你好,我是方远。
好久不见,我想最近我们每个人都可以感受到AI行业发生着巨大的变化,似乎有点当年iPhone4问世的那种感觉。在这次行业变迁的主角就是最近被提出的基础模型。我们现在聊得最多的ChatGPT,就是一个典型的代表。
如果我们把ChatGPT比作一款应用软件的话,那么基础模型就相当于运行它的操作系统。这次加餐,我们就来聊聊基础模型以及它的代表模型。了解了这些,你将会对新的AI研究有更加宏观深入的理解。
基础模型Foundation model
在2021年,斯坦福大学的学者在论文 On the Opportunities and Risks of Foundation Models 中,以基础模型(Foundation Model)来命名这样的模型。
论文中给出的定义是这样的。
A foundation model is any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks
意思就是说,基础模型是利用大量数据进行训练,可以在广泛的下游任务中通过微调等手段进行应用的模型。
当我们有了某个领域中的基础模型时,就可以通过微调、迁移学习或者零样本学习直接将其应用到一个新的子任务中。
不难看出,基础模型具有超高的表现力以及广泛的应用,似乎有种包罗万象的感觉,这主要得益于基础模型是使用多样和大规模数据进行训练的大型模型。
这意味着我们的工作模式正在发生改变。曾经当我们要开发某一模型时,首先要准备对应的数据(通常来说是需要人工标注的),然后设计模型、训练模型与评估模型。
事实上,在这一套流程里,无论是在开发还是运营的成本上都存在着很多制约的因素。除此之外,即使我们在一个特定任务中训练出了一个模型,当数据的分布发生变化时,模型的效果往往都会变得非常差。
而如今的基础模型完全不需要这样了,基础模型仅仅需要少量数据即可满足各种任务的需求,不需要针对特定任务进行定制,因此对于分布外数据的预测性能更加鲁棒。
简单来说,有了基础模型,就可以把原先“单一任务,单一模型”转变为“多样任务,通用模型”,无需再为每个任务单独设计模型。后面这张图就很好地概括了基础模型。

那么,为什么基础模型可以做到这些呢?同样,论文中给出了这样的回答。
Transfer learning is what makes foundation models possible, but scale is what makes them powerful. Scale required three ingredients: (i) improvements in computer hardware — e.g., GPU throughput and memory have increased 10× over the last four years (§4.5: systems); (ii) the development of the Transformer model architecture [Vaswani et al. 2017] that leverages the parallelism of the hardware to train much more expressive models than before (§4.1: modeling); and (iii) the availability of much more training data
归纳一下,就是说基础模型成为可能,主要有三个原因。
1.算力的提升 2.Transformer技术的提升 3.大规模数据的活用
此外,对于基础模型的性能,scaling这个概念也是至关重要的。对于scaling来说,迭代次数、数据规模和参数量这三个变量是非常重要的。

通过前面的实验截图也可以看到,随着这三个变量的增大,基础模型的性能会提高。这三个变量也是如今高性能AI模型的的重要指导方针了,各大研究机构与企业正在竞相将深度模型扩大规模。
后面这张图就是个典型例子,我们可以看到,语言模型的参数数量以每年10倍的速度增长。
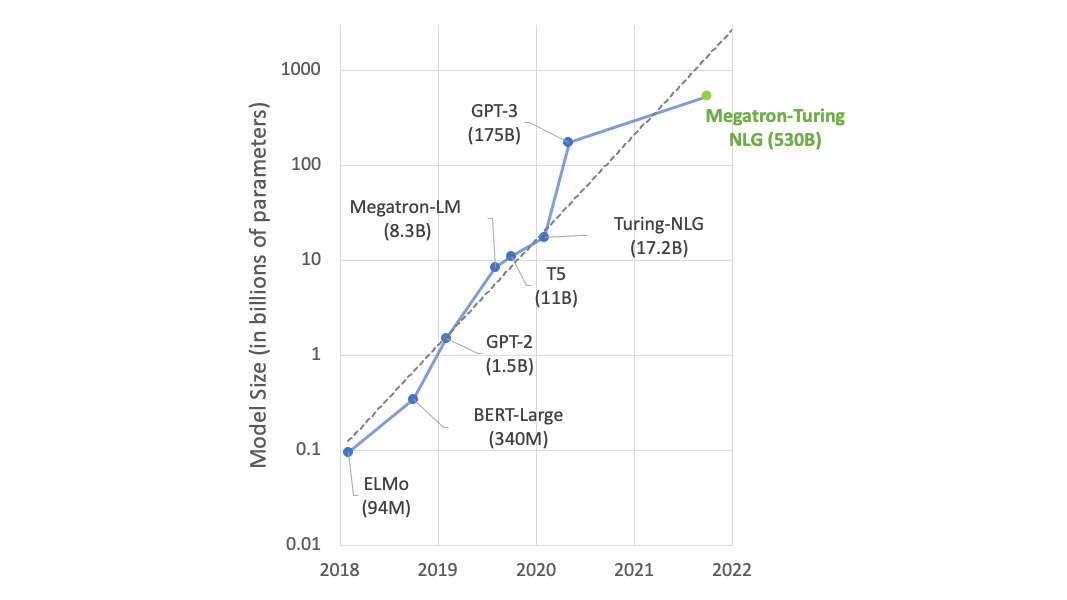
这些变量的增加也确实为我们带来了模型性能上的提高。很多以前无法解决的任务,现在只需扩大模型规模即可解决。例如,在2022年5月发布的语言模型“PaLM”中,其完整模型在BIG-bench测试中首次超过了人类的平均得分。
截止到现在,我想通过扩展模型规模来解决问题的上限还没有被发现。所以,现在AI模型的发展趋势是——开发模式正从“为每个任务单独开发专用模型”转变为“创建一个最强的模型然后应用到一些细分领域”。
基础模型的代表
我们再来看看基础模型的代表吧。从应用的角度看,基础模型可以分为语言模型与多模态模型。
语言模型
Large Language Model(LLM)是使用大量文本数据进行训练、可以处理自然语言任务的模型。
我想我们现在所说的大模型,就是由此翻译而来。不过,大模型这个概念现在也没出现明确的定义,仁者见仁,智者见智,如果你的理解是基础模型是大模型的话,也未尝不可。
通常来说对大语言模型进行微调,就可以生成针对不同任务的自然语言模型,比方说文本分类、情感分析、摘要生成、文本生成与智能问答等等细分模型。
2018年Google推出的BERT,还有2020年OpenAI的GPT-3就是两个很好的代表。
ChatGPT我想大家一定不陌生。它就是基于GPT(Generative Pre-trained Transformer)模型进行微调的一个最典型应用。
其实,大语言模型中的Large也没有明确的定义,以BERT与GPT-3作为参考。BERT是使用28亿字的维基百科与8亿字的Google BookCorpus数据进行训练的,GPT-3是使用45TB的数据(4990亿个token)训练而成的。
在大语言模型中比较有代表性的模型有GPT-3、MT-NLG、PaLM,感兴趣的话你可以自己去研究研究。
多模态模型
模态其实是数据来源的一种形式。对我们人类来说,有视觉、触觉、嗅觉等“数据来源”。延伸到计算机中就是图像、文本以及音频等数据形式了,这些形式就是计算机的多模态了。
我们机器学习的核心思想就是让机器像人一样思考,多模态学习向这一核心思想又迈进了一步。既然我们人类可以通过听觉、视觉来对某一事物进行判断,那多模态模型同样可以做到,让模型接受不同模态的输入,然后进行推断。
目前,多模态的模型中似乎都是以文本与图像居多,下面我列了几个具有代表性的多模态模型。
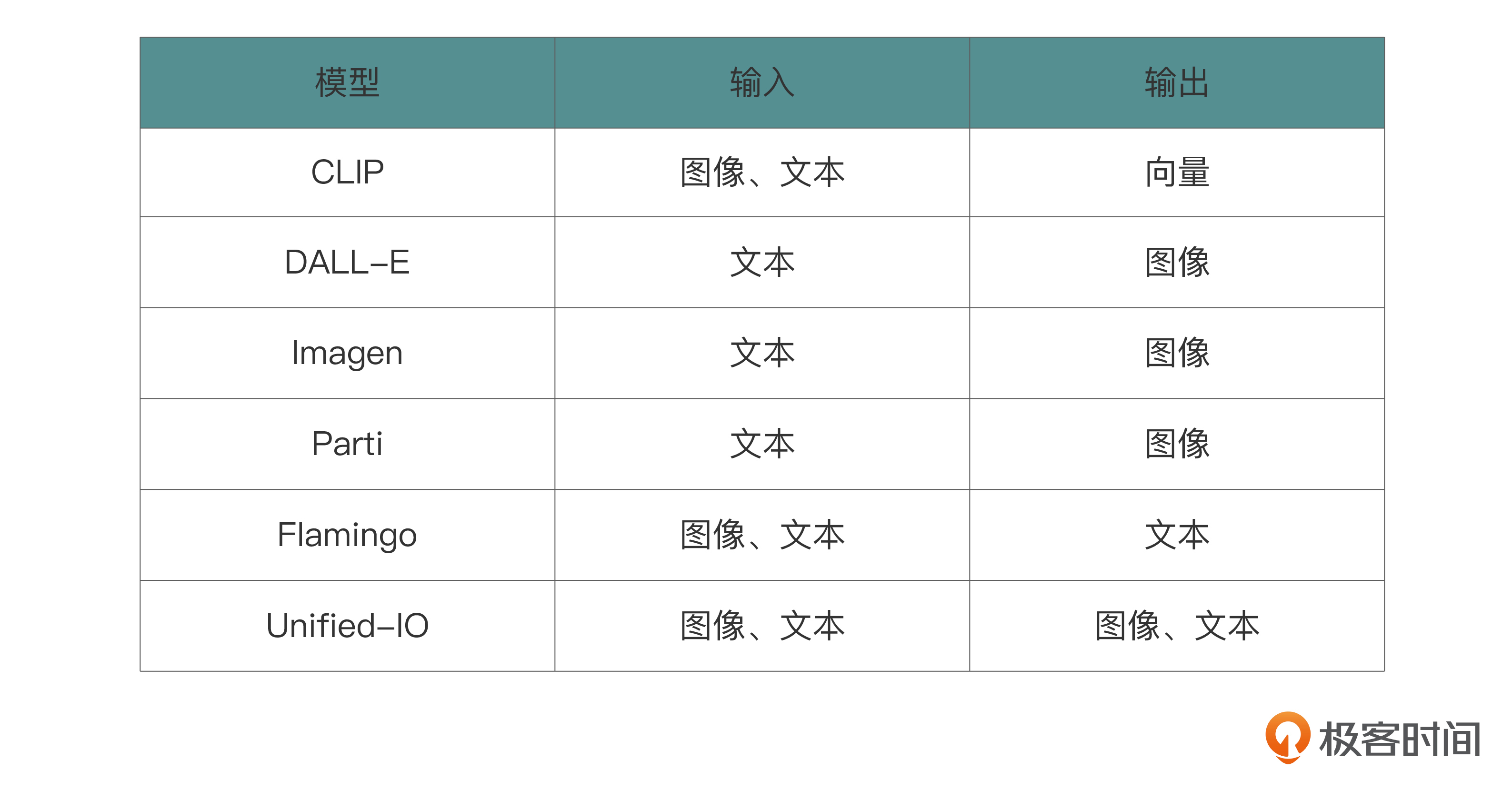
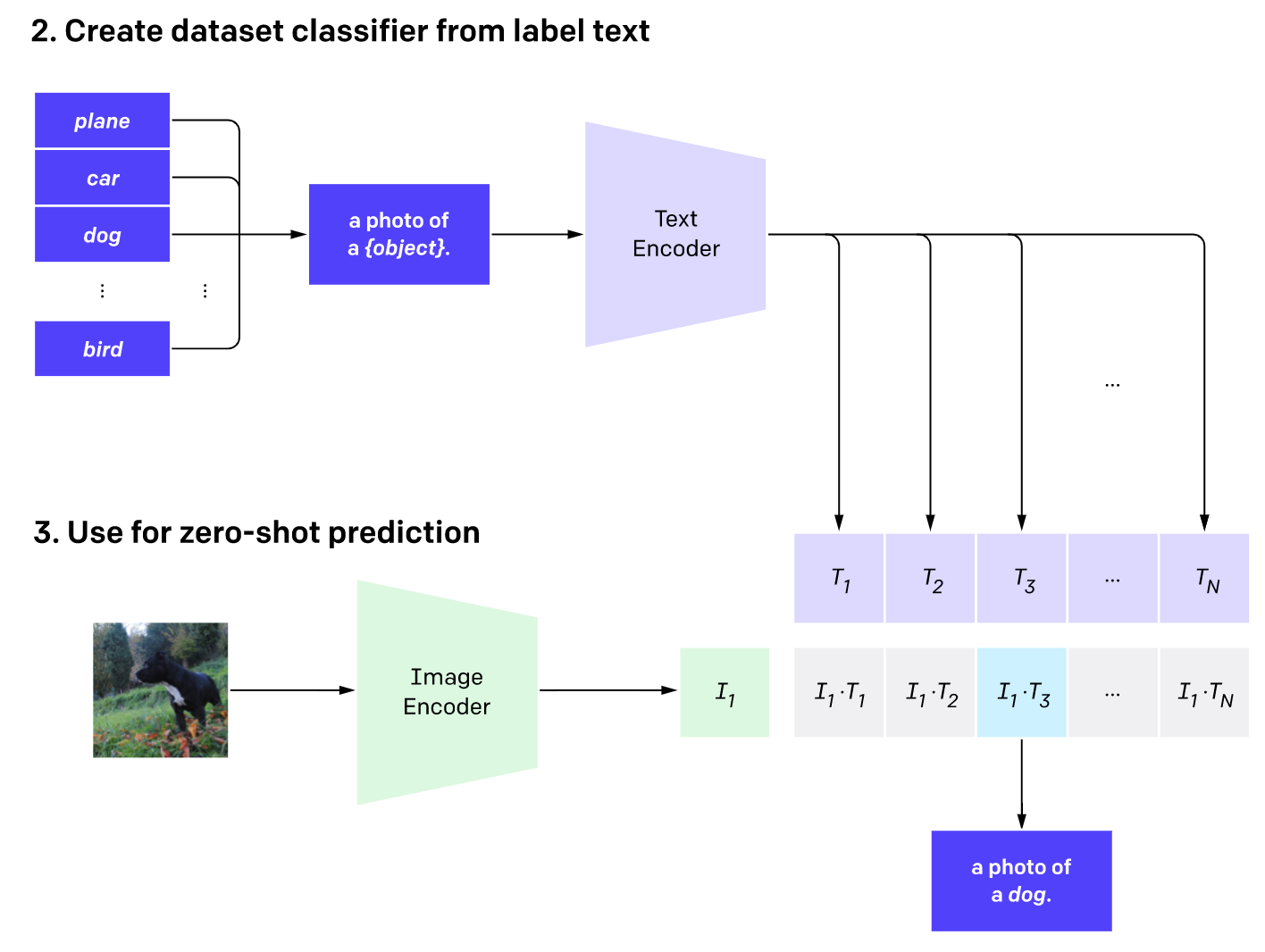
2021年的CLIP被认为是视觉和语言处理的基础模型的重大突破。CLIP包括两个编码器,它们将文本和图像映射到相同的特征空间。使用CLIP,可以在不进行任何额外训练的情况下解决图像分类问题。
那么CLIP用于图像分类具体的机制是怎样的呢?
首先要将每个候选类别用文本形式表示(例如,“狗的照片”),再输入到文本编码器中。接下来,将要分类的图像输入到图像编码器中。然后计算从图像获取的向量与候选类别得到的多个向量之间的余弦相似度。最后,将具有最高相似度的类别作为输出结果。
除此之外,还有可以根据输入文本自动生成图片的多模态模型。后面这张图是最新的Imagen的示例,它的输入是泰迪熊在参加奥林匹克400米蝶泳比赛。

OpenAI在2023年3月14日最新发布的GPT-4就是一个多模态模型,这也是它与GPT-3最大的区别了。它不仅可以接受文本数据作为输入,同样可以接受图像数据作为输入,然后以文本的形式进行输出。不过,目前的ChatGPT还不支持图片作为输入。
未来畅想
基于GPT-4的基础模型是当前最先进的自然语言处理模型之一,它在多个NLP任务上表现出色。未来,我想基础模型将在以下几个方面得到进一步发展。
- 更大规模的模型:基础模型的大小已经达到了数十亿个参数,但未来会有更大规模的模型出现,这将进一步提升其在各种任务上的表现。
- 更高效的训练方法:目前训练基础模型还需要消耗大量的计算资源和时间,未来将出现更高效的训练方法,让更多的研究者和企业可以开发自己的应用。
- 更广泛的应用场景:目前基础模型已经在多个领域得到应用,包括金融、医疗、电商等,未来还将在更广泛的应用场景中发挥作用,比如教育、娱乐等领域。应用方向也不仅局限于自然语言处理,还将涉及到其他领域,如计算机视觉、语音识别、推理和决策等。
一旦这些方面有所突破,基础模型会进一步扩展它的应用范围,并为人工智能的发展提供更多可能性。
好了,今天的加餐分享就到这里,也欢迎你在留言区跟我和其他同学交流想法。
- Juha 👍(0) 💬(2)
老师好,想问下一个不太专业的问题,就是chatpt这类模型出现之后,与pytorch和tensorflow这些框架的关系是怎样的呢
2023-11-15 - Monin 👍(0) 💬(1)
方老师 关于“未来畅想”这部分 作为一名业务开发程序员 深度研究哪块可以更好的抓住未来的大模型趋势 ?
2023-08-30 - ifelse 👍(0) 💬(0)
学习打卡
2023-12-16