20 图像分割(下):如何构建一个图像分割模型?
你好,我是方远。
在上一节课中,我们掌握了图像分割的理论知识,你是不是已经迫不及待要上手体验一下,找找手感了呢?
今天我们就从头开始,来完成一个图像分割项目。项目的内容是,对图片中的小猫进行语义分割。为了实现这个项目,我会引入一个简单但实用的网络结构:UNet。通过这节课的学习,你不但能再次体验一下完整机器学习的模型实现过程,还能实际训练一个语义分割模型。
课程代码你可以从这里下载。
数据部分
我们还是从机器学习开发三件套:数据、训练、评估说起。首先是数据准备部分,我们先对训练数据进行标记,然后完成数据读取工作。
分割图像的标记
之前也提到过,图像分割的准备相比图像分类的准备更加复杂。那我们如何标记语义分割所需要的图片呢?在图像分割中,我们使用的每张图片都要有一张与之对应的Mask,如下所示:


上节课我们说过,Mask就是含有像素类别的特征图。结合这里的示例图片,我们可以看到,Mask就是原图所对应的一张图片,它的每个位置都记录着原图每个位置对应的像素类别。对于Mask的标记,我们需要使用到Labelme工具。
标记的方法一共包括七步,我们挨个看一下。
第一步,下载安装Labelme。我们按照Github中的安装方式进行安装即可。如果安装比较慢的话,你可以使用国内的镜像(例如清华的)进行安装。
第二步,我们要将需要标记的图⽚放到⼀个⽂件夹中。这里我是将所有猫的图片放入到cats文件夹中了。
第三步,我们事先准备好⼀个label.txt的⽂件,⾥⾯每⼀⾏写好的需要标记的类别。我的label.txt如下:
这里我要提醒你的是,前两行最好这么写。不这样写的话,使用label2voc.py转换就会报错,但label2voc.py不是唯一的数据转换方式(还可以使用labelme_json_to_dataset,但推荐你使用label2voc.py)。从第三行开始,表示要标记的类别。
第四步,执行后面的这条命令,就会自动启动Labelme。
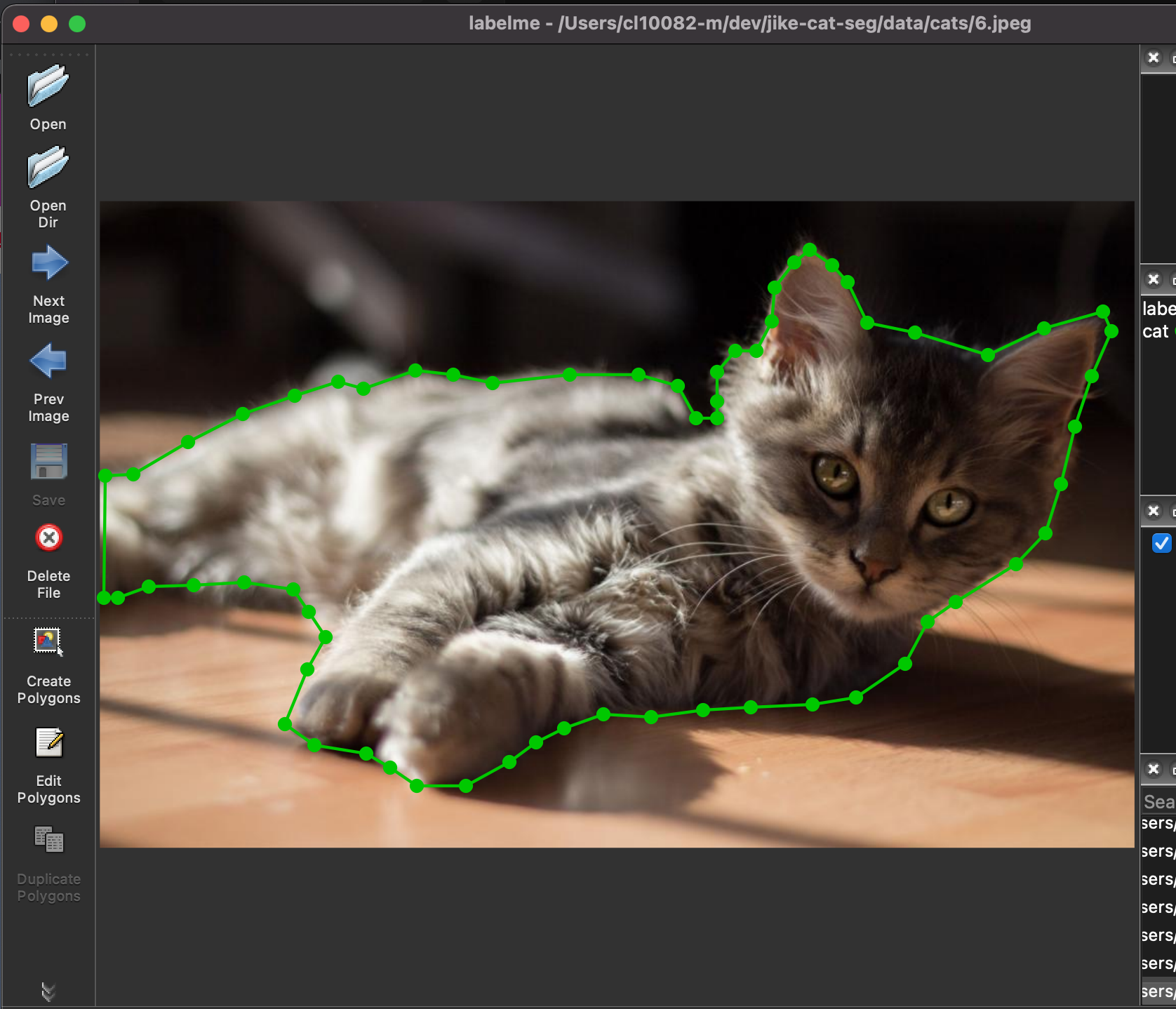
第五步,点我们击左侧的Open Dir,选择第二步中的文件夹,就会自动导入需要标记的图片。在右下角选择需要标记的文件后,会自动显示出来,如下图所示。

第六步:点击左侧的Create Polygons。就可以开始标注了。标记的方式就是将小猫沿着它的边界给圈出来,当形成一个闭环的时候,Labelme会自动提示你输入类别,我们选择cat类即可。
标记成功后,结果如下图所示。
当标记完成后,我们需要保存一下,保存之后会生成标记好的json文件。如下所示:
第七步,执行下面的代码,将标记好的数据转换成Mask。
上面代码里用到的label2voc.py,你可以通过后面这个链接获取它:https://github.com/wkentaro/labelme/blob/main/examples/semantic_segmentation/labelme2voc.py。
其中,cats为标记好的数据,cats_output为输出文件夹。在cats_output下会自动生成4个文件夹,我们只需要两个文件夹,分别是JPEGImages(训练原图)与SegmentationClassPNG(转换后的Mask)。
到此为止,我们的数据就准备好了。我一共标记了8张图片,如下所示。当然了,在实际的项目中需要大量标记好的图片,这里主要是为了方便演示。
到此为止,标记工作宣告完成。
数据读取
完成了标记工作之后,我们就要用PyTorch把这些数据给读入进来了,我们把数据相关的写在dataset.py中。具体还是和之前讲的一样,要继承Dataset类,然后实现__init__、__len__和__getitem__方法。
dataset.py的代码如下所示,我已经在代码中写好注释了,相信结合注释你很容易就能领会意思。
import os
import torch
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
class CatSegmentationDataset(Dataset):
# 模型输入是3通道数据
in_channels = 3
# 模型输出是1通道数据
out_channels = 1
def __init__(
self,
images_dir,
image_size=256,
):
print("Reading images...")
# 原图所在的位置
image_root_path = images_dir + os.sep + 'JPEGImages'
# Mask所在的位置
mask_root_path = images_dir + os.sep + 'SegmentationClassPNG'
# 将图片与Mask读入后,分别存在image_slices与mask_slices中
self.image_slices = []
self.mask_slices = []
for im_name in os.listdir(image_root_path):
# 原图与mask的名字是相同的,只不过是后缀不一样
mask_name = im_name.split('.')[0] + '.png'
image_path = image_root_path + os.sep + im_name
mask_path = mask_root_path + os.sep + mask_name
im = np.asarray(Image.open(image_path).resize((image_size, image_size)))
mask = np.asarray(Image.open(mask_path).resize((image_size, image_size)))
self.image_slices.append(im / 255.)
self.mask_slices.append(mask)
def __len__(self):
return len(self.image_slices)
def __getitem__(self, idx):
image = self.image_slices[idx]
mask = self.mask_slices[idx]
# tensor的顺序是(Batch_size, 通道,高,宽)而numpy读入后的顺序是(高,宽,通道)
image = image.transpose(2, 0, 1)
# Mask是单通道数据,所以要再加一个维度
mask = mask[np.newaxis, :, :]
image = image.astype(np.float32)
mask = mask.astype(np.float32)
return image, mask
然后,我们的训练代码写在train.py中,train.py中的main函数为主函数,在main中,我们会调用data_loaders来加载数据。代码如下所示:
import torch
from torch.utils.data import DataLoader
from torch.utils.data import DataLoader
from dataset import CatSegmentationDataset as Dataset
def data_loaders(args):
dataset_train = Dataset(
images_dir=args.images,
image_size=args.image_size,
)
loader_train = DataLoader(
dataset_train,
batch_size=args.batch_size,
shuffle=True,
num_workers=args.workers,
)
return loader_train
# args是传入的参数
def main(args):
loader_train = data_loaders(args)
以上就是数据处理的全部内容了。接下来,我们再来看看模型训练部分的内容。
模型训练
我们先来回忆一下,模型训练的老三样,分别是网络结构、损失函数和优化方法。
先从网络结构说起,今天我要为你介绍一个叫做UNet的语义分割网络。
网络结构:UNet
UNet是一个非常实用的网络。它是一个典型的Encoder-Decoder类型的分割网络,网络结构非常简单,如下图所示。

它的网络结构虽然简单,但是效果并不“简单”,我在很多项目中都用它与一些主流的语义分割做对比,而UNet都取得了非常好的效果。
整体网络结构跟论文中给出的示意图一样,我们重点去关注几个实现细节。
第一点,图中横向蓝色的箭头,它们都是重复的相同结构,都是由两个3x3的卷积层组合而成的,在每层卷积之后会跟随一个BN层与ReLU的激活层。按照第14节课讲的,这一部分重复的组织是可以单独提取出来的。我们先来创建一个unet.py文件,用来定义网络结构。
现在unet.py中创建Block类,它是用来定义刚才所说的重复的卷积块:
class Block(nn.Module):
def __init__(self, in_channels, features):
super(Block, self).__init__()
self.features = features
self.conv1 = nn.Conv2d(
in_channels=in_channels,
out_channels=features,
kernel_size=3,
padding='same',
)
self.conv2 = nn.Conv2d(
in_channels=features,
out_channels=features,
kernel_size=3,
padding='same',
)
def forward(self, input):
x = self.conv1(input)
x = nn.BatchNorm2d(num_features=self.features)(x)
x = nn.ReLU(inplace=True)(x)
x = self.conv2(x)
x = nn.BatchNorm2d(num_features=self.features)(x)
x = nn.ReLU(inplace=True)(x)
return x
这里需要注意的是,同一个块内,特征图的尺寸是不变的,所以padding为same。
第二点,就是绿色向上的箭头,也就是上采样的过程。这块的实现就是采用上一节课所讲的转置卷积来实现的。
最后一点,我们现在是要对小猫进行分割,也就是说一共有两个类别——猫与背景。对于二分类的问题,我们可以直接输出一张特征图,然后通过概率来进行判断是正例(猫)还是负例(背景),也就是下面代码中的第71行。同时,下述代码也补全了unet.py中的所有代码。
import torch
import torch.nn as nn
class Block(nn.Module):
...
class UNet(nn.Module):
def __init__(self, in_channels=3, out_channels=1, init_features=32):
super(UNet, self).__init__()
features = init_features
self.conv_encoder_1 = Block(in_channels, features)
self.conv_encoder_2 = Block(features, features * 2)
self.conv_encoder_3 = Block(features * 2, features * 4)
self.conv_encoder_4 = Block(features * 4, features * 8)
self.bottleneck = Block(features * 8, features * 16)
self.upconv4 = nn.ConvTranspose2d(
features * 16, features * 8, kernel_size=2, stride=2
)
self.conv_decoder_4 = Block((features * 8) * 2, features * 8)
self.upconv3 = nn.ConvTranspose2d(
features * 8, features * 4, kernel_size=2, stride=2
)
self.conv_decoder_3 = Block((features * 4) * 2, features * 4)
self.upconv2 = nn.ConvTranspose2d(
features * 4, features * 2, kernel_size=2, stride=2
)
self.conv_decoder_2 = Block((features * 2) * 2, features * 2)
self.upconv1 = nn.ConvTranspose2d(
features * 2, features, kernel_size=2, stride=2
)
self.decoder1 = Block(features * 2, features)
self.conv = nn.Conv2d(
in_channels=features, out_channels=out_channels, kernel_size=1
)
def forward(self, x):
conv_encoder_1_1 = self.conv_encoder_1(x)
conv_encoder_1_2 = nn.MaxPool2d(kernel_size=2, stride=2)(conv_encoder_1_1)
conv_encoder_2_1 = self.conv_encoder_2(conv_encoder_1_2)
conv_encoder_2_2 = nn.MaxPool2d(kernel_size=2, stride=2)(conv_encoder_2_1)
conv_encoder_3_1 = self.conv_encoder_3(conv_encoder_2_2)
conv_encoder_3_2 = nn.MaxPool2d(kernel_size=2, stride=2)(conv_encoder_3_1)
conv_encoder_4_1 = self.conv_encoder_4(conv_encoder_3_2)
conv_encoder_4_2 = nn.MaxPool2d(kernel_size=2, stride=2)(conv_encoder_4_1)
bottleneck = self.bottleneck(conv_encoder_4_2)
conv_decoder_4_1 = self.upconv4(bottleneck)
conv_decoder_4_2 = torch.cat((conv_decoder_4_1, conv_encoder_4_1), dim=1)
conv_decoder_4_3 = self.conv_decoder_4(conv_decoder_4_2)
conv_decoder_3_1 = self.upconv3(conv_decoder_4_3)
conv_decoder_3_2 = torch.cat((conv_decoder_3_1, conv_encoder_3_1), dim=1)
conv_decoder_3_3 = self.conv_decoder_3(conv_decoder_3_2)
conv_decoder_2_1 = self.upconv2(conv_decoder_3_3)
conv_decoder_2_2 = torch.cat((conv_decoder_2_1, conv_encoder_2_1), dim=1)
conv_decoder_2_3 = self.conv_decoder_2(conv_decoder_2_2)
conv_decoder_1_1 = self.upconv1(conv_decoder_2_3)
conv_decoder_1_2 = torch.cat((conv_decoder_1_1, conv_encoder_1_1), dim=1)
conv_decoder_1_3 = self.decoder1(conv_decoder_1_2)
return torch.sigmoid(self.conv(conv_decoder_1_3))
到这里,网络结构我们就搭建好了,然后我们来我看看损失函数。
损失函数:Dice Loss
这里我们来看一下语义分割中常用的损失函数,Dice Loss。
想要知道这个损失函数如何生成,你需要先了解一个语义分割的评价指标(但更常用的还是后面要讲的的mIoU),它就是Dice系数,常用于计算两个集合的相似度,取值范围在0-1之间。
Dice系数的公式如下。
$$Dice=\frac{2|P\cap G|}{|P|+|G|}$$
其中,$|P\cap G|$是集合P与集合G之间交集元素的个数,$|P|$和$|G|$分别表示集合P和G的元素个数。分子的系数2,这是为了抵消分母中P和G之间的共同元素。对语义分割任务而言,集合P就是预测值的Mask,集合G就是真实值的Mask。
根据Dice系数我们就能设计出一种损失函数,也就是Dice Loss。它的计算公式非常简单,如下所示。
$$Dice Loss=1-\frac{2|P\cap G|}{|P|+|G|}$$
从公式中可以看出,当预测值的Mask与GT越相似,损失就越小;当预测值的Mask与GT差异度越大,损失就越大。
对于二分类问题,GT只有0和1两个值。当我们直接使用模型输出的预测概率而不是使用阈值将它们转换为二值Mask时,这种损失函数就被称为Soft Dice Loss。此时,$|P\cap G|$的值近似为GT与预测概率矩阵的点乘。
定义损失函数的代码如下。
import torch.nn as nn
class DiceLoss(nn.Module):
def __init__(self):
super(DiceLoss, self).__init__()
self.smooth = 1.0
def forward(self, y_pred, y_true):
assert y_pred.size() == y_true.size()
y_pred = y_pred[:, 0].contiguous().view(-1)
y_true = y_true[:, 0].contiguous().view(-1)
intersection = (y_pred * y_true).sum()
dsc = (2. * intersection + self.smooth) / (
y_pred.sum() + y_true.sum() + self.smooth
)
return 1. - dsc
其中,self.smooth是一个平滑值,这是为了防止分子和分母为0的情况。
训练流程
最后,我们将模型、损失函数和优化方法串起来,看下整体的训练流程,训练的代码如下。
def main(args):
makedirs(args)
# 根据cuda可用情况选择使用cpu或gpu
device = torch.device("cpu" if not torch.cuda.is_available() else args.device)
# 加载训练数据
loader_train = data_loaders(args)
# 实例化UNet网络模型
unet = UNet(in_channels=Dataset.in_channels, out_channels=Dataset.out_channels)
# 将模型送入gpu或cpu中
unet.to(device)
# 损失函数
dsc_loss = DiceLoss()
# 优化方法
optimizer = optim.Adam(unet.parameters(), lr=args.lr)
loss_train = []
step = 0
# 训练n个Epoch
for epoch in tqdm(range(args.epochs), total=args.epochs):
unet.train()
for i, data in enumerate(loader_train):
step += 1
x, y_true = data
x, y_true = x.to(device), y_true.to(device)
y_pred = unet(x)
optimizer.zero_grad()
loss = dsc_loss(y_pred, y_true)
loss_train.append(loss.item())
loss.backward()
optimizer.step()
if (step + 1) % 10 == 0:
print('Step ', step, 'Loss', np.mean(loss_train))
loss_train = []
torch.save(unet, args.weights + '/unet_epoch_{}.pth'.format(epoch))
需要注意的点,我都在注释中进行了说明,你可以自己看一看。其实就是我们一直说的模型训练的那几件事情:数据加载、构建网络以及迭代更新网络参数。
我用训练数据训练了若干个Epoch,同时也保存了若干个模型,保存为pth格式。到这里就完成了模型训练的整个环节,我们可以使用保存好的模型进行预测,来看看分割效果如何。
模型预测
现在我们要用训练生成的模型来进行语义分割,看看结果是什么样子的。
模型预测的代码如下。
import torch
import numpy as np
from PIL import Image
img_size = (256, 256)
# 加载模型
unet = torch.load('./weights/unet_epoch_51.pth')
unet.eval()
# 加载并处理输入图片
ori_image = Image.open('data/JPEGImages/6.jpg')
im = np.asarray(ori_image.resize(img_size))
im = im / 255.
im = im.transpose(2, 0, 1)
im = im[np.newaxis, :, :]
im = im.astype('float32')
# 模型预测
output = unet(torch.from_numpy(im)).detach().numpy()
# 模型输出转化为Mask图片
output = np.squeeze(output)
output = np.where(output>0.5, 1, 0).astype(np.uint8)
mask = Image.fromarray(output, mode='P')
mask.putpalette([0,0,0, 0,128,0])
mask = mask.resize(ori_image.size)
mask.save('output.png')
这段代码也很好理解。首先,用torch.load函数加载模型。接着加载一张待分割的图片,并进行数据预处理。然后将处理好的数据送入模型中,得到预测值output。最后将预测值转化为可视化的Mask图片进行保存。
输入图片也就是待分割的图片,如下左图所示。最终的输出,即可视化的Mask图片如下右图所示。

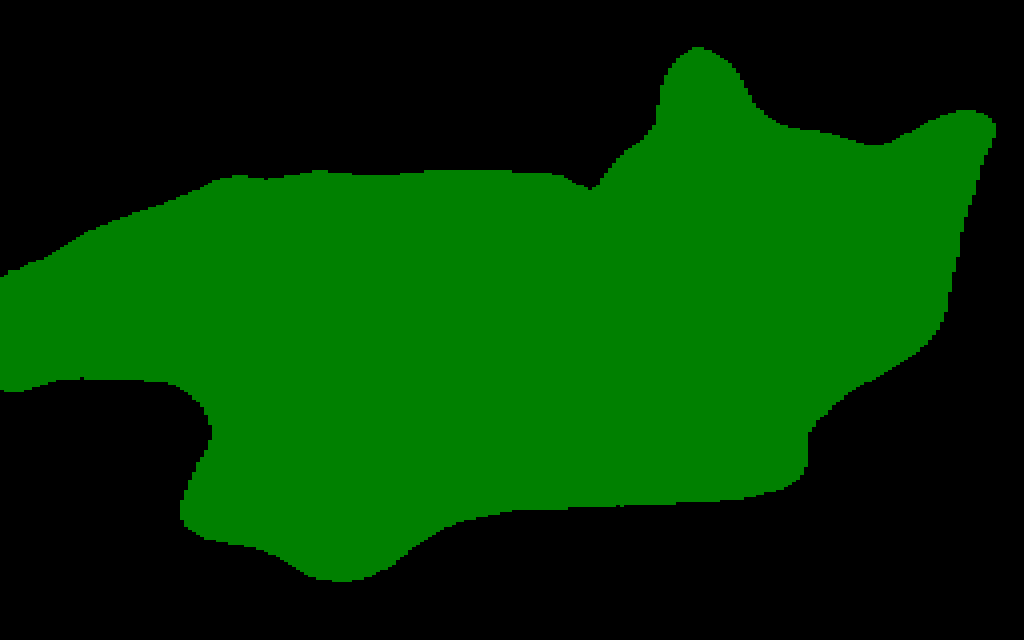 }{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"
在将预测值转化为Mask图片的过程中,最终预测值的概率卡了0.5的阈值,超过阈值的像素点,在output矩阵中的值为1,表示猫的区域,没有超过阈值的像素点,在output矩阵中的值为0,表示背景区域。
为了将output矩阵输出为可视化的图像,我们使用Image.fromarray函数,将Numpy的array转化为Image格式,并将模式设置为“P”,即调色板模式。然后用putpalette函数来给Image对象上色。
其中,putpalette函数的参数是一个列表:[0, 0, 0, 0, 128, 0],列表前三个数表示值为0的像素的RGB([0, 0, 0]表示黑色),列表后三个数表示值为1的像素的RGB([0, 128, 0]表示绿色)。这样,我们保存的Mask图片,黑色部分即为背景区域,绿色部分即为猫的区域。
不过,这样分开的轮廓图,可能无法让我们很直观地看出语义分割的效果。所以我们将原图和Mask合成一张图片来看看效果。具体的代码如下。
image = ori_image.convert('RGBA')
mask = mask.convert('RGBA')
# 合成
image_mask = Image.blend(image, mask, 0.3)
image_mask.save("output_mask.png")
首先,我们将原图image和Mask图片都转换为’RGBA’带透明度的模式。然后使用Image.blend函数将两张图片合成一张图片,最后一个参数0.3表示Mask图片透明度为30%,原图的透明度为70%。 最终的结果如下图所示。

这样我们就可以直观地看出哪些地方预测得不准确了。
模型评估
在语义分割中,常用的评价指标是mIoU。mIoU全称为mean Intersection over Union,即平均交并比。交并比是真实值和预测值的交集和并集之比。
真实值就是我们刚刚用labelme标注的Mask,也是Ground Truth(GT)。如下左图所示。
预测值就是模型预测出的Mask,用Prediction表示。如后面右图所示。

 }{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"
交集是指真实值与预测值的交集,如下图黄色区域所示。并集是指真实值与预测值的并集,如下图蓝色区域所示。

通过上面几个图,我们很容易就能理解mIoU了。mIoU的公式如下所示。
$$mIoU=\frac{1}{k}\sum_{i=1}^{k}{\frac{P\cap G}{P\cup G}}$$
其中,k为所有类别数,在我们的例子中,只有“cat”一类,因此k为1,我们通常不将背景计算到mIoU中;P为预测值;G是真实值。
小结
恭喜你,完成了今天的学习任务。这节课我们一起完成了一个图像分割项目的实践。
首先,我带你了解了图像分割的数据准备,需要使用Labelme工具为图像做标记。数据质量的好坏决定了最终模型的质量,所以你要对数据的标注好好把握。在使用Labelme标记完成之后,我们可以使用label2voc.py将json转换为Mask。
之后我们学习了一种非常高效且实用的模型–UNet,并使用PyTorch实现了其网络结构。
然后,我为你讲解了图像分割的评估指标mIoU和损失函数Dice Loss。
mIoU的公式如下:
$$mIoU=\frac{1}{k}\sum_{i=1}^{k}{\frac{P\cap G}{P\cup G}}$$
mIoU主要是从预测结果与GT的重合度这一角度,来衡量分割模型的好与坏的,它是图像分割中经常使用的评价指标。
最后,我们使用训练好的模型进行预测,并对分割结果进行了可视化绘制。相信通过之前学习的图像分类项目与今天学习的图像分割项目,对于图像处理,你会获得更深层次的理解。
每课一练
你可以根据今天的内容,自己动手试试建立一个图像分割模型,然后用一张图片来测一下效果如何。
欢迎你在留言区跟我交流讨论,也推荐你把今天的内容分享给更多同事、朋友,我们下节课见。
- 克bug体质 👍(5) 💬(4)
老师你好,Loss也要放到放到gpu后也会报和之前一样的错误:【 Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument weight in method wrapper__cudnn_batch_norm) File "D:\U-Net\unet.py", line 25, in forward x = nn.BatchNorm2d(num_features=self.features)(x) File "D:\U-Net\unet.py", line 67, in forward conv_encoder_1_1 = self.conv_encoder_1(x) File "D:\U-Net\train.py", line 50, in main y_pred = unet(x) File "D:\U-Net\train.py", line 136, in <module> main(args) 】 我尝试在unet.py文件中的创建class UNet中self.conv_encoder_1 = Block(in_channels, features)改为:self.conv_encoder_1 = Block(in_channels, features).to(device)后也没解决这个问题,会报一样的错。
2022-02-14 - vcjmhg 👍(3) 💬(2)
老师您好,我自己有尝试复现deeplab v3+这个比较主流的语义分割网络,然后发现针对一些尺寸较大的目标其分割效果还是比较不错的,但是对小的目标分割效果很差,甚至好多时候都分割不到,请问针对这种小目标,除了在数据集上做处理外,还有哪些好的处理或者优化方法呢?
2021-11-27 - .................. 👍(2) 💬(1)
真的很棒,我要亲手操作一遍
2022-05-06 - 蓝色天空 好萌啊 👍(1) 💬(1)
老师你好,请问有这节课的完整代码地址吗?
2022-01-21 - Geek_a95f0e 👍(1) 💬(2)
方老师,可不可以解释一下自定义类中 super().__init__() 和super(class_name,self).__init__() 有什么区别?
2021-12-13 - Geek_niu 👍(0) 💬(1)
老师你好,请问数据准备中,标记好的图片有什么作用呢,谢谢
2024-03-05 - 学渣汪在央企打怪升级 👍(0) 💬(2)
老师你好,非常感谢老师的耐心,我成功的跑通了自己的一个实例。但目前遇到如下问题,麻烦老师有空的时候能提点一下。 使用unet训练,还是老师的代码,差不多是40 epoch之后,预测出来的图像分割,预测对的点的概率非常集中,大概都在[1,...,0.99999535 0.9999949 0.9999943 0.9999933 0.999992 0.9999907 0.9999889 0.99998796 0.99998724 0.9999856 0.99998343 0.99998116 0.99997723 0.99997675 0.9999764 0.9999703 0.9999577 0.9999535 0.9999486 0.9999453 0.999944 0.99992955 0.99992025 0.9999181 0.9999089 0.9999058 0.9998952 0.99984705 0.9998202 0.9996326 0.9996008 0.9995078 0.99922884 0.9967386 0.99539775 0.995391 0.991197 0.9906724 0.9892915 0.9892553 0.9782649 0.96968466 0.95937544 0.9416338 0.93462884 0.91682875 0.8949944 0.87671226 0.75603426 0.7475551 0.7284518 0.6420492 0.62891126 0.5325708 0.52544403, ... ] 请教一下,这样是不是过拟合了。有没有什么好的方法可以使得预测概率有阈值可选?丰富样本吗?麻烦老师了。
2022-11-29 - 学渣汪在央企打怪升级 👍(0) 💬(1)
方老师,请教一下: 如果我不是对图片进行语义分割,而是对类似视频,比如(400,384,288)的数据立方体进行语义分割,还可以使用unet吗?如果使用的话,这个示例里的通道数是从3->512->32->1,那么这种400通道的该怎么处理? 谢谢。
2022-10-30 - gavin 👍(0) 💬(1)
方老师,请问一下如果是多分类,特征图输出要怎么弄?
2022-09-16 - John(易筋) 👍(0) 💬(1)
predict_single.py 代码改了一下文件的相对路径可以跑通,发现output.jpg 大小为256x256. 原图微1024x640. 请教方老师,为啥语义分割出来的图片不是原始图片的等比缩小呢? 谢谢 ``` import torch import numpy as np from PIL import Image img_size = (256, 256) unet = torch.load('./ckpts/unet_epoch_51.pth') unet.eval() im = np.asarray(Image.open('./data/JPEGImages/6.jpg').resize(img_size)) im = im / 255. im = im.transpose(2, 0, 1) im = im[np.newaxis, :, :] im = im.astype('float32') output = unet(torch.from_numpy(im)).detach().numpy() output = np.squeeze(output) output = np.where(output>0.5, 150, 0).astype(np.uint8) print(output.shape, type(output)) im = Image.fromarray(output) im.save('./output.jpg') ```
2022-08-23 - 万化8af10b 👍(0) 💬(2)
请问/weights/unet_epoch_51.Pth找不到,谢谢
2022-07-03 - zhangting 👍(0) 💬(1)
老师,这个猫的数据集可以分享一下么?
2022-05-30 - Geek_709f77 👍(0) 💬(1)
lebelme那个github上的zip包下载后怎么解压的时候报文件已损坏啊?
2022-04-07 - Cougar 👍(0) 💬(1)
self.image_slices.append(im / 255.) 请问这里为什么要除以一个255呢
2022-03-31 - dndidoflbup 👍(0) 💬(1)
老师好,对于输入图片的尺寸有要求么,我自己用900*900的学习,报错如下: conv_decoder_3_2 = torch.cat((conv_decoder_3_1, conv_encoder_3_1), dim=1) RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 224 but got size 225 for tensor number 1 in the list.
2022-01-10