06 RAG检索:混合检索与重排序技术
你好,我是常扬。
我们本节课正式开始讲解 RAG 检索流程。当前主流的 RAG 检索方式主要采用向量检索(Vector Search),通过语义相似度来匹配文本切块。这种方法在我们之前的课程中已经深入探讨过了。然而,向量检索并非万能,它在某些场景下无法替代传统关键词检索的优势。
例如,当你需要精准搜索某个订单 ID、品牌名称或地址,或者搜索特定人物或物品的名字(如伊隆·马斯克、iPhone 15)时,向量检索的准确性往往不如关键词检索。此外,当用户输入的问题非常简短,仅包含几个单词时,比如搜索缩写词或短语(如 RAG、LLM),语义匹配的效果也可能不尽理想。
这些正是传统关键词检索的优势所在。关键词检索(Keyword Search)在几个场景中表现尤为出色:精确匹配,如产品名称、姓名、产品编号;少量字符的匹配,用户习惯于输入几个关键词,而少量字符进行向量检索时效果可能较差;以及低频词汇的匹配,低频词汇往往承载了关键意义,如在“你想跟我去喝咖啡吗?”这句话中,“喝”“咖啡”比“你”“吗”更具重要性。
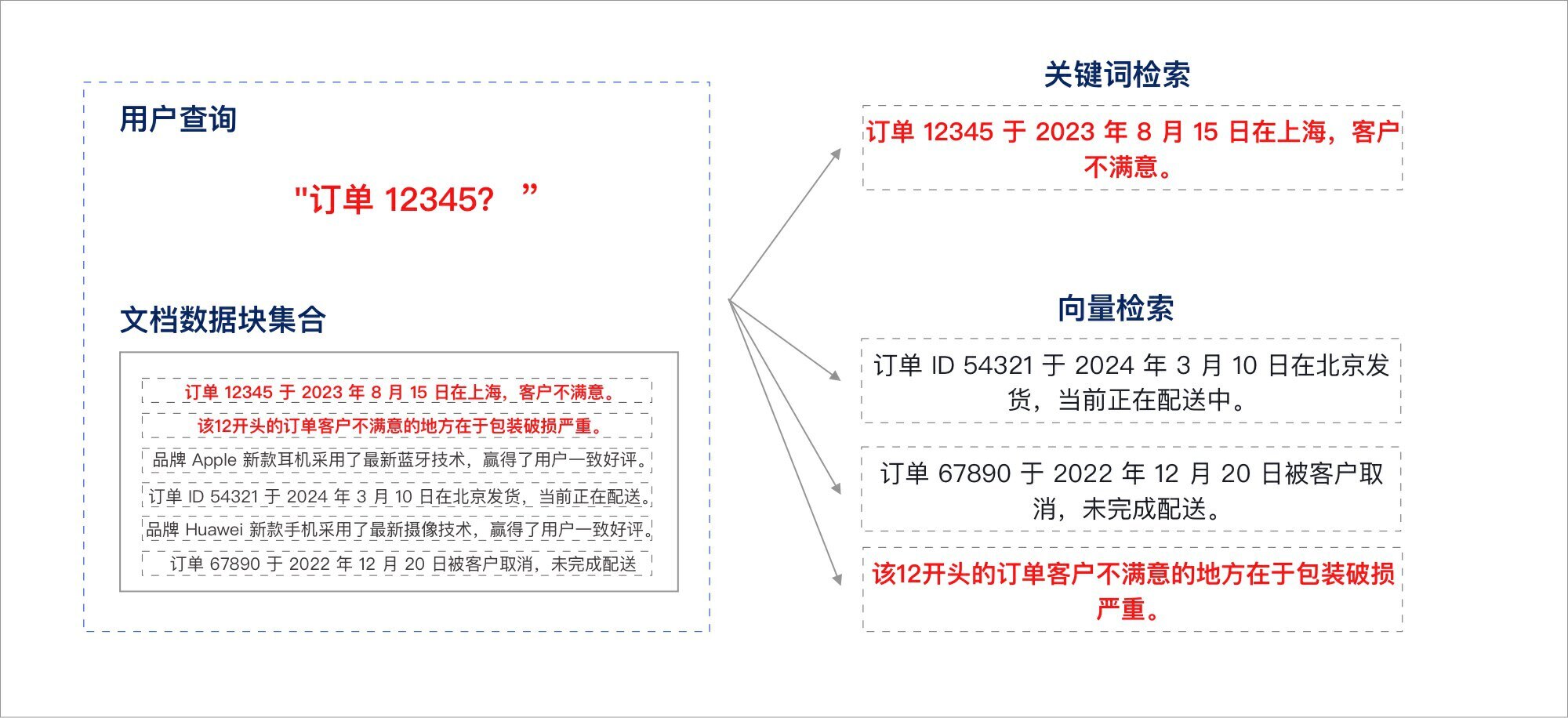
在上述案例中,虽然依靠关键词检索可以精确找到与“订单 12345”匹配的特定信息,但它无法提供与订单相关的更广泛上下文。另一方面,语义匹配虽然能够识别“订单”和“配送”等相关概念,但在处理具体的订单 ID 时,往往容易出错。
混合检索(Hybrid Search)通过结合关键词检索和语义匹配的优势,可以首先利用关键词检索精确定位到“订单 12345”的信息,然后通过语义匹配扩展与该订单相关的其他上下文或客户操作的信息,例如“12开头的订单、包装破损严重”等。这样不仅能够获取精确的订单详情,还能获得与之相关的额外有用信息。
在 RAG 检索场景中,首要目标是确保最相关的结果能够出现在候选列表中。向量检索和关键词检索各有其独特优势,混合检索通过结合这多种检索技术,弥补了各自的不足,提供了一种更加全面的搜索方案。
仅具备混合检索的能力还不足以满足需求,检索到的结果还需要经过优化排序。重排序(Reranking)的目的是将混合检索的结果进行整合,并将与用户问题语义最契合的结果排在前列。在上述案例中,由于缺乏有效的排序,我们期望的结果位于第一和第四位,尽管依然可以被检索到,但理想情况下,如果检索方式更为精确,该结果应该被优先排序在前两位。
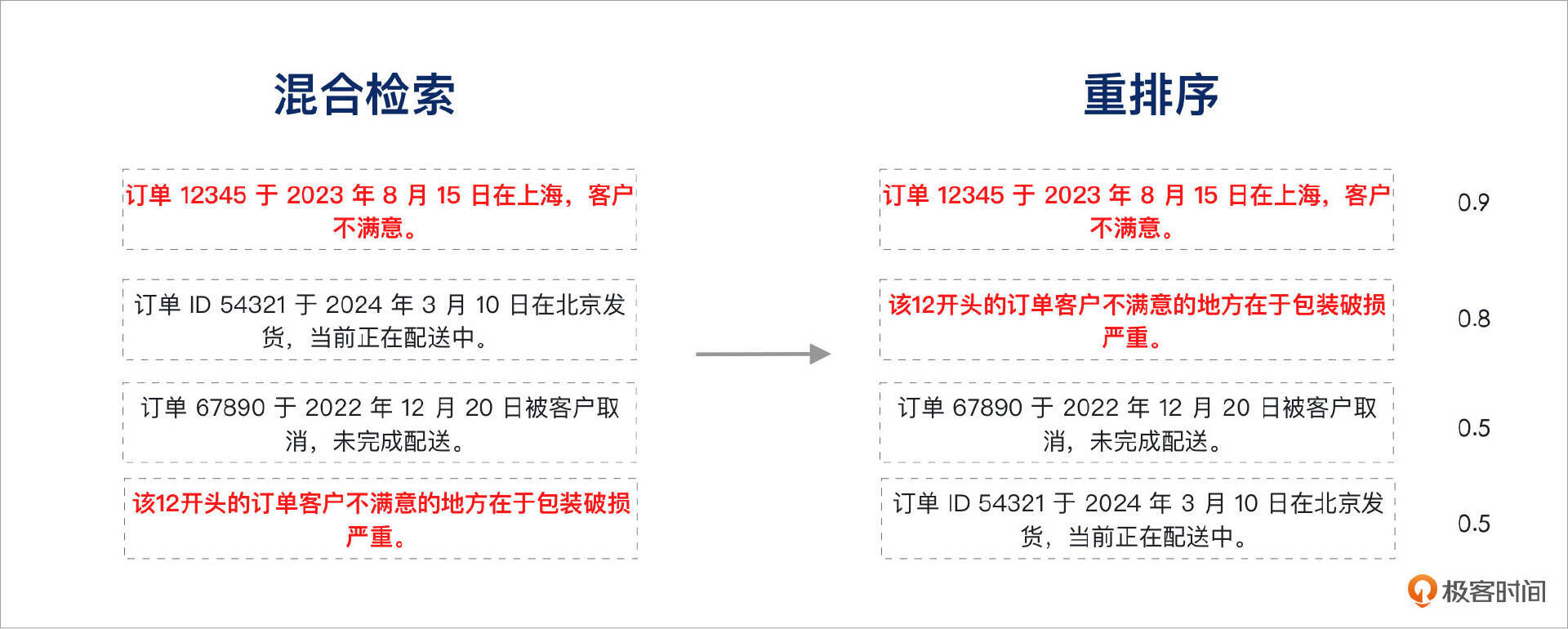
在这个案例中,我们通过重排序技术成功找到了与问题语义最契合的结果。系统评分显示,“订单 12345 于 2023 年 8 月 15 日在上海,客户不满意。”与“该12开头的订单客户不满意的地方在于包装破损严重。”这两个文档块的相关性分别为 0.9 和 0.8,排序为第一和第二位。
重排序技术在检索系统中扮演着至关重要的角色。即使检索算法已经能够捕捉到所有相关的结果,重排序过程依然不可或缺。它确保最符合用户意图和查询语义的结果优先展示,从而提升用户的搜索体验和结果的准确性。通过重排序,检索系统不仅能找到相关信息,还能智能地将最重要的信息呈现在用户面前。
本节课将深入讲解 RAG 检索流程中的混合检索(多路召回)与重排序技术。相关实战代码已发布在 Gitee 托管项目中,代码文件为 rag_app_lesson6.py 。
为什么需要混合检索?
古人云:“兼听则明,偏信则暗。”意思是,只有听取各方面的意见,才能正确认识事物;而只相信单一的观点,必然会导致片面的错误。在 RAG 检索中,这一原则同样适用。通过同时从多个信息源获取信息,我们的检索结果将更加全面和准确。
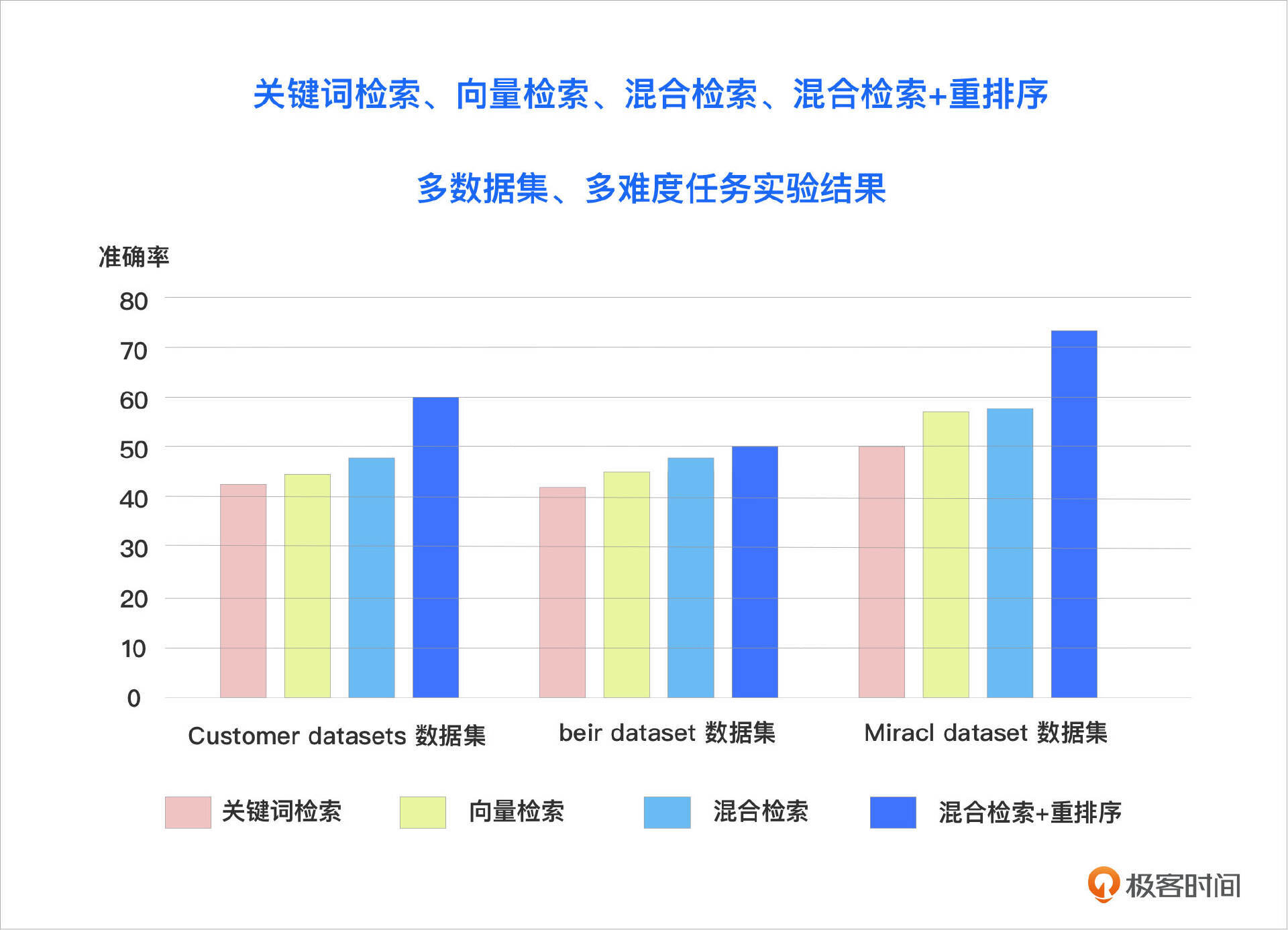
2023年,Microsoft Azure AI 发布了《Azure 认知搜索:通过混合检索和排序能力超越向量搜索》一文。这篇文章对在 LLM RAG 应用中引入混合检索和重排序技术进行了全面的实验数据评估,并量化了这些技术组合在提升文档召回率和准确性方面的显著效果。实验结果表明,在多个数据集和多种检索任务中,混合检索与重排序的组合均取得了最佳表现。
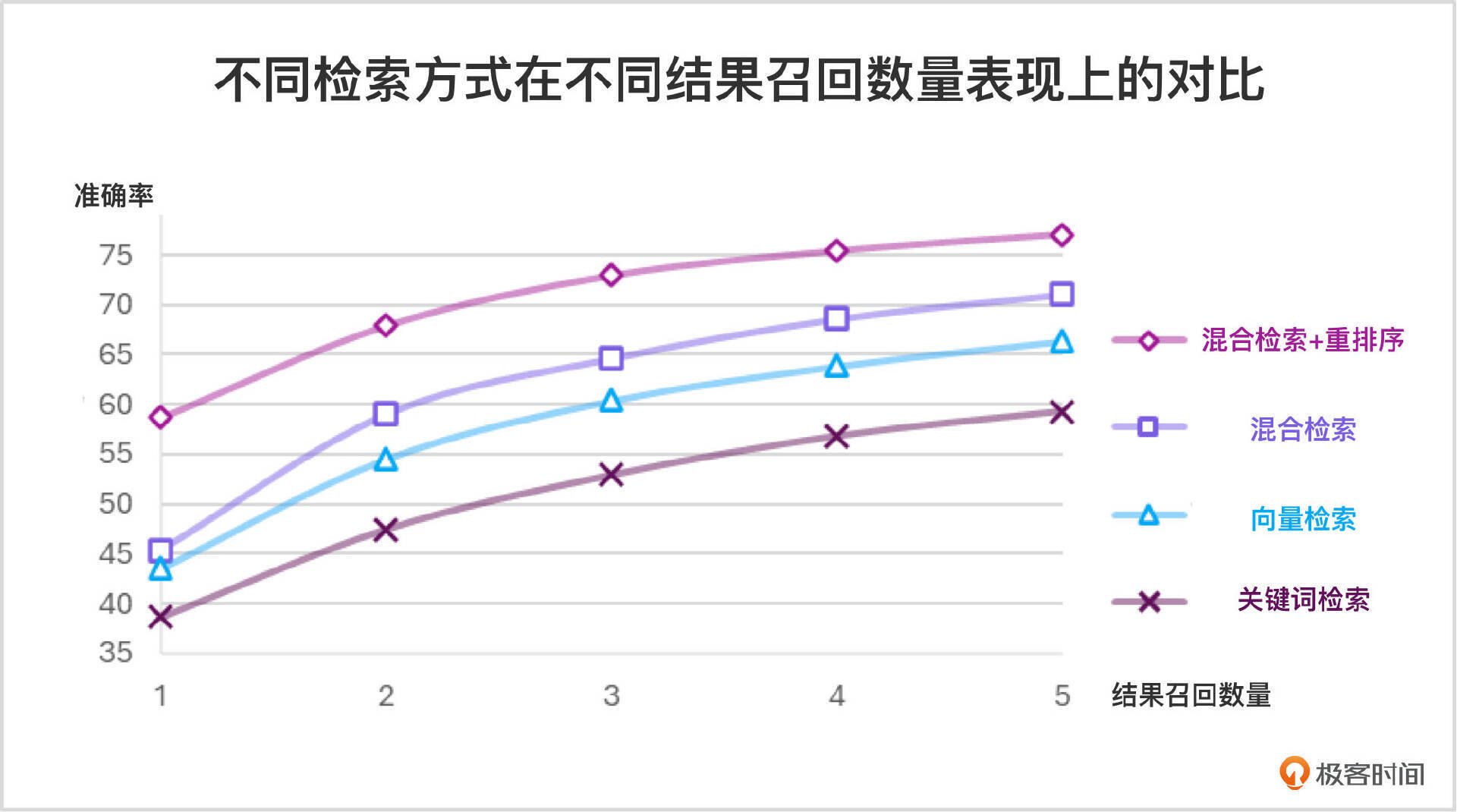
下图展示了在不同数量的文档块召回情况下,各种检索方式的效果对比。结果表明,混合检索结合重排序的方法显著提升了检索的有效性和准确性,远超单独依赖向量检索或关键词检索的传统方法。
混合检索(多路召回)
混合检索,又称融合检索/多路召回,是指在检索过程中同时采用多种检索方式,并将各类检索结果进行融合,从而得到最终的检索结果。混合检索的优势在于能够充分利用不同检索方式的优点,弥补各自的不足,从而提升检索的准确性和效率。下图展示了混合检索的流程:
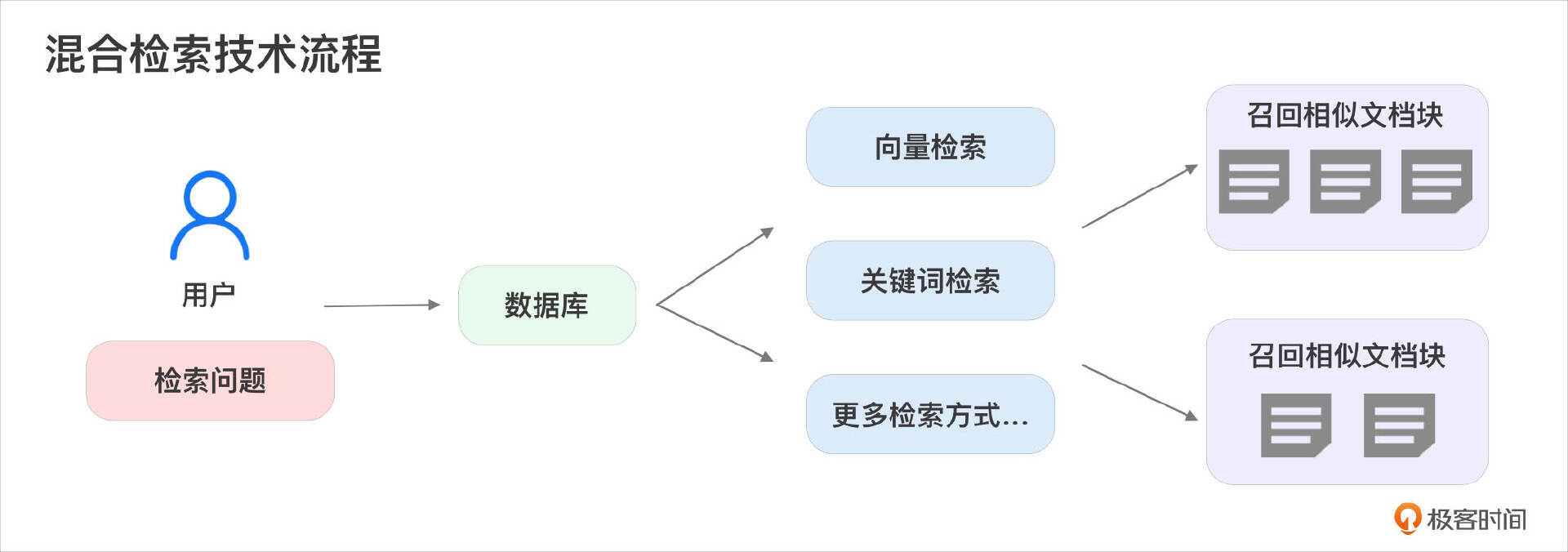
混合检索实际上并没有严格限定必须包含哪几种检索方式。这节课我们以向量检索和关键词检索的组合为例,但实际上可以包含多种检索方式的组合。如果我们将其他搜索算法结合在一起,也同样可以称为“混合检索”。例如,可以将知识图谱技术用于检索实体关系,并与向量检索技术相结合。
更多的 RAG 检索方式还包括多重提问检索、上下文压缩检索、集成检索、多向量检索、自查询检索等,每种检索方式说明如下:

上述方法均包含在 LangChain 的检索器模块 langchain_community.retrievers 中,具体详情可以查看 LangChain 检索器站点。
混合检索后,我们需要对多个检索方式的检索结果进行综合排名。这节课后半段会详细讲解重排序技术,但在此之前,我们可以使用一种更简单的方法来排序,称为递归折减融合(Reciprocal Rank Fusion, RRF)排序。RRF 是一种把来自不同检索方法的排名结果结合起来的技巧。它的基本思想是,如果一个文档在不同的检索结果中都排得比较靠前,那么它在综合排名中就应该得到更高的位置。
相比于复杂的重排序技术,RRF 的操作更加简单,不需要对每种检索结果进行复杂的调整或计算。它通过直接考虑文档在不同方法中的排名,快速生成一个合理的综合排名。这种方法非常适合那些需要快速融合多个检索结果的场景,短时间内得到一个有参考价值的排序。
选择何种检索技术,取决于开发者需要解决什么样的问题,系统的性能要求、数据的复杂性以及用户的搜索习惯等。针对具体需求选择合适的检索技术,能够最大化地提升RAG系统的效率和准确性。
混合检索技术实战
在实战中,我们使用 rank_bm25 作为 RAG 项目的关键词搜索技术。BM25是一种强大的关键词搜索算法,通过分析词频(TF)和逆向文档频率(IDF)来评估文档与查询的相关性。具体来说,BM25 检查查询词在文档中的出现频率,以及该词在所有文档中出现的稀有程度。如果一个词在特定文档中频繁出现,但在其他文档中较少见,那么 BM25 会将该文档评为高度相关。
此外,BM25 还通过调整文档长度的影响,防止因文档长度不同而导致的词频偏差。正是这种结合了词频和文档长度平衡的机制,使得 BM25 在关键词搜索中能够提供精准的检索结果,在 RAG 项目中尤为有效。
本课程代码中的注释将仅标注与这节课需要学习和掌握的内容。同时,开发环境将完整地展示在这节课的实战内容中,无需依赖之前课程的内容来追溯配置,实现单课时中即可运行的依赖库安装和代码。这部分的代码文件为 rag_app_lesson6_1.py。
下载本课程对应的 Gitee 上托管项目,若已下载,则需进入 rag_app 文件夹中执行 git pull 命令,拉取最新代码:
创建并激活虚拟环境,若已创建则无需重复执行:
命令行中拉取仓库的最新代码,执行依赖库安装命令,本课时对应的是 jieba 中文分词库和 rank_bm25 BM25 检索库:
source rag_env/bin/activate
pip install -U pip jieba rank_bm25 chromadb langchain langchain_community sentence-transformers dashscope unstructured pdfplumber python-docx python-pptx markdown openpyxl pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
代码中设置大模型qwen_model,qwen_api_key参数,访问阿里云百炼大模型服务平台获得。
执行课程代码:
本课程涉及的代码改动均已在 rag_app_lesson6_1.py 文件中添加详细注释,演示了如何结合向量检索与 BM25 检索来实现中文文本的检索功能,主要包括以下内容:
- 引入了 rank_bm25 库中的 BM25Okapi 类,用于实现 BM25 算法的检索功能。
- 引入了 jieba 库,用于对中文文本进行分词处理,这对于 BM25 算法处理中文文本起关键作用。
- 在 retrieval_process 方法中,从 Chroma 的 collection 中提取所有存储的文档内容,并使用 jieba 对这些文档进行中文分词,将分词结果存储为 tokenized_corpus,为后续的 BM25 检索做准备。
- 利用分词后的文档集合实例化 BM25Okapi 对象,并对查询语句进行分词处理。
- 计算查询语句与每个文档之间的 BM25 相关性得分 (bm25_scores),然后选择得分最高的前 top_k 个文档,并提取这些文档的内容。
- 返回合并后的全部检索结果,包含向量检索和 BM25 检索的结果。
在此代码实现中,没有使用混合检索的RRF(递归折减融合)排名,课程下半部分会对检索结果进行进一步的重排序,所以这节课直接返回了向量检索和 BM25 检索的结果,并按顺序合并,集中展示 BM25 关键词检索的代码实战。
具体代码改动如下:
引入依赖库:
from rank_bm25 import BM25Okapi # 从 rank_bm25 库中导入 BM25Okapi 类,用于实现 BM25 算法的检索功能
import jieba # 导入 jieba 库,用于对中文文本进行分词处理
retrieval_process方法:
def retrieval_process(query, collection, embedding_model=None, top_k=3):
query_embedding = embedding_model.encode(query, normalize_embeddings=True).tolist()
vector_results = collection.query(query_embeddings=[query_embedding], n_results=top_k)
# 从 Chroma collection 中提取所有文档
all_docs = collection.get()['documents']
# 对所有文档进行中文分词
tokenized_corpus = [list(jieba.cut(doc)) for doc in all_docs]
# 使用分词后的文档集合实例化 BM25Okapi,对这些文档进行 BM25 检索的准备工作
bm25 = BM25Okapi(tokenized_corpus)
# 对查询语句进行分词处理,将分词结果存储为列表
tokenized_query = list(jieba.cut(query))
# 计算查询语句与每个文档的 BM25 得分,返回每个文档的相关性分数
bm25_scores = bm25.get_scores(tokenized_query)
# 获取 BM25 检索得分最高的前 top_k 个文档的索引
bm25_top_k_indices = sorted(range(len(bm25_scores)), key=lambda i: bm25_scores[i], reverse=True)[:top_k]
# 根据索引提取对应的文档内容
bm25_chunks = [all_docs[i] for i in bm25_top_k_indices]
# 打印 向量 检索结果
print(f"查询语句: {query}")
print(f"向量检索最相似的前 {top_k} 个文本块:")
vector_chunks = []
for rank, (doc_id, doc) in enumerate(zip(vector_results['ids'][0], vector_results['documents'][0])):
print(f"向量检索排名: {rank + 1}")
print(f"文本块ID: {doc_id}")
print(f"文本块信息:\n{doc}\n")
vector_chunks.append(doc)
# 打印 BM25 检索结果
print(f"BM25 检索最相似的前 {top_k} 个文本块:")
for rank, doc in enumerate(bm25_chunks):
print(f"BM25 检索排名: {rank + 1}")
print(f"文档内容:\n{doc}\n")
# 合并结果,将 向量 检索的结果放在前面,然后是 BM25 检索的结果
combined_results = vector_chunks + bm25_chunks
print("检索过程完成.")
print("********************************************************")
# 返回合并后的全部结果,共2*top_k个文档块
return combined_results
为什么要使用重排序技术?
在RAG检索流程中,重排序技术(Reranking)通过对初始检索结果进行重新排序,改善检索结果的相关性,为生成模型提供更优质的上下文,从而提升整体RAG系统的效果。
尽管向量检索技术能够为每个文档块生成初步的相关性分数,但引入重排序模型仍然至关重要。向量检索主要依赖于全局语义相似性,通过将查询和文档映射到高维语义空间中进行匹配。然而,这种方法往往忽略了查询与文档具体内容之间的细粒度交互。
重排序模型大多是基于双塔或交叉编码架构的模型,在此基础上进一步计算更精确的相关性分数,能够捕捉查询词与文档块之间更细致的相关性,从而在细节层面上提高检索精度。因此,尽管向量检索提供了有效的初步筛选,重排序模型则通过更深入的分析和排序,确保最终结果在语义和内容层面上更紧密地契合查询意图,实现了检索质量的提升。
以下是使用重排序技术的几个优势:
- 优化检索结果
在 RAG 系统中,初始的检索结果通常来自于向量搜索或基于关键词的检索方法。然而,这些初始检索结果可能包含大量的冗余信息或与查询不完全相关的文档。通过重排序技术,我们可以对这些初步检索到的文档进行进一步的筛选和排序,将最相关、最重要的文档置于前列。
- 增强上下文相关性
RAG 系统依赖于检索到的文档作为生成模型的上下文。因此,上下文的质量直接影响生成的结果。重排序技术通过重新评估文档与查询的相关性,确保生成模型优先使用那些与查询最相关的文档,从而提高了生成内容的准确性和连贯性。
- 应对复杂查询
对于复杂的查询,初始检索可能会返回一些表面上相关但实际上不太匹配的文档。重排序技术可以根据查询的复杂性和具体需求,对这些结果进行更细致的分析和排序,优先展示那些能够提供深入见解或关键信息的文档。
重排序模型 Reranking Model
RAG流程有两个概念,粗排和精排。粗排检索效率较快,但是召回的内容并不一定强相关。而精排效率较低,因此适合在粗排的基础上进行进一步优化。精排的代表就是重排序(Reranking)。
重排序模型(Reranking Model)查询与每个文档块计算对应的相关性分数,并根据这些分数对文档进行重新排序,确保文档按照从最相关到最不相关的顺序排列,并返回前top-k个结果。
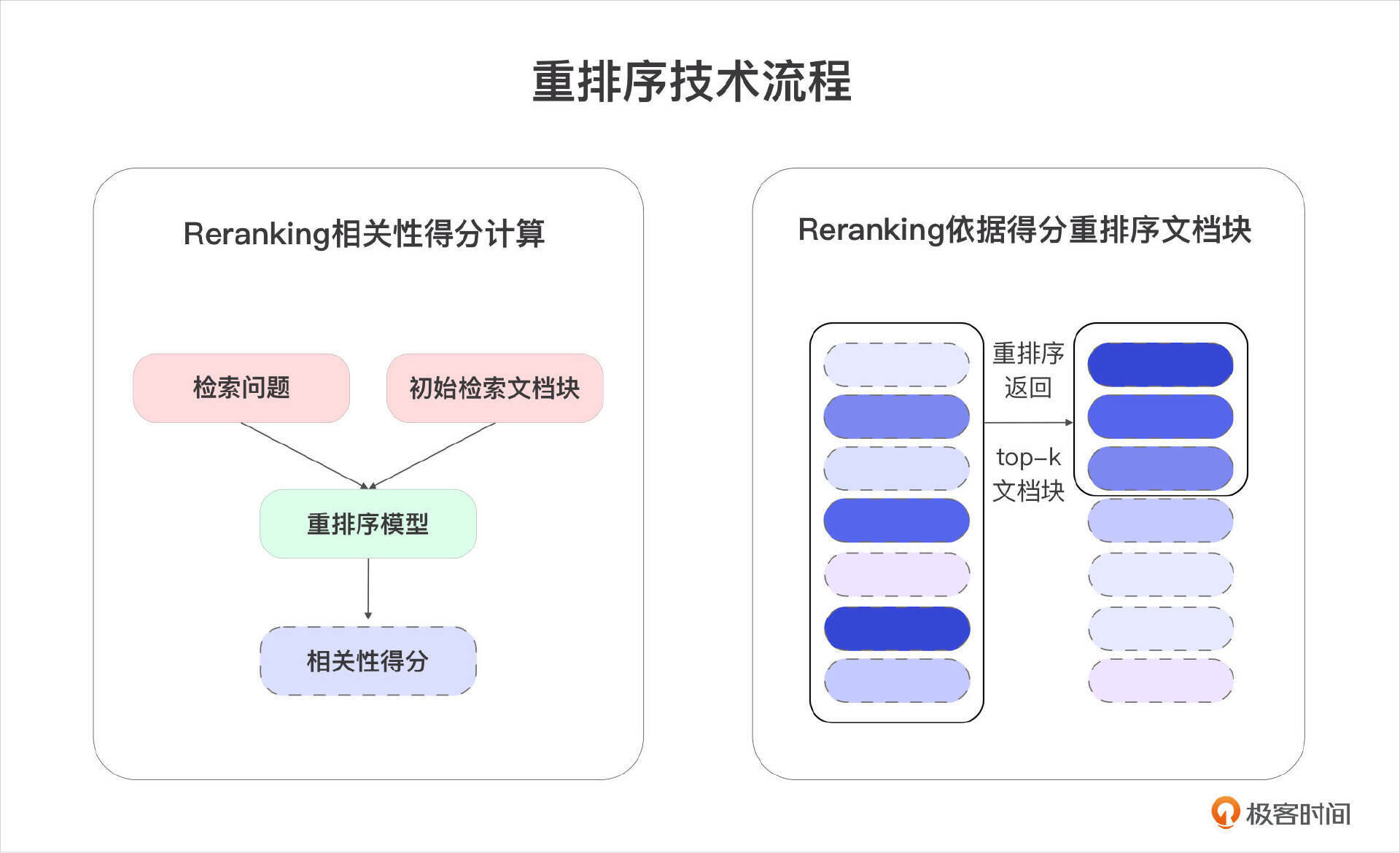
与嵌入模型不同,重排序模型将用户的查询(Query)和文档块作为输入,直接输出相似度评分,而非生成嵌入向量。目前,市面上可用的重排序模型并不多,商用的有Cohere,开源的有BGE、Sentence、Mixedbread、T5-Reranker等,甚至可以使用指令(Prompt)让大模型(GPT、Claude、通义千问、文心一言等)进行重排,大模型指令参考如下:
以下是与查询 {问题} 相关的文档块:
请根据这些文档块与查询的相关性进行排序,以 “1,2,3,4”(文档块数字及逗号隔开的形式),输出排序结果。
在生产环境中使用重排序模型会面临资源和效率问题,包括计算资源消耗高、推理速度慢以及模型参数量大等问题。这些问题主要源于重排序模型在对候选项进行精细排序时,因其较大参数量而导致的高计算需求和复杂耗时的推理过程,从而对 RAG 系统的响应时间和整体效率产生负面影响。因此,在实际应用中,需要根据实际资源情况,在精度与效率之间进行平衡。
重排序技术实战
在实战中,我们使用来自北京人工智能研究院 BGE 的 bge-reranker-v2-m3 作为 RAG 项目的重排序模型,这是一种轻量级的开源和多语言的重排序模型。更多模型相关信息参考,可访问 bge-reranker-v2-m3 官方介绍站点。
这部分的代码文件为 rag_app_lesson6_2.py。下载本课程对应的 Gitee 上托管项目,若已下载,则需进入 rag_app 文件夹中执行 git pull 命令,拉取最新代码:
创建并激活虚拟环境,若已创建则无需重复执行:
命令行中拉取仓库的最新代码,执行依赖库安装命令,本课时对应的是 FlagEmbedding 向量操作库和 Peft 大语言模型操作库:
source rag_env/bin/activate
pip install -U pip FlagEmbedding Peft jieba rank_bm25 chromadb langchain langchain_community sentence-transformers dashscope unstructured pdfplumber python-docx python-pptx markdown openpyxl pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
代码中设置大模型qwen_model,qwen_api_key参数,访问阿里云百炼大模型服务平台获得。
执行课程代码:
本课程涉及的代码改动均已在 rag_app_lesson6_2.py 文件中添加详细注释,主要包括以下内容:
- 引入 FlagEmbedding 库中的 FlagReranker 类,用于对嵌入结果进行重新排序的工具类。
- 增加 reranking 方法,对初始检索到的文档块进行重新排序。该方法初始化了使用 BAAI/bge-reranker-v2-m3 的 FlagReranker 模型,并通过计算每个 query 与 chunk 的语义相似性得分对文档块进行排序。最后,返回排名前 top_k 的文档块。
- 在 retrieval_process 方法中,新增了对检索结果进行重排序 reranking 的步骤,返回重排序后的前 top_k 个文档块。
具体代码改动如下:
引入依赖库:
增加reranking方法:
def reranking(query, chunks, top_k=3):
# 初始化重排序模型,使用BAAI/bge-reranker-v2-m3
reranker = FlagReranker('BAAI/bge-reranker-v2-m3', use_fp16=True)
# 构造输入对,每个 query 与 chunk 形成一对
input_pairs = [[query, chunk] for chunk in chunks]
# 计算每个 chunk 与 query 的语义相似性得分
scores = reranker.compute_score(input_pairs, normalize=True)
print("文档块重排序得分:", scores)
# 对得分进行排序并获取排名前 top_k 的 chunks
sorted_indices = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)
reranking_chunks = [chunks[i] for i in sorted_indices[:top_k]]
# 打印前三个 score 对应的文档块
for i in range(top_k):
print(f"重排序文档块{i+1}: 相似度得分:{scores[sorted_indices[i]]},文档块信息:{reranking_chunks[i]}\n")
return reranking_chunks
retrieval_process方法:
# 使用重排序模型对检索结果进行重新排序,输出重排序后的前top_k文档块
reranking_chunks = reranking(query,vector_chunks + bm25_chunks, top_k)
print("检索过程完成.")
print("********************************************************")
# 返回重排序后的前top_k个文档块
return reranking_chunks
总结
这节课我们讲解 RAG 检索流程,介绍了混合检索与重排序技术,通过代码实战巩固所学知识。课程代码已公开在Gitee代码仓库中,链接地址为:https://gitee.com/techleadcy/rag_app。
- 混合检索技术(Hybrid Search)
混合检索(多路召回),通过结合多种检索方式(向量检索、关键词检索等),利用各自的优势,确保最相关的结果能够出现在候选列表,以提升检索的准确性和全面性。经过实验验证,混合检索与重排序的组合取得了最佳表现。实战中采用 BM25 作为关键词搜索技术,结合向量搜索,获得混合搜索的检索结果。
- 重排序技术(Reranking)
重排序技术通过对初始检索结果进行重新排序,进一步提升检索结果的相关性,从而优化整体 RAG 系统的效果。不同于向量检索依赖全局语义相似性,重排序模型能够捕捉查询词与文档块之间更细微的相关性,从而找到最符合查询意图的文档块,实现检索质量的提升。在实际应用中,我们采用 bge-reranker-v2-m3 作为重排序模型,对初始检索到的文档块进行重新排序,并返回与查询语义最契合的 top_k 个文档块。
思考题
本节课程涵盖了混合检索技术和重排序技术两个关键知识点。对应这两个知识点,我给你留两道思考题。
- 在你的业务场景中,哪些查询需求更适合使用混合检索?在哪些细分场景中,关键词检索可能比向量检索表现出更显著的优势?
- 既然提到重排序模型的高资源消耗,分享一下在你的业务场景中,对 RAG 检索效果与效率的具体需求是什么级别?针对提高流程效率,你在研发过程中考虑了哪些优化方向?
欢迎你把你的经验和思考分享到留言区,和我一起讨论,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
- 冰炎 👍(3) 💬(2)
用bge-reranker-large重排后发现mrr值居然不如重排前直接使用bge和bm25混合检索得到的,不知道是哪里使用不当还是什么原因
2024-09-07 - xuwei 👍(2) 💬(1)
老师,咨询下,我实际项目中,用的是问答对。将问题embedding存入向量库,召回使用的混合召回。如果用bge-reranker-large,是将用户的原始问题和检索出来的问题放到模型里做重排吗?然后根据重排结果,找到对应的答案吗?
2024-10-09 - 王海 👍(2) 💬(1)
混合检索中的关键词检索可以换成 ES 实现吗?
2024-09-25 - kevin 👍(1) 💬(1)
老师课程中的代码为何不使用LangChain中,`EnsembleRetriever`组件实现混合检索呢?
2024-11-10 - king 👍(0) 💬(1)
老师请问下加载重排序模型无法加载,是啥原因:huggingface_hub.errors.LocalEntryNotFoundError: An error happened while trying to locate the file on the Hub and we cannot find the requested files in the local cache. Please check your connection and try again or make sure your Internet connection is on.
2024-12-09 - Grain Buds 👍(0) 💬(1)
请问为什么运行app_rag_lesson6_2.py ,在reranking阶段发生Bus error (core dumped)
2024-11-27 - Geek_8af4ba 👍(0) 💬(1)
第一张图,向量检索和关键词检索是不是画反了?
2024-09-20 - 张申傲 👍(2) 💬(0)
第6讲打卡~ 在LangChain中,可以使用`EnsembleRetriever`组件实现混合检索,支持指定检索器列表,并为每个检索器设置权重。
2024-10-24