10 进阶(二):微软GraphRAG
本课程为精品小课,不标配音频
你好,我是常扬。
在关于 Modular RAG 的课程中,我们提到了 RAG 结合 Knowledge Graph (知识图谱)的概念。微软对此进行了深入的验证和项目实践,并于 2024 年 2 月发布了博客《GraphRAG: Unlocking LLM Discovery on Narrative Private Data》,同年 4 月又发布了论文《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》,深入探讨了和验证了 RAG 结合知识图谱的技术效果。最终,他们在 7 月初通过 GitHub 开源了 GraphRAG 项目,迅速获得了业界的广泛关注。
微软提出,在实际应用中,RAG 在使用向量检索时面临两个主要挑战。
- 信息片段之间的连接能力有限:RAG 在跨越多个信息片段以获取综合见解时表现不足。例如,当需要回答一个复杂的问题,必须通过共享属性在不同信息之间建立联系时,RAG 无法有效捕捉这些关系。这限制了其在处理需要多跳推理或整合多源数据的复杂查询时的能力。
- 归纳总结能力不足:在处理大型数据集或长文档时,RAG 难以有效地归纳和总结复杂的语义概念。例如,试图从一份包含数百页的技术文档中提取关键要点,对 RAG 来说是极具挑战性的。这导致其在需要全面理解和总结复杂语义信息的场景中表现不佳。
为了解决这些挑战,微软提出了 GraphRAG,通过利用大模型生成的知识图谱来改进 RAG 的检索部分。GraphRAG 的核心创新在于利用结构化的实体和关系信息,使检索过程更加精准和全面,特别在处理多跳问题和复杂文档分析时表现突出。通过这些改进,GraphRAG 在处理私有数据和复杂信息处理任务时,显著提升了问答性能,提供了比 RAG 更为准确和全面的答案。
GraphRAG 能够通过知识图谱有效地连接不同的信息片段。例如,当一个查询需要整合来自不同部门的报告时,GraphRAG 可以识别并链接跨文档的相关实体,如关键指标、关键行动、关键事项等。这使得 RAG 不仅能够提供准确的答案,还能展示答案之间的内在联系,提供更丰富和有价值的结果。
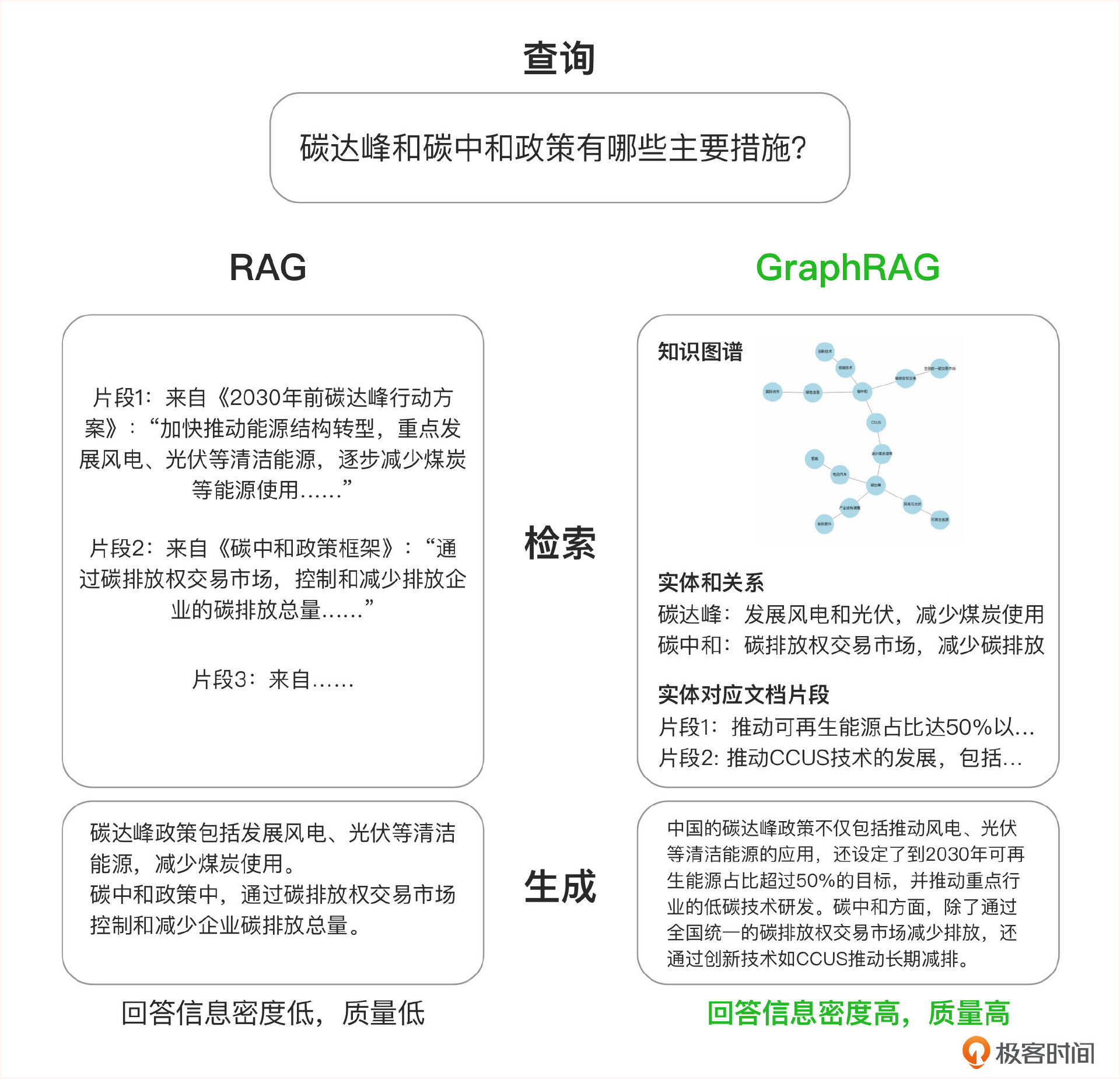
上图展示了归纳性问题的查询中两个系统的对比:RAG 与 GraphRAG 。GraphRAG 先利用知识图谱,关联查询的实体和关系,然后从与图谱实体直接相关的文档中检索片段,最终提供了一个更全面、指标化、高信息密度的总结。
为什么要使用 GraphRAG?
GraphRAG 通过构建知识图谱,将实体和实体之间的关系结构化地表示出来,克服了传统 RAG 的复杂推理局限性。其主要优势体现在以下几个方面:
- 提高答案准确度和完整性
- 精确的关系捕捉:知识图谱能够显式地表示实体及其关系,使得 GraphRAG 在处理涉及多实体、多关系的复杂查询时,能够准确地检索相关信息。
- 多跳推理能力:通过图结构,GraphRAG 可以自然地实现多跳推理,连接不同的信息片段,提供更加全面和深入的回答。
- 实证效果:微软的学术论文表明,GraphRAG 在回答业务复杂问题时,LLM 响应的准确度平均提升了三倍以上。
- 增强数据理解和迭代效率
- 直观的数据表示:知识图谱以图形方式展示数据,便于开发者和用户理解数据之间的关联和结构。
- 提升可解释性和可追溯性
- 可解释性:知识图谱的结构化特点使得系统的决策过程透明化,便于理解模型给出某一答案的原因。
- 可追溯性:每个结论都可以在知识图谱中找到对应的路径,支持对决策过程的复查和验证。
知识图谱是什么?
在计算机科学和人工智能领域,图谱(Graph)是一种用于表示实体及其相互关系的数学结构。一个图由一组 节点(Nodes) 和连接这些节点的 边(Edges) 组成。节点通常代表实体,如人物、地点或概念,边则表示实体之间的关系或关联。
知识图谱(Knowledge Graph) 是一种特殊类型的图谱,用于表示知识领域中的实体及其关系。它以结构化的方式组织信息,使机器能够理解和推理复杂的语义关系。知识图谱的核心要素包括:
- 实体(Entities):表示具体的对象或概念,例如苹果公司、iPhone、智能手机。
- 属性(Attributes):描述实体的特征,如成立日期、创始人。
- 关系(Relations):连接实体之间的语义关联,如生产、竞争对手。
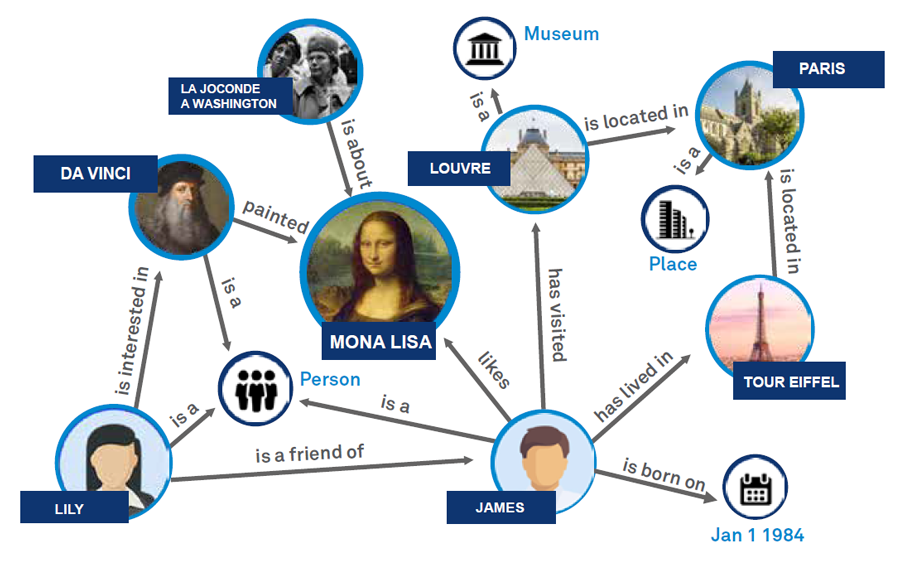
通过这种结构,知识图谱能够高效地组织和检索信息,为各种应用提供支持,包括RAG系统、推荐引擎和语义搜索。
在 GraphRAG 中,知识图谱被引入以增强传统 RAG 的能力,主要体现在以下方面:
- 结构化信息表示:通过将文本数据转换为知识图谱,GraphRAG 能够以结构化的方式捕捉实体和关系,超越了纯粹向量表示的局限。
- 增强语义理解:知识图谱提供了显式的语义关系,使模型能够理解实体之间的复杂关联,支持多跳推理和全局信息整合。
- 改进检索效率:在检索阶段,利用知识图谱可以更精准地定位相关信息,减少无关数据的干扰,提高RAG的检索速度。
假设需要回答“《三体》的主要人物关系是什么?”。传统 RAG 可能难以从大量文本中准确提取相关信息。而在 GraphRAG 中:
- 构建知识图谱:从小说文本中抽取人物实体和他们之间的关系,构建人物关系图谱。
- 检索与推理:利用知识图谱,模型可以高效地找到主要人物及其相互关系,提供准确的回答。
构建知识图谱通常涉及以下步骤:
- 实体识别:从文本或数据源中识别出关键实体。
- 关系抽取:确定实体之间的关系,可能通过自然语言处理技术实现。
- 三元组生成:将实体和关系表示为 (主体,关系,客体) 的形式。
- 图谱存储:使用图数据库或专门的存储系统保存知识图谱。
构建知识图谱的问题在于成本,尤其是涉及大规模数据处理和图谱维护时,所需的资源和技术复杂性往往较高。以下几个方面是知识图谱构建中的主要成本挑战:
- 数据收集与清洗成本:构建高质量的知识图谱依赖于从多源异构数据中抽取出可靠的实体和关系。这需要对数据进行大量清洗和预处理,以消除冗余、噪声和冲突数据,确保图谱的准确性和一致性,这种过程通常需要大量的人工干预和计算资源。
- 知识图谱构建成本:知识图谱的构建依赖于从数据中识别并提取实体及其关系,传统上依赖于人工识别和提取,现在可以借助大模型来完成,但均需要大量的成本。以处理 200 页的文本为例,假设使用ChatGPT-4完成构建,需要进行约 449 次调用,总成本约为 11 美元。
- 图谱的维护与更新:知识图谱是动态的,随着新的数据和知识不断涌现,图谱需要持续更新以保持其准确性和时效性。维护和更新图谱需要定期重新处理数据,以确保新添加的实体和关系与现有结构保持一致。
微软GraphRAG详解

GraphRAG 通过将知识图谱中的结构化数据与输入文档中的非结构化数据相结合,利用相关实体信息来增强LLM的上下文理解。
在处理用户查询时(可选结合对话历史记录),系统采用本地搜索方法,从知识图谱中识别与用户输入语义相关的一组实体。这些实体作为知识图谱的访问点,帮助提取更多相关信息,包括关联实体、关系以及文档片段。随后,系统对这些候选数据源进行优先级排序与筛选,以适应单个上下文窗口的预定义大小,从而为用户生成准确的查询响应。
下面我们展示GraphRAG示例代码,更多细节查看GraphRAG官网。
- 安装 GraphRAG
- 设置文档文件夹和添加官方示例
mkdir -p ./ragtest/input
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt > ./ragtest/input/book.txt
- 项目初始化配置
此操作将在 ./ragtest 目录下创建两个文件:.env 和 settings.yaml,其中
.env: 包含运行 GraphRAG 所需的环境变量。该文件将包括一个 GRAPHRAG_API_KEY=<API_KEY> 的变量,你可以将其替换为你自己的 OpenAI 密钥。
settings.yaml: 包含Pipeline的设置,你可以修改此文件来自定义Pipeline的行为。
有关 GraphRAG 配置的更多详细信息,请参阅配置文档。
- 运行索引流程
此过程需要一些时间,具体取决于你的输入数据大小、所使用的模型以及文本块大小(这些可以在 settings.yaml 文件中进行配置)。完成后,你会看到一个名为 ./ragtest/output/<timestamp>/artifacts 的新文件夹,其中包含一系列处理后的文件。
- 运行检索及生成流程
python -m graphrag.query \
--root ./ragtest \
--method local \
"Who is Scrooge, and what are his main relationships?"
总结
这节课我们讲解了近期爆火的微软开源项目 GraphRAG。
GraphRAG 通过将 RAG与知识图谱相结合,显著提升了RAG在处理复杂信息和多跳推理方面的能力。GraphRAG 的核心优势在于结构化地表示实体及其关系,增强了语义理解和检索效率,从而提高了答案的准确性和完整性。同时,它还提升了可解释性和可追溯性。
知识图谱是一种用于表示知识领域中实体、属性和关系的图形结构。它通过节点(实体)和边(关系)来构建,能够高效地组织和检索信息,支持复杂的语义理解和推理。然而,在 GraphRAG 流程中构建和维护知识图谱存在一定的挑战和成本,包括数据收集与清洗、实体识别与关系抽取以及图谱的持续更新和维护。
思考题
针对知识图谱构建和维护成本高的挑战,可以采用哪些方法或策略来降低成本、提高效率,从而促进 GraphRAG 的广泛应用?欢迎你在留言区分享,和我一起讨论,也欢迎你把这节课的内容分享给对RAG感兴趣的朋友!
- 张申傲 👍(1) 💬(1)
第10讲打卡~ 感谢老师高质量的课程,受益匪浅~
2024-10-29 - 柏颍 👍(1) 💬(1)
老师好,我读过GraphRAG这篇论文,我看他好像还有抽取event(covariate),可以解释一下这是什麽吗?
2024-09-19 - ACY 👍(0) 💬(1)
结课打卡,不知道使用自己部署的大模型做graph rag资源要求怎么样。
2024-11-17 - kevin 👍(0) 💬(1)
答思考题作业,降低大模型成本,或者使用开源的大模型部署到本地,以节约成本。不使用OPENAI,
2024-11-10 - kevin 👍(0) 💬(1)
知识图谱是一个很专业的工作,这个一个很高的成本,如果没有高质量领域的知识图谱怎么办。
2024-11-10 - 煜寶 👍(0) 💬(1)
微软的这个GraphRAG安全性如何呢。。。想用本地自己部署的,但是不知道这个数据安全性是否有猫腻,很多内部资源都不适合对外的
2024-11-10