03 RAG 索引(一):文档解析技术
本门课程为精品小课,不标配音频
你好,我是常扬。
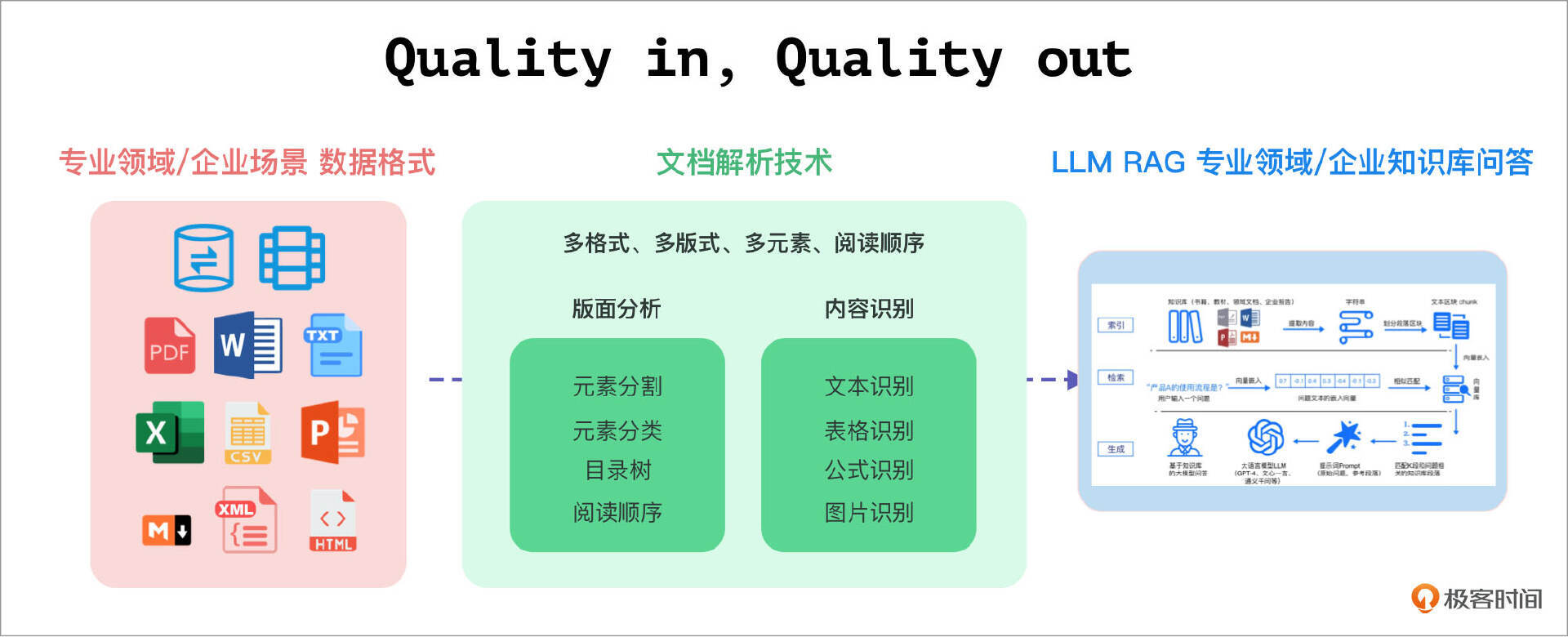
在之前的课程中,我们了解到,RAG(检索增强生成)系统的首要步骤是索引(Indexing)流程中的文档解析。文档解析技术的本质在于将格式各异、版式多样、元素多种的文档数据,包括段落、表格、标题、公式、多列、图片等文档区块,转化为阅读顺序正确的字符串信息。“Quality in, Quality out” 是大模型技术的典型特征,高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精准度的信息,对RAG系统最终的效果起决定性的作用。
RAG系统的应用场景主要集中在专业领域和企业场景。这些场景中,除了关系型和非关系型数据库,更多的数据以 PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML、HTML 等多种格式存储。尤其是PDF文件,凭借其统一的排版和多样化的结构形式,成为了最为常见的文档数据存储与交换格式。文档解析技术不仅需要支持上述所有常见格式,还需要特别强化对于PDF的解析能力,包括对电子档和扫描档的处理,支持多种版面形式的解析、不同类型版面元素的识别,并能够还原正确的阅读顺序。
此外,由于PDF文档往往篇幅巨大、页数众多,且企业及专业领域PDF文件数据量庞大,因此文档解析技术还需具备极高的处理性能,以确保知识库的高效构建和实时更新。
这节课我会先为你讲解各种文档格式的解析方法,并演示相关的代码。接下来,我将深入讲解PDF文件的解析,并提供针对性的技术方案分析。这节课的所有代码和示例文档将公开发布在Gitee项目中,rag_app_lesson3.py 代码基于第 02 讲中的 rag_app_lesson2.py 进行迭代更新。
LangChain Document Loaders 文档加载器
本课程示例RAG项目基于 LangChain 架构,提供在实际应用场景中常见文档格式的解析方案,涵盖 PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML 和 HTML 格式。鉴于 PDF 格式在实际应用中的使用占比最高,这节课的后半部分我们将对其进行深入讲解。
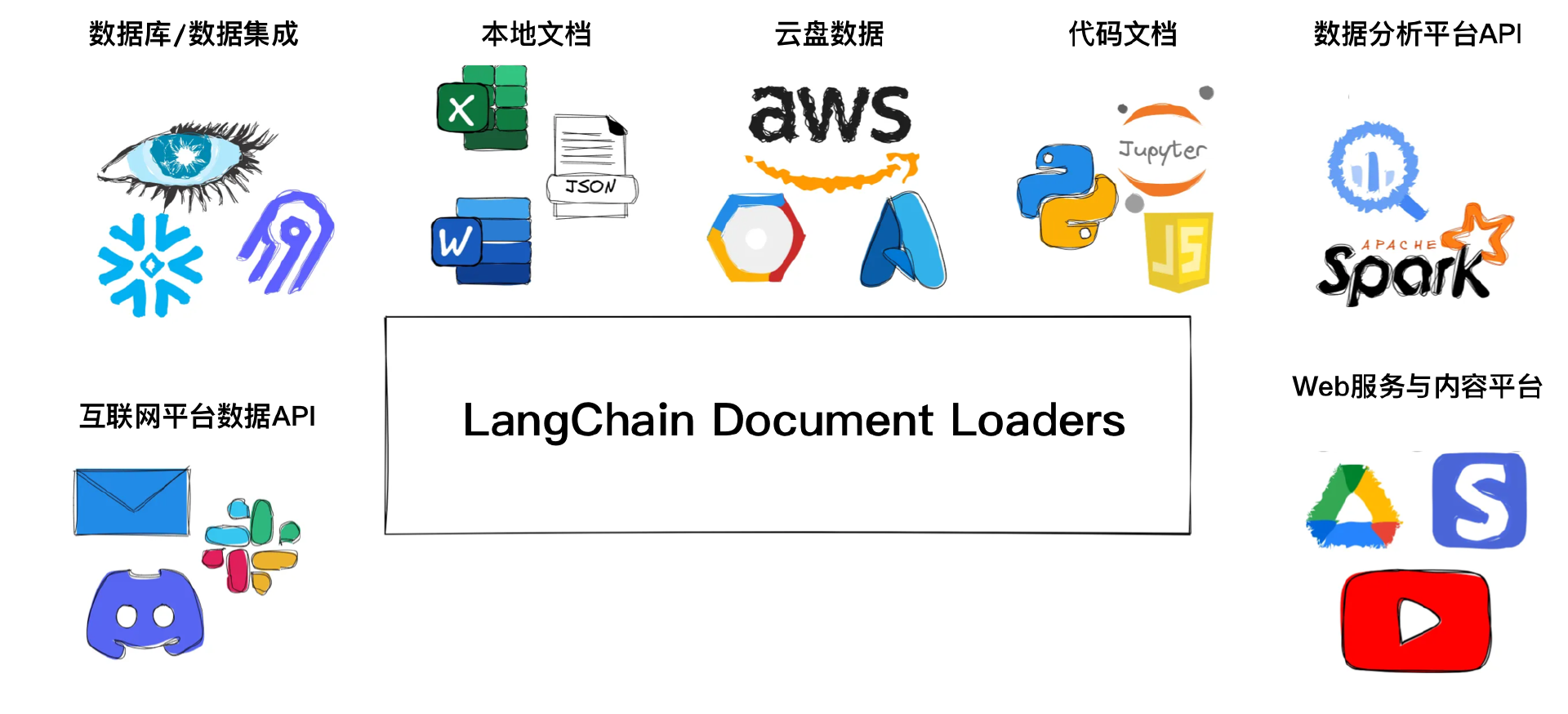
LangChain 提供了一套功能强大的文档加载器(Document Loaders),帮助开发者轻松地将数据源中的内容加载为文档对象。LangChain 定义了 BaseLoader 类和 Document 类,其中 BaseLoader 类负责定义如何从不同数据源加载文档,而 Document 类则统一描述了不同文档类型的元数据。
开发者可以基于 BaseLoader 类为特定数据源创建自定义加载器,并将其内容加载为 Document 对象。使用预构建的加载器比自行编写更加便捷。例如,PyPDF 加载器能够处理 PDF 文件,将多页文档分解为独立的、可分析的单元,并附带内容及诸如源信息、页码等重要元数据。
langchain_community 是 LangChain 与常用第三方库相结合的拓展库。各类开源库和企业库基于 BaseLoader 类在 langchain_community 库中扩展了不同文档类型的加载器,这些加载器被归类于 langchain_community.document_loaders 模块中。每个加载器都可以输入对应的参数,如指定文档解析编码、解析特定元素等,以及对 Document 类进行提取或检索等操作。目前,已有超过 160 种数据加载器,覆盖了本地文件、云端文件、数据库、互联网平台、Web 服务等多种数据源。详情可以在 LangChain 官网查看。
Document Loader 模块是封装好的各种文档解析库集成SDK,项目中使用还需要安装对应的文档解析库。例如,当我们项目中使用 from langchain_community.document_loaders import PDFPlumberLoader 时,需要先通过命令行 pip install pdfplumber 安装 pdfplumber 库。某些特殊情况下,还需要额外的依赖库,比如使用 UnstructuredMarkdownLoader 时,需要安装 unstructured 库来提供底层文档解析,还需要 markdown 库来支持 Markdown 文档格式更多能力。此外,对于像 .doc 这种早期的文档类型,还需要安装 libreoffice 软件库才能进行解析。
实际研发场景中,使用 Document Loader 文档加载器模块时,需要根据具体的业务需求编写自定义的文档后处理逻辑。针对业务需求,开发者可以自行编写和实现对不同文档内容的解析,例如对标题、段落、表格、图片等元素的特殊处理。在本课程的案例中,我们将从 Document 类中提取所有文本内容,进行下一步的文档分块处理。
多格式文档解析
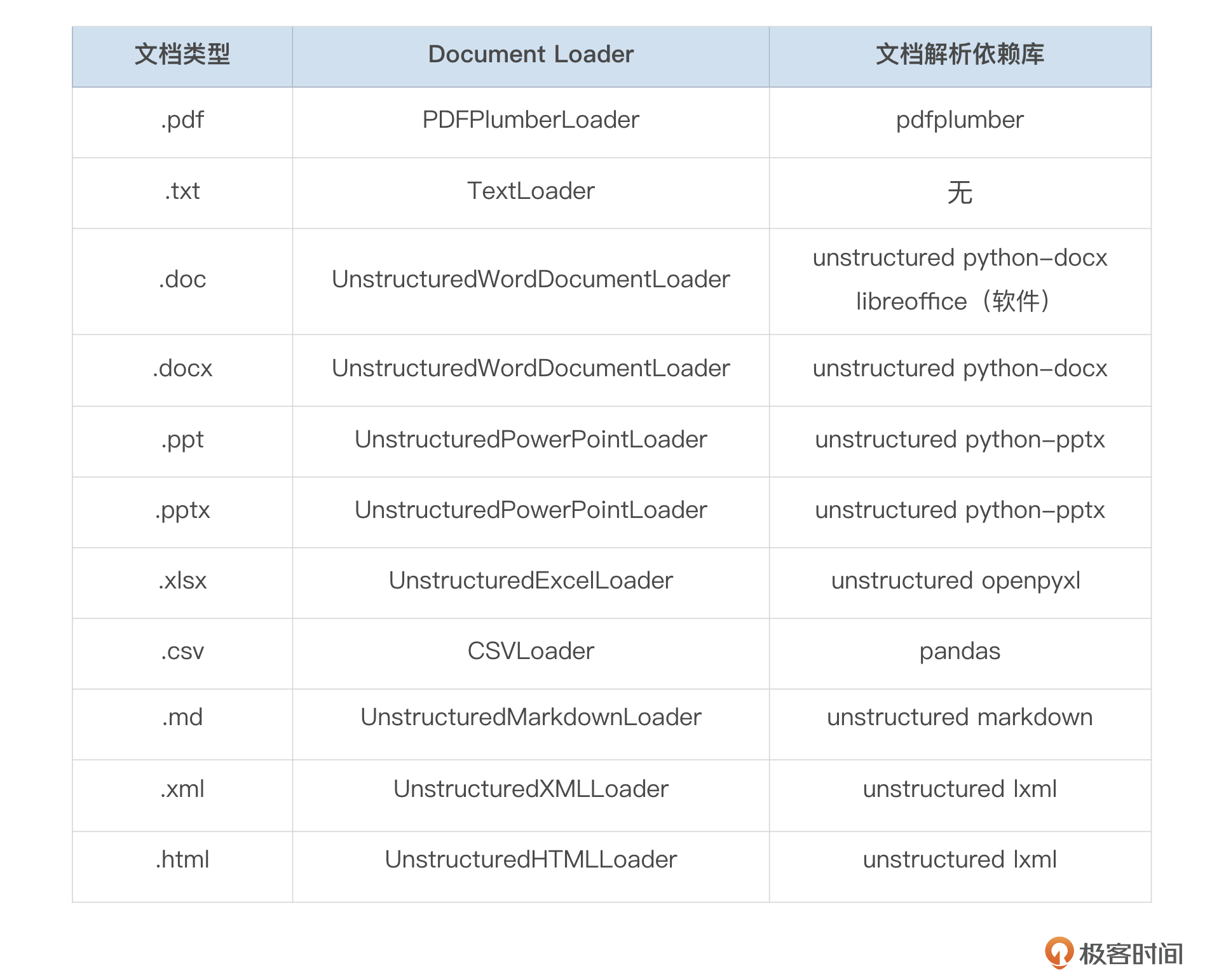
本次实战我们将解析不同类型的文档,其对应的 Document Loader 和所需的文档解析依赖库如下表所示:
关于开发环境以及 langchain 和 langchain_community 等库的安装和配置,我们已经在第 02 课中详细说明了。在执行以下指令之前,需要先完成第 02 课的实战内容。下面实战的代码更新在托管项目的 rag_app_lesson3.py 代码文件中。
在使用 Document Loader 之前,先在命令行中执行以下安装命令:
source rag_env/bin/activate # 激活虚拟环境
pip install unstructured pdfplumber python-docx python-pptx markdown openpyxl pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
安装 .doc 文件的支持软件 LibreOffice:
定义加载各种格式文档的方法,load_document:
from langchain_community.document_loaders import (
PDFPlumberLoader,
TextLoader,
UnstructuredWordDocumentLoader,
UnstructuredPowerPointLoader,
UnstructuredExcelLoader,
CSVLoader,
UnstructuredMarkdownLoader,
UnstructuredXMLLoader,
UnstructuredHTMLLoader,
) # 从 langchain_community.document_loaders 模块中导入各种类型文档加载器类
def load_document(file_path):
"""
解析各种文档格式的文件,返回文档内容字符串
:param file_path: 文档文件路径
:return: 返回文档内容的字符串
"""
# 定义文档解析加载器字典,根据文档类型选择对应的文档解析加载器类和输入参数
DOCUMENT_LOADER_MAPPING = {
".pdf": (PDFPlumberLoader, {}),
".txt": (TextLoader, {"encoding": "utf8"}),
".doc": (UnstructuredWordDocumentLoader, {}),
".docx": (UnstructuredWordDocumentLoader, {}),
".ppt": (UnstructuredPowerPointLoader, {}),
".pptx": (UnstructuredPowerPointLoader, {}),
".xlsx": (UnstructuredExcelLoader, {}),
".csv": (CSVLoader, {}),
".md": (UnstructuredMarkdownLoader, {}),
".xml": (UnstructuredXMLLoader, {}),
".html": (UnstructuredHTMLLoader, {}),
}
ext = os.path.splitext(file_path)[1] # 获取文件扩展名,确定文档类型
loader_tuple = DOCUMENT_LOADER_MAPPING.get(ext) # 获取文档对应的文档解析加载器类和参数元组
if loader_tuple: # 判断文档格式是否在加载器支持范围
loader_class, loader_args = loader_tuple # 解包元组,获取文档解析加载器类和参数
loader = loader_class(file_path, **loader_args) # 创建文档解析加载器实例,并传入文档文件路径
documents = loader.load() # 加载文档
content = "\n".join([doc.page_content for doc in documents]) # 多页文档内容组合为字符串
print(f"文档 {file_path} 的部分内容为: {content[:100]}...") # 仅用来展示文档内容的前100个字符
return content # 返回文档内容的多页拼合字符串
print(file_path+f",不支持的文档类型: '{ext}'") # 若文件格式不支持,输出信息,返回空字符串。
return ""
上述代码实现了解析多种文档格式并返回文档内容的字符串的方法 load_document。函数通过检查文件的扩展名 ext,动态选择合适的文档加载器 Document Loader,使用相应的加载器调用对应库读取文档内容 documents。支持的文档格式与对应的加载器类和参数在字典 DOCUMENT_LOADER_MAPPING 中进行了映射。根据文件的扩展名,函数会实例化对应的加载器,并将文档内容加载为字符串 content,支持多页文档的合并处理。
调整RAG索引流程方法,处理文件夹中所有类型的文档文件,indexing_process调整部分:
def indexing_process(folder_path, embedding_model):
"""
索引流程:加载文件夹中的所有文档文件,并将其内容分割成文档块,计算这些小块的嵌入向量并将其存储在Faiss向量数据库中。
:param folder_path: 文档文件夹路径
:param embedding_model: 预加载的嵌入模型
:return: 返回Faiss嵌入向量索引和分割后的文本块原始内容列表
"""
# 初始化空的chunks列表,用于存储所有文档文件的文本块
all_chunks = []
# 遍历文件夹中的所有文档文件
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
# 检查是否为文件
if os.path.isfile(file_path):
# 解析文档文件,获得文档字符串内容
document_text = load_document(file_path)
print(f"文档 {filename} 的总字符数: {len(document_text)}")
# 配置RecursiveCharacterTextSplitter分割文本块库参数,每个文本块的大小为512字符(非token),相邻文本块之间的重叠128字符(非token)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, chunk_overlap=128
)
# 将文档文本分割成文本块Chunk
chunks = text_splitter.split_text(document_text)
print(f"文档 {filename} 分割的文本Chunk数量: {len(chunks)}")
# 将分割的文本块添加到总chunks列表中
all_chunks.extend(chunks)
# 文本块转化为嵌入向量列表,normalize_embeddings表示对嵌入向量进行归一化,用于准确计算相似度
......省略未改动部分
return index, all_chunks
上述代码是在上一讲的 indexing_process 函数基础上进行了迭代,新增了批量处理多种格式文档文件的功能。调整部分为函数遍历文件夹中的所有文档文件,通过调用 load_document 获取文档的字符串内容,并将其切分为文本块 chunks,然后将所有文档的 chunks 汇总到一个总列表 all_chunks 中。当前的实现主要聚焦于文档解析技术,chunks 和对应的嵌入向量 index 暂时存储在内存中,持久化存储的部分将在后续的向量库课程中详细讲解。
测试脚本 main 函数对应调整:
# 索引流程:加载文件夹中各种格式文档,分割文本块,计算嵌入向量,存储在Faiss索引中(内存)
index, chunks = indexing_process('rag_app/data_lesson3', embedding_model)
先参照第02讲的大模型参数配置方法,配置 qwen_model 与 qwen_api_key 参数后,在命令行窗口中执行指令定位到具体的RAG项目文件夹,在命令行中执行以下指令即可开始RAG应用测试:
data_lesson3 文件夹内置了本课程涉及的所有格式的测试文档文件,所有文件的信息保持一致,旨在观察不同格式文档的解析效果。测试代码通过 main 函数串联各个步骤,索引流程将 data_lesson3 中所有的文档文件进行解析,准确完成“下面报告中涉及了哪几个行业的案例以及总结各自面临的挑战?”的RAG问答任务。
PDF文档解析
PDF文件在我们的业务场景中占有最高的比例,广泛应用于商业、学术和个人领域。尽管PDF文件的内容在表达图像、文字和表格信息,但其本质上是一系列显示和打印指令的集合。如下图所示,即使是一个仅包含 “Hello World” 文字的简单PDF,其文件内容也是一长串的打印指令。

PDF文件的显示效果不受设备、软件或系统的影响,但对计算机而言,它是一种非数据结构化的格式,储存的信息无法直接被理解。此外,大模型的训练数据中不包含直接的PDF文件,无法直接理解。
PDF解析,对于纯文本格式可以转换为文本字符串,而对于包含多种元素的复杂格式,选择 MarkDown 文件作为统一的输出格式最为合适。这是因为MarkDown文件关注内容本身,而非打印格式,能够表示多种文档元素内容。MarkDown格式被广泛接受于互联网世界,其信息能够被大模型理解。
PDF文件分为电子版和扫描版。PDF电子版可以通过规则解析,提取出文本、表格等文档元素。目前,有许多开源库可以支持,例如 pyPDF2、PyMuPDF、pdfminer、pdfplumber和papermage 等。这些库在 langchain_community.document_loaders 中基本都有对应的加载器,方便在不同场景下切换使用。
在基于规则的开源库中,pdfplumber对中文支持较好,且在表格解析方面表现优秀,但对双栏文本的解析能力较差;pdfminer和PyMuPDF对中文支持良好,但表格解析效果较弱;pyPDF2对英文支持较好,但中文支持较差;papermage集成了pdfminer和其他工具,特别适合处理论文场景。开发者可以根据实际业务场景的测试结果选择合适的工具,pdfplumber或pdfminer都是当前不错的选择。
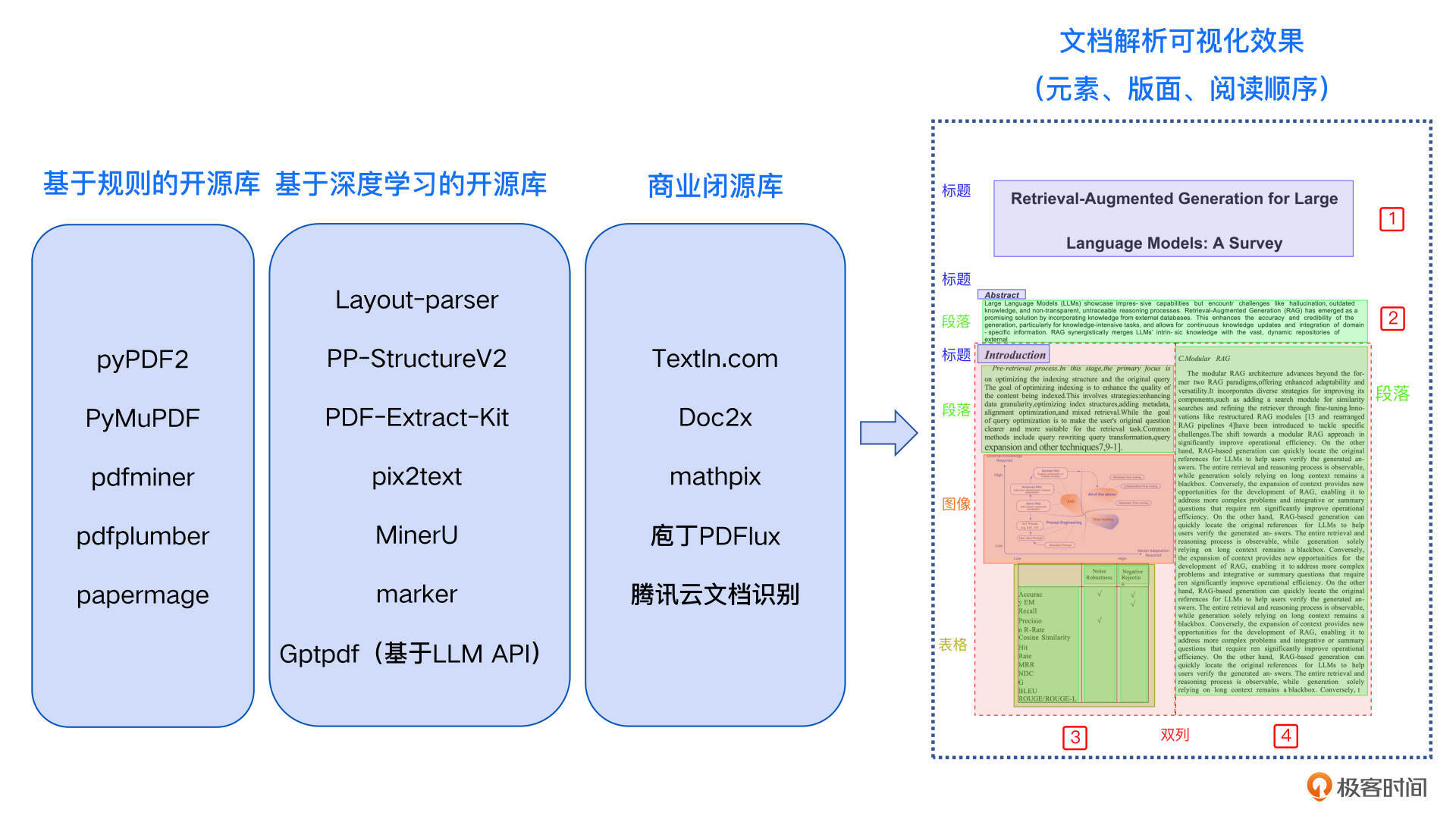
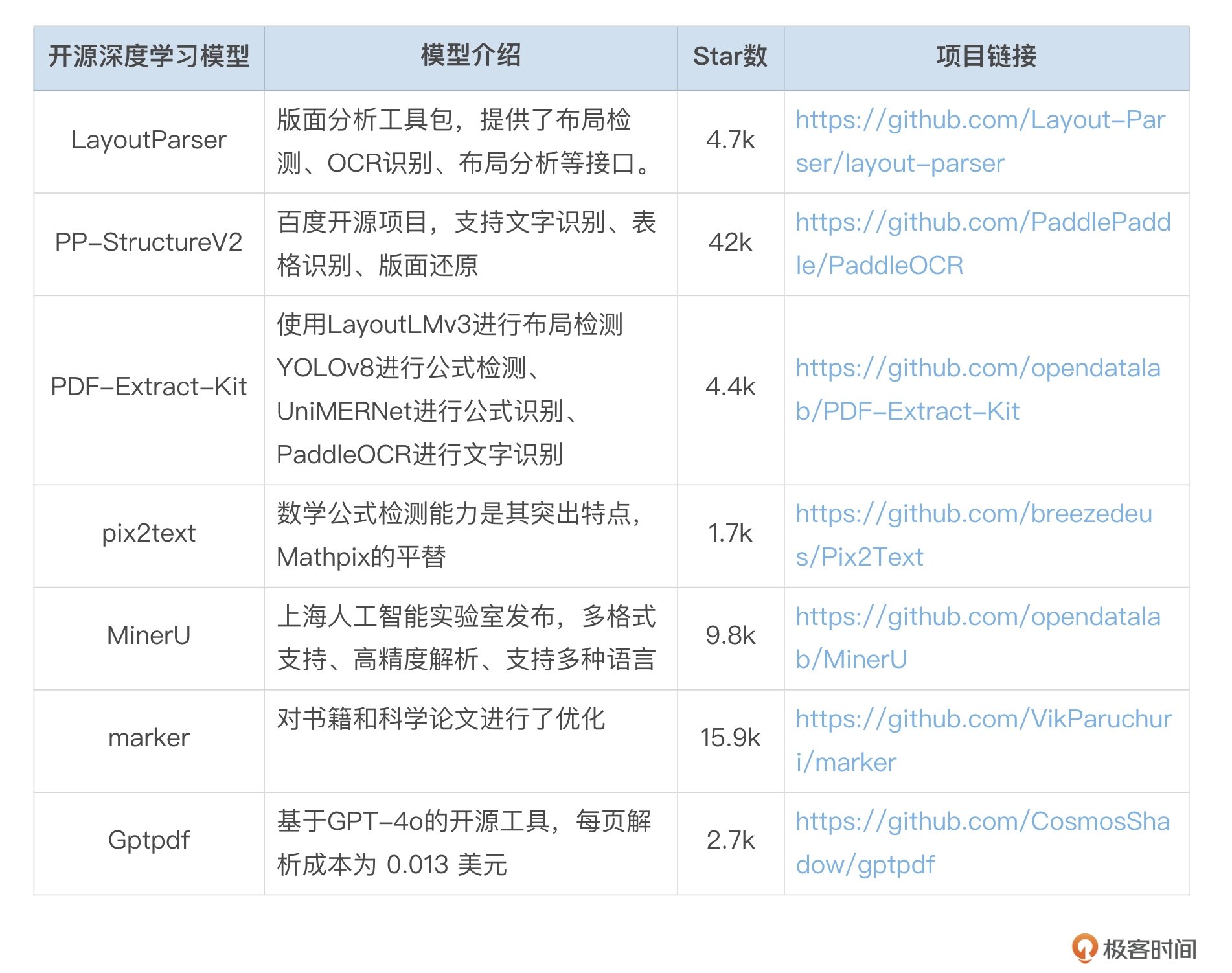
PDF扫描版需要经过文本识别和表格识别PDF扫描图像,才能提取出文档中的各类元素。同时要真正实现文档解析的目标,无论扫描版还是电子版均需进行版面分析和阅读顺序的还原,将内容解析为一个包含所有文档元素并且具有正确阅读顺序的MarkDown文件。单纯依赖规则解析是无法实现这一目标的,目前支持这些功能的多为基于深度学习的开源库,如 Layout-parser、PP-StructureV2、PDF-Extract-Kit、pix2text、MinerU、marker等。
然而,由于深度学习模型的部署复杂性以及对显卡配置的要求,这些库尚未集成在 langchain_community.document_loaders 中,使用时需要进行独立部署。我在下面列出了模型相关信息和GitHub链接,你可以根据业务需求进行选择和安装。
由于PDF文档解析整体流程用到了多个深度学习模型组合,真正在生产场景中会遇到效率问题。商业闭源库由于其部署的云端集群可以做并行处理和工程效率优化,所以在精度和效率上都能做到生产中的级别,比如TextIn.com、Doc2x、mathpix、庖丁PDFlux、腾讯云文档识别等,当然商业库会存在成本问题,你可以按需选择。
此外,还需要进一步探索PDF中的图像内容理解,不仅限于文字模态,还包括对图片中非文字内容的解析,如常见的折线图、柱状图等,也包含重要的内容信息。将这些内容转换为文字形式并嵌入到MarkDown文件中,通常需要依赖端到端的多模态大模型,如GPT-4o或Gemini。然而,目前这些模型在效率和成本方面仍存在挑战,但其未来潜力巨大,值得期待。
总结
这节课我们深入探讨了RAG索引流程中的文档解析技术,通过理论与实战代码展示了LangChain Document Loaders 文档加载器以及 PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML、HTML 多种格式的解析方法。同时我们对PDF文件的解析进行了进阶分析,涵盖了基于规则的开源库、基于深度学习的开源库,以及商业闭源库的技术说明与选型指南。最后说明了端到端的多模态大模型在文档解析领域应用和潜力。
选用适合业务场景的支持多格式、多版式、高精度、高效率的文档解析技术,是构建成功RAG系统的基础。相关代码已公开在Gitee 代码仓库中了,代码文件为 rag_app_lesson3.py。
思考题
在你的RAG系统所涉及的具体业务场景中,文档元素的类别识别是否有助于后续的文本分块和提升RAG系统的效果?如果有,请举例说明具体情况。欢迎你留言参与讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- Joney Hsiao 👍(1) 💬(2)
尝试过解析有图片的pdf文件,但是不理想,大模型输出“由于没有提供具体的图片内容,无法对图片进行分析。如果报告中有相关的图表或图像,请提供详细描述或上传图片,以便进一步分析。” 请问应该如何从哪点开始优化?
2024-12-30 - 张申傲 👍(1) 💬(1)
第3讲打卡~
2024-10-22 - Jaycee-张少同 👍(1) 💬(1)
实际工作场景中我认为pdf doc docx文件元素是构建字符切块的主要类型,另也可加入ppt演示文件内的文本字符。严格说我认为excel表格文件应当是份属db gpt的事情。不过事事无绝对,欢迎探讨
2024-09-03 - JMGAO 👍(0) 💬(2)
linux下解析文件类型pdf/txt/csv 能够成功,解析md/docx/ppt/xml/html等提示 zipfile.BadZipFile: File is not a zip file ``` File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/unstructured/partition/text_type.py", line 270, in exceeds_cap_ratio if sentence_count(text, 3) > 1: File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/unstructured/partition/text_type.py", line 219, in sentence_count sentences = sent_tokenize(text) File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/unstructured/nlp/tokenize.py", line 56, in sent_tokenize _download_nltk_packages_if_not_present() File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/unstructured/nlp/tokenize.py", line 41, in _download_nltk_packages_if_not_present tagger_available = check_for_nltk_package( File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/unstructured/nlp/tokenize.py", line 29, in check_for_nltk_package nltk.find(f"{package_category}/{package_name}", paths=paths) File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/nltk/data.py", line 551, in find return find(modified_name, paths) File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/nltk/data.py", line 538, in find return ZipFilePathPointer(p, zipentry) File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/nltk/data.py", line 391, in __init__ zipfile = OpenOnDemandZipFile(os.path.abspath(zipfile)) File "/root/workspace/mingjian/env_rag/lib/python3.10/site-packages/nltk/data.py", line 1020, in __init__ zipfile.ZipFile.__init__(self, filename) File "/usr/lib/python3.10/zipfile.py", line 1272, in __init__ self._RealGetContents() File "/usr/lib/python3.10/zipfile.py", line 1339, in _RealGetContents raise BadZipFile("File is not a zip file") ```
2025-01-06 - 大胡 👍(0) 💬(1)
另外,csv文件也存在一个gbk编码错误
2024-12-28 - 大胡 👍(0) 💬(1)
此处问题较多。下面是一个下载问题,有什么好办法吗? Resource punkt_tab not found. Please use the NLTK Downloader to obtain the resource: >>> import nltk >>> nltk.download('punkt_tab') For more information see: https://www.nltk.org/data.html Attempted to load tokenizers/punkt_tab/english/
2024-12-28 - Grain Buds 👍(0) 💬(1)
课程代码顺利跑通,但是生成结果准确性不足呢?生成回答中,有关金融业的部分并没有提取到,仅做了简略描述
2024-11-17 - Seachal 👍(0) 💬(1)
第3讲打卡~
2024-11-15 - kevin 👍(0) 💬(1)
在windows下运行,csv可以解析,但doc一解析系统就挂了,也不知道怎么回事,装了LibreOffice 24.8
2024-10-25 - 影明 👍(0) 💬(1)
在windows下运行,csv可以解析,但docx报错: 文档 ./data_lesson3\test.csv 的部分内容为: 案例名称: 制造业的数字化转型 公司背景: 制造业案例介绍了一家成立于20世纪初的德国老牌汽车制造公司,拥有悠久的历史和丰富的制造经验。面对日益激烈的市场竞争和消费者需求的变化,公司意识到传统制造模式... 文档 test.csv 的总字符数: 1262 文档 test.csv 分割的文本Chunk数量: 3 soffice failed to convert to format docx:MS Word 2007 XML with code 0 Error: source file could not be loaded Traceback (most recent call last): File "c:\Users\yingm\LAB\PycharmProjects\rag_app\rag_app_lesson3.py", line 238, in <module> main() File "c:\Users\yingm\LAB\PycharmProjects\rag_app\rag_app_lesson3.py", line 227, in main index, chunks = indexing_process('./data_lesson3', embedding_model) File "c:\Users\yingm\LAB\PycharmProjects\rag_app\rag_app_lesson3.py", line 93, in indexing_process document_text = load_document(file_path) File "c:\Users\yingm\LAB\PycharmProjects\rag_app\rag_app_lesson3.py", line 55, in load_document documents = loader.load() # 加载文档 ...... elements = func(*args, **kwargs) File "C:\Users\yingm\.conda\envs\rag_env_39\lib\site-packages\unstructured\partition\docx.py", line 160, in partition_docx opts = DocxPartitionerOptions.load( File "C:\Users\yingm\.conda\envs\rag_env_39\lib\site-packages\unstructured\partition\docx.py", line 222, in load return cls(**kwargs)._validate() File "C:\Users\yingm\.conda\envs\rag_env_39\lib\site-packages\unstructured\partition\docx.py", line 376, in _validate raise FileNotFoundError(f"no such file or directory: {repr(self._file_path)}") FileNotFoundError: no such file or directory: 'C:\\Users\\yingm\\AppData\\Local\\Temp\\tmpij10aiti\\test.docx'
2024-09-21 - grok 👍(3) 💬(2)
组里有个项目需要处理合同pdf(扫描件/英文),主要难点是夹杂的特殊字符和希腊字母。效果不达标。 已尝试: Adobe, Nitro, Azure Doc intelligence, GPT4o, ensemble of doc intelligence + gpt4o/V 下一步打算尝试: AWS Textract, Google Vision API, Nougat, Texify, Tesseract/pytesseract
2024-09-01