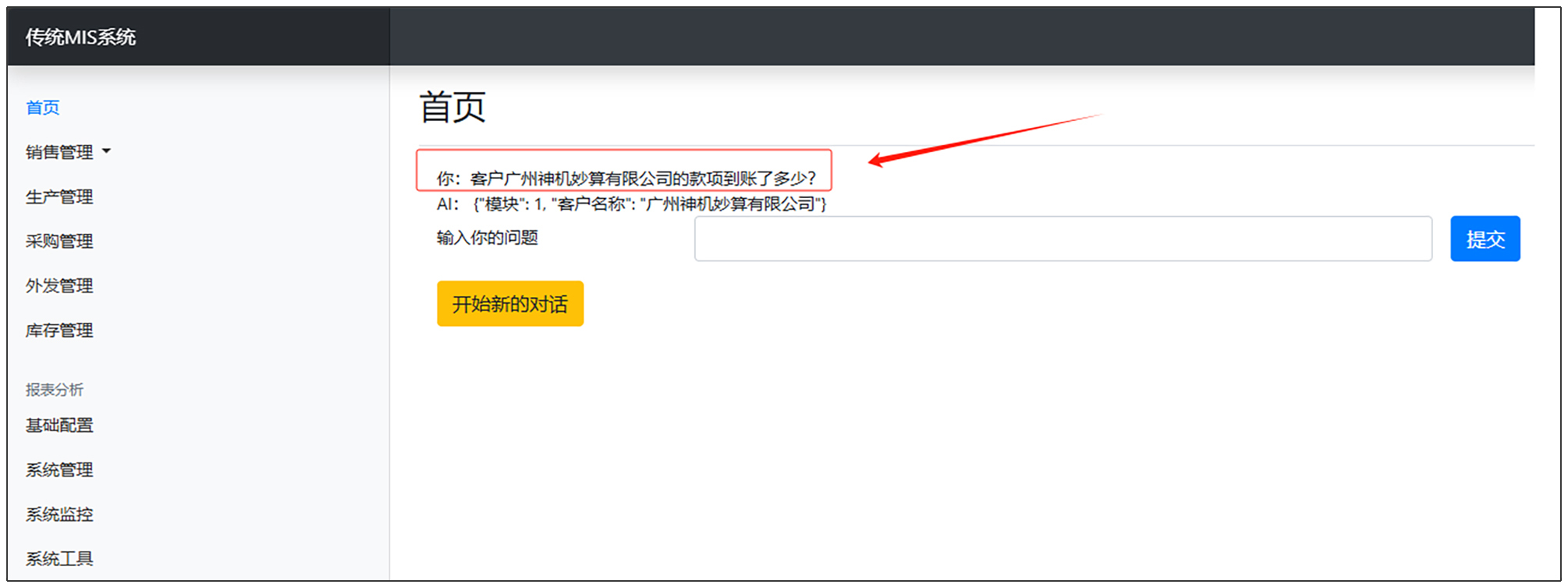
你: 请根据用户的输入返回json格式结果,除此之外不要返回其他内容。注意,模块部分请按以下选项返回对应序号: 1. 销售对账 2. 报价单 3. 销售订单 4. 送货单 5. 退货单 6. 其他 示例1: 用户:客户北京极客邦有限公司的款项到账了多少? 系统: {'模块':1,'客户名称':'北京极客邦有限公司'} 示例2: 用户:你好 系统: {'模块':6,'其他数据',None} 示例3: 用户:最近一年你过得如何? 系统: {'模块':6,'其他数据',None} 用户:客户广州神机妙算有限公司的款项到账了多少? 系统:
AI: {"模块": 1, "客户名称": "广州神机妙算有限公司"}
显然,这并不是我们想要的结果。为什么呢?主要存在两个问题。
- 第1行应该只显示用户的发问,而不应该把所有细节都展示出来。
- 第2行AI的回答不应该展现给用户。
那么如何解决这个问题呢?针对第1点,我们应该把用户提问保存在对话记录的一个字段,然后把具体细节保存在另一个字段。具体处理方式详见下一节。
针对第2点,我们需要用一个字段来表示这条记录是否需要出现在用户和大模型对话中。
只带入人机对话
我们把用户提问保存在对话记录表的 content 字段,把细节保存在对话记录表的处理后content 字段。
因此我们需要修改对话模式函数。
def 对话模式(messages,用户输入):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-lite-8k?access_token=" + get_access_token()
json_obj = {
"messages": messages,
}
playload= json.dumps(json_obj)
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=playload)
json_result = json.loads(response.text)
if "error_code" in json_result:
return json_result["error_msg"] + ":" + playload
else:
处理后结果 = 对AI结果进一步处理(json_result["result"])
保存对话记录(messages[-1]["role"],用户输入,messages[-1]["content"],None,False)
保存对话记录("assistant",json_result["result"],处理后结果,None,False)
return 处理后结果
我们在第1行多添加了一个传入参数。然后在第19行将这个传入参数保存在对话记录表的 content 字段。
然后我们还要修改调用对话模式函数的代码。
def 根据查询结果回答用户输入(查询结果,用户输入):
当前messages = 构造查询结果用的messages(查询结果,用户输入)
之前的messages = 对话记录.objects.filter(已结束=False,不带入大模型对话中 = False).order_by('created_time')
全部messages = 构造全部messages(之前的messages,当前messages)
对话模式(全部messages,用户输入)
还需要修改以下函数里面的代码。
def 获取结构化数据查询参数(用户输入):
之前的用户输入 = 获取之前的用户输入()
重试总次数 = 2
当前重试次数 = 0
while 当前重试次数 <= 重试总次数:
try:
结构化数据 = 对话模式(构造解析用户输入并返回结构化数据用的messages(之前的用户输入,用户输入),用户输入)
查询参数 = json.loads(结构化数据)
return 查询参数
except:
当前重试次数 += 1
return None
我们再运行一遍,然后提问,就会得到以下结果。
我们发现,第1个问题解决了。接下来我们去解决第2个问题。
页面隐藏部分对话
我们继续修改对话模式函数。
def 对话模式(messages,用户输入,原文不带入大模型对话中,结果不带入大模型对话中):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-lite-8k?access_token=" + get_access_token()
json_obj = {
"messages": messages,
}
playload = json.dumps(json_obj)
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=playload)
json_result = json.loads(response.text)
if "error_code" in json_result:
return json_result["error_msg"] + ":" + playload
else:
处理后结果 = 对AI结果进一步处理(json_result["result"])
保存对话记录(messages[-1]["role"],用户输入,messages[-1]["content"],playload,原文不带入大模型对话中)
保存对话记录("assistant",json_result["result"],处理后结果,None,结果不带入大模型对话中)
return 处理后结果
这次我们多传了两个参数。一个是原文不带入大模型对话中,用于用户提问。另一个是结果不带入大模型对话中,用于AI的回答。
然后我们更新一下调用对话模式的函数。
def 获取结构化数据查询参数(用户输入):
之前的用户输入 = 获取之前的用户输入()
重试总次数 = 2
当前重试次数 = 0
while 当前重试次数 <= 重试总次数:
try:
结构化数据 = 对话模式(构造解析用户输入并返回结构化数据用的messages(之前的用户输入,用户输入),用户输入,原文不带入大模型对话中=False,结果不带入大模型对话中=True)
查询参数 = json.loads(结构化数据)
return 查询参数
except:
当前重试次数 += 1
return None
我们在获取结构化数据查询参数的时候,需要将原文不带入大模型对话中设置为False,将结果不带入大模型对话中设置为True,也就是第7行代码。
然后是根据查询结果回答用户输入函数。同样地,我们将原文不带入大模型对话中设置为True,将结果不带入大模型对话中设置为False,也就是第5行代码。
def 根据查询结果回答用户输入(查询结果,用户输入):
当前messages = 构造查询结果用的messages(查询结果,用户输入)
之前的messages = 对话记录.objects.filter(已结束=False,不带入大模型对话中 = False).order_by('created_time')
全部messages = 构造全部messages(之前的messages,当前messages)
对话模式(全部messages,None,原文不带入大模型对话中=True,结果不带入大模型对话中=False)
最后别忘了更新一下实战案例1\改造前\templates\home\index.html文件。变化就添加了第2行代码。
{% for current_obj in object_list %}
{% if current_obj.不带入大模型对话中 is False%}
<div>
{% if current_obj.role == "user" %}
你:{{current_obj.content}}
{% else %}
AI:{{current_obj.处理后content}}
{% endif %}
</div>
{% endif %}
{% endfor %}
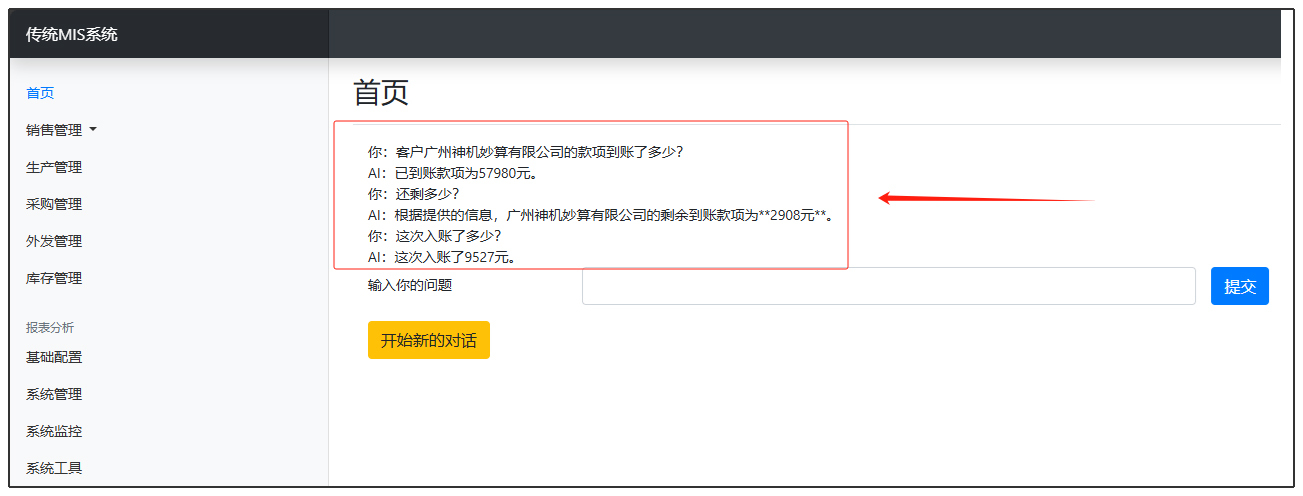
现在我们重新运行一下,点击“开始新的对话”,然后重新发问。如果你看到类似后面这样的返回结果,就表明一切顺利,我们的改造终于完成了!
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了两件事情。
第一件事情是从数据库查不到相关数据时如何处理。这时候我们需要明确告诉用户:抱歉,数据库里面没有你需要的信息。
第二件事情是根据查询结果回答用户输入。具体包括将查询结果转为字符串、构造全部messages、保存对话记录、只带入人机对话、页面隐藏部分对话。
其实今天我们得到的系统只是个demo,如果要支持更多的用例、支持更多的模块,我们需要像上一节课说的,添加更多选项序号、示例还有提示。不过用户使用我们系统的时候,我们并没有在旁边看着,那我们如何知道应该添加哪些内容?又如何知道怎么改进?这个问题我们下节课再讨论。
思考题
如果有多个用户使用这个系统,那么如何判断哪条对话记录属于哪个用户?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- 秋天 👍(2) 💬(2)
AI:抱歉,数据库里面没有你需要的信息。 AI:抱歉,数据库里面没有你需要的信息。 AI:抱歉,数据库里面没有你需要的信息。 AI:抱歉,数据库里面没有你需要的信息。 AI:抱歉,数据库里面没有你需要的信息。 AI:抱歉,数据库里面没有你需要的信息。 AI:抱歉,数据库里面没有你需要的信息。 一直没有数据
2024-10-25