08 RAG效果提升:检索精度的优化与RAG效果评估
本门课程为精品小课,不标配音频。
你好,我是常扬。
在之前的课程中,我们已经学习了RAG的完整流程。RAG索引阶段,首先解析文档,并将文档进行分块处理,接着通过嵌入模型将这些文本块向量化,最终将生成的向量存储在向量数据库中。在 RAG检索阶段,RAG系统会将用户查询向量化,并在向量数据库中进行语义相似度匹配,筛选出与查询最相似的多个文本块。最后,在 RAG生成阶段,系统将用户的查询与检索出的文本块进行指令组合和设计,并通过大模型的理解生成最终回答,至此完成整个RAG流程。
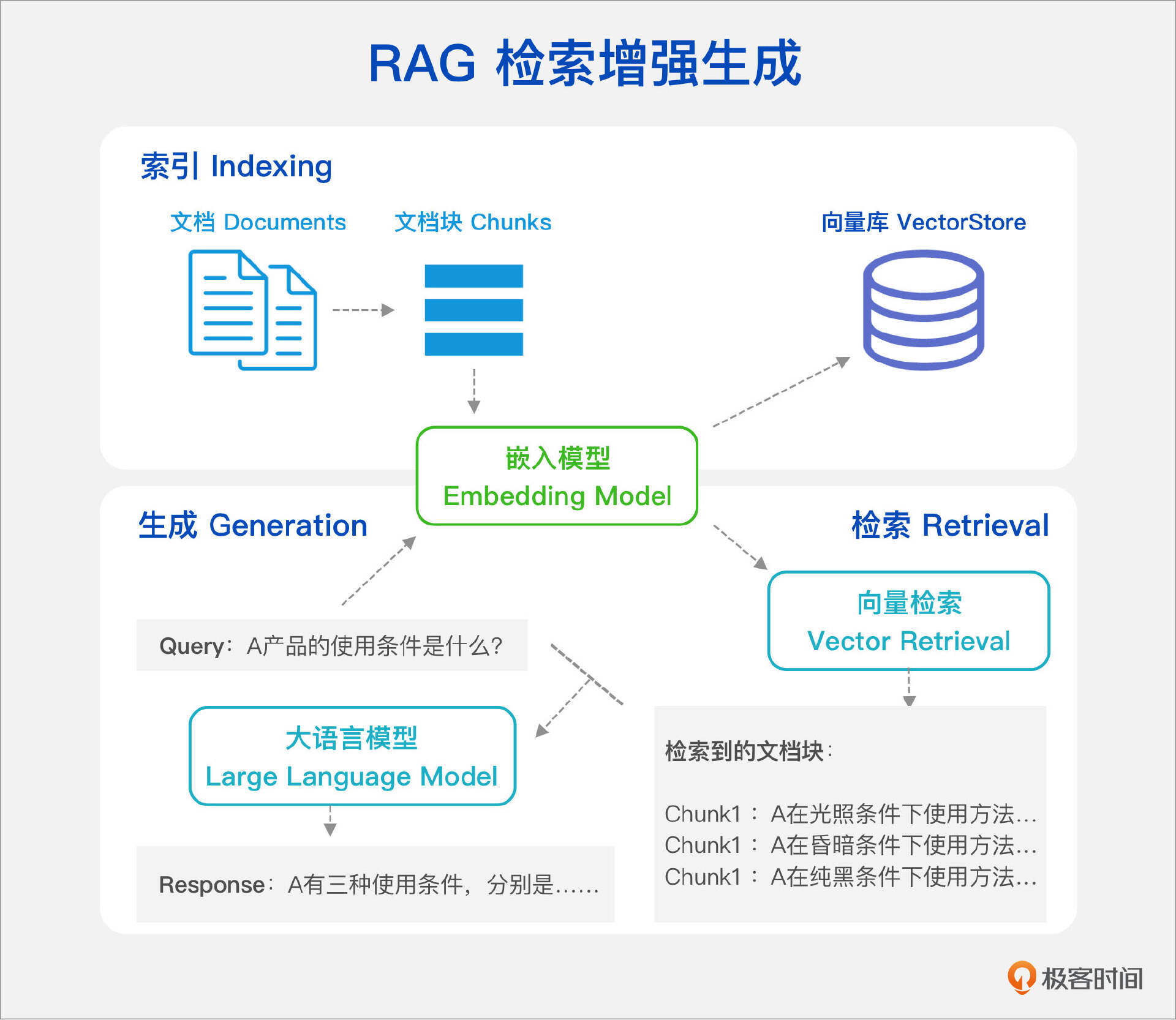
上述内容的讲解实际上已经涵盖了一些能够提升 RAG 检索效果的关键技术。这些技术包括:处理多种文档格式、版面布局及阅读顺序还原的高精度、高效率文档解析技术,适用于特定场景的多样化分块策略,综合考虑特定领域精度、效率和文本块长度的嵌入模型,支持高效索引、检索和存储的向量数据库,结合多种检索技术的混合检索方法,以及能够捕捉查询词与文档块相关性的重排序技术。每个技术的细节优化都可以进一步提升整体检索精度。
这节课我们会在之前课程的基础上,进一步补充优化检索精度的方法。
数据清洗和预处理
在RAG索引流程中,文档解析之后、文本块切分之前,进行数据清洗和预处理能够有效减少脏数据和噪声,提升文本的整体质量和信息密度。通过清除冗余信息、统一格式、处理异常字符等手段,数据清洗和预处理过程确保文档更加规范和高质量,从而提高RAG系统的检索效果和信息准确性。
以下是其中一些方法及其示例:
处理冗余的模板内容
在企业内部文档中,特别是合同或报告等类型的文档,通常会出现大量的重复段落,例如多个合同中包含相同的法律条款或说明性文字。这类重复内容会增加向量数据库的存储负担,并影响检索效率。通过去除冗余内容,能够减少不必要的干扰,提升检索速度和相关性。
处理前:
处理后:
消除文档中的额外空白和格式不一致
文档中可能存在多余的空行、缩进或其他格式不一致的情况,这些多余的空白和格式会影响文本块的切分和向量化过程。通过清理这些格式化问题,能够确保文本块的划分更加精准,减少分块过程中的误差。
处理前:
处理后:
去除文档脚注、页眉页脚、版权信息
在文档解析时,可能会从网页或PDF中提取出脚注、版权声明、页眉页脚等无关信息。这些内容会增加数据的噪声,影响向量生成的精度。去除这些无关的页脚和版权信息,有助于提升文本块的语义密度。
处理前:
处理后:
查询扩展
在RAG系统的典型检索步骤中,用户的查询会转化为向量后进行检索,但单个向量查询只能覆盖向量空间中的一个有限区域。如果查询中的嵌入向量未能包含所有关键信息,那么检索到的文档块可能不相关或缺乏必要的上下文。因此,单点查询的局限性会限制系统在庞大文档库中的搜索范围,导致错失与查询语义相关的内容。
查询扩展策略通过大模型从原始查询语句生成多个语义相关的查询,可以覆盖向量空间中的不同区域,从而提高检索的全面性和准确性。这些查询在嵌入后能够击中不同的语义区域,确保系统能够从更广泛的文档中检索到与用户需求相关的有用信息。
以下是查询扩展的指令模版:
你是一个AI语言模型助手。
你的任务是生成五个不同版本的用户问题,以便从向量数据库中检索相关文档。
通过从多个角度生成用户问题,你的目标是帮助用户克服基于距离的相似性搜索的一些局限性。
请将这些替代问题用换行符分隔。原始问题:{查询原文}
假设原始查询问题为:“下面报告中涉及了哪几个行业的案例以及总结各自面临的挑战?”
通过查询扩展指令,GPT-4o生成如下结果:
请问报告中提到的案例涉及了哪些行业?这些行业各自面临的挑战有哪些?
报告中有哪些行业的案例被讨论?每个行业在报告中描述的挑战是什么?
这个报告中具体提到了哪些行业的案例?能否总结一下这些行业当前面临的主要挑战?
该报告中涵盖了哪些行业案例,并对各行业的挑战进行了哪些讨论?
在报告中提到的行业案例有哪些?这些行业分别遇到的主要问题和挑战是什么?
通过这种查询扩展策略,原始问题被分解为多个子查询,每个子查询独立检索相关文档并生成相应的结果。随后,系统将所有子查询的检索结果进行合并和重新排序。此方法能够有效扩展用户的查询意图,确保在复杂信息库中进行更全面的文档检索,从而避免遗漏与查询语义密切相关的重要内容。
自查询
在将用户查询转化为向量的过程中,无法确保查询中的所有关键信息都被充分捕捉到向量中。例如,若希望检索结果依赖于查询中的标签,直接通过嵌入向量进行检索并不能确保这些标签在向量表示中被完整表达,或者在与其他向量的距离计算中占有足够的权重。这种不足可能会导致检索结果缺乏相关性和准确性。
自查询策略通过大语言模型自动提取查询中对业务场景至关重要的元数据字段(如标签、作者ID、评论数量等关键信息),并将这些信息结合到嵌入检索过程中。通过这种方式,可以确保嵌入向量中包含这些关键信息,从而提高检索的全面性与精确性。
以下是自查询的指令模版:
假设原始查询问题为:“下面报告中涉及了哪几个行业的案例以及总结各自面临的挑战?”
通过自查询指令,GPT-4o生成如下结果:
通过这种自查询策略,系统能够精准提取查询中的关键信息,结合关键词检索及向量检索,确保这些元数据在向量检索中得以充分利用,从而提高检索结果的相关性和准确性。
提示压缩
提示压缩旨在减少上下文中的噪声,并突出最相关的信息,从而提高检索精度和生成质量。在RAG系统中,检索到的文档通常包含大量无关的文本,这些无关内容可能会掩盖与查询高度相关的信息,导致生成结果的相关性下降。提示压缩通过精简上下文、过滤掉不相关的信息,确保系统只处理与查询最相关、最重要的内容。
以下是提示压缩的指令模版:
你是一个AI语言模型助手,负责对检索到的文档进行上下文压缩。
你的目标是从文档中提取与用户查询高度相关的段落,并删除与查询无关或噪声较大的部分。
你应确保保留所有能够直接回答用户查询的问题核心信息。
输入:
用户查询:{用户的原始查询}
检索到的文档:{检索到的文档内容}
输出要求:
提取与用户查询最相关的段落和信息。
删除所有与查询无关的内容,包括噪声、背景信息或扩展讨论。
压缩后的内容应简洁清晰,直指用户的核心问题。
输出格式:
{压缩段落1}
{压缩段落2}
{压缩段落3}
通过提示压缩,系统能够准确提取出与查询高度相关的核心信息,去除冗余内容,并返回简洁的压缩结果。组合成为新的指令,输入大模型获得回复,提高RAG系统答案准确度。
RAG效果评估
在RAG系统的开发、优化与应用过程中,RAG效果评估是其中不可或缺的一环。通过建立统一的评估标准,能够公平、客观地比较不同RAG系统及其优化方法,从而识别出最佳实践。这套评估体系不仅帮助开发者发现系统的优劣,亦为后续的改进提供了有力的参考依据。
下面我介绍一种在真实应用场景中采用的RAG效果评估标准与方法。
评估方式:
- 大模型打分:通过使用大语言模型对RAG的输出进行自动评分。这类评估方式效率高,能够快速处理大规模的评估任务,但在准确性上可能受到模型本身偏差的影响。
- 人工打分:由人类评审员对RAG的输出进行逐一打分。人工评估方式可以提供更为精确、细致的反馈,特别是在检测生成答案中的细微错误和幻觉时,但其耗时较长,成本较高。
评估指标:
- CR 检索相关性(Context Relevancy):该指标用于测量检索到的信息与查询上下文的相关性。如果检索到的信息偏离了原始查询,后续的生成任务就会受到负面影响。
- AR 答案相关性(Answer Relevancy):衡量生成答案与原始问题之间的相关性。该指标主要评估生成的答案是否能够解决用户的问题,且内容是否逻辑连贯。
- F 可信度(Faithfulness):评估生成的答案中是否存在幻觉(hallucination)或不准确之处。这一指标尤为重要,因为虚假的答案会极大影响用户对RAG系统的信任度。
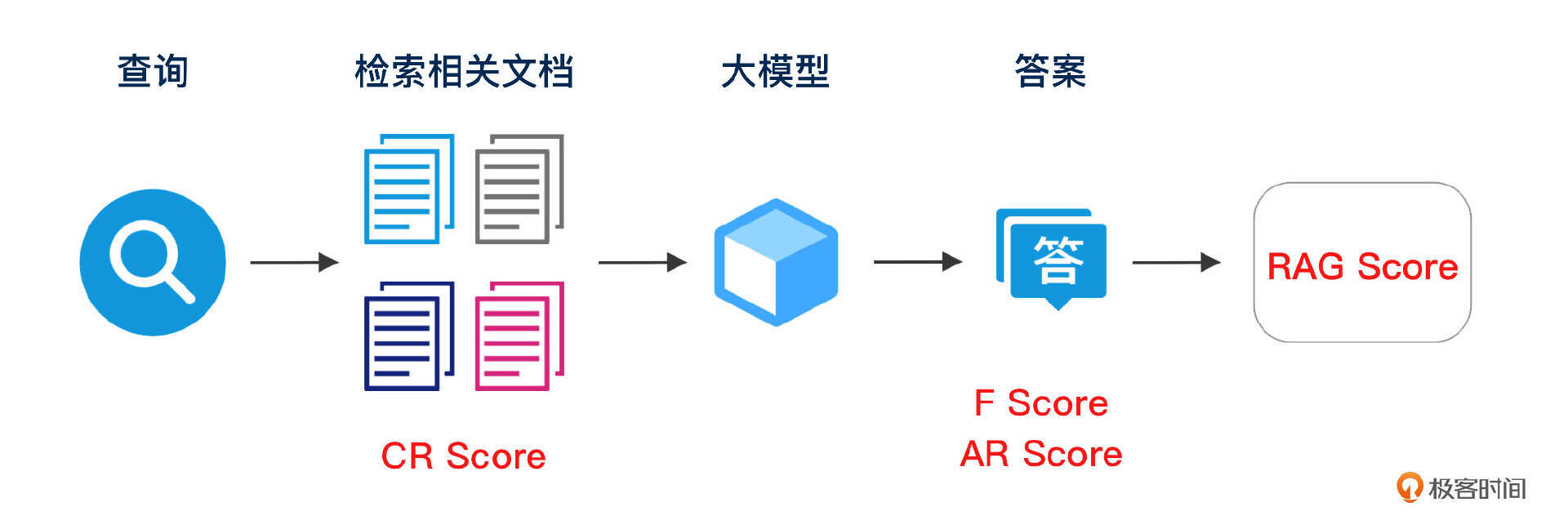
打分标准:
- 完美(Perfect)1.0分
- 可接受(Acceptable)0.75分
- 缺失(Missing)0.5分
- 错误(Incorrect)0分
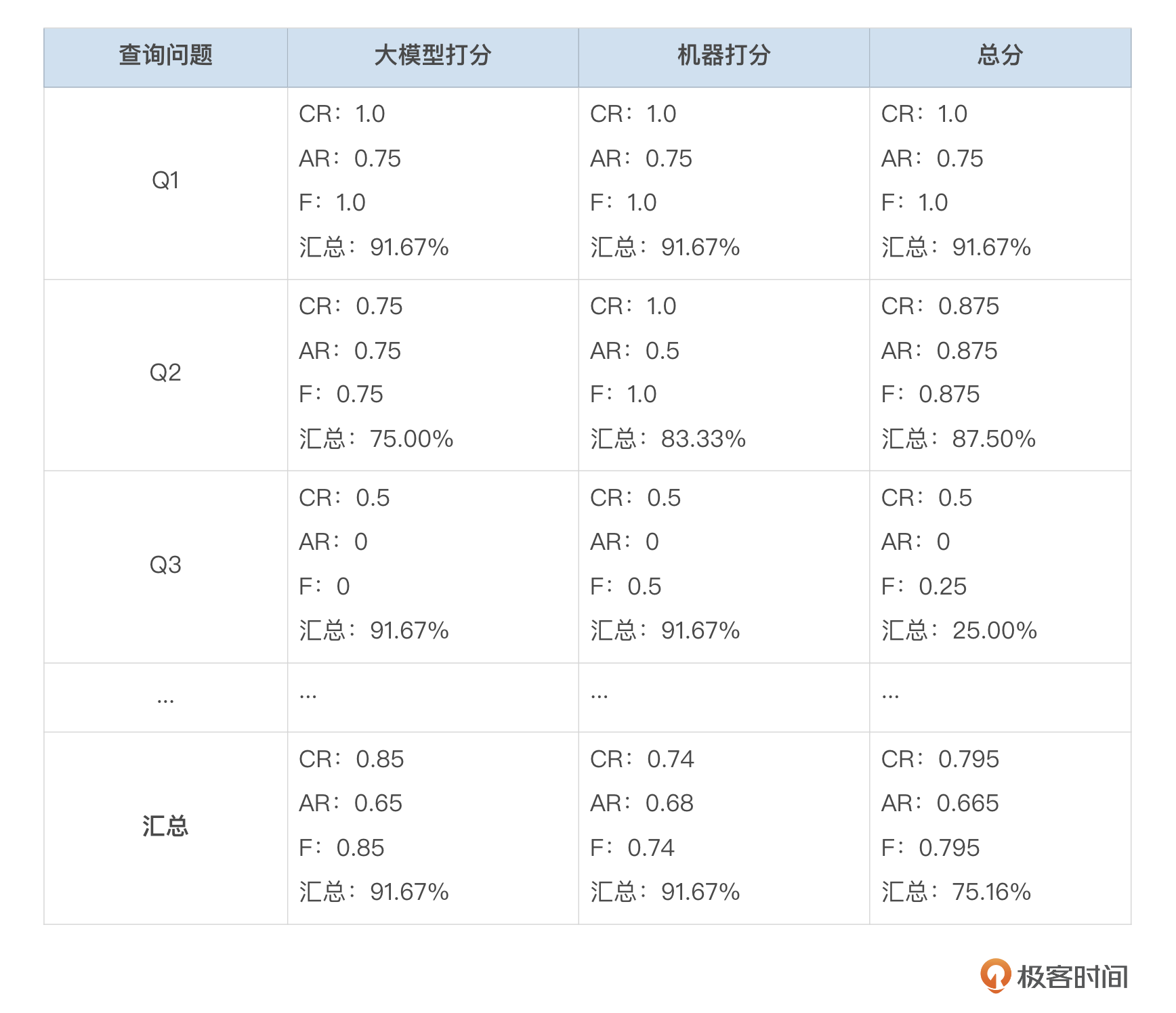
RAG效果评估是RAG系统完成搭建后的一个持续优化流程。通过设定打分标准和评估指标,综合评分能够准确反映RAG系统的整体性能。针对不同的应用场景,还可以引入更多评估指标,如 Top5 召回率、Top3 召回率、Top1 召回率以及其他常用的 NLP 评估指标。通过灵活组合这些评估方式与指标,可以更加精确地衡量RAG系统在特定场景中的表现,并为后续优化提供方向。
总结
这节课我们讲解了RAG系统检索精度的优化方法及效果评估。
- 检索精度的优化
既往课程中文档解析技术、分块策略、嵌入模型、向量数据库、混合检索方法、重排序技术均可优化检索精度,在此基础上补充了四种优化检索精度的方法。
数据清洗和预处理,通过清除冗余信息、统一格式和处理异常字符,有效提升文档质量和信息密度,减少噪声干扰。常用的方法包括去除重复内容、清理空白和格式不一致、移除无关的页眉页脚和版权信息。
查询扩展,通过生成多个语义相关的查询覆盖不同向量空间,扩展检索范围,确保检索结果更全面和准确,避免遗漏重要信息。
自查询,从查询中提取关键信息,如标签和元数据,并结合向量检索,提高检索的精准度,确保关键元素在检索过程中得到充分利用。
提示压缩,通过压缩检索到的文档上下文,去除无关内容,保留核心信息,减少噪声,提升生成答案的相关性和准确性。
- RAG效果评估
RAG效果评估在持续优化过程中至关重要。我们今天介绍了一套评估标准与方法,涵盖大模型打分和人工打分两种评估方式,以及检索相关性、答案相关性和可信度评估指标,配以打分标准。最终通过多项指标综合评分来评估系统性能,以指导后续优化方向。
思考题
除了我们这节课提及的优化方法与评估维度外,还有哪些RAG检索精度的优化方法和评估维度?欢迎你在留言区分享,和我一起讨论,也欢迎你把这节课的内容分享给对RAG感兴趣的朋友,我们下节课再见!
- 张申傲 👍(1) 💬(1)
第8讲打卡~ 对RAG效果的评估,还可以考虑增加用户反馈的机制,让用户可以对每一个回复结果进行打分和反馈。
2024-10-28 - licl1008 👍(0) 💬(1)
老师 如果pdf中存在表格,怎么在解析,分段,检索等各环节增加RAG的准确度
2025-02-16 - edward 👍(0) 💬(2)
请问下老师 RAG评估这块内容 可以给出一个示例么?
2024-10-12