16 显微镜下的Stable Diffusion(二):从图像变体到神雕侠侣(SDXL)
你好,我是南柯。
在上一讲,我们详细探讨了Stable Diffusion模型的核心技术,包括无分类器引导、UNet模块构成、负向描述词原理等。
事实上,随着AI绘画技术的不断发展,Stable Diffusion模型也在持续进化,比如2023年6月刚刚发布的SDXL模型。参考上一讲的叫法,为了方便,我们还是将Stable Diffusion简称为SD。
在SD模型家族中,有两个具有特殊能力的模型,也就是我们今天要探讨的SD图像变体(Stable Diffusion Reimagine)和“神雕侠侣”(SDXL)。SD图像变体模型用来对标DALL-E 2的图像变体功能,SDXL模型则用来和Midjourney这个最强画师掰掰手腕。
在我看来,生成图像变体和生成通用高美感图片,是当前多数开源垂类模型都做不好的事情。所以这一讲,我们把这SD中的两个特殊模型单独拿出来,用显微镜分析它们的能力和背后的算法原理。理解了这些之后,也会给我们向自己的SD模型引入新能力带来启发。
SD图像变体
你是否还记得,在关于DALL-E 2的解读中(可以回顾第13讲内容),我们提到了一种名为图像变体的图像生成策略。
我带你快速回忆一下这个策略的设计理念。用户输入一张图像,使用CLIP的图像编码器提取图像表征作为图像解码器的输入,这样就实现了生成图像变体的能力。图像变体能力在实际工作中能快速生成相似图像效果,激发我们的设计灵感。
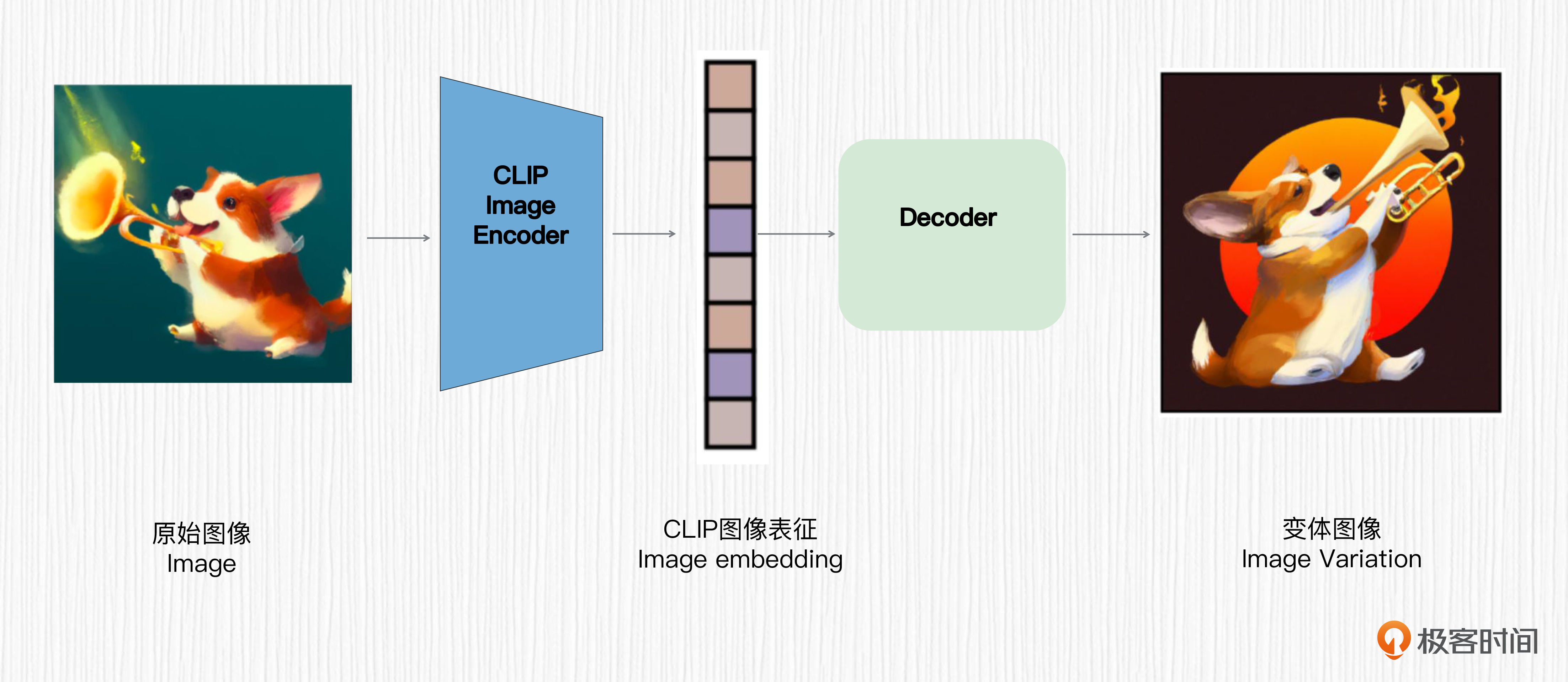
提到图像变体,你也许会联想到SD模型的图生图模式。但实际上,SD的图生图和我们今天要继续探讨的图像变体,在原理上和效果上是完全不同的。
在SD模型中,图生图能力通过重绘强度这个超参数向原始图像添加噪声,并根据prompt文本描述重新去噪得到新图像。这种方式生成的新图像在轮廓上会和原始图像非常接近,而内容和风格上则会更接近文本引导。
而图像变体,生成的图像与输入图像在色调、构图和人物形象方面具有相似性。你可以参考后面的图片,来看看图生图和图像变体的效果对比。
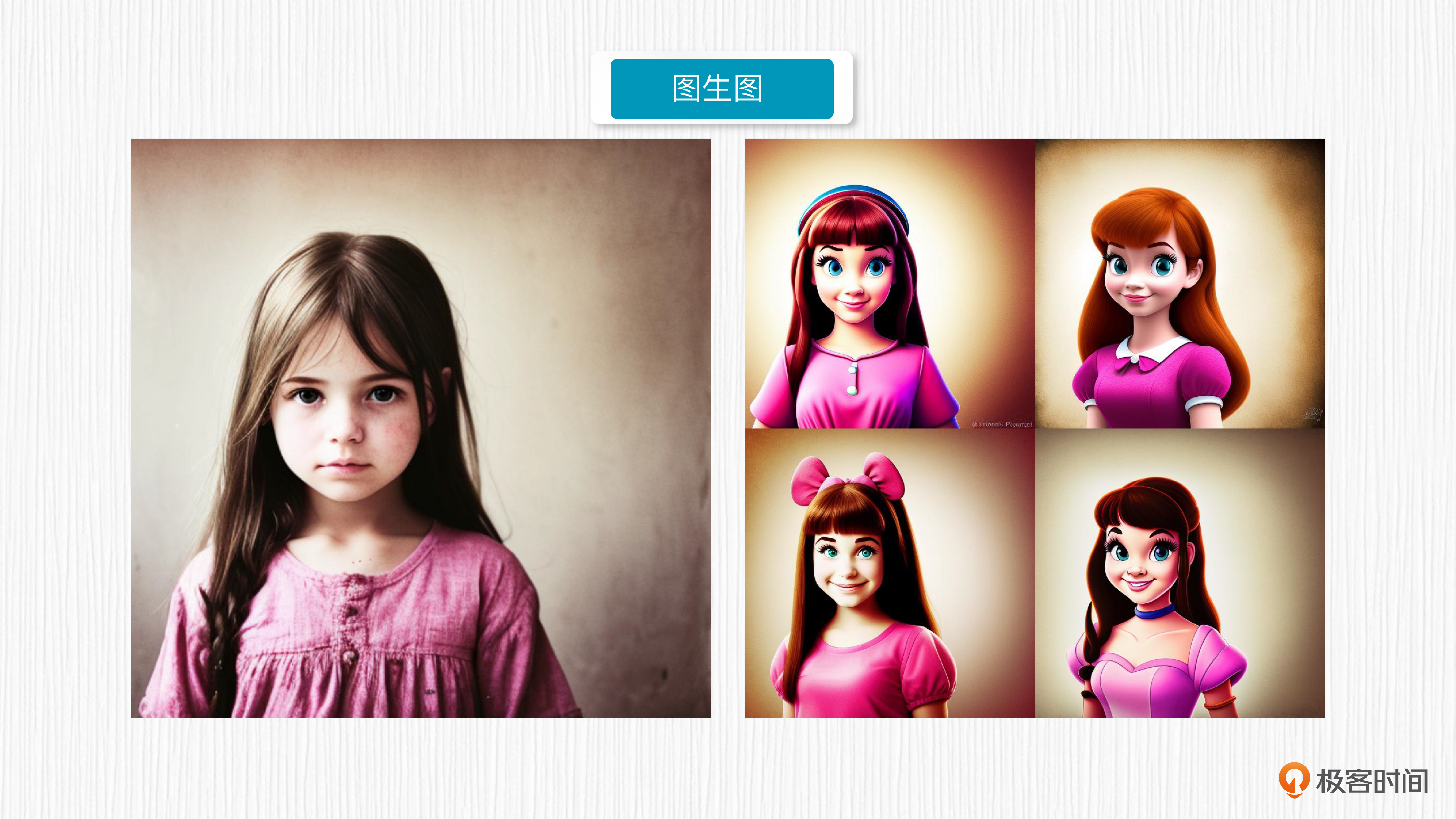
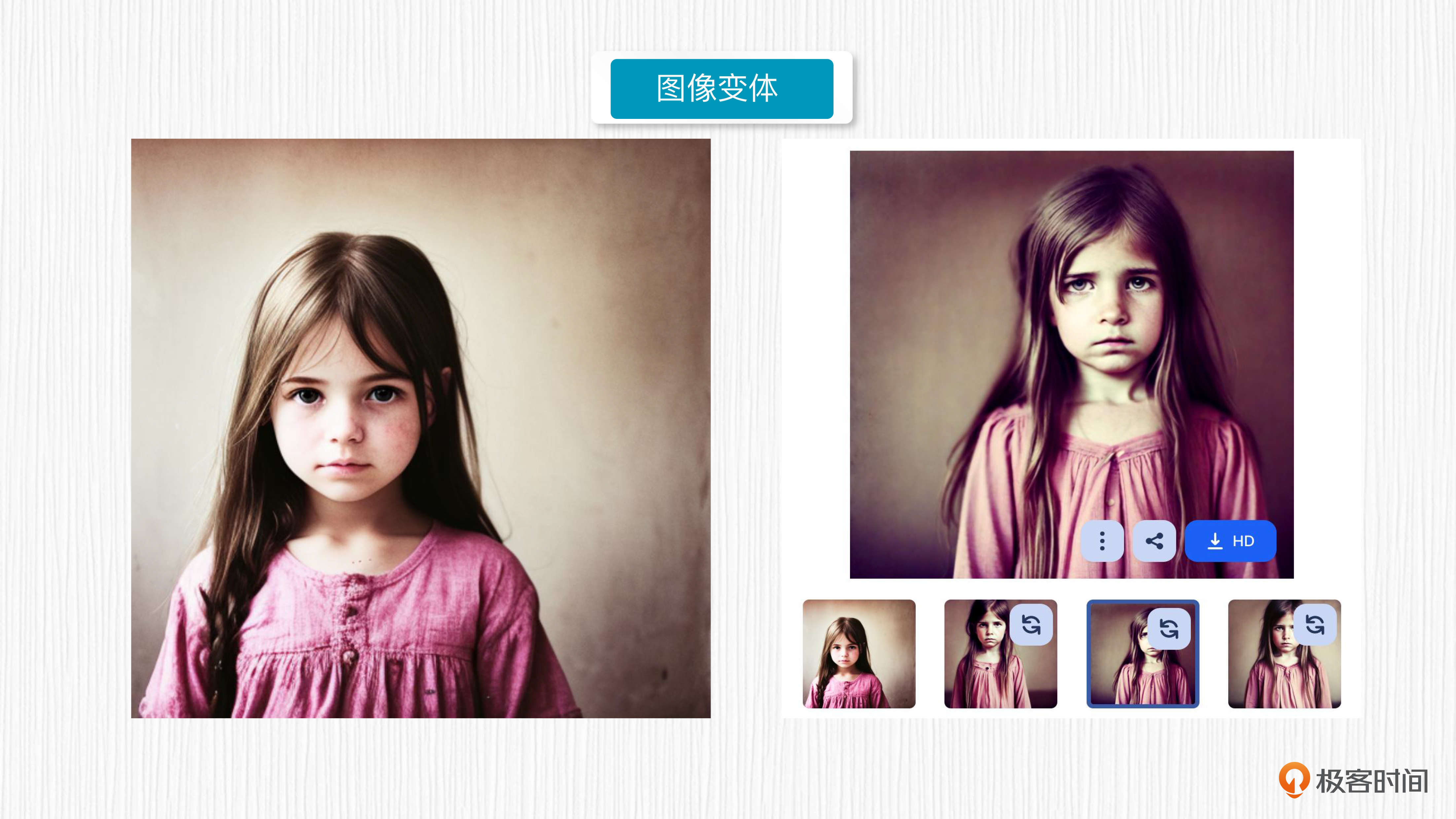
分析了这么多,我来给你稍微归纳一下。图生图和图像变体,它们都是以图像为主进行变化。图生图本质是依赖于prompt来引导相似轮廓下的内容变化;图像变体则以输入图像为基础,生成具有相似内容但不同样式的图像,过程不需要描述语句的引导。
SD图像变体的使用
那么,这种有趣且神奇的图像变体能力,是否只有DALL-E 2才具备呢?
事实上并非如此。接下来,我们就来看看如何利用SD模型实现图像变体,即SD图像变体能力(Stable Diffusion Reimagine)。

不需要复杂的prompt,SD图像变体功能从图像中提取需要使用的信息,帮助用户生成输入图片的多种变化。那么,相比标准SD模型(比如SD1.5等),SD图像变体模型究竟有何区别呢?
不妨拿出我们的显微镜来看一看。SD图像变体实际上是一个全新的SD模型,其官方名称为Stable unCLIP 2.1。没错,与DALL-E 2一样,它也属于unCLIP模型,也就是我们第10讲CLIP模型的扩展版。我们回顾下CLIP和unCLIP的算法原理。
CLIP通过4亿图文对数据进行对比学习,得到一个图像编码器和一个文本编码器。在使用CLIP时,成对的图像文本经过对应模态的编码器后,得到的特征会更接近。

而DALL-E 2 利用CLIP图像编码器提取图像表征,得到的图像表征直接通过扩散模型解码器生成变体图像。这个过程被称为 unCLIP。
了解了这些,我们再来看SD图像变体的能力。SD图像变体模型是基于SD2.1模型微调而来的,能生成768x768分辨率的图像。在我编写这一讲的内容时,WebUI尚未集成SD图像变体模型。如果你想使用这个模型,可以使用官方平台Clipdrop试试效果,或者按照Hugging Face中提供的代码示例进行操作。
首先,我们看一下如何通过官方平台实现图像变体功能。打开Clipdrop后,我们只需上传图像,耐心等待一会,便可以看到SD图像变体模型生成的新图像。
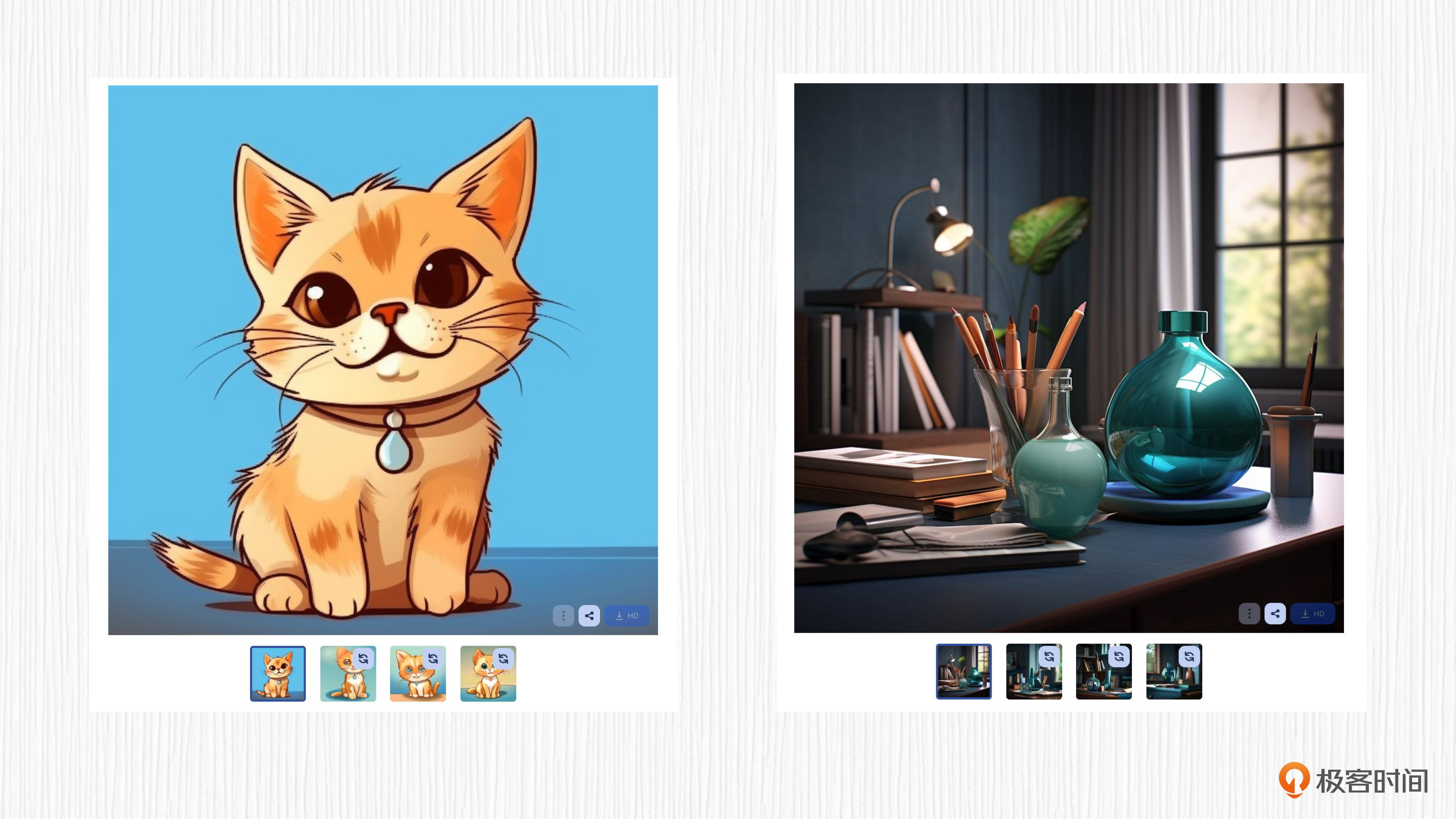
为了看图更直观,我们可以将变体图像下载到本地查看。


虽然在平台上使用图像变体功能非常方便,但如果想调整参数和批量生成图像变体,更推荐你用写代码的方式调用。
标准的SD图像变体用法,我们可以采用后面的方式来调用。你可以点开 Colab 一起进行操作。
from diffusers import StableUnCLIPImg2ImgPipeline
from diffusers.utils import load_image
import torch
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16")
pipe = pipe.to("cuda")
# 这里的url可以换成你想测试的图片url链接
url = "https://ice.frostsky.com/2023/08/13/ec9539fef32052dac71f19c11d76ab6c.png"
init_image = load_image(url)
images = pipe(init_image).images
images[0].save("variation_image.png")
我来给你解释下这段代码。首先,我们从官方仓库下载SD图像变体模型。然后,我们使用一张“在祈祷的猫咪图像”作为输入,调用SD图像变体模型完成图像生成。这里,你也可以使用自己的图像替换掉上面第10行代码中的图片链接。

图中两只猫咪在“气质上”确实比较相似。你应该已经注意到,在上面的生成过程中,我们并没有使用prompt。也正因此,生成图像变体的过程并不是很可控,比如上面的猫咪没有呈现出祈祷的姿势。
为了更好地控制图像变体,我们也可以设置prompt语句。你可以参考后面的代码。
from diffusers import StableUnCLIPImg2ImgPipeline
from diffusers.utils import load_image
import torch
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
)
pipe = pipe.to("cuda")
url = "https://ice.frostsky.com/2023/08/13/ec9539fef32052dac71f19c11d76ab6c.png"
init_image = load_image(url)
images = pipe(init_image).images
images[0].save("variation_image.png")
prompt = "A praying cat"
images = pipe(init_image, prompt=prompt).images
images[0].save("variation_image_two.png")

使用prompt引导图像变体生成的关键在于前面代码的第18行。在生成过程中,我们引入了新的参数prompt。
我们已经知道,DALL-E 2的图像变体功能是不能使用prompt的,那么问题来了,为什么SD图像变体却可以使用prompt呢?接下来,我就带你探索一下这背后的原因。
技术细节探究
带着我们前面的疑问,咱们从源代码入手来“破案”。
根据SD图像变体的源代码(StableUnCLIPImg2ImgPipeline ),我们发现输入的图像首先会进入 _encode_image这个函数,这个函数负责将输入图像转为图像表征。
# 4. Encoder input image
noise_level = torch.tensor([noise_level], device=device)
image_embeds = self._encode_image(
image=image,
device=device,
batch_size=batch_size,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
noise_level=noise_level,
generator=generator,
image_embeds=image_embeds,)
接下来,我们分析一下图像表征的注入方式。实际上,图像表征是在UNet模型每次预测噪声的过程中引入的。
我们已经知道,标准SD中UNet的输入包括文本表征、上一步去噪后的潜在表示以及时间步t的编码。而在SD图像变体方案里,除了刚提到的三项标准输入,代码中多了 “class_labels = image_embeds” 这一项(第6行),这正是它与其他SD模型不同之处。
你可以这样理解,SD图像变体模型的prompt作用机制和其他SD模型是相同的,而参考图像的信息是额外新增的。
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
class_labels=image_embeds, # 破案的关键,输入了图像的表征
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]
为了更深入了解这个过程,我们可以进一步探究SD图像变体模型UNet 预测噪声的代码,这里我只截取了关于图像表征(image_embeds)使用方式的部分。在代码最后一行,SD图像变体模型将图像表征与时间步的编码做了相加处理。通过这种方式,参考图像便可以直接影响我们的生成结果。
emb = self.time_embedding(t_emb, timestep_cond)
if self.class_embedding is not None:
if class_labels is None:
raise ValueError("class_labels should be provided when num_class_embeds > 0")
if self.config.class_embed_type == "timestep":
class_labels = self.time_proj(class_labels)
class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
emb = emb + class_emb
至此,我们找到了关键所在。SD图像变体模型不仅可以输入参考图生成变体,同时还能使用prompt进行引导。这个过程与DALL-E 2的图像变体能力是截然不同的。
“神雕侠侣”
除了SD图像变体模型外,SD系列最近亮眼的更新莫过于“神雕侠侣”(SDXL)这个模型了。
我们已经知道,标准SD模型和SD图像变体模型,都是StabilityAI这家公司推出的开源AI绘画模型,在Hugging Face、Civitai这些论坛备受追捧。但遗憾的是,Midjourney在AI绘画生成效果上始终一骑绝尘。
可能是为了证明SD模型同样拥有无限的AI绘画潜力,StabilityAI决定大力出奇迹,开发一款能与Midjourney效果相匹配的模型。于是,SDXL便应运而生。
初识SDXL
2023年6月,Stable Diffusion XL 0.9 正式发布,我们先来看看它的AI绘画效果。当我写这一讲的时候,SDXL1.0版本也已经正式发布。

论文中也将SDXL和DeepFloyd IF、Midjourney v5.2、DALL-E 2等方案做了对比。这个比较很有意思,在相同prompt下测试了当下各个最强的AI绘画模型。你可以点开大图做一下对比,选择你心中的top1。

我们可以看出相比于其他版本的SD模型,比如SD1.5、SD2.1等,SDXL的提升也非常明显的。不仅生成的图像瑕疵更少,图片被裁切的情况也得到明显改善。你可以点开图片查看。

看了这么多效果,你一定也很好奇,这是怎么做到的呢?我们这就来探索一下SDXL背后的技术细节!
SDXL的整体方案
SDXL采用级联模型的方式完成图像生成。所谓级联模型,就是将多个模型按照顺序串联,目的是完成更复杂的任务。
SDXL将Base模型和Refiner模型进行串联,整体方案你可以参考后面这张图。

我们知道SD1.x系列模型的潜在表示是64x64维度,而SDXL为了生成更高清的图像,直接在128x128维度的潜在表示上进行去噪计算。Base模型的整体思路和SD模型一致,不过它更换了更强的CLIP、VAE模块,使用了更大的UNet模型。
Base模型去噪后的潜在表示,也使用了较低的加噪步数(比如200步)进行加噪,对Refiner进行训练。
Refiner模型的作用有点类似于我们的图生图功能。该怎么理解呢?
Base模型已经生成了我们要的图像,默认分辨率是1024x1024。然后我们给这张图像加上少许噪声,Refiner模型负责二次去除这些噪声。较低的加噪步数类似于我们知道的重绘强度,避免加噪到纯粹的噪声,那样的话就很难保持第一阶段图像的“绘画成果”了。总之,引入Refiner这个模型,可以进一步提升AI绘画的效果。
经过Refiner得到的潜在表示,经过VAE解码后,便可以直接得到1024x1024分辨率的图像。
新的VAE、CLIP和UNet
SDXL模型没有沿用SD1.x和SD2.x模型中使用的VAE模型,而是基于同样的模型架构,使用更大的训练batch_size来重新训练VAE。
我们在第11讲也提到过,VAE决定了SD模型生成图像的上限,未经过单独调优的VAE并不擅长处理小脸和细节的重建。而SDXL单独训练的VAE模型,在各种图像生成评测任务上都有明显提升。

说完VAE,再来看CLIP。SD1.x系列使用的是CLIP ViT-L/14这个模型,该模型来自OpenAI,参数量是123M。而SD2.x系列将文本编码器升级为OpenCLIP 的ViT-H/14模型,参数量是354M。
SDXL更进一步,使用了两个文本编码器,分别是OpenCLIP的ViT-G/14模型(参数量694M)和OpenAI的ViT-L/14模型。在实际使用中,分别提取这两个文本编码器倒数第二层的特征,将1280维特征(Vit-G/14)和768维特征(ViT-L/14)进行拼接,得到2048维度的文本表征。
我们在Imagen那一讲已经提过,拥有更强的文本表征能力,就意味着AI绘画模型更能听懂我们的指令。
我们再来看看SDXL中的UNet模型结构。相比于上一讲标准SD模型的UNet,SDXL的CADB模块(CrossAttnDownBlock2D)只有两层,UNet最终的潜在表示维度也从8x8提升到了32x32。同时,在CADB内部,SDXL也使用了更多层的Transformer结构。
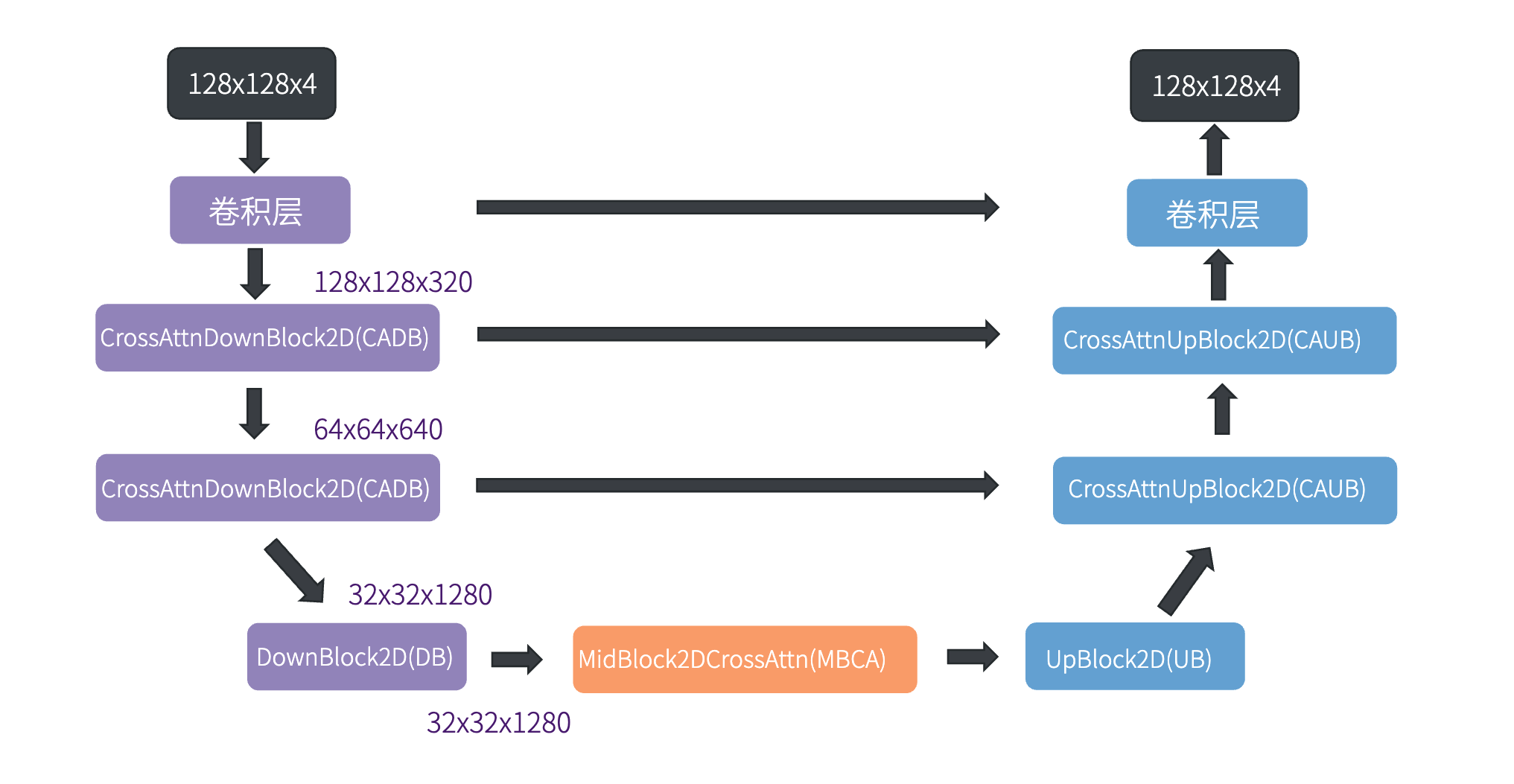
了解完这些技术细节,相信你会对“大力出奇迹”背后的含义理解更深刻。值得一提的是,SDXL的UNet有2.6B参数量,相比于DeepFloyd IF模型的4.3B参数量,还是“小巫见大巫”。

SDXL的使用
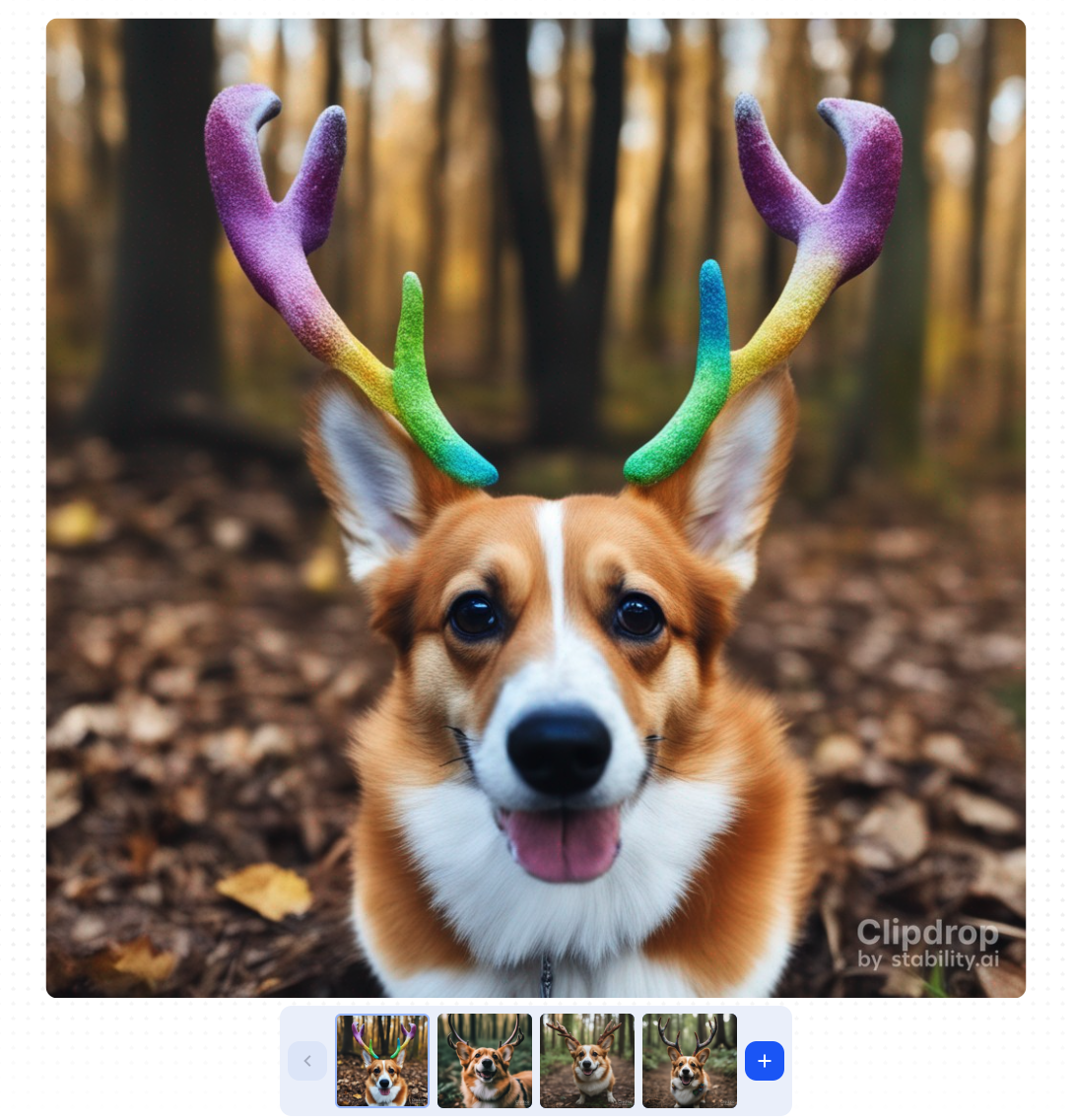
最后我们上手体验一下,看看SDXL这个模型怎么用。最简单的方法依旧是使用官方平台 clipdrop 或者 dreamstudio。比如我们在中心区域输入我们想要生成的图像,“一只长着鹿角的彩虹色柯基犬”。
我们还可以测试一下SDXL在图片中写文字的能力,比如我们要求其绘制这样一幅画:一个飞行在天空的热气球,挂着一个边缘镶嵌满鲜花的木板,木板上写着“Geekbang”。
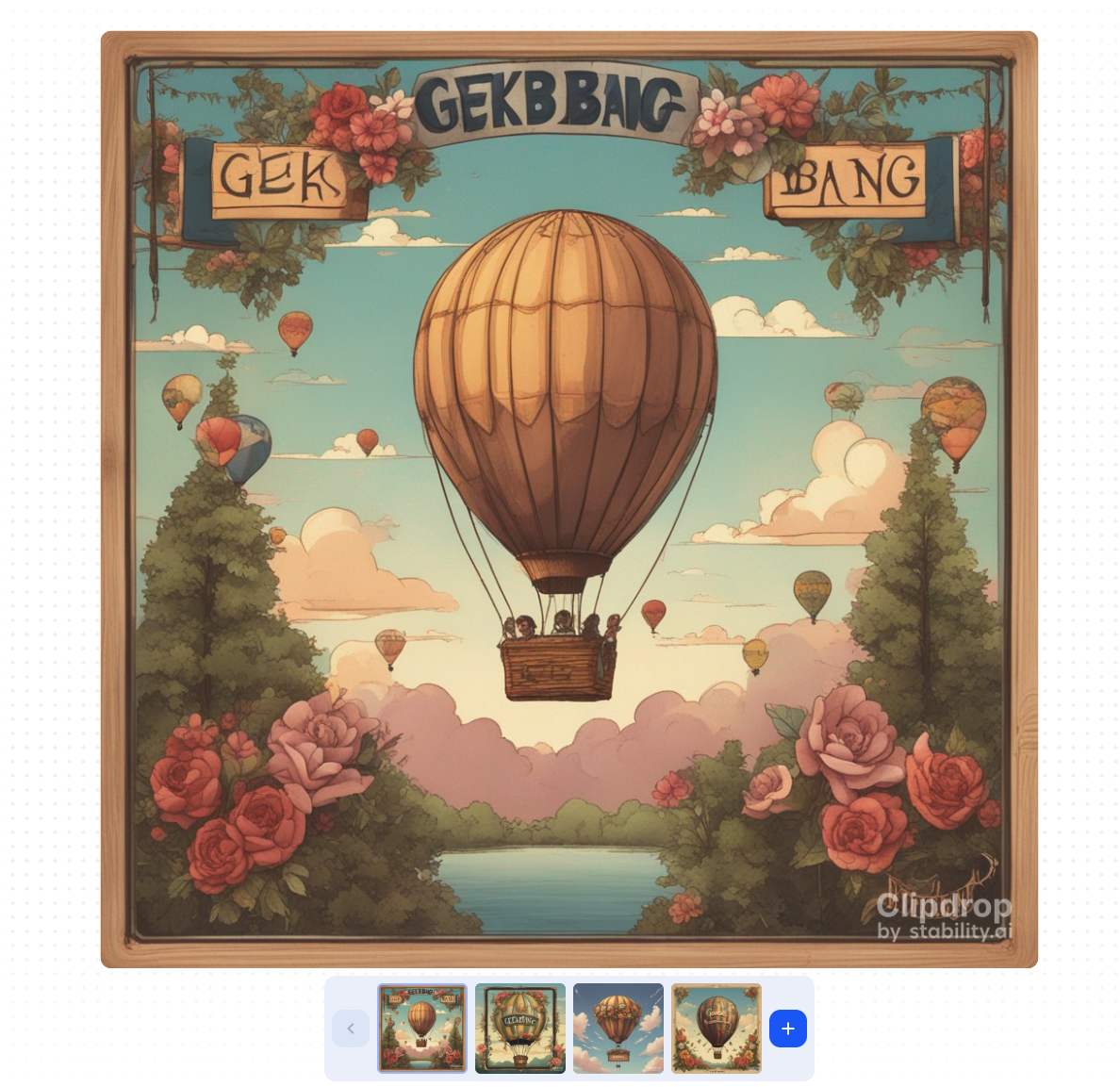
从图片结果看,并不理想。你还记得这个prompt下DeepFloyd模型的表现么?DeepFloyd模型是可以胜任这个任务的。从这个测试我们可以知道,SDXL的文本编码器还有一定的提升空间。
当然我们也可以通过写代码的方式使用SDXL模型批量生成图像。你可以点开 Colab链接,了解更多的代码细节。需要说明,使用SDXL的Refiner模型生成1024x1024分辨率的图片,需要较多GPU显存,Colab 15G的T4显卡不能胜任这个任务。推荐使用V100-32G这个性能的显卡来运行这个Colab。
可以看到,代码中我们加载了Base和Refiner两个扩散模型,AI绘画的过程也是使用这两个模型通过“接力”的方式生成的。
from diffusers import StableDiffusionXLPipeline, StableDiffusionXLImg2ImgPipeline
import torch
# 下载并加载SDXL1.0的Base模型,未来SDXL模型更新新版本,需要根据实际情况替换版本号
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipe.to("cuda")
# 下载并加载SDXL1.0的Refiner模型,未来SDXL模型更新新版本,需要根据实际情况替换版本号
refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
)
refiner.to("cuda")
prompt = "ultra close-up color photo portrait of a lovely corgi"
use_refiner = True
# Base模型生成图像
image = pipe(prompt=prompt, output_type="latent" if use_refiner else "pil").images[0]
# Refiner模型生成图像
image = refiner(prompt=prompt, image=image[None, :]).images[0]
我们对比下Base模型和Refiner模型生成的图像效果,可以发现,Base模型和Refiner模型生成的图像效果都不错,而Refiner在细节上更胜一筹。
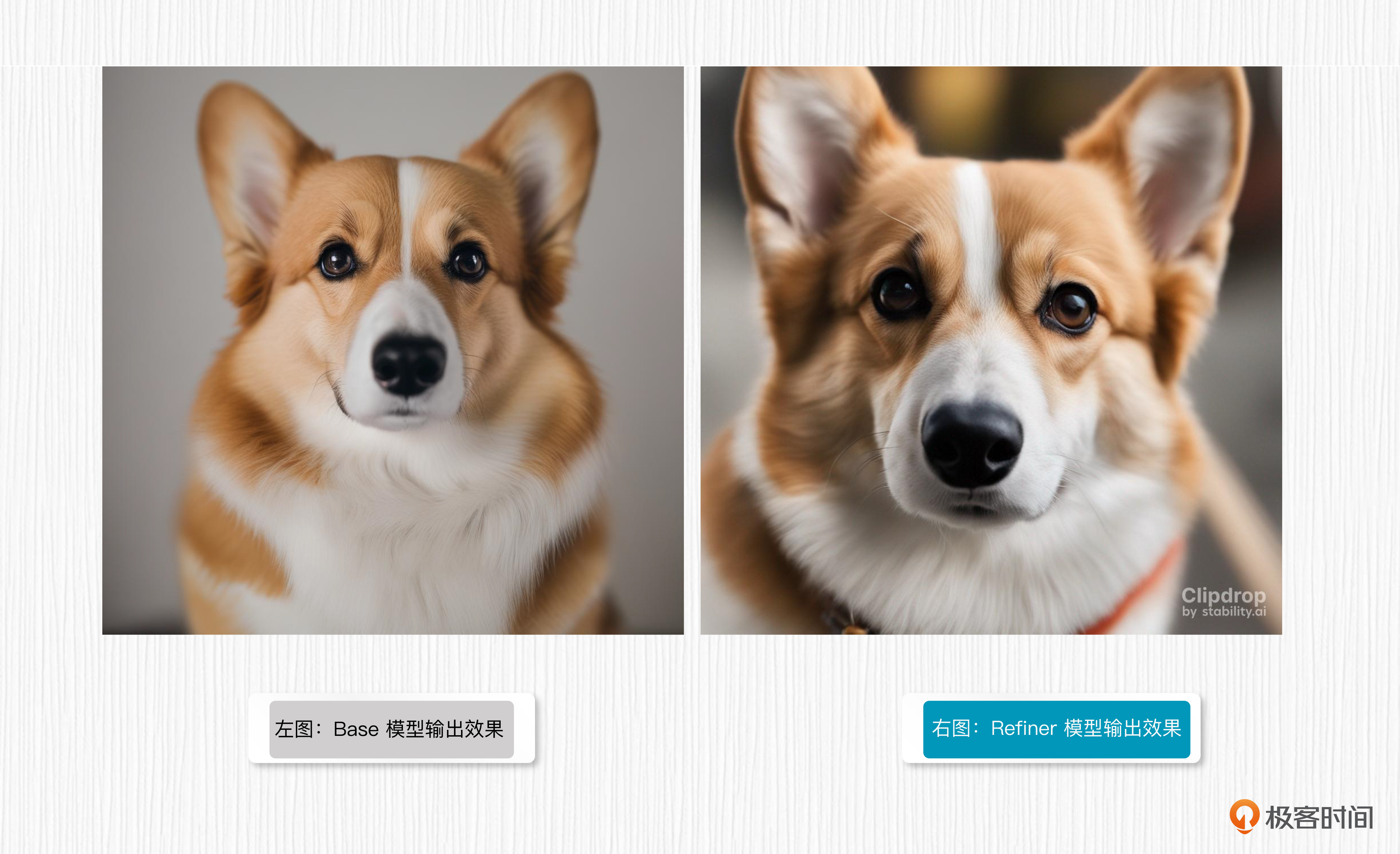
左边的图片是Base模型输出效果,详情你可以参考 Colab代码链接。右边的图片则是Refiner模型输出效果,是通过 Clipdrop 平台生成的。
事实上,6月底发布的SDXL0.9版本相当于测试版,StabilityAI这家公司根据用户体验反馈针对性补充了训练数据,同时还引入了RLHF技术(人类反馈强化学习),才完成SDXL1.0模型的优化。下面这张图对比了0.9和1.0版本的AI绘画效果,直观感受上差别不大。

到这里,我们已经掌握了SDXL的算法原理和使用方法,现在你可以在 clipdrop 上使用SDXL创作更多有意思的AI绘画作品了。
课程小结
这一讲,我们学习了SD系列两个有意思的模型,分别是SD图像变体和SDXL模型。
SD图像变体和DALL-E 2有异曲同工之妙,都可以输入一张图像产生多张变体,从而帮我们完成相似图像的生成任务。不同之处在于,SD图像变体可以使用额外的prompt,引导模型生成图像变体,而这一点,DALL-E 2是无法做到的。我们详细探讨了这背后的原因。
SDXL是SD系列“大力出奇迹”的结果,目标是在AI绘画效果上挑战Midjourney。SDXL用了两个强大的CLIP文本编码器,重新训练了VAE模型,而且引入了更多参数的UNet结构。与此同时,SDXL还使用级联模型的方式进一步提升AI绘画效果。
今天学到的两个模型都可以通过官方平台 clipdrop 进行体验。在这些新能力的加持下,也期待你能生成出更多有趣的作品。
思考题
SD图像变体与SDXL分别具有哪些优势和特点,可以应用于哪些场景中?
期待你在留言区和我交流互动,如果这一讲对你有启发,也推荐你发给身边更多朋友。
- Wiliam 👍(2) 💬(1)
老师,能从原理上解释一下为什么加入Refiner 模型之后,效果能更好呢?
2023-09-29 - zhihai.tu 👍(1) 💬(1)
目前最新版本的webui中,这两个特殊模型是否已经集成进去了啊?
2023-08-23 - Geek_55d08a 👍(0) 💬(1)
"SDXL 模型没有沿用 SD1.x 和 SD2.x 模型中使用的 VAE 模型,而是基于同样的模型架构," 这句话是有笔误么?
2023-09-05 - Seeyo 👍(0) 💬(1)
老师请问一下,关于batch处理的问题。 测试阶段: 1、我目前的理解是不能用batch进行不同text prompt对应图片的处理,是因scheduler的处理方式是自回归吗? 2、当使用相同的promot时,因为webui支持批量生成,为什么此时可以使用batch的生成方式?虽然text产生的embedding相同,但每个推理时刻,产生的x_t-1是不一样的。 训练阶段: 要使用ddpm采样器,为什么能使用batch训练呢? 以上是目前的个人理解,期待老师的回答指正
2023-09-04 - peter 👍(0) 💬(1)
请教老师两个问题: Q1:模型的数学推导主要用哪些方面的知识?微积分吗? Q2:图像变体每次运行的结果都是不同的吗?
2023-08-24 - 海杰 👍(0) 💬(1)
老师,既然提到SDXL, 会讲下ComfyUI 的使用吗?
2023-08-23 - YX 👍(0) 💬(0)
SDXL 更进一步,使用了两个文本编码器,分别是 OpenCLIP 的 ViT-G/14 模型(参数量 694M)和 OpenAI 的 ViT-L/14 模型。在实际使用中,分别提取这两个文本编码器倒数第二层的特征,将 1280 维特征(Vit-G/14)和 768 维特征(ViT-L/14)进行拼接,得到 2048 维度的文本表征。 ------ 老师请问下,这句话是不是意味着对于SDXL模型,clip skip可以不需要再设置了呢
2024-02-12 - Charles 👍(0) 💬(1)
老师,怎么实现将中文嵌入图片中呢?这些都是只支持英文的,对中文不友好。 比如:生日卡片,有气球和生日蛋糕,卡片上写着“XX生日快乐”
2023-10-27 - Wiliam 👍(0) 💬(0)
老师,能从原理上解释一下,为什么引入了Refiner 模型,效果能更好呢?
2023-09-29