20 ControlNet:出道即巅峰,构图控制没有对手
你好,我是南柯。
我们知道Stable Diffusion可以用文本引导图像生成。除了使用prompt这种比较原始的方式,还有没有控制能力更强的方法呢?
其实早在第2讲,我就留过一个思考题,AI 绘画生成的图像在手部和脸部细节存在瑕疵有哪些解决方式。而我们今天要讲的技术—— ControlNet 就可以解决这个问题,对图像结构做出一定的限制,比如手部的关键点信息、五官信息等。
2023年2月,ControlNet这个方法一经提出,便凭借其对于AI绘画效果的控制能力火遍全网。最初的ControlNet主要用于线稿上色、图像风格化、可控姿态的人体生成等任务。如今各路网友脑洞大开,使用ControlNet做出了创意二维码、将文字自然地融入照片等趣味效果。
这一讲,我们一起来探讨ControlNet背后的技术原理和各种应用场景。掌握了ControlNet这个“大杀器”,你对于AI绘画效果的控制能力会上一个台阶,在下个实战篇实现创意AI绘画任务时也会更加得心应手。
初识ControlNet
如果说prompt是对于AI绘画模型指令级的控制,ControlNet无疑是构图级的控制。为了让你对它建立感性认识,我们先结合一些图片例子,感受一下ControlNet的构图控制能力。
我们首先需要准备一张原始图片,比如一张鹿的照片,我们可以通过图像边缘提取算法获取图像轮廓。把这个轮廓图作为ControlNet的输入,同时使用这样一句prompt “a high-quality, detailed, and professional image”生成图片,便可以得到右侧的四张图片。

这里有两个要点值得我们关注。第一,我们的prompt中并不包括任何描述图像内容的信息,便可以得到四张不同鹿的照片。第二,生成的四张照片都满足我们输入的轮廓限制,并且效果各异。
类似地,我们可以提供建筑的外形线条,通过简单的prompt引导,得到各种风格迥异的建筑效果图。

再比如,我们随手画一个草图,比如简单几笔勾勒出乌龟、奶牛和热气球,同样是配合上我们随手写出的prompt,便可以生成精美的图片。

事实上,ControlNet可用的控制条件还远不止这些。比如后面这些图,展示的就是使用HED边缘、人体姿态点、图像分割结果作为控制条件,配合上各种不同prompt生成的图像效果。



ControlNet算法原理
那么,ControlNet是如何控制生成结果的呢?这就需要我们深入了解它的算法原理了。
因为ControlNet要和SD结合起来使用,所以我们先回顾下SD模型(为了描述方便,我们接下来都用SD来指代Stable Diffusion)的图像生成过程。你可以看后面这张图,VAE编码器输出的潜在表示,经过一个UNet模型结构便可以完成当前时间步t的噪声预测。对于SD1.x系列,输入的潜在表示和预测得到的噪声都是一个64x64x4的向量。
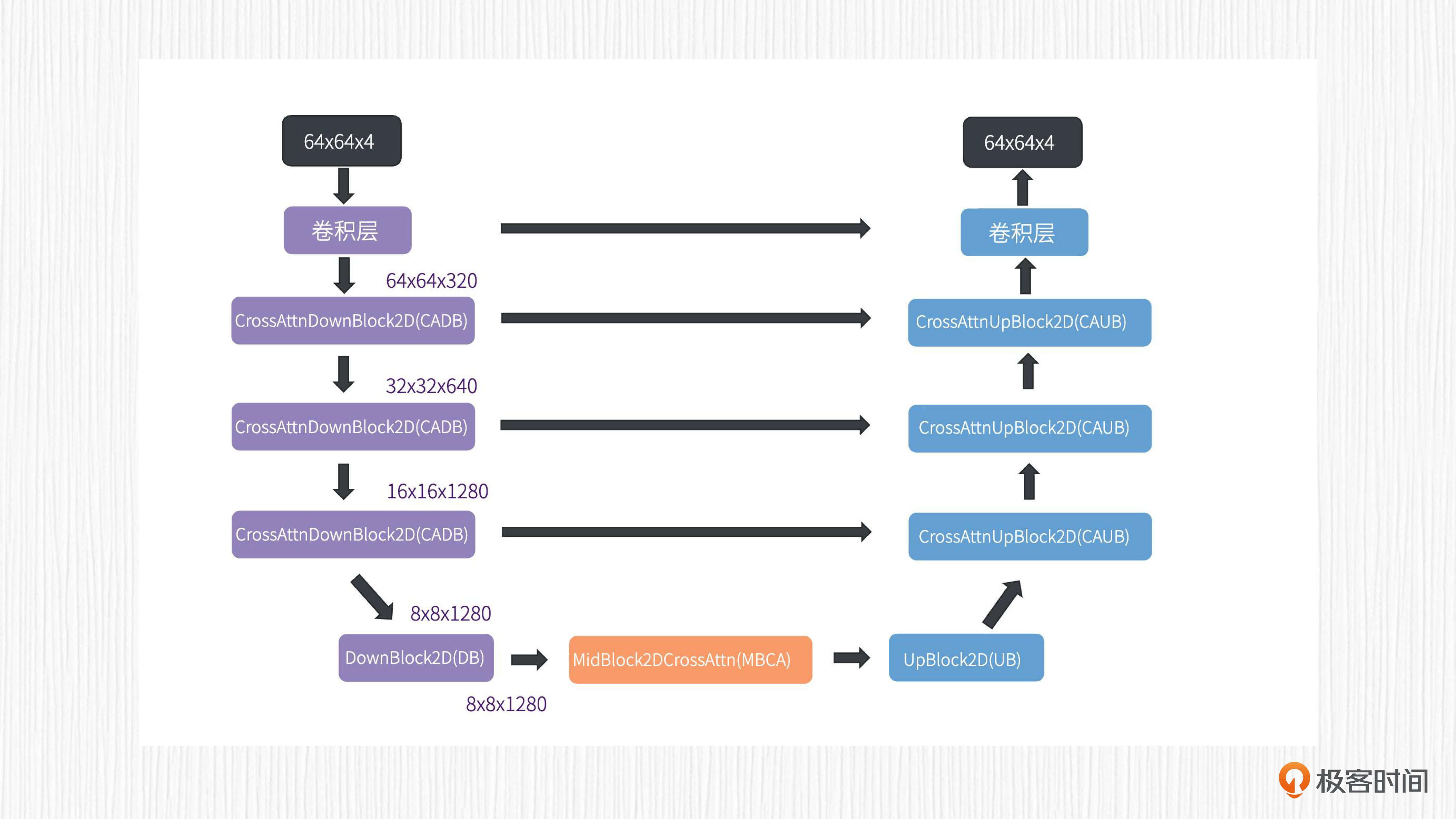
我们第9讲学过的采样器负责在输入的潜在表示上将我们预测的噪声去除,这样便完成了SD模型的一步去噪。将这个过程重复N次(N是我们的采样步数),我们便可以得到最终潜在表示。这个潜在表示经过VAE解码器,便可以生成一张清晰的图像。
ControlNet的基本结构
接下来我们看看ControlNet的基本结构。
ControlNet并没有改变SD模型的VAE、CLIP文本编码器和UNet结构,而是在这个方案的基础上多加了一些东西。
后面这张图便是ControlNet的算法原理图,红框中的区域是我们熟悉的SD模型,绿框中的区域便是ControlNet模型。
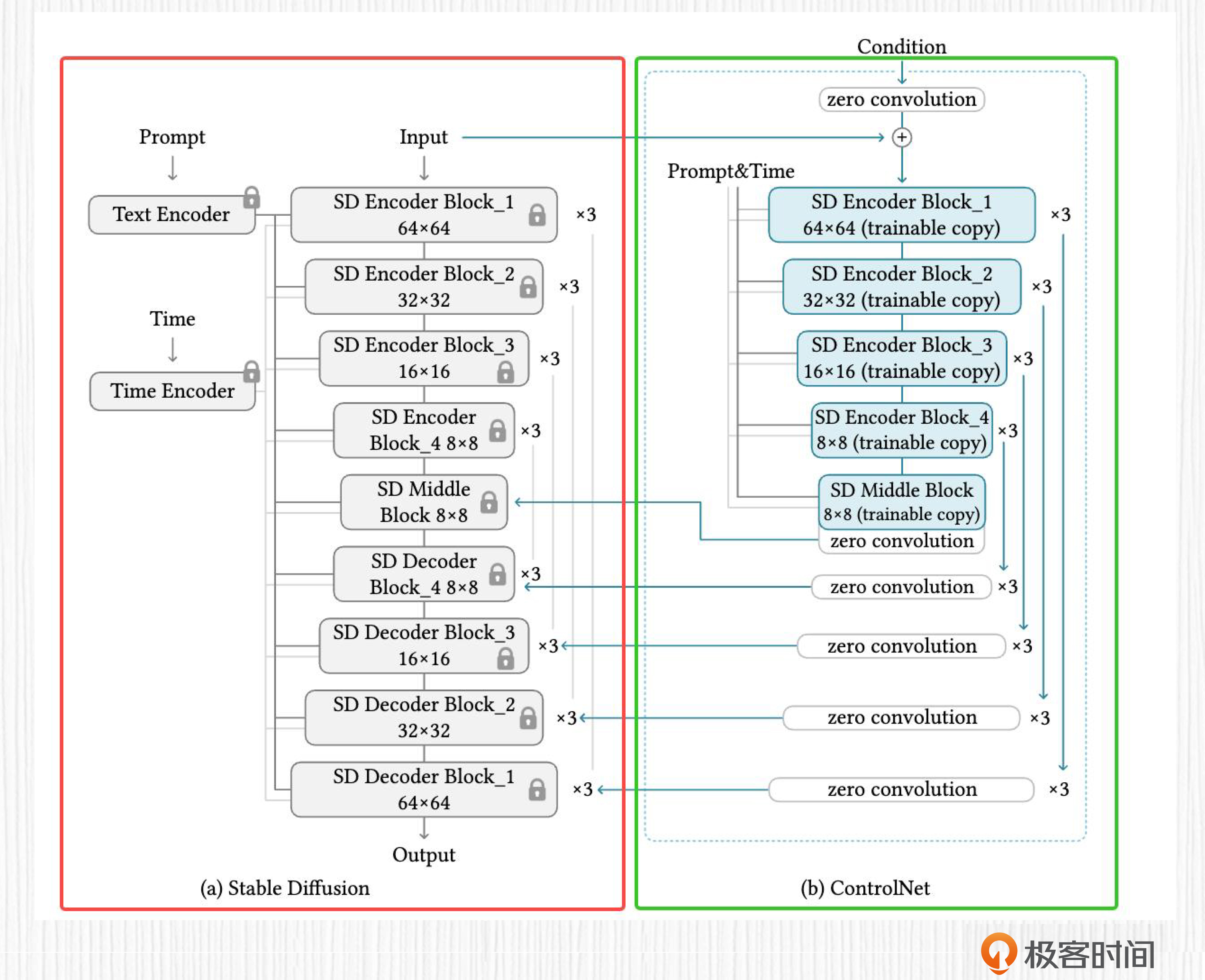
SD部分带有锁的标志表示在ControlNet模型的训练过程中,SD模型的权重不进行更新。为什么要这样做呢?
有两个原因。第一,ControlNet作为一个即插即用的插件,训练过程应该避免影响到SD模型的部分。第二,固定SD权重可以减少一半以上的可学习参数,这么做能节省计算资源。
也就是说,训练ControlNet的前提是,我们手中已经拥有了一个训练完成的SD模型,比如SD1.5这样的预训练模型。ControlNet的训练目标是得到绿框中新增的模型权重。
那么,为了实现通过条件控制图像生成这一目的,ControlNet这个插件模型该怎么设计呢?
我们需要考虑三个问题。
- 如何设计ControlNet的模型结构。
- 控制条件该怎么输入。
- ControlNet和SD模型之间的信息要如何交互。
先来看第一个问题,如何设计ControlNet的模型结构。要回答这个问题,我们还需要再回顾一下前面的ControlNet算法原理图。
红框中SD模型部分展示的是我们熟悉的UNet结构,我们能看到,这里的UNet由12个编码器模块、1个中间模块和12个解码器模块构成。Prompt的文本表征和时间步t的编码都直接作用于这些模块。更多细节,你可以复习我们课程的第15讲。
为了能够对齐控制信号和SD特征之间的维度,ControlNet部分直接拷贝了UNet的12个编码器模块和中间模块的权重,并加入了14个名为零卷积(zero convolution)的层。需要注意的是,prompt的文本表征和时间步t的编码同样作用于ControlNet部分的UNet编码模块。零卷积的作用我们等会再讨论。
理解了ControlNet的模型结构设计之后,我们再来看第二个问题,ControlNet的控制条件该如何输入。我们知道,SD模型UNet部分的输入是潜在表示,而ControlNet的输入是我们使用的控制条件,比如图像轮廓、手绘线稿等。
潜在表示是经过VAE编码器处理后的特征,分辨率是64x64x4。而ControlNet的输入,比如我们提供的目标轮廓线,通常是512x512这样的图像。这样ControlNet的控制信号和SD模型就不一致了,因此我们需要使用一个小型深度学习网络,将512x512维度的控制条件转换为64x64维度的特征。
之后,我们再来看第三个问题,处理ControlNet和SD模型之间的信息交互。
仔细观察ControlNet的方案图你会发现,ControlNet输入的特征经过一层零卷积层计算后,就会与SD模型输入的潜在表示相加。这样,SD模型便将潜在表示传递给了ControlNet模块。而ControlNet后面13个零卷积层的输出特征,直接和SD模型UNet部分对应的特征相加,这么做是为了将控制条件引入到SD模型。
了解了ControlNet与SD模型的关系,最后我们再来看看零卷积的作用。所谓零卷积,就是初始化权重为零的卷积算子。
之所以要将权重初始化为零,是为了在ControlNet训练的第一步,无论控制条件是什么,经过全零卷积后得到的数值都为零。这样,ControlNet后面13个零卷积层的输出特征也全为零,和SD模型UNet部分对应的特征相加便没有任何效果。
因为原始的SD模型已经在海量数据上充分训练过了,ControlNet使用零卷积在一开始不会对SD产生任何影响,这样一来,引入新的ControlNet权重仍可以最大程度保留SD模型的AI绘画能力。
随着ControlNet模型的训练,这些初始化为零的权重会根据梯度进行更新,逐渐开始发挥对SD模型的控制作用。
训练ControlNet
搞定了原理,我们再来深入聊一聊该如何训练一个ControlNet。
这个过程可以分为两步。
第一,根据你要使用的控制方法,在你的数据集上生成这些控制条件,比如提取图像边缘轮廓或者提取人体姿态点。
第二,按照标准的SD模型训练流程进行训练,UNet的输入包括带噪声的潜在表示、时间步t的编码、prompt文本表征和ControlNet的控制信号。
与常规SD模型的训练不同,UNet的输入多了一个ControlNet的控制信号。值得一提的是,在第15讲我们已经知道,标准SD训练过程中使用无分类器引导,一般有10%的概率会将训练的prompt设置为空字符串。而ControlNet的训练中,这个概率是50%!
这是为了让SD模型在预测噪声时,有更多信号源自ControlNet的控制信号,而不是prompt文本表征。说到底,还是为了加强控制。
在训练ControlNet时,针对每一种控制条件需要单独完成。这里的控制条件可以是轮廓线(Canny、HED等),也可以是法线、深度图等。所以,在Hugging Face中我们可以找到20余种不同的ControlNet模型权重。下一讲我们会探讨这些权重的使用方式。
ControlNet的持续进化
前面我们学习了ControlNet1.0的算法效果和技术原理。在两个月之后的2023年4月,ControlNet又推出了1.1版本。1.1和1.0两个版本的设计思路完全相同,不过1.1改进了1.0版本模型的图像生成效果,并推出了几个全新的ControlNet模型。
我精选了其中最有趣的两个新模型,我们一起来看看。
指令级修图
首先是指令级修图的ControlNet。比如后面这张风景图片,我们希望转换图片里的季节,就可以通过prompt写下“make it winter”。图中的五个冬季效果是使用不同随机种子得到的。

再比如后面这个例子,原始照片是一张人像照,我们可以利用prompt把绿衬衫的男人换成钢铁侠。可以看到,ControlNet保持了原始人像轮廓,生成了钢铁侠的效果。

有了这个功能,我们不用复杂的PS,写个prompt就能修图。但它背后的原理是怎样的呢?
其实也并不复杂,只不过在训练ControlNet的时候使用了特殊的成对数据,我们看个例子就明白了。

图片中的文本就是训练ControlNet用的prompt,原始图像作为ControlNet的输入条件,而指令修图后的图像作为SD模型的目标输出。更多训练细节你有兴趣的话,可以看看这个链接。
Tile功能
Tile在中文里是瓷砖的意思,字面理解是将图片切分成棋盘格的样式分别处理再拼接。这个功能很强大,因为它可以帮我们补充图像中的细节。
Tile功能对于生成超高分辨率的图片(比如4K图像)非常有用,比如后面这张图片,我们的prompt是“a handsome man”,希望AI绘画模型帮我们补充各种局部细节。如果是使用传统SD模型切块生成再合并,每个切块内都会有一个帅哥,拼接起来的画面自然很鬼畜。
而使用Tile功能时,ControlNet模型的Tile功能会先识别当前切片中的图片内容,如果切片内容和prompt无关,使用Tile功能生成切片内图像的时候就会降低prompt对于生成图像的影响。图片中树叶部分的切片经过Tile功能的处理,就会变得格外清晰。你可以点开后面的图片查看效果。

我们再来看一个超分辨率的例子。比如后面这张图,输入图像是一张64x64分辨率的小狗,使用Tile功能配合上“dog on grassland”这个prompt,可以轻松实现图像的8倍超分,得到512x512分辨率的效果。

作为对比,如果选择经典的超分算法Real-ESRGAN,同样是将64x64分辨率超分到512x512,得到的效果是后面这个样子。

观察图片可以发现,看到超分的效果并不理想。这样的对比也体现了ControlNet Tile功能的优势。
总结时刻
今天这一讲我们探讨了ControlNet这个强大的AI绘画工具,包括它的算法原理、控图效果和最新能力。
ControlNet模型需要与预训练好的SD模型配合使用。ControlNet拷贝了原始SD模型的12个编码器模块和中间模块权重,并加入了14个零卷积层。在训练过程中,SD的权重保持不动,仅更新ControlNet部分的模型权重。
此外,我们还探讨了全零卷积这种特殊设计背后的思考,以及它如何用于SD模型和ControlNet模型之间的信息传输。
之后,我们详细讨论了ControlNet1.1两个亮眼的能力:指令级修图和Tile功能。有了这两项能力,我们“动动嘴”便可以实现强大的P图和超分功能。
了解了ControlNet的基本原理,下一讲我们便会使用Control1.0和1.1,完成各种有趣的实战项目,比如创意二维码生成、图像风格化等,敬请期待!
思考题
这一讲中我们介绍了ControlNet的几种控制条件,比如边缘轮廓、分割图、人体关键点等。你还知道ControlNet有哪些控制条件?这些控制条件我们需要通过怎样的方式获得?
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,也推荐你分享给身边更多同事、朋友。
- Geek_fbb96d 👍(0) 💬(1)
老师你好,我在 Stable Diffusion 的界面上没有找到 ControlNet 的位置?请问在哪里?
2024-05-21 - hallo128 👍(0) 💬(1)
ControlNet官方GitHub:https://github.com/lllyasviel/ControlNet ControlNet论文原文:https://arxiv.org/abs/2302.05543
2024-05-03 - peter 👍(0) 💬(1)
请教老师两个问题: Q1:ControlNet可以独立使用吗? Q2:ControlNet只能配合SD使用吗?还是可以和其他模型配合?
2023-09-03 - hallo128 👍(0) 💬(0)
老师,想请问下,如何训练自己的ControlNet插件呢?如果要更精细化的控制一些不一样的场景,而不是直接调用已训练好的ControlNet插件
2024-04-25