04 快速上手(二):LobeChat+AI 网关 +Ollama打造高可用大模型集群
你好,我是邢云阳。
在上一节课,我们使用 Ollama 部署了一个 DeepSeek-R1:32B 的模型,并通过修改聊天模板,完成了让模型强制 think 的修改。今天这节课,我们继续上一节课的思路,完成多 Ollama 实例的负载均衡的配置,使之成为一个高可用的 Ollama 集群。
话不多说,让我们先从集群架构设计开始吧。
部署架构图
首先看一下整体的部署架构。
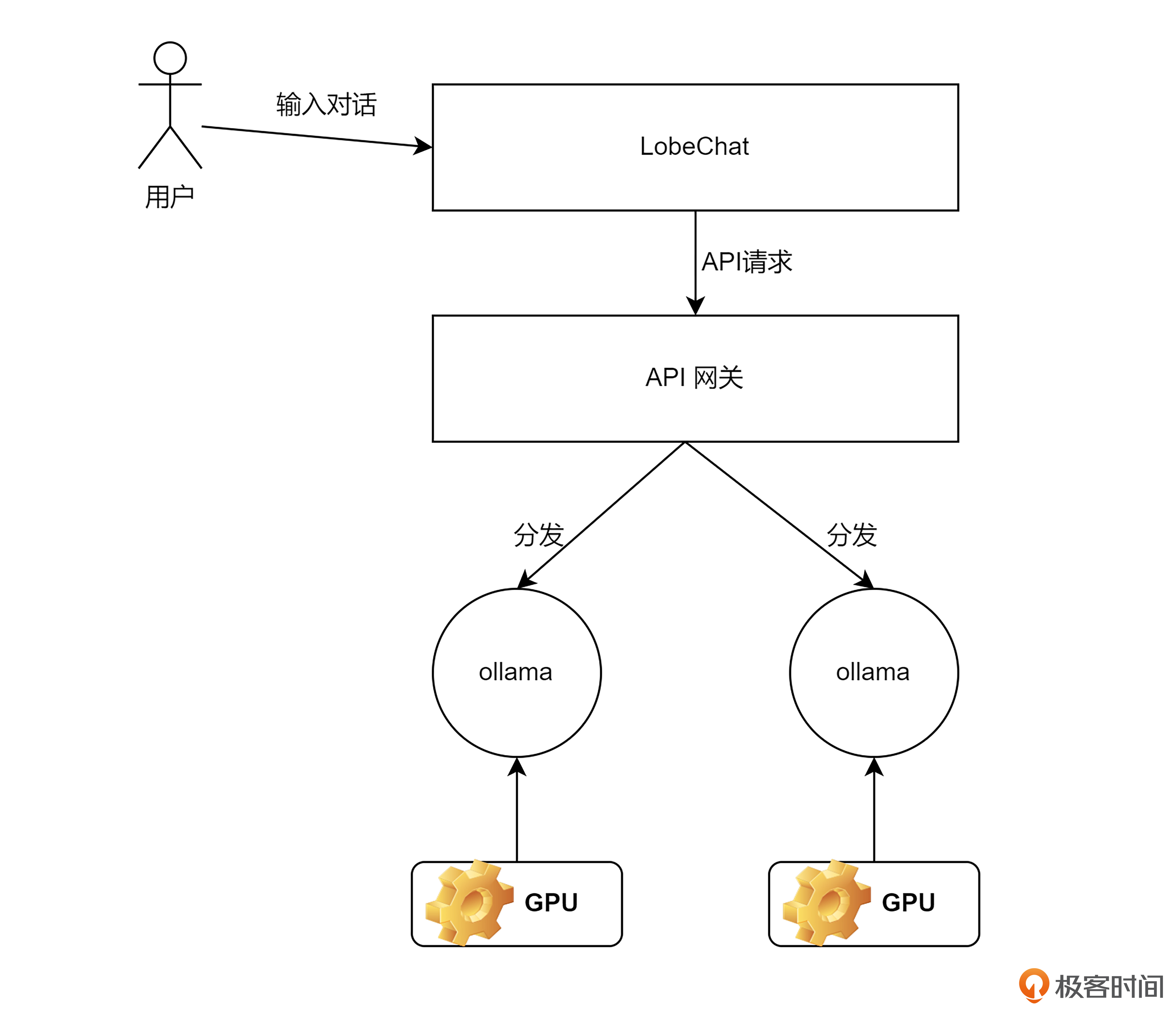
上节课,我介绍过,在我的服务器上,有两张 T4 卡,因此我会创建两个 Ollama 实例,两个实例分别占用一张卡,并且每一个实例都对应一个 DS-R1:32B 模型。
之后为了满足对于大模型服务的负载均衡和流量转发,我们需要针对 AI 时代的新需求去对 API 网关进行选型。
最后为了能让用户像使用 ChatGPT 一样,通过一个前端页面与大模型进行问答交互,我部署了开源社区特别火的一款对话前端,名字叫 LobeChat。LobeChat 开箱即用,支持多模型的对接,非常适合我们做对话测试。
使用 Ollama 启动 DS 模型
接下来,我们启动一下两个 Ollama。我依然使用的是将模型下载服务器,然后挂载到 Docker 容器内的启动方式。命令行如下所示,注意区分两个实例的名称以及端口号,不能重复。同时要注意 --gpus 参数的设置,第一个实例用 0 号卡,第二个实例用 1 号卡。
实例1:
docker run -dp 8880:11434 --runtime=nvidia --gpus device=0 --name DeepSeek-R1-1 -v /usr/share/ollama/.ollama/models:/root/.ollama/models docker.1ms.run/ollama/ollama:0.5.11
实例2:
docker run -dp 8881:11434 --runtime=nvidia --gpus device=1 --name DeepSeek-R1-2 -v /usr/share/ollama/.ollama/models:/root/.ollama/models docker.1ms.run/ollama/ollama:0.5.11
我们使用 docker ps 查看一下启动情况:
root@aitest:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
db280e09c715 docker.1ms.run/ollama/ollama:0.5.11 "/bin/ollama serve" 4 seconds ago Up 3 seconds 0.0.0.0:8881->11434/tcp, [::]:8881->11434/tcp DeepSeek-R1-2
30ea38431349 docker.1ms.run/ollama/ollama:0.5.11 "/bin/ollama serve" 17 seconds ago Up 16 seconds 0.0.0.0:8880->11434/tcp, [::]:8880->11434/tcp DeepSeek-R1-1
可以看到两个实例都启动了。此时,你可以使用上节课的 curl 命令,来分别测试一下两个实例通过 API 方式的对话是否正常。
网关选型
根据我们的部署架构图,接下来就是 API 网关的选型了。在传统的业务中,我们经常使用 Nginx 等作为流量转发和负载均衡网关。这对于单次 HTTP 连接时间短,单次请求数据量小的场景来说没有问题。但在 AI 时代,网关后端对接的不再是传统的 HTTP Server,而是大模型。
如果只是简单测试一下负载均衡效果,那使用 Nginx 完全 OK。但如果是真正的实现生产级别的应用,那么我们就需要针对 AI 时代的新挑战而使用 AI 网关,比如 Kong、Higress 等。
AI 时代给网关带来的挑战
AI 时代给网关带来了哪些新挑战呢?
第一,服务连续性。LLM 应用通常需要较长的内容生成时间,用户体验很大程度上依赖于对话的连续性。因此,如何在后端系统更新时保持服务不中断成为了一个关键问题。
第二,资源安全。与传统应用相比,LLM 服务处理单个请求时需要消耗大量计算资源。这种特性使得服务特别容易受到攻击,攻击者可以用很小的成本发起请求,却会给服务器带来巨大负担。如何保障后端系统的稳定性变得尤为重要。
第三,商业模式保护。很多 AGI 企业会提供免费调用额度来吸引用户,但这也带来了风险,部分黑灰产会利用这些免费额度封装成收费 API 牟利。如何防范这类商业损失是一个现实问题。
第四,内容安全。不同于传统 Web 应用的简单信息匹配,LLM 应用通过 AI 推理来生成内容。如何确保这些自动生成的内容安全合规,需要特别关注。
第五,多模型管理。当我们需要接入多个大模型时,如何统一管理不同厂商的 API,降低开发和维护成本也是一个重要课题。
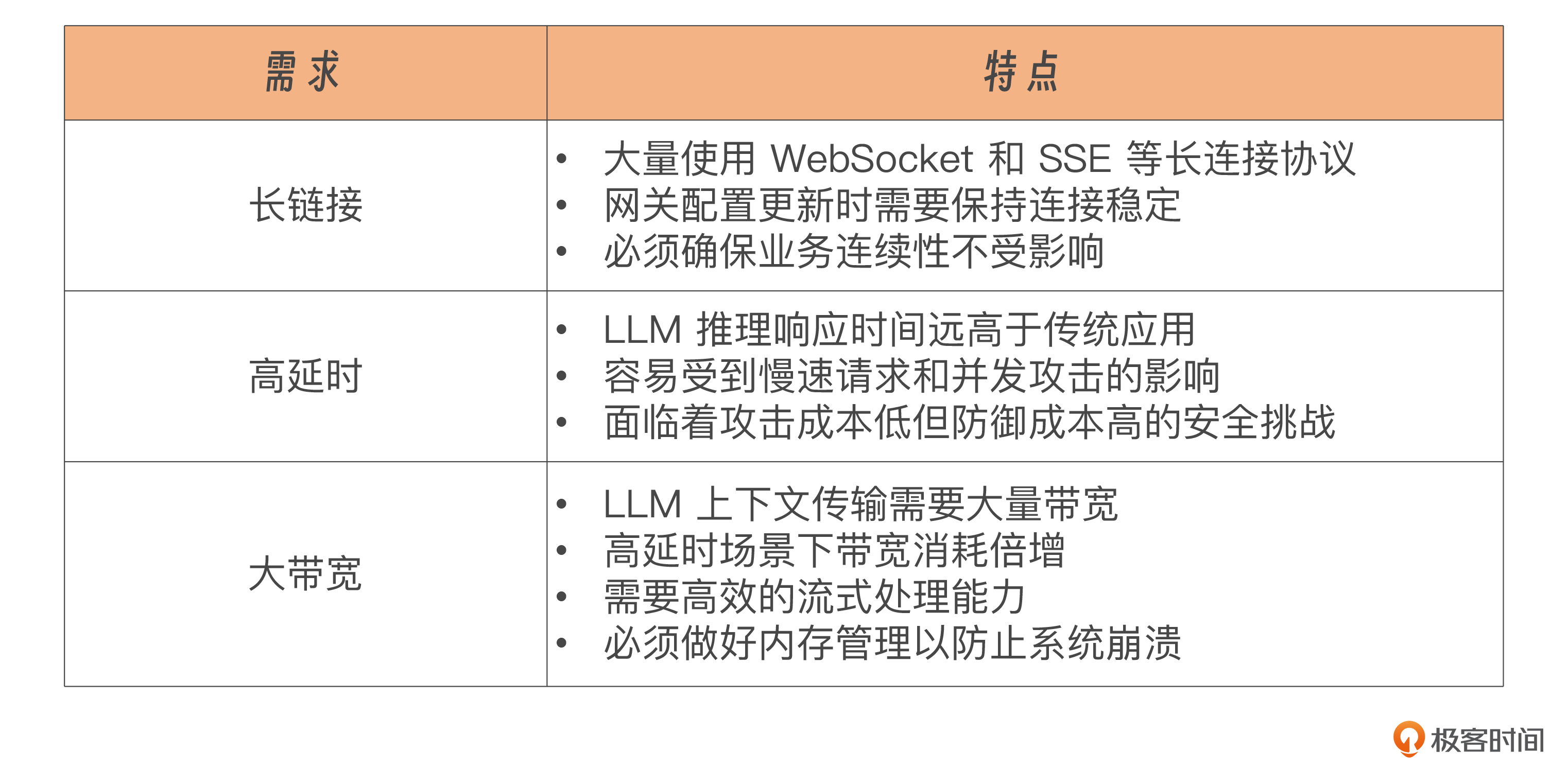
在网关的流量层面,AI 时代还面临着三大新需求,分别是长连接、高延时和大带宽,我整理了一张表格描述每个需求的特点。
AI 网关 Higress
因此如果像做传统业务一样,仅仅考虑负载均衡,流量转发是远远不够的。考虑到这样的背景,我们的课程里将会使用阿里云开源 Higress,作为我们高可用大模型集群的网关。
Higress 部署与测试
Higress 在 AI 时代之前是一个云原生 API 网关,在阿里内部,为解决 Tengine(加强版 Nginx)reload 对长连接业务有损,以及 gRPC/Dubbo 负载均衡能力不足的问题,Higress应运而生。Higress 提供了基于 K8s 的部署模式,以及基于 Docker 的 all-in-one 的部署模式,这节课,我们使用后一种模式。
首先执行如下命令,将安装脚本下载下来。
如果你只想内网使用,可以直接执行 bash install.sh 命令一键安装。但如果想将网关暴露在公网,则需要打开配置文件,在第 428 行找到如下图所示的内容,将红框中三行的 127.0.0.1: 全部去掉。

然后执行 bash insta…sh 进行安装。首先会让你选择要对接什么大模型,此处可以不选,直接回车跳过。
之后出现如下显示,代表安装成功:
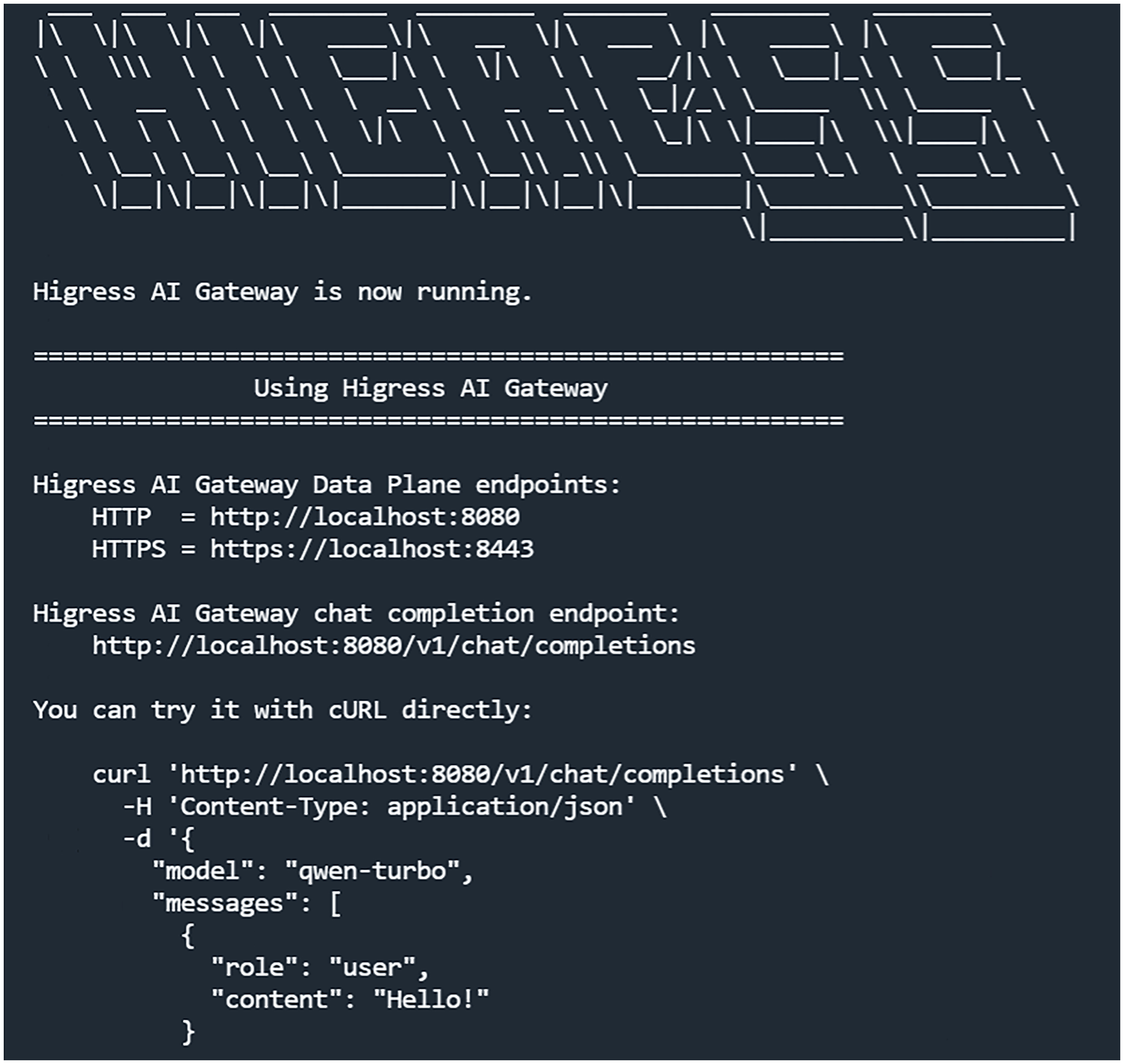
从安装信息中,我们可以看到 Higress 暴露了三个端口,分别是 HTTP 访问端口 8080,HTTPS 访问端口8443,以及控制台访问端口 8001。
我们可以在浏览器输入 <公网ip>:8001 进入 Higress 控制台。首次进入会让用户初始化管理员账户。
Higress 针对 AI 的需求,设计了 AI 流量入口管理的功能,可以非常简单地完成添加大模型服务,以及添加大模型的访问路由等功能。
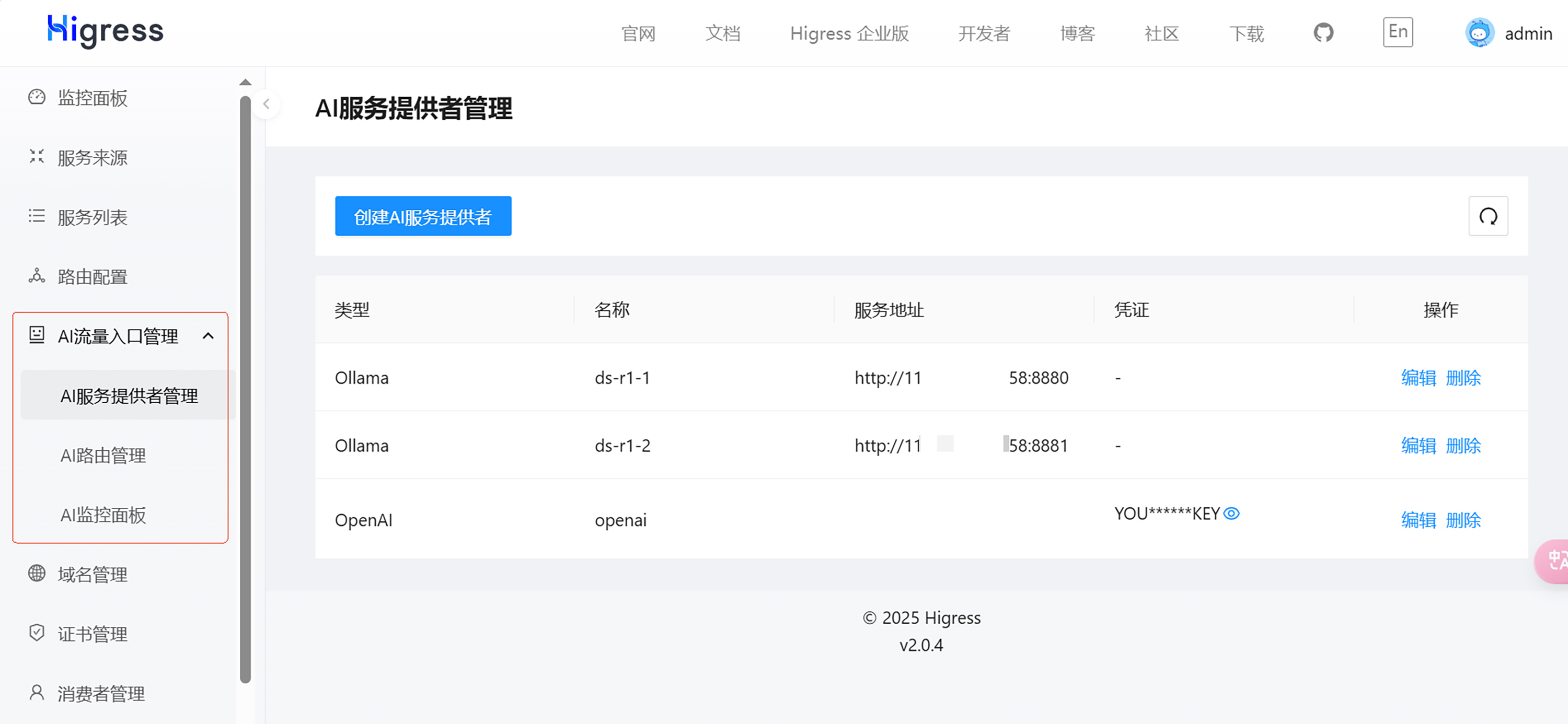
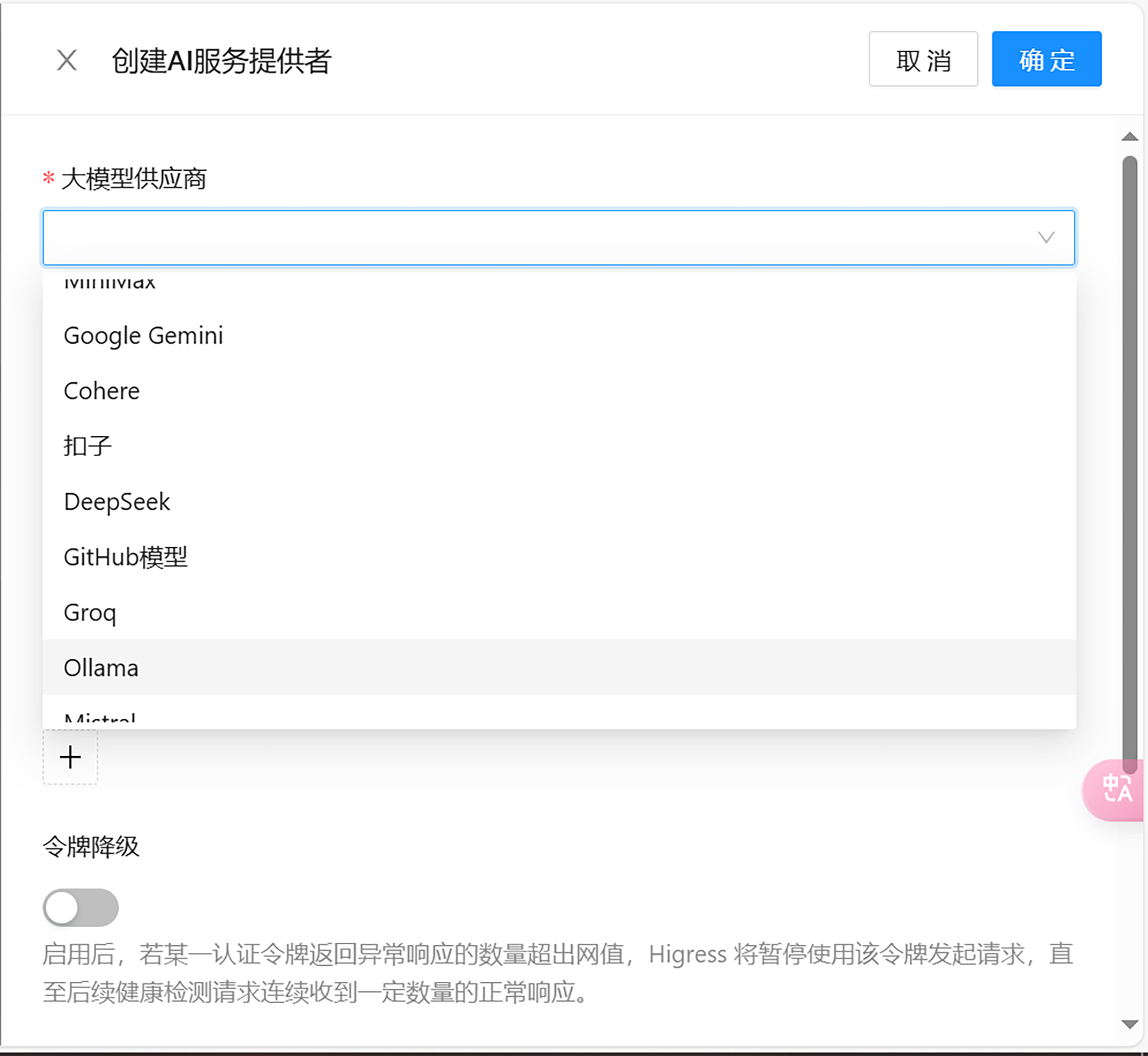
我们点击创建 AI 服务提供者,将服务器上的两个 Ollama 服务都添加上。
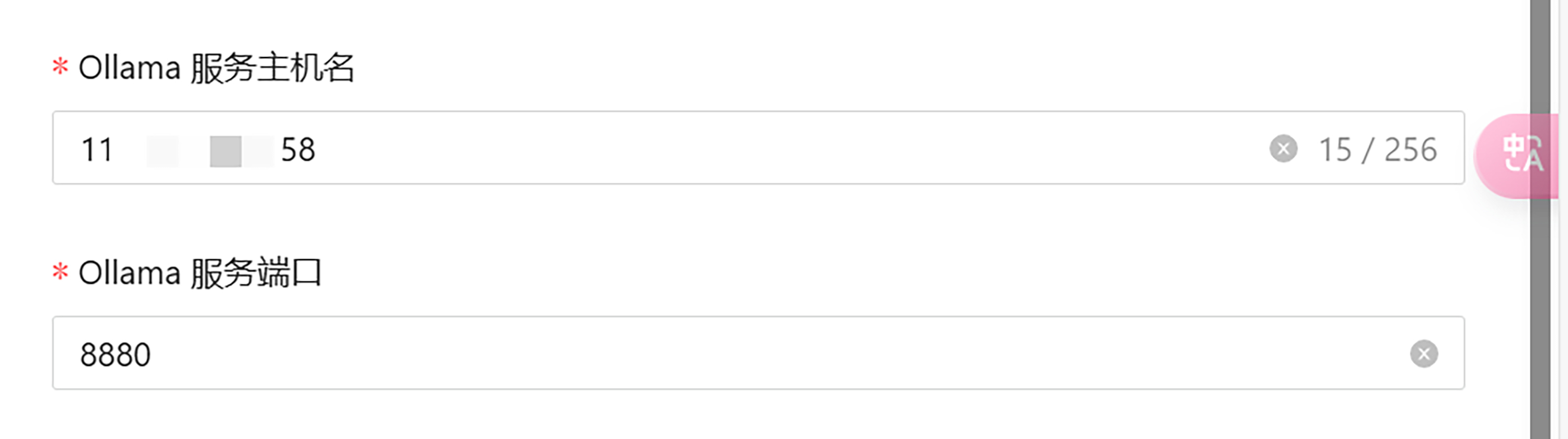
注意 Ollama 服务主机名要填服务器的公网地址,这是因为 Higress 运行在 Docker 容器中,访问不到服务器内网。
服务添加完成后,接下来就是添加访问路由了。由于我们是要对两个 Ollama 做负载均衡,因此需要在一台路由中,将两个 Ollama 服务都关联上。
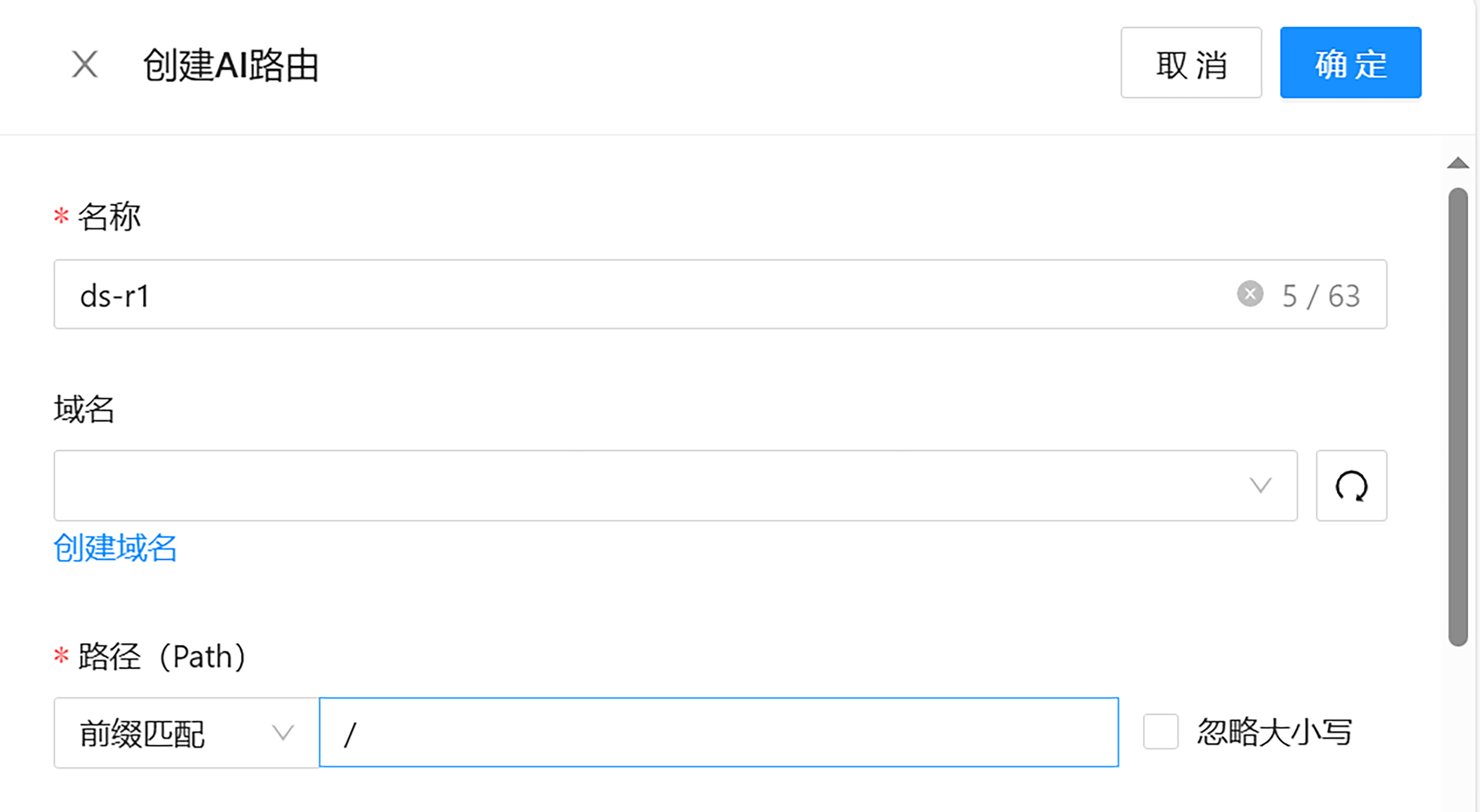
Higress 同时支持设置每个服务的请求比例,在这里,我设置的是各占 50%。
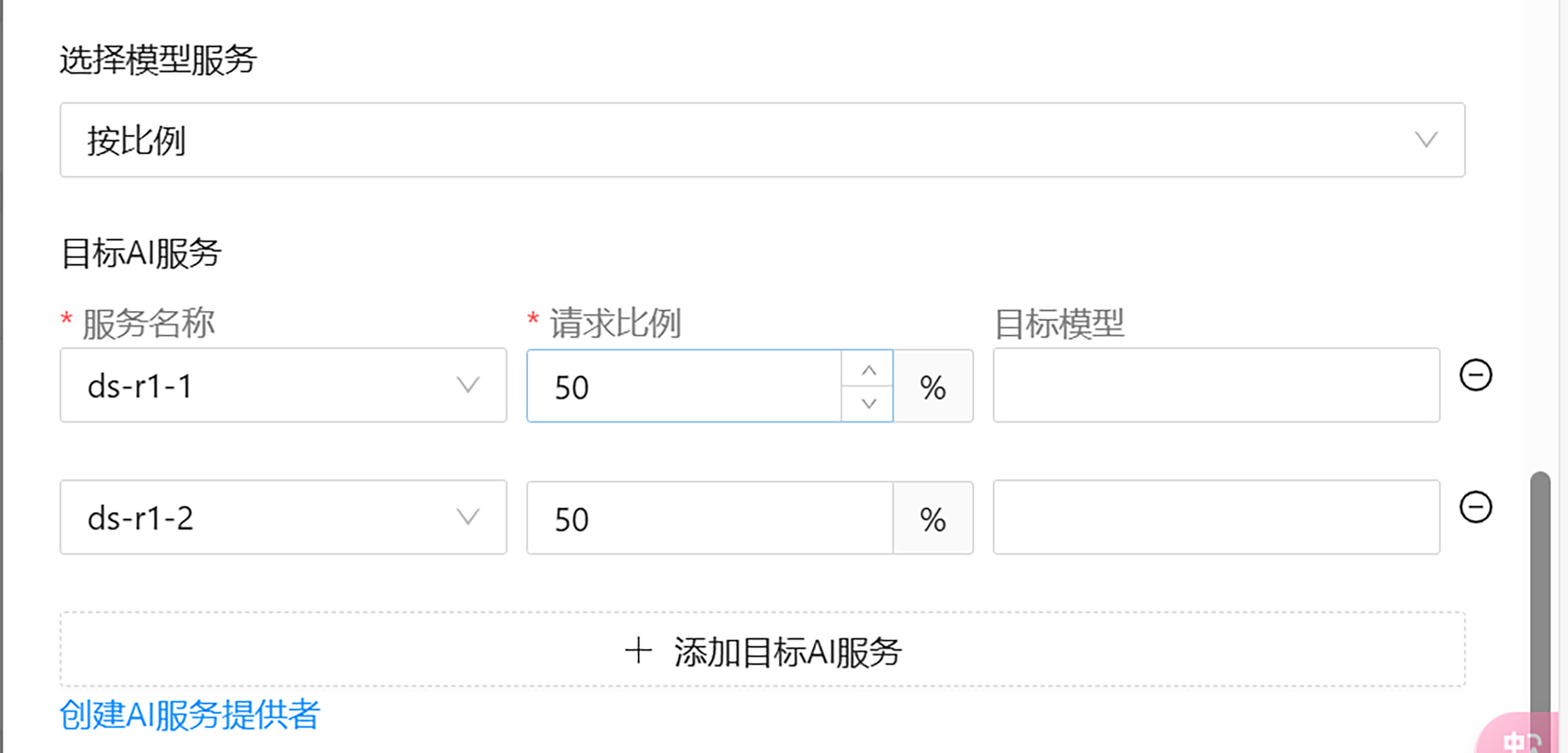
设置完成后,便可以在服务器上使用 curl 命令进行测试了。Higress 提供了兼容 OpenAI 数据格式的服务,我们可以使用 OpenAI 数据格式进行路由的请求。命令如下:
curl -sv http://localhost:8080/v1/chat/completions \
-X POST \
-H 'Content-Type: application/json' \
-d \
'{
"model": "deepseek-r1:32b",
"messages": [
{
"role": "user",
"content": "你是一个python编程专家,请帮我写一个计算加法的程序"
}
]
}'
此时 Higress 会将请求随机路由到一个 Ollama 服务上去,命令的输出如下:
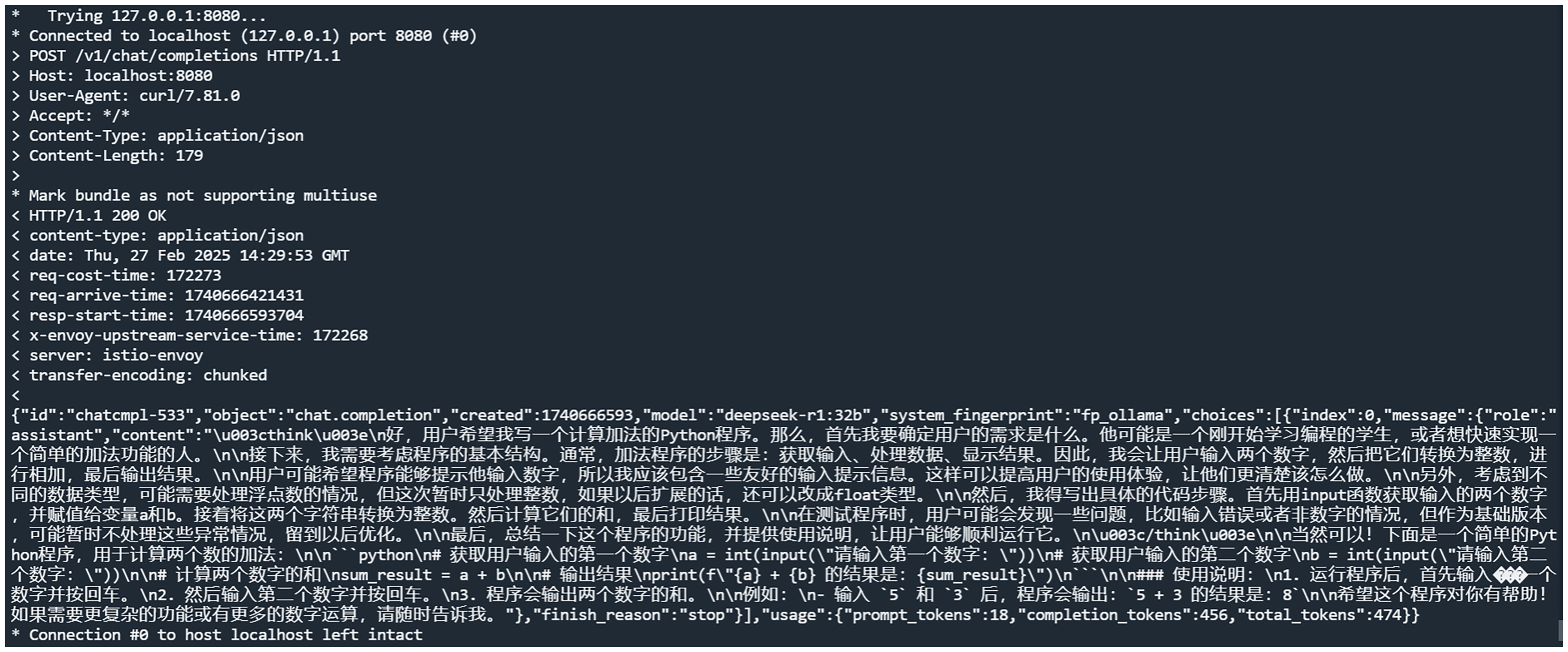
可以看到,请求成功了。
API Key 二次分租
如果我们想将 Ollama 集群面向多用户提供服务,这种场景该如何满足呢?比如面向公司内部员工使用,每个员工一个 API Key,或者面向外部客户,按 API Key 使用量收费等。
Higress 提供了 API Key 二次分租的功能。我们可以这样理解这个功能—— Ollama 是房东,Higress 租下了 Ollama 的房子,然后又把房子租给了别人,自己变成了二房东。
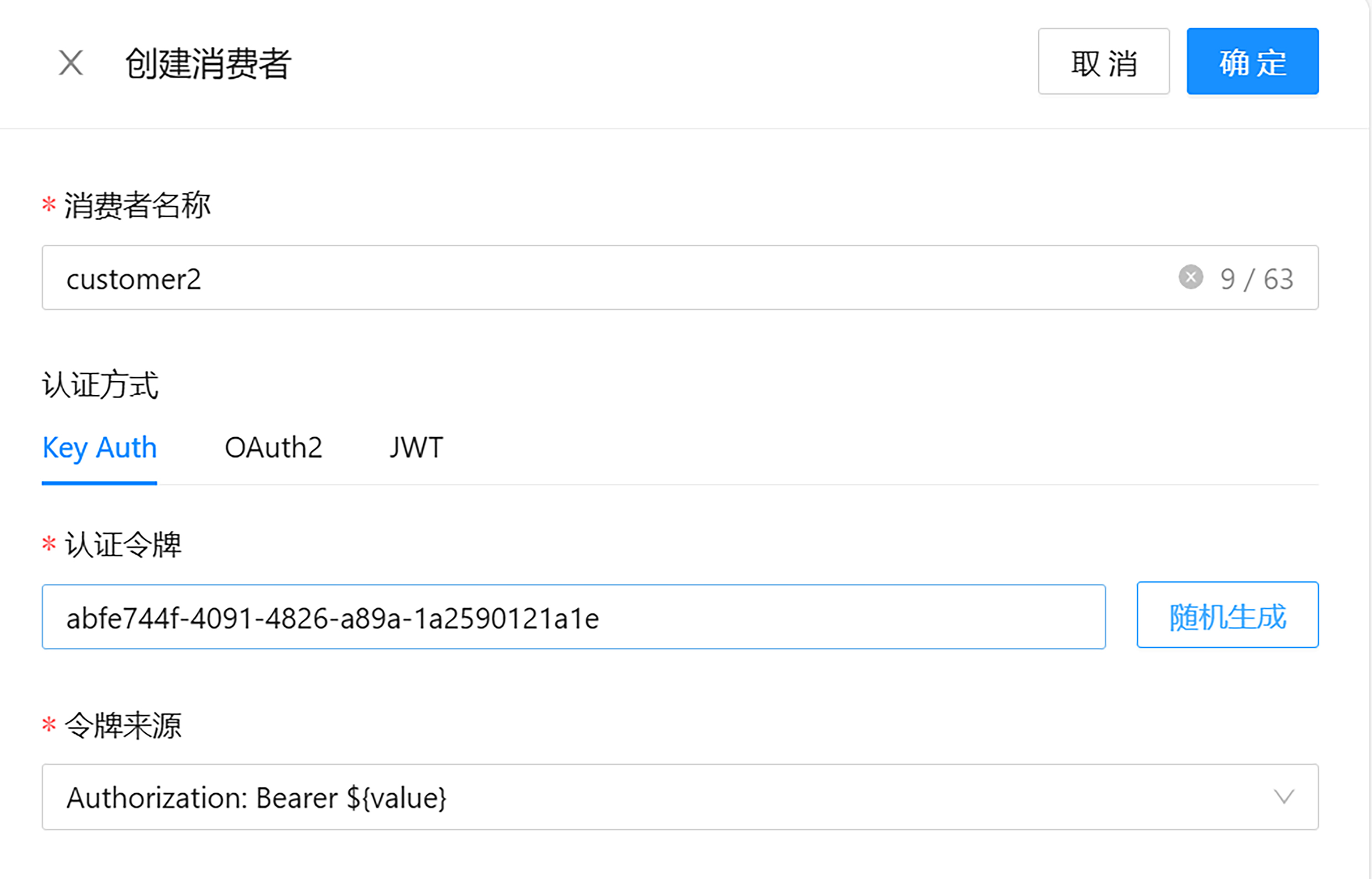
接下来,我们进行测试。首先将页面切到消费者管理,创建消费者。
 }{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"
我们模拟向两个用户提供服务的场景,来创建两组认证令牌,也就是 API Key。
之后,用户如果使用 API Key 访问网关,则需要在请求头中进行添加,命令如下所示:
curl -sv http://localhost:8080/v1/chat/completions \
-X POST \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer fcb8c143-bb01-4bf3-ad5c-6d76bc727e66" \
-d \
'{
"model": "deepseek-r1:32b",
"messages": [
{
"role": "user",
"content": "你是一个python编程专家,请帮我写一个计算加法的程序"
}
]
}'
这样,Higress 就可以控制消费者的调用权限和调用额度,还可以配合可观测能力,对每个消费者的 token 用量进行观测统计。
Token 用量观测
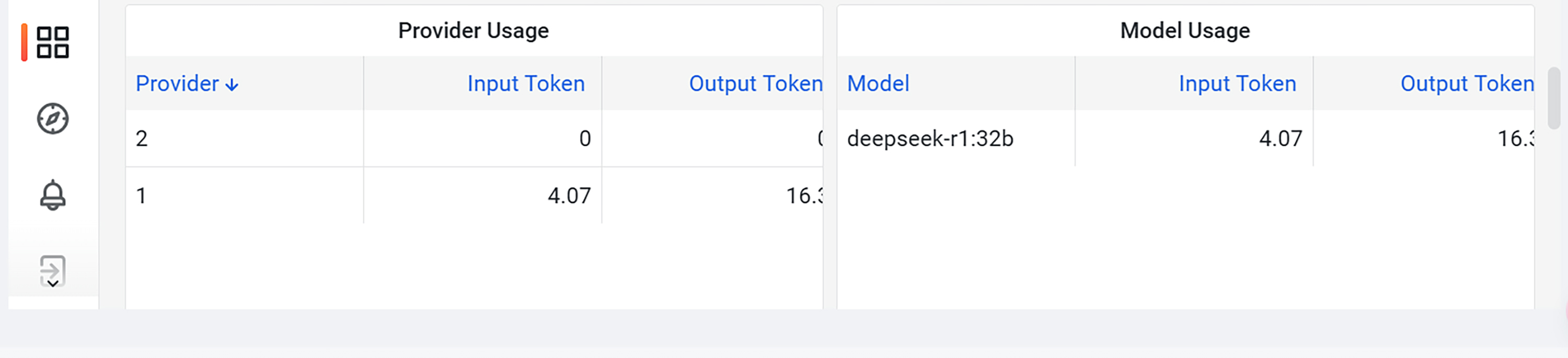
Higress 内置了 Prometheus + Grafana 的指标监控套件。可以将页面切换到 AI 控制面板进行查看。
接入 LobeChat
curl 命令只是我们研发人员测试使用的,如果让用户也使用 curl,就太不像话了。因此最后,我们将网关接入到一个可视化的自然语言前端,为我们的整个方案画上圆满的句号。
在 Github 上,开源的自然语言前端有很多,热度比较高的有 OpenWebUI、LobeChat 等,今天我就用 LobeChat 为大家演示。
LobeChat 的部署分为两种类型。第一种是新手体验版本的,这个版本只需要在本地部署一个对话客户端就可以使用,所有的历史对话数据,配置信息等都是存在 LobeChat 的云服务器上的。第二种则是完全私有化的部署,即数据存储在自己的本地。
由于这节课侧重演示方案,因此我就用新手版的,大家如果后续在生产使用,可以使用完全私有化版。
新手版 Lobechat 可以使用 docker 一键拉起:
$ docker run -d -p 3210:3210 \
-e OPENAI_API_KEY=fcb8c143-bb01-4bf3-ad5c-6d76bc727e66 \
-e OPENAI_PROXY_URL=http://higress:8080/v1 \
-e ACCESS_CODE=lobe66 \
--name lobe-chat \
lobehub/lobe-chat
由于我们是通过 LobeChat 的 OpenAI 接口对接 Higress,因此需要填写 OPENAI_API_KEY 和 OPENAI_PROXY_URL 两个参数,OPENAI_API_KEY 是上文中我们二次分租创建的 API Key,如果你没有开启二次分租,则可以填写 unused。OPENAI_PROXY_URL 即为 higress 的 HTTP 访问地址。LobeChat 的客户端会通过 3210 端口暴露。
在浏览器输入 <公网地址>:3210 即可打开 LobeChat 对话客户端,然后就可以开始对话了。
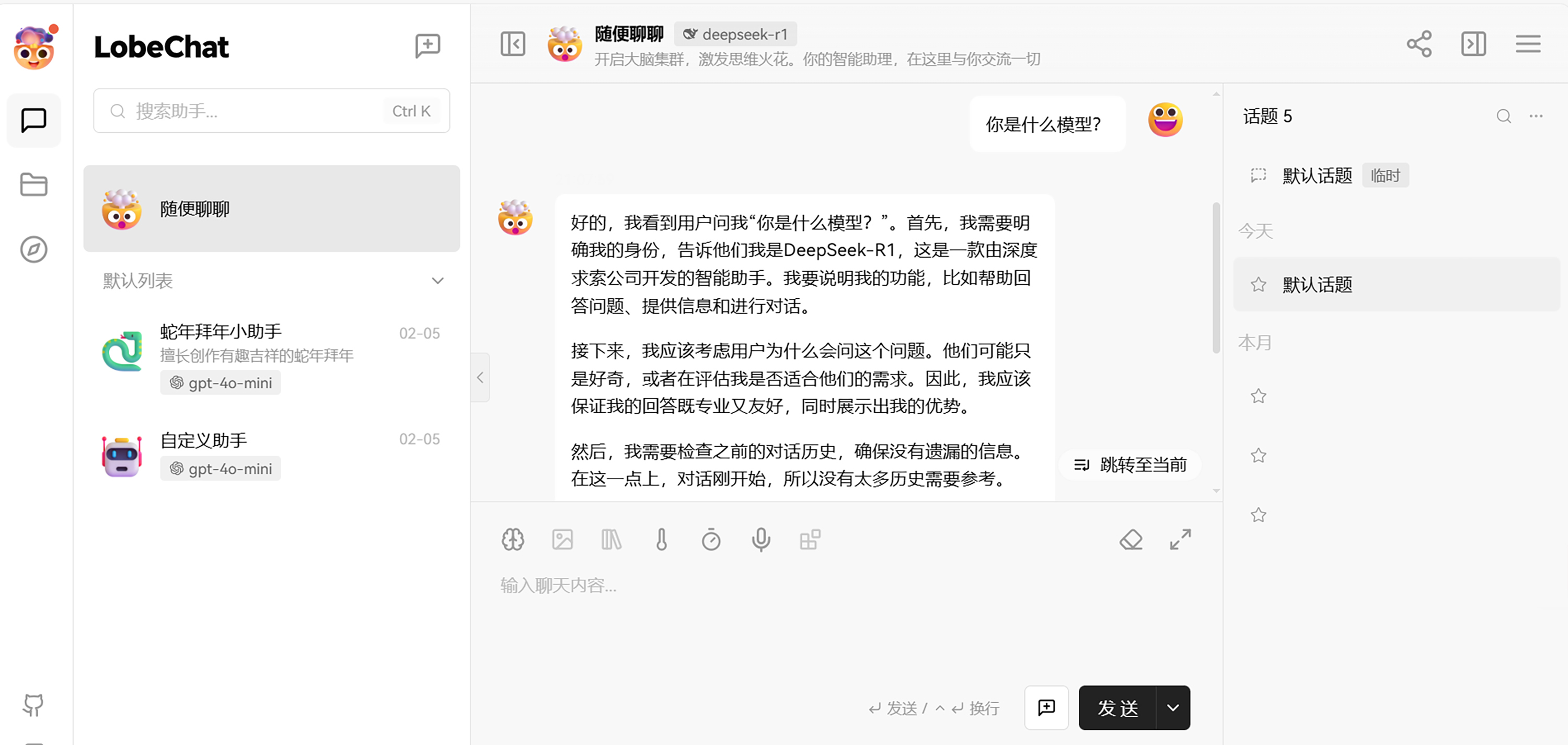
大家测试后,会发现使用 LobeChat 进行对话,会像我们使用 DeepSeek 官网的对话页面一样,直接开始一个字一个字的输出,而不是等待一段时间后,直接把全部内容显示出来。这种一个字一个字的输出方式就叫流式模式,在内容特别多的大对话场景下,流式输出可以减轻服务器和网关的压力,还能让用户的使用体验更好。
总结
今天,我们在大家已经掌握 Ollama 的基本使用方法之后,又为大家引入了 AI 网关 Higress 以及对话前端 LobeChat。通过这两个组件,我们组成了一个带有可视化自然语言对话前端的高可用高可控的大模型集群。
这节课的重点在于网关的选型。传统的类似 Nginx 的网关已经无法应对 AI 时代的长连接、高延时和大带宽的要求。Hgress 是以 istio 和 envoy 为核心开发的,天然对于这些特性就有完美的契合。在加上其内置的多种插件,完全可以满足企业内外部大模型服务的提供。
思考题
企业在提供大模型服务时,通常希望网关能够拦截一些用户提问中的敏感词,防止出现法律等方面的风险。我们可以使用 Higress 的哪个插件来实现这个功能呢?你以通过 Higress是什么?-Higress官网 里插件使用文档这部分来找到答案。
欢迎你在留言区展示你的思考结果,我们一起探讨。如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- 小林子 👍(5) 💬(1)
催更
2025-03-05 - Toni 👍(5) 💬(1)
思考题: 使用 Higress 的插件checkRequest,能够使网关Higress拦截一些用户提问中的敏感词,插件checkResponse用于检查大模型的回答内容是否合规,这两个以合规为目的设计的插件用于规避可能出现的法律等方面的风险。
2025-03-04 - Nico 👍(2) 💬(1)
Cherry Studio 感觉也不错
2025-03-15 - 霰雪纷飞 👍(2) 💬(4)
老师,你的LobeChat有什么额外设置么?我Higress配置好了,通过postman能访问且也能回答成功,但是安装LobeChat,安装也成功了,我ollama安装的是llama3.1,按理和deepseek-r1差不多。因为higress默认的容器名是higress-ai-gateway,所以我run起来命令是docker run -d -p 3210:3210 -e OPENAI_API_KEY=43acaf98-4689-4221-8d4a-e3a6050e0e77 -e OPENAI_PROXY_URL=http://higress-ai-gateway:8080/v1 -e ACCESS_CODE=lobe66 --name lobe-chat docker.1ms.run/lobehub/lobe-chat。可是在界面上,我选择llama3.1提示我{ "error": { "message": "Load failed", "name": "TypeError" }, "provider": "ollama" },这是什么情况阿?
2025-03-13 - 周毅 👍(2) 💬(2)
为什么不直接用Dify的呢?我理解LobeChat在Dify有类似的平替。
2025-03-06 - b1a2e1u1u 👍(2) 💬(1)
老师请教一下,在用Higress创建AI负载路由时,路径(Path)是个必填项,是否需要写成/v1/chat/completions,还是保持默认/即可?
2025-03-05 - Atinfo 👍(1) 💬(1)
老师,通过higress,如何流式输出呢?接口风格和OPENAI的一致吗?
2025-03-26 - 流沙 👍(1) 💬(1)
我用的云服务器向外网端口映射的原因,higress容器内访问不到ollama的公网服务,填公网地址不行。 奇怪的是用docker网络172.17.0.1的地址,在higress容器是能访问8880和8881的服务的。但我把地址172.17.0.1配到higress上,还是不成功。 用curl调用higress的服务upstream connect error or disconnect/reset before headers. reset reason: connection timeout。 请问老师和同学们知道这里该如何处理吗?谢谢
2025-03-12 - 陌兮 👍(1) 💬(1)
好看,催更
2025-03-11 - 王建 👍(1) 💬(1)
催更,催更。 原来云厂商也是用的ollama啊,学到了。 老师,后面会讲其它部署方式的对比吗,比如vllm什么的。
2025-03-08 - timefly 👍(1) 💬(6)
请教老师: mac book pro m3如何 部署deepseek 本地开发环境
2025-03-06 - 茗 👍(1) 💬(1)
老师,请教一个问题,那个API key不填写会怎样?如果填写了是不是一个key就要创建一个对应的lobe chat 实例?
2025-03-06 - 秋刀鱼 👍(0) 💬(1)
配置完网关代理后:"""curl -sv http://localhost:8080/v1/chat/completions""" 报错:""""* Connection #0 to host localhost left intact {"error":{"message":"Authentication Fails, Your api key: ****_KEY is invalid","type":"authentication_error","param":null,"code":"invalid_request_error"}}root@iZbp17wsa0ljs3bnb27od7Z"" 2、直接请求:"""curl -sv http://localhost:8880/v1/chat/completions""",正常,到:vi gateway.log 先情况 重新请求,里面看不到日志
2025-05-02 - helloworld 👍(0) 💬(2)
老师,我全部用 docker 实验的,前面都很顺利,到最后配了路由就报错路径 404,路由的配置为: / 前缀匹配 能帮忙看看哪里有问题吗,官网啥也没有 docker run -dp 8880:11434 --name ollama1 --hostname ollama1 -v ~/.ollama/models:/root/.ollama/models docker.1ms.run/ollama/ollama:0.5.11 docker run -dp 8881:11434 --name ollama2 --hostname ollama2 -v ~/.ollama/models:/root/.ollama/models docker.1ms.run/ollama/ollama:0.5.11 docker run -d --rm --name higress-ai --hostname higress-ai \ -p 8001:8001 -p 8089:8080 -p 8443:8443 \ higress-registry.cn-hangzhou.cr.aliyuncs.com/higress/all-in-one:latest 在 higress-ai 容器中,执行以下命令测试都是正常的 curl -sv http://172.17.0.2:11434/v1/chat/completions \ -X POST \ -H 'Content-Type: application/json' \ -d \ '{ "model": "deepseek-r1:1.5b", "messages": [ { "role": "user", "content": "你是一个python编程专家,请帮我写一个计算加法的程序" } ] }' curl -sv http://172.17.0.4:11434/v1/chat/completions \ -X POST \ -H 'Content-Type: application/json' \ -d \ '{ "model": "deepseek-r1:1.5b", "messages": [ { "role": "user", "content": "你是一个python编程专家,请帮我写一个计算加法的程序" } ] }' curl -sv http://localhost:8880/v1/chat/completions \ -X POST \ -H 'Content-Type: application/json' \ -d \ '{ "model": "deepseek-r1:1.5b", "messages": [ { "role": "user", "content": "你是一个python编程专家,请帮我写一个计算加法的程序" } ] }' 最后一步测路由 curl -sv http://localhost:8001/v1/chat/completions \ -X POST \ -H 'Content-Type: application/json' \ -d \ '{ "model": "deepseek-r1:1.5b", "messages": [ { "role": "user", "content": "Hello!" } ] }' 报错 404 {"timestamp":1745311351102,"status":404,"error":"Not Found","path":"/v1/chat/completions"}%
2025-04-22 - Eric 👍(0) 💬(4)
老师,我在使用本节课方式部署Higress后,发现监控面板的指标记录只保留了当天的数据,查历史时间范围的指标统计数据都是0,这个要怎样解决?
2025-04-13