03 智能推荐:在对话中为用户推荐内容
本门课程为精品小课,不标配音频
你好,我是王吕。上节课我们讨论了极客时间小助手的功能和设计,这节课我想跟你聊聊如何在对话过程中给用户推荐优质内容,这里以极客时间课程推荐为具体案例。
我们知道,在极客时间的课程中,对话消息中的上下文包含了文章片段,有了文章片段,我们就可以得到文章 ID 和课程 ID,之后我们就可以把引用的课程推荐给用户,整个过程如下图:
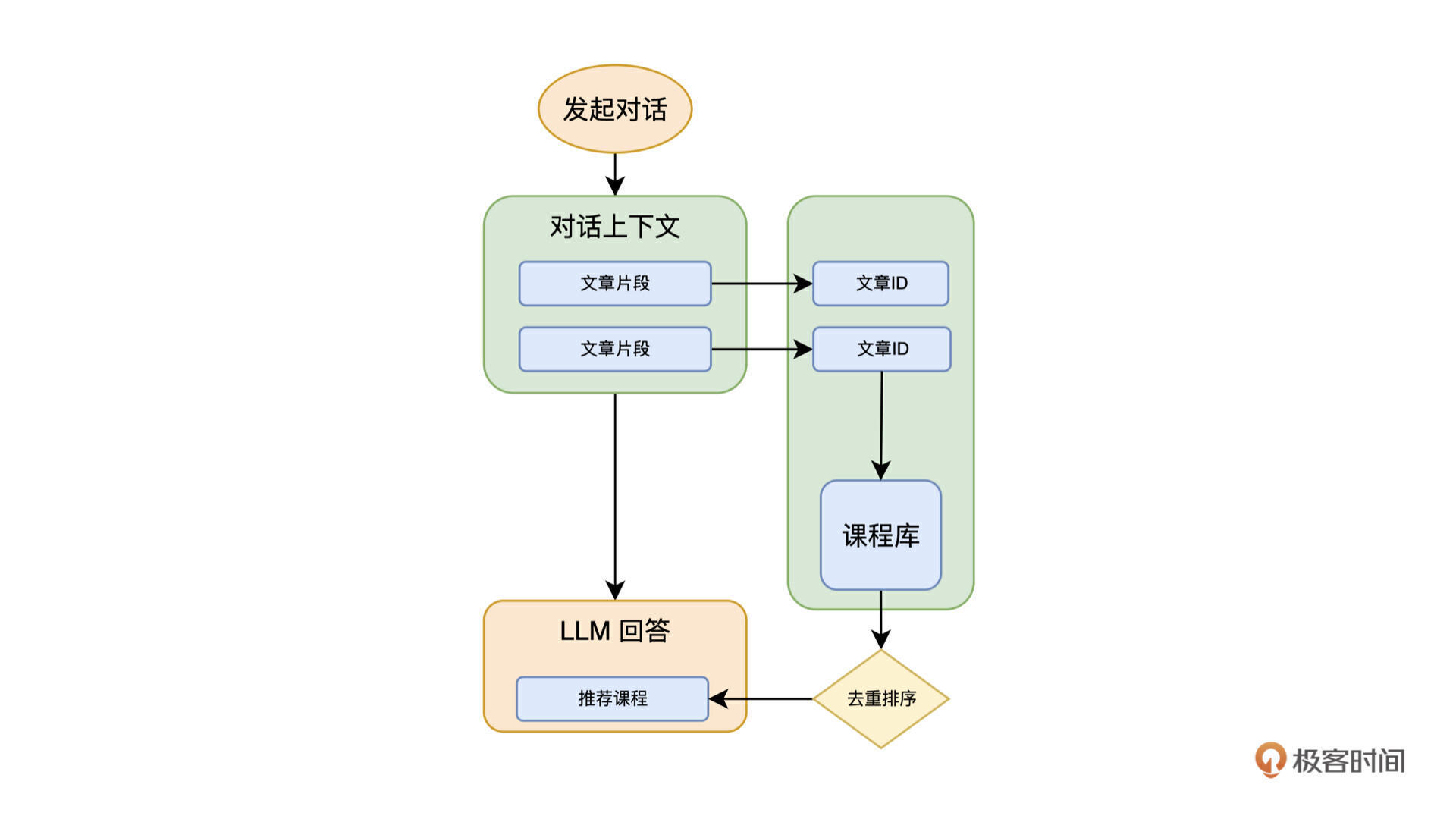
这是最直接的方案,实现起来也非常简单,把引用文章所属的课程直接推荐给用户,听起来也很合理。
我们假设这样一个场景:我是一名后端工程师,我问了一个 Nginx 相关的问题,恰好有一门前端课程,整个课程只有一个小节的一小部分用上了Nginx,其余部分都是前端知识,这个时候,很有可能这个课程也被推荐给了我,但这并不是我想要的。
为什么会出现这个问题呢?其实根本原因还是在于我们想要推荐的课程是一个整体,它有自己的主题,而课程下的文章被分割成段落之后,每个段落也有了自己的主题,这两者很多时候并不是完全一致的,如果按照段落去找课程,很容易就会以偏概全,导致推荐出不合适的课程。那么,极客时间是怎么解决这个问题的呢?
我们给课程也增加了 Embedding。在向量数据库,我们增加了一个课程集合,每当有课程上新,我们就在课程集合里增加一条记录,根据课程的介绍生成向量。用户提问的时候,还是按照上下文的规则,拿到引用课程,同时使用问题向量去课程集合检索,找到最接近的2门课程,和引用的课程做一下合并去重,重新排序之后,取前 3 条作为推荐课程推荐给用户。我画了一个流程图供你参考。
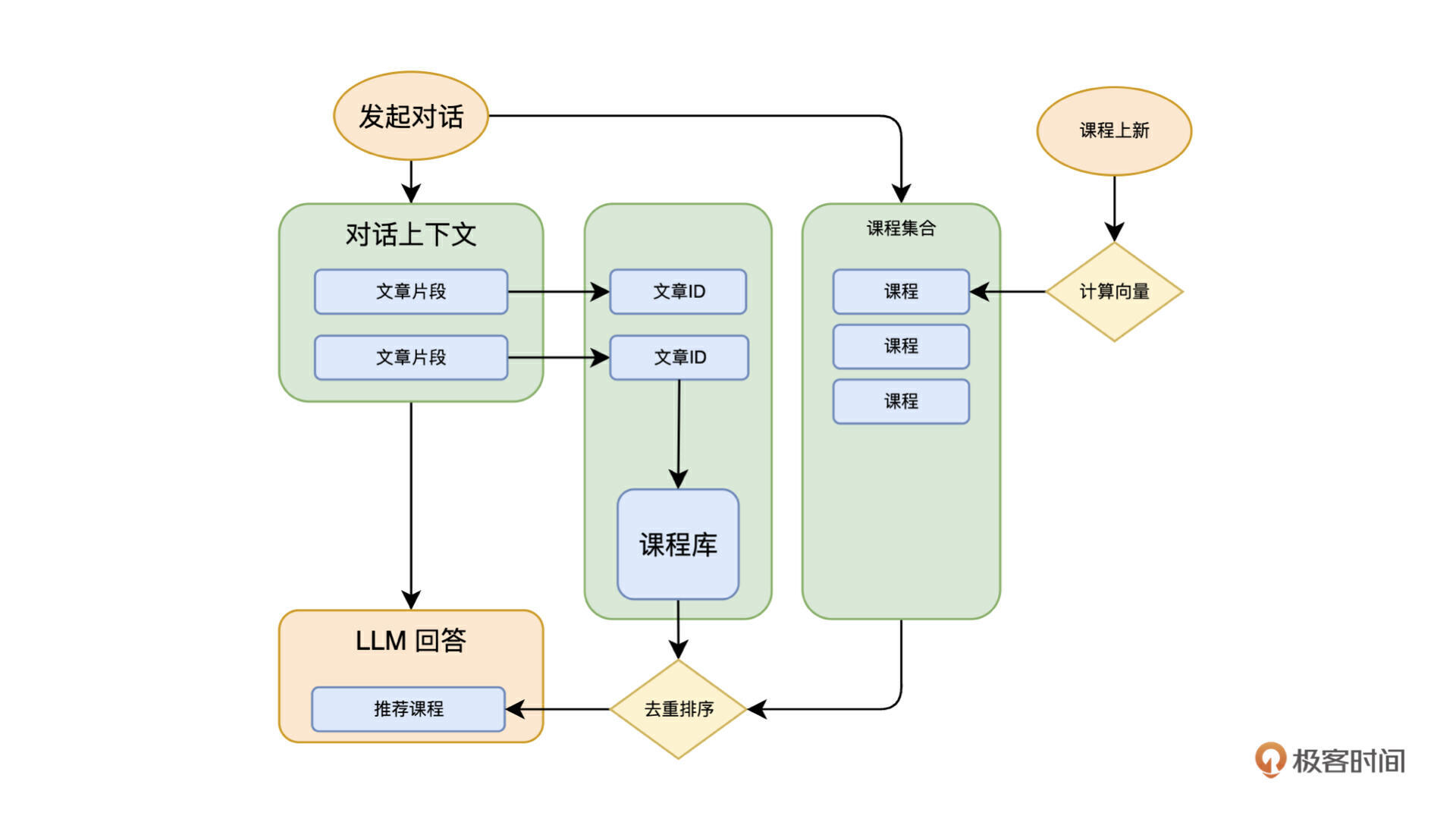
这是目前小助手的实现方案,已经可以做到尽量减少上边假设的问题了,不过这个实现还有没有什么可以改进的地方呢?
当然有,下面我按照数据流向讲一下各个环节遇到的问题以及对应的解决方法。
数据准备阶段
对于极客时间的课程,编辑同学都会精心设计课程介绍,课程介绍里包含了很多图片素材,使用课程介绍计算向量的时候,图片没办法参与计算,这样就导致课程向量不是很准确,缺少了很多关键信息,所以在使用用户问题检索的时候,匹配度不太稳定,明明非常符合用户需求的课程,却没有被检索到。
针对这个问题,我们首先想到的就是 OCR,把图片进行 OCR,然后和文本一起做成向量。当然这样相比之前会有提升,不过这又会带来新的问题,图片中的文字如果跟课程内容相关性不高,会导致生成的向量跟用户问题匹配度降低(图片可能会有很多推广内容)。这时候,我们可以再尝试这样的改进。
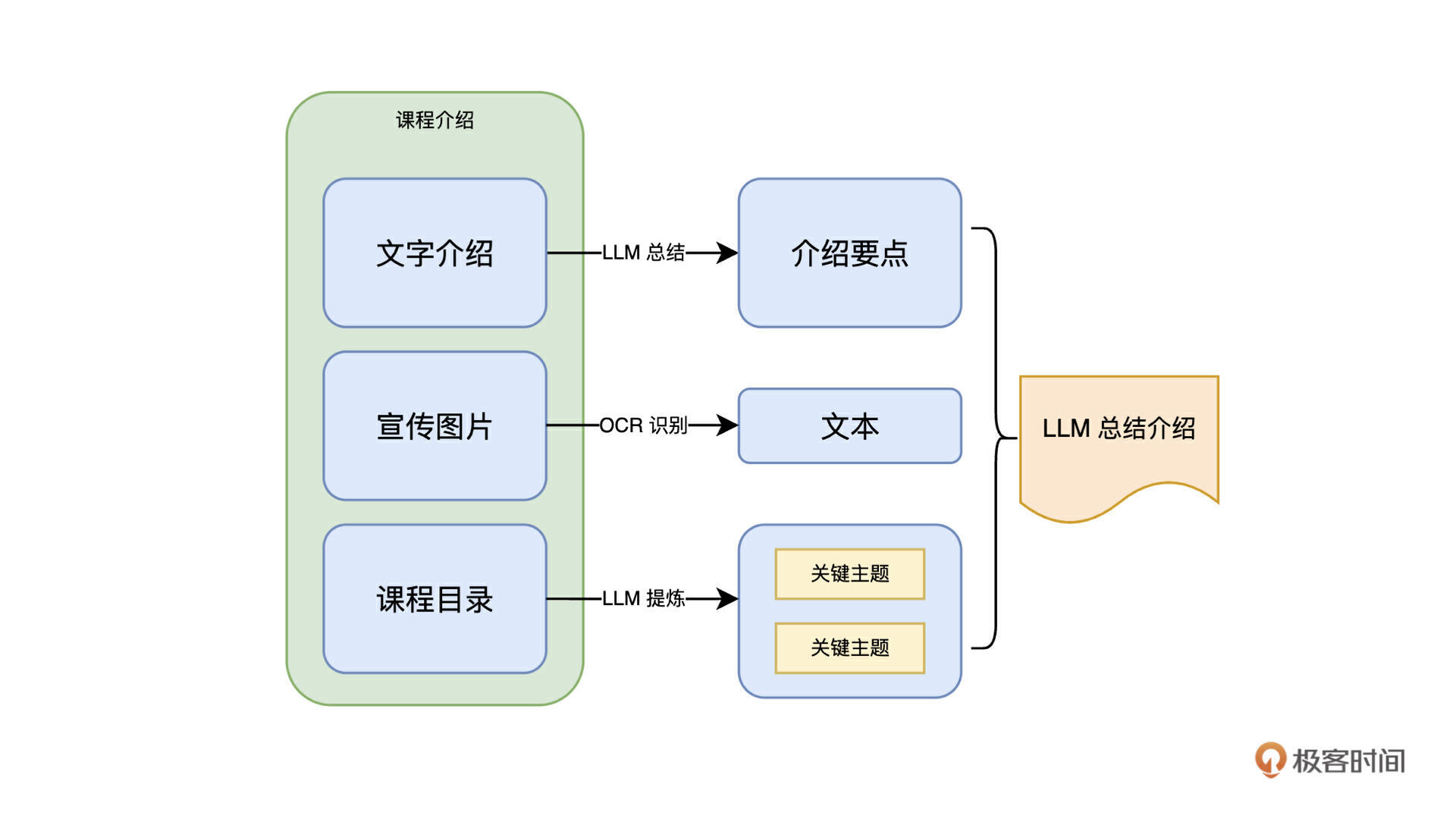
得到 OCR 之后的课程介绍后,我们先用 LLM 总结提炼一遍介绍的要点,同时针对课程目录,也总结成几个关键主题,把这些要点合并起来,这样的文本可以尽量精准地描述这门课的内容,我们把它作为这门课程的向量,进一步提高了向量描述课程的准确度。
对话阶段
在这个阶段,我们第一个可以改进的点就是优化用户的提问。用户发起对话之后,拿到用户问题的同时,去历史记录里拿到最近的两条或者三条记录,结合在一起,使用 LLM 重写一遍,重新描述一下用户的问题,使用这个问题作为本次对话的用户问题。这里要注意的是,重写之后,可以判断一下用户是否在讨论编程或者学习相关的问题,只有用户对课程有需求的时候,才去进行后边的推荐。
第二个可以改进的地方是推荐课程的排序。使用问题去课程集合检索,得到了推荐课程,去文章集合检索,得到了引用课程,两个结果数组合并到一起,首先想到的是去除重复课程。不过这里有一个小技巧,就是如果一个课程在两边都出现了,那么说明这门课的匹配程度还是很高的,所以可以把重复出现的课程去重之后,排到最前边,之后的权重关系是:来自课程集合的推荐的权重是大于引用课程的,不过,如果有多个相同的引用课程,那么它的权重可以认为是大于课程集合的推荐的,我用一张图来解释一下权重的大小关系。
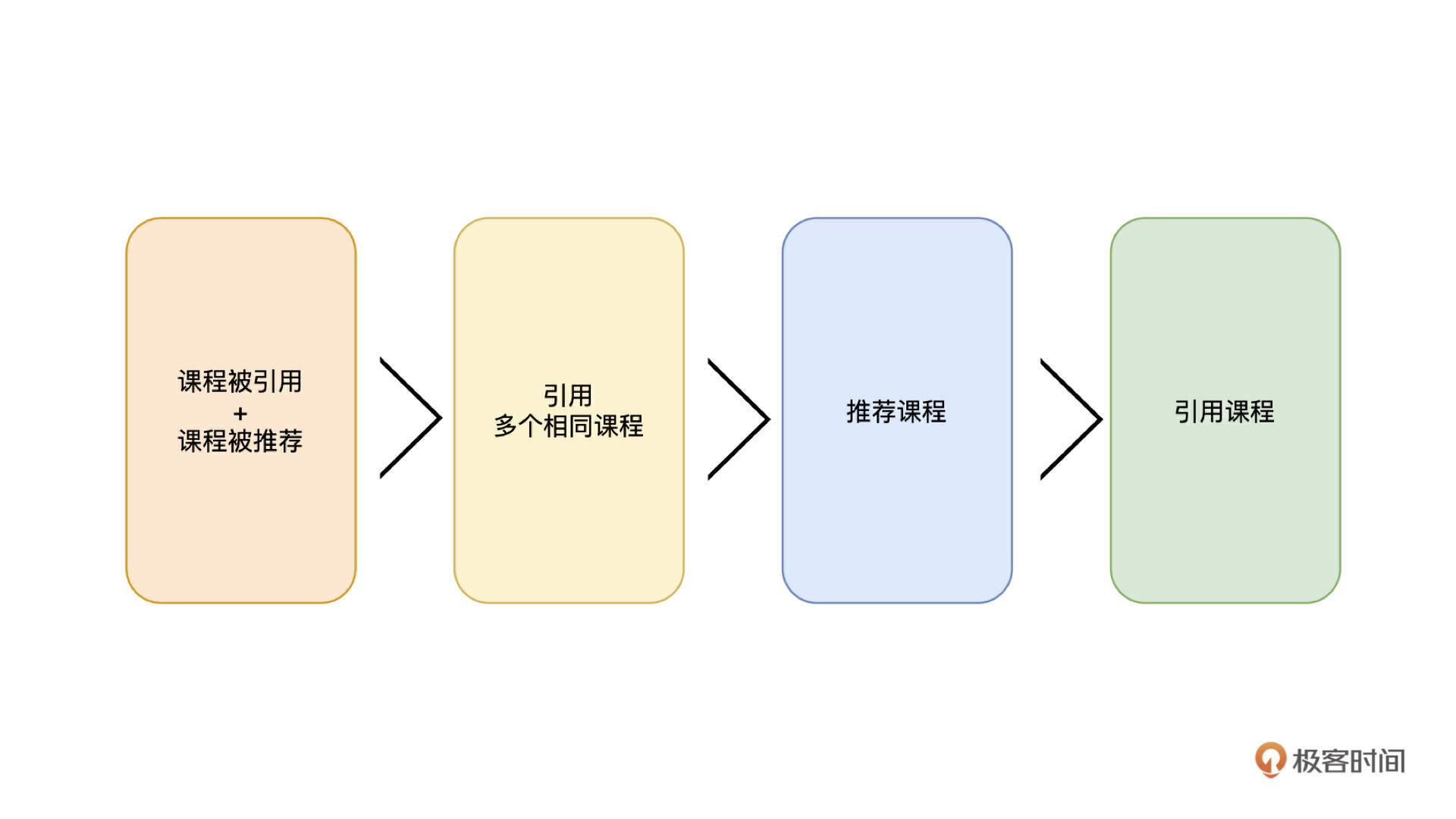
数据优化阶段
每个课程都会携带埋点数据,经过上报处理之后,我们会拿到反馈,在推荐的 ABC 三门课程里,哪个点击率更高。这里的策略可能稍微复杂一点,涉及到用户画像和传统的推荐系统结合了。
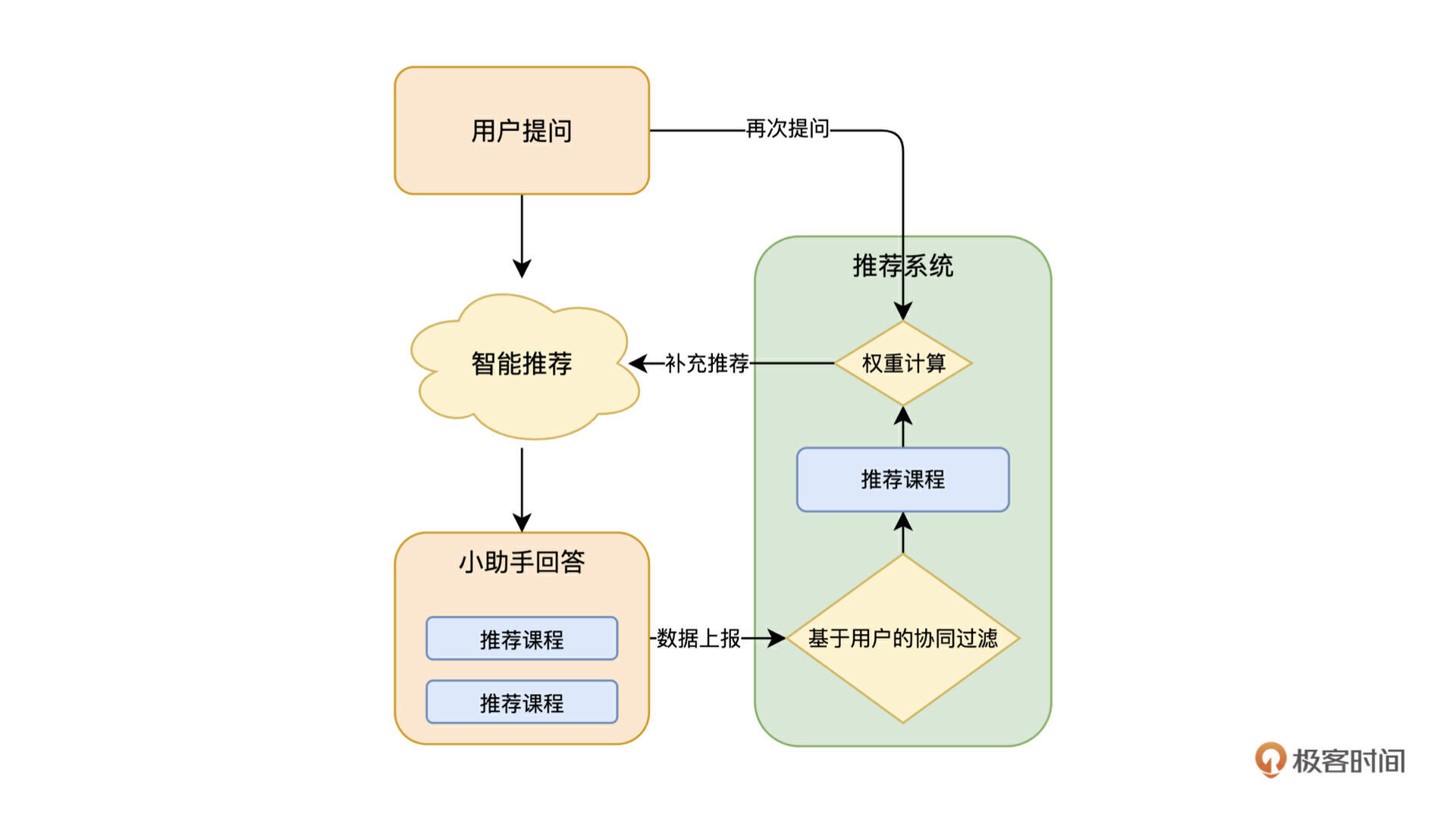
这部分推荐属于系统干预推荐,基于极客时间的用户画像,使用基于用户的协同过滤方法,找到可以推荐给这个用户的课程集合,然后再基于问题计算向量近似度,找到推荐的课程,放到上边的推荐课程排序列表里。作为第三类来源的课程,这里的权重就看具体的策略是如何制定的,如果想要更多人工干预,就增加这部分课程的权重即可。
经过以上几处优化,推荐内容质量也会有一个很大的提升,那么在代码实现的时候,推荐内容放到哪里呢?
这可以基于对话接口的实现方式来考虑。
针对没有采用流式输出的接口,推荐课程可以直接放到响应结构体里,毕竟 LLM 生成回答需要的时间远远大于计算推荐课程的时间,这里可以在服务端使用协程并发处理两条业务流。
如果使用了流式输出对话,那就有意思多了,还记得上节课我们讲过的 SSE,它的数据格式如下:

这里的 data 字符串不是固定的,我们可以自定义成任意字符串,只需要在前端增加对应的解析就可以。比如,我们的推荐数据放到 SSE 流中可以是这样的:

有了这个启发,我们其实可以在 SSE 中塞入任何的内容格式,制定我们自己的数据协议。
小结
这节课我们了解了极客时间小助手的推荐课程能力,也探讨了在不同的数据流阶段改进推荐效果的一些方法。其实还有很多改进方法,课程列出的只是其中的一部分,和极客时间内容匹配的一部分,你也可以根据你的数据集的特点,制定自己的优化策略。核心原则就是通过 LLM 精准描述内容特点,尽力识别用户意图。
希望能对你有所启发,也欢迎把你的想法写到评论区,我们一起交流。
- 大魔王汪汪 👍(2) 💬(1)
可以简单介绍下用户画像和协同过滤部分的方法吗
2024-09-18 - 愤毛阿青 👍(0) 💬(1)
围绕用户问题如何将内容库匹配度高的内容推荐给用户,一步一步将问题掰开,干货满满
2024-09-09