04 动手实战:UI 实现和国产免费大模型接入
你好,我是叶伟民。
前面几节课,我们已经对RAG的基础概念有了一定的了解。从这节课开始,我们就来动手实战,使用RAG来改造传统的MIS系统。
学完这节课,同学们将掌握所有RAG应用所必需的基础——接入大模型。我们先从UI和接入大模型开始。
UI代码
首先,我们来实现UI代码。
我们在第 1 节课里提过,使用RAG改造传统MIS系统,最终界面应该是后面图里这样。
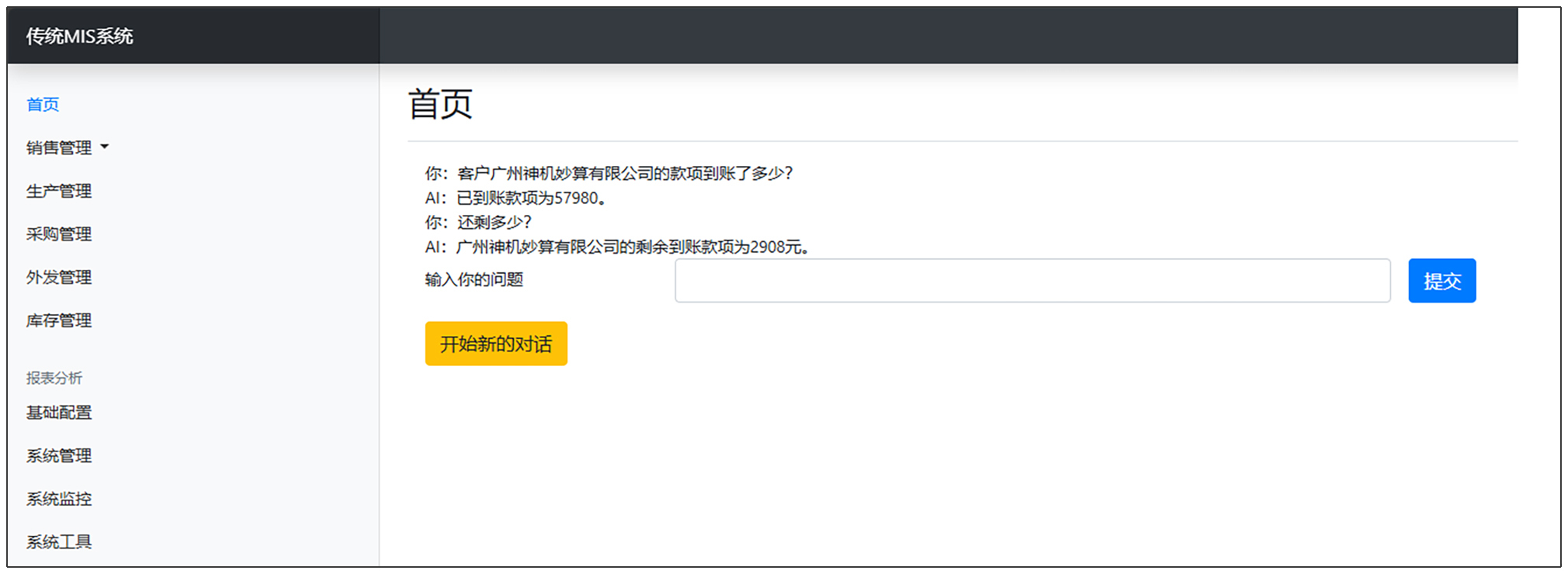
为了方便用户,一般来说我们会把这个UI放在首页,让用户一打开应用,就能看到我们这个UI。
我们看到,我们把传统MIS系统的所有查询、新增、修改、删除页面都整合成上图这么一个页面。所以RAG应用UI部分相对其他软件应用简单很多,代码也少很多。
UI主要包括三部分:
- 对话记录
- 发问
- 开始新的对话。
我们先从对话记录部分开始。
对话记录部分
对话记录部分是指下图中的红框标出的部分。
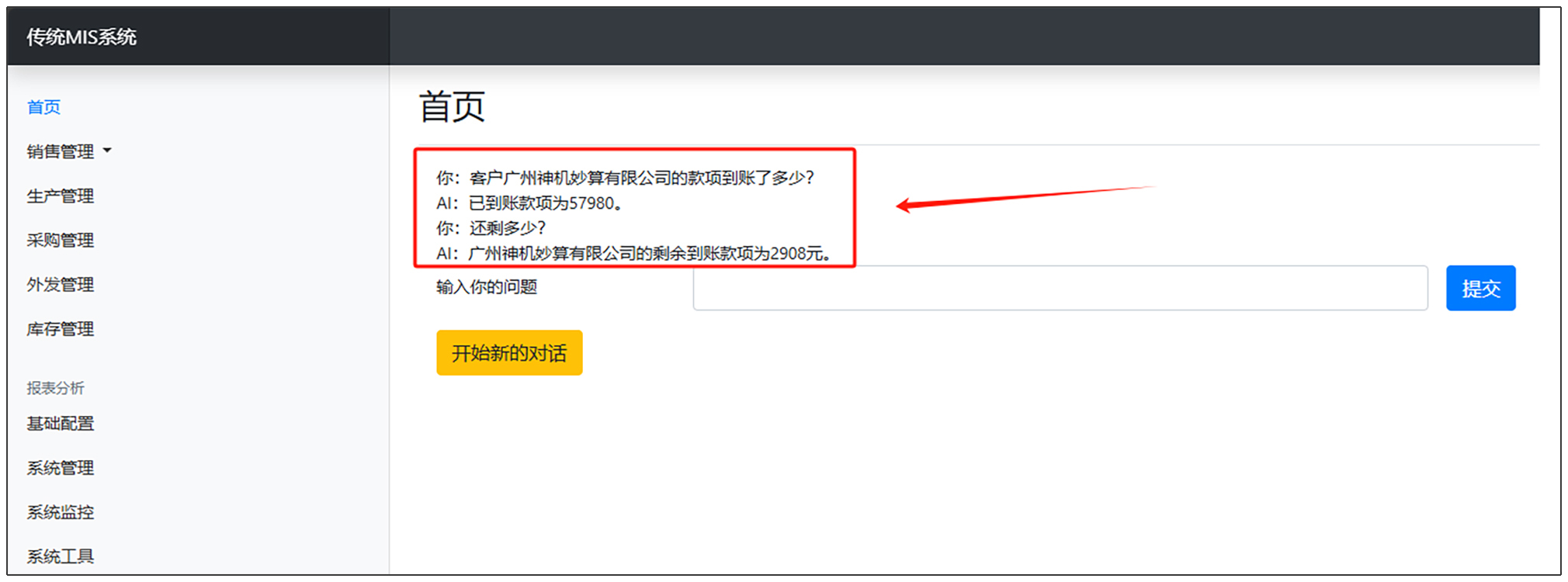
我们打开在第 1 节课使用RAG改造传统MIS系统成果展示、切入点下载的代码,也就是打开实战案例1\改造前\templates\home\index.html文件。
然后在 {% block main_content%} 和 {% endblock %} 中间插入对话记录部分的代码。
<div class="d-flex justify-content-between flex-wrap flex-md-nowrap align-items-center pt-3 pb-2 mb-3 border-bottom">
<h3 class="h3">首页</h3>
</div>
<div class="col-sm-10">
{% for current_obj in object_list %}
<div>
{% if current_obj.role == "user" %}
你:{{current_obj.content}}
{% else %}
AI:{{current_obj.处理后content}}
{% endif %}
</div>
{% endfor %}
</div>
我来带你梳理一下这段代码的重点内容。第6行代码是遍历对话记录里面的每一条。
然后第9行代码判断当前这条对话记录的角色是否为用户(user)。如果是,则以“你”这个称谓开头。有些UI追求美观度的话,还会把这一行靠右显示。
然后第11行代码是指如果当前这条对话记录的角色不是用户,也就是AI的话。则以 “AI” 这个称谓开头。同样,为了美观,有些UI会把这一行靠左显示。
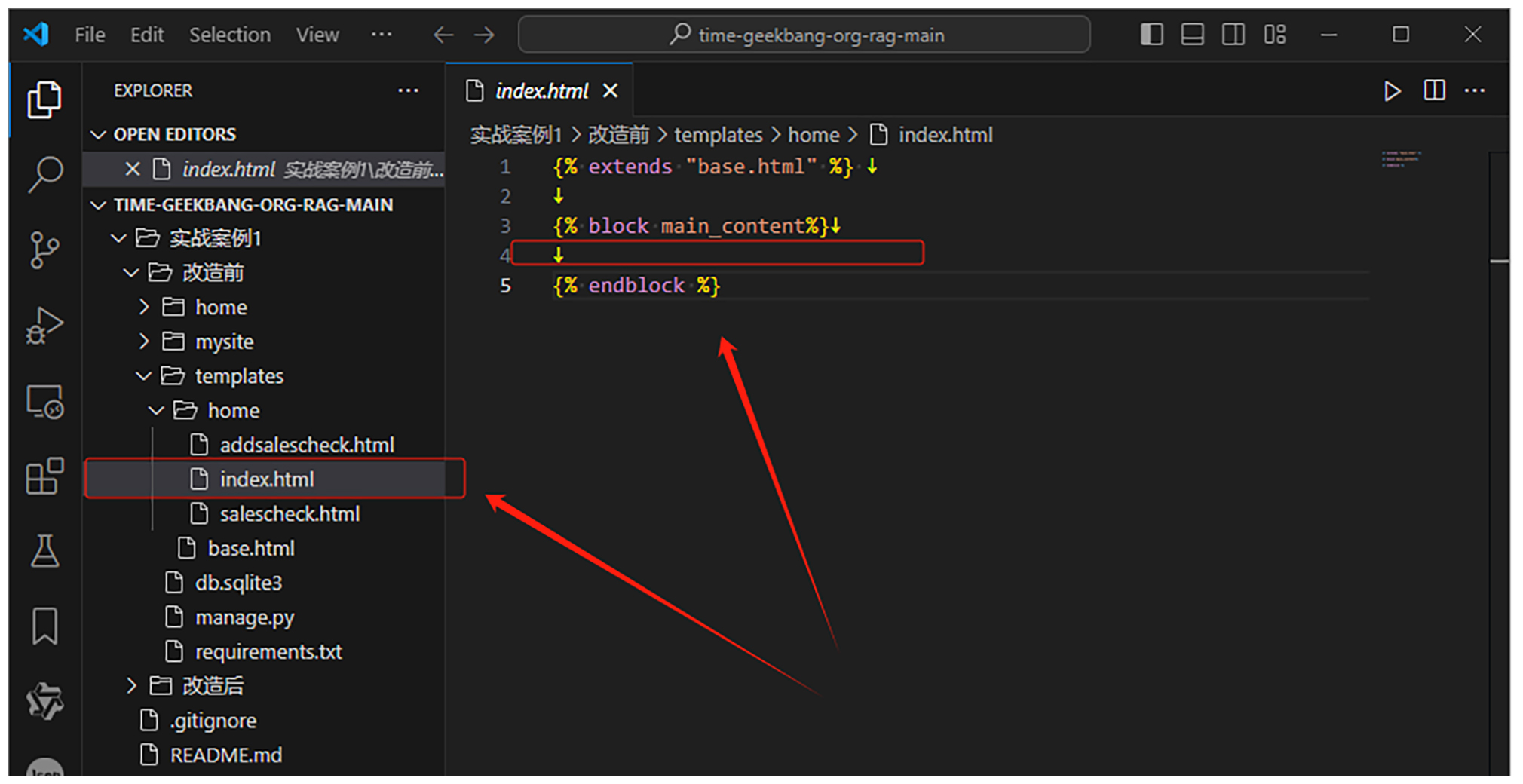
那么第6行代码的object_list从何而来?从数据库里面查询得出。对应的是后面这段后台代码。我们打开文件实战案例1\改造前\home\views.py 找到如下位置。
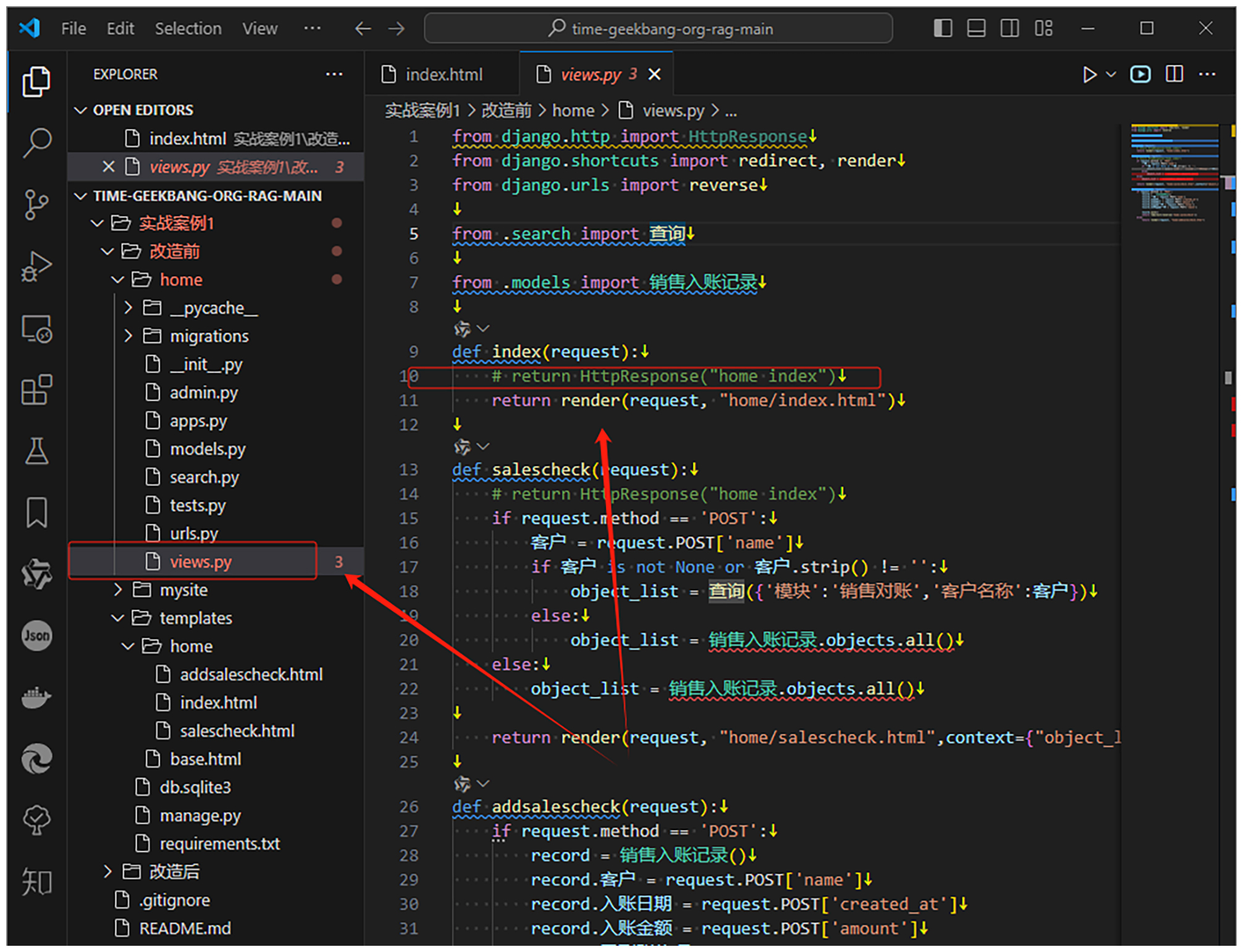
之后,我们在 def index(request): 和 return render(request, “home/index.html”) 之间插入以下代码。
conversation_list = 对话记录.objects.filter(已结束=False).order_by('created_time')
return render(request, "home/index.html",{"object_list":conversation_list})
第1行代码是从数据库的对话记录表里面获取已结束字段为False的记录,并且按时间顺序返回。然后通过第2行代码将这些记录传递给页面。
因为要导入对话记录表,所以我们需要在实战案例1\改造前\home\views.py文件的顶部加入后面这段代码。它的作用是导入数据库模型,也就是在第7行“销售入账记录”部分加入对话记录。
加入之后效果如下。
然后我们打开实战案例1\改造前\home\models.py 文件。在尾部添加以下代码。
class 对话记录(models.Model):
id = models.IntegerField(
primary_key = True,
editable = False)
role = models.TextField()
content = models.TextField(null=True)
处理后content = models.TextField(null=True)
提交给大模型的playload = models.TextField(null=True)
不带入大模型对话中 = models.BooleanField(default=False)
已结束 = models.BooleanField(default=False)
created_time = models.DateTimeField(auto_now_add=True)
lastmodified_time = models.DateTimeField(auto_now=True)
第一个字段(第2行到第4行代码)是记录的id,数据类型为整型,由数据库自动生成。
第二、三个字段(对应第6、7行代码),分别表示对话模式的角色和内容,这个我们在第2节课的基础概念里讲过。
第四个字段(第8行代码)代表处理后的内容,我们后面的课程里再展开。
第五个字段(第9行代码)对应这节课后面对话模式代码中的playload,意思是在请求中发送到服务器的数据。
第六个字段(第10行代码),用于标记这条对话记录是否要带入大模型对话中,同样会在后续课程里展开。
第七个字段(第11行代码)用于标记这条对话记录是否已经结束。当我们点击开始新的对话按钮之后,会将前面所有对话记录的这个字段值设置为True,以表示对话已经结束。
第八、第九个字段(第13、14行代码)都和时间有关,前者是对话记录发生的时间,我们可以根据它排序显示对话记录,后者是对话记录更新的时间。这两个字段具体的值都由系统自动插入的,不需要我们操心。
发问部分
发问部分是指下图中的红色部分。
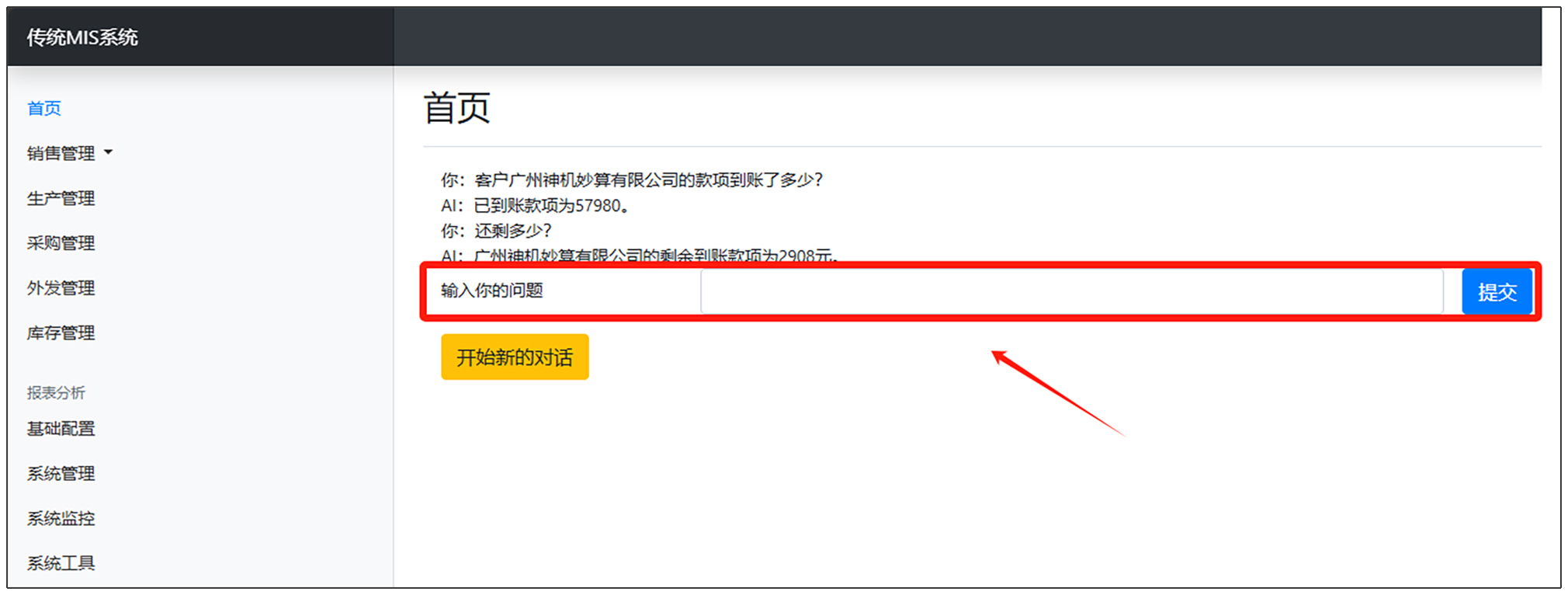
我们在刚才实战案例1\改造前\templates\home\index.html 文件对话部分最后的一个div之前,加入发问部分的代码。
<form method="POST">
{% csrf_token %}
<div class="form-group row">
<label for="inputEmail3" class="col-sm-2 col-form-label">输入你的问题</label>
<div class="col-sm-6">
<input type="input" class="form-control" name="question">
</div>
<button type="submit" class="btn btn-primary">提交</button>
</div>
</form>
这段代码的第1、6、8行需要你特别留意,这三行构成了发问部分的核心。
首先第1行是一个HTML表单。这个表单以POST的形式提交。然后第6行是一个输入框。而第8行是一个HTML提交按钮。
其他代码用于丰富表单和改善交互友好性。比如说,你可以添加校验输入框是否非空的代码,也可以添加通过ajax提交表单并显示等待进度条的代码。
当点击“提交”按钮之后,将会调用后台的这段代码。我们回到文件实战案例1\改造前\home\views.py在def index(request): 和 conversation_list 中间添加第2行到第14行代码。
def index(request):
if request.method == 'POST':
用户输入 = request.POST['question']
查询参数 = 获取结构化数据查询参数(用户输入)
查询结果 = None
if 查询参数 is not None:
查询结果 = 查询(查询参数)
if 查询结果 is None:
从数据库查不到相关数据时的操作()
else:
根据查询结果回答用户输入(查询结果,用户输入)
conversation_list = 对话记录.objects.filter(已结束=False).order_by('created_time')
return render(request, "home/index.html",{"object_list":conversation_list})
这段代码也很好理解,我们来梳理一下主要的运行逻辑。首先第2行代码用来判断是否是表单提交。如果是,则通过第3行代码获取用户的输入,也就是用户的发问。
第5行代码获取查询参数,第8行代码则会根据查询参数去数据库查询数据,也就是我们前面所说的知识。
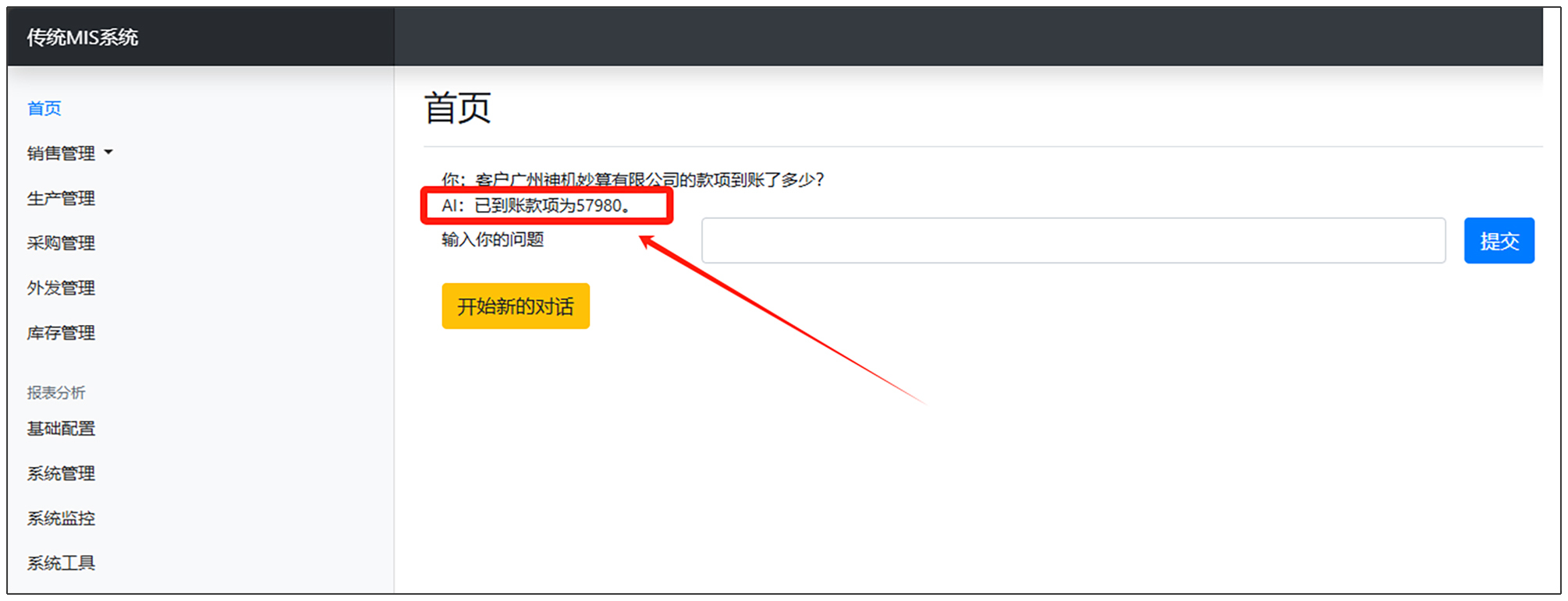
如果能够查询到数据,我们将调用第13行代码根据查询结果回答用户输入。具体结果如下图所示。
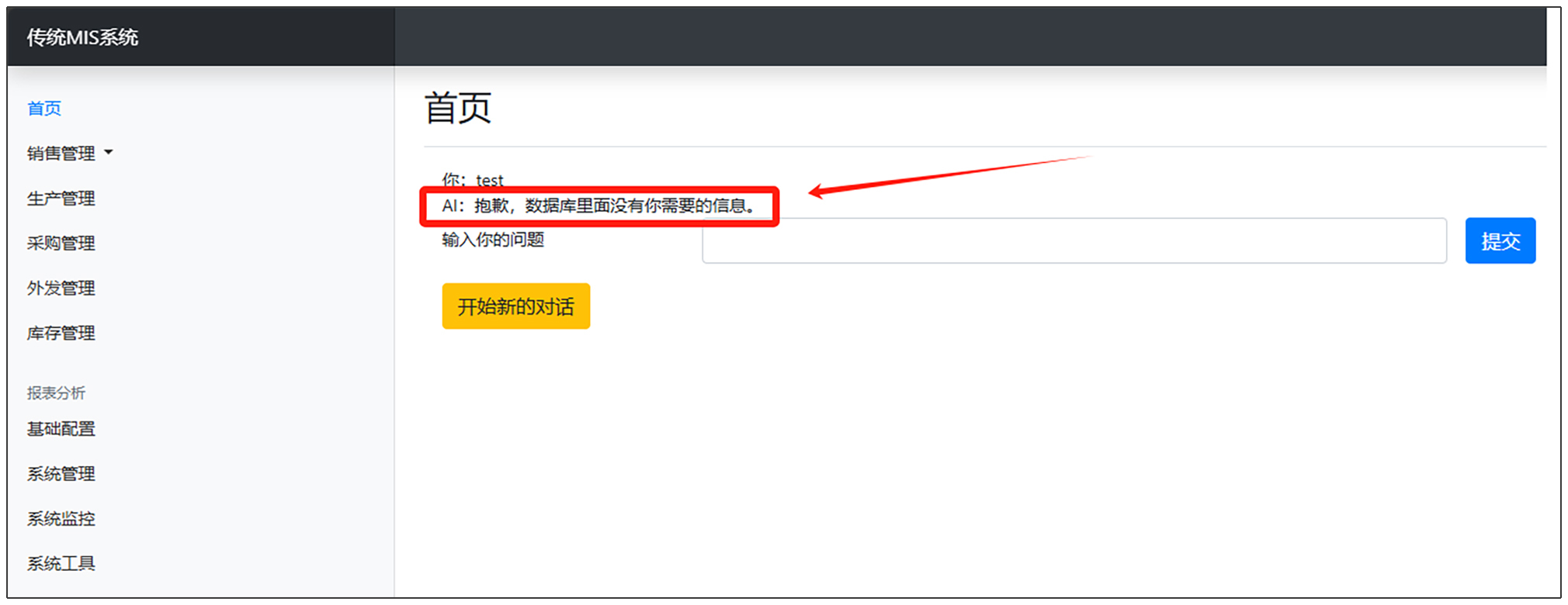
如果没有查询到相关数据,则调用第11行代码。具体结果如下图所示。
注意,其中获取结构化数据查询参数、从数据库查不到相关数据时的操作、根据查询结果回答用户输入这几个函数目前还没有添加,我们会在后续章节中添加。
开始新的对话部分
开始新的对话部分是指下图中的红色部分。
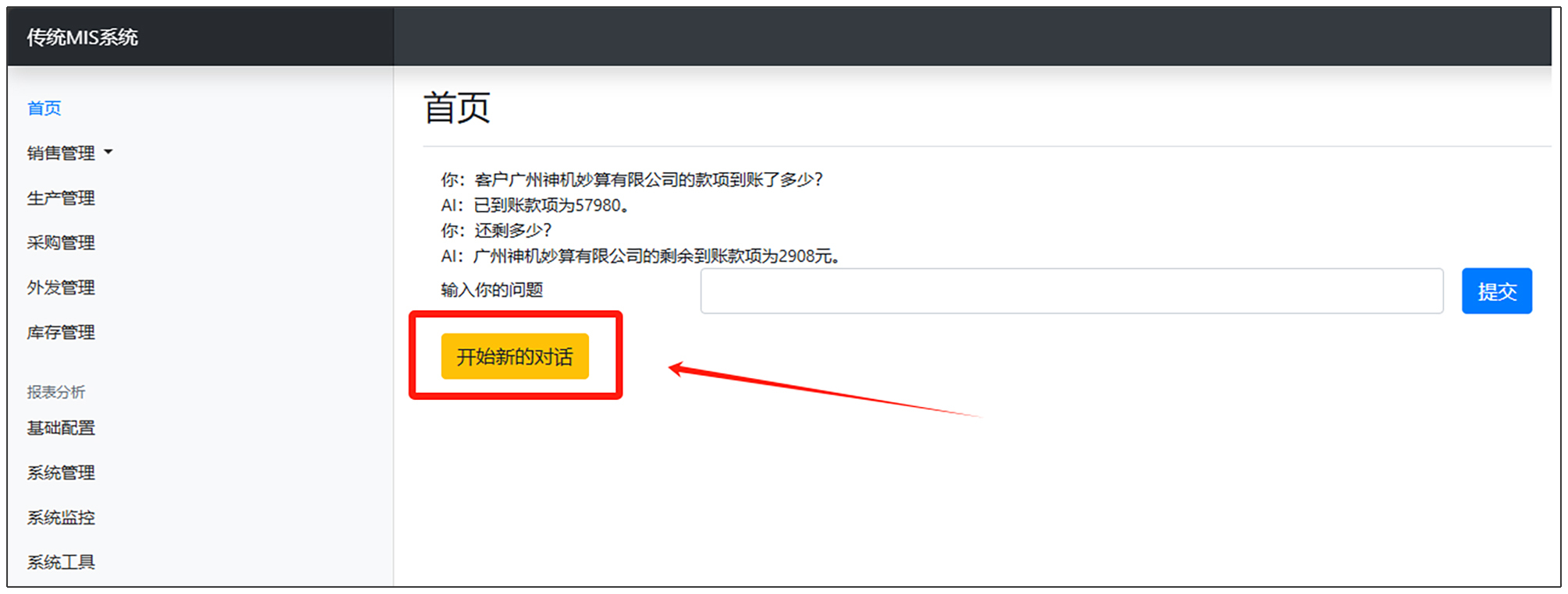
我们在发问部分代码后面,继续添加代码,开始新的对话部分。
我们可以看到,这是一个链接,点击这个链接将会调用以下后台代码。我们回到文件实战案例1\改造前\home\views.py在def index(request): 前面添加它。
def newtalk(request):
未结束的对话 = 对话记录.objects.filter(已结束=False)
for current in 未结束的对话:
current.已结束 = True
对话记录.objects.bulk_update(未结束的对话, ['已结束'])
return redirect(reverse('home:index'))
第2行代码会从数据库里面检索出未结束的对话记录。然后第3行代码遍历这些对话记录。第4行代码将对话记录的已结束字段的值设置为True,也就是说标记为结束。第5行代码用于将更改内容批量保存进数据库。
一切工作完成后,通过第6行代码即可跳转回首页。这时候我们会看到页面上没有了对话记录。
注意,我们还需要打开实战案例1\改造后\home\urls.py 文件,把newtalk注册进去。
from django.urls import path
from . import views
app_name = "home"
urlpatterns = [
path("", views.index, name="index"),
path("salescheck", views.salescheck, name="salescheck"),
path("addsalescheck", views.addsalescheck, name="addsalescheck"),
path("newtalk", views.newtalk, name="newtalk"),
]
其中第10行就是我们注册newtalk的代码。请注意这个地方不同的MIS系统不一样,而且与RAG无关,同学们可以不用关注它。
UI部分就讲到这里了,完整HTML最终代码请参见这里,对应的后台代码请参见这里。你可能会发现,最终代码和上述代码有点不一样,会多了一些代码,多出来的这部分代码我们会在后续章节中提到。
申请大模型
然后我们需要接入大模型。因为最著名的OpenAI大模型申请比较麻烦,不利于同学们入门。所以我们使用百度ERNIE-Lite-8K大模型。
选择这个模型主要考虑了这三点。
- 完全免费,同学们可以随便玩。
- 性能已经足够入门用了。
- 调用格式兼容OpenAI和很多大模型,所以只我们需要改极少量代码就可以切换到其他大模型。
同学们可以直接去 https://qianfan.cloud.baidu.com/ 申请百度ERNIE-Lite-8K大模型。因为百度的文档很完善,客服也很给力,按照上面的链接很容易就可以完成申请。
不过需要注意的是,百度更新很快,以上链接可能会失效,这时候我们可以向百度客服咨询。
调用大模型
申请以后,就到了调用大模型的环节。我们需要先获取access token,具体代码如下。我们在 实战案例1\改造前\home目录下新增 rag.py 文件,然后添加以下代码。
import json
import requests
def get_access_token():
ernie_client_id = xxxx # 替换为你的client_id
ernie_client_secret = xxxx # 替换为你的client_secret
url = f"https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={ernie_client_id}&client_secret={ernie_client_secret}"
playload= json.dumps("")
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=playload)
return response.json().get("access_token")
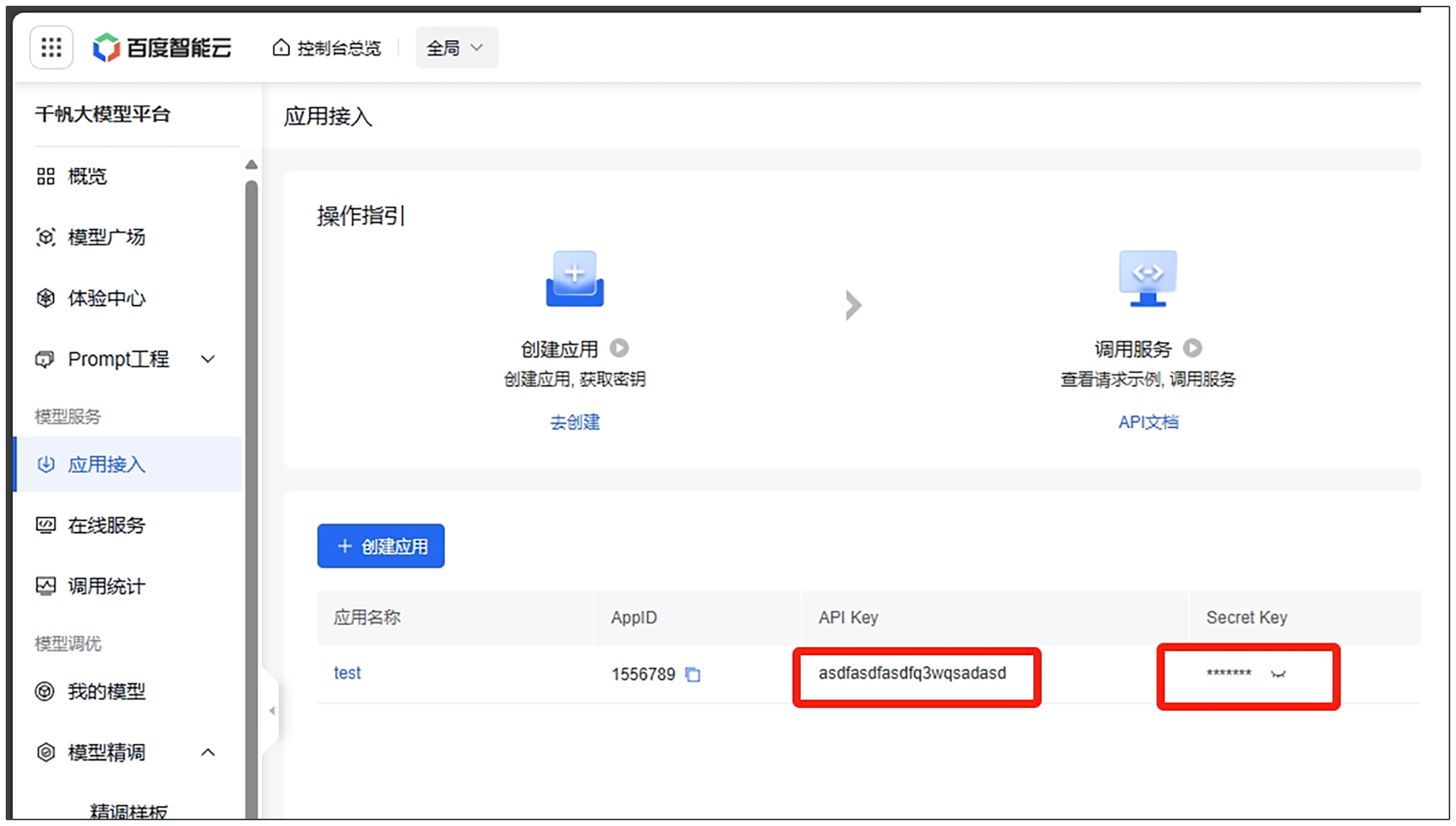
你需要把上面代码中的ernie_client_id和ernie_client_secret替换为你自己的ernie_client_id和ernie_client_secret。你可以在这里找到它们。
其中 ernie_client_id为下图中的API Key,ernie_client_secret为下图中的Secret Key。
获取完access token之后,我们就可以调用大模型进行问答,也就是进入第2节课所讲的对话模式了。我们继续在实战案例1\改造前\home\rag.py 文件的尾部添加以下代码。
def 对话模式(messages):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-lite-8k?access_token=" + get_access_token()
json_obj = {
"messages": messages,
}
playload= json.dumps(json_obj)
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=playload)
json_result = json.loads(response.text)
return json_result["result"]
这两个函数是百度大模型所特有的,不同大模型的代码不一样,换一个大模型可能就要改,所以我们就不铺开描述了。我们只需要知道,对话模式函数用于接收我们在第2节讲过的messages参数。
以上两个函数的最终代码可以在这里看到。
细心的同学可能会发现,这里和后续章节的代码很多变量和函数都用了中文。这么做只是为了让你更容易理解,学习起来更轻松。在实际工作中建议还是采用英文,以避免出现奇奇怪怪的问题。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了两件事情。
第一件事情是介绍UI部分。UI部分包括:对话记录、发问、开始新的对话。第二件事情是如何申请和调用大模型。这是所有RAG应用都要做的第一步。虽然代码看起来并不复杂,但如果你从未接触,课后还是需要花一些精力仔细研读和动手练习的,这样学习效果会更好。
下一节我们将实现如何根据用户发问查询数据,也就是添加前面发问部分提到的获取结构化数据查询参数代码。
思考题
前面“调用大模型”一节中的ernie_client_id和ernie_client_secret是十分重要的,如果泄露出去会带来很大的麻烦,甚至带来金钱损失。
所以在实际工作中这两个参数的具体值不应该直接写在代码里面,那么应该如何处理呢?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- Billy火炎焱燚(不羁的风) 👍(2) 💬(0)
为什么不选择OpenAI? 首先,我是一名负责AI应用落地的工程师,不是科学家。当项目出现问题,半夜叫醒是工程师,而不是科学家。科学家只考虑性能,工程师考虑的是如何不被半夜叫醒,即使半夜被叫醒,能否快速解决问题。以OpenAI的客服能力,做不到这点。这点国内大厂做得十分好。 其次,如果做垂直应用,不需要去到OpenAI那么强的性能。这方面傅盛老师讲得十分到位,大家可以关注傅盛老师的视频号。另外如果大家需要选本地的大模型,我推荐傅盛老师的Orion-14B LLM,因为我在遇到问题的时候确实能从配套的微信群得到技术支持。同时傅盛老师做为上市公司的CEO,都能十分快的回答我。在客户支持方面,OpenAI距离国内厂商实在是差得太远。
2024-09-15 - grok 👍(3) 💬(2)
请教各位大佬:对于中文问答,到底哪家LLM最强?我只知道去lmsys leaderboard, 有个下拉列表可选Chinese Prompts, 看排名. 其他有更好的榜单吗?
2024-09-09 - 张申傲 👍(2) 💬(2)
第4讲打卡~ 思考题:诸如api_key、token这类敏感数据,可以考虑写入环境变量中,或者放到内网的分布式配置中心中。
2024-09-12 - Geek_fbf3a3 👍(0) 💬(1)
课后作业:环境变量
2024-11-06 - overland 👍(0) 💬(2)
老师,这个百度模型是需要收费吧,是调用公网的吧?想请教下,像我们做项目产品很多是必须私有化的,私有化模型怎么使用这块有讲解内容吗?谢谢老师
2024-09-29 - Wynnja Woo 👍(0) 💬(1)
对于以下代码,请问为什么获取结构化数据需要用到之前用户的输入? def 获取结构化数据查询参数(用户输入): 之前的用户输入 = 获取之前的用户输入() 重试总次数 = 2 当前重试次数 = 0 while 当前重试次数 <= 重试总次数: try: 结构化数据 = 对话模式(构造解析用户输入并返回结构化数据用的messages(之前的用户输入,用户输入),用户输入,原文不带入大模型对话中=False,结果不带入大模型对话中=True) 查询参数 = json.loads(结构化数据) return 查询参数 except: 当前重试次数 += 1 return None
2024-09-14 - Wynnja Woo 👍(0) 💬(1)
代码运行后两个问题:1.查询结果AI:抱歉,数据库里面没有你需要的信息。2.销售管理 / 销售对账 / 添加入账记录 直崩溃
2024-09-13 - 非洲黑猴子 👍(1) 💬(0)
没用过 Django, 一开始没实操出来, 其实还有一步: 修改代码之后, 申请大模型之前还要在命令行执行一次 `python manage.py makemigrations` 命令再刷新页面, 才能看到页面变化
2024-11-17 - 亚林 👍(0) 💬(0)
配置中心。与大模型无关,这是业务系统架构的事
2025-02-14