18 DreamBooth和LoRA:低成本实现IP专属的AI绘画模型
你好,我是南柯。
学完前两章内容,我们已经掌握了AI绘画的基本原理,也熟悉了AI绘画的经典解决方案。从这一讲开始,我们正式进入课程的综合演练篇,一起探讨图像定制化生成与编辑的经典算法方案。
使用Stable Diffusion模型的时候,基于prompt生成图像已经是我们比较熟悉的模式,比如一个人在某个地方做某件事。这种方式生成的图像类似开盲盒,因为我们在看到效果之前,并不确定图中生成的物体和风格是什么样的。
而接下来我们要学习的定制化图像生成技术就不同了,它的目标是控制指定的一个人在某个地方做某件事,或者控制生成的图片是某只动物,再或者生成的图像是某个确定的风格。
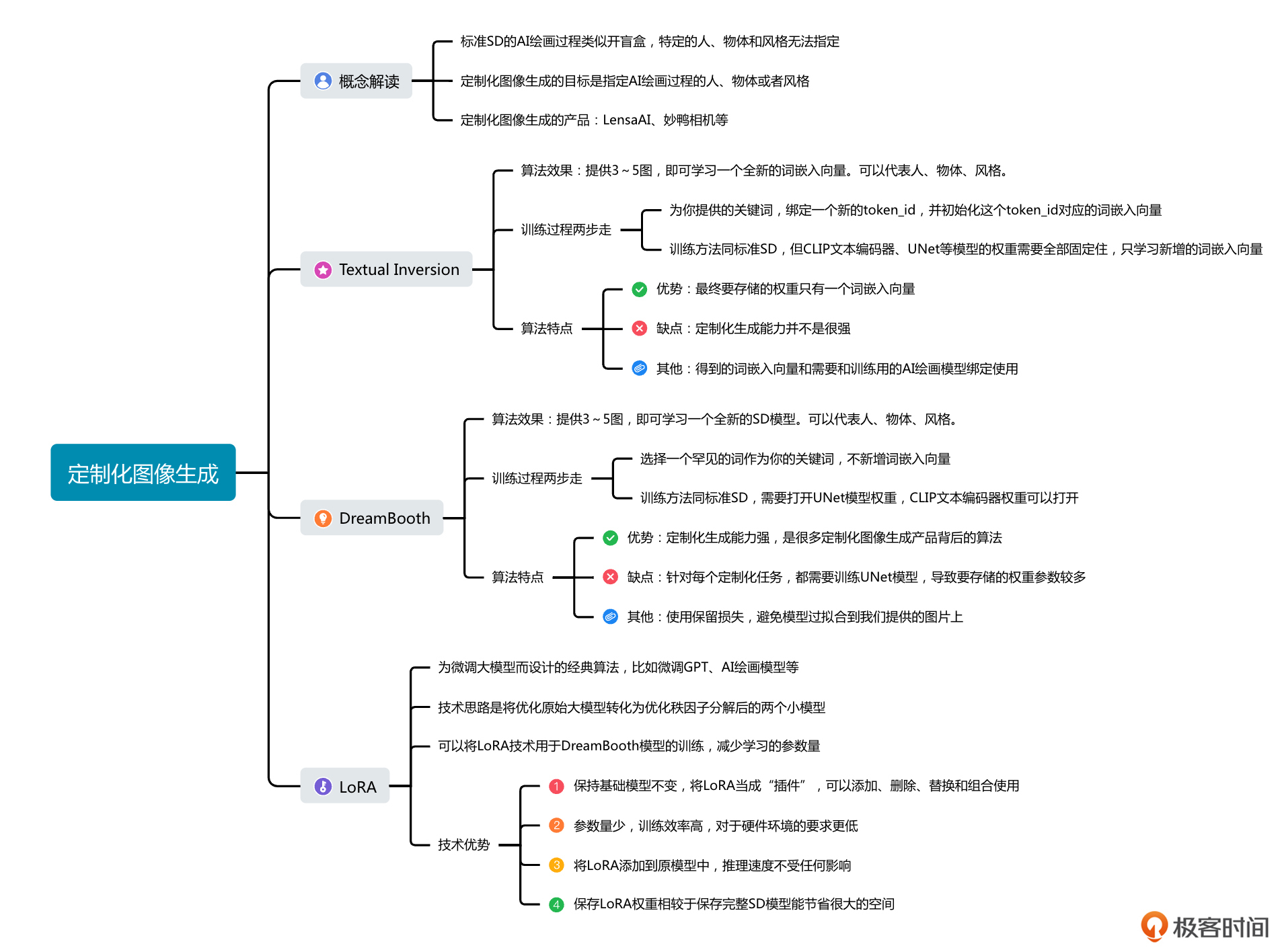
可不要小看了这个定制化的思想,海外非常流行的LensaAI和国内风靡一时的“妙鸭相机”,它们都是定制化图像生成的具体产品方案。今天这一讲,我们要学习三种经典的定制化算法方案,分别是Textual Inversion、DreamBooth和LoRA。
Textual Inversion
为了帮你更好地理解Textual Inversion这个算法,我先带你回顾下SD词嵌入向量的使用方式。
在SD AI绘画过程中,我们输入的prompt首先会经过tokenizer完成分词,得到每个分词的token_id。之后在预训练的词嵌入库中根据token_id拿到词嵌入向量,并将这些词嵌入向量拼接在一起,输入到CLIP的文本编码器。接着,经过CLIP文本编码器提取到的文本表征,便可以通过交叉注意力机制控制图像生成。
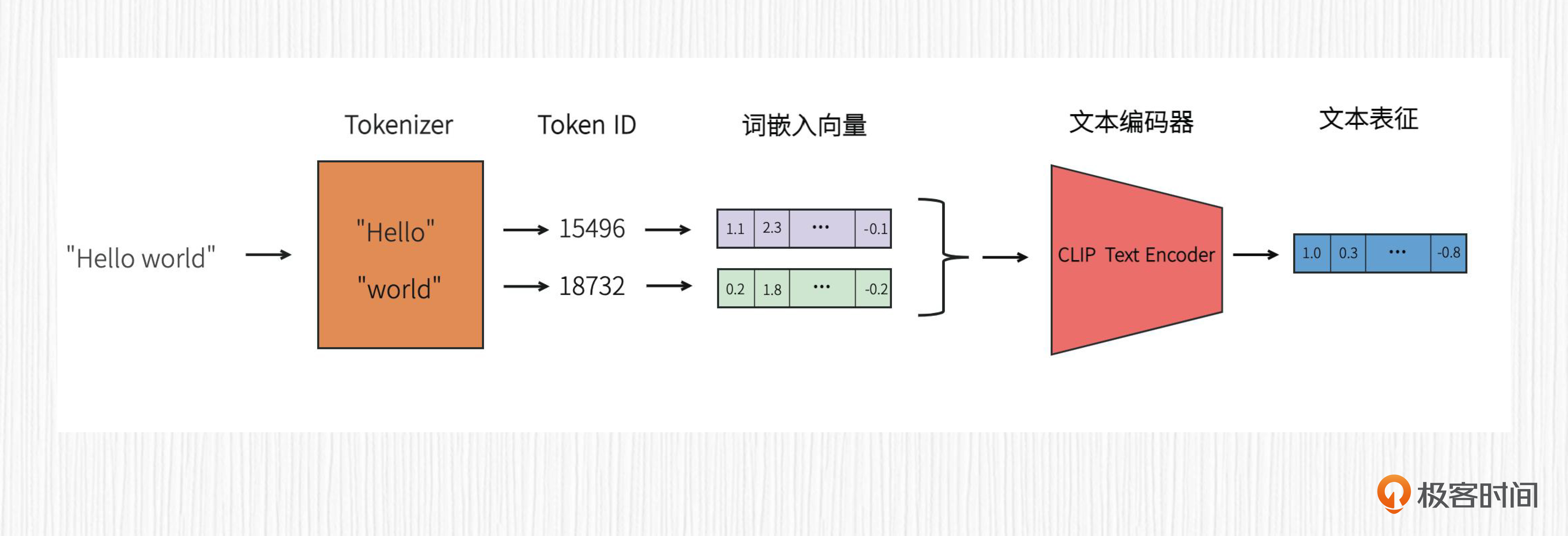
理解了SD词嵌入向量的使用,再来学习Textual Inversion这个算法就会非常简单。
Textual Inversion 算法的本质是学习一个全新的词嵌入向量,用于指代定制化的内容。其核心思想便是,对于一个给定的物体或者风格,去学习一个全新的词嵌入向量,并绑定一个符号比如S*,为其分配一个新的token_id。这样,每次文生图的时候只需要带上S*,就能生成我们想要定制化的物体或者风格。
这个思想很简单,我们来看下这个算法的效果。


从前面的图中我们可以看到,对于一个物体或者风格,我们只需要使用3~5张图训练,便可以得到新的关键词S*,从而完成定制化图像生成的任务。
那么,这个过程具体是如何完成的呢?你可以结合后面这张算法原理图,听我继续分析。

Textual Inversion的训练过程一共分两步。
第一,我们需要为你提供的关键词(比如S*),绑定一个新的token_id,并初始化这个token_id对应的词嵌入向量。举例来说,比如原始词嵌入库中包括20000个关键词,token_id对应的数值就是1~20000,那么我们新增关键词S*的token_id便应该是20001。
第二,准备好前人已经训练好的AI绘画模型,比如Stable Diffusion模型或者DALL-E 2模型。训练过程中CLIP文本编码器、UNet等模型的权重需要全部固定住。按照对应AI绘画模型的标准训练方法,在你提供的3-5张图片上进行训练。
整个过程中,只有你新初始化的词嵌入向量是可以学习的。当训练完成后,你便得到了你的定制化词嵌入向量,它的作用是表达训练图片中的物体或者风格。
我想提示你注意两点。第一,得到的词嵌入向量是和训练使用的AI绘画模型绑定在一起的。第二,Textual Inversion的训练也可以同时优化多个新增的词嵌入向量。你可以点击链接查看Textual Inversion的训练代码,加深了解。
DreamBooth
由于Textual Inversion训练过程中的可学习参数非常少,通常只有512或者768个浮点数,所以它的定制化生成能力并不是很强。在市场上各种常见的定制化生成产品中,更常用的方法是 DreamBooth。
关于DreamBooth这个命名有个很有意思的小插曲。Google团队是这样解释的:DreamBooth就像是一个摄影棚(PhotoBooth),但是一旦拍摄主体被记录下来,它可以被合成到你梦想的任何地方。
DreamBooth同样是需要上传3~5张图,使用一个新的描述词[V],它同样可以定制化一个物体或者一种风格。DreamBooth的生成效果你可以参考后面的图片。


那么DreamBooth是怎么实现的呢?我们先来看看论文给出的方案图。

我来解释下这个方案。算法过程还是两步。
第一,选择一个罕见的词作为你的关键词,比如CSS。不同于Textual Inversion,这里的词不需要绑定全新的词嵌入向量。
第二,准备好前人已经训练好的AI绘画模型,比如Stable Diffusion模型或者DALL-E 2模型。训练过程中UNet模型的权重需要打开。然后,我们要按照对应AI绘画模型的标准训练方法,在你提供的3-5张图片上进行训练。
你可能会问,只用3-5张图去优化UNet这么多参数,不会造成模型的过拟合么?比如使用3-5张你自己的小狗得到的模型,就再也无法生成其他样式的小狗。
答案是会的。这样得到的模型,无论你的prompt是 “a CSS dog” 或者是 “a dog”,都会得到训练用的小狗。
为了解决这个问题,论文作者提出了保留损失(preservation loss)这个应对方法。具体操作就是先使用AI绘画模型生成一批小狗的图片,在训练DreamBooth的时候,这批图像也加入AI绘画模型的训练。通过这种方式得到的模型便可以有效地避免过拟合。
这里我想提醒你留意,训练DreamBooth的时候,CLIP文本编码器也可以打开训练,实践证明这样做可以提升定制化图像生成的算法效果。
我用一句话概括一下Textual Inversion和DreamBooth的区别:前者只会优化一个或几个词嵌入向量,后者会对整个AI绘画模型做微调。
接下来,我们不妨对比下Textual Inversion和DreamBooth的算法表现。在实际使用中,推荐你用DreamBooth这个方案。你可以点击链接查看训练代码。

LoRA
如果我们想实现DreamBooth定制化图像生成的效果,又不希望更改原有AI绘画模型的模型权重,还有什么思路呢?
答案是使用LoRA。
LoRA 的全称是Low-Rank Adaption of large language model。从名字我们能一眼看出,这个技术最开始是为大语言模型设计的。
在了解它的技术原理之前,我们要先复习一个线性代数的基本概念:矩阵的秩。
举个例子,如果你有一个2x2的矩阵(也就是有2行2列的矩阵),第2行是第1行的两倍,那么这个矩阵的秩就是1,而不是2,即使这个矩阵有两行。因为第2行实际上并没有提供新的信息,它只是第1行的两倍而已。所以,我们可以把秩理解为矩阵所能提供的信息量或者矩阵所描述的空间维度。
对于深度学习模型而言,我们学习得到的权重便是一个巨大的矩阵W。
我们假设这个矩阵的维度是dxd,而它的秩是r。我们可以找到两个矩阵A和B,其中A的大小是dxr,B的大小是rxd,使得W=AB。这在数学上叫做矩阵的秩因子分解。一般来说,r远小于d。
LoRA便是利用了矩阵的这个性质。在训练过程中,W保持固定,优化矩阵A和矩阵B的权重。这样,W + AB便是我们最终要用的模型权重。理解了这些,我们再去看LoRA论文中给出的方案图就简单多了。

你可能在Civitai上下载过不少基础模型权重和LoRA模型权重。你有没有发现,基础模型动辄3-4GB,而LoRA模型最大不过200M,这是为什么呢?
还是以上面的矩阵运算为例,我们假定W的维度d=10000,W的秩r=100。那么原始权重的参数量便是100M,而A和B的参数量只有1M。这便是LoRA模型远远小于基础模型的原因。
那么LoRA的效果如何呢?在原始论文中作者设计了一个实验,在某个特定数据集上微调GPT-3的全部参数,对比只微调LoRA模型的参数。
从下面的图中你可以看到,GPT-3的全部参数有1750亿,而训练的LoRA只有37.7M。后者大概只占全部参数的万分之二,在所有测试指标上都超过了全量参数微调。

LoRA算法一经提出,便开始席卷AI绘画圈。相比GPT-3 1750亿的参数,负责去噪的UNet通常只有几百M的参数,顶多算是小模型。但是LoRA仍然能有效减少可学习参数,为我们的模型训练和存储提供便利。
我们使用LoRA模型的时候,加入LoRA的参数相当于给原始模型添加了新功能,不用的时候还可以将LoRA功能关闭,一举两得。这也就解释了我们实战1中为何要下载基础模型(比如SD1.5)和LoRA模型(比如我们实战1用的IN LoRA模型)。
回到我们今天的话题定制化图像生成。我们已经知道,DreamBooth的训练是对整个AI绘画模型做微调。这个过程当然也可以引入LoRA模型,来做CLIP文本编码器和UNet模型的权重微调。
使用LoRA相比于微调原始模型有哪些好处呢?我认为有以下四点。
第一,可以保持基础模型不变,将LoRA当成“插件”,可以添加、删除、替换和组合使用。
第二,LoRA的参数量少,训练效率高,对于硬件环境的要求更低。普通人也都训练得动。
第三,训练后可以直接将LoRA添加到原模型中,而且模型的推理速度不受任何影响。比如在AI绘画任务中,我们将LoRA模型与基础模型组合使用后,生成图片的速度不会受到影响。
第四,对于妙鸭相机这类头像产品,往往需要在一段时间内保存用户的模型权重,保存LoRA权重相比保存完整SD模型能节省很大的空间。
总结时刻
今天我们学习了定制化图像生成技术,包括Textual Inversion和DreamBooth这两种算法方案,以及如何使用LoRA来减少DreamBooth训练过程中的模型参数。
Textual Inversion技术通过新增一个或者多个可学习的词嵌入向量,只需3-5张图便可实现定制化图像生成。它的优点是不影响基础模型性能、得到的权重只是几百个浮点数,缺点是很多时候定制化生成的效果并不理想。
DreamBooth并不新增词嵌入向量,而是使用用户提供的3-5张图优化整个AI绘画模型。其优点是定制化生成的效果好。缺点是影响基础模型性能、得到的模型权重与原始模型相当,并且DreamBooth容易造成模型的过拟合,需要引入保留损失来抑制过拟合。
最后我们学习了LoRA这个技术。简单来说,它的工作原理是将处理一个大的权重矩阵的任务转变为处理两个较小的权重矩阵。这两个小的权重矩阵可以看作是原始大矩阵的一种分解表示。LoRA技术不仅可以用于大语言模型的训练,还能够用于AI绘画模型的微调。
这一讲的重点内容,我用导图方式做了整理,供你参考。
思考题
除了我们今天提到的LensaAI和妙鸭相机,你还知道哪些AI产品,用到了我们今天学习的定制化图像生成技术?
欢迎你在留言区和我交流讨论。如果这一讲对你有启发,也推荐你分享给身边更多同事、朋友。
- 易企秀-郭彦超 👍(5) 💬(3)
老师,关于Textual Inversion您有没有这方面的研究: 目前S需要输入几张图像进行训练才能获取对应的特征,去替换对应位置的clip embedding输入,那有没有一种不需要训练的方案, 比如我给一张或多张图,通过一个模型去提取对应的特征,然后将这些特征替换输入的文本token embedding,进而实现类似的效果,大大降低了使用成本,交互上也更便捷了
2023-08-28 - Seeyo 👍(3) 💬(2)
老师,请教两个问题 1、关于dreambooth和lora,除了计算能耗外,dreambooth的效果是否基本优于lora? 2、人物定制方面,我想定制多个人物,比如甲乙丙丁,在我实验dreambooth时,我先训练了甲,然后拿甲得到的模型去训练乙之后,发现模型的画质和画风大幅下降。请问多人物训练该如何通过dreambooth制定? 如果走lora路线,比如制作十个lora,让模型一同加载,是否会影响人物人脸的一致性?(这部分我还未开始实验) 想听听老师对于多人物定制的建议,因为线上部署时,希望模型初始化只发生在服务启动环节,后续不做模型的切换。
2023-08-28 - Toni 👍(1) 💬(1)
当训练某个LoRA1 时,基础模型W1 的参数保持不变。如果W1的维度是d1xd1, 训练LoRA1时调整两个矩阵 A1 和矩阵 B1 的权重,最后A1xB1的维度也将是d1xd1,因此输出的结果就可以表示为W1+ A1xB1。 问题1: 在使用LoRA1 时,基础模型只能选W1? 问题2: 使用LoRA1 时,如果选择了另一个基础模型W2,其具有d2xd2的维度,输出W2+ A1xB1是否会严重偏离预期? 如何评估这样的结果?
2023-08-29