20 部署一个鲜花网络电商的人脉工具(上)
你好,我是黄佳,欢迎来到LangChain实战课!
从今天开始,我要用4节课的篇幅,带着你设计两个有趣而又实用的应用程序。设计这两个应用程序的目的,是为了让你能够把LangChain中的各个组件灵活地组合起来,融会贯通,并以此作为启发,在你熟悉的业务场景中,利用LangChain和LLM的能力,开发出更多、更强大的效率工具。
第一个应用程序,是用LangChain创建出一个专属于“易速鲜花”的网络人脉工具。光这么说,有些模糊,这个人脉工具长啥样?有些啥具体功能?
动手之前,让我先给你把这个所谓“人脉”工具的能力和细节说清楚。
“人脉工具”项目说明
项目背景:易速鲜花电商网络自从创建以来,通过微信、抖音、小红书等自媒体宣传推广,短期内获得了广泛流量展示。目前,营销部门希望以此为契机,再接再厉,继续扩大品牌影响力。经过调研,发现很多用户会通过微博热搜推荐的新闻来购买鲜花赠送给明星、达人等,因此各部门一致认为应该联络相关微博大V,共同推广,带动品牌成长。
然而,发掘并选择适合于“鲜花推广”的微博大V有一定难度。营销部门员工表示,这个任务比找微信、抖音和小红书达人要难得多。他们都希望技术部门能够给出一个“人脉搜索工具”来协助完成这一目标。
项目目标:帮助市场营销部门的员工找到微博上适合做鲜花推广的大V,并给出具体的联络方案。
项目的技术实现细节
这个项目的具体技术实现细节,这里简述如下。
第一步:通过LangChain的搜索工具,以模糊搜索的方式,帮助运营人员找到微博中有可能对相关鲜花推广感兴趣的大V(比如喜欢玫瑰花的大V),并返回UID。
第二步:根据微博UID,通过爬虫工具拿到相关大V的微博公开信息,并以JSON格式返回大V的数据。

第三步:通过LangChain调用LLM,通过LLM的总结整理以及生成功能,根据大V的个人信息,写一篇热情洋溢的介绍型文章,谋求与该大V的合作。
第四步:把LangChain输出解析功能加入进来,让LLM生成可以嵌入提示模板的格式化数据结构。
第五步:添加HTML、CSS,并用Flask创建一个App,在网络上部署及发布这个鲜花电商人脉工具,供市场营销部门的人员使用。
在上面的5个步骤中,我们使用到很多LangChain技术,包括提示工程、模型、链、代理、输出解析等。
这节课我们先来实现项目的前两个部分。
第一步:找到大 V
因为咱们的项目需要用到很多工具,所以我创建了一个项目目录,叫做socializer_v0(项目每完成一步,我就创建一个新目录,并把版本号加1)。当第一个步骤“找到大 V”实现之后,项目中的文档结构如下。
这里,主程序是findbigV.py。意思就是派程序来作为智能代理,找到喜欢鲜花的微博大V。
主程序 findbigV.py
主程序findbigV.py在第一步完成之后,是这样的。
# 设置OpenAI API密钥
import os
os.environ["OPENAI_API_KEY"] = ''
os.environ["SERPAPI_API_KEY"] = ''
# 导入所取的库
import re
from agents.weibo_agent import lookup_V
if __name__ == "__main__":
# 拿到UID
response_UID = lookup_V(flower_type = "牡丹" )
print(response_UID)
# 抽取UID里面的数字
UID = re.findall(r'\d+', response_UID)[0]
print("这位鲜花大V的微博ID是", UID)
这里,我们要搜到的,是一个热爱鲜花的大V的微博UID,而不是URL。
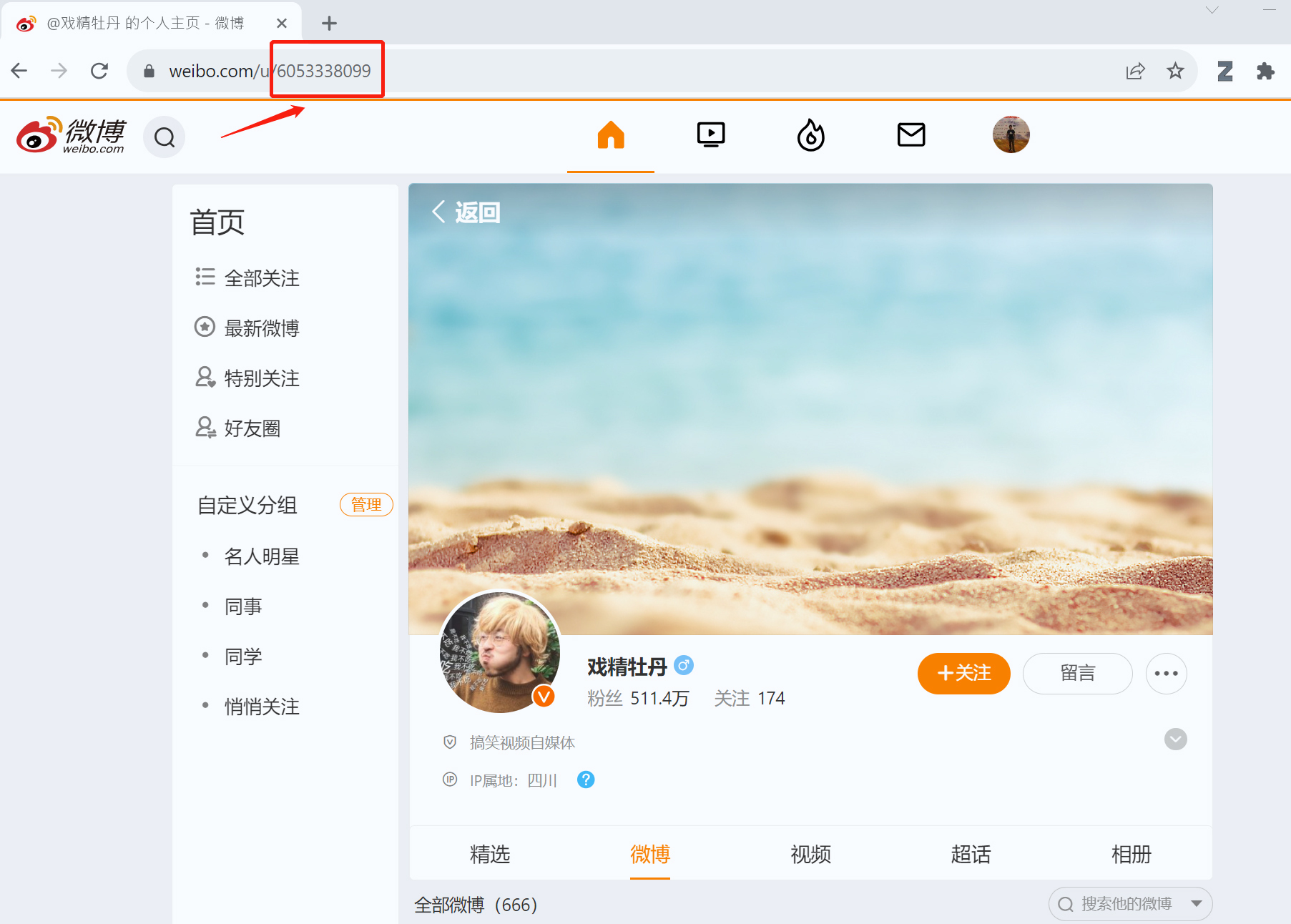
比如,上面这位喜欢牡丹花的大V,他的UID是6053338099。这些都是公开的信息。
为什么我们希望得到UID呢?因为我们可以通过这个ID,爬取他个人主页里的更多介绍信息,有利于进一步了解他。
微博 Agent:查找大 V 的 ID
下面,我们就来看看,文件agents\weibo_agent.py中的lookup_V函数是如何实现这个搜寻UID的功能的。
# 导入一个搜索UID的工具
from tools.search_tool import get_UID
# 导入所需的库
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
# 通过LangChain代理找到UID的函数
def lookup_V(flower_type: str) :
# 初始化大模型
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# 寻找UID的模板
template = """given the {flower} I want you to get a related 微博 UID.
Your answer should contain only a UID.
The URL always starts with https://weibo.com/u/
for example, if https://weibo.com/u/1669879400 is her 微博, then 1669879400 is her UID
This is only the example don't give me this, but the actual UID"""
# 完整的提示模板
prompt_template = PromptTemplate(
input_variables=["flower"], template=template
)
# 代理的工具
tools = [
Tool(
name="Crawl Google for 微博 page",
func=get_UID,
description="useful for when you need get the 微博 UID",
)
]
# 初始化代理
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 返回找到的UID
ID = agent.run(prompt_template.format_prompt(flower=flower_type))
return ID
这段代码的目的,是为了通过提供的花的类型(flower type)来查找与之相关的微博UID。其中使用了LangChain中的代理和工具。
这里有两点需要特别说明:
- 搜索UID的工具通过from tools.search_tool import get_UID导入,这个内容后面还会介绍。
- 下面的提示模板说明,强调了需要的是UID,而不是URL。刚才说了,这是因为后续的爬虫工具需要一个特定的UID,来获取该微博大V的个人信息(公开)。然后我们会继续利用这些信息让LLM为我们写“勾搭”文案。
# 寻找UID的模板
template = """given the {flower} I want you to get a related 微博 UID.
Your answer should contain only a UID.
The URL always starts with https://weibo.com/u/
for example, if https://weibo.com/u/1669879400 is her 微博, then 1669879400 is her UID
This is only the example don't give me this, but the actual UID"""
定制的 SerpAPI:getUID
上面的程序只是调用了代理,但是没有给出具体的工具实现。现在我们来继续实现搜索大V的UID的功能。
这个具体的实现,在代码 \tools\search_tool.py 中。
说到通过LangChain来搜索微博,相信你会马上想到已经多次使用过的SerpAPI。我们先来试一试标准的SerpAPI,看看它能否满足我们的需求。
from langchain.utilities import SerpAPIWrapper
def get_UID(flower: str):
"""Searches for Linkedin or twitter Profile Page."""
search = SerpAPIWrapper()
res = search.run(f"{flower}")
return res
写好了这段代码,第一步就可以说是完成了。下面我们跑一遍findbigV.py,看看程序会给出我们什么样的结果。

结果还好,不算太失望,SerpAPI找到了一个貌似喜欢牡丹花的大V,名叫戏精牡丹,搜到的信息也都是真实的。看起来他蛮适合为我们的牡丹花代言。然而,这个大V的微博ID肯定不是6。
中间哪里或许是出了点小问题。
像这样的错误,明显发生在LangChain内部,那你的 trouble_shooting 也只能通过Debug来解决。这里,我就忽略掉一长串的错误排查过程,直接指出问题的根本原因所在。
让我们把断点设置在SerpAPIWrapper类的_process_response中。
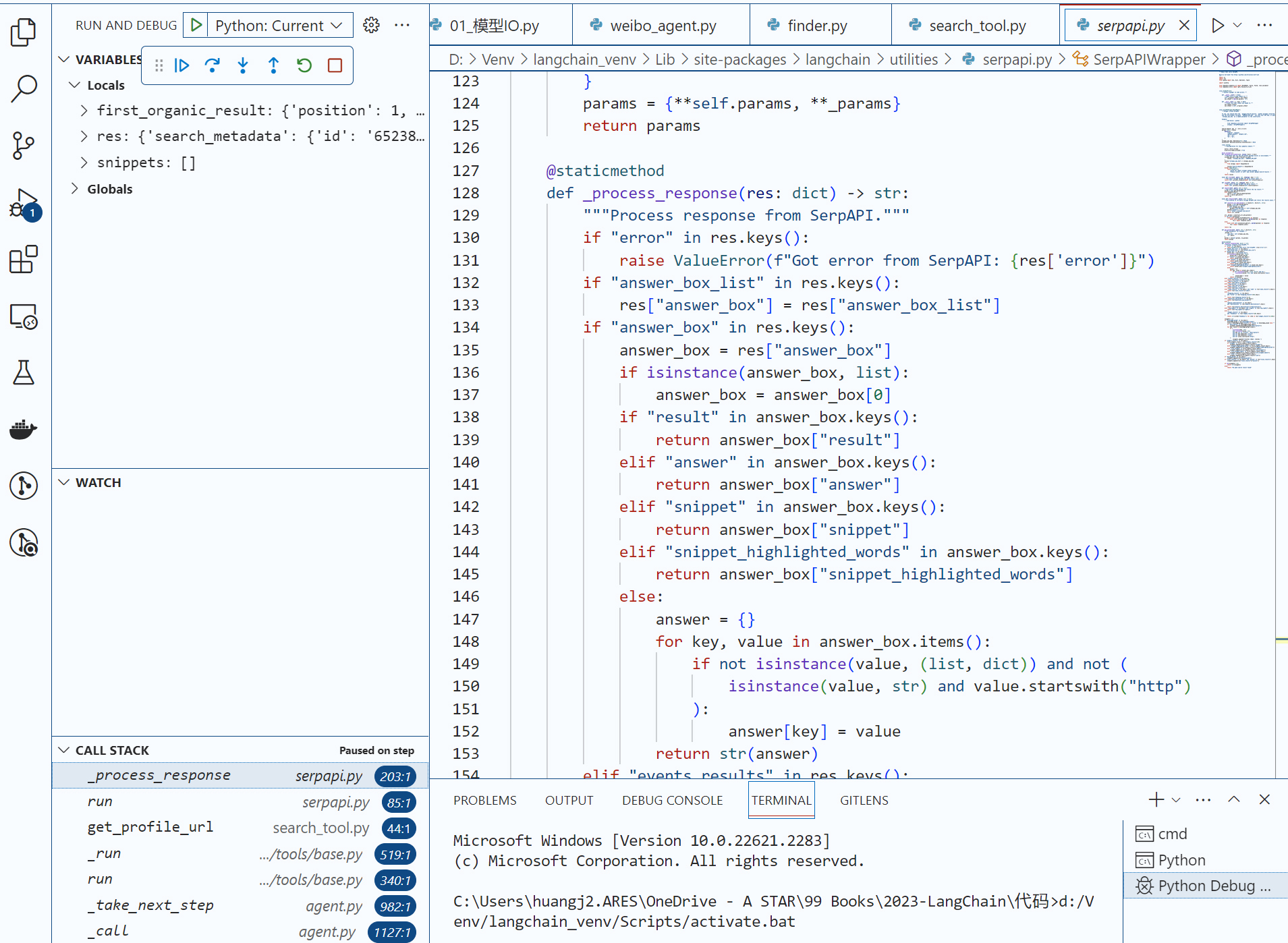
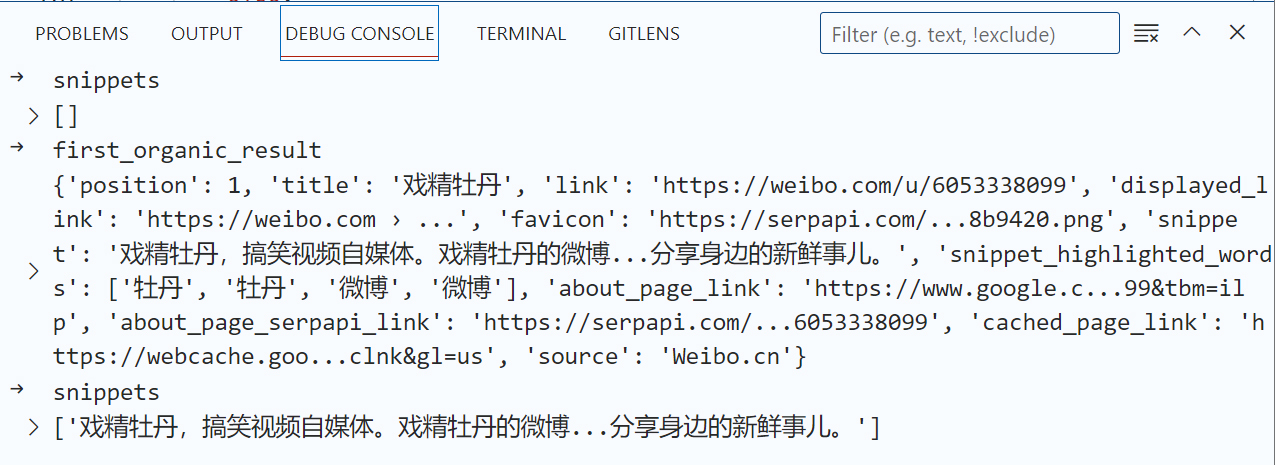
当程序进入 if "organic_results" in res.keys() 这段逻辑之后,我发现,它返回的总是一个snippet(摘要文字),而不是link(URL)。
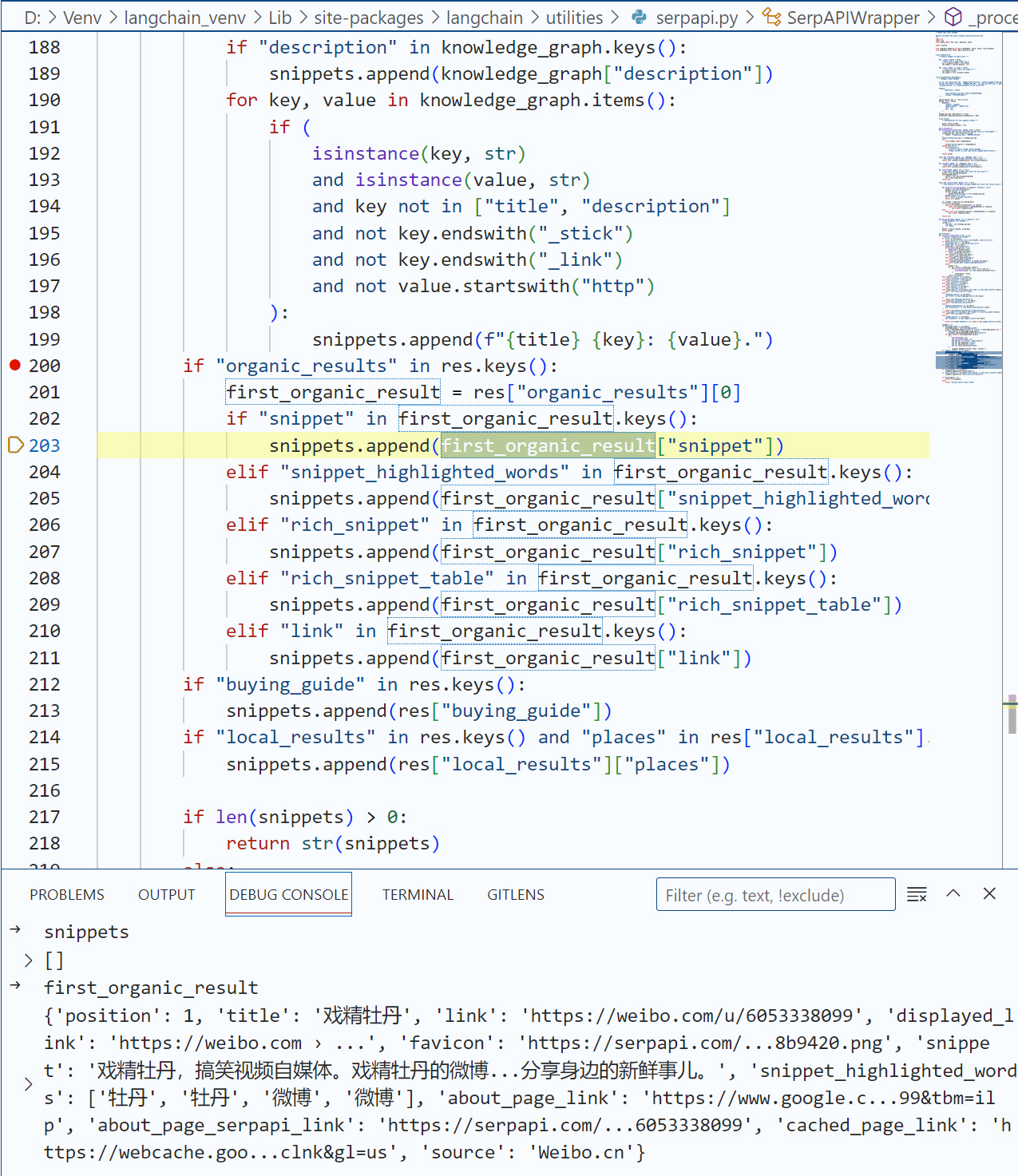
无论这背后的逻辑何在,这并不是我们所想要的。在Debug过程中,我们发现,新浪微博的UID,实际上包含在URL中,也就是 https://weibo.com/u/6053338099。因此,如果我们不返回微博的简短说明(戏精牡丹,搞笑视频自媒体……),而是返回URL,会更有利于大模型提炼出UID。
如何做呢?直接修改LangChain的SerpAPIWrapper类的_process_response源代码肯定不是一个好办法。
因此,这里我们可以继承SerpAPIWrapper类,并构造一个CustomSerpAPIWrapper类,在这个类中,我们重构_process_response这个静态方法。
新的search_tool.py完整代码如下:
# 导入SerpAPIWrapper
from langchain.utilities import SerpAPIWrapper
# 重新定制SerpAPIWrapper,重构_process_response,返回URL
class CustomSerpAPIWrapper(SerpAPIWrapper):
def __init__(self):
super(CustomSerpAPIWrapper, self).__init__()
@staticmethod
def _process_response(res: dict) -> str:
"""Process response from SerpAPI."""
if "error" in res.keys():
raise ValueError(f"Got error from SerpAPI: {res['error']}")
if "answer_box_list" in res.keys():
res["answer_box"] = res["answer_box_list"]
'''删去很多无关代码'''
snippets = []
if "knowledge_graph" in res.keys():
knowledge_graph = res["knowledge_graph"]
title = knowledge_graph["title"] if "title" in knowledge_graph else ""
if "description" in knowledge_graph.keys():
snippets.append(knowledge_graph["description"])
for key, value in knowledge_graph.items():
if (
isinstance(key, str)
and isinstance(value, str)
and key not in ["title", "description"]
and not key.endswith("_stick")
and not key.endswith("_link")
and not value.startswith("http")
):
snippets.append(f"{title} {key}: {value}.")
if "organic_results" in res.keys():
first_organic_result = res["organic_results"][0]
if "snippet" in first_organic_result.keys():
# 此处是关键修改
# snippets.append(first_organic_result["snippet"])
snippets.append(first_organic_result["link"])
elif "snippet_highlighted_words" in first_organic_result.keys():
snippets.append(first_organic_result["snippet_highlighted_words"])
elif "rich_snippet" in first_organic_result.keys():
snippets.append(first_organic_result["rich_snippet"])
elif "rich_snippet_table" in first_organic_result.keys():
snippets.append(first_organic_result["rich_snippet_table"])
elif "link" in first_organic_result.keys():
snippets.append(first_organic_result["link"])
if "buying_guide" in res.keys():
snippets.append(res["buying_guide"])
if "local_results" in res.keys() and "places" in res["local_results"].keys():
snippets.append(res["local_results"]["places"])
if len(snippets) > 0:
return str(snippets)
else:
return "No good search result found"
# 获取与某种鲜花相关的微博UID的函数
def get_UID(flower: str):
"""Searches for Linkedin or twitter Profile Page."""
# search = SerpAPIWrapper()
search = CustomSerpAPIWrapper()
res = search.run(f"{flower}")
return res
唯一的区别就是,我们在下面的逻辑中返回了link,而不是snippet。
if "organic_results" in res.keys():
first_organic_result = res["organic_results"][0]
if "snippet" in first_organic_result.keys():
# snippets.append(first_organic_result["snippet"])
snippets.append(first_organic_result["link"])
再次Debug,我们发现返回的snippets里面包含了URL信息,其中UID信息包含在URL中了。
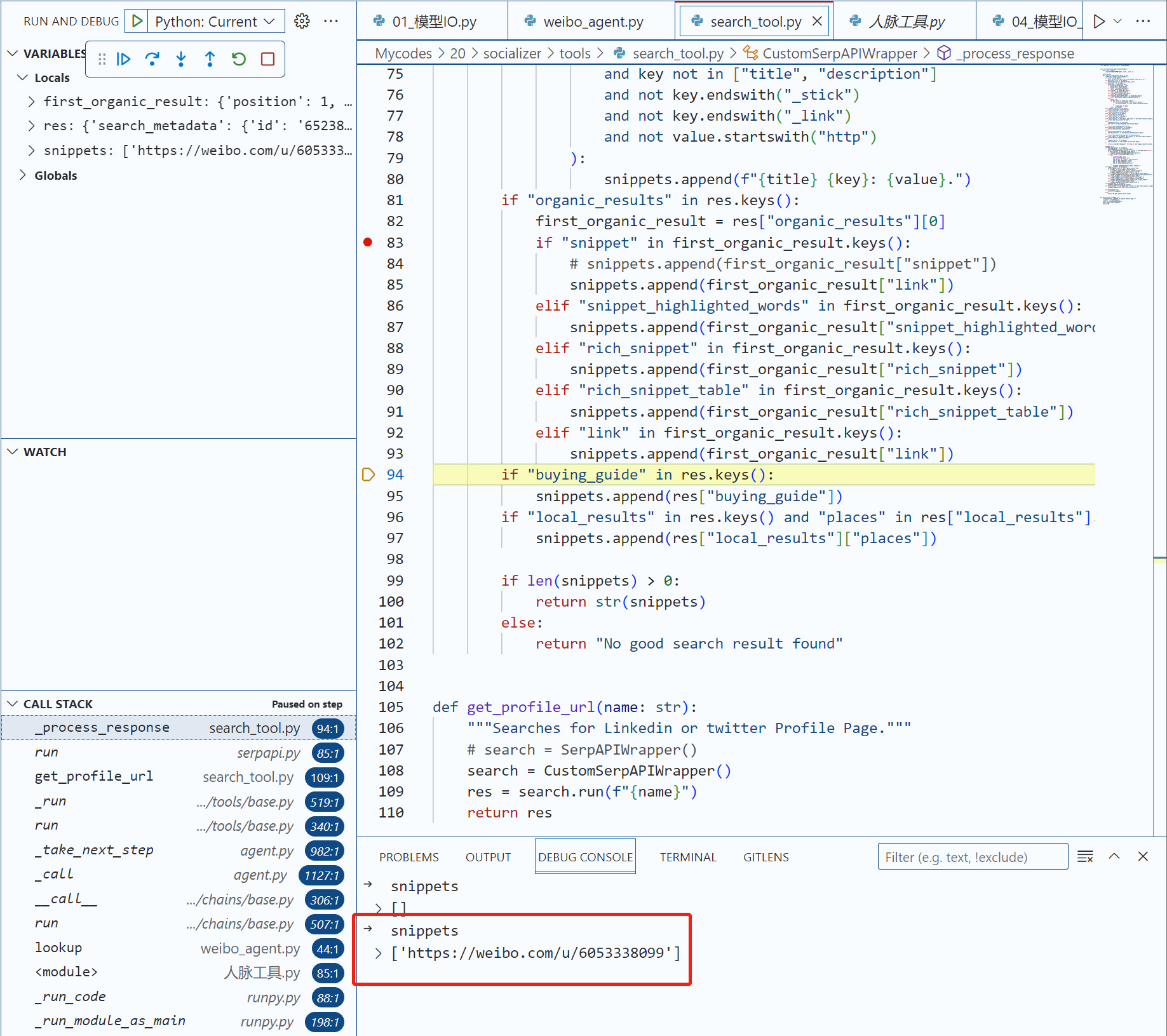
此时运行主程序findbigV.py,会发现代理中返回了URL信息,并且经过进一步思考,提炼出了UID。

第二步:爬取大 V 资料
好的,第一步虽然是有磕有绊,但是经过了调整的CustomSerpAPIWrapper工具和代理,在LLM的帮助之下,总算是不辱使命,完成了找到UID的任务。
这位大V,看起来又喜欢牡丹,又喜欢搞笑。我们很想和他联络一下,也许他很适合为我们的牡丹花品牌代言。(到底是否适合,不必特别认真哈,总之搜索“牡丹”,Agent给了这个ID,就可以了。咱学的是LangChain,不是真的要找他代言)
不过,知己知彼,百战不殆。想要和他沟通,就得了解他更多。下面,我们将使用爬虫程序,通过UID来爬取他的更多信息。
主程序 findbigV.py
第二步完成之后,主程序代码如下:
# 设置OpenAI API密钥
import os
os.environ["OPENAI_API_KEY"] = 'Your OpenAI API Key'
os.environ["SERPAPI_API_KEY"] = 'Your SerpAPI Key'
# 导入所取的库
import re
from agents.weibo_agent import lookup_V
from tools.general_tool import remove_non_chinese_fields
from tools.scraping_tool import get_data
if __name__ == "__main__":
# 拿到UID
response_UID = lookup_V(flower_type = "牡丹" )
# 抽取UID里面的数字
UID = re.findall(r'\d+', response_UID)[0]
print("这位鲜花大V的微博ID是", UID)
# 根据UID爬取大V信息
person_info = get_data(UID)
print(person_info)
从第一步到第二步,我们主要是完成了一次微博信息的爬取。
scraping_tool.py 中的 scrape_weibo 方法
第二步中的关键逻辑是scraping_tool.py中的scrape_weibo方法,具体代码如下:
# 导入所需的库
import json
import requests
import time
# 定义爬取微博用户信息的函数
def scrape_weibo(url: str):
'''爬取相关鲜花服务商的资料'''
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Referer": "https://weibo.com"
}
cookies = {
"cookie": '''SINAGLOBAL=3762226753815.13.1696496172299; ALF=1699182321; SCF=AiOo8xtPwGonZcAbYyHXZbz9ixm97mWi0vHt_VvuOKB-u4-rcvlGtWCrE6MfMucpxiOy5bYpkIFNWTj7nYGcyp4.; _sc_token=v2%3A2qyeqD3cTZFNTl0sn3KAYe4fNqzMUEP-C7nxNsd_Q1r-vpYMlF2K3xc4vWNuLNBbp3RsohghkJdlSVN09cymVo5AKAm0V92004V8cSRe9O5v9B65jd4yiG_sATDeB06GnjiJulXUrEF_6XsHh1ozK6jvbTKEUIkF7v0_BlbX6IcWrPkwh6xL_WM_0YUV2v7CtNPwyxfbAjaWnG32TsxG_ftN3s5m7qfaRftU6iTOSnE%3D; XSRF-TOKEN=4o0E6jaUQ0BlN77az0sURTg3; PC_TOKEN=dcf0e7607f; login_sid_t=36ebf31f1b3694fb71e77e35d30f052f; cross_origin_proto=SSL; WBStorage=4d96c54e|undefined; _s_tentry=passport.weibo.com; UOR=www.google.com,weibo.com,login.sina.com.cn; Apache=7563213131783.361.1696667509205; ULV=1696667509207:2:2:2:7563213131783.361.1696667509205:1696496172302; wb_view_log=3440*14401; WBtopGlobal_register_version=2023100716; crossidccode=CODE-gz-1QP2Jh-13l47h-79FGqrAQgQbR8ccb7b504; SSOLoginState=1696667553; SUB=_2A25IJWfwDeThGeFJ6lsQ-SbNzjuIHXVr5gm4rDV8PUJbkNAbLUWtkW1NfJd_XHamKIzj5RlT_-RGMma6z3YQZUK3; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFDKvBlvg14YuHk_4c6MEH_5NHD95QNS024eK.ReK-NWs4DqcjZCJ8oIN.pSKzceBtt; WBPSESS=gyY2mn77F4p5VxWF2IB_yFR0phHVTNfaJAHAMprnW7MeUr-NHPZNyeeyKae3tHELlc_RbcI1XPSz-TjSJqWrIXs-yh1fwhxL4mSDrnpPZEogFt8ScF5NEwSqPGn7x2KMAgTHtWde-3MBm6orQ98PDA=='''
}
response = requests.get(url, headers=headers, cookies=cookies)
time.sleep(3) # 加上3s 的延时防止被反爬
return response.text
# 根据UID构建URL爬取信息
def get_data(id):
url = "https://weibo.com/ajax/profile/detail?uid={}".format(id)
html = scrape_weibo(url)
response = json.loads(html)
return response
我这段爬虫代码特别简洁,不需要过多的解释,唯一需要说明的部分是怎么找到你自己的Cookies。
Cookie 是由服务器发送到用户浏览器的一小段数据,并可能在随后的请求中被回传。它的主要目的是让服务器知道用户的上下文信息或状态。在Web爬虫中,使用正确的Cookie可以模拟登录状态,从而获取到需要权限的网页内容。
首先,我是用QQ ID登录的微博,我发现通过这样的方式找到的Cookie能用得比较久。
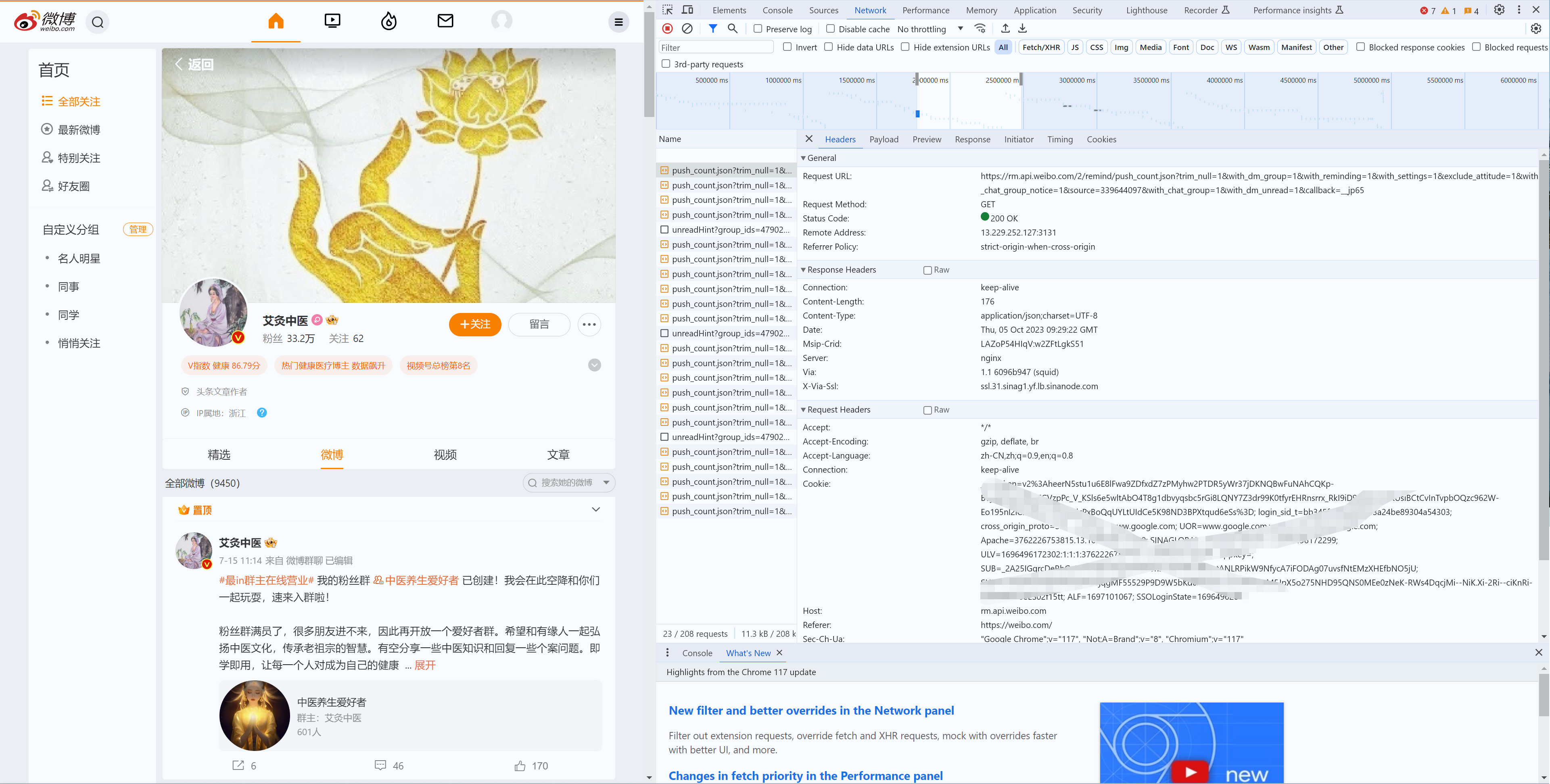
然后,从我的浏览器中获取 Cookie,以下是简单步骤:
- 使用浏览器(如 Chrome、Firefox)访问微博并登录。
- 登录后,右键单击页面并选择“检查”(Inspect)。
- 打开开发者工具,点击 Network 选项卡。
- 在页面上进行一些操作(如刷新页面),然后在 Network 选项卡下查看请求列表。
- 选择任一请求项,然后在右侧的 Headers 选项卡中查找 Request Headers 部分。
- 在这部分中,你应该可以看到一个名为 Cookie 的字段,这就是你需要的 Cookie 值。
将获取到的完整Cookie值复制(挺长的),并替换上述代码中的 "你的Cookie" 部分。
但请注意,微博的Cookie可能有过期时间,所以如果你发现一段时间后你的爬虫无法正常工作,你可能需要再次获取新的Cookie。同时,频繁地爬取或大量请求可能会导致你的账号被封禁,所以请谨慎使用爬虫。
此时,运行 findbigV.py,就得到了下面的输出。

精简爬取输出
最后一个步骤,是精简上面的输出,因为类似 'word_color': '#FFEA8011', 'background_color': '#FF181818' 这样的内容会占据很多Token空间,而且对于LLM总结整理信息,也没啥作用。
因此,我创建了一个额外的步骤,就是\tools\general_tool.py中的remove_non_chinese_fields函数。
import re
def contains_chinese(s):
return bool(re.search('[\u4e00-\u9fa5]', s))
def remove_non_chinese_fields(d):
if isinstance(d, dict):
to_remove = [key for key, value in d.items() if isinstance(value, (str, int, float, bool)) and (not contains_chinese(str(value)))]
for key in to_remove:
del d[key]
for key, value in d.items():
if isinstance(value, (dict, list)):
remove_non_chinese_fields(value)
elif isinstance(d, list):
to_remove_indices = []
for i, item in enumerate(d):
if isinstance(item, (str, int, float, bool)) and (not contains_chinese(str(item))):
to_remove_indices.append(i)
else:
remove_non_chinese_fields(item)
for index in reversed(to_remove_indices):
d.pop(index)
在findbigV.py中,调用这个函数,对爬虫的输出结果进行了精简。
重新运行findbigV.py,结果如下:

此时,爬取的内容就只剩下了干货。
总结时刻
这节课我们完成了前两步的工作。分别是,找到适合推广某种鲜花的大V的微博UID,并且爬取了大V的资料。这为我们后续生成文本、进一步链接大V打下了良好的基础。
其中,我们用到了大量之前学习过的LangChain组件,具体包括:
- 用提示模板告诉大模型我们要找到内容(UID)。
- 调用LLM。
- 使用Chain。
- 使用Agent。
- 在Agent中,我们使用了一个Customized Tool,因为LangChain内置的SerpAPI Tool不能完全满足我们的需要。这给了我们一个好机会创建自己的“私人定制” Tool。
在下节课中,我们还要继续利用大模型的总结文本、生成文本的功能,来为我们撰写能够打动大V和咱易速鲜花合作的文案,我们还将利用Output Parser把文案解析成需要的格式,部署到网络服务器端。敬请期待!
思考题
- 如果Agent不返回UID,而是返回URL,是不是也能够完成这个任务?你可以尝试重构提示模板以及后续逻辑,返回URL,然后手动从URL中解析出UID。
- 研究一下SerpAPIWrapper类的_process_response中的代码,看看这个方法具体是怎么设计的,用来实现了什么功能?
期待在留言区看到你的分享,如果觉得内容对你有帮助,也欢迎分享给有需要的朋友!
- 马里奥的马里奥 👍(2) 💬(2)
2个问题 1.虽然修改了获取link的方式,依然是会有错误,在我这里解析到的是 https://weibo.com/p/xxx后的这个xx数字; 2.我尝试修改提示词,只搜索粉丝超过一百万的账号,似乎也不生效。
2023-12-31 - Liberalism 👍(0) 💬(1)
在爬取微博用户资料时报 400 错误,请问是哪里出了问题???? def scrape_weibo(url: str): """爬取相关鲜花服务商的资料""" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/89.0.4389.82 Safari/537.36", "Referer": "https://weibo.com"} cookies = { "cookie": '''SINAGLOBAL=6620500101466.929.1684124696145; ULV=1701318517344:5:1:1:2994044278409.513.1701318517342:1695626334231; SUB=_2A25IbH_LDeRhGedJ71EX9C3Kwz6IHXVrAP0DrDV8PUNbmtAGLWP8kW9NVhncgwwKDAJC-BEIEyWCj9aAZiYRqGGn; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WF1hJoCEpSf.bqAJzfD-UMO5JpX5KzhUgL.Fo2NShecShec1hz2dJLoI7peIgiLMJ8jIPS_qgRt; ALF=1732854554; XSRF-TOKEN=Dr6hVUuVr5JfuRn3NHntHjk7; WBPSESS=qWBqMfNAAnlnO3TmyuUMG1qvHg86Rz2Zv7YHVRzN1MJAsJSyBhxx0_AUvWsjCUhaTWJpEmAC3UJ6u4OKi_zznpkRnRQ8ciUPXXDldaaw58i1fvBUm_1oDKnjo6sGr9qeK-zdbnLVltKplYXJysV88A==''' } response = requests.get(url, headers=headers, cookies=cookies) time.sleep(3) # 加上3s 的延时防止被反爬 return response.text
2023-12-02 - Liberalism 👍(0) 💬(1)
def scrape_weibo(url: str): """爬取相关鲜花服务商的资料""" headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Referer': 'http://www.baidu.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)' } cookies = { "cookie": '''SINAGLOBAL=6620500101466.929.1684124696145; ULV=1701318517344:5:1:1:2994044278409.513.1701318517342:1695626334231; SUB=_2A25IbH_LDeRhGedJ71EX9C3Kwz6IHXVrAP0DrDV8PUNbmtAGLWP8kW9NVhncgwwKDAJC-BEIEyWCj9aAZiYRqGGn; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WF1hJoCEpSf.bqAJzfD-UMO5JpX5KzhUgL.Fo2NShecShec1hz2dJLoI7peIgiLMJ8jIPS_qgRt; ALF=1732854554; XSRF-TOKEN=Dr6hVUuVr5JfuRn3NHntHjk7; WBPSESS=qWBqMfNAAnlnO3TmyuUMG1qvHg86Rz2Zv7YHVRzN1MJAsJSyBhxx0_AUvWsjCUhaTWJpEmAC3UJ6u4OKi_zznpkRnRQ8ciUPXXDldaaw58i1fvBUm_1oDKnjo6sGr9qeK-zdbnLVltKplYXJysV88A==''' } response = requests.get(url, headers=headers, cookies=cookies) time.sleep(3) # 加上3s 的延时防止被反爬 return response.text 爬取数据这里一直报错 400
2023-12-01 - fireshort 👍(0) 💬(2)
黄老师,这里的Agent感觉没有发挥作用,没有太多智能,LLM就加了“微博”去搜索。 ID = agent.run(prompt_template.format_prompt(flower=flower_type)) 改成 ID = get_UID(flower_type+" 微博") 得到一样的结果。
2023-11-30 - starj 👍(0) 💬(2)
github上没有代码?
2023-10-31 - 卓丁 👍(0) 💬(1)
我遇到一个报错: raise JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 2 column 3 (char 3) 看着好像是 json.loads解析失败了。 进一步看报错栈,是报 400 的状态码。 于是我尝试将get_data方法所请求的url打印出来了一下。
结果如下: > Finished chain. 这位鲜花大V的微博ID是 100808 url-> https://weibo.com/ajax/profile/detail?uid=100808 <h2>400 Bad Request</h2> Traceback (most recent call last): File "/Users/bawenmao/PycharmProjects/socializer_v0/findbigV.py", line 23, in <module> person_info = get_data(UID) ^^^^^^^^^^^^^ File "/Users/bawenmao/PycharmProjects/socializer_v0/tools/scraping_tool.py", line 26, in get_data response = json.loads(html) ^^^^^^^^^^^^^^^^ File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/json/__init__.py", line 346, in loads return _default_decoder.decode(s) ^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/json/decoder.py", line 337, in decode obj, end = self.raw_decode(s, idx=_w(s, 0).end()) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/json/decoder.py", line 355, in raw_decode raise JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0) 是不是所请求的那个url 本身不对; 请教下老师,这是哪里的问题;2024-02-21