01 数据处理:把企业知识组织起来
本门课程为精品小课,不标配音频
万丈高楼平地起,想要做好企业大模型应用,数据就是地基。
你好,我是王吕,今天我们正式开始第一讲的学习。大模型想要变成生产力,目前还有两个制约因素,第一个是交互过程中的长文本,第二个是内容的实时更新,RAG 就是为解决这两个问题诞生的。
在传统的应用开发中,我们写程序是把数据一条一条存进数据库中,这可能是关系型数据库,也可能是非关系型数据库,数据库保留了应用的全部记忆。而在 AI 时代,向量数据库(Vector Database)充当了这一角色,在 RAG 系统中,数据通常被转换为高维向量形式,使得语言模型能够进行高效的语义相似度计算和检索。在向量数据库中,查找变成了计算每条记录的向量近似度,然后按照分值倒序返回结果。RAG 就是如何存取向量的方法论,根据不同的实现策略,还衍生出了不同的 RAG 技术,比如利用图结构表示和检索知识的 GraphRAG,结合知识图谱增强生成能力的KGA2G(Knowledge Graph Augmented Generation)等等。
尽管AI应用的数据建模与传统应用有相似之处,但它更强调数据的语义表示和关联性,以支持更灵活的查询和推理。因此,高质量的数据处理不仅影响检索的准确性,还直接决定了语言模型生成内容的质量和可靠性。这正是我们将数据处理作为整个课程首要内容的原因。
接下来,我分享一下极客时间组织数据的一些方法和经验,我们一起学习。
分析业务需求,找到业务需要的数据,确定数据流向
以极客时间小助手的对话场景为例,在对话过程中,小助手会根据用户问题找到对应文章相关的段落,再根据段落文章内容给出回答,同时找到相关的专栏推荐给用户。根据这个需求场景,我们能梳理出来整个过程使用了三种数据。
- 文章数据:这部分数据需要根据用户问题进行向量检索,所以这部分数据是需要向量化的。
- 课程数据:这里其实就可以有多种处理方案,一是由于第一个步骤我们拿到了文章数据,可以根据引用的文章找到所属的课程,得到课程数据;二是可以把用户的提问和最终答案组合到一起,对课程进行向量检索,找到跟问题最相关的课程。这两种方式都可以,根据业务选择即可,这里我们使用第二个方案举例。
- 对话数据:我们需要知道用户之前的对话上下文,所以提供给 LLM 的数据中也要包含历史对话。
找到了需求所需的数据之后,我们就可以确定如何存取这些数据的流程。
- 针对文章和专栏数据,最终的数据源一定是来自极客时间的数据库,并且这部分数据还要进行向量化,使用的过程都是通过向量进行检索。
- 针对对话数据,目前最简单的方案是读取对话列表的前 N(极客时间默认取 3 条)条记录,和文章数据一起组成上下文,不需要向量化,直接用传统数据库就能搞定。在后续章节中,我会介绍一些更好的方案。
经过上述分析,文章数据和专栏数据是需要进行建模和向量化,做进一步处理的。
统一不同数据源的数据,选型 LLM 和向量数据库
上边的数据需求有点简单,实际应用中,可能你的数据会来自数据库,也可能是钉钉文档,或者是 WPS 文档,甚至可能是一堆 PPT 或者音视频。
这里,我们的思路是:先把所有内容转成文本(毕竟我们只是使用“大语言模型”)+ 额外数据(用来关联数据)的方式,然后我们选择一个 Embedding 模型,把文本转成向量,配合关联数据存储到向量数据库中。
关于常见的 Embedding 模型,我整理了如下列表,作为参考。
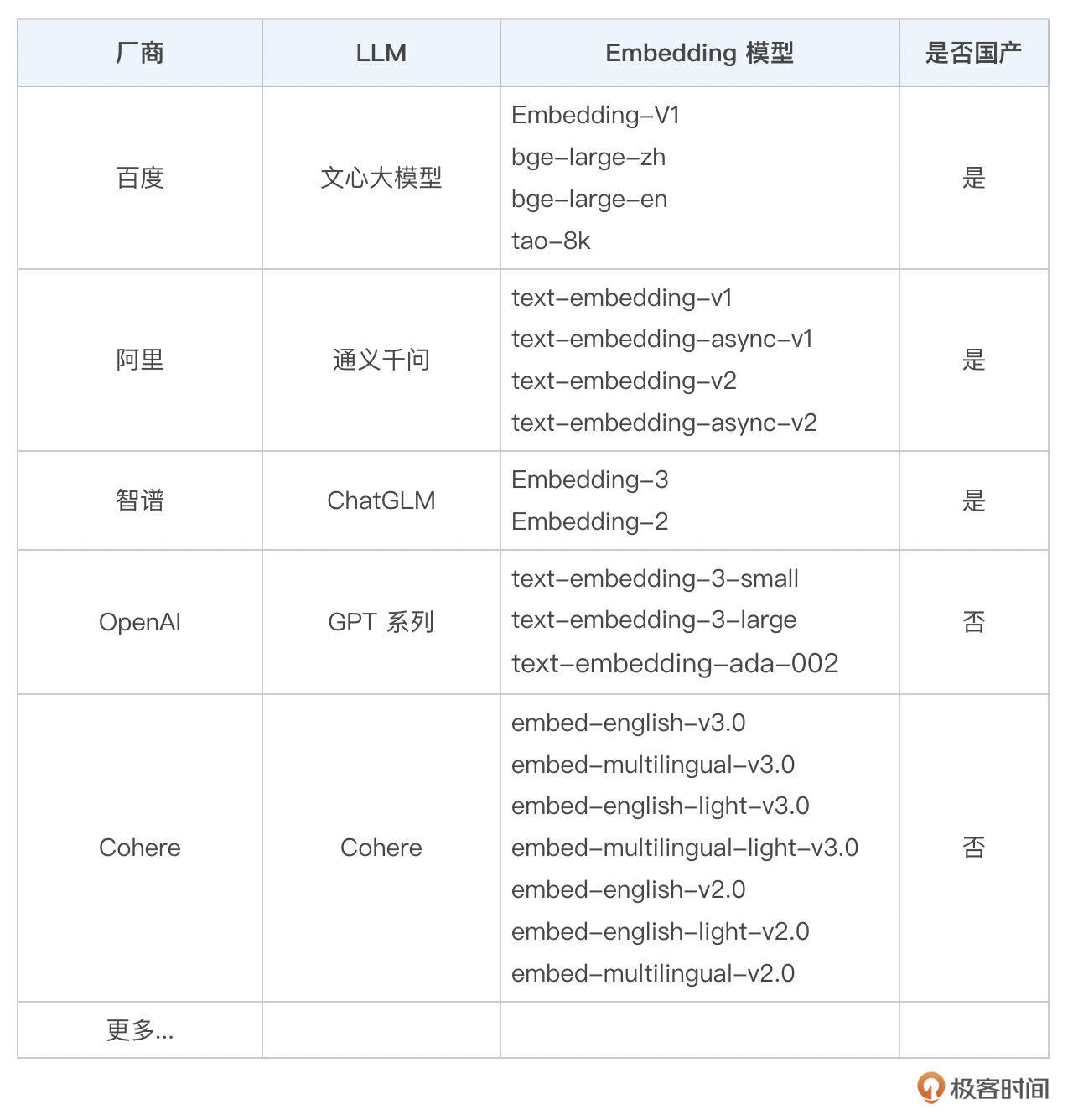
之后我们来选择向量数据库,我把常见的向量数据库及其特性也整理了一下,供你参考。
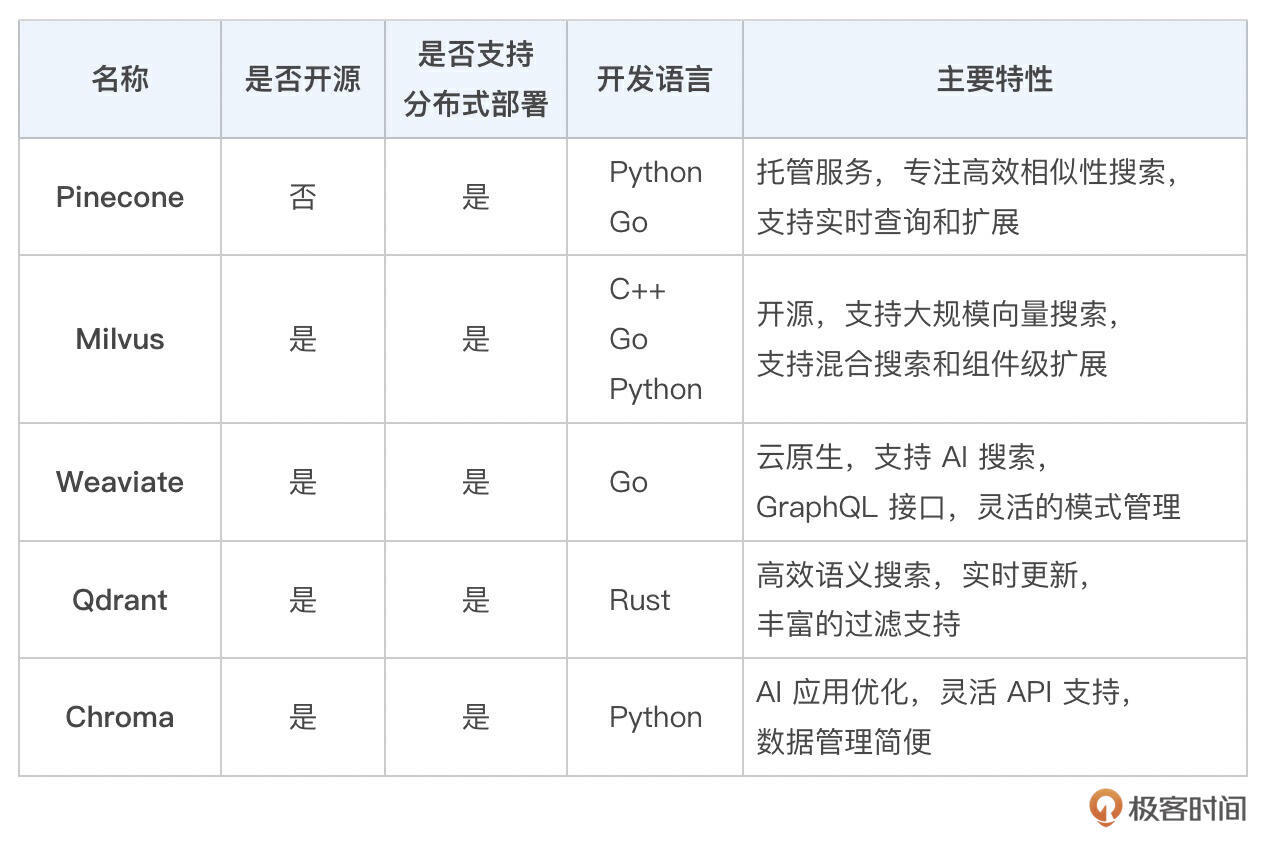
目前极客时间使用的向量数据库是 Qdrant,性能强,使用简单,上手容易,本地开发搭建方便,SDK 也很完整。
数据建模,实现数据使用流程
接下来,我会使用 Qdrant 作为案例。不过在开始建模之前,我先简单讲解一下 Qdrant 的数据结构。
Tips:每个向量都需要提前设置维度,向量表现在计算机上就是一个 float 数组,维度就是数组长度。
Qdrant 的 collection 对应了数据库的表,Point 对应了一条记录,Point 由 3 部分组成:唯一 ID、向量和 Payload 数据。
// 项目地址: https://github.com/qdrant/qdrant
// 源码位置: lib/collection/src/operations/point_ops.rs
pub struct PointStruct {
/// Point id 每条记录的唯一 ID
pub id: PointIdType,
/// Vectors 存储的向量,向量维度(数组长度)是创建 collection 的时候确定的
#[serde(alias = "vectors")]
#[validate]
pub vector: VectorStruct,
/// Payload values (optional) 记录携带的数据,理论上可以带任意值
pub payload: Option<Payload>,
}
Qdrant 的简单使用,可以参考这篇文章。
整个数据处理流程如下图:
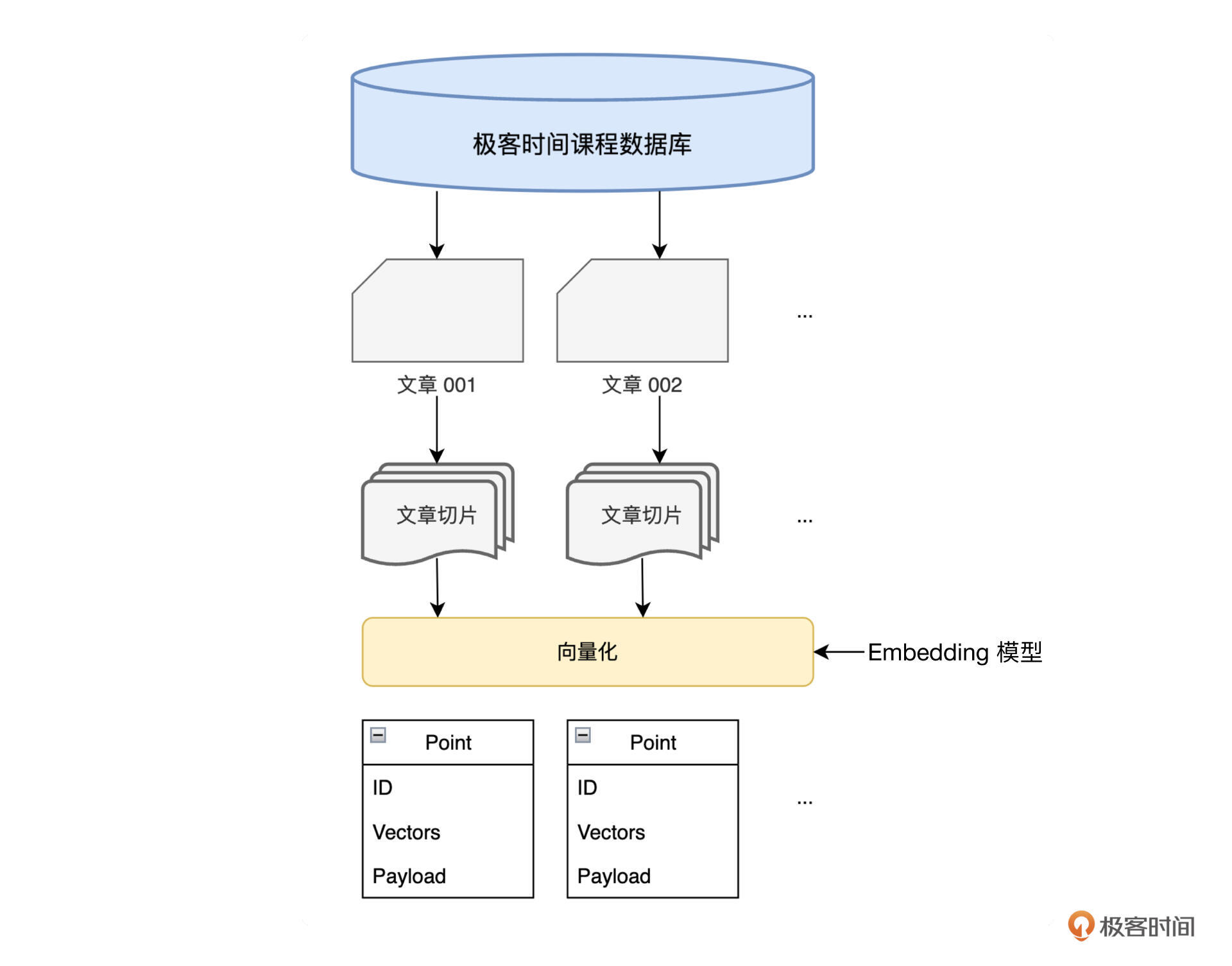
下面我们开始设计“文章/课程”数据模型,这里有几点经验可以分享一下。
- 由于向量数据库还在高速发展阶段,很多东西可能会有变化,如果选定数据库之后,可以多关注官网的更新日志,留意一些特性和 Bug 修复,万一我们也碰到了这个 Bug 呢?
- 往向量数据库写数据的时候,是把文本先转成向量,再带上对应的数据写入,向量没办法手动修改。如果在测试阶段,不要全量写入,这样会带来大量的 Embedding 费用。如果文本切片规则变动的话,也会涉及到全量的 collection 更新,这样基本上就是新建一个 collection 了,成本也很高,需要关注一下。
- collection 的向量维度是要跟 Embedding 模型保持一致的,不同的 Embedding 模型生成的限量维度可能不一样,需要注意一下,写入同一个 collection 和读取的 Embedding 应该是同一个。
- 我们可以自定义的地方就是 payload,但是尽量不要在 payload 中存储长文本,只放一些 关键的 ID 数据,把确定性的信息还是用传统数据库保存,两种数据库配合使用。
- 线上环境使用 Qdrant 执行分布式部署的时候,需要注意一下
write_consistency_factor这个参数,这个参数用来设置副本数量,类似 Kafka 的副本,需要在一致性和性能上找一个平衡。 - 通常为了设计的通用性,在大模型应用中,把传进来的长文,可能是文章,也可能是课程介绍,统一抽象叫做“文档(document)”,文档拆分之后的每个小块叫做“节点(node)”,也就是切片。
综上,文章数据的 payload 就可以设计成:
同时,还要使用传统数据库(如 MySQL)保存一些文档的属性。
- 文档记录表:主要保存文档的相关属性。
document_id 文档 ID
node_count 拆分的节点数量
algorithm 拆分的算法类型,可以是固定长度,还可以是按照 \n 换行... 下节详细讲这里
source_type 文档来源
source_id 原文档对应的 ID
content 可以保存一份文档副本,用来追溯排查问题
- 节点记录表:保存每个切片的属性。
document_id 文档 ID
node_id 切片 ID
node_order 切片的顺序 (可选记录),方便做一些复杂的功能
text 切片内容
... 也可以增加一些其他额外数据,记录这个切片的信息,根据业务情况
有了以上数据模型之后,任意的文档过来,经过上述处理流程保存到 Qdrant 中,都可以被关联查询。
保持数据更新和质量监控
做好数据更新,维护好数据
构建好上述数据处理流程之后,还需要把整个过程做成接口或者脚本可以触发的应用,这样后续有新文章更新的时候,自动触发更新数据流程。
监控数据质量,剔除无效/低效内容
等到应用运行之后,我们还要定期关注数据质量。比如,切片是否切出了无效切片,类似“好的”、“Java” 这些切片文字很少,而且单词含义很广、很常见,这种切片在查询向量数据库的时候,可能会得到一个很高的评分,最终污染上下文。我们要在文档切片的时候,增加一些数据清洗的步骤,尽量过滤掉这些情况,当然这就跟业务相关了,需要持续观察,制定对应的清洗策略。
小结
开发大模型应用,首先要做好数据基础。
在需求分析阶段,我们按照「查找依赖数据 -> 分析哪些需要向量化 -> 归类数据处理流程」的步骤,提炼出我们要维护和使用的数据流程。
之后在实施阶段,我们首先要统一不同来源的数据。然后确定一个向量数据库,标准是满足性能需求和之前的数据需求。接下来就开始数据建模,这里的数据建模是需要反复尝试的,可能要尝试多种切片算法,一遍一遍地做,直到得到效果符合要求的策略,这里是非常考验耐心的,有时候一个切片长度就需要调好长时间,不过既然准备涉足新领域了,我相信你也做好了准备!
当然最终还要建立一套机制,用来维护数据和监控数据的质量。上线之后,也要持续观察,甚至那时才会发现文档切片的问题,不过没关系,持续优化它!
以上是极客时间在处理数据的一些经验和心得,你还有哪些技巧?欢迎在评论区分享讨论!
- Mttao 👍(3) 💬(1)
你好,Embedding 模型怎么选型?
2024-09-07 - 星期三。 👍(2) 💬(1)
单篇文章内容发生了变动,这时候对应的embedding要重建吗?
2024-09-18 - tsukiyo 👍(1) 💬(1)
怎么不用milvus,还是go写的。是考虑rust性能高吗
2024-09-07 - HXL 👍(0) 💬(1)
文档切片如何做呢?如何保证不会对语义有影响呢?
2024-09-26 - geek_arong2048 👍(0) 💬(1)
对长文本存储前的分割以及检索时对输入的分割,可以有一些更详细的介绍吗
2024-09-18 - 大魔王汪汪 👍(0) 💬(1)
长文本切片有哪些方法论或技巧吗?以提高向量检索的相似度质量
2024-09-18 - 夏云 👍(0) 💬(1)
请问在应用向量库的过程中,数据量如果很大,怎么做水平扩展?
2024-09-05 - 贵州 IT民工 👍(0) 💬(0)
“先把所有内容转成文本(毕竟我们只是使用“大语言模型”)+ 额外数据(用来关联数据)的方式,然后我们选择一个 Embedding 模型,把文本转成向量,配合关联数据存储到向量数据库中。” 老师,请问下这个额外数据怎么理解,可以举例说明下吗
2025-02-19