02 学习小助手:基于企业私有数据构建聊天机器人
本门课程为精品小课,不标配音频
你好,我是王吕,欢迎你跟我一起来学习大模型 LLM & RAG 快速应用。今天我准备给你介绍一下极客时间小助手的开发细节和考量,希望能解答你在大模型对话系统开发过程中的问题。
极客时间小助手是一个基于 RAG 技术的对话问答应用,他的特点就是使用了极客时间课程内容作为知识库,利用讲师专家的经验作为背书,提供更好的技术类问答能力。入口在这里:https://aibot.geekbang.org
这是一个标准的 RAG 应用场景,下面我们从需求到技术仔细聊聊。
需求设计
我们开发小助手的核心目的是使用大模型技术帮助用户解答编程问题,其次是通过用户问题,找到用户可能感兴趣的内容,推荐给用户。
目的已经明确了,我们开始一步一步思考实现。既然要让大模型使用极客时间的知识库回答用户问题,那么就要把我们的知识资料输入给大模型,目前主要是两种方式,Fine-tuning 和 RAG,以下是两种技术的对比。
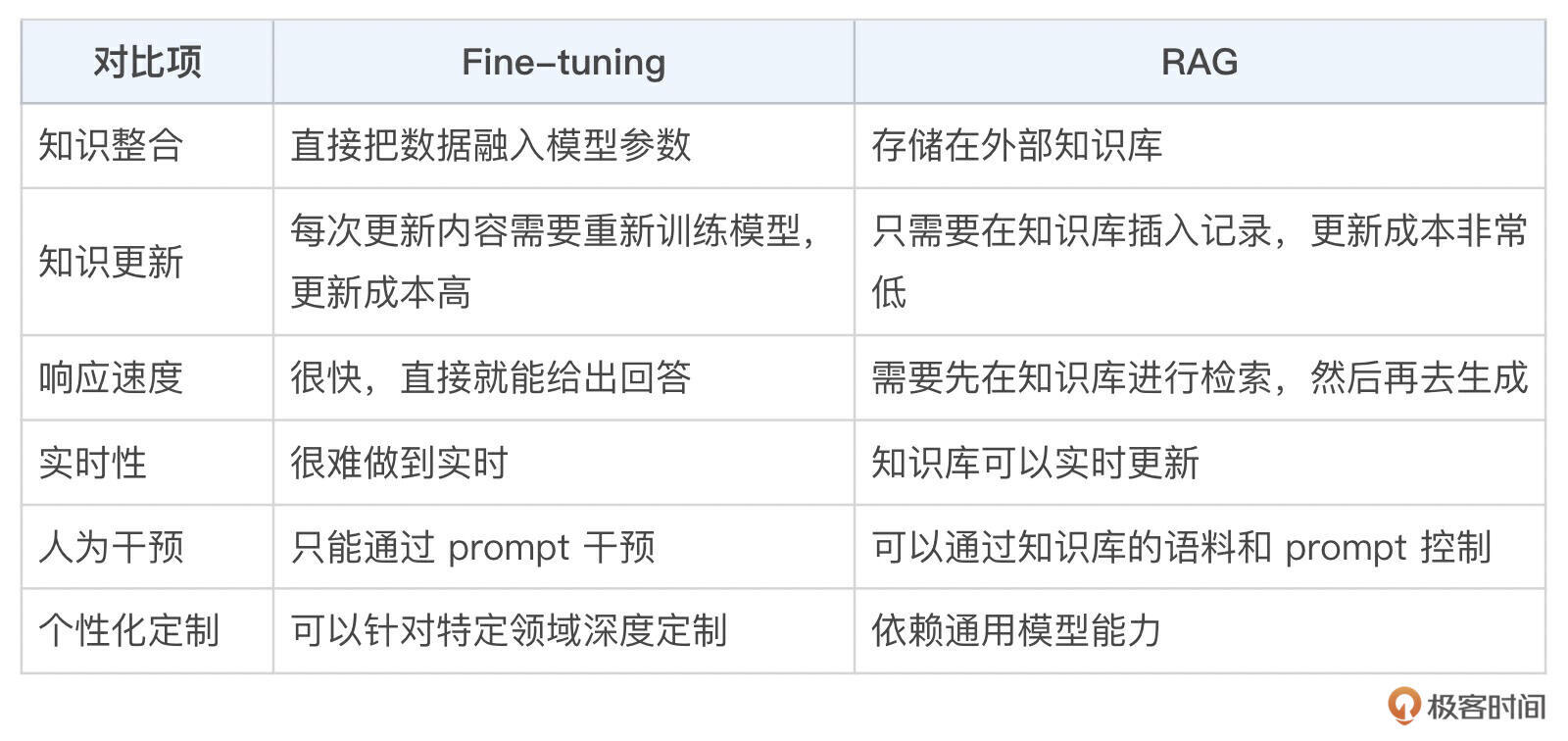 我们对小助手的要求是,要能实时更新知识资料,不需要模型去深度探讨问题,重点使用我们的知识经验去解答用户问题。基于此,我们选择了 RAG 技术作为技术方案。
我们对小助手的要求是,要能实时更新知识资料,不需要模型去深度探讨问题,重点使用我们的知识经验去解答用户问题。基于此,我们选择了 RAG 技术作为技术方案。
这里你可能会想,那什么时候使用 Fine-tuning 合适呢?
- 特定场景下的高一致性和定制化:比如让助手回答品牌宣传和企业文化相关内容。
- 数据量充足并且稳定:拥有高质量的对话原始数据的情况下,如果基于现有数据做对话助手,可以直接使用原始数据微调。
- 强个性化需求:比如文言文理解和输出,需要使用大量文言文语料微调之后,才能适当地满足要求。
- 高速响应:相比 RAG,微调模型能够直接输出有效内容,所以响应速度理论上要比先检索再生成快很多。
要使用 RAG,第一步要先构建知识库。
极客时间最大的知识库就是各种优秀的专栏及文章数据,我们只是需要把文章内容“投喂”给大模型,即把文章作为上下文和用户问题一起发送给 LLM,让 LLM 根据上下文做出回答。我们知道,所有的大模型针对输入都是有长度限制的,计量单位是 token,一个 token 对应了一个英文单词、一个英文短语或者一个汉字,比如 OpenAI 的 GPT-3.5 模型,最大 token 长度是 4k,这个数量包含了输入和输出的总和。极客时间的一篇文章就 4000 多字了,所以第一个问题来了,我们要对文章进行切片,把文章切成一段一段的段落,然后挑选最合适的段落再结合用户问题去向 LLM 提问。
所以整个小助手应用就分为两个系统:
- 构建并且更新知识库,把文章更新到知识库中。
- 提供问答能力,结合前端构建用户端应用。
以上是我们当时做小助手的思考过程,现在看起来就是简化版的 RAG 的推导过程。
技术实现
目前线上版本的小助手还是基于以前刀耕火种的技术方案,在介绍实现的时候,我会用当前的实现结合最新的行业应用方案(小助手也在基于最新技术方案重构中,敬请期待),讲解一下实现的关键要点和相关问题。
构建并更新知识库
这个可以参考第01讲的内容,没有阅读的话可以先回去看一下。我们需要把文章数据进行建模放入数据库中,并且实现实时更新,这里我们遇到的最大的问题,就是如何切割文档,我们尝试过的方案包括:
- 按照固定长度切割
- 按照 \n 换行切割
目前线上在使用的方案是两种结合在一起,先按照换行切割,如果段落超过长度,再根据长度切割。
按照长度进行切割的时候,会有一个 buffer,尽量防止出现生硬截断的情况。比如长度设置在 50 个字符,buffer设置的是10,截断位置前5个、后5个,恰好第52个字符是结尾句号。如果不设置buffer,那么就会直接截断,造成前后两个段落不是一个整体。有了buffer之后,就会从 45开始读取到55,如果检测到 52 位置是句号,那么就会从这里进行截断,保证了前后两个段落完整。此刻机智的你可能会有一个问题:假如 55 位置是句号呢? 那你可太细心了,这种方式只能做到尽量,无法做到彻底。
这里还有一些当时我们遇到的问题,供你参考。
1. 固定长度要切多长?
这个问题我们尝试了非常非常多次,无论怎么样切割,总会出现特例,这也是最终我们优先使用段落分割,其次再使用固定长度切割的原因。不过这里还是有一点我们大量尝试得到的经验,就是段落长度固然是一个参考点,还有一个重要参考点,就是上下文的设计规则,我画了一张图来说明一下上下文的构成。
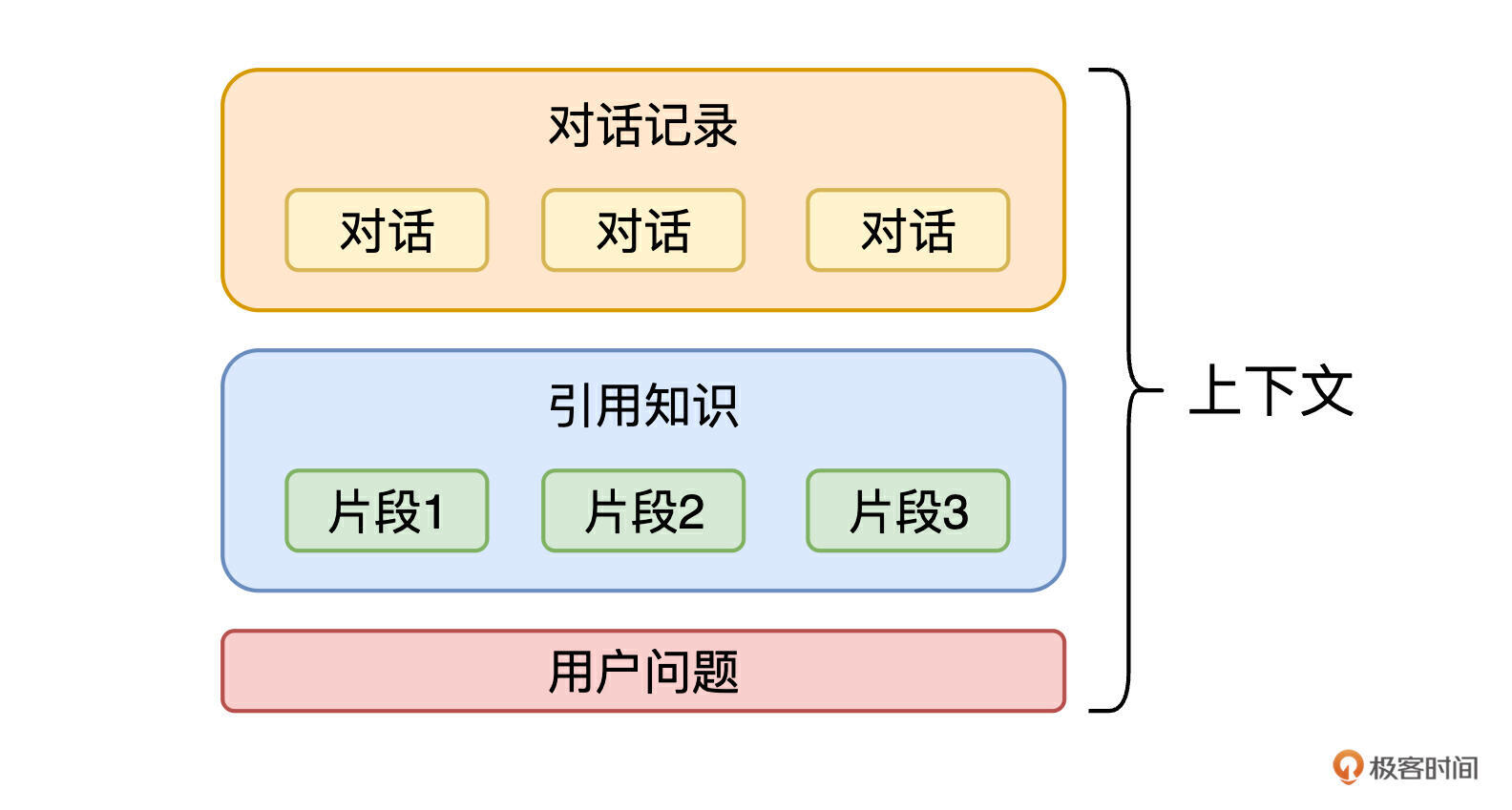
可以看到,在一轮问答中,占主要长度的是引用的资料数量和回答长度。回答长度确定之后,留给引用资料的 token 数量也就基本上确定了,然后我们再确定引用多少条资料,这个就要根据业务情况来了。极客时间目前选了5条,剩余的token数量除以条数,就可以知道每条资料要包含多少内容了。这里也要注意一下,要给对话预留出一点 token。
2. 只有 \n 换行作为语义分割吗?
换行是一个性价比最高的选项,当然这在现代 RAG 理论中,叫做“内容感知切割”,如果我们的文章使用了 Markdown 或者 HTML 标签语法,基于语法标签切割也是一个很好的选择,现在很多工具也都提供了这些能力。
这里稍微透露一下,重构版的小助手使用了 llama-index 库,里边集成了多种切割方案,甚至你也可以自定义一种文档处理方法。
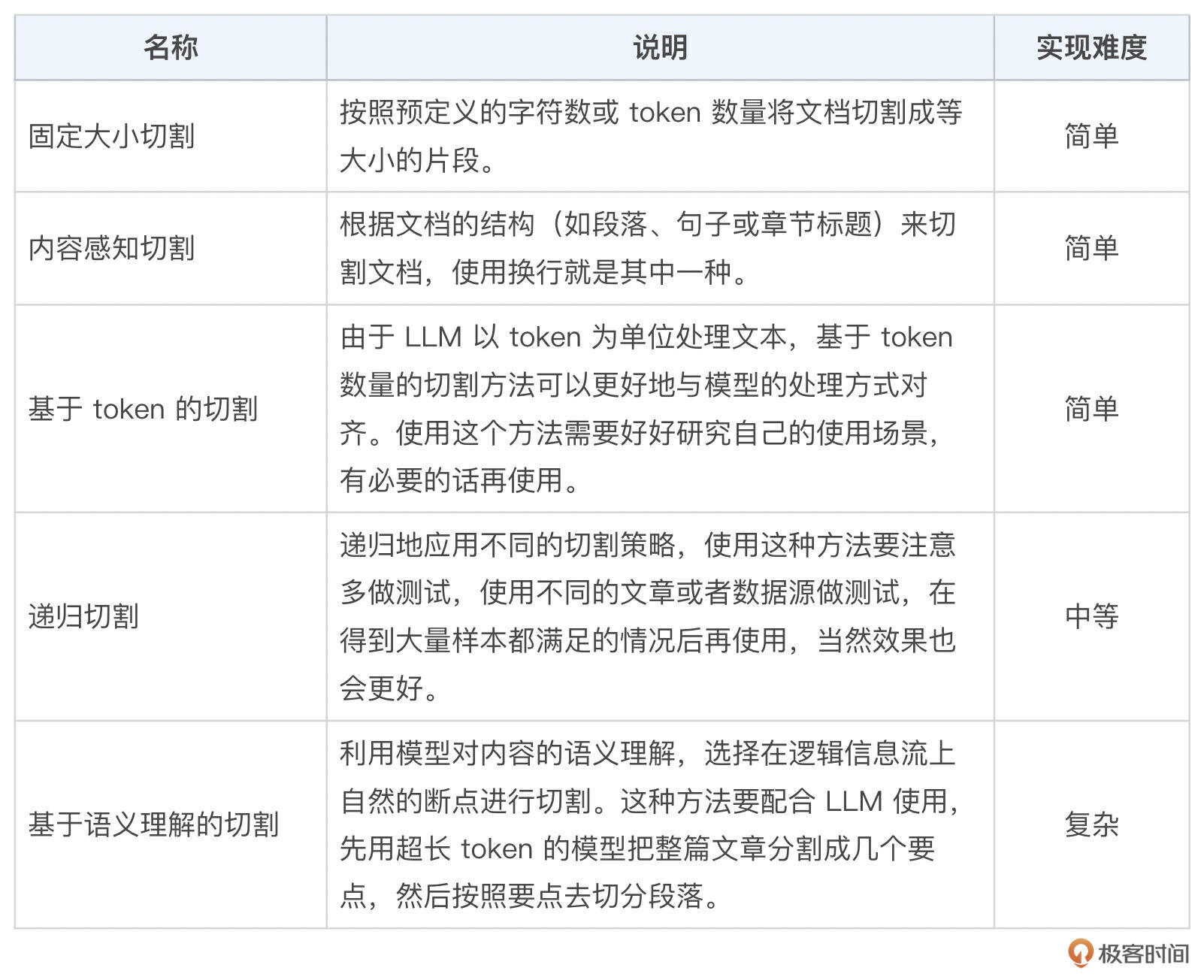
3. 还有其他的分割方式吗?
有的,这里我把目前行业内的通用方法都整理成一张表格,帮你扩展一下思路,你也可以根据自己的知识储备情况,自由组合使用。
实现对话应用
知识库构建好之后,接下来我们开始实现小助手的问答能力。
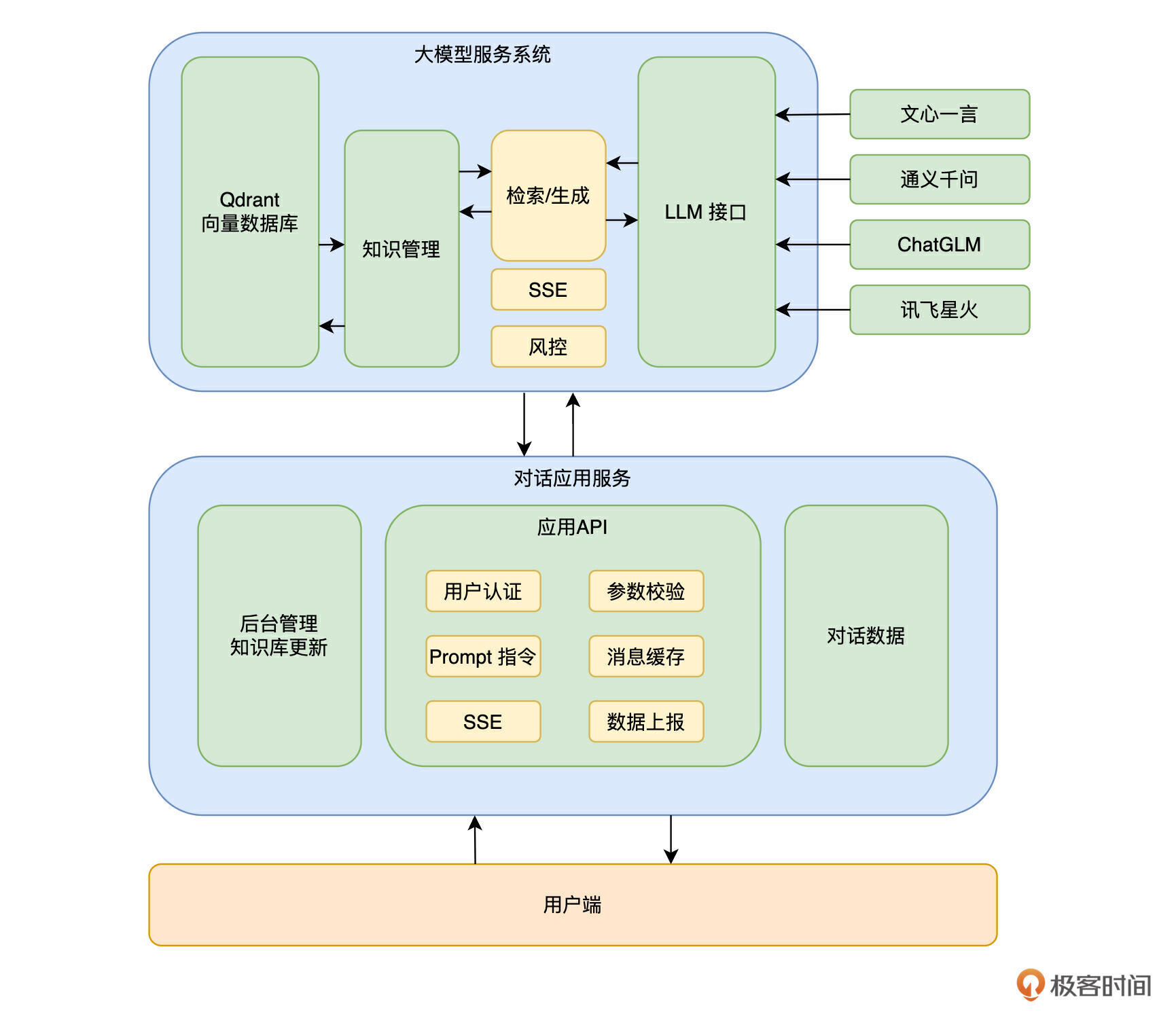
这里先放一下极客时间的对话应用结构图。
极客时间后端技术栈以 Golang 为主,这里分成了两个服务。
- 大模型服务:这个服务包含了模型处理和知识库处理功能,相当于把 LLM 和 Qdrant 向量数据库的部分抽象了出来,在这里消化掉不同模型的差异,统一文档处理,和业务无关,对外输出统一的接口能力。
- 对话应用服务:这个服务主要是和业务相关,包含了针对前端的接口服务,针对服务端不同业务的数据处理能力,还有一些对话数据的管理能力。
1. 大模型服务系统
我们把和大模型有关的功能都放到了这里,包括 LLM 和 Qdrant 相关功能。目前我们接入了 5 家大模型,定义了一个接口,封装各家模型,实现了这个接口,然后在请求参数里控制使用哪家模型。同时每个模型要支持多个 key 的轮换,防止某个账号出现问题,导致服务不可用的情况。这里还接入了统一风控,针对用户输入和 LLM 输出 (可选)做了安全过滤,保证经过大模型的数据一定是合法合规的。不过这里使用风控会有一些限制,一会介绍 SSE(HTTP Server-Sent Events) 的时候会解释。
2. 对话应用服务
这里就是业务系统了,根据不同的业务包装不同的 prompt。当然这里的 prompt 严格意义上来说还不是完整的 prompt,毕竟文档上下文相关的内容是在大模型服务系统里。这里的 prompt 会使用占位符和参数控制哪里需要什么类型的上下文,传递给大模型服务系统之后,才会拼出完整的 prompt。用户对话记录相关的数据会保存在这里,对话记录会记录相关的文章ID、专栏ID等业务数据,携带几轮对话也是在这一层实现的。
在极客时间上,我们实现了一个 message cache 模块,每个用户都会有一个 cache,存储用户最新的 3 条消息,采用 FIFO 的方式,每次会把这个cache 作为对话记录部分传递给 LLM。
在供给前端的接口方面,可以支持流式对话选项,能让用户快速得到响应,这也要求大模型服务系统也得支持这个能力。极客时间使用的是 SSE 技术方案,接下来我来聊聊这个技术。其他厂家也可能使用 WebSocket,这里我简单对比一下这两种技术,你在选型的时候可以做个参考。
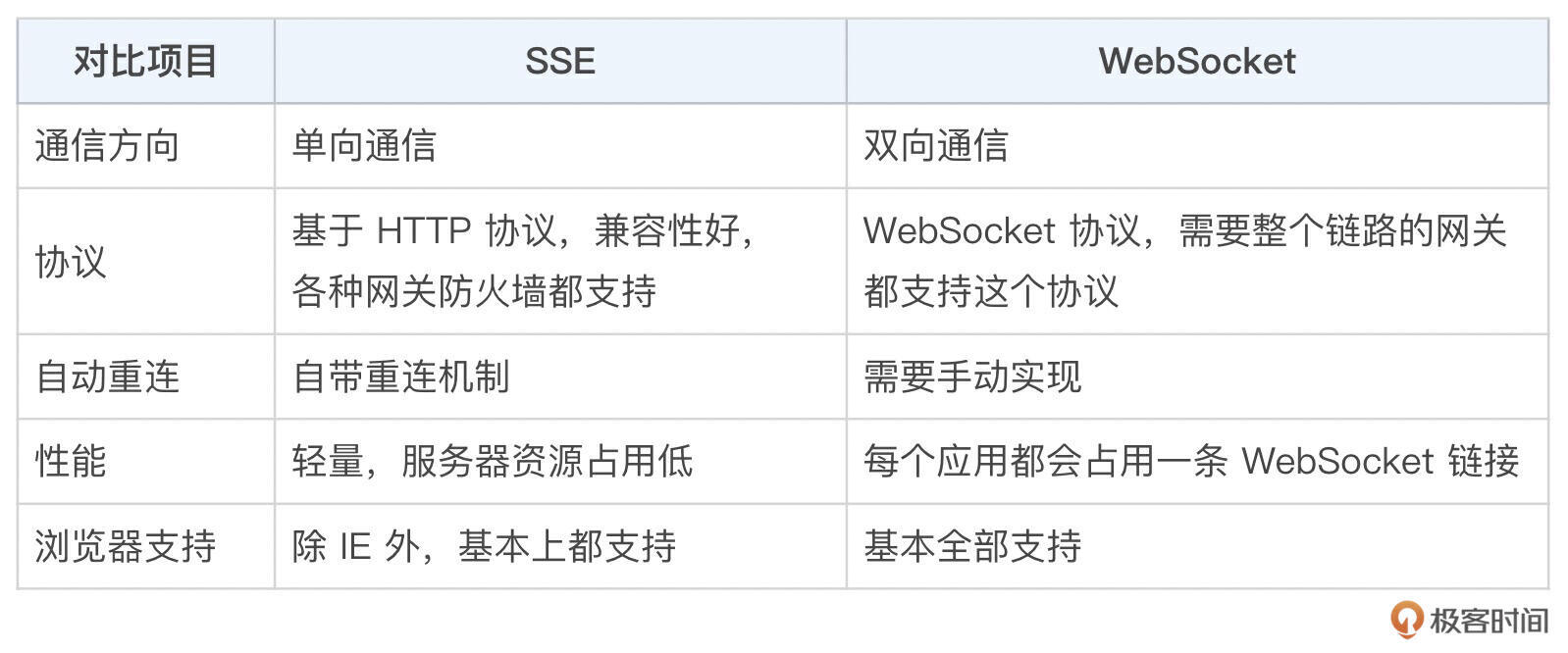 除非是要兼容 IE 浏览器,否则 SSE 是更合适的选择。
除非是要兼容 IE 浏览器,否则 SSE 是更合适的选择。
SSE 技术
SSE(Server-Sent Events)是一种允许服务器主动向客户端发送实时更新数据的技术。它是 HTML5 标准的一部分,通常用于建立从服务器到客户端的单向数据流(就非常适合流式对话场景)。在 SSE 中,客户端通过一个 HTTP 请求与服务器建立连接,服务器可以在连接期间不断地推送事件到客户端,直到收到截止符,而无需客户端重复发送请求。
我们使用 Golang 结合 channel 实现了 SSE 消息的接收。
// 使用一个 channel 用来处理每次请求
ch := make(chan ChatStreamResponse)
// 在协程中读取第三方的 SSE 相应结果,解析成一条一条的消息发送到 channel 中
go func() {
defer close(ch)
// 读取 SSE 响应
reader := bufio.NewReader(rsp.RawBody())
defer rsp.RawBody().Close()
for {
// 按行读取,每行就是一条消息
line, _, err := reader.ReadLine()
if err != nil {
if err == io.EOF {
return
}
log.Context(ctx).Error("chat glm sse read request error", request, err)
return
}
// 解析每条消息,协议标准格式:data:{xxx...}
kvArr := strings.Split(string(line), ":")
// 检查消息格式
if len(kvArr) != 2 {
continue
}
switch {
case kvArr[0] == "data":
line = line[6:]
if len(line) == 0 {
continue
}
// 结束符
if string(line) == "[DONE]" {
continue
}
default:
continue
}
var result ChatStreamResponse
err = json.Unmarshal(line, &result)
if err != nil {
log.Context(ctx).Error("json unmarshal error", string(line), err)
continue
}
ch <- result
}
}()
通过上述处理,我们在读取消息内容的时候,就是在从channel读取数据,直到channel 关闭,就可以拿到全部的消息了。
这里我们遇到的问题是:SSE 响应的每条消息都是一个 token,所以想要针对相应的结果使用风控,不可能针对每个字去做风控,必须要等待所有消息接收完之后,把消息拼接成完整的响应字符串才能调用风控处理文本,这样流式输出就退化成了普通响应。
这里我们最终的方案是:先对用户问题进行风控,再选用国产经过备案的模型进行生成,然后把结果返回给前端进行输出,等到输出完之后,再对结果进行风控。如果发现有问题,马上标记撤回这条消息,缺点是用户在页面上可能会看到违规内容,这个方案也算是一种妥协吧,针对这个问题,大家可以一起交流,讨论一下更好的方案。
小结
这节课我带你了解了一下极客时间小助手从需求设计到技术实现的全过程。
在设计需求的时候,要根据功能需求和成本(模型成本和研发成本)去选择对应的技术栈。在实现阶段,基于知识资料的实际情况去选择合适的分割策略,设计应用服务的时候,最好把模型相关的外部依赖包装一下,这样可以拥有更好的容错性。
任何系统都是迭代的系统,我们也在不断成长中,如果你有自己的见解和补充,欢迎你在评论区发出来,我们一起讨论学习。
- geek_arong2048 👍(2) 💬(1)
对于流式输出,是不是可以不直接每个流都立即给前端,而是中间通过一层buffer缓存一次,当缓存到完整的句子时进行风控,无问题将buffer给到前端
2024-09-18 - 听水的湖 👍(1) 💬(2)
很精彩的文章,把需求到实现的完整过程给串起来了。 我想请教一个问题:了解了一下发现,从协议层来看:websocket跟http,是同一层次的两种协议,都是跑在tcp上面;而SSE是放在了html标准里面的一个更新。为什么会在选型方案里用Websocet和SSE做对比呢?2.
2024-09-13 - 旅梦开发团 👍(0) 💬(1)
讲的很好, 但为何不细化一些, 把代码给出来?
2024-10-06 - 大魔王汪汪 👍(0) 💬(1)
带有占位符和参数的prompt怎么设计的?
2024-09-18 - nick 👍(0) 💬(0)
针对银行内部使用的场景构建助手的话,有什么建议,请详细分析下,谢谢。
2024-12-25