01 DeepSeek“民用级”程序员使用指北
你好,我是邢云阳。
飞雪连天射白鹿,笑书神侠倚碧鸳。金庸老先生的著作人物众多,武学精妙绝伦,剧情跌宕起伏,非常吸引人。我在上大学时,曾经两天时间就读完了《射雕英雄传》。
恰逢最近 DeepSeek 模型爆火,“模型蒸馏”这个专业名词也频繁出现在大众视野,所以在前置课程里面,我想先借着《射雕英雄传》里的人物,来聊聊“模型蒸馏”。不过你不用担心它过于深奥,作为应用开发者,我们只要知道它大致的原理就足够了。
然后呢,我想和你聊聊普通程序员怎么迎接 DeepSeek 的东风,可以用它帮我们做那些事儿。还会分享一下课程学习方法和建议,让你轻装上阵,为后续课程的学习打好基础。
蒸馏是什么?
在《射雕英雄传》中,洪七公是江湖上人人敬仰的北丐,武功高强,见识广博,内力深厚,就像大模型,经过了海量数据的训练,拥有强大的知识储备和计算能力。然而,大模型的训练和部署成本极高,就像洪七公的武功,不是人人都能轻易学会的。
但洪七公总要收徒传艺,将丐帮武学传承下去。因此他需要将武功用“浓缩”的方式交给徒弟,在保证一定精度的同时,大幅降低对于内力(GPU)的要求,例如,他将打狗棒法传给了黄蓉,将降龙十八掌传给了郭靖等等,这便是模型蒸馏技术。
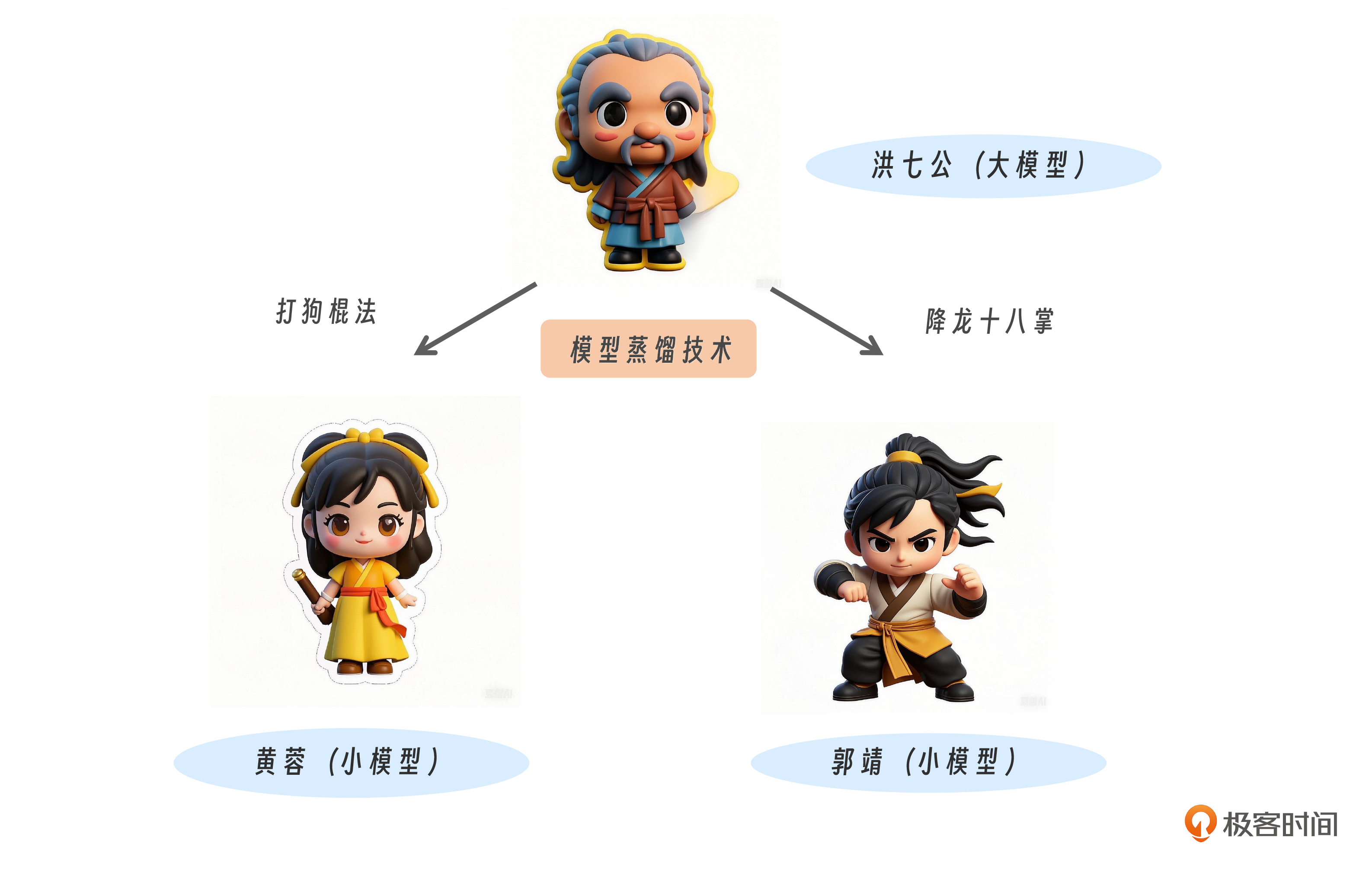
黄蓉等小模型,虽然武功不及洪七公,但是胜在没有洪七公这么大的江湖名望(部署和推理成本低),因此对付三流的沙通天、灵智上人之类的小卡拉米时,没有江湖前辈欺负后辈的心理包袱。
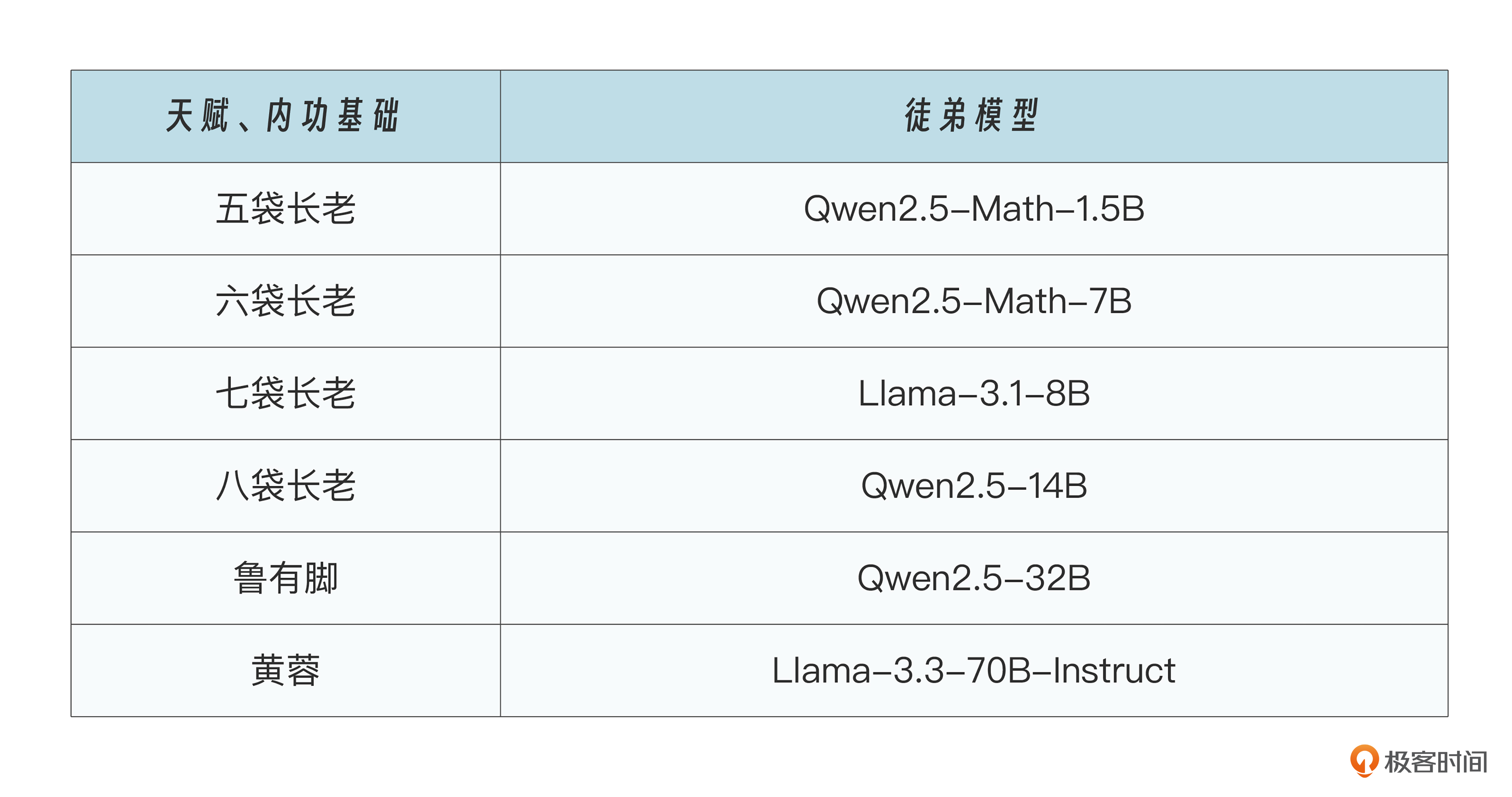
以 DeepSeek 发布的六个蒸馏模型为例,满血版 671B 参数量的 DeepSeek R1 就是洪七公,而洪七公针对不同尺寸的徒弟模型进行武功蒸馏,这些徒弟模型包括:
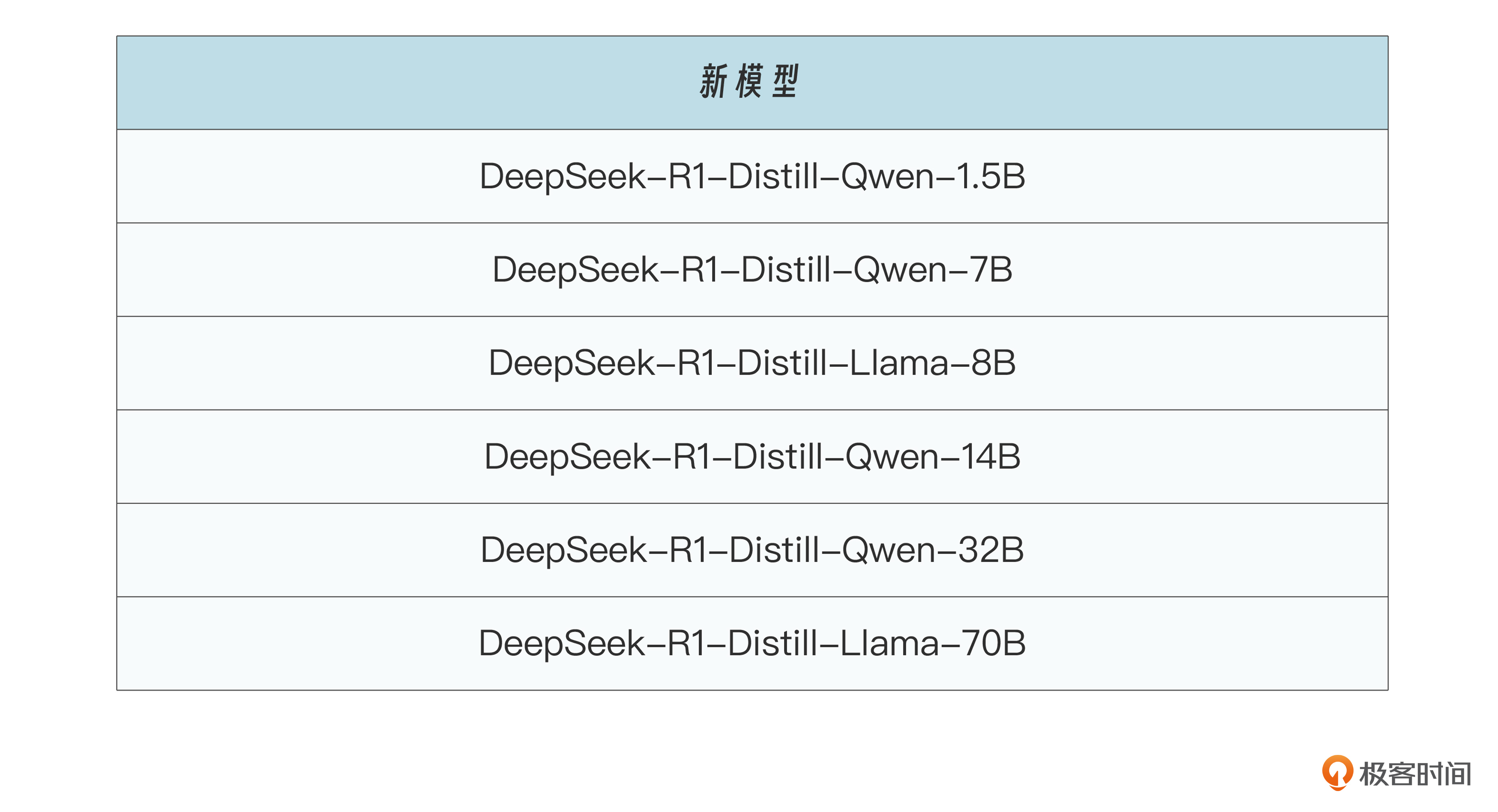
经过蒸馏后便得到了新模型:
 总之,每个徒弟的资质、水平不一样,基础素质越高的,能力越强,越能从师父身上学到更多的东西,也就越接近师父的水平。
总之,每个徒弟的资质、水平不一样,基础素质越高的,能力越强,越能从师父身上学到更多的东西,也就越接近师父的水平。
洪七公教徒弟的方法,是他先演示一遍,然后让徒弟跟着模仿一遍。但洪七公不会让徒弟死记硬背,而是会交给他们思维方式,让他们自己感受内力的流动,做到招式随心而发。在模型蒸馏中,思维方式有一个专业名称,叫做软标签,软标签并不是直接告诉小模型“这是对的”,而是通过大模型的输出,给出每个类别的概率分布。小模型通过学习这些概率分布,能够理解不同类别之间的微妙区别。
徒弟们在拜入洪七公门下时,都有自己的武功根基,因此在学习洪七公的武功时,会有一些自己的想法,这被称之为硬标签。在实际蒸馏过程中,徒弟要尽可能学习师父的本领,但是又不能和自己原本的内功冲突,导致走火入魔。因此需要在软硬标签间寻找一个标准,得到标准后,进行反复训练,直到纯熟,此时徒弟就出师了。
OK,以上就是关于模型蒸馏的一点白话解读,对于做应用开发的我们来讲,不需要深究其中的原理,只需要大概了解,会用即可。
“民用级”程序员是什么?
接下来我们回到这节课的标题,厘清一下我说的“民用级”程序员是指什么。
大约在元旦前,一则新闻引起了不少关注——雷军以千万年薪,从 DeepSeek 挖来了一位95后的 AI 天才——罗福莉。罗福莉曾在 DeepSeek 参与 DeepSeek-V2 的研发,是这款模型的核心开发者之一。消息一出,有人曝光了 DeepSeek 研发团队成员的背景。这些人基本都是95后、00后,且大多数拥有清华、北大的博士学历,令人惊讶的是,他们中的许多人在本科入学的前两三个月,就已经发表了相当于博士毕业水平的论文。
那我自己来说,本科论文的主题跟基于神经网络的车牌识别系统相关,被答辩导师说研究水平相当于硕士毕业水平,当时已经觉得很牛了,但和人家一比,完全就如繁星比皓月,寒鸦比凤凰。
因此如果你也是这种搞科研的、研究 AI 模型底层的高精尖人才,那这个课程可能不适合你,因为对你来说太简单了。但除此之外,如果大家都是像我一样是普通人,普通学历、普通智商,那如何用好 AI,如何更新自己的思想,如何让 AI 帮助我们更好的做应用开发,如何把 AI 应用到产品当中,才是我们要考虑的,这就是“民用级”程序员的学习重点,也是我们这个课程所要讲解的内容。
DeepSeek 如何使用?
既然要用好AI,首先我们得做到第一个字——“用”。
我们这就来看看 DeepSeek 如何使用。如果想先体验一下模型的能力,我们可以直接去官网(DeepSeek | 深度求索),点击开始对话,就可以免费体验官方版本的 DeepSeek-V3 以及满血版 671B 的 DeepSeek-R1 的能力。

默认使用的是 DeepSeek-V3 模型。
如果想体验 DeepSeek-R1 671B,就点击深度思考(R1)。

DeepSeek-V3 适合做聊天对话,写文章、翻译、客服问答,常规的代码生成等事情。
DeepSeek-R1 是在 满血版 DeepSeek-V3 671B 的基础上进行强化训练和微调得来的,擅长做逻辑推理,常用于做科研分析,金融策略生成,编程开发等需要复杂逻辑推理的场景。
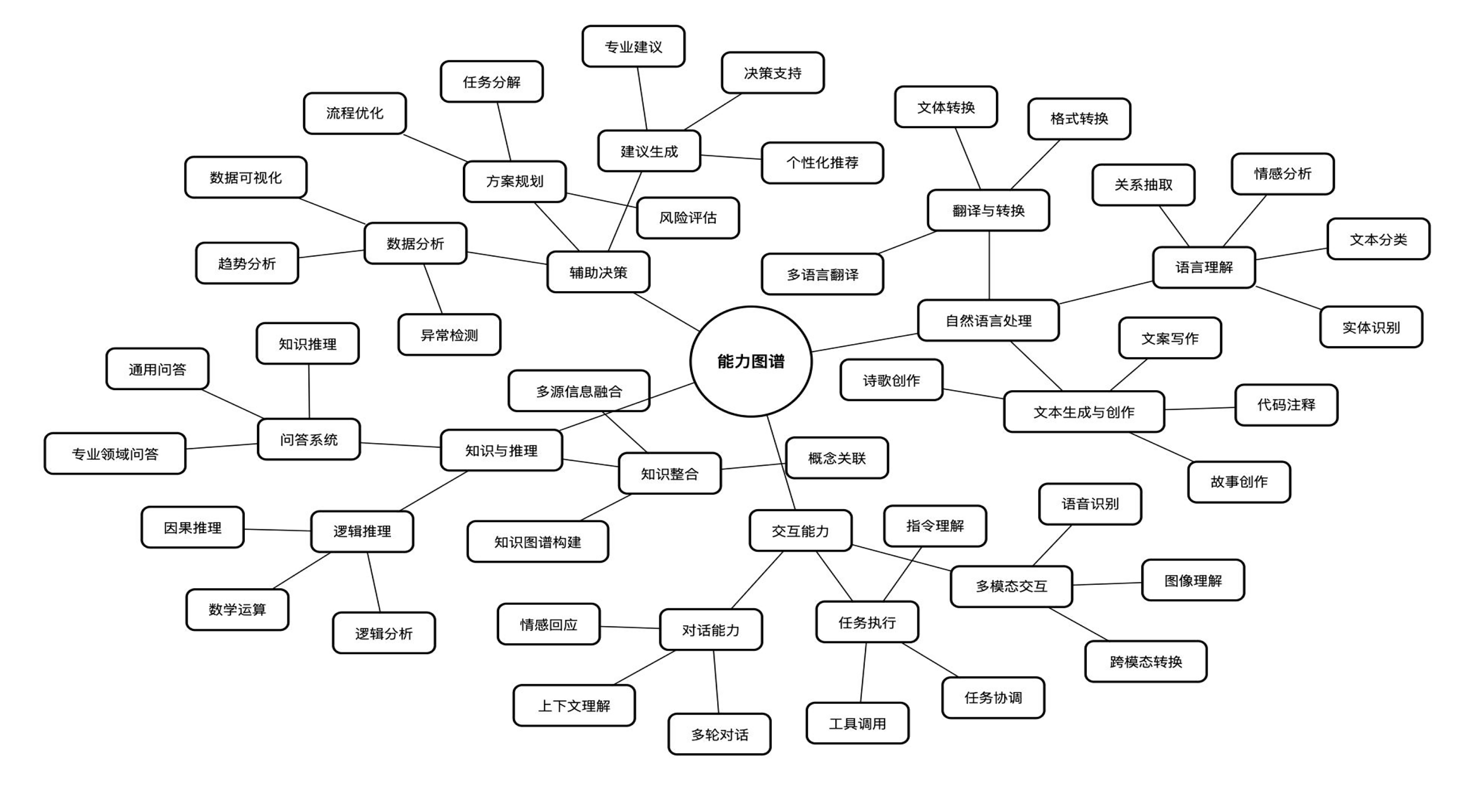
之前清华大学公开了一个 《DeepSeek 从入门到精通》的 PPT,其中有一页列出了 DeepSeek 的能力图谱,也就是下图,大家可以参考一下,并思考DeepSeek在自己熟悉的业务领域内,能做什么事情。
官方版本的模型还有另一个功能——联网搜索。这个功能就比较常见了,像是 Kimi、通义千问等也有这个功能。这个功能的实现其实就是通过提示词,让大模型调用浏览器 API 去搜索相应的内容,然后通过学习搜索到的内容,经过自己的思考和整合后,回复给用户。
因此,回复内容的质量,取决于调用的什么浏览器的 API,比如现在调用 Google 的 API 相对就比调用百度的更加强大。这个功能,我们自己也能做。我在我的上一门课《AI 重塑云原生应用开发实战》的 第 11 讲 讲过如何调用浏览器 API,感兴趣的同学可以看一下。
再使用过对话功能后,大家会发现,DeepSeek-R1 基本在第二轮提问时,就会出现如下回复。
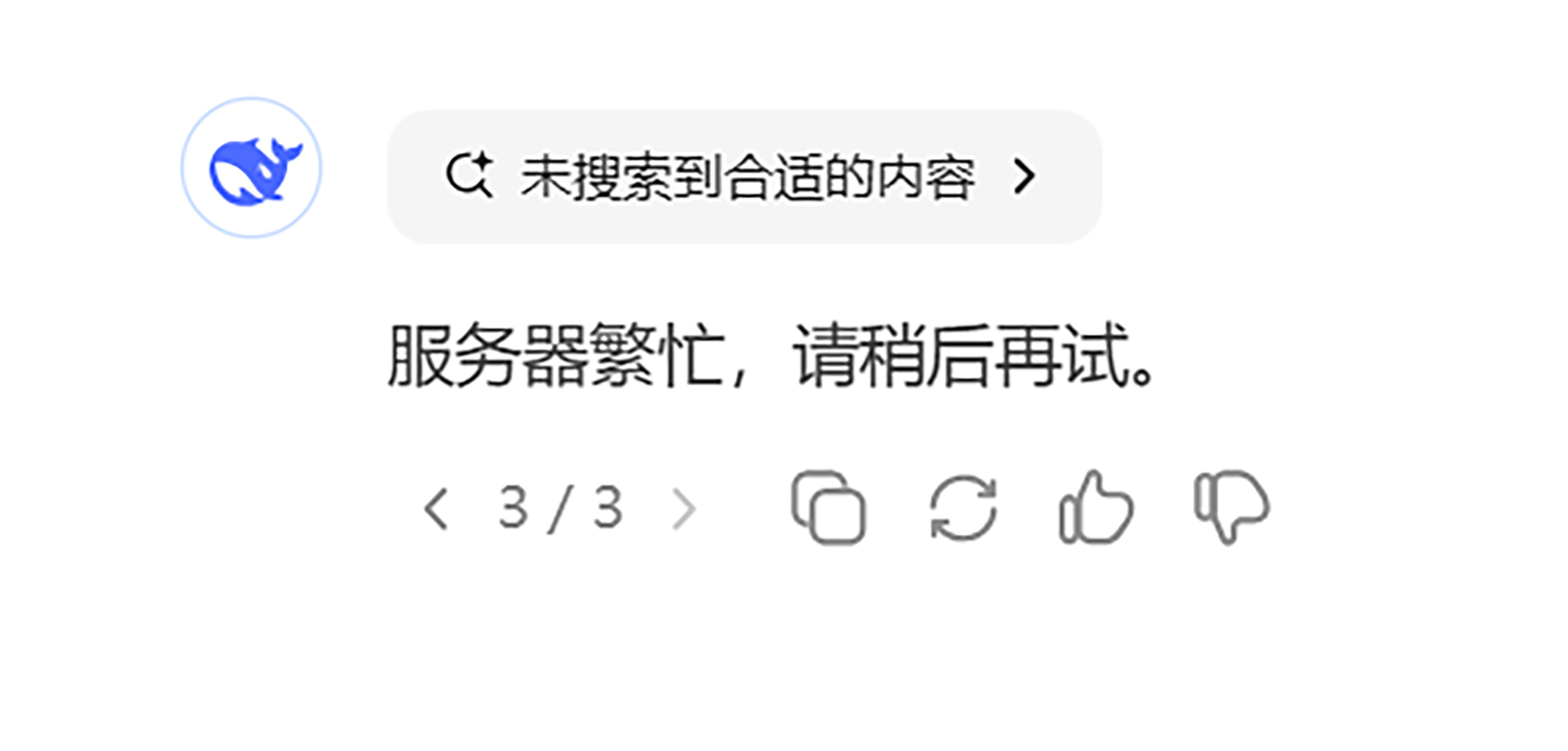
这是因为 DeepSeek 的突然爆火,导致访问的人数太多,官方的服务器算力不够了。包括 DeepSeek 的 开放平台,也就是我们用 DeepSeek 做应用,需要付费调用 DeepSeek 对话等功能的 API,现在也暂停充值,不让用了。这可是 DeepSeek 赚钱的业务啊。
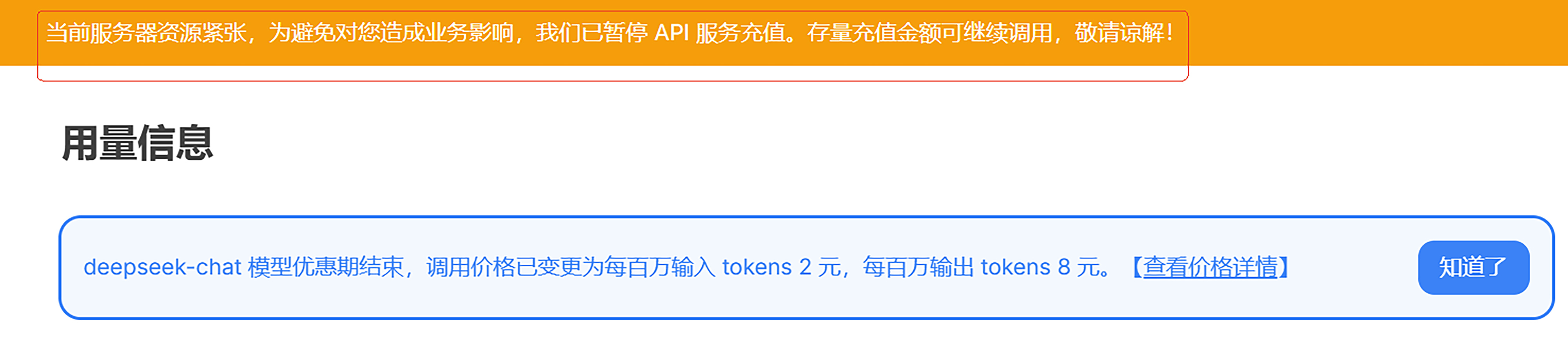
所以这也给各云厂商带来了商机,你没有显卡了,我有啊。于是以华为、阿里、腾讯、百度、讯飞等等为首的云厂商,都快速在自己的平台部署了 DeepSeek,开始卖 token,卖算力了。
虽然我们自己没钱买这么多显卡部署,但模型部署的方法我们得会,下一章我们就会详细了解云厂商部署模型的几种方案。这样今后,如果你的公司老板想要部署私有化大模型,你就可以站出来承接这个工作了。
解决问题的能力越强,你的价值就越大。不过有一点你不用担心,那就是我们后面几章节的项目实战,不会使用自己部署的模型,而是直接去阿里等厂商充值,来付费使用这些厂商的 API,降低大家的学习成本。
我们从前面的图片就能看到,DeepSeek 大模型很便宜啊,每百万token大概是2块钱。百万 token 什么概念呢?
每个大模型的计算公式不太一样,但通常是百万 token ≈ 75 万英文单词 ≈ 50万汉字。大家可以拿自己的平时做的项目,估算一下大概的代码量,就可以对百万 token 有一个直观的概念了。所以,如果我们的项目数据量不是特别庞大的话,几块钱就可以搞定。
学了 DeepSeek 以后能帮我们做什么
聊完怎么使用,我再分享一下学了 DeepSeek 以后都能帮我们做什么。
提升个人价值
程序员群体是终身学习的群体,因此我们要与时俱进,多多了解一些热门话题。特别是不懂技术的人都关心的一些话题,其背后的相关知识,我们就需要了解,以备不时之需。
现在讨论最多、最热的 DeepSeek 部署等方面的知识,我们掌握了就有利于我们解决更多的问题,提升自己的价值。比如有的公司从业务角度考虑,特别希望在公司内自己部署微调蒸馏 DeepSeek 模型;再比如做一些 RAG 对话之类的,70B 就足够的场景;而有的是为了向客户展示,彰显公司实力。毕竟现在 DeepSeek 完全开源,而且可以商用,谁都可以部署。
用 AI 改造现有业务
作为“民用级”程序员,我们日常的主要工作就是做应用、做业务。那 DeepSeek 或者说 AI 再结合 AI Agent(智能体)等技术,在这个过程中,就可以起到智能桥梁的作用。
比如我们做应用的都少不了运维这一环节。根据报错分析日志,事件,是我们解决问题的常用手段。但如果我们在这个环节中加入 AI,让 AI 根据报错,自动抓取日志,然后给出分析和问题定位,甚至自动去修复问题,整个过程,我们只需要说一句 “xx 报错了,请帮我分析一下原因”,达到运维全靠“喊”的效果,程序员就可以少加很多班了。
再比如说,我们研发的一些业务系统,由于我们懂业务,会觉得自己开发的前端已经非常友好了。但实际上,我们经常会遇到不懂业务的客户,点不明白我们的页面。如果我们的前端,能提供自然语言化的窗口,用户可以直接说“我想xxxx”,然后相关内容就以自然语言化的形式输出了,这样的效果就能让用户更为满意。
个人创业
最后,我们再谈谈个人创业的问题。个人创业其实只会技术是不够的,还需要懂业务,有资源(客户等)以及有一定的经济基础。
如果这几点恰好你都能满足,那 AI 就可以帮你做很多事情。比如,可以通过模型微调、精调等做出一个私有化模型,之后去做一些行业应用,比如 AI 医疗、AI 炒股等等,也可以去做一些工作流之类的应用,比如短视频转爆款小红书文案等等。有了AI的加持,不一定人人都能成为开发者,但善于借力AI新技术的朋友,肯定在抓住机遇方面更占优势。
如何学习 DeepSeek 与 AI 应用开发
讲到这,大家可能对于 DeepSeek,以及如何应用,或多或少有一些感觉了。所以,我们最后就来讲一下如何学习的问题。
首先,要先排除两个学习误区或者说思维模式。
第一就是作为普通人去研究 DeepSeek 底层的知识。
那在上面我介绍过 DeepSeek 模型的研发团队,都是一些我们只能仰望的大神,因此模型底层、模型原理这些事情,和普通人几乎没有任何关系。我们只需要利用好 AI,做好应用开发就足够了。
第二是用学习传统知识的思维模式,去学习 AI 开发。
我接触过很多同行,能力很强,也很有钻研精神。学东西喜欢系统学习,从头学习,不希望放过任何一个知识点。那在 AI 时代,这样的学习方式是不能跟上时代发展的,因为技术进步实在太快了,就像LangChain 社区几乎天天更新版本,几个周不用,再更新新版本时,可能接口就变了。
我们这门课程要用到 Python,可能有的同学会想着是不是去啃大部头的完整Python书籍或者课程学习。那等学完了,周围的同事可能都会 AI 了,那你的价值就发挥不出来了。
接下来就要说说推荐的做法了。
有句话叫知行合一,其实只有你能运用上的知识,才是真正的知识,不然只能算是存在你脑子里的信息,很难发挥多少价值。因此在AI时代,我更推荐你把学习重点放在学习思想、手法、应用方案上面。我们的课程设计也是如此,很多基础知识,包括LangGragh这样的框架,我们花一两节课就能有个大致了解。
之后就会通过实战演练来巩固,用于练手的项目是我精心设计的,我也把自己学习、实战、踩坑的经验都融在了里面。而且,我也不会从头开始讲大模型基础之类的。像是项目中的必备技术,Function Calling 和 Agent,在我们的课程中都属于一两节课搞定的前置课程,因为 AI 时代,时间真的很宝贵,咱们要把更多时间花在刀刃上。
如果你希望有更好的学习效果,我这里提供几条小建议。
第一,不要止步于简单使用 DeepSeek,而是领会不同模型、技术的特点,学会根据项目需求选择合适的模型。这样你才能举一反三,把课程所学应用到自己工作里。
第二,眼到之外还要“手到”,才能提升自己的实战能力。
第三,学习快速学习AI新知识的方法套路,这样面对不断涌现的新模型、新技术,你才能更从容地面对。
写在最后
如果你对中国传统文化感兴趣,你可能听说过“八运”、“九运”的说法。
2024年(不含)往前的 20 年属于艮八运,主土,因此房地产,建筑等行业在这 20 年很火。而 2024 年开始呢,就进入了离九运,主火,这 20 年 AI 等科技会大爆发。25 年的春节这一波热度已经看到了趋势,因此让我们沿着正确的道路,快速而有节奏地开始学习吧。
欢迎你在留言区和我交流互动。也欢迎你分享自己对于DeepSeek的学习有什么预期目标,有什么业务应用上的灵感。
- 完美坚持 👍(30) 💬(5)
作为银行科技条线的基层工作人员,给老师和大家提供一些需求端的信息。 除了想要去部署一些私有的大模型的接口,似乎更重要的是,如何找到一些切口,可以让大模型真的能够赋能具体的业务场景、工作场景,能不能提高工作的效率。 我这两天一直在找相关的课程,发现极客时间上面很多是讲技术原理和技术实现的,有的课程会有一些具体的案例,但是案例更多是服务于技术原理和技术实现的学习,案例本身可能没有那么强的实用性。 在得到AI学习圈的内容,更多是个人层面去做一些小工具,是toC的一些需求的开发。 B站上的内容非常新,更多是一些toC小工具的演示和实现方法初探。 我觉得我们这门课既然是要帮助我们提升自己为领导分忧解难的,在现有内容之外,可以多分享一下业界用deepseek、大模型的技术做了哪些有意思的toB应用,启发我们也可以做一些ai企业级应用的创新思路。 我看了老师的背景,想老师一定在这方面有很多可以分享的内容。 举个例子来讲,我是大数据相关的工作者,我们的领导就特别想看大模型能够在数据治理、数据资产沉淀、数据需求处理、基于数据分析的营销管理等方面有没有一些可以切入的可以赋能的点。 比如 业务提供了一个数据资产建设的需求,我们如何根据现有的数据资产,帮忙评估建设的必要性(是不是有已经可用的数据资产) 再比如,我们有很多的数据字段需要打上各种各样的标签,能不能利用大模型来帮助我们给数据打标。 比如,如何开发一个大模型,业务在提出一个数据需求的时候,可以帮助我们自动化地评估我们的数据湖里、成熟的数据资产有没有相应的数据源,数据的时效性怎么样,是不是能够满足业务的需求,基于此来做一个数据需求的预评估,以及用什么的方式满足业务的需求,扮演一个数据咨询顾问的角色 再比如,更近一步,能不能利用我们现有的数据资产,帮助我们直接去满足业务老师的一些数据需求,取出想要的数据并且做合适的整理,甚至是生成自己想要的图表, 希望邢老师能够多一些AI toB端领域应用的案例介绍。我想在我们学习完这门课有了实现的技术之后,多一些这样的应用开发的思路启发,是非常有意义的一件事情——因为AI是一定要用了才有学习的意义
2025-03-02 - Abner S. 👍(12) 💬(1)
最近几天一直在看各个课程,都是难懂的理论,头好大。看到老师举的例子去讲解蒸馏,豁然开朗。看了课程安排,真是是忍不住往下看。适合宝宝体质,可放心食用
2025-03-08 - AI悦创 👍(9) 💬(1)
我使用原生的部署Qwen时,和使用 ollam部署 qwen时,会出现:ollam生成的回复快于本地直接部署(很明显的对比)不知道是什么问题导致的?而且,我还是喜欢自主性强一些的,就是本地部署大模型,所以发现这个区别。清华大学的开源模型,我也发现会很忙,ollam是做了什么优化,还是去掉了某些东西?
2025-03-09 - 猿人谷 👍(8) 💬(1)
“写在最后”,这一段映衬了“ AI的尽头是玄学”😁。
2025-03-03 - 张申傲 👍(7) 💬(1)
个人觉得,在大模型时代,人与人之间通用技能的差距会被迅速拉齐,初级程序员借助AI,也同样可以写出不亚于资深程序员的代码。更有价值的反而是解决特定领域问题、快速推进方案落地的能力,比如垂直领域的私有数据如何获取、如何对数据进行建模和加工、如何结合特定场景进行性能评估等等,所以对业务的理解会是越来越重要的技能~
2025-03-04 - 非平凡零点 👍(3) 💬(1)
期待老师尽快更新~ 我是一个有多年经验的电商领域开发人员,但ai的使用是新手。目前需要对大量seo数据进行分析,得出广告投放和店铺、商品的优化建议, 想试试用ds解决,老师能否建议下相关的学习路径,参考资料?
2025-03-03 - Clement 👍(2) 💬(1)
其实就是垂直的业务场景怎样与ai技术融合的问题,这与马克思主义中国化的思想是异曲同工之妙,每个公司每个项目每个人的情况都不一样,不可能一一列举,只能先把底层逻辑理解清楚,这样才能更好地解决自己的问题。
2025-03-04 - 一路前行 👍(2) 💬(1)
作者是懂玄学的,这点必须点赞。另外上图中ai agent是不是应该属于大模型的一部分呢或者说是大模型agent的能力。
2025-03-04 - YueShi 👍(2) 💬(1)
落地,赚钱,干中学
2025-03-03 - 慎独明强 👍(2) 💬(1)
最近确实很火,在自己公司里也经常会提到这块。纯小白,跟着老师一起学习。
2025-03-03 - 方华Elton 👍(1) 💬(1)
2024 年(不含)往前的 20 年属于艮八运,主土,因此房地产,建筑等行业在这 20 年很火。而 2024 年开始呢,就进入了离九运,主火,这 20 年 AI 等科技会大爆发。25 年的春节这一波热度已经看到了趋势,因此让我们沿着正确的道路,快速而有节奏地开始学习吧。 有意思!
2025-03-24 - Geek_ca6a8b 👍(1) 💬(1)
老师您好!您说的抖音转爆款小红书的app叫什么方便透露吗?
2025-03-23 - Geek_326d74 👍(1) 💬(1)
老师的学识很高呀!非常喜欢!
2025-03-12 - 阙耀楚 👍(1) 💬(1)
老师,现在还只放了两讲内容吗?
2025-03-03 - scarlett🦌 👍(1) 💬(1)
真乃及时雨
2025-03-03