27 DALL E 3技术探秘(二):从unCLIP到缝合怪方案
你好,我是南柯。
上一讲,我们已经了解了DALL-E 3针对训练数据使用的策略,也就是重新生成图像描述。事实上,除了数据策略,相比DALL-E 2,DALL-E 3还在方法上大刀阔斧地做了很多改变。它放弃了unCLIP的模型设计思路,转而借鉴了Imagen、Stable Diffusion等模型的方案,成为了新一代“缝合怪”。
这一讲我们继续揭密DALL-E 3,深入探究它背后的技术方案。我们先从DALL-E 3的模型结构说起。
加入VAE结构
通过第13讲我们知道,DALL-E 2使用的是unCLIP结构。这个方法可以概括为用 CLIP 提取文本表征,通过一个扩散模型将文本表征转换为图像表征,然后通过另一个扩散模型指导图像的生成。
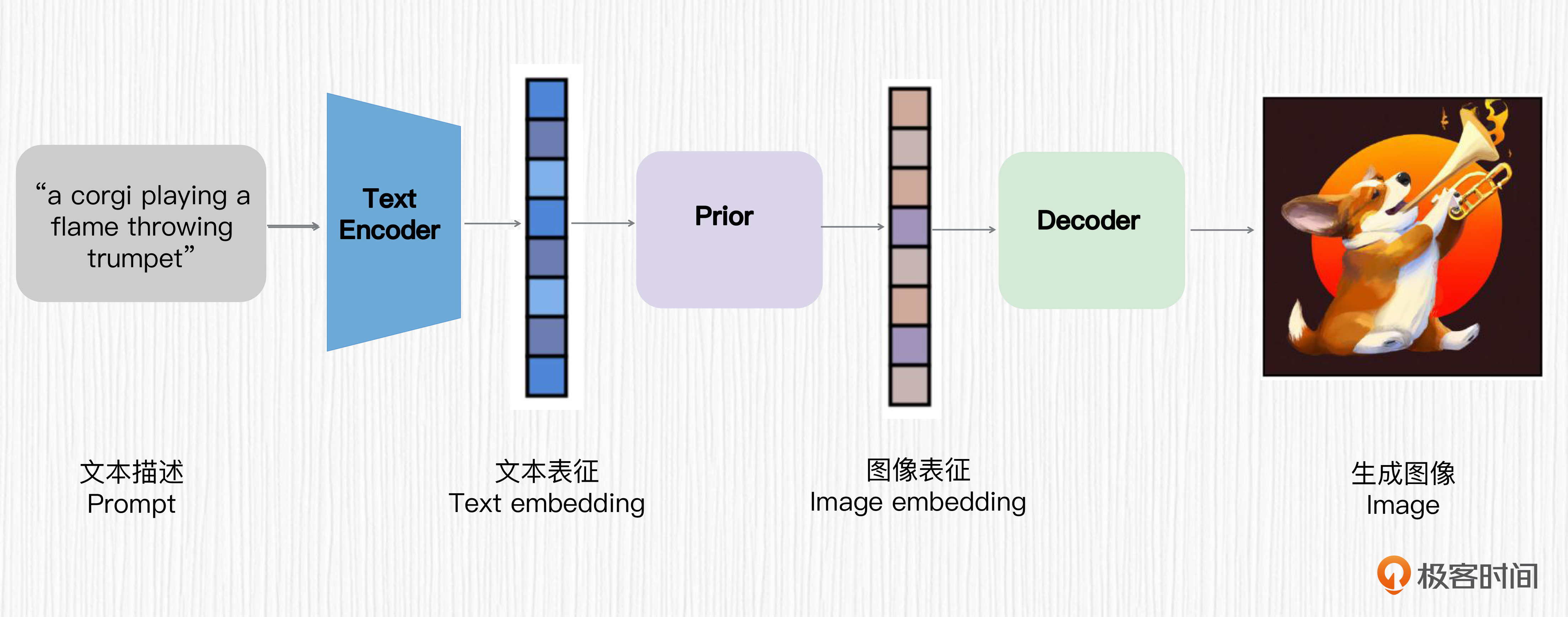
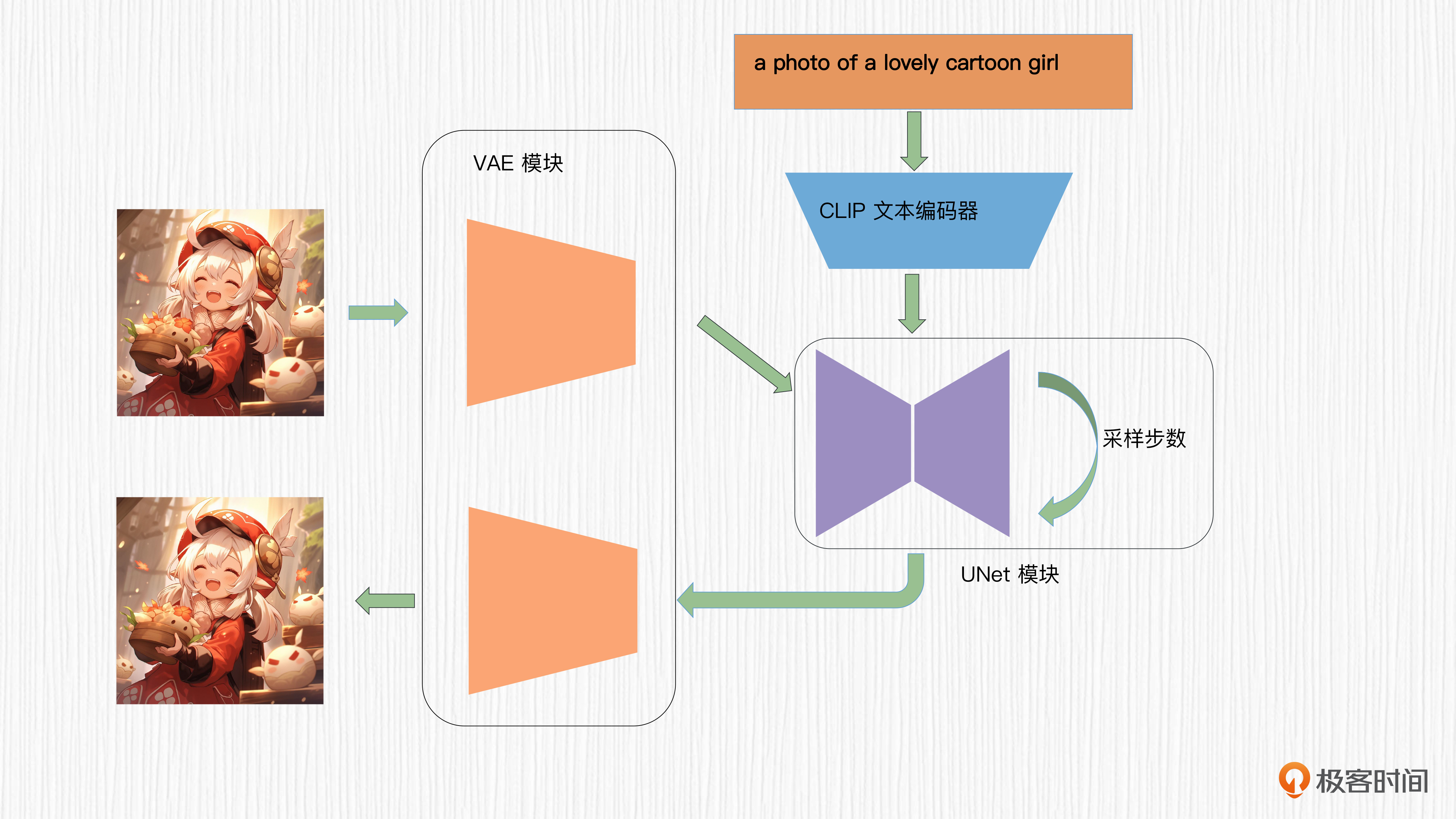
不过DALL-E 3没有采用这种结构,而是借鉴了Stable Diffusion的思路,引入了VAE模块,在潜在空间进行加噪和去噪。关于Stable Diffusion的算法原理,你可以回顾课程的第15讲。在DALL-E 3中,VAE的编码器对训练图像进行8倍下采样,提升了扩散模型的训练效率。
DALL-E 3生成图片的分辨率是不固定的,比如我们使用两个不同prompt生成图像,并没有指定生成图像的分辨率,得到的图像分辨率分别为1024x1024、1792 × 1024,你可以点开图片查看效果。

检查ChatGPT扩写后的prompt,我们也没有发现分辨率相关的信息。
左图原始prompt:山重水复疑无路,轻舟已过万重山 [说明:源自两首诗]
ChatGPT扩写prompt:Photo of a vast landscape with towering mountains that seem to endlessly stack upon each other, and deep waters that appear to have no end. Amidst this daunting scenery, a small boat has successfully navigated its way, signaling it has crossed countless mountains.
右图原始prompt:写着“Midjourney is scared”的标志板
ChatGPT扩写prompt:Illustration of a rectangular wooden board hanging by chains, with the words 'Midjourney is scared' painted in rustic white letters, surrounded by creeping ivy and set against a brick backdrop.
结合上述信息,我推测DALL-E 3训练时使用了不同分辨率的图像数据,比如512x512、892x512等分辨率,经过8倍降采样后得到潜在表示训练扩散模型。
之后,DALL-E 3也有可能采用类似DALL-E 2、Imagen等方案的扩散模型超分方法,进一步提高输出图像的分辨率。在生成图像时,根据用户输入的prompt,确定文生图任务的宽和高,类似于我们在WebUI中指定图像宽高的过程。
CLIP换T5
在DALL-E 3技术报告放出来之前,我曾经猜测它背后的文本编码器是某个比T5-XXL更强大的模型。
这样猜测的依据是,即使使用Imagen、DeepFloyd等模型,能在图像中写入的文字不超过3-4个,当我们要求更多文字时,生成的效果就会比较诡异。而当我测试DALL-E 3时,发现写入更多文字的任务它也能胜任。
比如下面两张图,是DALL-E 3和ideogram两个模型采用相同prompt的效果,对比之后就能看到DALL-E 3的生成效果要更好一些。
但论文中对于文本编码器的介绍否定了我的推测,OpenAI将DALL-E 2的CLIP文本编码器换成了Google的T5-XXL模型。
我们在第14讲学习Imagen的时候详细讨论过,T5-XXL模型是纯文本语料训练得到的模型,参数量共计110亿,是DALL-E 2用到的CLIP文本编码器的175倍。可以说T5-XXL文本编码器是现在所有能实现Text-in-Image能力的模型的首要选择,比如 Imagen、DeepFloyd 模型,我推测Imagen团队成员推出的 ideogram 模型用的也是T5-XXL。
值得一提的是,想要增强AI绘画模型的文本理解能力,除了使用T5-XXL模型这种策略,还有一种策略是组合使用多个CLIP模型。
表面上看是“三个臭皮匠,顶个诸葛亮”,实际效果上似乎差点意思。比如,我们熟悉的SDXL(第16讲)便是将多个CLIP模型提取的文本表征拼接起来,这样做虽然让AI绘画模型更听话一些,但仍旧不能胜任Text-in-Image的任务。你可以点开后面的图片,观察下这些经典模型的Text-in-Image能力。

问题来了:为什么同样是T5-XXL模型,用在DALL-E 3里就能呈现出更强的Text-in-Image能力呢?我推测答案仍旧是DSC数据本身包含了训练图片中的文字,数据质量的提升让DALL-E 3能更好地发挥T5-XXL的能力。
值得一提的是,T5模型提取的文本表征,并没有直接通过交叉注意力机制作用于UNet结构(这里建议回顾第15讲),而是通过一个xfnet的结构完成的。遗憾的是我并没有检索到xfnet相关信息,论文中也没有给出xfnet的参考论文,目前我推测它的作用是处理DSC语料文本较长的问题,从而提升交叉注意力机制的计算效率。
改进时间步编码
此外,DALL-E 3还升级了时间步编码的作用机制。我们首先回顾下Stable Diffusion中的UNet模型结构。以512x512分辨率的生成任务为例,经过VAE的8倍降采样编码后,潜在表示维度为64x64x4,然后使用降采样、上采样和跳跃连接,完成UNet预测噪声的过程。
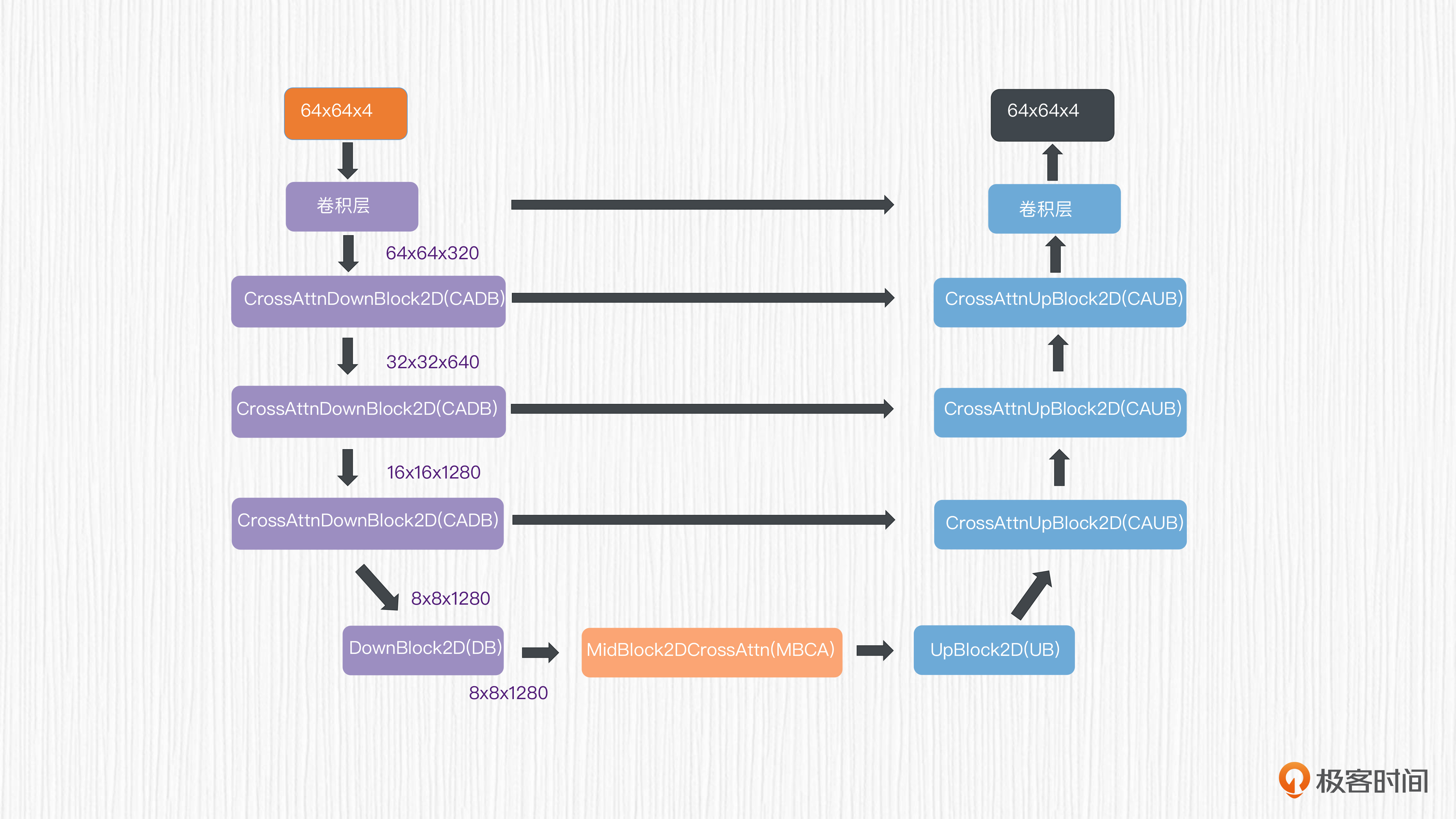
prompt文本表征和时间步编码作用于所有降采样和上采样模块。其中时间步编码作用于ResnetBlock模块,文本表征通过交叉注意力完成信息注入。

想要搞清楚DALL-E 3对于时间步编码的改进,我们还需要了解时间步编码作用于ResnetBlock模块的原理。下面这张图展示了常规文本表征注入形式和DALL-E 3改进后的注入形式。
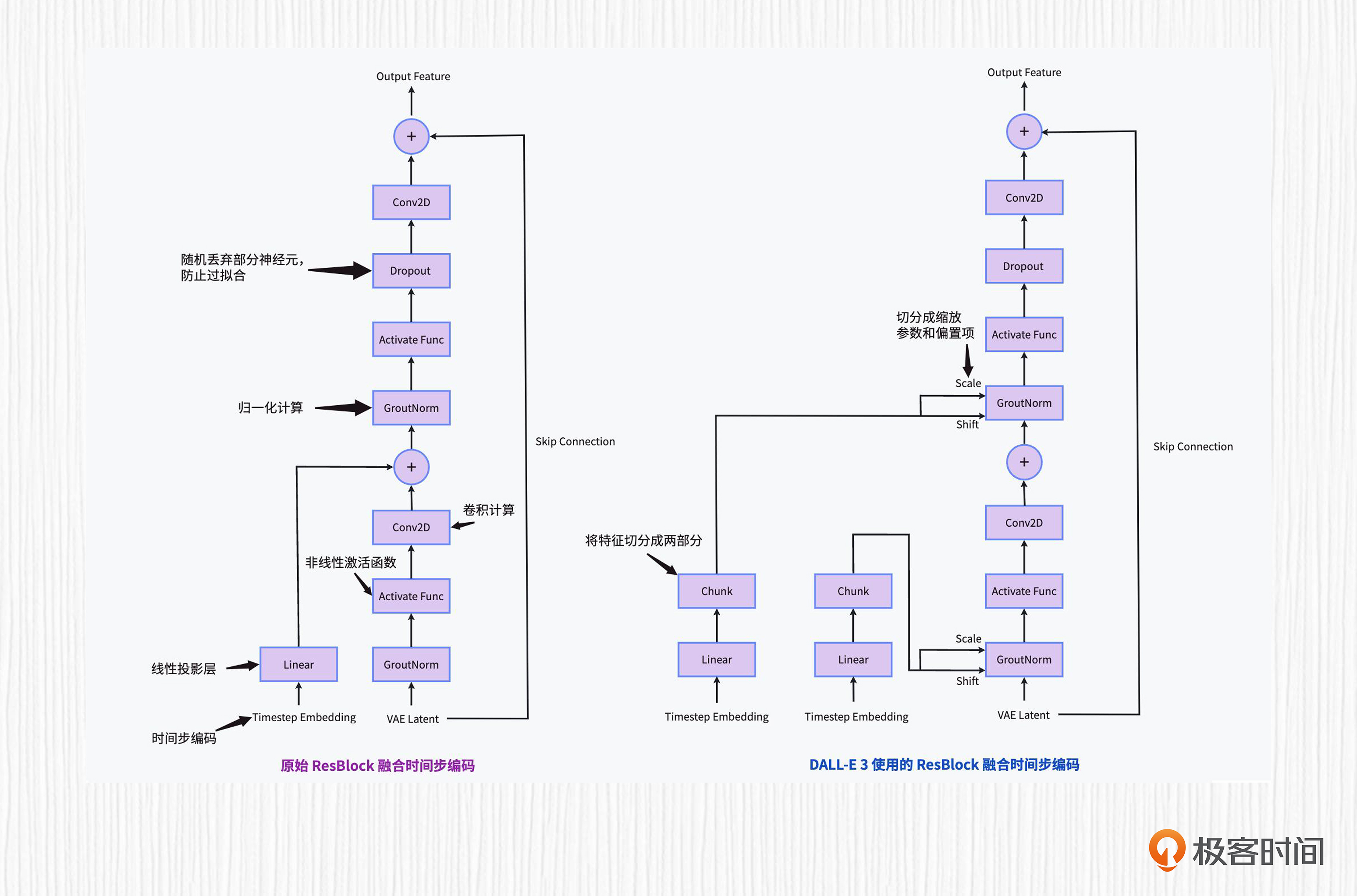
顺便说一句,这张图我画了一个小时,你头一次看可能觉得很复杂,但跟上我的思路一定可以看明白。我们这就来分析其中的细节。
先看图中的左半部分,可以发现,原始的时间步编码经过全连接投影(Dense)后,直接“加到”了图像特征上。
然后再观察图中的右半部分,我们可以发现在DALL-E 3中,时间步编码通过两个可学习的线性投影层(Linear),拆分(Chunk)成两块,分别得到缩放参数(Scale)和偏置项(Shift),作用于原始ResnetBlock模块的GroupNorm部分。简言之,不同时间步可以得到不同的缩放参数和偏置项,从而影响这一步的GroupNorm的计算。
这里我们顺路复习下四种常见的归一化(Norm)计算方法,对于图像任务来说,特征一般包含四个维度,分别是批次大小(Batch)、通道数(Channel)、特征宽度(Width)和特征高度(Height)。归一化的本质就是给特征在特定维度上减去均值再除以方差,这四种归一化在计算时,用于计算均值和方差的部分如图中蓝色区域所示。
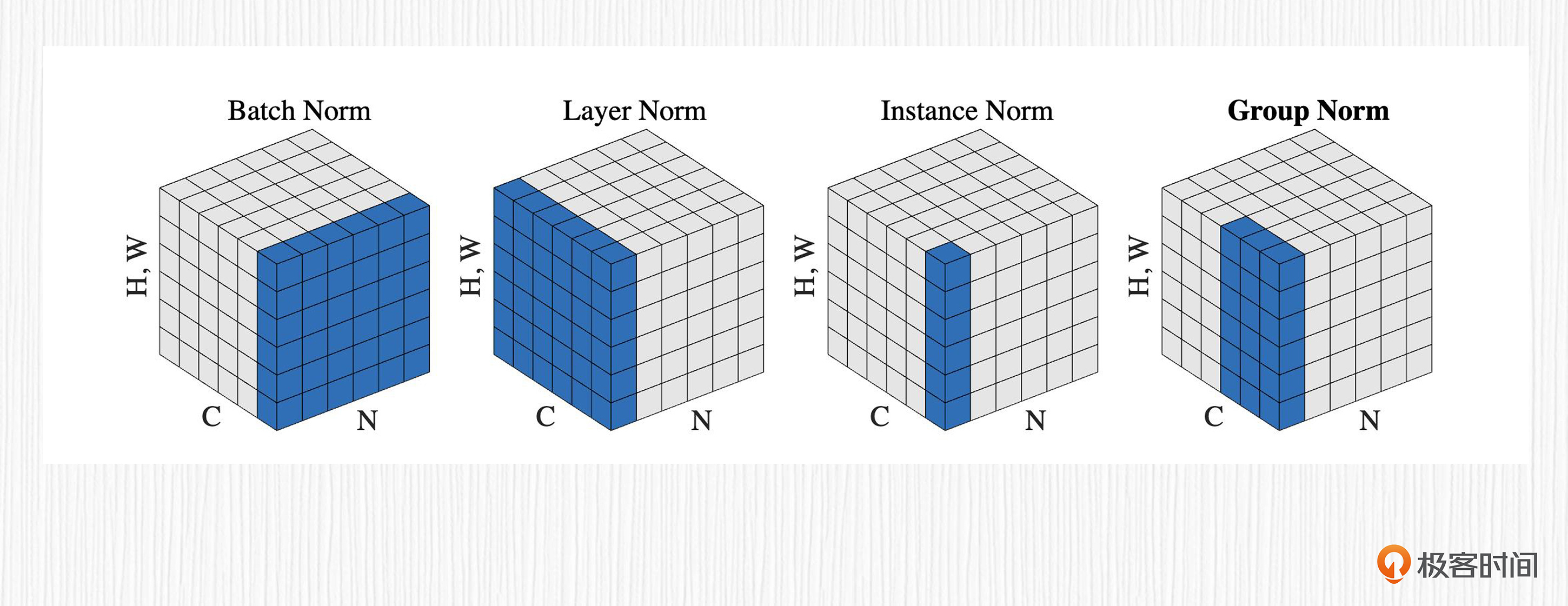
我们可以结合代码进一步理解这四种归一化计算方法,对比各自的计算方式我们会发现,这四种归一化最大的差别便是计算均值和方差的维度。
# x的形状应为 [batch_size, channels, height, width]
def custom_batchnorm2d(x, gamma, beta, epsilon=1e-5):
# 计算批量均值和方差
mean = torch.mean(x, dim=(0, 2, 3), keepdim=True)
var = torch.var(x, dim=(0, 2, 3), unbiased=False, keepdim=True)
# 归一化
x_normalized = (x - mean) / torch.sqrt(var + epsilon)
# 伸缩偏移变换
out = gamma * x_normalized + beta
return out
def custom_groupnorm(x, gamma, beta, num_groups, epsilon=1e-5):
N, C, H, W = x.size()
G = num_groups
# reshape the input tensor to shape: (N, G, C // G, H, W)
x_grouped = x.reshape(N, G, C // G, H, W)
# 计算组均值和方差
mean = torch.mean(x_grouped, dim=(2, 3, 4), keepdim=True)
var = torch.var(x_grouped, dim=(2, 3, 4), unbiased=False, keepdim=True)
# 归一化
x_grouped = (x_grouped - mean) / torch.sqrt(var + epsilon)
# 伸缩偏移变换
out = gamma * x_grouped + beta
# reshape back to the original input shape
out = out.reshape(N, C, H, W)
return out
def custom_layernorm2d(x, gamma, beta, epsilon=1e-5):
# 计算批量均值和方差
mean = torch.mean(x, dim=(1, 2, 3), keepdim=True)
var = torch.var(x, dim=(1, 2, 3), unbiased=False, keepdim=True)
# 归一化
x_normalized = (x - mean) / torch.sqrt(var + epsilon)
# 伸缩偏移变换
out = gamma * x_normalized + beta
return out
def custom_instancenorm2d(x, gamma, beta, epsilon=1e-5):
# 计算批量均值和方差
mean = torch.mean(x, dim=(2, 3), keepdim=True)
var = torch.var(x, dim=(2, 3), unbiased=False, keepdim=True)
# 归一化
x_normalized = (x - mean) / torch.sqrt(var + epsilon)
# 伸缩偏移变换
out = gamma * x_normalized + beta
return out
说完了归一化,我们再来看看DALL-E 3中使用的GroupNorm的实现方式。你可以通过阅读后面这几行代码,来了解这个过程。观察forward函数,我们可以看到,图像特征和时间步编码作为函数输入,缩放参数(代码中第45行的 “1+scale”,对应于前面代码片段中的 “gamma”)和偏置项(代码中第45行的 “shift”,对应于前面代码片段中的 “beta”)都是时间步编码经过线性投影获得的。
class AdaGroupNorm(nn.Module):
"""
GroupNorm layer modified to incorporate timestep embeddings.
"""
def __init__(
self, embedding_dim: int, out_dim: int, num_groups: int, act_fn: Optional[str] = None, eps: float = 1e-5
):
super().__init__()
self.num_groups = num_groups
self.eps = eps
if act_fn is None:
self.act = None
else:
self.act = get_activation(act_fn)
self.linear = nn.Linear(embedding_dim, out_dim * 2)
def forward(self, x, emb):
'''
x是输入latent
emb是时间步编码
'''
if self.act:
emb = self.act(emb)
# DALL-E 3中提到的
# "a learned scale and bias term that
# is dependent on the timestep signal
# is applied to the outputs of the
# GroupNorm layers"
# 对应就是下面这几行代码
emb = self.linear(emb)
emb = emb[:, :, None, None]
scale, shift = emb.chunk(2, dim=1)
# 需要说明,下面这行代码中没有传weight(gamma)和bias(beta)参数,此时
# F.group_norm只进行减均值+除方差操作,没有进行下面这一行的伸缩偏移变换:
# out = gamma * x_grouped + beta
x = F.group_norm(x, self.num_groups, eps=self.eps)
# 使用根据时间步编码计算得到的scale和shift完成group_norm的伸缩偏移变换:
x = x * (1 + scale) + shift
return x
关于这样做的好处,我说说个人理解。原始的GroupNorm中的缩放和偏移参数同样可学习,一旦UNet训练完成,对所有时间步t都是唯一确定的。通过时间步t来精细化调整GroupNorm的计算,不同时间步t得到的缩放和偏移不同,可以调控不同时间步t对应的GroupNorm数值范围,这有助于稳定扩散模型预测噪声、去除噪声的过程。
扩散模型解码器
在论文的最后,作者还提到一个有意思的技术细节,那就是引入了一个扩散模型解码器,放在完成UNet去噪后的潜在表示和VAE解码器之间。
这个解码器的结构也是一个扩散模型,训练过程和标准扩散模型相同,这个模型的输出通过VAE解码后便得到了DALL-E 3最终输出的图像。论文中使用了名为一致性模型(Consistency Model)的采样技巧,可以在两步内完成扩散模型解码器的采样。
一致性模型背后的数学推导非常复杂,这里我们可以不做细究。作者说通过新增加的扩散模型解码器,改善了Text-in-Image、脸部细节生成的效果。关于这个解码器,我也说说我的理解。
在第11讲我们了解过VAE的训练方式,VAE编码器会预测出一个用于解码器的潜在表示。试想一下,此时如果我们对潜在表示再加入一些数据干扰,破坏掉潜在表示的分布,解码后的图像效果就会大打折扣。
类似地,在Stable Diffusion中,解码器的输入是扩散模型去噪后获得的,因此我们无法保证扩散模型输出的潜在表示能“完美兼容”VAE解码器,文生图的效果可能会变差。
DALL-E 3的扩散模型解码器,更像是一个“分布调整器”,将扩散模型输出的潜在表示做一个微调,让它更合VAE解码器的“口味”。我的个人看法是,这里的重点不在于一致性模型,而是这种“修正数据分布”的设计思路。
局限性
尽管DALL-E 3在指令跟随方面取得了重要的进步,但它也存在自己的局限性。
首先,DALL-E 3不擅长处理关于定位和空间相关的prompt。比如,使用“在……的左边”“在……的下面”“在…….的背后”等prompt生成的效果经常翻车,对应后面图片中前两个例子。究其原因是因为用于训练的DSC语料在描述对象位置方面并不可靠。正所谓“成也数据、败也数据”。
其次,DALL-E 3对于一些特殊的prompt会翻车,例如生成某个特定品种的植物或者鸟类。后面的第三张图,DALL-E 3没有成功生成一朵名为“腐肉花”的植物。出现这个问题同样是由于DSC语料在描述特定品种时不可靠导致的。

再次,DALL-E 3相比于其他AI绘画模型已经算是很擅长在图中写文字了,但作者认为表现还不够好。我们的测试也佐证了这一点。
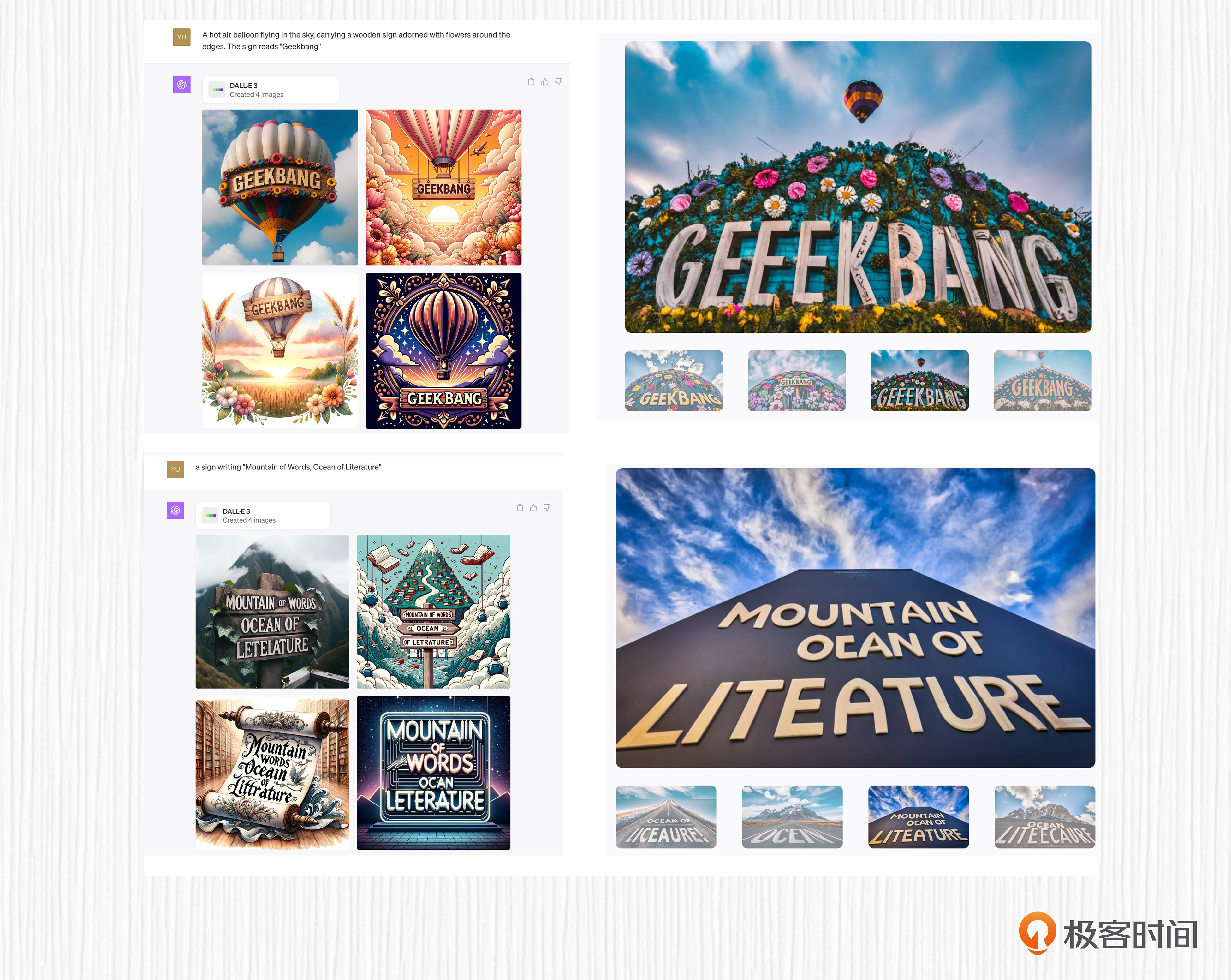
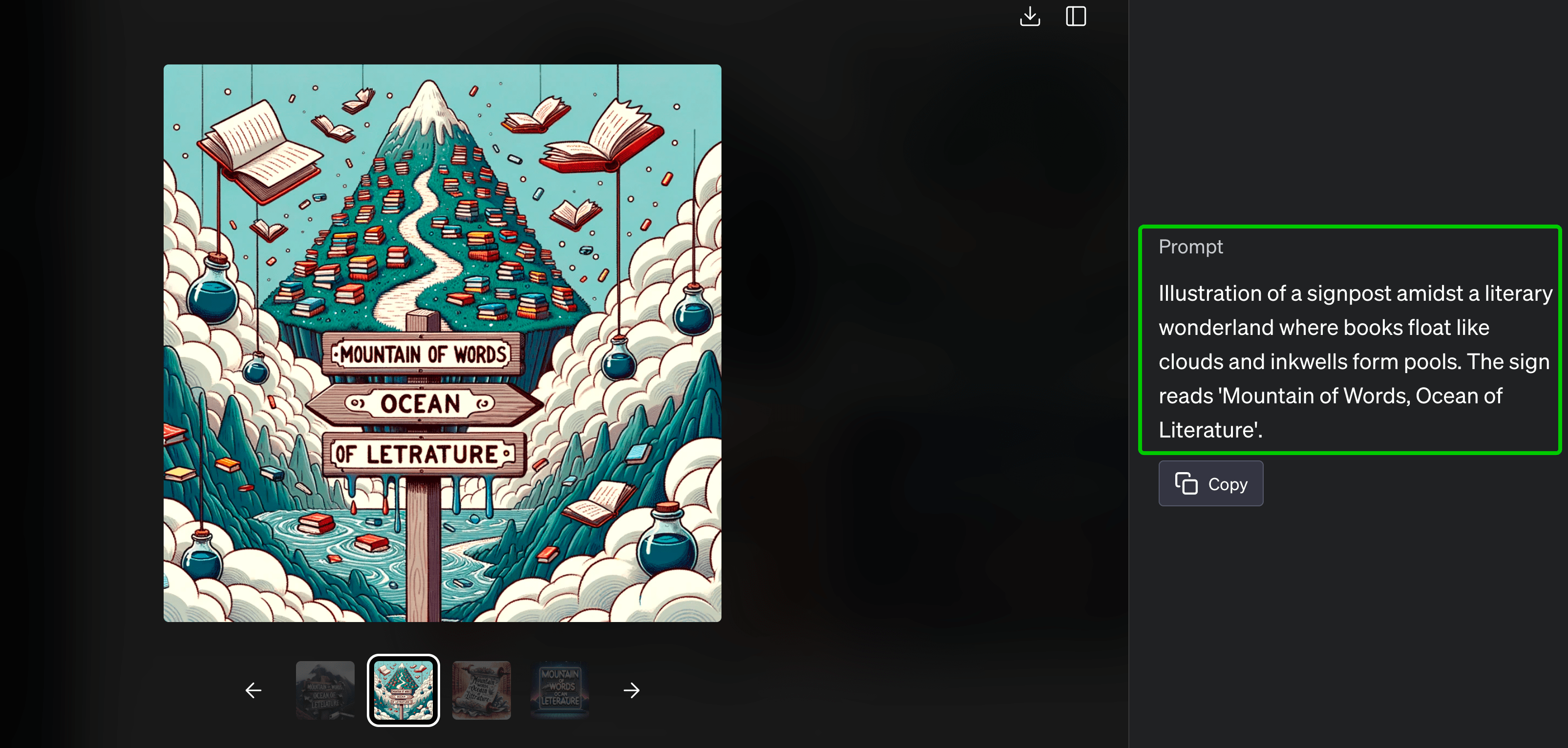
比如下面这张DALL-E 3生成的“文山会海(Mountain of words, ocean of literature)”的例子,“literature” 这个单词的模型就没有准确写入到图片中。作者指出这是因为T5模型对句子进行分词造成的,未来会探索文字级别(character-level)的文本编码模型。
此外,放弃了原有的unCLIP结构转而采用Stable Diffusion这类方案,使得DALL-E 3丧失了DALL-E 2的图像变体功能,也算是一点小小的遗憾。
总结时刻
这两讲我们追了一把热点,详细讨论了刚刚放出的DALL-E 3这个最新AI绘画模型,包括它的生成效果、技术方案和算法局限性。
在生成效果上,DALL-E 3尤其擅长处理复杂指令下的图像生成,并且它的Text-in-Image能力也是时下最强。
在技术方案上,DALL-E 3的重点放在了优化训练数据上,使用预训练+微调的方式得到了一个专门的图像描述生成模型,并使用该模型重新生成了训练数据的caption。
同时,DALL-E 3放弃了上一代的unCLIP方案,转而引入VAE结构,使用类似Stable Diffusion的方案。它还提出几个有意思的技术细节,比如引入T5-XXL模型、使用带时间步的GroupNorm方案、训练单独的扩散模型解码器等。
关于算法局限性,DALL-E 3在空间相关生成任务、特定动植物种类、图中写文字等方面偶有翻车,并且失去了图像变体的能力。
不过总的来说,DALL-E 3仍然在文生图任务上表现出众,相比于Midjourney也毫不逊色,为后来者提供了诸多启发。简言之,高质量图片、精细化文本、强大的文本编码器,三者缺一不可,共同决定AI绘画模型的最终效果。
思考题
假如你是国内某大厂的技术负责人,想要训练出效果对标Midjourney v5.2、DALL-E 3的AI绘画模型,可以从DALL-E 3的论文中得到哪些启发?
期待你在留言区里和我交流互动,如果你觉得这一讲对你有启发,也推荐你分享给身边更多的朋友。
- Toni 👍(0) 💬(1)
大语言模型现在本质上还是“语言接龙”或“语言填空”。这个“本领”是通过学习海量数据得来的,学习的并非是真正的“语意”,而是词与词之间的“习惯用法”,学会的是自然语言应用中的某种概率统计分布,通俗地讲就是学会了“大家都怎么说”。 这种学习过程特别适合训练英法德这样的拼音文字大语言模型。 中文和其它语言一样也有“大家都这么说”的统计规律,但做为象形文字的杰出代表,她还有一个特殊性,其表现在具有固定的偏旁部首,这些偏旁部首具有明显的分类特征,比如将与金属有关的东西都用带金属旁的字来表达,等等,自带特别容易识别的归类特征。 处理中文大语言模型时如果通过卷积运算提取文字特征,即偏旁部首,间架结构,进而学习到单词的真正语意。用一篇文章来解释一个字的语料还是很丰富的,用这样的语料训练模型更像是在训练模型理解字义。中文核心词汇,具有独立语意的有2000-4000字(大概估的),掌握这些知识的中文大语言模型一定更具优势,遣词造句出的文章水平会更高。 南柯老师: 有什么模型在做这样的事吗?
2023-11-14 - Toni 👍(1) 💬(0)
目前领衔的AI绘画模型 Midjourny5.2, SDXL1.0, DALL-E3 各有各的优势,这一现象本身就表明无论哪个模型都有巨大的发展空间。AI模型的好坏主要取决于三大要素,1. 优秀的基础大语言模型,2. 优质的训练素材,3. 与任务匹配的合适算法和经过反复调优的超参数。这与人类的学习过程类似,1. 广博的知识和经验的积累,2. 读优秀经典的著作,3. 正确的学习方法和有效的知识图谱建立。 DALL-E3 依托优质大语言模型的"理解能力",不满足于现有训练资料的品质,提出质疑并力图改进,在模型训练过程中尝试不同的超参量并发现问题直至给出最优解,令人印象深刻。模型改进的背后是大量的试错,调制,经验模型的必由之路。敬佩所有付出努力的尝试。
2023-11-12 - 进化论 👍(1) 💬(0)
先点赞,在观看
2023-11-09