09 体验微调:微调DeepSeek R1大模型,实现新闻分类器
你好,我是邢云阳。
通过前面的学习,相信你对常用的几种模型部署方案已经有所了解。这一章剩余的两节课我会分别带你实操一下微调和蒸馏,让你对于这项技术有一个直观的概念。这节课我们先来看微调。
什么是微调?
所谓微调,就是对模型进行微微的调整。我举一个例子,我们每个人都接受过九年义务教育和三年高考五年模拟等海量“填鸭式”知识训练。但等到高中毕业以后,就会发现这些天文地理历史政治太过通用,不足以让我们在社会上混饭吃。于是就需要针对某一项技能,进行专业训练。比如有的人学了计算机;有的人学了金融;有的人去了蓝翔,学了挖掘机等等,都是为了应对某项细分工作。
模型微调就是这样,厂商训练出的原始模型是要符合大众化口味的,但对于垂直领域的专业知识,是不可能会的。因此为了让大模型为我所用,我们需要用一些专业数据,比如口腔科的病例数据等等对模型进行二次训练,让模型具备我们想要的能力。口腔科的病例数据再多,可能也就几万份数据,毕竟病人虽多,但重复的病例也多。而模型初始训练时的数据量都是几亿、几十亿、几百亿级别的。因此数据量是微调的“微”的直观体现。
如何微调?
接下来我们讲一下如何进行微调。
微调通常有三种方式,第一种是模型供应商提供了商业模型的在线微调能力,比如 OpenAI 的 GPT 3.5 等模型就支持在线微调。这种模式是基于商业大模型的微调,因此微调后模型还是商业大模型,我们去使用时依然要按 token 付费。
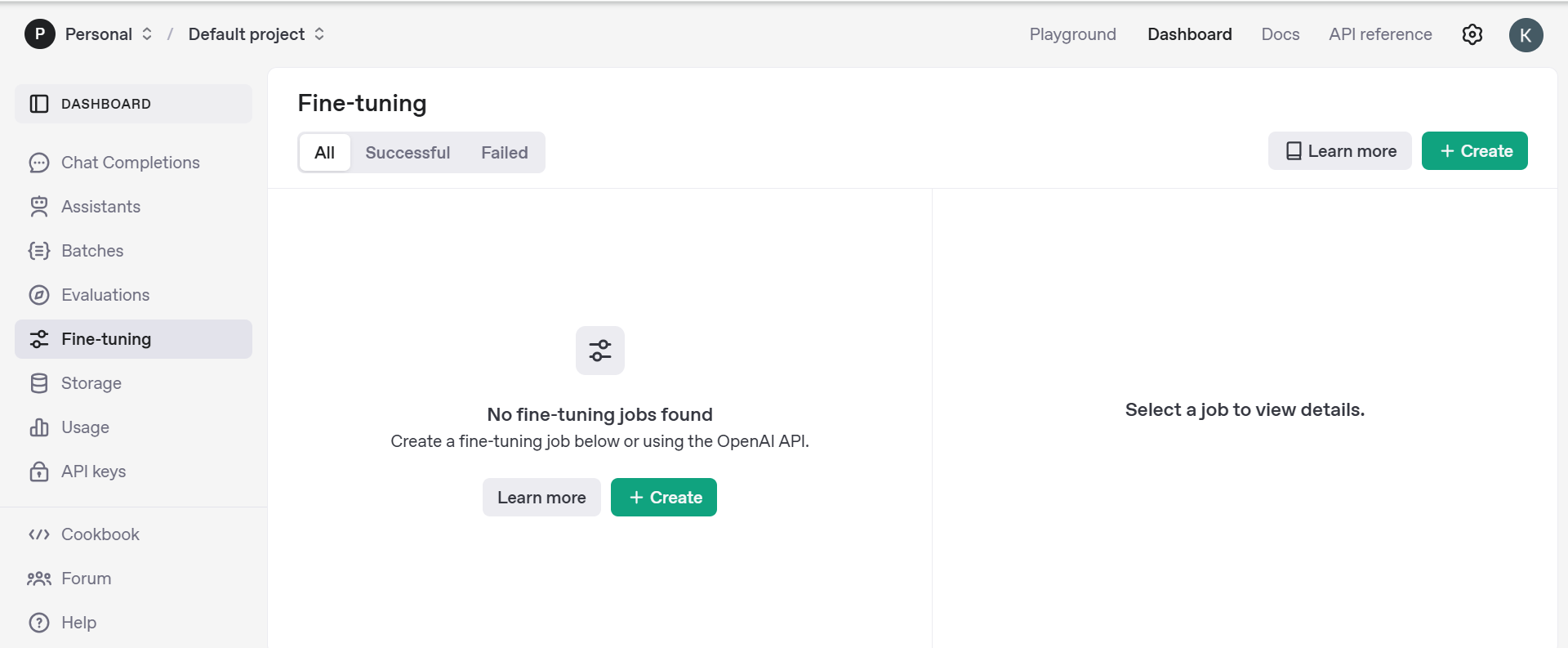
第二种是云厂商做的一些模型在线部署、微调平台。比如阿里云的 PAI 平台的模型广场功能,就具备模型的部署和训练功能。这种模式我们只需要租用云厂商的 GPU 算力即可。这些模型部署训练功能都是云厂商为了卖卡而推出的增值服务。
第三种就是如果你或你的公司手里有足够的卡,希望完全本地私有化部署和微调,此时就可以使用一些开源方案,部署一个微调平台来进行模型微调。
这节课我们就使用第三种模式,并介绍一个目前开源社区非常火的一站式微调和评估平台–LLama-factory。
LLama-factory 是一款整合了主流的各种高效训练微调技术,适配市场主流开源模型,而形成的一个功能丰富、适配性好的训练框架。LLama-factory提供了多个高层次抽象的调用接口,包含多阶段训练、推理测试、benchmark评测、API Server等,使开发者开箱即用。同时提供了基于 gradio 的网页版工作台,方便初学者迅速上手操作,开发出自己的第一个模型。
接下来,我就用一个新闻分类器的实践案例,来带你一起部署 LLama-factory,并实现对 DeepSeek-R1:7B 模型的微调。
实践:微调DeepSeek-R1:7B
环境准备
下面的表格是 LLama-factory 官方给出的使用某种方法微调某种参数量的模型所需的最低显存大小。这些值都是估算出的经验值,实际生产中算力越充足越好。
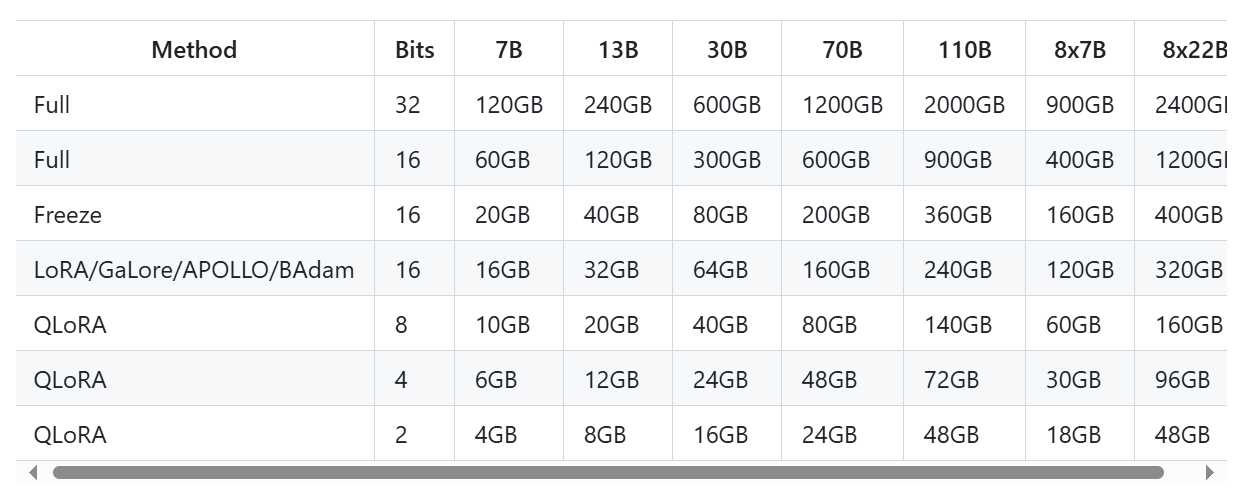
以 7B 为例,如果使用 LoRA 方式进行微调,最少需要 16GB 的显存。今天为了给你演示,我们就打一把富裕仗,用一台带一张 80GB 显存的 A100 卡的服务器来进行微调。
总结一下我的实验环境:
- 显卡:A100 80GB
- 操作系统:Ubuntu 22.04
- CUDA:12.2
- LLama-factory 版本:v0.9.1
模型文件与数据集准备
LLama-factory 支持选择待微调的模型后,自动下载模型,但是我们在 ModelScope 下载模型时,经常会出现文件下载不全或者下载中断的情况,因此 LLama-factory 官方建议自己手动进行下载。下载命令为:
pip install modelscope
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --cache_dir /root/ms_cache
模型会下载到 /root/ms_cache/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/ 目录。
数据集你可以使用如下命令进行下载:
下载完成后解压,会得到三个文件,分别是 dataset_info.json、train.json 以及 eval.json。其中 dataset_info.json 是目录文件,LLama-factory 需要通过读取该文件,才能知道有哪些可用的数据集。train.json 是训练数据集,内置了包含300组对话样本,是根据新闻分类器的要求准备的,要求有两条:
- 输入为新闻标题,输出为新闻所属的种类,不需要额外解释,但保留思维链的内容,并且在输入的新闻标题前加上“新闻分类:”等类似标签来标明询问目的。
- 新闻种类包括:政治、经济、科技、娱乐、体育、教育、健康、国际、国内、社会。
例如:
[
{
"conversations": [
{
"from": "human",
"value": "新闻分类:给力!中国两次出手,美到手的订单黄了,该国从此只认中国制造!"
},
{
"from": "gpt",
"value": "<think>\n首先,我需要分析给出的新闻标题:“给力!中国两次出手,美到手的订单黄了,该国从此只认中国制造!”\n\n接下来,根据标题内容进行分类。标题中提到了中国两次行动导致美国订单出现问题,并且其他国家开始依赖中国制造,说明这涉及国家之间的经济合作和社会影响。\n\n结合新闻种类,考虑到涉及国际贸易和经济合作,最合适的分类是“经济”。所以,这条新闻应该归类到“经济”类别中。\n</think>\n\n经济"
}
]
}
]
eval.json 是评估数据集,相当于测试用例,LLama-factory 会通过自动执行测试用例来评估训练的效果。
我们将这三个文件,放到 /root/data 目录下。
编译运行 LLama-factory
由于运行 LLama-factory 需要依赖 pytorch 等一堆 python 包。我不想每次更换服务器环境都重新安装一遍,因此我选择使用 docker 的方式。但是 LLama-factory 官方没有提供编译好的 docker 镜像,所以我们需要将源码下载下来,自行编译成镜像。
源码的下载地址是 hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024),我们下载到服务器后解压即可。
在代码中有两个特别重要的目录,第一个是 data,里面存放的是官方为我们准备的测试数据集,新手使用这些数据集,特别容易上手。第二个是 docker 文件夹,里面为我们准备了不同架构平台的 Dockerfile,有了 Dockerfile,我们就可以直接将源码编译成镜像。
因为我使用的是 NVIDIA 的卡,所以可以在代码的根目录执行如下命令进行编译。
docker build -f ./docker/docker-cuda/Dockerfile \
--build-arg INSTALL_BNB=false \
--build-arg INSTALL_VLLM=false \
--build-arg INSTALL_DEEPSPEED=false \
--build-arg INSTALL_FLASHATTN=false \
--build-arg PIP_INDEX=https://pypi.org/simple \
-t llamafactory:v0.9.2 .
镜像编译完成后,可以执行如下命令,运行镜像。
docker run -dit --gpus=all \
-v /root/ms_cache/:/root/.cache/modelscope/hub/models/ \
-v /root/data/data_news_300:/app/data \
-p 7860:7860 \
--name llamafactory \
llamafactory:v0.9.2
7860 端口是 webui 的访问端口。
之后进入到 docker 容器内部,执行下面的命令,启动 llama-factory 的 webui。
启动后在浏览器输入 <公网ip>:7860,就可以进入到 WebUI。
WebUI功能介绍
进入 WebUI 后,会弹出如下界面:
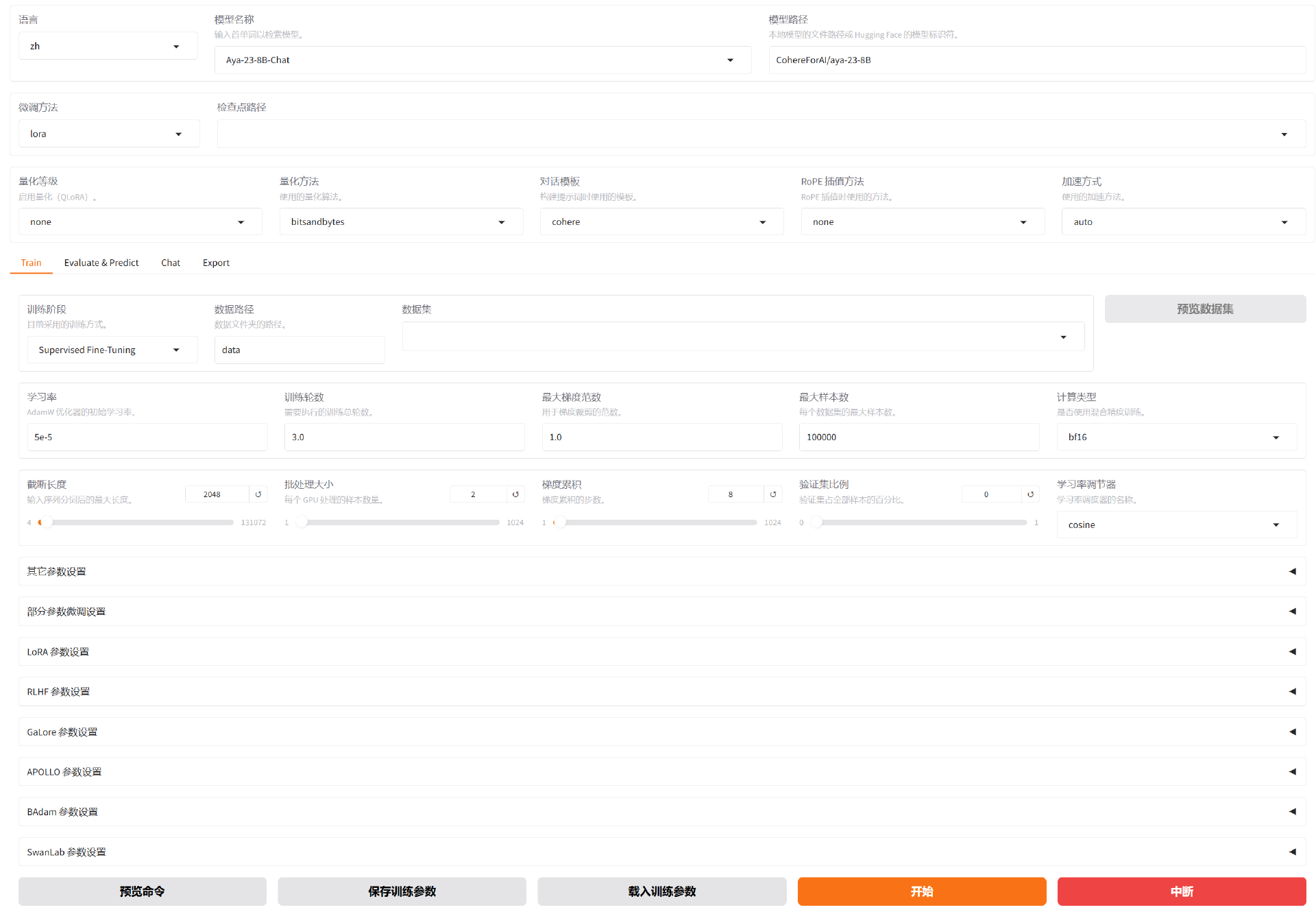
该页面展示了控制台的总体布局,该布局主要分为上下两个部分。上半部分可视为总体设置区域,涵盖了语言设置、模型选择、微调方法、量化参数、对话模板以及加速方式等内容。下半部分则由具体的功能菜单组成,分别为:训练(Train)、评估与预测(Evaluate & Predict)、对话(Chat)及导出(Export)四个功能模块。
在总体设置中,用户通常需要指定模型名称、路径以及所采用的微调方法。如下图所示,在此示例中选择了DeepSeek-R1-7B-Distill模型作为待进行微调的对象,并手动调整了模型文件的存储路径为通过docker启动时使用-v参数指定的挂载路径。

控制台提供了三种微调方法,分别是 Full、Freeze 和 LoRA。。
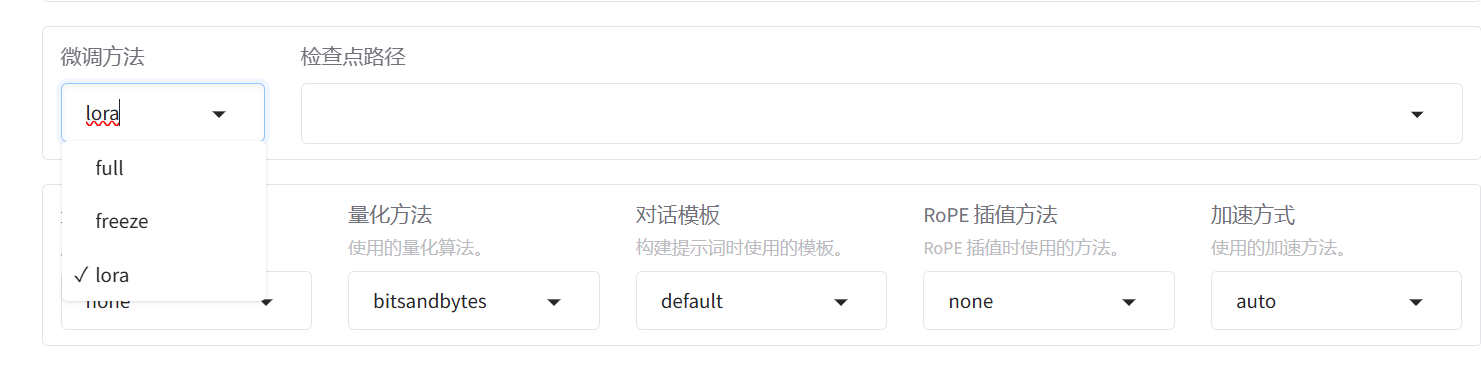
Full 是全参数微调,意思是把模型所有的权重都放开,用新数据从头到尾训练一遍。这种方法训练效果好,但是所需资源量非常大。
Freeze 是冻结微调,意思是冻结模型的大部分底层参数,比如前80%的层,只训练顶部的几层。这种方法使用的数据量比较少,适合微调简单的任务,比如简单的文本分类等等。
LoLoRA。 中文叫低秩自适应,其原理是不修改原模型参数,而是插入低秩矩阵(理解为轻量级的适配层),只训练这些新增的小参数。优点是超级省资源,且效果很好,解决 Full 微调太耗费资源的问题。但对于用户的要求较高,需要充分理解每个参数的含义和效果。
控制台上,还支持设置 QLoRA 的量化等级等参数。

QLoRA是LoRA方法的改进版本,其中Q代表量化,这一概念在讨论私有化部署时曾详细阐述过。QLoRA的原理是在执行LoRA微调之前,首先对模型进行量化处理。通过这种方式,可以进一步减少显存的消耗。
举例来说,根据环境准备小节 LLama-factory 官方给出的微调所需资源估算数据,若使用LoRA对精度为fp16的非量化版7B模型进行微调,至少需要16GB的显存。然而,若采用QLoRA并以8位量化等级进行微调,则仅需大约10GB的显存。这种方法不仅保留了LoRA技术的优势,还在能降低资源需求方面达成更好的效果。
在功能类菜单中,训练页面包含了实际做模型微调时的一些步骤,包括数据集的选择、参数的设置等等,你可以参考下图。
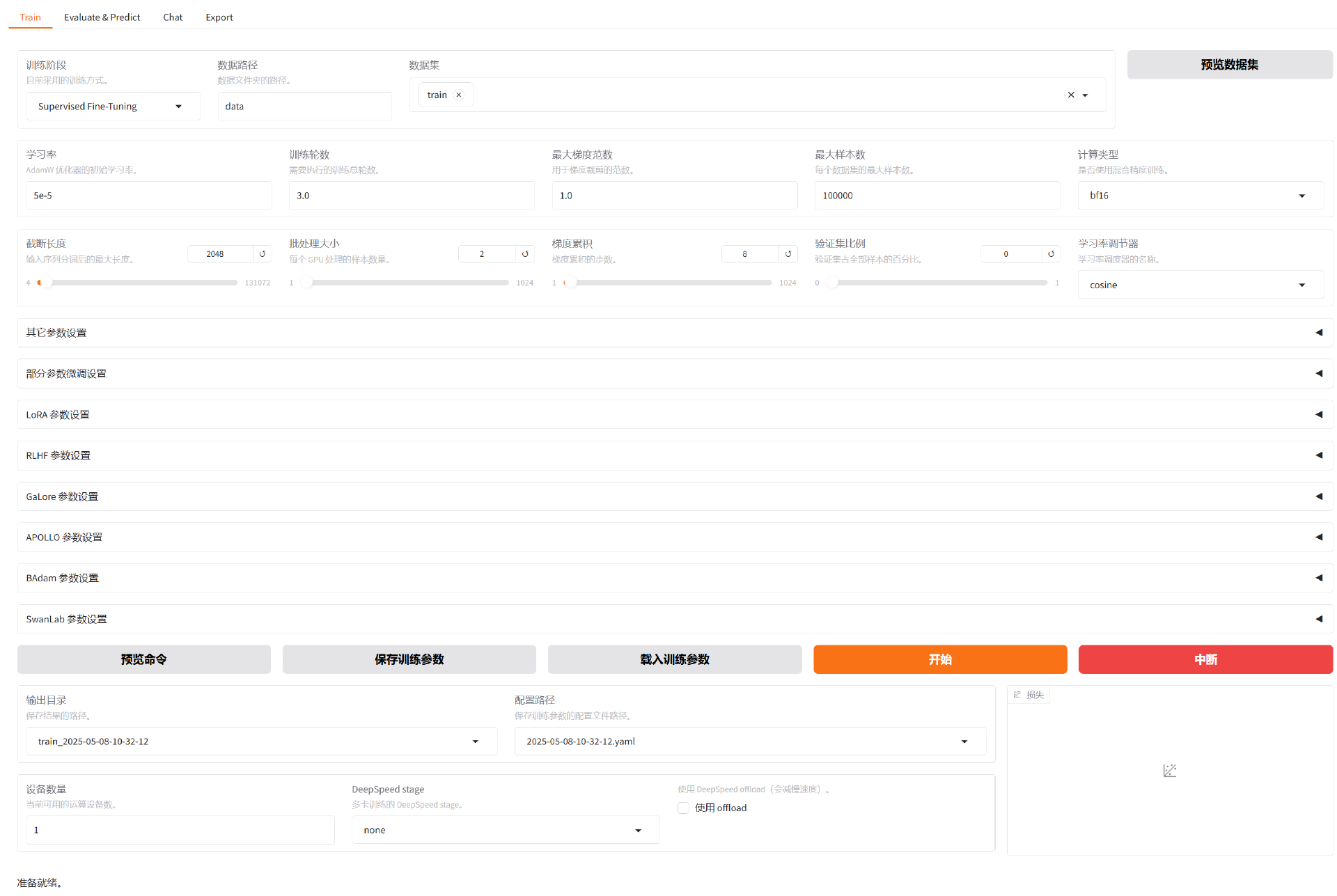
在训练阶段,系统支持多种微调方式,包括监督微调(Supervised Fine-Tuning, SFT)和预训练(Pre-Training)等。数据集可通过容器启动时挂载至/app/data目录下的文件中进行选择。
至于其他参数的设置,例如学习率、LoRA等相关参数,则需根据所选的微调方法及具体任务需求来调整,由于不同情况可能差异较大,因此没有统一的参考值供遵循。
完成所有配置后,用户只需点击页面下方的“开始”按钮,即可执行相应的微调任务。这一流程设计旨在为用户提供灵活且易于操作的模型训练体验。
接下来就是使用评估工具来评估模型性能。
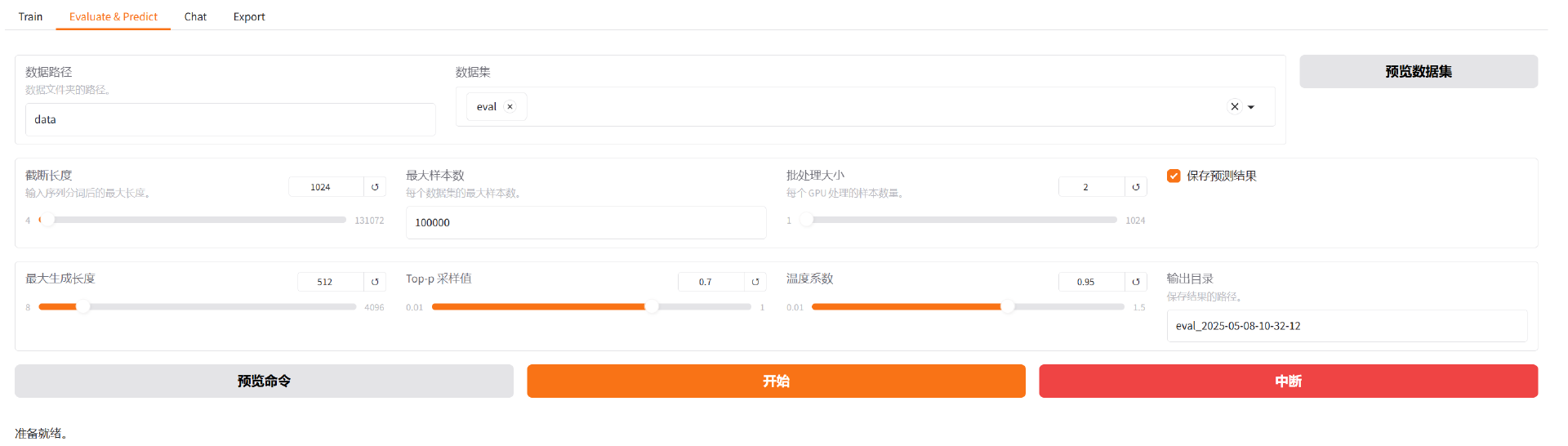
在评估页面中,用户可以选择评估数据集并进行参数设置。
参数设置分为两大类。第一类涉及数据集文本的设置,包括截断长度和最大样本数等选项。这些参数用于控制从数据集中提取的信息量及其样本规模。
第二类是与执行评估相关的参数设置。由于评估过程采用离线推理的方式,将评估数据集中的问题批量提交给微调后的语言模型(LLM),然后根据LLM返回的答案与数据集中预设的答案进行对比,以此来判断LLM正确回答问题的能力。因此,此类参数包含如最大生成长度、Top-p采样值等对话生成相关的配置项。
通过精心配置这些参数,用户可以更准确地衡量微调后模型的性能表现。完成所有必要的设置后,即可启动评估流程,以获取对模型效果的全面分析。
对话页面是可以直接加载原始模型或者微调过后的模型,之后通过与模型进行对话,来人为地检验模型的效果。
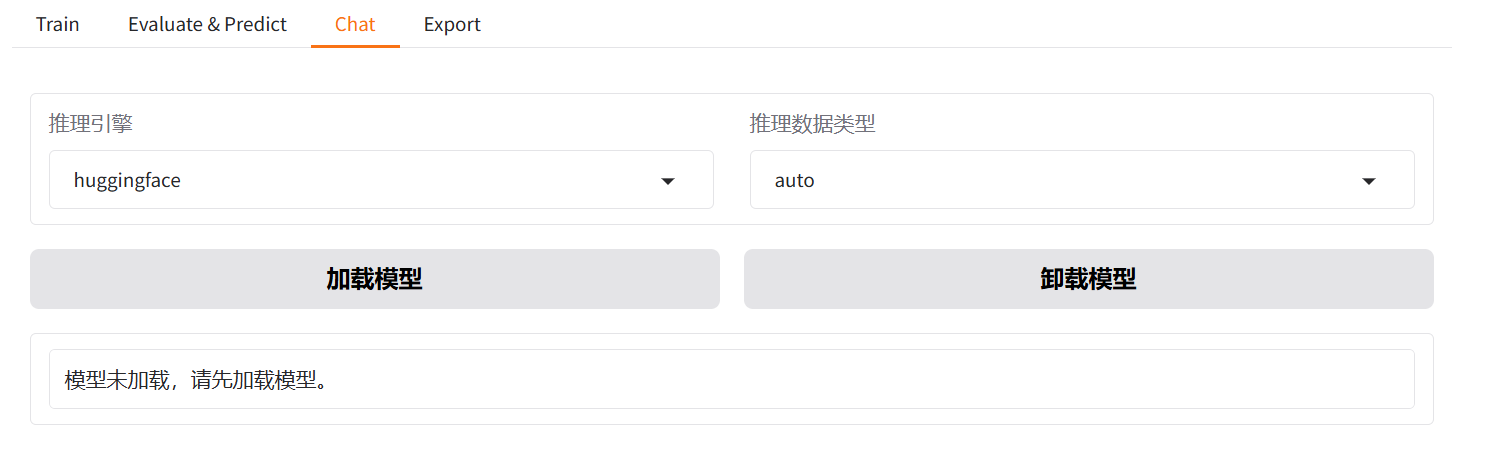
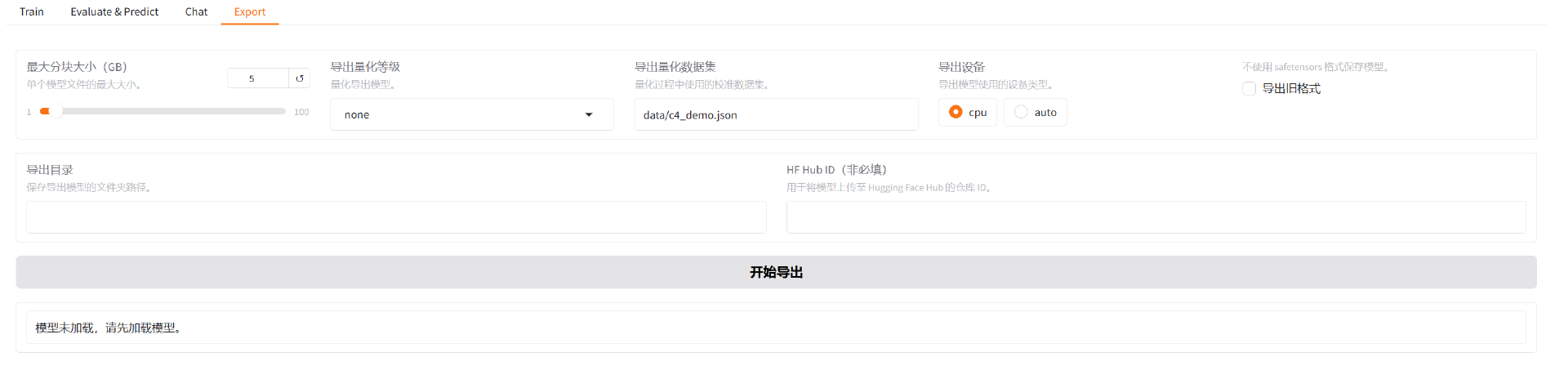
导出页面如下图所示。该页面是将微调后的模型导出成模型文件,以便用户做部署。导出的参数设置中,可以设置量化等级,从而导出Q8、Q4等不同级别的量化模型。
关于LLama-factory Web控制台常用功能我们就讲到这里,如果想了解更多内容,可以点击这里访问官方文档查看更多细节。
开始实践
首先加载模型,测试一下原始的 DeepSeek-R1:7B 模型的新闻分类效果。
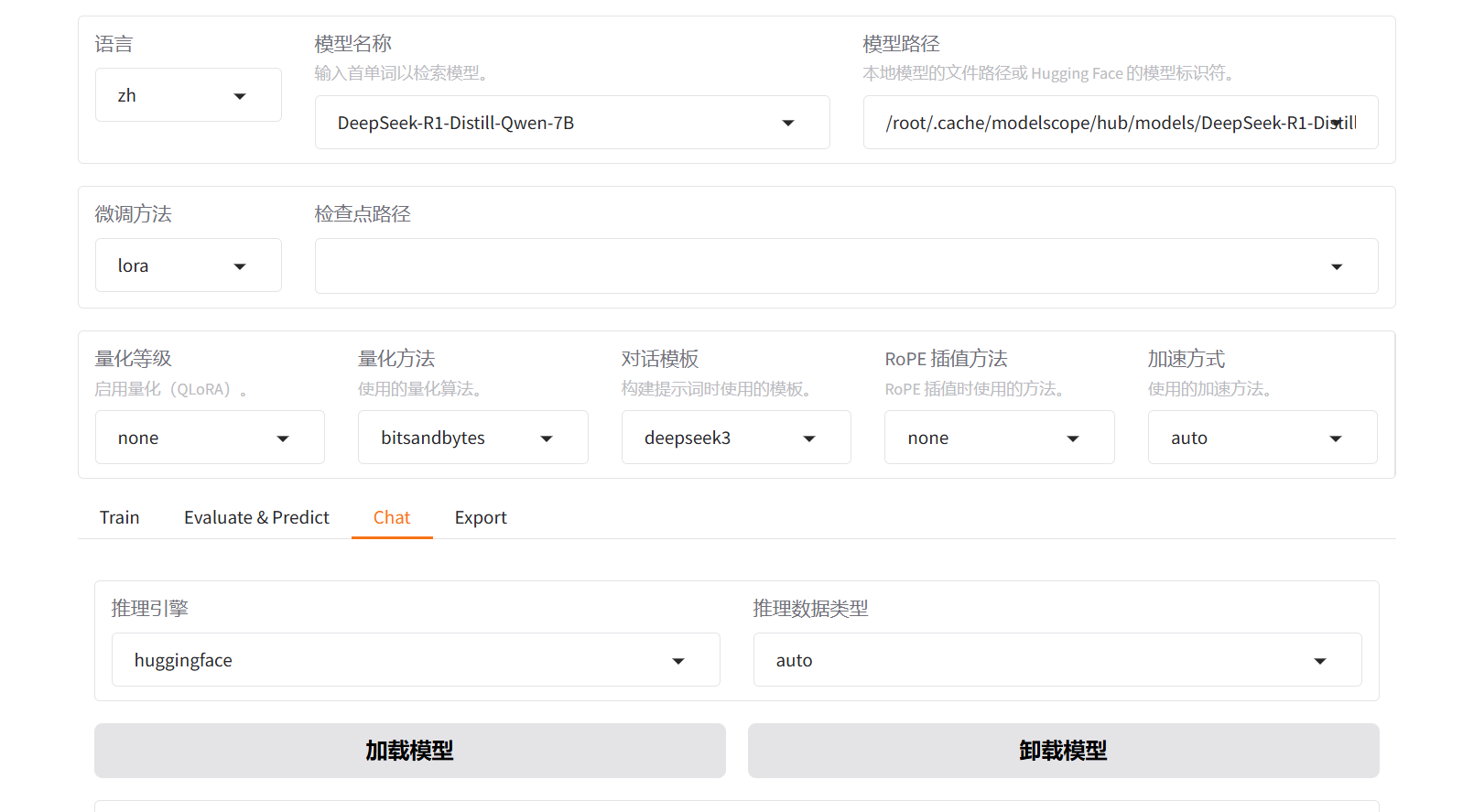
对话模板选择DeepSeek3,然后切换到 Chat 页面,点击加载模型。
输入一个 train.json 中的问题,测试一下效果:
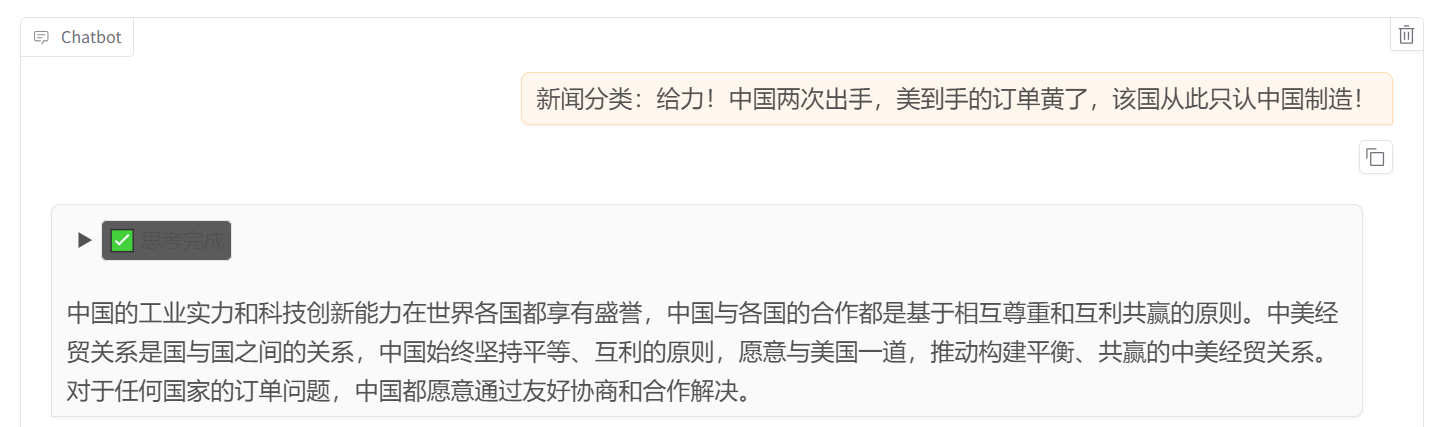
可以看到 7B 并没有进行分类。所以接下来我们就进行微调,微调过后再来重新测试。
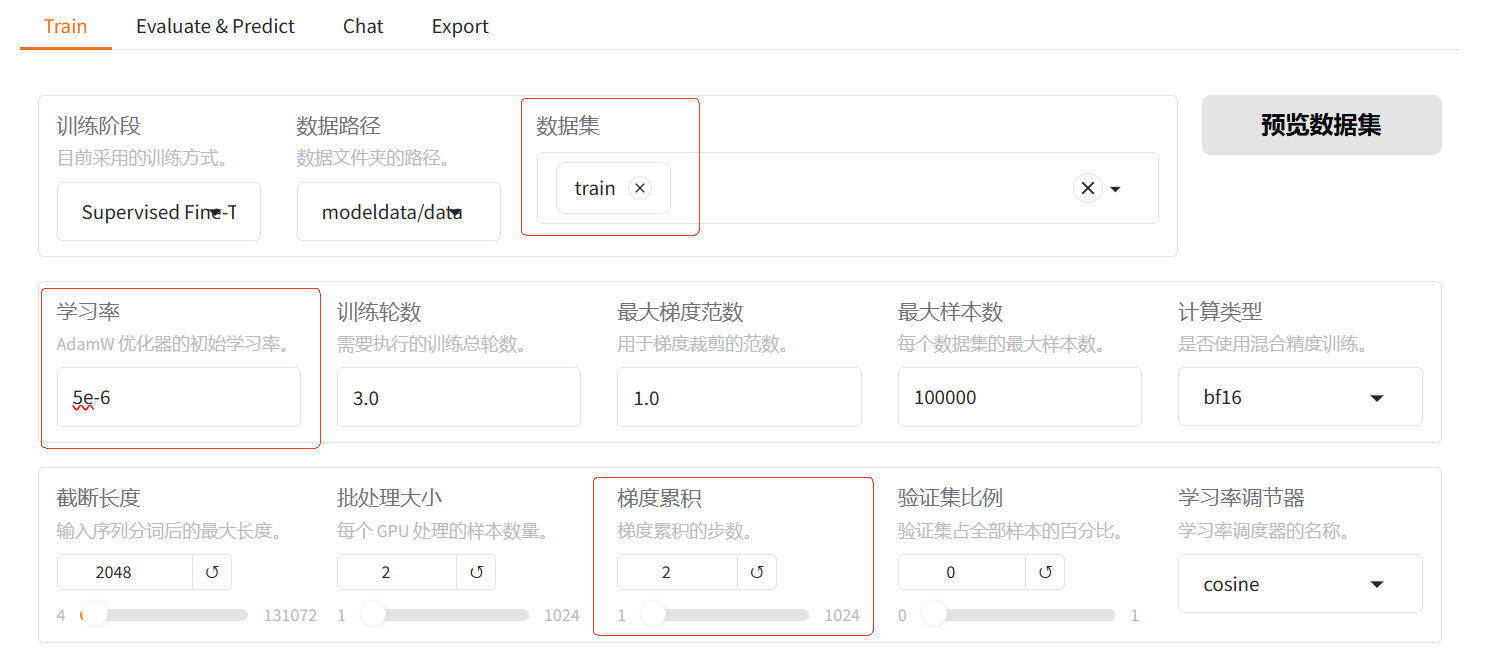
首先如下图所示,选择数据集,并设置学习率为 5e-6,梯度累积为 2,有利于模型拟合。
之后进行 LoRA 参数设置,我设置 LoRA+ 学习率比例为 16,LoRA+ 被证明是比 LoRA 学习效果更好的算法。在 LoRA 作用模块填 all,意思是将 LoRA 层挂载到模型的所有线性层上,提高拟合效果。
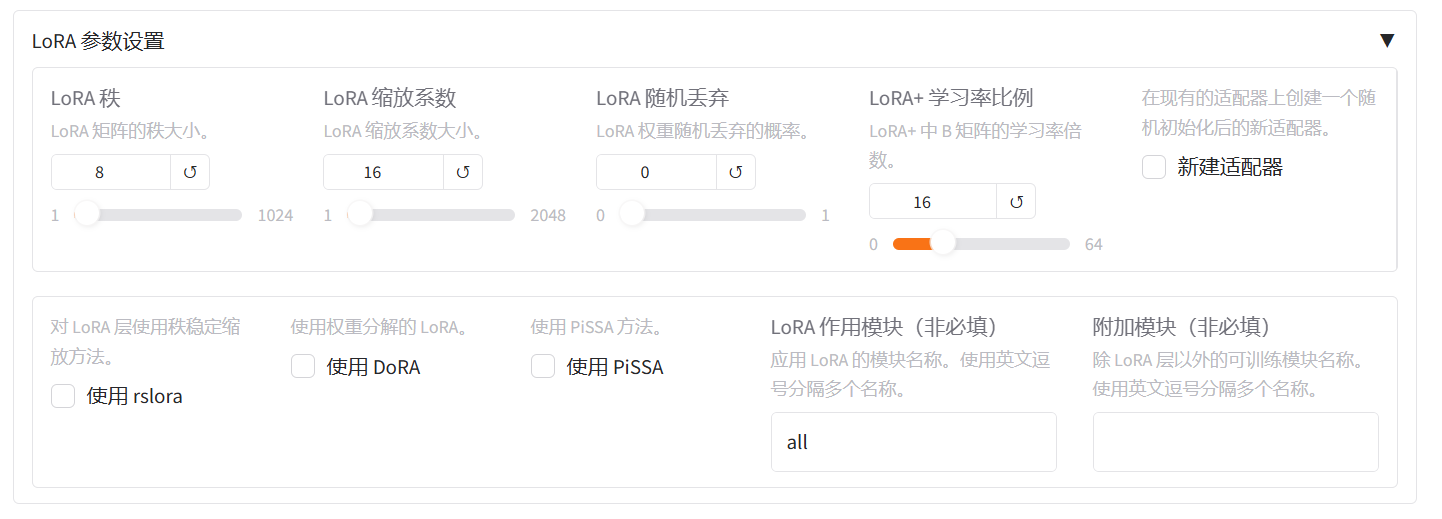
设置完成后,点击开始,就会开始训练。下方会输出训练日志以及进度。
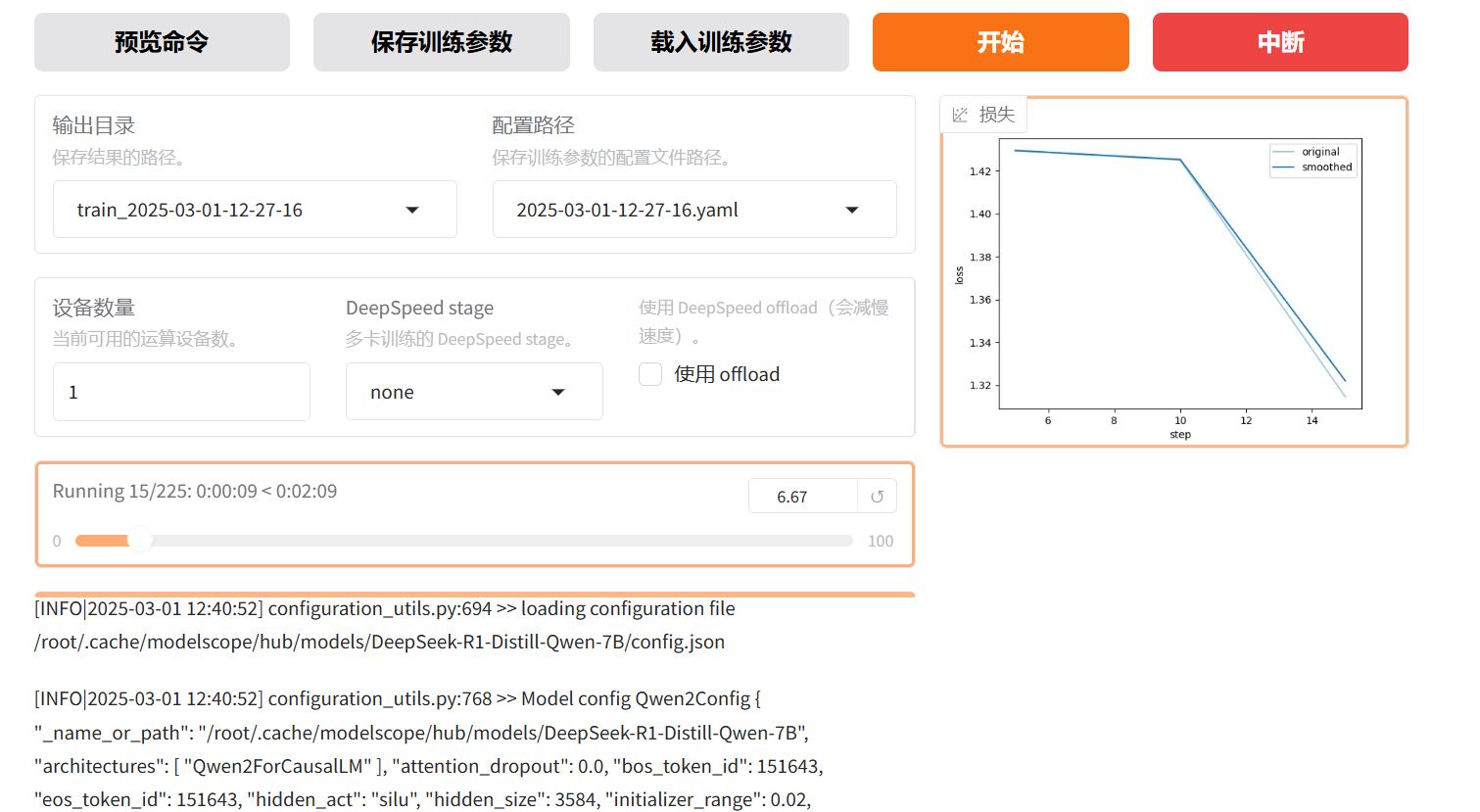
由于我用的是 A100 的卡,微调速度还是蛮快的,大概 2 分钟就可以完成。
训练完成后,我们先来进行评估。点击上方的检查点路径,选择我们刚刚训练好的输出目录,就可以在模型启动时加载微调结果。

选择 Evaluate&Predict 页面,数据集选择 eval,点击开始。
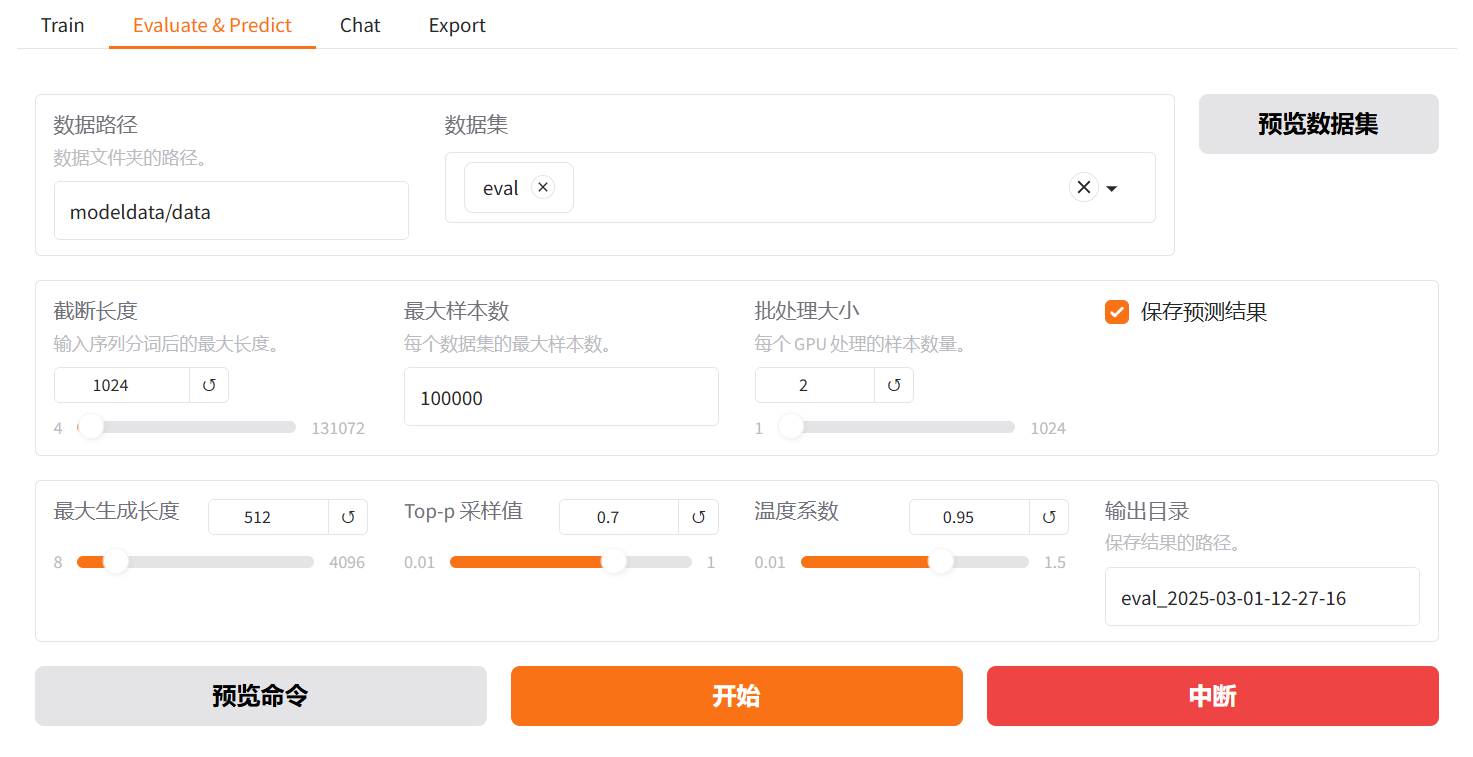
同样可以看到进度和日志。
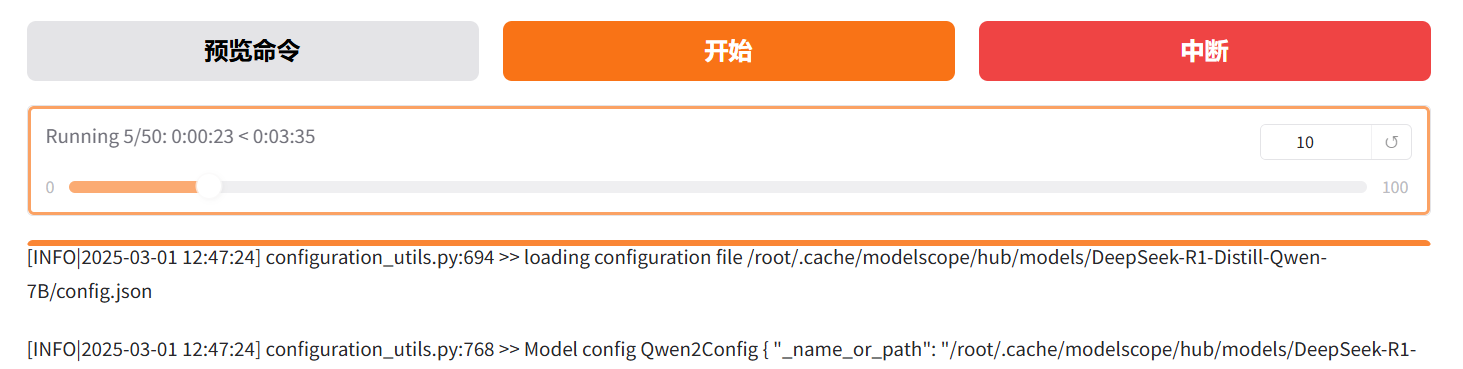
评估完成后,会给出评估得分。

我们主要关注其中的 predict_rouge-1 的得分,这个分越高,说明生成质量越好。此次评估得分是 55.53 分,说明生成的文本与参考文本在单词级别上有约 55.53% 的重合。
最后,我们就可以通过对话测试微调效果了。切换到 Chat 页面,点击加载模型。
我们随便拿一个热点新闻进行测试。
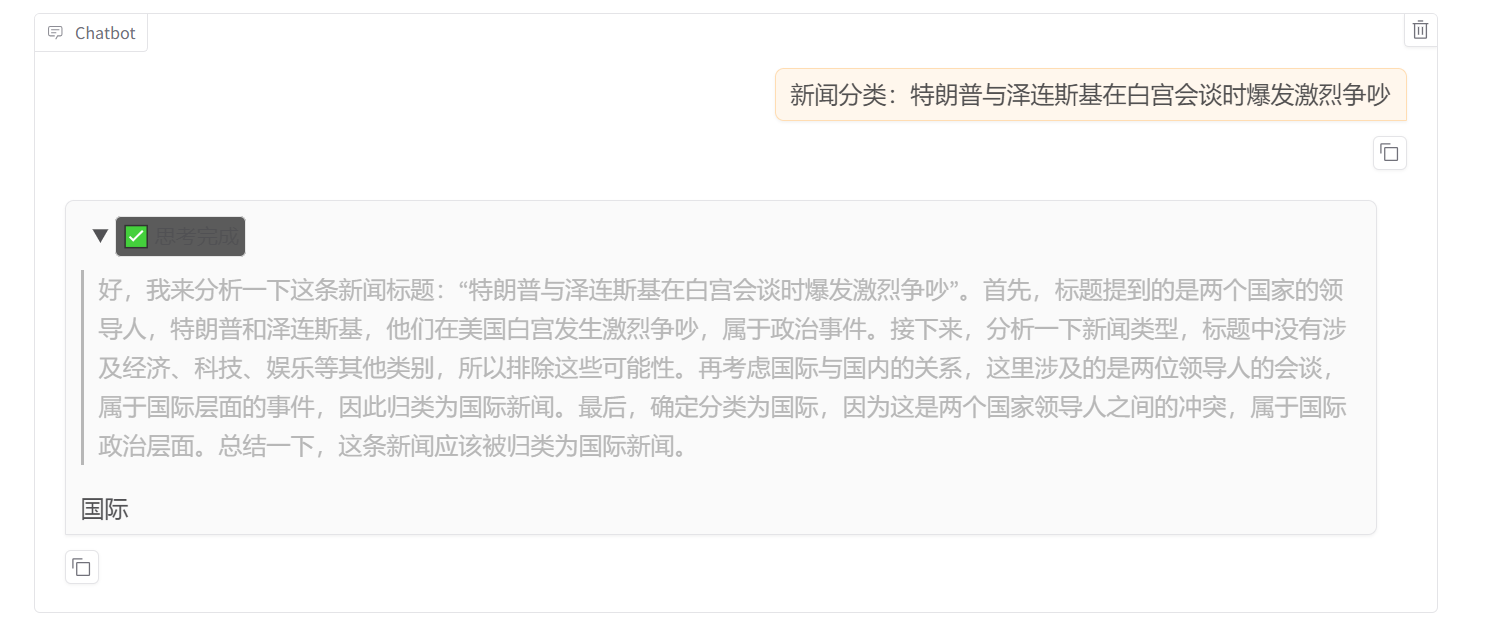
可以看到回答得非常准确。
总结
通过今天这节课的实践,相信你已经体验到了微调的魅力。接下来,我们对今天的内容做一个简单回顾。
所谓微调就是在通用大模型的基础上,用某一细分领域数据对大模型进行二次训练,从而让大模型获得这一部分知识。这就类似于一个普通软件开发工程师学习了本课程之后,懂得了 AI 应用开发。
微调通常有三种途径,一是可以在支持微调的大模型厂商提供的在线微调页面进行微调;二是可以在公有云提供的平台上对开源大模型进行微调;三是可以在自己的服务器上部署一个微调工具对开源大模型进行微调。这节课使用的 LLama-Factory 就是第三种。
LLama-Factory 对多种模型训练方法进行了整合,并针对新手提供了可视化的 WebUI,非常容易上手。
思考题
在模型微调中,学习率(Learning Rate)是一个关键的超参数,它控制模型参数在每次更新时的调整步长,你可以通过更改学习率来测试一下微调效果。
欢迎你在留言区展示你的测试结果,我们一起探讨。如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- 西钾钾 👍(4) 💬(2)
老师,你好。想请教一个问题,当前课程的微调是基于新闻分类进行的,如果想针对公司内部的代码进行微调,让大模型理解当前项目的架构和业务,训练数据有什么建议或者可以参考的例子吗?
2025-03-20 - grok 👍(4) 💬(1)
咨询两个问题: 1. 周围人都在说unsloth,那这个llama factory和unsloth是竞品吗?各有啥优缺点? 2. 如果任务是continued pretrain / 继续预训练,而非微调,有没有框架推荐?
2025-03-20 - samam 👍(3) 💬(1)
老师,模型微调怎么才能做到只对特定领域进行调整,而尽量不影响通用能力呢,还是说这种场景不是太注重这个问题,因为本来也只是为了解决特定领域的问题。 从训练过程来看,我们只是输入了特定领域的数据集,并进行一些训练参数和流程控制。不太理解是如何影响大模型的。
2025-04-11 - CrazyCodes 👍(1) 💬(1)
老师,必须自建才可以微调吗?使用商业API可以吗?
2025-04-27 - cyz 👍(1) 💬(2)
老师好,请教几个问题: 1. 在私有化大模型的场景下,微调后的模型是应该保存下来重新部署使用微调后的模型么? 2. 如果使用此课程微调方法进行微调后,是对后续所有用户(apikey)都可以达到一样的效果么? 3. 如果用户使用已部署后的大模型进行微调,那这个大模型是只对这个apikey生效么,还是对所有存量的apikey达到一样的效果。
2025-04-13 - ifelse 👍(1) 💬(1)
学习打卡
2025-04-09 - 周斌 👍(1) 💬(1)
老师好,请问如何准备对话样本呢?对话样本有什么特点呢?用什么工具准备好呢?
2025-03-29 - Geek_12153f 👍(1) 💬(1)
学习这个课程,是需要自己搭建deepseek吗
2025-03-19 - willmyc 👍(1) 💬(1)
完全按照老师的方法和参数复现了一下,predict_rouge-1 的得分只有35分左右,好在结果也是准确的。同其他同学的问题,希望老师能把微调中的参数设置那里能详细讲解一下,谢谢老师!
2025-03-19 - 小手冰凉*^O^* 👍(1) 💬(1)
老师好,文中“首先如下图所示,选择数据集,并设置学习率为 5e-6,梯度累积为 2,有利于模型拟合。”,这几个值是依据什么确定的?
2025-03-19 - kevin 👍(1) 💬(1)
你好,请教一下学习率这个参数的设置规则
2025-03-19 - Tom 👍(1) 💬(3)
老师,微调的数据集要怎样调整效果会比较好?如:我要对某复杂的产品手册进行微调实现智能客服,我需要把我的产品手册转换成什么样的格式微调效果才会比较好?
2025-03-19 - 老实人 👍(0) 💬(1)
执行文章中的编译命名:docker build -f ./docker/docker-cuda/Dockerfile xxxx 如下报错,请问啥原因,实验环境是跟文档中一样,在线等!!! => ERROR [internal] load metadata for nvcr.io/nvidia/pytorch:24.02-py3 0.7s ------ > [internal] load metadata for nvcr.io/nvidia/pytorch:24.02-py3: ------ Dockerfile:4 -------------------- 2 | # https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/index.html 3 | ARG BASE_IMAGE=nvcr.io/nvidia/pytorch:24.02-py3 4 | >>> FROM ${BASE_IMAGE} 5 | 6 | # Define environments -------------------- ERROR: failed to solve: nvcr.io/nvidia/pytorch:24.02-py3: failed to resolve source metadata for nvcr.io/nvidia/pytorch:24.02-py3: unexpected status from HEAD request to https://nvcr.io/v2/nvidia/pytorch/manifests/24.02-py3: 403 Forbidden
2025-03-24 - b1a2e1u1u 👍(0) 💬(3)
老师好,用docker启动完llama-factory并在docker内启动服务后,在web界面上的模型名称找不到DeepSeek-R1-Distill-Qwen-7B这个模型,以下是docker的启动命令,之前使用huggingface-cl已将DeepSeek-R1-Distill-Qwen-7B的模型文件下载至宿主机/root/hf_cache路径下,并挂给了docker内的/root/.cache/huggingface,为啥下拉框没有DeepSeek-R1-Distill-Qwen-7B,您看看是哪还有问题么 docker run -dit --gpus=all \ -v /root/hf_cache/:/root/.cache/huggingface \ -v /root/data:/app/modeldata/data \ -v /root/config:/app/config \ -v /root/saves:/app/saves \ -v /root/output:/app/output \ -p 7860:7860 \ -p 8000:8000 \ --name llamafactory \ llamafactory:v0.9.2
2025-03-19