26 DALL E 3技术探秘(一):用OpenAI的方式搞数据
你好,我是南柯。
时隔一年半,在2023年9月OpenAI “悄悄”发布了DALL-E 3这个AI绘画模型。相比Midjourney V5.2、SDXL等时下最强模型,DALL-E 3在长文本文生图、图中写入文字(也就是我们常说的Text-in-Image)等方面优势非常明显。
就在这个月(10月份),OpenAI相继放出了DALL-E 3的安全审核方案和技术方案。它背后所用的技术方案也终于公之于众,刷新了算法工程师对于AI绘画模型的理解。接下来的两讲内容,我们就一起探秘DALL-E 3,带你搞清楚它的技术方案、局限性以及发展趋势。
在我看来,DALL-E 3有两方面的探索最值得我们关注。一个是如何用生成数据来训练模型,另一个是如何将各种AI绘画模型训练技巧有机地组合起来。这节课,我会先为你分享DALL-E 3的使用体验,然后结合论文为你深入解读DALL-E 3如何用OpenAI的方式生成数据。
这两年,技术圈围绕能否使用生成数据训练大模型的话题一直争论不休。使用BLIP这类模型为图像生成的描述,无论是用于训练文生图模型,还是训练类似GPT-4 Vision这样的图文问答模型,都没有带来显著的收益。如今DALL-E 3的成功无疑证实了生成数据用于模型训练的可行性,也将引领下一波用生成数据优化AI绘画模型的趋势。
因此,了解了OpenAI的数据构造思路,不仅能给微调Stable Diffusion模型带来新思路,也能帮你提前预判下一步国内各文生图团队的模型升级方案。
初识DALL-E 3
如果你现在想要体验DALL-E 3,有两种推荐做法。第一种是使用 NewBing 的 AI 聊天功能,比如我们要求DALL-E 3为我们画一幅画,描述一块写着 “GeekBang” 的标志板。你可以点开图片查看生成效果。
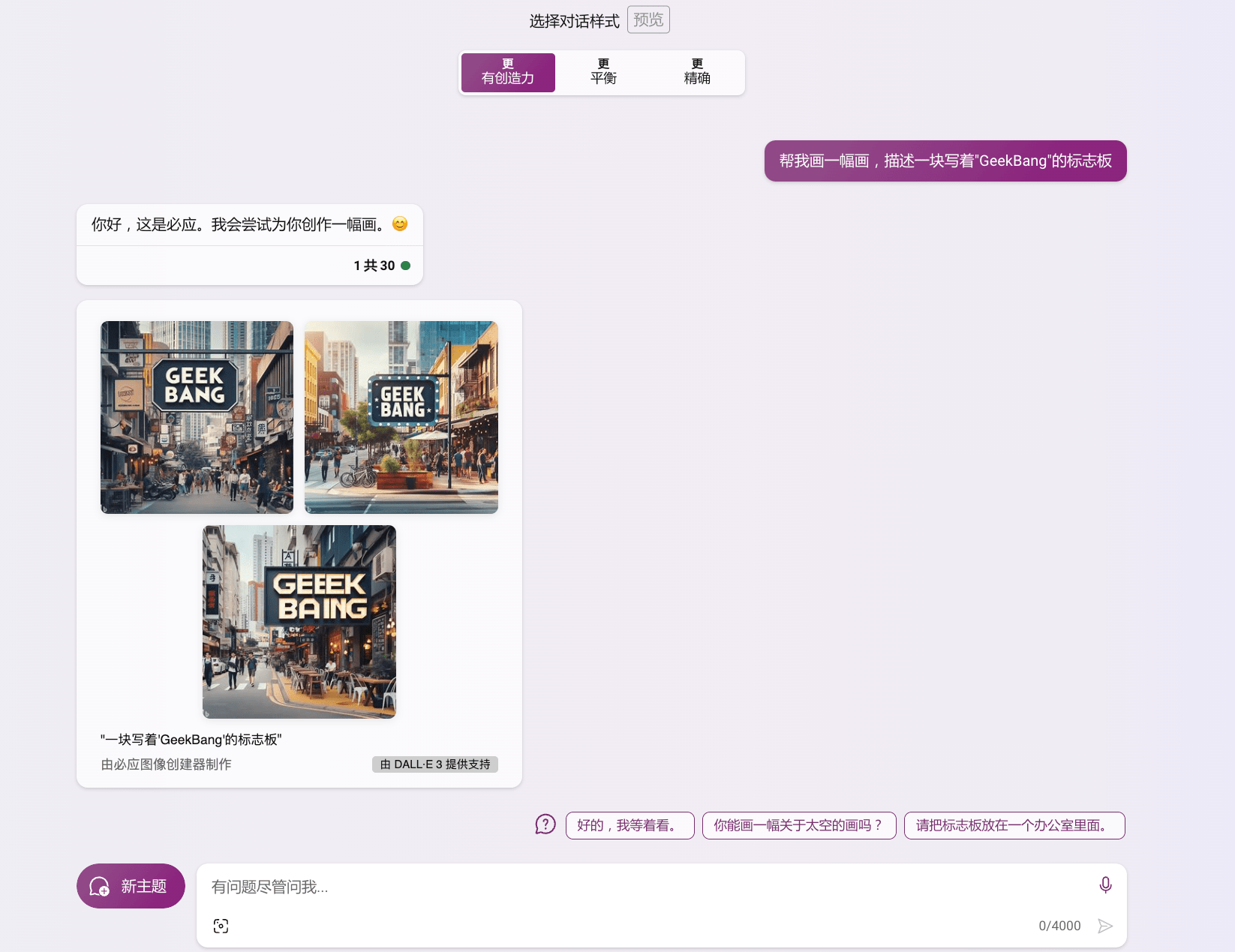
点开生成图像看细节,我们会发现生成的图像效果一般,甚至图中的人脸都是糊掉的。这是怎么回事呢?别急,我们接着往下看。

第二种体验DALL-E 3的方法是使用ChatGPT的DALL-E 3功能,这种方案需要开通ChatGPT的plus会员,对于普通用户来说,有一定的运气会命中DALL-E 3的内测。如果想通过这种方式体验,可以设法购买已经命中内测的DALL-E 3账号。
还是沿用前面的测试案例,这次我们在ChatGPT上进行AI绘画。你可以点开图片查看我们生成的效果。

可以发现,ChatGPT和NewBing同样使用DALL-E 3,生成的效果完全不同。
我个人认为造成这种差异的可能原因有两个:第一,NewBing背后使用的DALL-E 3可能是某个“阉割版”,效果不如ChatGPT提供的完整版;第二,ChatGPT会针对我们提供的prompt,做一个详细扩展,将扩展后的prompt提供给DALL-E 3生成图像,DALL-E 3对于经过ChatGPT扩展后的prompt更友好。
你可以点开图片,查看ChatGPT对于我们提供的prompt作出的拓展(图片右侧的文字)。
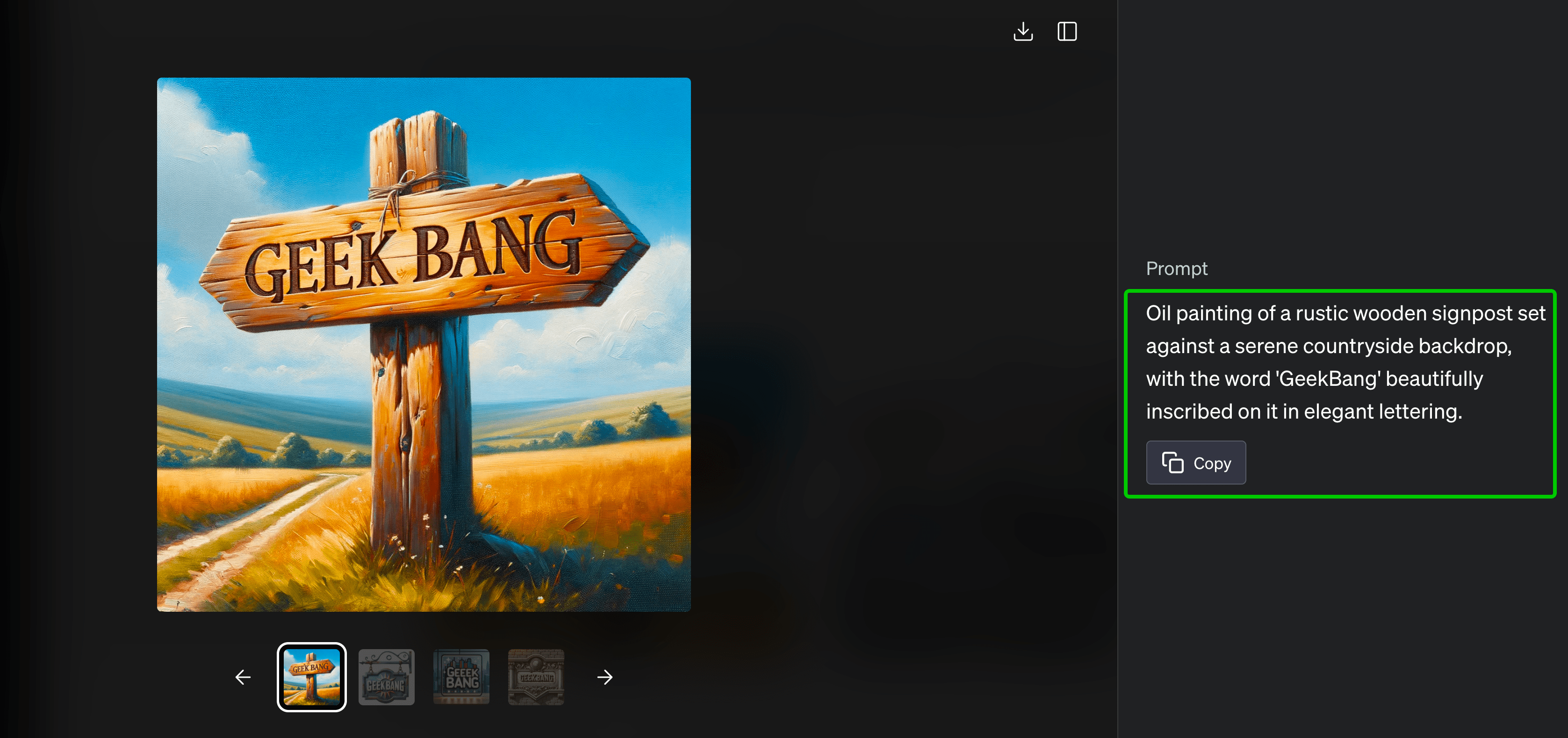
动手体验完,我们再来看看OpenAI提供的文生图效果。通过分析这些图像,我们可以得出一个初步结论:配合ChatGPT的prompt增强能力,DALL-E 3模型尤其擅长Text-in-Image任务、长文本图像生成任务。熟悉Midjourney、SDXL等模型的同学应该更容易感受到DALL-E 3带来的能力提升。


总的来说,DALL-E 3能力的提升主要源自更好的数据策略,同时丢弃掉DALL-E 2所采用的unCLIP结构,选择在Stable Diffusion方案的基础上做出定制化改进。现在我们就来看看数据背后的“黑魔法”。
基础概念介绍
在正式开始前,我先简单解释一下我们接下来会用到的术语——caption、Alt Text、prompt和图像描述,有图像描述生成基础的同学可以快速浏览。
对于模型训练而言,使用的数据为图文成对数据,其中的文本部分我们称为 caption,也就是图像标题。从互联网爬取的成对图文数据,其中的caption最常用的是 Alt Text(或“alternate text”“alternative text”)。Alt Text是一个HTML属性,它提供了对图片内容的文本描述。比如后面代码片段中展示的样子。
Google这类搜索引擎在展示搜索到的图片时,通常会显示与图片相关的描述信息,比如下面图像中柯基犬的例子。

训练CLIP模型使用的就是互联网上的这些图像文本数据,其中的文本部分多数情况下就是图像的Alt Text。
为什么说多数情况呢?是因为部分图像没有Alt Text,这时候搜索引擎需要根据网页中图片周围的文本内容,或者由机器学习模型提供的图像分析信息等,为图像生成描述信息。在DALL-E 3论文中,基线方案使用的就是Alt Text作为训练数据的caption。
认真观察上面图片中的图像caption,我们会发现图文一致性并不是很理想,比如第一张图看不出“柯基犬的优缺点”。此时,我们可以使用BLIP等模型为图像生成caption,这个过程称为图像描述。
当完成AI绘画模型的训练,用户便可以提供文本描述完成文生图任务,这里的文本描述我们更习惯称为prompt。
搞定了这些稍显复杂的概念,我们便可以进一步了解OpenAI的技巧了。
数据集重新描述
在数据维度,DALL-E 3重新描述了用于训练的图像数据,也就是丢弃掉图片的Alt Text,用专门的模型生成更准确的caption。作者将这个技术称为 Dataset Recaptioning。
互联网图文数据存在图文一致性差的问题,通过前面柯基犬的例子我们已经有了初步认识。
我们熟悉的Stable Diffusion模型是使用互联网数据训练得到的,尽管Stable Diffusion模型不停迭代,但从下面的图中可以看出,最初Stable Diffusion的迭代主要围绕丰富图像的美学质量展开(直白一点说就是让图像更美观)。
所以,虽然Stable Diffusion模型文生图的效果在不断提升,但是我们在使用Stable Diffusion时,还是会经常遇到生成图像很难准确遵循prompt内容的情况,也就是模型“不够听话”。

DALL-E 3的作者认为“不听话”的问题主要是由于训练数据造成的,具体来说,原始数据至少存在后面这四个问题。
第一,caption通常只关注图像主体部分而忽略细节,比如厨房中的水槽、人行道的标志牌。
第二,caption中对于图像物体的位置信息、数量信息常常会给出不准确的描述。
第三,caption中对于图像物体的颜色、大小等常识性知识会有缺失。
第四,caption通常不会描述图像中展示的文字内容。
如果caption内容更完整,训练出来的AI绘画模型能否更听话?正是基于这样的考量,DALL-E 3使用了 Dataset Recaptioning 策略,也就是丢弃掉图片的Alt Text,用专门的模型生成更准确的caption。
那具体要用什么模型生成图片描述呢?在DALL-E 3之前最常用的做法是使用 BLIP、DeepDanbooru 这些模型。用过这些模型的同学会发现,BLIP生成的caption像是一个模子刻出来的,通常就一句话。而DeepDanbooru这类模型生成的prompt通常是一系列标签,所以使用这类模型时,我们需要使用 “1girl” 这类奇奇怪怪的prompt。

既然常用的模型不能生成理想的caption,DALL-E 3便重新训练了描述生成模型。训练过程分为预训练和模型微调两个阶段。
在预训练阶段,使用CLIP图像编码器提取的图像特征作为输入,使用源自互联网的原始caption作为目标输出,通过自回归的方式进行caption生成,也就是每次预测下一个token。
你可以点开后面的图像深入了解。图中的图像编码器(Image Encoder)是一个预训练的CLIP模型,单模态文本解码器(Unimodal Text Decoder)可以提取文本特征,用于和图像特征计算相似度。然后,图像编码器输出的特征会通过交叉注意力机制(第7讲)的形式作用于多模态文本解码器,为图像生成描述。
因此整个训练过程有两个损失函数:CLIP对比学习损失(Contrastive Loss)和描述预测的损失(Captioning Loss)。

由于用于训练的目标描述存在前面提到的四个问题,预训练模型为图像生成的prompt同样存在这四个问题。
正因如此,作者提出需要对预训练模型进行第二阶段的微调。预训练模型的目的是使用大量数据让模型具备基本的图像理解能力,微调的目的则是通过少部分数据让模型输出信息丰富的caption,这点我想提醒你注意区分一下。
在模型微调阶段,作者使用两种不同的caption语料得到两个描述生成模型,问题的关键还是如何构造高质量的训练语料。
第一个模型使用的语料仅包含图像主体内容描述,第二个模型使用的语料则包括内容翔实的图像内容描述,包括文字信息、颜色细节等。训练过程和预训练阶段相同,两个微调模型生成的caption分别被称为SSC(短合成语料,short synthetic captions)和DSC(详细合成语料,descriptive synthetic captions)。
你可以点开图片查看原始caption(Alt Text)、SSC语料和DSC语料,需要说明,图片中展示的是用于训练模型的caption,而非模型生成的结果。

虽然论文中没有说明这两份训练语料是如何获得的,我们还是可以大胆猜测,这两份训练语料是由GPT-4 Vision模型生成的。
我们不妨通过ChatGPT模拟一下这个过程。首先上传一张图片(示例截图自原始论文,你也可以选自己手里的图片测试),然后我们要求GPT帮我们生成两份训练语料,对应DALL-E 3论文中的SSC和DSC语料。你可以点开下面的图片查看数据生成效果,对比DALL-E 3论文给出的样例,是不是有点相似?


生成数据有效性
完成了对图片数据的重新描述,下一步就是验证生成数据的有效性,需要通过实验回答下面两个问题。
第一,使用生成数据是否会影响AI绘画模型的最终表现。
第二,生成数据和真实数据的最佳混合比例是多少。
针对第一个问题,作者设计了三个实验,分别使用真实数据、SSC数据和DSC数据训练文生图任务,分别用50000条未参与训练的真实prompt、DSC prompt进行文生图测试。
针对测试的prompt和生成的图像,使用我们第10讲学过的CLIP模型计算图文一致性。具体来说,就是用CLIP的图像编码器提取图像特征,文本编码器提取文本特征,然后计算它们归一化之后的余弦相似度,用1减去余弦相似度便是余弦距离。余弦距离越小,表示图像和文本的一致性越强,也就代表了AI绘画模型“更听话”。
关于余弦距离的计算,你可以参考后面这段代码来理解。
import numpy as np
def cosine_distance(a, b):
dot_product = np.dot(a, b)
norm_a = np.linalg.norm(a)
norm_b = np.linalg.norm(b)
cosine_similarity = dot_product / (norm_a * norm_b)
# 由于精度问题,有时候cosine_similarity可能略大于1,所以进行一下clip操作
cosine_similarity = np.clip(cosine_similarity, -1.0, 1.0)
cosine_distance = 1.0 - cosine_similarity
return cosine_distance
# 使用示例
a = np.array([1,2,3])
b = np.array([4,5,6])
print(cosine_distance(a, b))
后面这组图中,左图是使用50000真实caption数据测试的结果,右图是使用50000 DSC数据测试的结果,图像的y轴代表的是余弦相似度。可以看出,在实验里,使用DSC数据做文生图训练,测试时图文一致性表现更好。
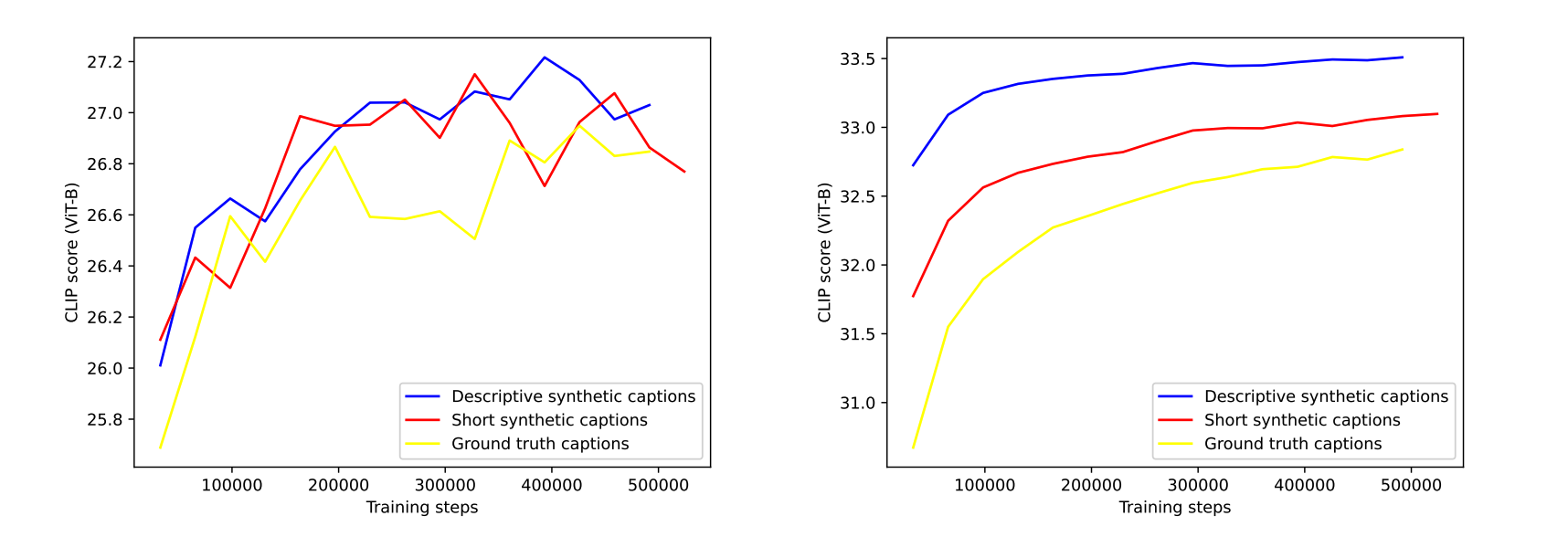
至于为什么没有使用SSC数据做测试,作者在论文中的说法是SSC数据测试的表现和真实caption数据非常接近,所以就没有把结果贴出来。
数据混合策略
既然生成数据比真实数据更优质,那我们自然会想到这样一个问题——在训练的时候能否只使用生成数据?答案是不能。
这是因为如果只使用生成数据,模型很容易过拟合到某个我们不知道的范式上,比如首字母大小写、prompt必须以句号结尾等,这些范式与使用的描述生成模型息息相关。在这种情况下,用户自己写prompt进行AI绘画的时候,由于不满足训练数据的范式,文生图的效果就会大打折扣。
针对这个问题,DALL-E 3给出了两个有趣的解决思路。
第一个解决思路很简单,既然互联网图片的文本信息多数都是人工撰写的,那就让模型既学习合成数据,也学习真实数据,即使真实数据质量不高。那混合比例怎么确定呢?
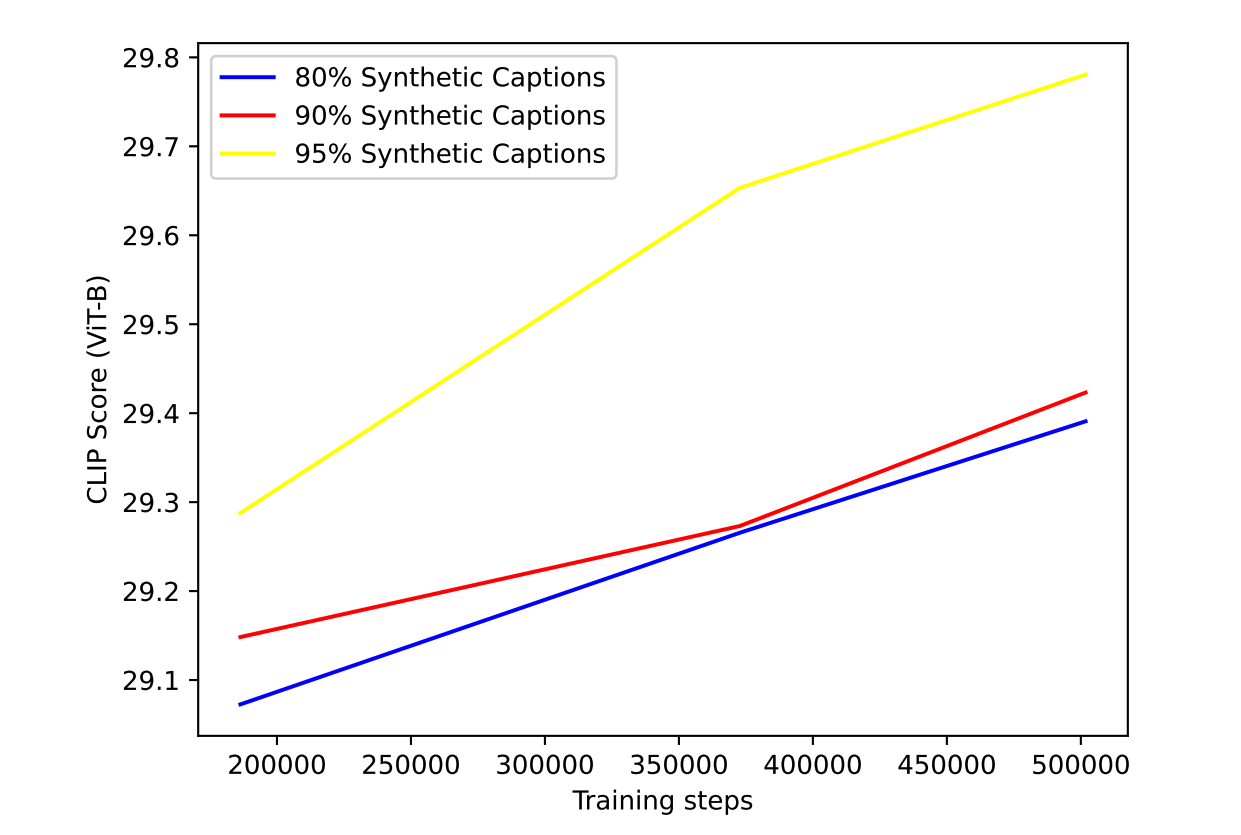
论文中设计了多组DSC数据和真实数据的混合实验,DSC数据占比为65%、80%、90%、95%等,仍旧使用CLIP特征的余弦相似度评估图文一致性。
后面的图片就是实验结果,可以看到,DSC数据占比95%训练得到的模型效果最好。DALL-E 3的模型便是使用这个数据配比训练得到的。
第二个解决思路是使用ChatGPT对用户输入的prompt进行“扩写”,论文中称为 “upsample”。后面图片中第一行是原始prompt及其文生图效果,第二行是扩写后的prompt及其文生图效果。
可以看到,扩写后的prompt不仅包含了更多细节信息,而且能够帮助模型处理复杂的逻辑关系。比如第二列图“披萨大小”的硬币,使用原始prompt没有生成出要求的硬币大小,而使用扩写后的prompt生成的图像则符合我们的要求。

我个人认为,大概率DSC、SSC的训练数据就是用ChatGPT生成的,所以使用ChatGPT对用户提供的prompt扩写,也是为了让DALL-E 3的输入prompt更加贴近训练数据范式,避免模型出现“翻车”的现象。
总结时刻
今天我们探讨了DALL-E 3惊艳效果背后的关键技巧:为图像数据重新生成描述。DALL-E 3不仅证明了更高质量的文本描述可以训练出更“听话”的模型,也成功论证了使用合成数据训练多模态大模型是可行的。
关于描述生成模型的训练,DALL-E 3采用两阶段的训练模式,第一阶段使用原始图文数据进行预训练,第二阶段使用高质量描述文本进行模型微调,最终得到一个优于BLIP、DeepDanbooru这类方案的描述模型,重新对文生图训练数据进行描述生成。
在使用DALL-E 3模型进行文生图时,同样会利用ChatGPT对用户输入的prompt进行扩写,这是为了提升文生图的算法效果。
对于Midjourney这类产品来说,遵循DALL-E 3的数据构造范式,可能是提升AI绘画模型的下一步举措。
思考题
我想请你思考这样一个问题:既然OpenAI能用自家的GPT-4 Vision输入图片生成DSC和SSC语料,为什么不直接用GPT-4 Vision为所有训练数据生成描述,而是舍近求远,微调一个单独的描述生成模型呢?
期待你在留言区里和我交流互动,如果你觉得这一讲对你有启发,也推荐你分享给身边更多的朋友。
- 沐瑞Lynn 👍(0) 💬(1)
极客时间能不能把更新的通知发一下,很多人估计都还不知道有更新吧
2023-11-03 - zhihai.tu 👍(0) 💬(1)
太棒啦,期待下一讲
2023-11-03 - 静心 👍(0) 💬(1)
分析的很巧妙,感谢加餐
2023-11-02 - 我听着呢 👍(0) 💬(1)
前排打卡,终于等到了更新
2023-11-02 - Grace 👍(0) 💬(0)
没有用GPT 4 Vison训练所有的数据,是因为GPT 4 Vison,太!贵!啦!
2024-02-01