02 对话模式:构建RAG应用的核心密码之一
你好,我是叶伟民。
上一节课我们看到,使用RAG改造之后的MIS系统,从以前的通过增删改查界面与数据交互变成了通过一问一答的对话模式交互。是的,所有RAG应用本质上都是通过对话模式交互的,即使少数看起来不是对话模式的RAG应用(例如后面几节提到的返回结构化数据的应用),其底层也是通过对话模式交互的。
今天我们就来深入探索上一节课的基础对话模式,为后面的实现环节打好基础。
对话模式以及相关概念
对话模式顾名思义,就是两个角色进行对话。体现在RAG里面,就是用户与AI进行对话。例如:
用户、AI与系统
在RAG里面,以上例子中的用户一般称为user(就是用户的英文),但是AI一般称为 assistant(助理的英文)。
比较特殊的是,从ChatGPT(GPT3.5)开始,OpenAI新增了一个角色——system(系统的英文),这个角色有助于设置助理的行为。你可以在system角色里面,描述助理在整个对话过程中应该如何表现。于是如果你使用OpenAI的大模型,上述用例就会变成这样:
但有两点需要我们注意。第一,系统消息是可选的。第二,目前除了OpenAI之外,很多大模型都不支持系统这一角色。因此我们课程里的对话模式也不会考虑系统角色。
记忆
正如人类之间的对话不止一个来回,对话模式也是如此。例如以上用例可以扩展为:
我们可以发现,在用户第二次提问时,用户并没有提到“客户A”,也没有提到“款项”和“到账”。但是AI能够正确判断出用户问的是“客户A”还剩多少“款项”没“到账”。那是因为AI根据前面的对话判断出来的,这里前面的对话就叫记忆(memory)。
正如人会遗忘,AI的记忆也是有上限的,不同的大模型甚至同一个大模型在不同版本所支持的记忆上限是不同的,但是有一点是肯定的,就是记忆是有上限的,区别只是上限有多高而已。就像天才和普通人一样,都是会遗忘,只不过天才能够记住的东西更多而已。
RAG
如何解决保留记忆的问题呢?都说好记性不如烂笔头,AI也同样如此。
因此在对话模式中,我们可以从我们的“烂笔头”,也就是外部的知识库(数据库)检索出相关的知识放进对话模式里面,这就是我们这门课程的主题——RAG。
RAG全称是“Retrieval-Augmented Generation”,即“检索增强的生成”。
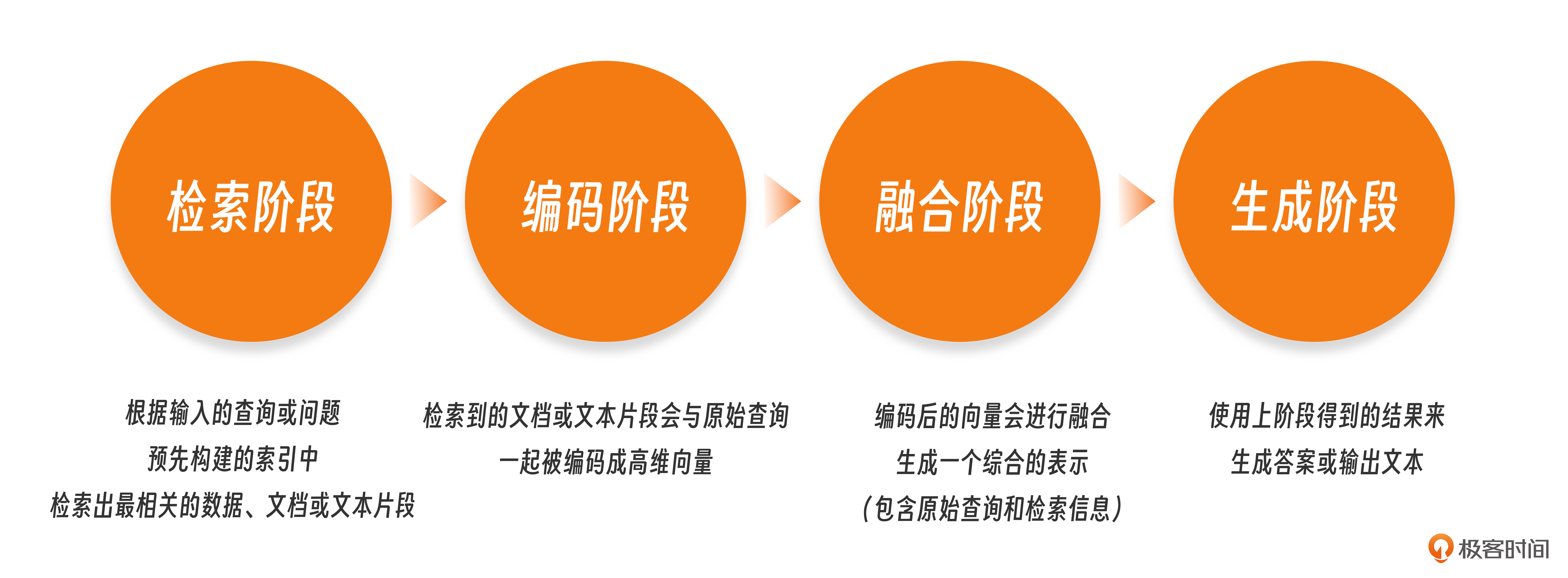
RAG的核心思想是利用外部知识库或数据集来辅助模型的生成过程。具体来说,RAG通常包含以下关键步骤。
- 检索阶段:首先,模型会根据输入的查询或问题,从预先构建的索引中检索出最相关的数据、文档或文本片段。这些数据、文档或片段在我们这门课程中将会是你熟悉的MIS关系数据库里面的数据(实战案例1)、日常看的IT技术新闻(实战案例3)等等。
- 生成阶段:随后,模型会使用这个综合的表示来生成答案或输出文本。在问答任务中,这通常意味着生成一个对原始查询的直接回答。
通俗地讲,就是用户问AI一个问题,然后AI马上去知识库(类似于翻书、翻词典)找到对应的词条,然后根据这个词条回答用户。
看过其他文章的同学可能会问,为什么这里少了两个阶段:
- 编码阶段:检索到的文档或文本片段会与原始查询一起被编码成高维向量(多维数组的专业说法,只不过这里的多维多到几百、上千的那种)。
- 融合阶段:编码后的向量会进行融合,以生成一个综合的表示,这个表示同时包含了原始查询和检索到的相关信息。
这个问题问得好,的确很多RAG应用(包括这门课后面的实战案例)是包含以上两个步骤的,也就是说会包含四个阶段:
- 检索阶段
- 编码阶段
- 融合阶段
- 生成阶段
但是我们的实战案例1并不需要编码和融合阶段,所以我们可以看出,编码和融合阶段并不是RAG应用必需的,检索和生成阶段才是RAG应用必需的。
根据奥卡姆剃刀原则,如无必要,勿增实体。我们在规划设计一个RAG应用的时候,也尽量勿增实体,如果不需要添加编码和融合阶段,那我们就不添加。在这方面,我们的实战案例1就是一个很好的例子。
对话模式在代码上是如何表示的
好了,前面讲了这么多,都还是停留在文字上。那么前面的例子和概念在代码上是如何表示的呢?
前面的例子在OpenAI的ChatGPT表现为:
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个ERP MIS系统"},
{"role": "user", "content": "客户A的款项到账了多少?"},
{"role": "assistant", "content": "已到账款项为57980。"},
{"role": "user", "content": "还剩多少?"},
{"role": "assistant", "content": "剩余到账款项为2908元。"}
]
)
我们课程里使用了百度ERNIE-Lite-8K大模型,因为它不支持系统(system)角色,所以表现为:
messages=[
{"role": "user", "content": "客户A的款项到账了多少?"},
{"role": "assistant", "content": "已到账款项为57980。"},
{"role": "user", "content": "还剩多少?"},
{"role": "assistant", "content": "剩余到账款项为2908元。"}
]
其中messages所支持的数量依赖于大模型对记忆的支持。
RAG在代码上是如何表示的
以上代码还没有用到外部知识库,使用了外部知识库,也就是RAG应用,在代码上是这么表现的:
从外部知识库检索到的知识="客户:A 入账日期:2024-07-06T00:00:00Z 入账金额:9527 已到账款项:57980 剩余到账款项:2908 "
根据外部知识组装的语言 = f"""
您已经知道以下信息:
{从外部知识库检索到的知识},
请根据以上您所知道的信息回答用户的问题:
"""
messages=[
{"role": "user", "content": 根据外部知识组装的语言 + "客户A的款项到账了多少?"},
{"role": "assistant", "content": "已到账款项为57980。"},
{"role": "user", "content": 根据外部知识组装的语言 + "还剩多少?"},
{"role": "assistant", "content": "剩余到账款项为2908元。"}
]
以上代码的第1到6行就是从外部知识库检索的过程。第8行和第10行则是将检索到的外部知识提供给大模型的代码。
那么从上面的代码中我们能够发现什么规律呢?
第一,组装之后的知识是放在user角色里面的,而不是assistant角色。这点跟前面的比喻不同。前面比喻提到的流程是:
- 用户问AI一个问题。
- 然后AI马上去知识库(类似于翻书翻词典)找到对应的词条。
- 最后AI根据这个词条回答用户。
而实际表现在代码上,应该是这样的。
- 用户提出一个问题。
- 我们的RAG应用马上去知识库(类似于翻书、翻词典)找到对应的词条。
- 然后我们的RAG应用把这个词条用语言组装一下再加上用户提出的问题,一起交给AI。
- AI根据我们给出的这些内容进行回答。
第二,检索到的知识是需要组装的,如果我们直接将代码第1行的知识喂给大模型,而不经过代码第2行的语言进行组装,大模型是很难正确处理的。
第三,有些同学可能发现,以上示例代码中,检索和组装外部知识的过程过于简单,并不足以支撑整个示例运行。
是的,为了让你把注意力先聚焦在基础概念上,我对这段代码做了一些简化。而这部分被简化的代码就是RAG应用的核心,这是这门课后续的内容。等同学们学习完后面的实战案例之后,你会发现,以上代码的其他部分基本就定型了,也没有太多的扩展,主要扩展的都是检索和组装外部知识部分的代码。我们下一节课就从检索外部知识所需的基本概念—— 返回结构化数据讲起。
小结
好了,今天这一讲到这里就结束了,最后我们来回顾一下。这一讲我们学会了两件事情。
第一件事情是三个概念以及这些概念在代码上的表示。
- 第一个概念是对话模式的角色。对话模式可以包括三个角色:用户(user)、AI(assistant)与系统(system)。注意,很多大模型目前还不支持系统角色。即使支持系统角色的大模型,系统角色也不是必需的。
- 第二个概念是记忆。通过记忆,用户只需要输入有限的文字,AI就能够根据记忆补全其他信息来回答用户的问题。
- 第三个概念就是我们课程的主题RAG。好记性不如烂笔头,RAG就是用外部知识库这个烂笔头来代替记忆。
第二件事情是RAG的整个流程。用户提出一个问题,我们的RAG应用检索到对应的知识,再加上用户的提问一起交给AI,AI根据这些内容进行回答。
思考题
如果用户与AI进行了一万次对话(一万次应该超出了目前所有大模型的记忆上限),那么我们的应用如何处理呢?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
- 张申傲 👍(8) 💬(2)
第2讲打卡~ 思考题:这种多轮对话的场景,通常需要系统支持Memory记忆功能,简单来说就是将用户与LLM的聊天记录保存下来,并在下次生成内容时传递给LLM。常用的记忆模式包括缓冲记忆、摘要记忆、混合记忆、向量数据库记忆等等,这些功能在LangChain中大多包含了内置的组件。关于Memory系统的实现,感兴趣的同学可以参考下我的文章:https://blog.csdn.net/weixin_34452850/article/details/141716143
2024-09-05 - 明辰 👍(2) 💬(1)
老师,我仔细看了您的课,有3个问题想请教一下 1、对话中输入的内容,我们一般全部放到role里,但是OpenAI额外增加了system,哪些指令应该放到system中,哪些放到role中 2、您提到编码、融合过程,是不是可以理解为这部分已经由基座模型实现了,一般我们不需要太多关注 3、您提到的“外部知识组装”环节应该怎么理解,是说检索到的信息需要改写成固定的格式再给到模型嘛 期待老师的解答~
2024-09-12 - kevin 👍(2) 💬(1)
在编码阶段,将历史问答进行压缩
2024-09-05 - NEO 👍(1) 💬(1)
提问-->LLM对问题进行完善丰富-->向量数据库根据完善后的提问进行检索--->编码-->融合-->生成-->prompt反馈-->优化......
2024-09-06 - grok 👍(1) 💬(1)
请教两个问题: 1. 系统角色在其他主流LLM支持吗 比如claude/gemini/grok 2. 超长窗口的LLM不断出现,会给RAG带来任何影响吗,比如https://magic.dev/blog/100m-token-context-windows
2024-09-06 - 叶绘落 👍(0) 💬(1)
将一万次对话进行切片,如每 10 、100 次对话为一个切片(每个切片进行持久化存储),将前一个切片交给 LLM 归纳总结,归纳结果作为下一个切片的上下文,以此类推,最终得到一万次对话的最终归纳结果,并将其持久化存储。 如有新提问,就以最终归纳结果和最近的一个对话切片作为上下文,结合新提问,交给 LLM 处理。
2024-09-11 - 爬行的蜗牛 👍(0) 💬(1)
方式一:对一万次会话进行总结,提取要点再作为Memory. 方式二:切片去最近的部分。
2024-09-07 - Geek小马哥 👍(0) 💬(0)
这个老师讲得好: 假传万卷书, 真传一案例.
2025-02-13 - alue 👍(0) 💬(0)
请问老师,RAG的能力是不是受限于推理上下文的大小?如果本地部署一个大模型,例如Qwen2.5-7b, 推理上下文大小是受限于硬件资源呢还是受限于模型本身?
2025-01-07 - 石云升 👍(0) 💬(0)
长期记忆压缩存储关键信息。
2024-09-25