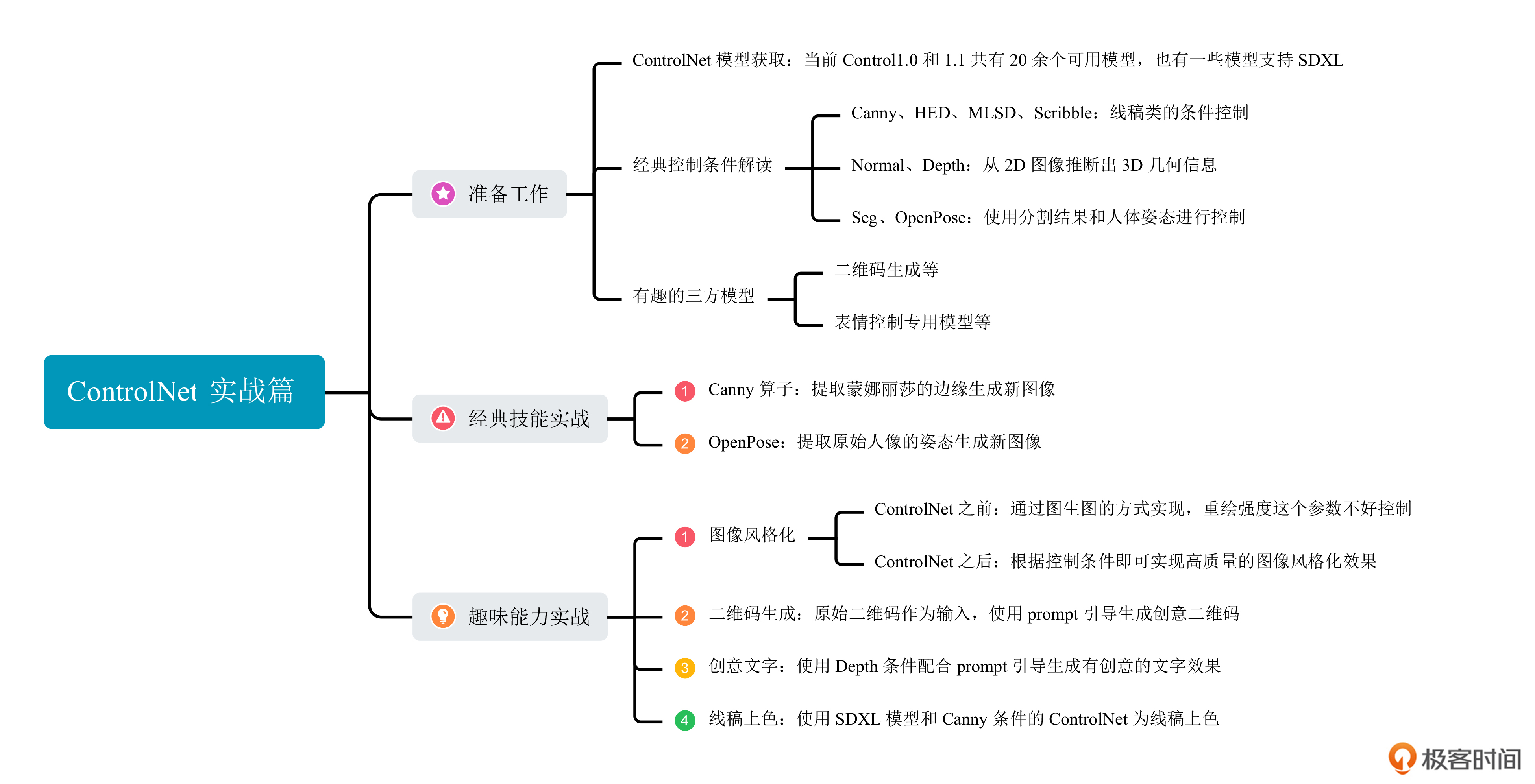
21 实战项目(四):用ControlNet给你的创意上色
你好,我是南柯。
上一讲我们已经学习了ControlNet的算法原理,也了解了它在AI绘画中强大的控制能力。今天我们一起来完成ControlNet的实战任务。
在这一讲中,我们将通过写代码的方式使用ControlNet,一起完成后面这三个任务。
- 认识官方已经发布的ControlNet模型以及社区传播的第三方ControlNet模型。
- 实现ControlNet论文中的控图生成任务,掌握ControlNet的基础能力。
- 探索ControlNet的趣味生成功能,包括图像风格化、二维码生成、创意文字和线稿上色。
掌握了这些技巧,你也一定能够发挥创意,做出很多结构鲜明的作品。让我们开始吧!
模型获取
在Hugging Face上,我们不光可以获取到海量AI绘画基础模型,还能找到各种开发者训练的ControlNet模型。正式使用之前,我们先来认识下这些模型。
官方发布的模型
首先是ControlNet论文作者在ControlNet1.0和1.1中发布的22个模型。
ControlNet1.0的8个模型可以通过后面这个 Hugging Face链接获取。我们可以看到ControlNet1.0各个模型的命名规则,以第一行的 “control_sd15_canny.pth” 为例,sd15表示用于训练这个ControlNet的基础模型是SD1.5,Canny便是ControlNet的控制条件是Canny算子,也就是提取原始图像的边缘。
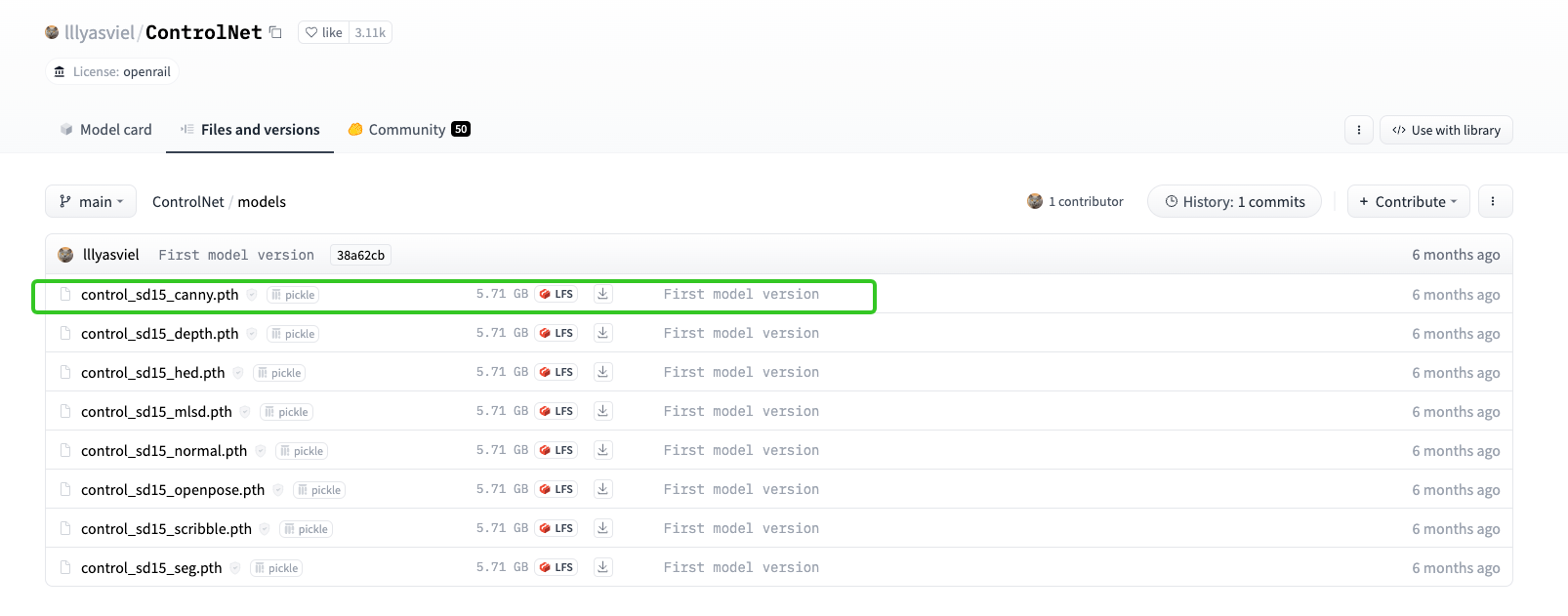
关于前面图中的八个控制条件,我们依次认识下。
首先来看Canny条件,它使用图像处理的Canny算子来提取图像的边缘信息,可以用于通用物体的可控生成。

接下来是HED条件。如果说前面提到的Canny算子是一种经典的、“上古的”边缘检测算法,HED则是一种基于深度学习方案的“现代化”边缘检测算法。HED条件可以看成Canny条件的升级版,适用于更复杂场景的精细化边缘提取。

下一个是MLSD条件,它使用 M-LSD算法 提取图像的直线轮廓,可以用于各种建筑图像和室内装饰场景的可控生成。


接下来要说的是Scribble条件,能根据我们的随手涂鸦生成图像。这也是我个人最喜欢的控制条件,简单几笔就能生成出丰富的细节。

下一个是Normal条件,Normal代表图像的法线,也就是与图像中物体表面切平面垂直的向量,通常用红、绿、蓝三个通道来表示法线向量在X、Y和Z方向的分量。从后面这个例子可以看出,Normal条件能够帮我们从2D图像中推断出3D几何信息,用于ControlNet的图像生成任务上。

接着是Depth条件。图像的Depth指的是图像的深度信息,可以理解为图像中每个像素距离我们的远近。和Normal条件一样,Depth条件也是包含3D信息的控制条件。

接下来是OpenPose条件,它的思路是使用人体关键点算法提取肢体关键点,使用关键点的连线图作为控制条件。OpenPose条件经常用在通过ControlNet做换装的任务上。

最后一个模型是Seg条件,作用是使用图像分割算法对原图进行分割处理,将分割的结果用作控制条件。
说完了ControlNet1.0的8个模型,我们再来看看ControlNet1.1的14个模型。这些模型可以通过后面的 Hugging Face链接获取。除了1.0中的8个控制条件,1.1中新增了指令级修图、Tile功能等能力,这些知识我们在上一讲中已经学过了。
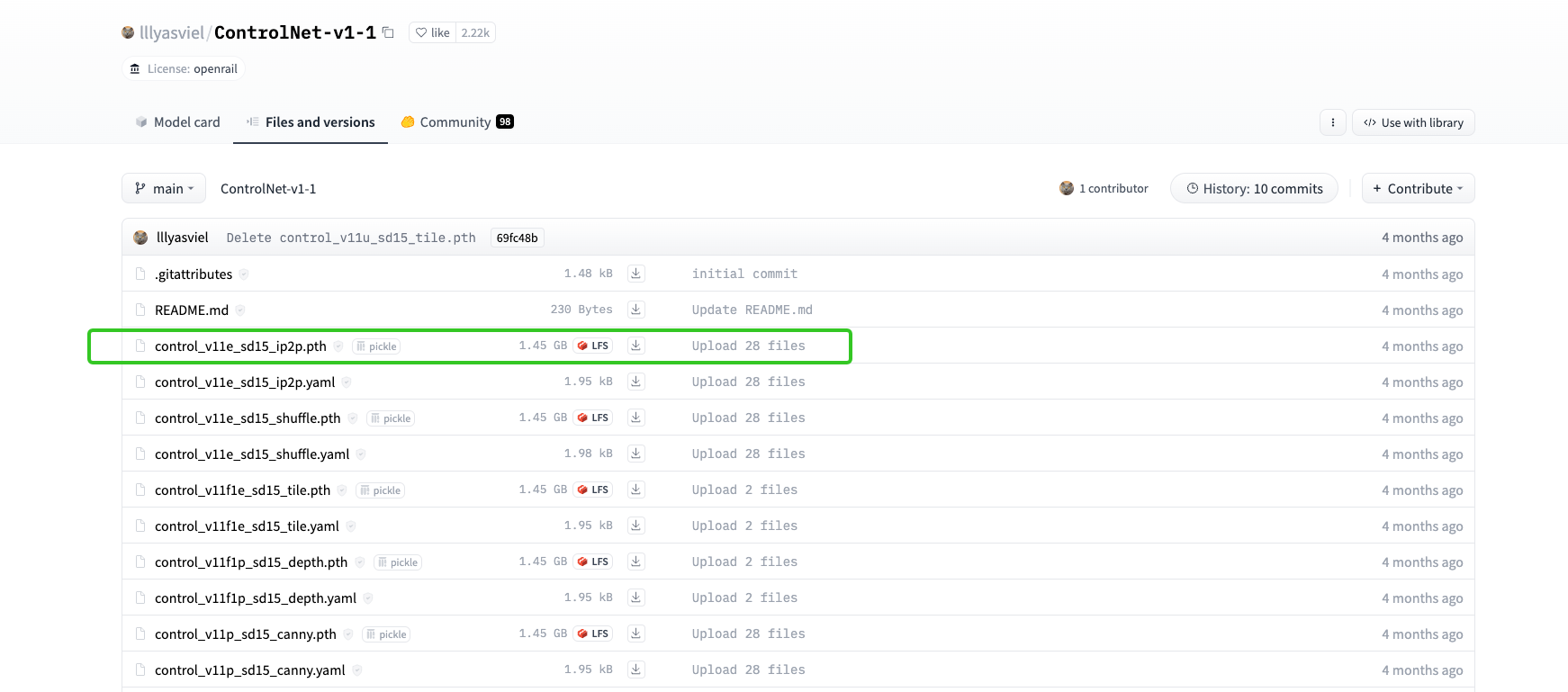
ControlNet 1.1模型的命名做出了规范,避免和1.0版产生混淆。
具体来说,可以看后面这张图,模型名称中的四个部分分别代表项目名、模型版本号、基础模型、控制方式。在模型版本号部分,你需要关注质量标签部分p、e、u三个字母的不同含义。p表示正式版(product-ready),e表示测试版(experimental),u表示未完成版(unfinished)。有时候我们还会看到f这个质量标签,它表示修复版(fixed)。

值得一提的是,随着SDXL的大火,有很多针对SDXL训练的ControlNet模型也逐渐流行。稍后的代码实战中,我们就会用到基于SDXL的ControlNet模型。
有趣的第三方模型
除了上面的官方模型,开源社区中也涌现了很多有意思的模型。
Civitai社区中的 QR Code Monster 模型可以用于生成创意二维码。具体来说,我们使用Canny或者HED等边缘检测算法提取原始二维码的边缘,用作ControlNet的控制条件,然后写一个prompt进行创意二维码的生成。

Hugging Face中实现类似二维码功能的模型还有很多,比如我们稍后实战用的 qr-pattern-v2 模型,可以先感受下它的二维码效果。

另一个要推荐的ControlNet模型专门用于控制表情生成。通过提取人脸的关键点信息,并把这些信息用作控制条件,配合prompt就可以生成各种有意思的效果。

你可以点开这个链接,获取更多开源社区的ControlNet模型。
经典技能
了解了如何获取模型,现在我们可以使用这些模型完成AI绘画任务了。你可以点开我的 Colab链接,和我一起感受ControlNet的各种趣味技能。
我们使用蒙娜丽莎作为输入图片,使用ControlNet的Canny控制条件进行AI绘画。
# 导入需要使用的库
import cv2 # OpenCV库,用于图像处理
from PIL import Image # PIL库中的Image模块,用于图像读取和处理
import numpy as np # NumPy库,用于数组和矩阵等的运算
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_image
# 使用蒙娜丽莎的图片用作原始图片提取Canny轮廓。你也可以替换为你自己的图片链接;或者上传本地图片到Colab。
image = load_image(
"https://ice.frostsky.com/2023/08/26/2c809fbfcb030dd8a97af3759f37ee29.png"
)
# 转化图像为NumPy类型的数组(矩阵),方便后续操作
image = np.array(image)
# 设置Canny边缘检测算法的低阈值和高阈值
low_threshold = 100
high_threshold = 200
# 使用Canny算法进行边缘检测。图像中灰度超过阈值的点,OpenCV会标记为边缘点
image = cv2.Canny(image, low_threshold, high_threshold)
# 因为Canny边缘检测后的输出是二维的,所以在第三维增加一个维度,以便转化为RGB图像
image = image[:, :, None]
# 将单通道图像复制三次,生成三通道(RGB)图像
image = np.concatenate([image, image, image], axis=2)
# 使用PIL库中的Image模块, 将NumPy的array类型转化为Image类型,方便后续图像保存与显示等操作
Canny_image = Image.fromarray(image)

然后依次加载SDXL模型和Canny控制条件对应的ControlNet模型。
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-Canny-sdxl-1.0-small",
torch_dtype=torch.float16
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
vae=vae,
torch_dtype=torch.float16,
)
之后,我们就可以使用蒙娜丽莎的Canny边缘轮廓,通过prompt引导模型生成不同的人像效果。你可以修改代码中的prompt描述,生成更多趣味效果。
# 可以替换你的prompt
prompt = ["a photo of a girl, best quality, super photorealistic"]*2
generator = torch.manual_seed(1024)
# 使用ControlNet完成AI绘画
controlnet_conditioning_scale = 0.6
images = pipe(
prompt, num_inference_steps=50, negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * len(prompt),
image=Canny_image, controlnet_conditioning_scale=controlnet_conditioning_scale, generator=generator
).images
image_grid(images, 1, 2)

体验完Canny控制的强大,现在我们再来动手完成基于OpenPose条件的ControlNet绘画过程。想要使用OpenPose控制,我们首先需要提取原始图片的肢体关键点,代码是后面这样。
from controlnet_aux import OpenPoseDetector
from PIL import Image
# 加载OpenPose提取模型
model = OpenPoseDetector.from_pretrained("lllyasviel/ControlNet")
# 提取肢体姿态
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
pose = model(image)
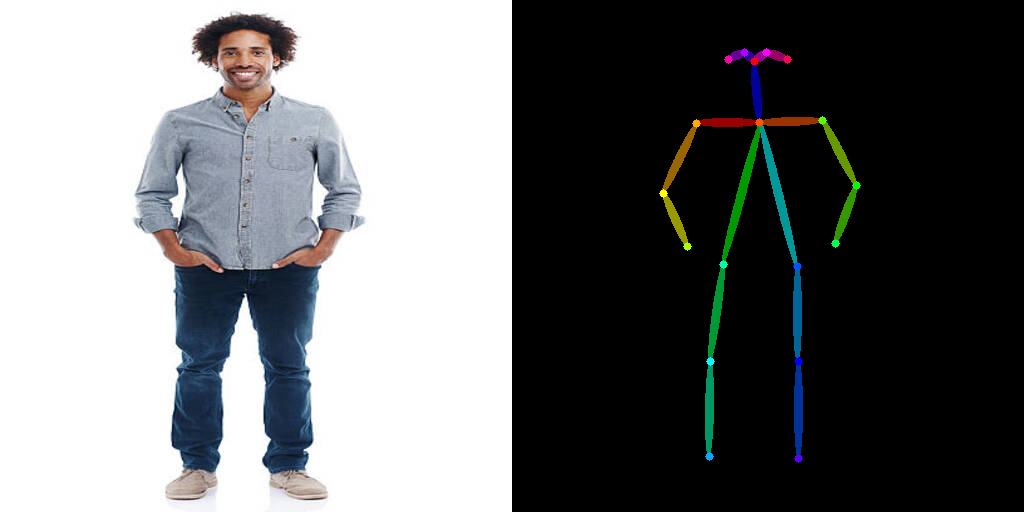
之后,我们依次加载SDXL模型和OpenPose条件的ControlNet模型,使用prompt要求模型根据原始图片的姿态,生成一组星球大战维德的形象效果。
# 加载ControlNet-OpenPose
controlnet = ControlNetModel.from_pretrained("thibaud/controlnet-OpenPose-sdxl-1.0", torch_dtype=torch.float16)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
# 可以更换为你想使用的prompt
prompt = "Darth vader dancing in a desert, high quality"
negative_prompt = "low quality, bad quality"
images = pipe(
prompt,
negative_prompt=negative_prompt,
num_inference_steps=25,
num_images_per_prompt=2,
image=pose.resize((1024, 1024)),
generator=torch.manual_seed(97),
).images
image_grid(images, 1, 2)

通过上面两个例子,相信你已经感受到了ControlNet功能的强大之处。也推荐你课后探索下更多控制条件的生成效果。
趣味玩法
事实上,除了ControlNet1.0和1.1官方仓库中提供的用途外,ControlNet还可以帮助我们完成很多创意用法,比如图像风格化、二维码生成等等。我们逐一来进行代码实现。
图像风格化
在第15讲中,我们曾经探讨过,使用图生图来实现图像的风格化效果。具体做法就是通过重绘强度这个参数的控制,对输入图片加入少量步数的噪声,然后使用一个擅长生成风格图片的SD模型进行图片去噪。在ControlNet出现之前,大多数图片风格化效果都是采用类似这种方法实现的。
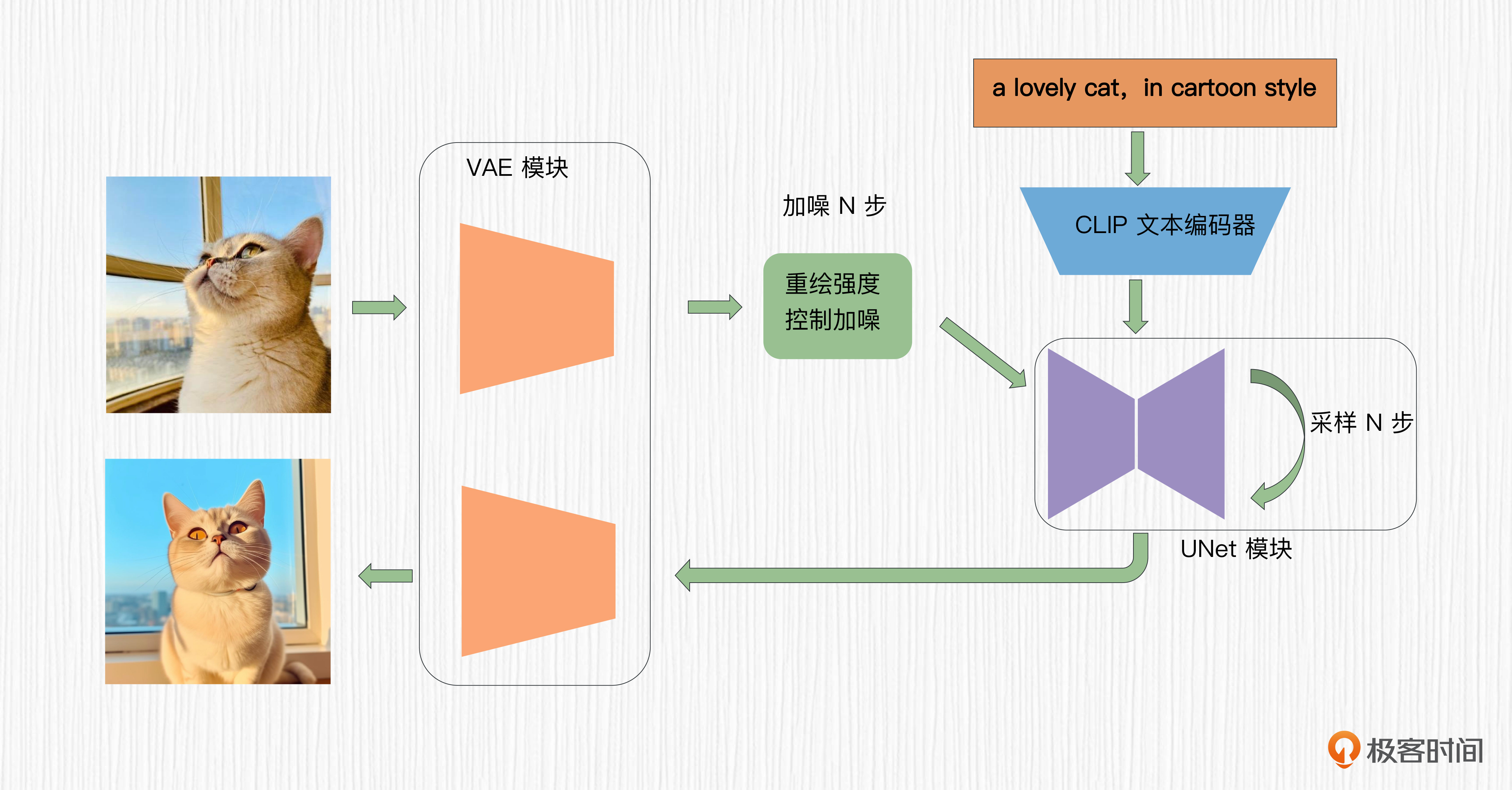
但是,这种风格化方法有一个缺陷,就是重绘强度这个参数的选择不好控制,可能要多次“抽卡”才能达到满意效果。如果重绘强度选择过小,最终生成的图片无法呈现目标风格效果。如果重绘强度选择过大,最终生成的图片就会丧失原始图片的构图,从而看不出与原图的关联。
ControlNet的出现弥补了这个缺陷。我们只需要提取原始图片的构图信息,比如使用Canny、HED、Depth等控制模块,便可以保证AI绘画效果与输入图片的构图一致。我们继续通过代码实现这个过程。你可以点开 Colab 进行操作。
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
from transformers import pipeline
# 提取图像的Depth信息
image = load_image(
"https://ice.frostsky.com/2023/08/19/7a93c14f96e2ea8b3a4b6911fff134a1.png"
)
Depth_estimator = pipeline('Depth-estimation')
image = Depth_estimator(image)['Depth']
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
control_image = Image.fromarray(image)
# 加载ControlNet1.1的Depth模型
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11f1p_sd15_Depth")
pipeline = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet
)
# 使用ControlNet完成风格化
prompt = ["a praying cat, cartoon style, best quality, (8k, best quality, masterpiece:1.2)"] * 2
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=30, generator=generator, image=control_image, height = 512, width = 512).images
后面的图片里,前两张图片分别展示了原始输入、我们提取的Depth信息。第二行则是我们ControlNet生成的效果。我们可以将文生图视作重绘强度为1.0的图生图,可以看到,利用ControlNet,我们可以在保持原有构图的前提下,将猫咪转换为卡通风格。


二维码
创意二维码生成是ControlNet非常亮眼的一个功能,比如我们这门课程的二维码,便是通过ControlNet来设计的。

这样的二维码该如何设计呢?首先需要准备一个原始的二维码图像。比如对于我们的课程链接,我们可以任意选择一个二维码生成工具,生成一张二维码。比如这里我使用链接中的工具,生成了两款原始二维码。


搞定了原始二维码,我们便可以用ControlNet来发挥我们的创造力了。你可以点开Colab链接和我一起操作。
首先加载生成二维码专用的ControlNet模型和对应的SD1.5基础模型。
from diffusers import ControlNetModel, StableDiffusionControlNetPipeline
# 加载二维码生成对应的ControlNet模型
controlnet = ControlNetModel.from_pretrained("Nacholmo/controlnet-qr-pattern-v2")
pipeline = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet
)
然后,我们使用原始二维码图像作为输入条件,并提供一个prompt用于引导AI绘画的生成过程。比如后面的代码中,使用我们课程的二维码作为控制条件,目标是生成两张创意二维码,分别是机器人风格和丛林风格。
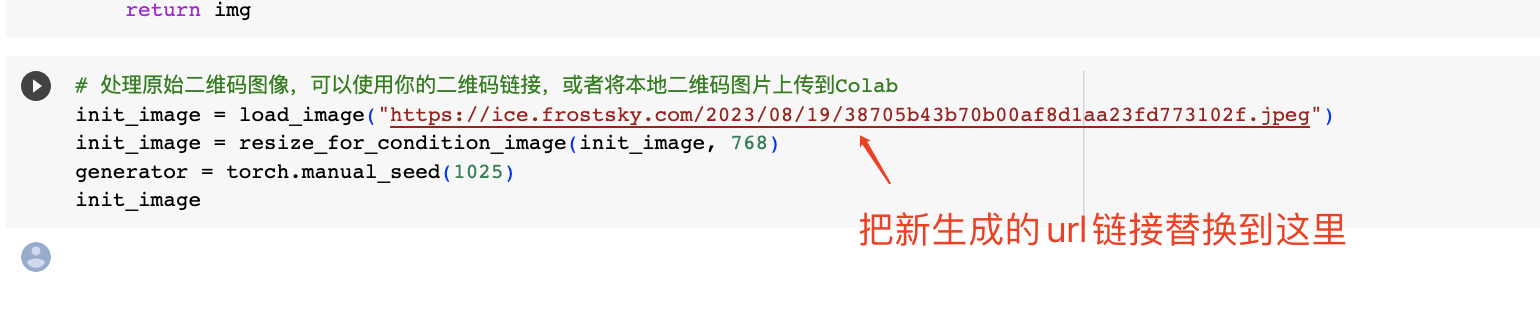
# 处理原始二维码图像,可以使用你的二维码链接,或者将本地二维码图片上传到Colab
# 这里我们将二维码图片上传到图床获取图片链接
init_image = load_image("https://ice.frostsky.com/2023/08/19/38705b43b70b00af8d1aa23fd773102f.jpeg")
# 可以替换成你的prompt
prompt = ["robot costume, best quality, extremely detailed", "masterpiece, forest, jungle, trees, mist, fog, water, river, vines, photorealistic"]
generator = torch.Generator("cuda").manual_seed(1025)
# 生成二维码
output = pipeline(
prompt,
init_image,
negative_prompt=["ugly, disfigured, low quality, blurry, nsfw"] * len(prompt),
generator=generator,
num_inference_steps=20,
)
如果你想上传自己手里的原始二维码,可以进入这个链接,参考后面的示意图上传二维码图片,然后复制url链接,替换到后面截图位置的代码里。
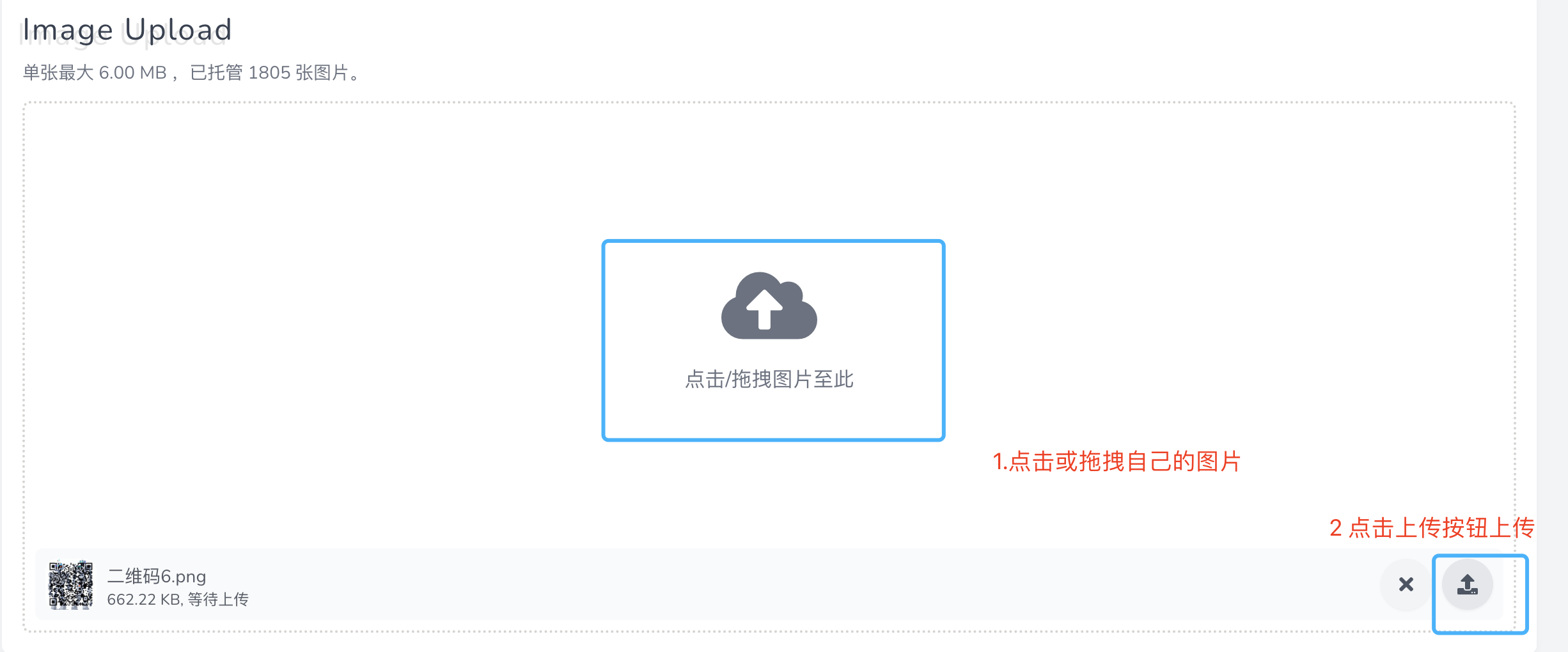

你可以点开图片查看我们生成的二维码效果,确认可以扫码成功便大功告成。

创意文字
与二维码类似,我们还可以在照片中写入我们希望的文字。比如我们希望实现一张写着“极客”的创意图片。
注意,我们要做的并不是全新的字体设计,而是用已有的字体来生成创意文字。比如我们可以在文档中选择“手札体”写下目标文字,然后截图保存。将这张图片上传到Colab或者图床后,我们便可以生成创意文字了。你可以点开 Colab链接和我一起完成操作。
image = load_image(
"https://ice.frostsky.com/2023/08/19/f9a6a52b210fb8dbc0fe347efbb22d9f.png"
)
# 将图像黑白颜色反转,得到的效果会更好
inverted_image = ImageOps.invert(image)
inverted_image
对于创意字体这个任务,我们要使用Depth控制条件的ControlNet模型。这是因为Depth条件中包含3D信息,用于指导生成有3D感的图片效果更好。
在提取Depth信息前,我们需要将图片黑白通道反转,实测下来效果会更好。然后,我们使用黑白通道反转的图片,来提取Depth控制信息。

image = inverted_image
Depth_estimator = pipeline('Depth-estimation')
image = Depth_estimator(image)['Depth']
image = np.array(image)
image = image[:, :, None]
# 将单通道图像复制三次,生成三通道(RGB)图像
image = np.concatenate([image, image, image], axis=2)
control_image = Image.fromarray(image)
你可以点开后面的图片,查看我们得到的Depth控制条件。

搞定了控制条件,我们就可以加载ControlNet1.1的Depth模型以及SD1.5基础模型,指定prompt要求模型生成指定场景,比如树叶、白云等,完成我们的创意字体生成任务。
# 使用ControlNet1.1的Depth模型
checkpoint = "lllyasviel/control_v11f1p_sd15_Depth"
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scHEDuler = UniPCMultistepScHEDuler.from_config(pipe.scHEDuler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=30, generator=generator, image=control_image).images[0]
你可以点开图片查看生成效果。可以看到,图像中的各个场景都呈现出“极客”的样式。当然,这里也可以选择其他和SD1.5亲缘关系接近的基础模型,实现更多有意思的效果。

线稿上色
现在我们再来尝试一下线稿上色的任务。如果你手中有现成的线稿图片,可以在Colab中直接使用你的线稿来进行AI绘画。如果手上没有线稿,可以挑选一张喜欢的动漫图片,使用链接中的工具进行线稿提取。你可以点开 Colab链接和我一起进行操作。
在这个任务中,我们使用最新的SDXL模型和它对应的ControlNet Canny模型。我们可以通过下面的代码进行模型加载。
# 特殊说明:模型计算量较大,需要使用Colab的高RAM模式,否则Colab容易Crash
# 高RAM模式需要点击「修改」-「笔记本设置」进行修改
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-Canny-sdxl-1.0-mid",
torch_dtype=torch.float16
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
vae=vae,
torch_dtype=torch.float16,
)
pipe.enable_model_cpu_offload()
之后我们需要读取图床的图片链接,或者读取上传到Colab的图片线稿。然后我们使用OpenCV的Canny轮廓提取函数获得图像的Canny边缘。后面图片展示的就是原始线稿和提取的Canny边缘。
# 你可以根据实际需求替换为你自己的图片
image_original = load_image("https://ice.frostsky.com/2023/08/26/3995bd36b16e2c65d5e7a98ad04264d2.png")
image_original
# 提取Canny边缘
image = np.array(image_original)
image = cv2.Canny(image, 100, 200)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
image = Image.fromarray(image)
image

一切准备就绪后,我们写一个prompt描述目标图像,比如“一个黄头发、红眼睛、红衣服的卡通男孩”。利用SDXL的文生图能力,配合ControlNet的Canny轮廓控制,便可以给我们的线稿自动上色。后面代码展示的就是文生图的过程。
# 结合ControlNet进行文生图
prompt = "a handsome cartoon boy, yellow hair, red eyes, red clothes"
generator = torch.manual_seed(1025)
negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, Normal quality, jpeg artifacts, signature, watermark, username, blurry"
controlnet_conditioning_scale = 0.6
images = pipe(
[prompt]*4, num_inference_steps=50, negative_prompt=[negative_prompt]*4, image=image, controlnet_conditioning_scale=controlnet_conditioning_scale,generator = generator
).images
在前面的代码中,我们一口气生成了4张效果图,耐心等待一会,便得到了下面图像中的效果。

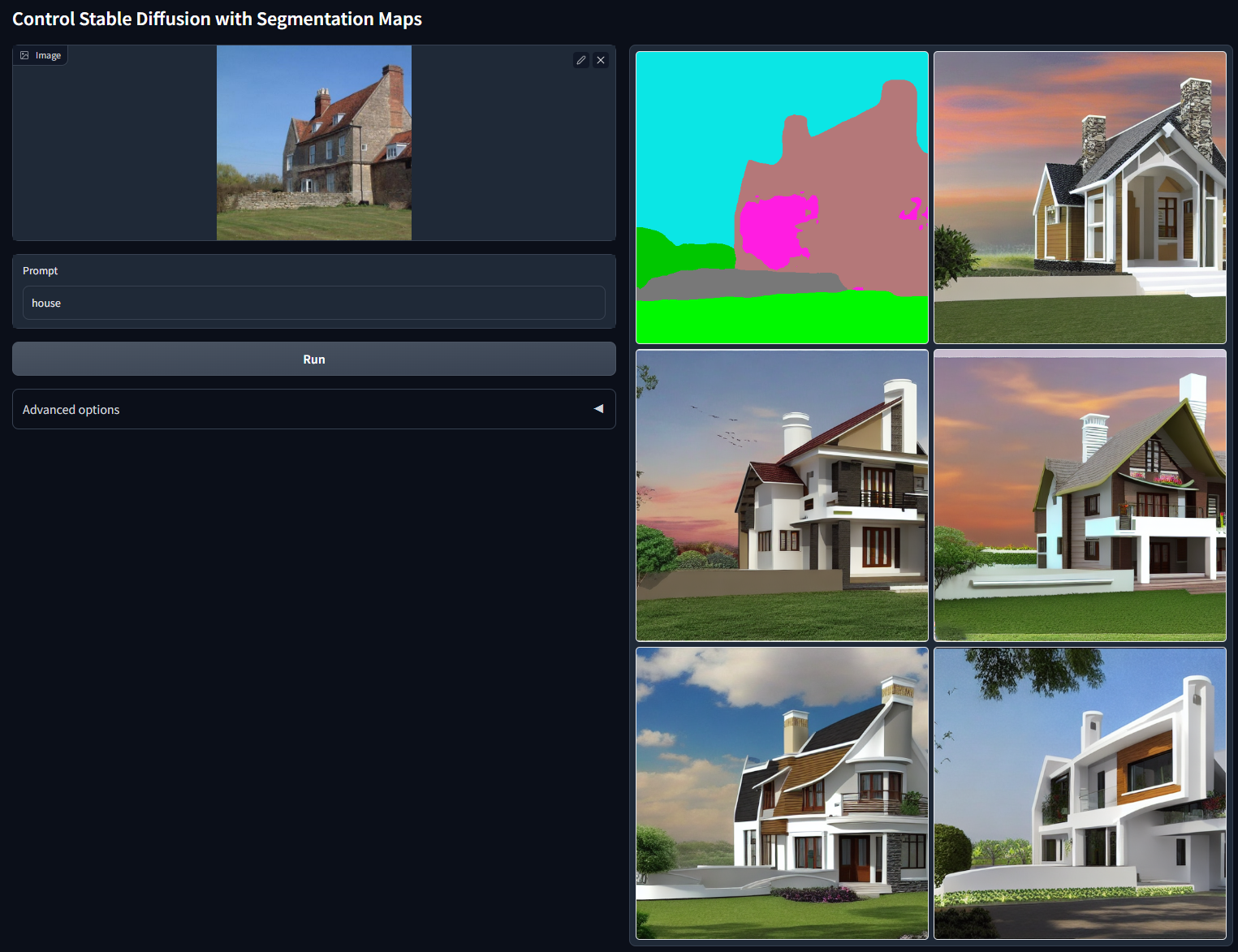
使用同样的方法,我们可以给下面图像中的房屋简笔画进行上色。这里我们用到的prompt描述是“一张高质量、有细节的专业图片”。你可以点开图片查看上色效果。


如果你手中有线稿,也期待你使用ControlNet为线稿实现染色效果。如果你有喜欢的动漫角色,也可以先提取线稿,然后试着为“他们”重新上色。
总结时刻
今天这一讲,我们一起完成了不少实战项目,一起认识了ControlNet各种控制条件的特性,还用ControlNet完成了一些有趣的创作。
首先我们了解了Canny、HED、Scribble、MLSD这几种控制条件,它们的思路就是用不同形式的轮廓线实现AI绘画的可控生成。Normal、Depth这两种控制条件,能够帮助我们从2D图像中推断出3D几何信息,生成的图片3D空间感更强。而Seg、OpenPose这两种条件,则分别从分割结果和人体姿态的角度控制构图。
然后我们以实战的形式,体验了如何使用Canny和OpenPose作为控制条件实现AI绘画效果,并使用ControlNet完成了图像风格化、创意二维码生成、创意文字生成和线稿上色等趣味用法。
实际上,ControlNet的能力还远不止于此。比如我们还可以用ControlNet完成动漫人物转真人、在人像照片中写入不违和的文字等任务。这些功能背后的原理都是ControlNet,不过需要更精心地选择控制条件、ControlNet模型和基础模型。
思考题
除了今天实战篇中学习的各种ControlNet用法,ControlNet还能实现哪些有趣的功能?欢迎你在Colab中实现出算法效果,并把你的Colab链接分享出来。
期待你在留言区和我交流讨论,也推荐你把今天的内容分享给身边更多朋友,和他一起探索ControlNet的多种玩法。
- Toni 👍(4) 💬(1)
包括ControlNet 在内的AI绘画工具越来越多,但AI绘画结果需要人工抽取结果的痛点依在。 现在AI 绘画的流程如下: 1. 先有个想画的想法, 2. 根据这个想法编出个prompt 输给AI 绘画工具, 3. AI绘画工具生成多张图片比如说4张供人参考, 4. 人们再依据上面步骤1中的想象,从出的4张图里面选出合意的,如不甚满意,就继续上面的步骤2改变prompt,然后再执行步骤3,让AI重新绘图,这过程可能会进行好几轮,比较费时。 那么问题来了,有没有什么方法让上面的过程自动化? 计算机的优势就是不知疲惫,虽然有时也宕机罢工,但总体来说比人能干。如果能将上面成图+判断的过程先交给计算机进行5轮,然后再由人类对出图给出评估,效率会提高很多,图的质量也会更高。 解决上面痛点的思考之一是设计一个质量控制层 QualityControlNet,这个可训练的质量控制层应包含下面的一些功能: 1. 有对图像质量评估的量化指标,可选艺术,技术,美学等几个方面做为评估参量,指标可调可变, 2. 有对正反prompt修正反馈的能力, 3. 要修正的图像+新的更改要求可以自动返回低维隐藏层,并启动重绘过程, 4. 能自动求解最佳重绘参数,最佳去噪步骤等参量。 达到上面要求中的一个或几个,对质量控制层 QualityControlNet 的一些想法,大家补充。
2023-09-05 - Geek_cbcfc8 👍(1) 💬(1)
腾讯发布了一个adapter https://github.com/tencent-ailab/IP-Adapter 可以实现根据一张图抽取人脸,风格,服装等特征,用于image to image
2023-09-04 - peter 👍(0) 💬(1)
请教老师两个问题: Q1:彩票上面的数字,只有一个数字,其他的看不到了,不知道是被雨淋了还是被撕掉了。用WebUI可以恢复吗?或者其他某个模型? Q2:controlNet或其他模型可以创作名片吗?
2023-09-05 - Geek_cbcfc8 👍(0) 💬(1)
老师你好,controlnet xl版本已经出来了,能加餐一个的换装任务吗,把一些知识点串一下 1、训练衣服或人物的lora模型 2、基于controlnet进行衣服或模特的更换 可应用到电商一键换装,或者帮组情侣实现AI婚纱摄影
2023-09-04 - 刘蕾 👍(0) 💬(0)
老师您好,这节课里面的蒙娜丽莎的那个例子,免费的CoLab资源是不是跑不了? 价值SDXL(stable-diffusion-xl-base-1.0)的那句,跑了1个多小时还没跑完。
2024-01-07