06 赛博记忆:为每个人生成独有的AI记忆
本门课程为精品小课,不标配音频
你好,我是王吕。
在之前的课程中,我们讨论了极客时间小助手这类聊天机器人的实现,用户可以和 LLM 对话互动,通过一问一答,获取想要的知识。不过在真实使用场景中,我们的对话都是连续的,我们也期望 LLM 能知道我们刚才说了什么。今天这节课,我就来帮你实现 AI 多轮对话的功能,并且讨论一下如何实现给每个用户增加记忆的功能。
什么是 LLM 的记忆?
记忆简单来说就是存储,把相关数据存储下来供之后使用,这就是 LLM 的记忆。可是,随着时间的增加,记忆数据越来越大,远远超过 LLM 对话的 token 长度了,这该怎么办?
我们首先想到的就是裁剪,只保留最近的数据,但是这样就会丢失很多的重要信息。最好的解决办法是把记忆抽象为两种类型:短期记忆和长期记忆,短期记忆是精确的数据,长期记忆是模糊的数据,只记录关键信息。
在这个方法的指导下,针对对话场景,我们可以设计下边这个结构体,作为传递给 LLM 的消息。
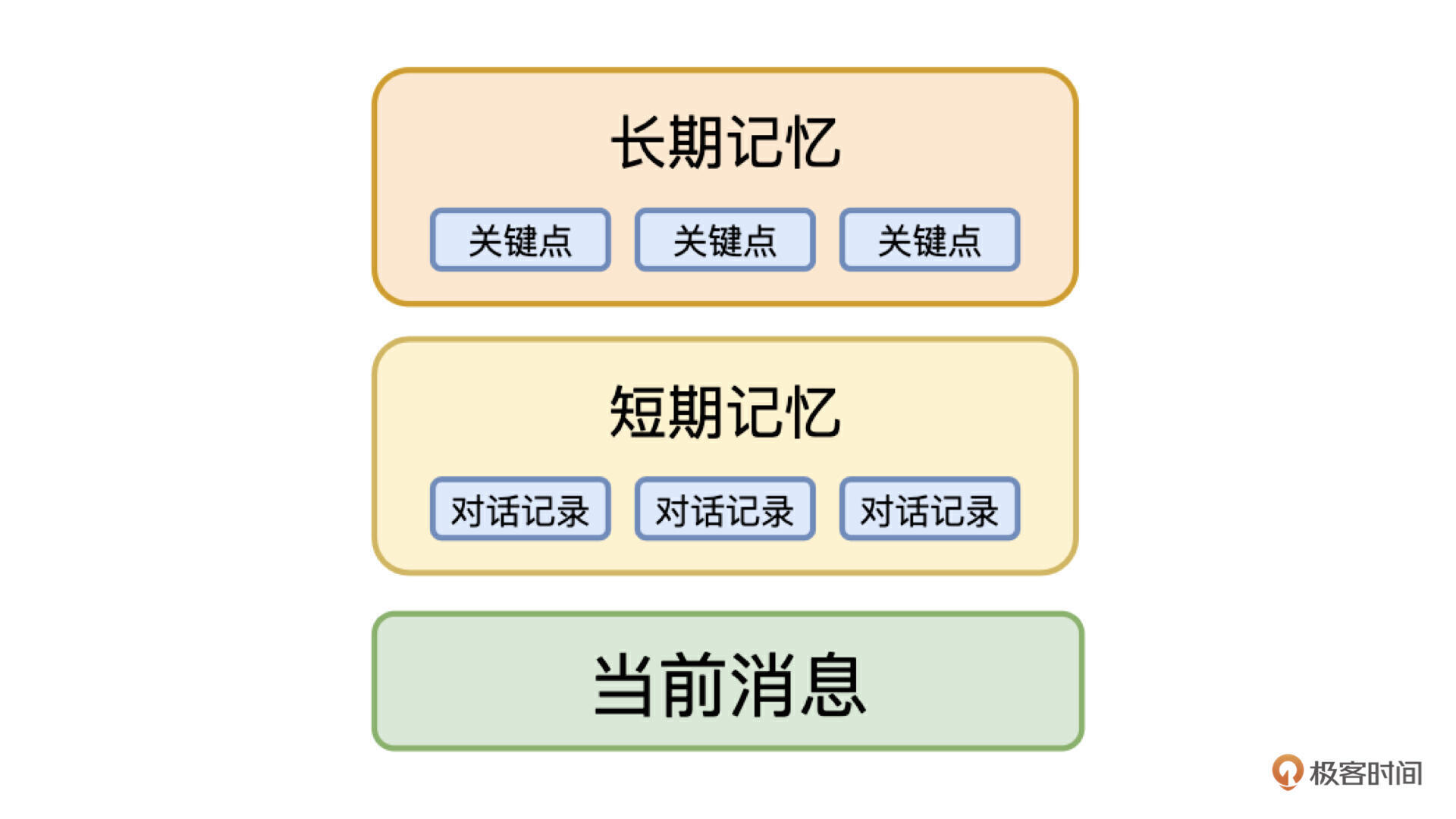
短期记忆很简单,我们直接把对话记录的最近 N 条作为短期记忆,也就是对话上下文,这保证了用户在对话过程中聊天内容的连续性。长期记忆是把之前的历史消息进行总结提炼,只记录关键信息,类似于背景信息,再加上用户最新的对话,这三部分就组成了一个拥有记忆的 LLM,可以实现多轮对话的能力。
按照上面的方案,长期记忆需要提取对话中的关键信息,我们可以自己实现这个功能。针对每轮对话,使用 LLM 处理一下,在 prompt 中告诉 LLM,要做的事情是提取关键信息,单独记录在数据库中。
不过记忆还有一个特性,就是它是会更新的,要实现这个功能,还需要在长期记忆的数据库里,遍历查找更新,需要设计一个复杂的算法处理这个问题。好在有一个开源项目,帮我们解决了这些复杂的问题,它就是 Mem0 (GitHub 地址:https://github.com/mem0ai/mem0)。
Mem0 介绍
Mem0 是一个功能强大的记忆框架,专为大语言模型(LLM)设计,设计的一个核心目标就是赋予模型类似于人类的长期记忆功能。相比传统 RAG 它的主要优势有:
- 实体关系:Mem0 能跨越多次交互理解和关联实体,而 RAG 仅从静态文档中检索信息,Mem0 能更深入理解上下文和关系。
- 最新性、相关性和衰减:Mem0 使用自定义搜索算法,优先考虑最近的交互,并逐渐遗忘过时信息,保持记忆的相关性和实时性,而 RAG 不具备这种动态特性。
- 上下文连续性:Mem0 能在不同会话中保持信息的连续性,适用于长期交互,如虚拟伴侣和个性化学习助手,RAG 则缺乏这种会话间的记忆功能。
- 自适应学习:Mem0 基于用户的交互和反馈不断优化个性化记忆,而 RAG 依赖于静态数据,无法动态学习用户的偏好。
- 动态更新:Mem0 能根据新信息实时更新记忆,支持即时调整,而 RAG 只能依赖固定的文档数据进行检索,缺乏实时性。
我画了一张图来简单描述它的工作过程。
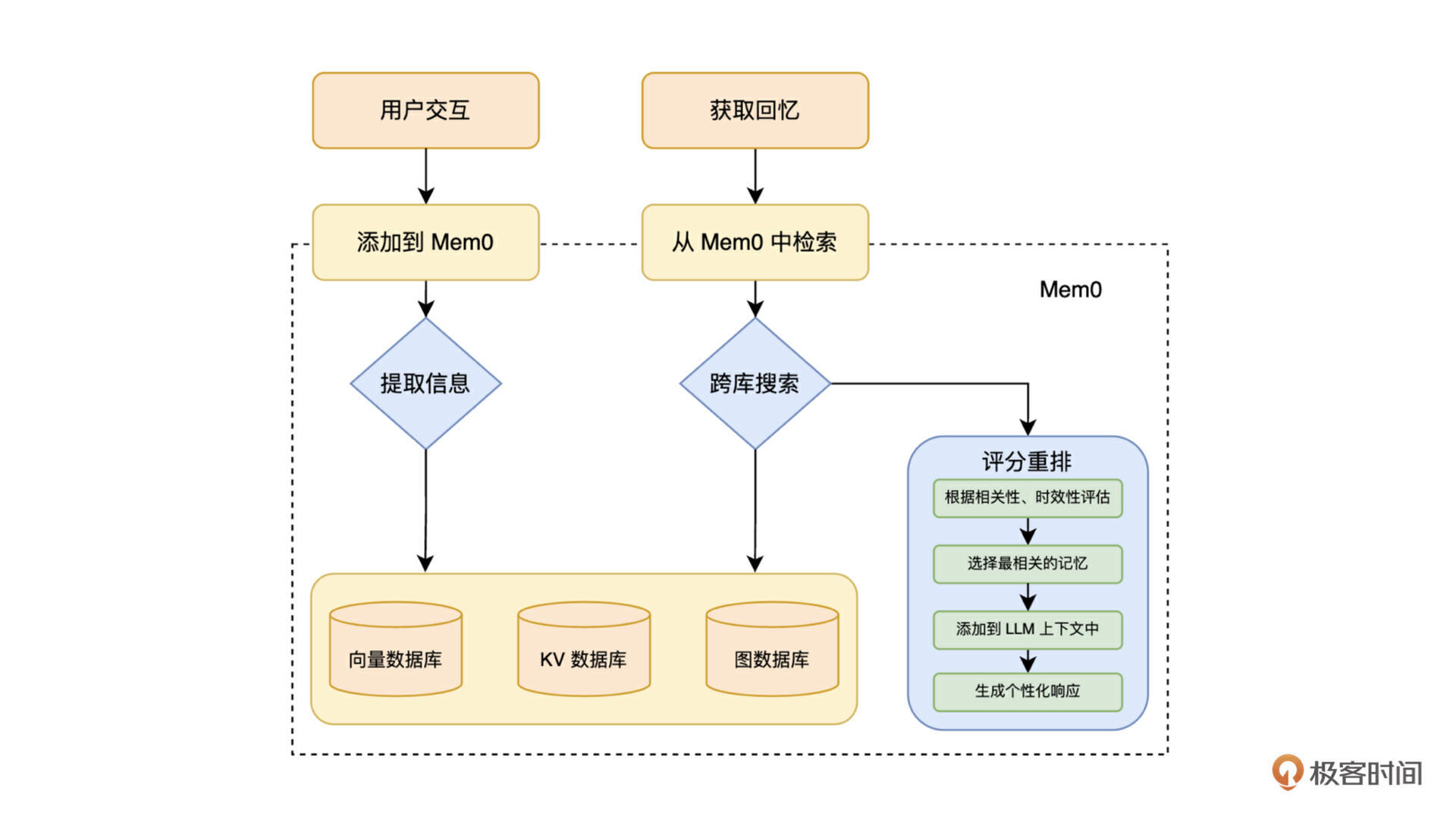
目前 Mem0 已经被广泛使用,应用在各种 AI 产品的后端。下面我们就基于 Mem0 来实现一下多轮对话。
实现多轮对话
按照上边的方案,构造对话上下文的流程如下:
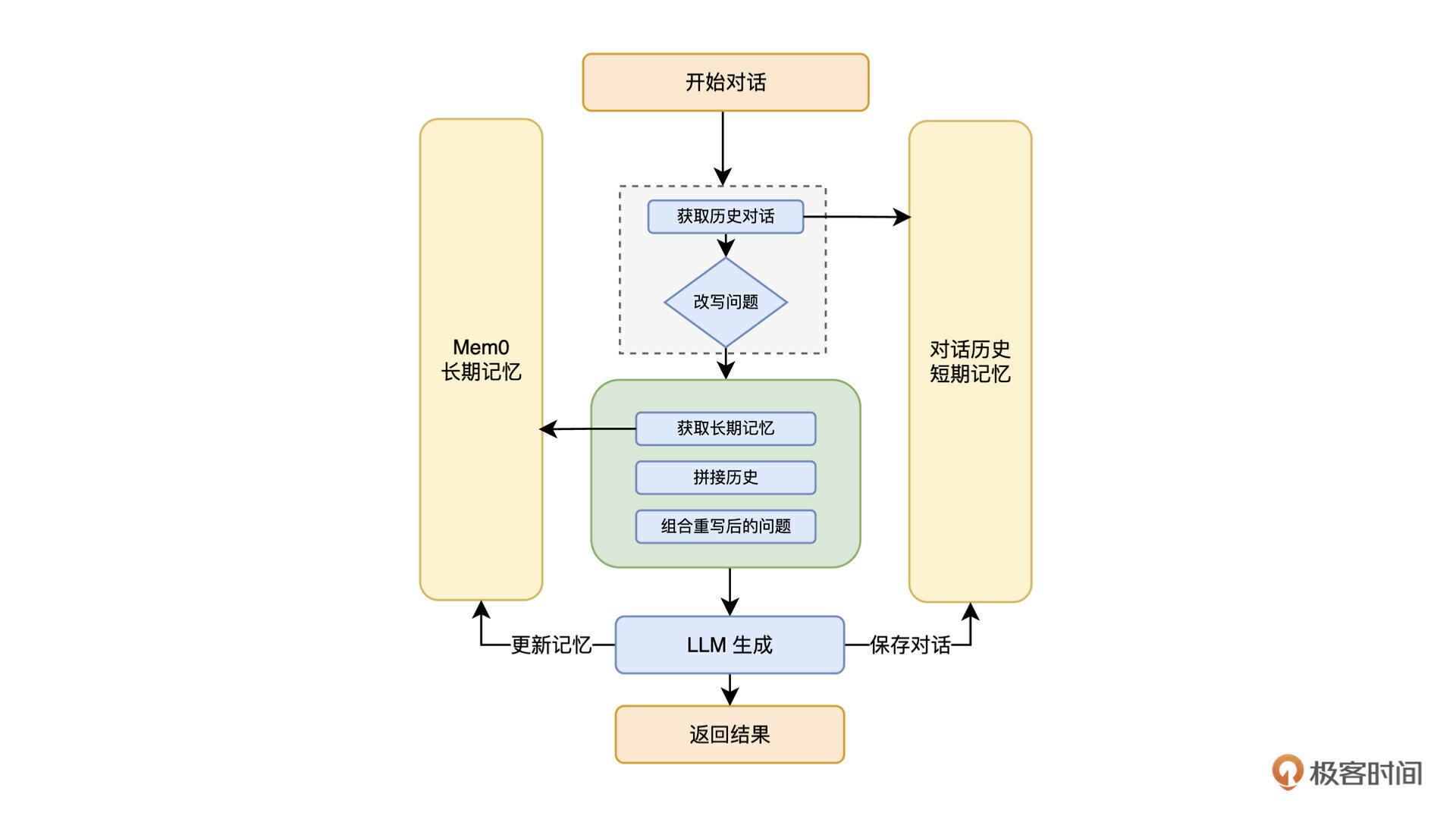
首先,我们使用传统数据库来保存历史消息,这个模块会提供读取最近 N 条消息和保存历史消息的功能。
# todo:消息体可以支持更多信息,比如消息类型,消息发送者等
class MessageEntiry:
def __init__(self, message: str, time: str) -> None:
self.message = message
self.time = time
class HistoryMessage:
def __init__(self, user_id: str) -> None:
self.user_id = user_id
# 保存消息
def save(self, message: MessageEntiry) -> None:
pass
# 获取最近的消息
def get_latest(self, count: int) -> list:
pass
之后用 Mem0 来实现长期记忆功能,Mem0 默认使用 Qdrant 作为向量数据库。这里我们直接用 Docker 启动一个 Qdrant(或者也可以使用 Qdrant Cloud 服务)存储记忆信息,使用 OpenAI 的 Embedding 模型作为向量化文本的模型。
# 初始化 mem0 客户端
config = {
"vector_store": {
"provider": "qdrant",
"config": {
"host": "localhost",
"port": 6333,
}
},
}
memory_client = Memory.from_config(config)
# 初始化 OpenAI 客户端
llm_client = OpenAI(
api_key="sk-xxx"
)
# 使用 mem0 作为长期记忆功能
class MemoryStore:
def __init__(self, user_id: str) -> None:
self.user_id = user_id
# 保存消息
def save(self, message: MessageEntiry) -> None:
memory_client.add(
message.message,
user_id=self.user_id,
metadata={"time": message.time}
)
# 查询记忆
def query(self, query: str) -> list:
memories = memory_client.search(query, user_id=self.user_id)
# 这里也可以使用 v2_search 方法,支持 metadata 过滤
# memories = memory_client.v2_search(
# query,
# filters={
# "AND":[
# {
# "user_id":"xxx"
# },
# {
# "time":{
# "gte": 123 # 大于等于时间戳
# }
# }
# ]
# },
# )
return memories
最后我们实现对话逻辑,参考如下:
def chat(user_id: str, question: str):
# 获取历史消息
history = HistoryMessage(user_id)
messages = history.get_latest(3)
# 组合消息 重写问题
question_context = messages.join("\n")
question_context += "\n{}".format(question)
# 调用 llm 进行重写
llm_completion = llm_client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "根据对话内容和用户问题,重写一下问题,完善一下必要的信息。"},
{"role": "user", "content": question_context}
]
)
rewrite_question = llm_completion.choices[0].message
if rewrite_question is None:
rewrite_question = question
# 获取长期记忆
memory_store = MemoryStore(user_id)
memories = memory_store.query(question)
# 组装 prompt
prompt = "长期记忆:\n"
for memory in memories:
prompt += memory.get("memory") + "\n"
# 添加对话记录
prompt += "对话记录:\n"
for message in messages:
prompt += message.message + "\n"
# 添加重写问题
prompt += "对话:"
prompt += rewrite_question
# 调用 llm 进行回答
response = llm_client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是极客时间专家,精通各种编程领域问题。。."}, # 这里根据业务设计角色信息
{"role": "user", "content": prompt}
]
)
answer = response.choices[0].message
if answer is None:
answer = "对不起,我不知道怎么回答你的问题。"
# 保存消息
history.save(MessageEntiry(question, time="123456")) # 这里可以扩展增加 AI 回复的消息
memory_store.save(MessageEntiry(question, time="123456"))
return answer
以上是多轮对话的主要逻辑实现。在真实使用场景中,可以完善 MessageEntity,增加 AI 回复,等等各种环境参数。在增加记忆的时候,也可以分类记忆,把额外的属性信息放到 metadata 中,方便在查询的时候,更加精准地选择合适的记忆内容。你也可以加入你的思考,在整个处理流程的每个阶段,更加精细化地处理数据,使最终的效果越来越好。
扩展记忆的应用场景
记忆功能让 LLM 能够针对每个用户提供个性化的服务,在用户体验上可以提升一个档次,同时也给 LLM 扩展了很多能力,比如:
- 上下文理解能力:本节课的多轮对话就是一个应用场景,通过对上下文的理解,使得 LLM 能理解整个对话的脉络,帮助 LLM 提供更加连贯、相关的回答,避免重复或矛盾的内容。
- 个性化交互能力:通过记住用户的偏好、习惯和背景信息,LLM可以为每个用户提供高度个性化的体验。比如,它可以记住用户喜欢的话题、表达方式,甚至是用户的情绪状态,从而调整自己的回答风格和内容。
- 长期任务处理能力:对于需要多次交互才能完成的复杂任务,记忆功能可以帮助LLM跟踪进度和中间结果。比如一些简单的对话类小游戏,就可以用这个来实现。
- 知识积累和更新:知识更新能让 LLM 提供更加准确的回答,对于极客时间来说,以前 A 用户一直提问前端问题,最近一段时间一直问后端问题,我们就可以判断用户最近对后端内容更感兴趣,从而更新记忆,在对话中给用户提供更多后端知识。
- 情感连接能力:通过记住与用户的互动历史,LLM可以建立一种类似于“情感连接”的能力。它可以回顾过去的对话,引用之前的互动,这种连续性可以让用户感觉到被理解和被重视。这个能力应用在客服类产品中,会给用户带来更加贴心的服务体验。
- 深度分析能力:通过把记忆点连接成网络,形成记忆地图,能挖掘出更多用户深层次的需求,再配合上已有的用户数据,可以去预判和推断用户的行为,提前发现问题,帮助用户更好地解答问题。
以上这些场景分析仅仅算是抛砖引玉,记忆能力本质上是给每个用户分配了一个专有的助理,一个知道用户喜好和习惯的助理,如果配合上用户画像和自己平台的数据分析系统,就可以为每个用户提供更加贴心的服务。
小结
记忆功能对 LLM 来说是如虎添翼,大大丰富了 LLM 的应用场景。这节课我们介绍了一些使用场景,你也可以结合你的业务,探索一下适合自己需求的场景,也欢迎你在评论区分享你的思考,我们一起讨论。
- 乔克哥哥 👍(0) 💬(0)
可以实现一个银翼杀手2049里的电子女友
2025-01-18