14 挑战者Imagen:为什么会后来居上?
你好,我是南柯。
上一讲我们一起探索了OpenAI推出的DALL-E 2背后的技术原理。仅仅过去一个月,在2022年5月,Google便发布了自己的AI绘画模型Imagen。Imagen在效果上显著优于DALL-E 2,并且通过实验证明,只要文本模型足够大,就不再需要扩散先验模型。
一年之后,2023年的4月28日,后来者StabilityAI,也就是搞出来Stable Diffusion这个模型的公司,发布了DeepFloyd模型。这个模型完美地解决了DALL-E 2不能在生成图像中指定文字内容的问题,是当下公认的效果最好的AI绘画模型之一。并且,DeepFloyd模型的技术方案,恰恰就是我们今天要讲的主角Imagen。
今天这一讲我们来探讨Imagen背后的技术,主要搞清楚以下几个问题。
第一,相比DALL-E 2,Imagen在能力上有哪些优势?
第二,Imagen的工作原理是怎样的?
第三,DeepFloyd又在Imagen的基础上做了哪些改进?
明白了这些,你会对AI绘画技术的发展趋势理解更深刻,在选择AI绘画模型时也会更加得心应手。让我们开始吧!
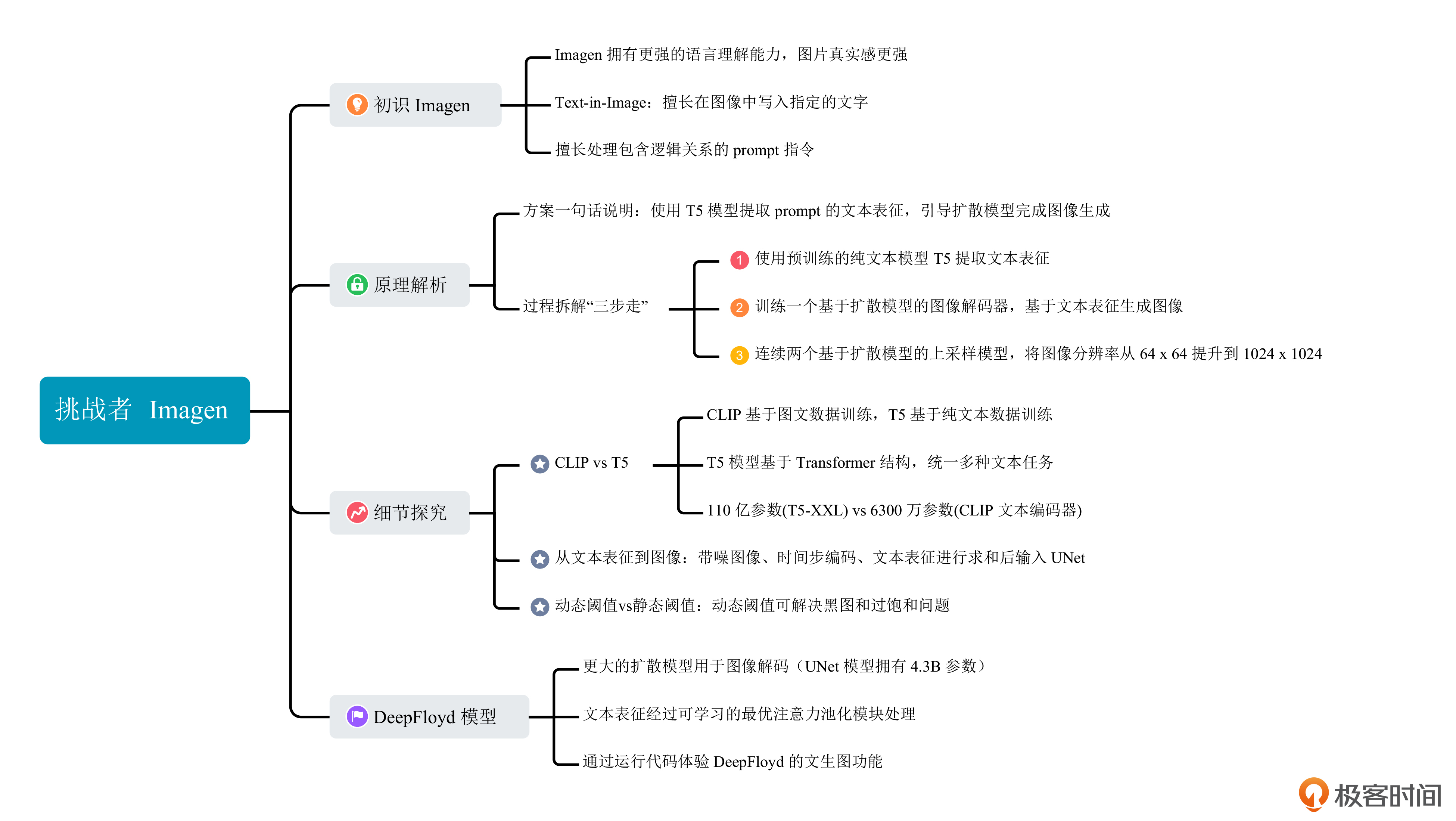
初识Imagen
我们先来看看Imagen模型在AI绘画这个任务上的表现,建立一个直观感受。

Imagen可以在生成的图像中指定写入的文字,之后我们简称这个能力为“Text-in-Image”。这项能力上,DALL-E 2和Imagen的效果对比如下图所示。

另外,上一讲我们说过DALL-E 2不擅长处理逻辑关系,而Imagen在这个问题上明显表现得更好。下面这幅图对比了DALL-E 2和Imagen处理逻辑关系类prompt的生成效果。

在Imagen的论文中,作者认为Imagen的两个核心优势是:图像真实感(photorealism)和更强的语言理解能力(language understanding)。我们结合前面这些例子也能看出 ,Imagen生成的图像在真实感、文本理解这两项能力上的表现确实非常惊艳。
前面我们说的DeepFloyd模型也是基于Imagen架构训练得到的,这个模型的AI绘画效果你可以参考下图。

可以看到,Imagen及其后来者都拥有强大的AI绘画能力。那挑战者Imagen为什么能够后来居上?这就不得不说到Imagen背后的工作原理了。
工作原理
我们先来看一下原论文中给出的Imagen整体方案流程。详情你可以参考项目官网的链接。

可以看到,文本描述经过文本编码器得到文本表征(Text Embedding),该文本表征不仅用于引导低分辨率图像的扩散生成,也用于指导连续的两个超分模块发挥作用。和我们前面学的DALL-E 2类似,Imagen首先会生成64x64分辨率的低分辨率图像,然后经过连续两次基于扩散模型的超分模块,将图像分辨率提升至256x256、1024x1024。
训练过程中,首先要将文本表征、初始噪声作为扩散模型的输入,去噪后的图像作为目标输出,就得到了低分辨率扩散模型;然后将低分辨率图像、文本表征作为输入,去噪后的图像作为目标输出,得到更高分辨率的扩散模型。
这么说有点抽象,你可以对照下面的过程示意图来加深理解。

你可能会问,Imagen相比于DALL-E 2,好像差不多?事实上,Imagen相比于DALL- E 2在方法上主要有三点不同。
第一,Imagen没有使用CLIP的文本编码器和图像编码器,而是直接使用纯文本大模型T5来完成文本编码任务。
这里做一个对比,Imagen用到的T5模型(T5-XXL)参数量共计110亿,CLIP的文本编码器参数量约为6300万。也就是说,Imagen的文本编码器参数量大约是DALL-E 2的200倍左右,这意味着Imagen拥有更强大的文本描述理解能力。站在语言模型的角度看,参数量越大,文本理解能力越强。我们熟悉的ChatGPT背后的GPT-3语言模型,有1750亿参数。
第二,Imagen没有使用unCLIP结构,而是直接把文本表征输入给图像解码器,生成目标图像。
第三,Imagen对扩散模型预测的噪声使用了动态阈值的策略,提升了AI绘画效果的稳定性。这一点我们稍后解释。
正是基于这样的方案改进,Imagen模型才能处理更复杂的文本描述,生成惊艳的绘画效果。为了让你更深入地理解Imagen,我们接下来便深入分析下这三个改进点。
T5模型提取文本表征
我们先看第一个改进点,为什么要选择T5模型,和CLIP相比T5的优势是什么?
要回答这个问题,就需要明白T5模型是怎么训练的。T5模型源自于2020年Google发布的一篇论文,使用Transformer结构,将翻译、问答、文本相似度估计等任务统一到一个模型中。
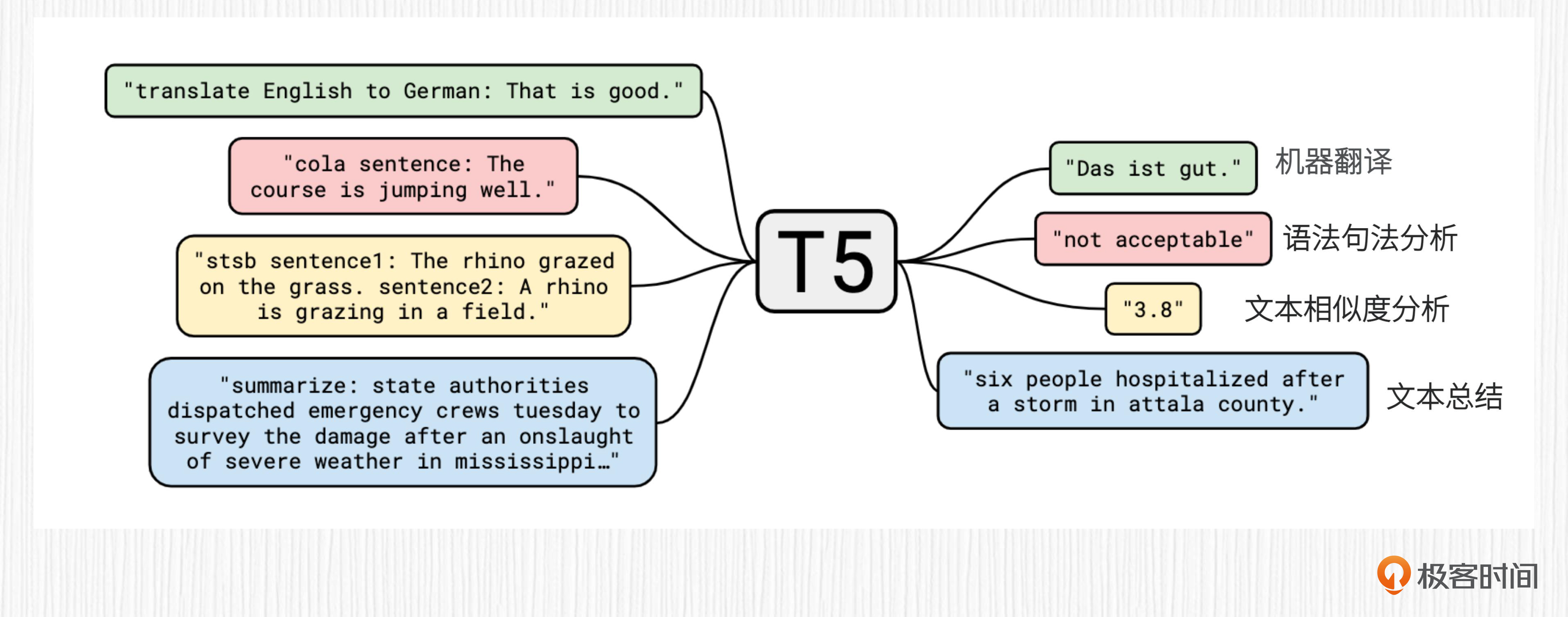
关于T5模型的统一训练方案,我们结合例子会更好理解。
对于翻译类任务,训练数据的输入部分需要加上一句指令,比如 “translate English to German”。以前面图示里翻译的句子为例,模型的输入是 “translate English to German: That is good.”,模型输出应该是翻译后的德文 “Das ist gut.”。
对于情感分析任务,训练数据的输入部分应该添加的指令为 “sentiment”,比如模型的输入可以是 “sentiment: This music is perfect.”, 模型输出的结果应该是 “positive”。
需要注意的是,T5模型的训练使用的是纯文本语料,而不是像CLIP那样需要使用文本-图像数据对。如果你想了解关于T5模型的更多细节,可以点击链接访问项目官网。
对于CLIP的训练过程,训练目标是对应的图像、文本描述的特征向量的余弦距离越大,让不对应的图像、文本描述之间的余弦距离尽可能小。这个过程必须要用成对的图文数据。

比起图像-文本成对数据,纯文本数据要更容易获得。图像-文本成对数据常用的Laion-5B数据集,也只包含50亿成对数据。而我们熟悉的大语言模型ChatGPT的训练语料又何止百亿规模。
由此,我们可以得到两个推测。
第一,由于训练数据的规模不同,T5相比于CLIP,拥有更强的文本信息提取能力。
第二,相比于大语言模型,AI绘画模型在数据规模上还有很长的路要走,大力仍能出奇迹。
从实验的结果看,T5模型确实能够更好地提取文本信息,“Text-in-Image” 类的效果就足以说明这个问题。
从文本表征到图像
那么,T5模型提取的文本表征如何指导扩散模型生成高清图像呢?为什么说Imagen不是unCLIP的方案?
要回答这个问题,还要从扩散模型的训练说起。我们已经知道,扩散模型的主要功能是从噪声通过多步去噪的过程,得到一张清晰的图像。你可以先回顾下这个过程的图解,再听我继续分析Imagen算法背后的原理。
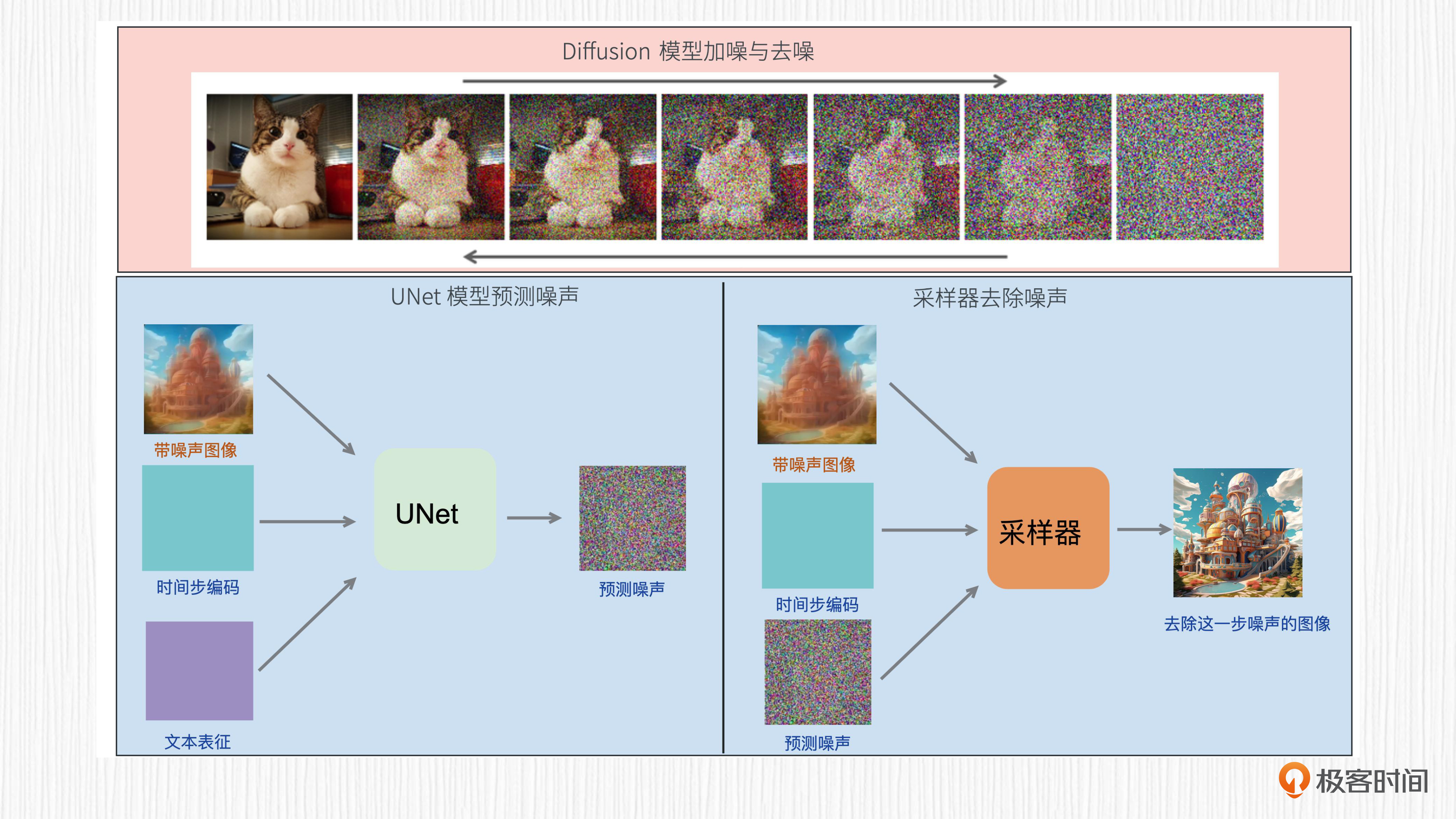
扩散模型生成图片的过程需要多个采样步,每一步都使用权重共享的UNet结构。对于文生图任务来说,UNet的输入信息包括当前带噪声的图像、时间步编码、文本表征编码。对于扩散模型细节感兴趣的同学可以复习第6讲。
在Imagen项目中,图像解码器使用的同样是扩散模型。扩散过程需要多步来完成,逐渐从噪声得到清晰图像。对于每一步去噪,Imagen都会将当前带噪声图像、时间步编码、文本表征编码进行求和,作为UNet模型的输入信息,如下图所示。
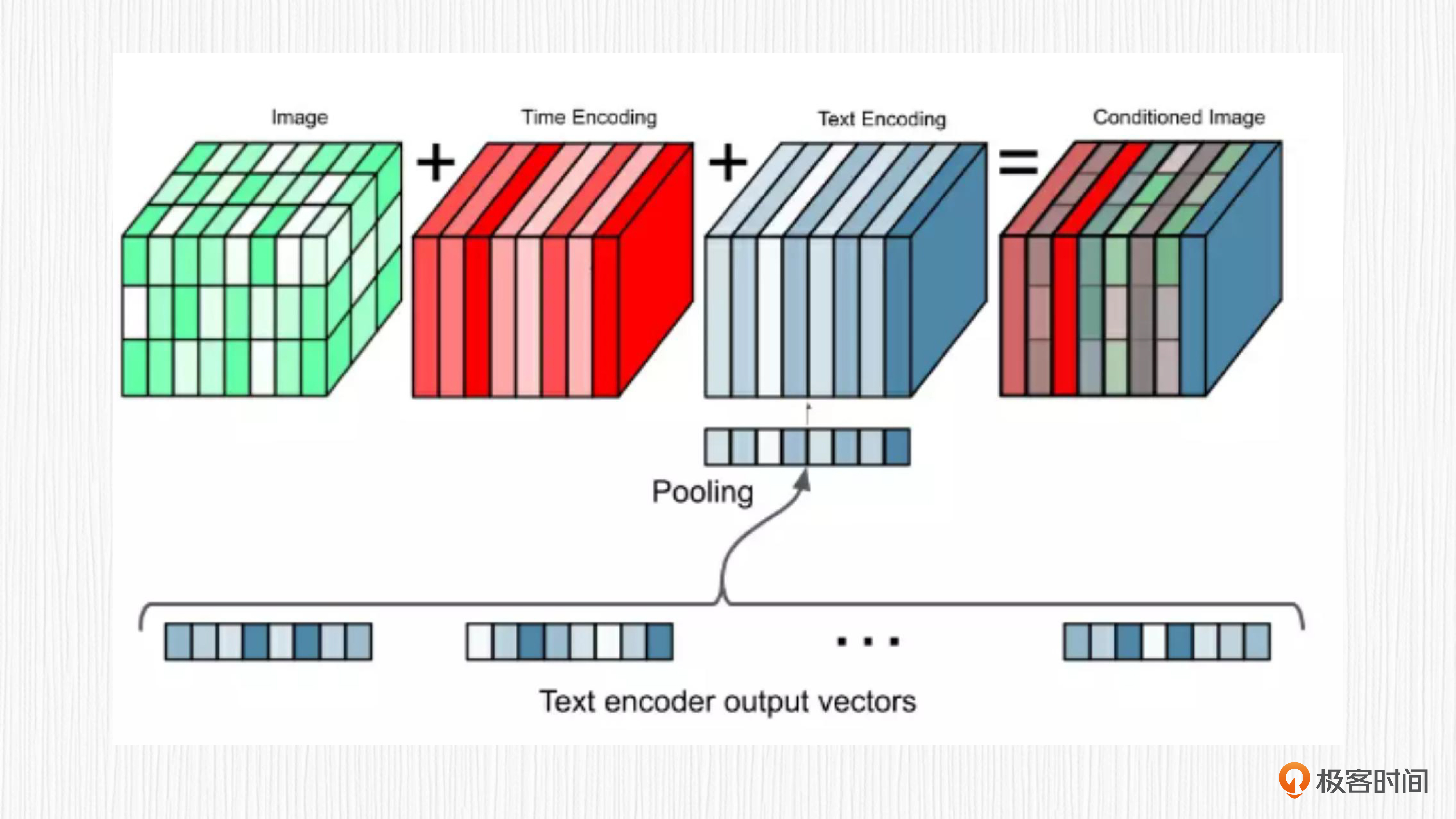
通过这种方式,T5模型提取的文本表征就能直接用来指导图像的生成了。细心的你应该已经发现了,这个过程既没有用到CLIP,也没有文本表征到图像表征的显式转换,自然就不是unCLIP的方案了。
巧用动态阈值策略
讨论完文本编码器,我们再来看看动态阈值(Dynamic Threshold)策略为什么能生成更真实的图像。
在扩散模型生成图像的过程中,每一步都会预测一个噪声值,然后基于采样器去除这个噪声。Imagen的作者发现,预测的噪声如果在数值上不做约束(比如限制到-1到1的范围),最终可能会生成纯黑图像。静态阈值策略可以用于缓解这个问题。
它的做法是把UNet预测的噪声超过1的部分全部设置为1,小于-1的部分全部设置为-1。静态阈值是一种常见的噪声图数值处理方法。作者实验发现使用静态阈值虽然有效果,但还是会产生图像过度饱和的问题。
在已有静态阈值的基础上,作者又提出了动态阈值的策略,解决了AI绘画过程中的黑图、过饱和等问题。
具体就是先确定一个百分比,比如90%。对于每一步去噪,都可以计算出一个数值s,噪声图中90%的元素都位于-s到s的范围内。小于-s的部分全部设置为-s,大于s的部分全部设置为s。然后对于所有元素都除以s,将最终噪声图标归一化到-1到1的范围。
这种策略可以有效地动态约束每一步去噪过程的数值范围,提升文生图过程的稳定性。
DeepFloyd IF
讲完Imagen的技术原理,我们再来研究StabilityAI最新推出的DeepFloyd IF模型时,就更好理解了。该模型的整体结构是后面这样,你有没有觉得它很眼熟?

没错,它和Imagen的结构一模一样。然而,DeepFloyd IF这个模型,在生成图像的效果上显著优于原始的Imagen。
DeepFloyd的作者对各个生成模型的效果做了评测,表格中Zero-shot FID-30K表示生成图像的真实感分数,该数值越低越好。

DeepFloyd IF模型能有这样的生成能力,主要源于这两个原因。
- 扩散模型解码器IF-I-XL的参数量达到43亿,大力出奇迹。
- DeepFloyd使用的是和Imagen一样的T5模型,但对T5得到的文本表征设计了一个叫最优注意力池化的模块。
与常见的最大值池化、均值池化这种预定义的池化方法相比,注意力池化是一种可学习的池化方法。感兴趣的同学可以到DeepFloyd的官网了解更多的算法细节,接下来我们一起来探索一下DeepFloyd IF模型的使用代码。
首先,要在你的jupyter环境中登录Hugging Face账号,确保能下载到模型文件。
然后,我们依次加载三个不同分辨率生成阶段的扩散模型。如果你的本地环境不包含这些模型,这段代码会自动请求在Hugging Face的服务器上,下载原始模型文件。
from diffusers import DiffusionPipeline
from diffusers.utils import pt_to_pil
import torch
# stage 1
stage_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
stage_1.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_1.enable_model_cpu_offload()
# stage 2
stage_2 = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16
)
stage_2.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_2.enable_model_cpu_offload()
# stage 3
safety_modules = {"feature_extractor": stage_1.feature_extractor, "safety_checker": stage_1.safety_checker, "watermarker": stage_1.watermarker}
stage_3 = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-x4-upscaler", **safety_modules, torch_dtype=torch.float16)
stage_3.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_3.enable_model_cpu_offload()
接下来,我们就可以提供文本描述来绘画创作了。这里我要求DeepFloyd画的是 “一只长着鹿角的彩虹色柯基犬”。
prompt = 'ultra close-up color photo portrait of rainbow corgi with deer horns in the woods'
# text embeds
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
generator = torch.manual_seed(0)
# stage 1
image = stage_1(prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt").images
pt_to_pil(image)[0].save("./if_stage_I.png")
# stage 2
image = stage_2(
image=image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt"
).images
pt_to_pil(image)[0].save("./if_stage_II.png")
# stage 3
image = stage_3(prompt=prompt, image=image, generator=generator, noise_level=100).images
image[0].save("./if_stage_III.png")

我们可以再体验一下DeepFloyd模型的Text-in-Image能力,比如我们要求其绘制这样一幅画:一个飞行在天空的热气球,挂着一个边缘镶嵌满鲜花的木板,木板上写着“Geekbang”。
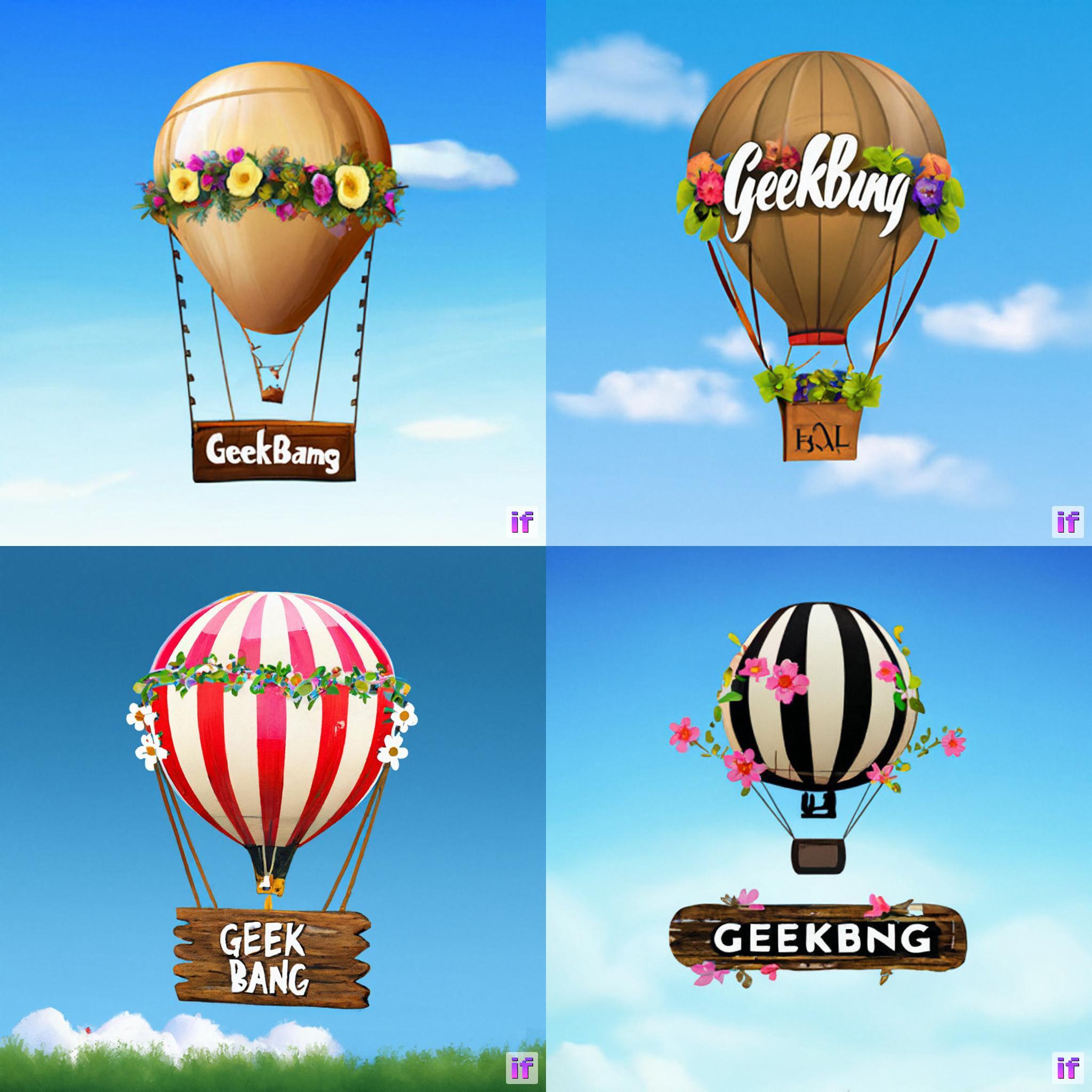
运行上面这段代码,需要至少20G以上的显存。如果需要降低显存占用,可以用xFormer优化Transformer的计算效率,或者释放已经完成推理的模型资源等。
这里我们仅仅展示了DeepFloyd的文生图功能,事实上,你还可以使用官方提供的 deepfloyd_if 模块,直接调用其超分、绘画补全等功能,感兴趣的同学可以访问DeepFloyd官网,获取更多使用信息。
总结时刻
总结一下,今天我们学习了Google的Imagen,这个AI 绘画模型比DALL-E 2晚一个月推出,在效果上明显优于DALL-E 2,颇有后来居上的气势。
我们先讨论了Imagen的技术原理,了解到Imagen使用纯粹的大语言模型T5作为文本编码器,以及文本信息如何有效指导扩散模型生成图像。之后,我们进一步学习了Imagen动态阈值策略,这个策略可以用于抑制模型输出黑图和过饱和图片。
最新的DeepFloyd模型仅仅扩展了Imagen模型,就成为了当下生成效果最好的模型之一。相比于Imagen,DeepFloyd使用更大的UNet,用于第一阶段图像生成的UNet便包含4.3B参数。同时,DeepFloyd引入一种可学习的最优注意力池化机制。这些技巧都可以提升AI绘画的效果。
非常鼓励你课后去读读原始论文、看一些开源代码实现来加深对Imagen的理解。
思考题
在课程的最后,我给你布置了一道思考题。除了我们今天学习的Google T5模型,你还知道哪些优秀的大语言模型,可以用于AI绘画模型的文本编码?
欢迎你在评论区里记录自己的思考或者疑问,我们可以一起留言讨论,共同进步!
- Toni 👍(1) 💬(3)
在Colab A100 下跑 DeepFloyd IF 的代码会出现下列报错: ModuleNotFoundError Traceback (most recent call last) <ipython-input-8-1bb975dcc2d2> in <cell line: 7>() 5 # stage 1 6 stage_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-M-v1.0", variant="fp16", torch_dtype=torch.float16) ----> 7 stage_1.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0 8 stage_1.enable_model_cpu_offload() 9 8 frames /usr/local/lib/python3.10/dist-packages/diffusers/models/attention_processor.py in set_use_memory_efficient_attention_xformers(self, use_memory_efficient_attention_xformers, attention_op) 191 ) 192 if not is_xformers_available(): --> 193 raise ModuleNotFoundError( 194 ( 195 "Refer to https://github.com/facebookresearch/xformers for more information on how to install" ModuleNotFoundError: Refer to https://github.com/facebookresearch/xformers for more information on how to install xformers -------------------- 再装 xformers 后报错依旧,什么原因? pip install -U xformers
2023-08-18 - Eric.Sui 👍(0) 💬(1)
边缘重绘用什么方案?算是变体吗?
2023-08-24 - Geek_7401d2 👍(0) 💬(1)
老师您好,DeepFloyd IF模型和stable diffusion 1.5、stable diffusion 2.0等是什么关系呢,他们是两类扩散模型吗?生成效果哪个更好呢
2023-08-22 - cmsgoogle 👍(0) 💬(1)
运行上面这段代码,需要至少 20G 以上的显存。如果需要降低显存占用,可以用 xFormer 优化 Transformer 的计算效率,或者释放已经完成推理的模型资源等。 - TextinImage的示例代码没有给出。
2023-08-20 - zhihai.tu 👍(0) 💬(1)
在哪里可以体验下imagen绘画呢?
2023-08-18