13 前浪DALL E 2:帮你魔改经典画作
你好,我是南柯。
通过上一章的学习,我们已经掌握了AI绘画的基础知识,了解了扩散模型、CLIP模型、自回归模型等模块的基本原理。从今天开始我们进入进阶篇的学习,我会带你基于已经了解的基础知识,继续探索业界最新最火的AI绘画模型。学完这部分内容,AI绘画的黑魔法在你面前就不是秘密了。
这一讲,我们将要学习的是引爆本轮AI绘画技术热潮的明星模型:DALL-E 2。
DALL-E 2是2022年4月由OpenAI发布的AI绘画模型,它的绘画效果相比过去的工作有了质的飞跃,而且它提出的unCLIP结构、图像变体能力也被后来的方法所效仿。我们只有真正理解了DALL-E 2,才算拿到了进入AI绘画世界的钥匙。
初识DALL-E 2
DALL-E这个名字源自西班牙艺术家Salvador Dali和皮克斯动画机器人Wall-E的组合。如果你想体验OpenAI的DALL-E 2原汁原味的效果,可以使用Edge浏览器NewBing的AI绘画能力。目前,NewBing的AI绘画能力还没有向中国大陆地区开放,需要你发挥聪明才智来体验它。如果你有好的办法,也欢迎你分享在评论区。
比如我们要求DALL-E 2帮我们生成一只可爱的精灵。你可以点开图像查看效果。


这里如果我们使用中文描述,生成的图像效果似乎打了点折扣。这是因为中文描述在输入到模型前需要先翻译成英文,翻译的结果和刚刚我们使用的英文描述并不一致。感兴趣的同学可以自己动手体验更多AI绘画的效果。
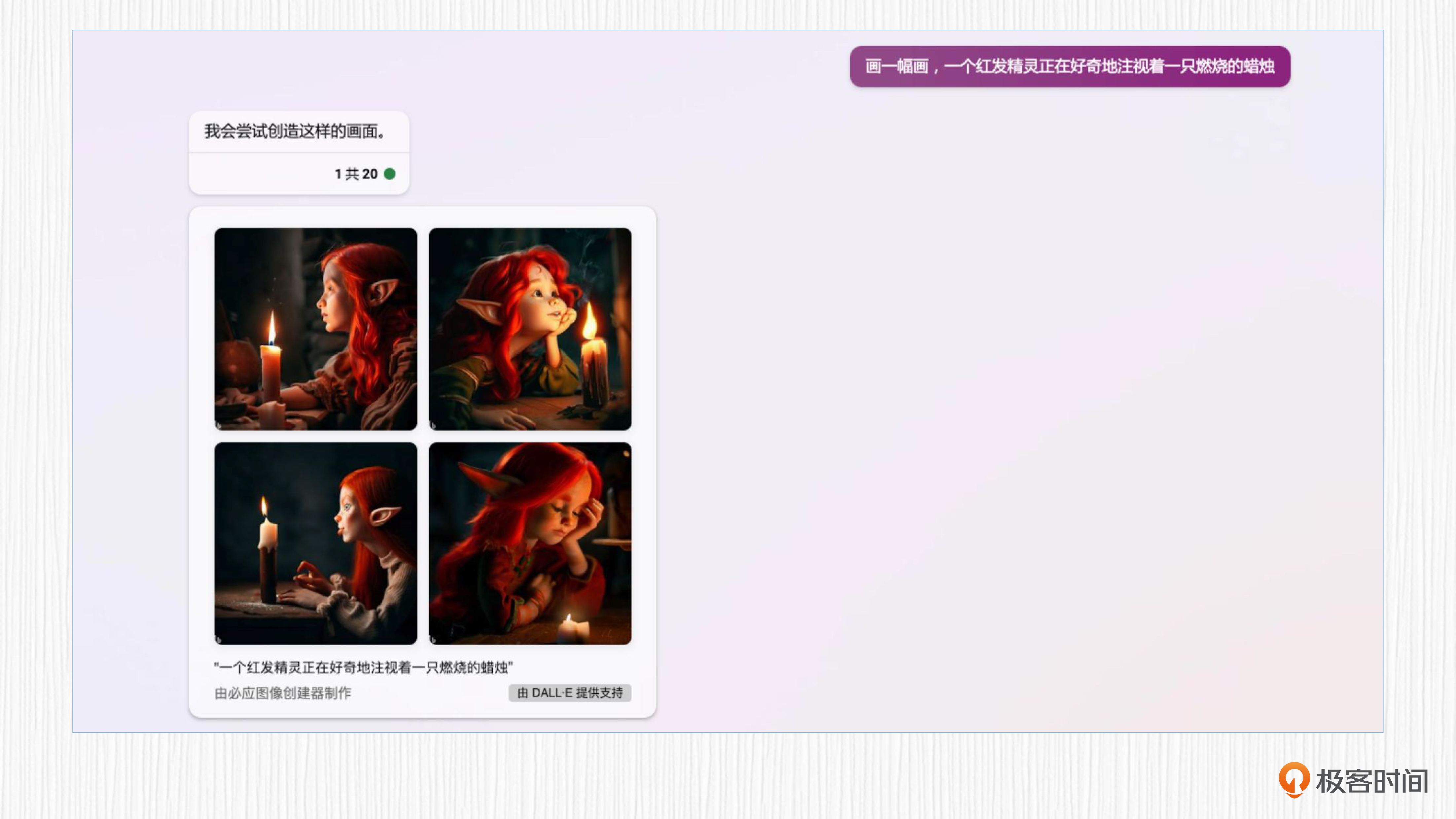
除了上面展示的基于文本描述生成高清图像的基本能力,DALL-E 2还有其他好玩的功能,我们继续来探索。
第一种玩法就是生成图像变体,我们可以对经典画作进行“魔改”。像后面这样,输入一张图片,DALL-E 2可以保留图像中的关键信息,并生成图像的变体。
不要小看这种魔改,实际工作里它能快速提供很多风格的demo,激发我们的设计灵感。比如当我们设计一个产品logo的时候,只需要提供一个设计效果,便可以用图像变体这个功能生成出更多的不同效果。

第二种玩法就是图像的融合。比如输入两张图片,DALL-E 2可以对两张图片进行插值,生成融合后的新图片。这里的融合既可以是图像风格上的融合,也可以是图像内容上的融合,或者是图像内容和图像风格二者的融合。

第三种是局部编辑。输入一张图片,DALL-E 2可以根据我们的指令局部编辑图像,让我们仿佛拥有了指令级PS的能力。

了解了这些,相信你一定会感到好奇:为什么 DALL-E 2 能拥有这些神奇的能力呢?接下来,我们将一起来探究它的工作原理,搞清楚这个模型背后的秘密。
工作原理
我们结合论文给出的整体流程,来拆解一下DALL-E 2都有哪些关键内容。如果你学过前面的章节,可能对图里的很多专业名词都已经很熟悉了。
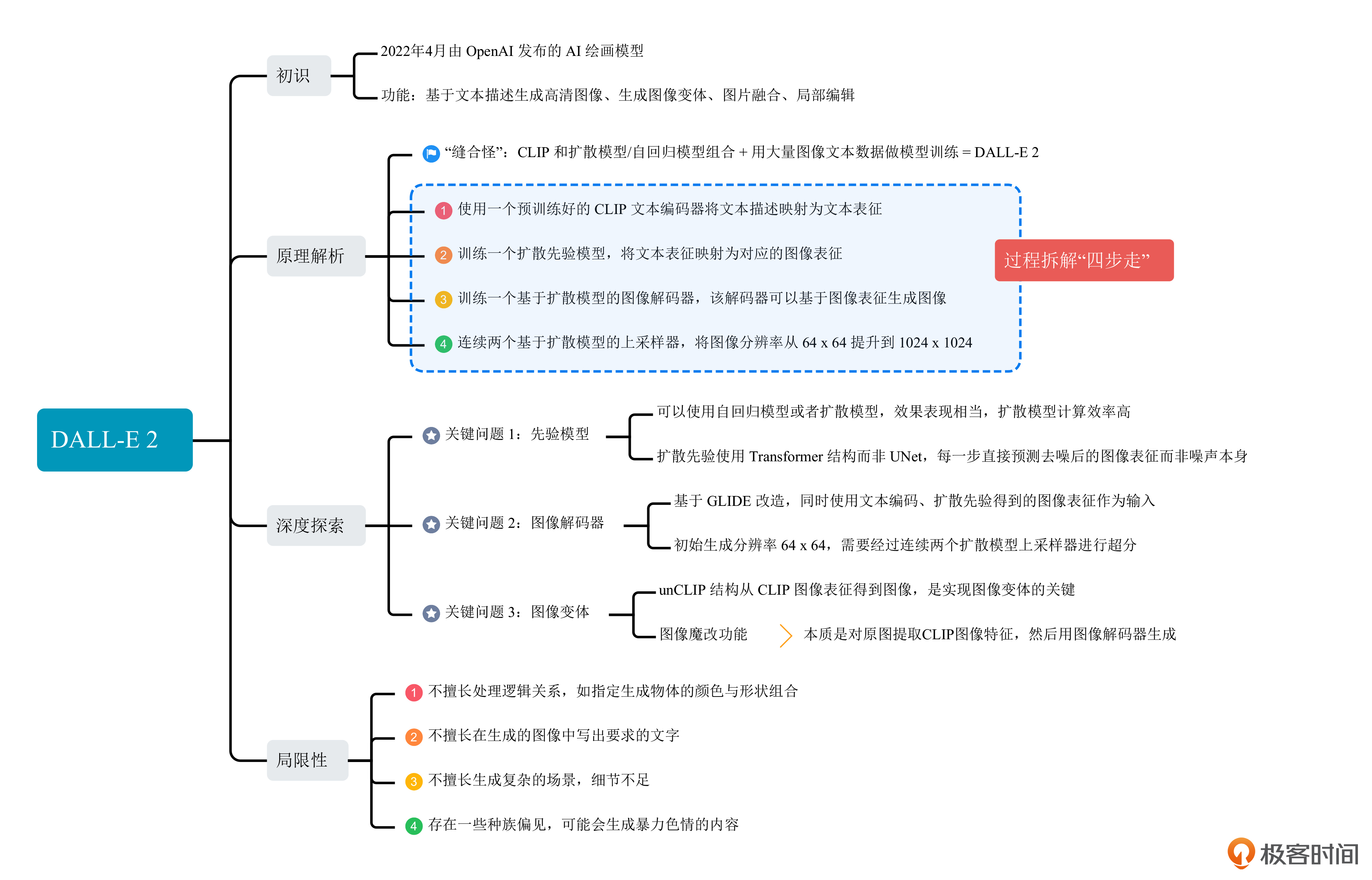
其实,DALL-E 2就是个“缝合怪”。我们把CLIP和扩散模型,或者CLIP和自回归模型组合到一起,引入大量图像文本数据进行模型训练后,便得到了DALL-E 2。
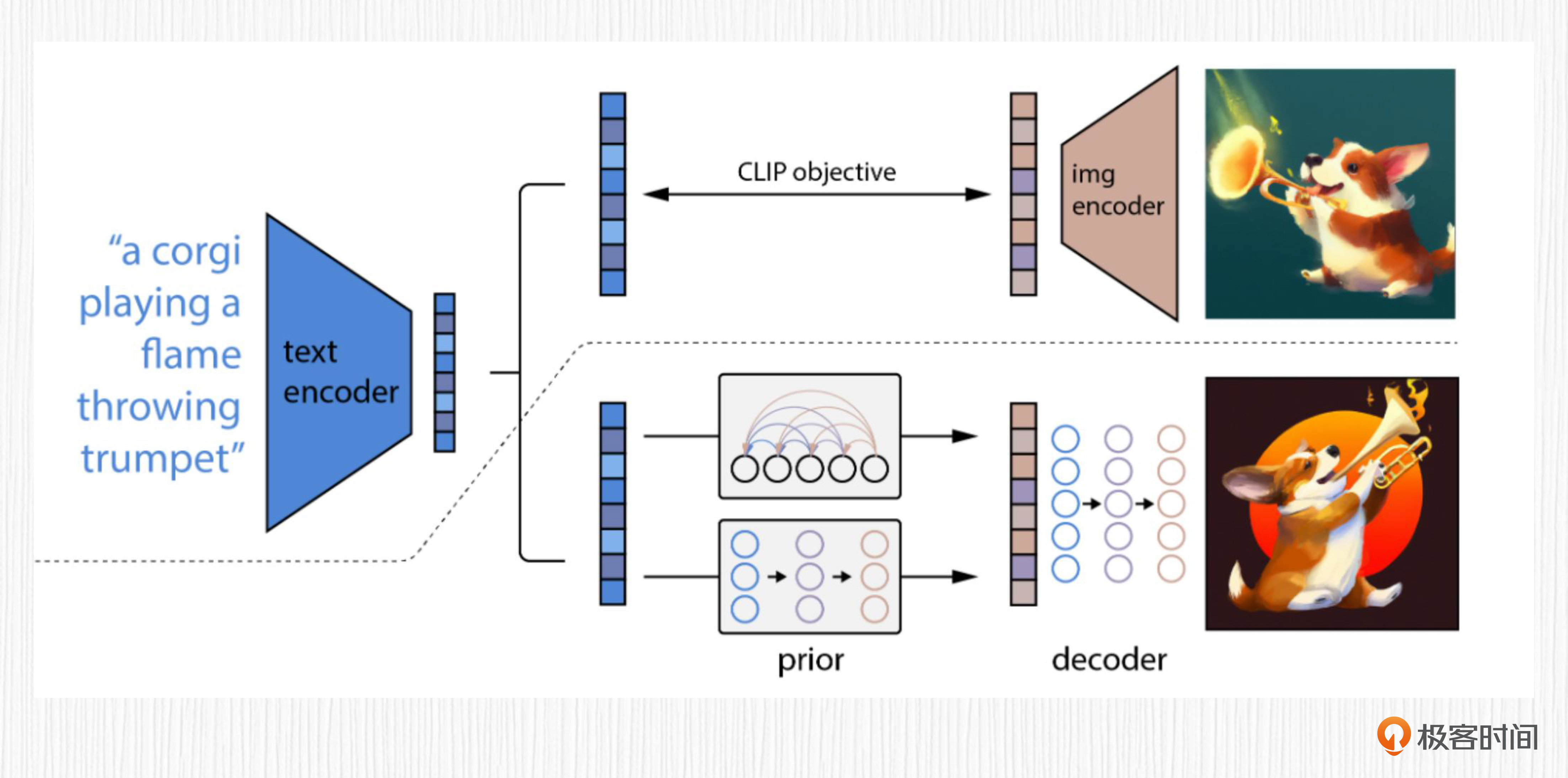
在基础篇中,我们已经学习过了CLIP、扩散模型、自回归模型的基本原理。在正式学习DALL-E 2的工作原理前,我先带你简单回顾下这些基础知识。如果前面内容你已经了然于胸了,也可以跳过后面这几段回顾内容。
CLIP,目的是训练一对图像编码器和文本编码器。使用成对的4亿图文数据,通过图像编码器和文本编码器将图像、文本描述分别映射到一个表征空间,然后计算图像和文本表征向量的距离。训练的目标是让成对的图像文本描述之间的距离更接近。对于 CLIP 的细节感兴趣的同学可以去复习下第10讲的课程。

扩散模型可以从噪声生成图片。这个过程需要多步去噪,每一步都使用权重共享的UNet结构。对于文生图任务而言,UNet的输入信息包括当前带噪声的图像、时间步编码、文本表征。对于扩散模型细节感兴趣的同学,可以去复习下第6至第9讲的内容。
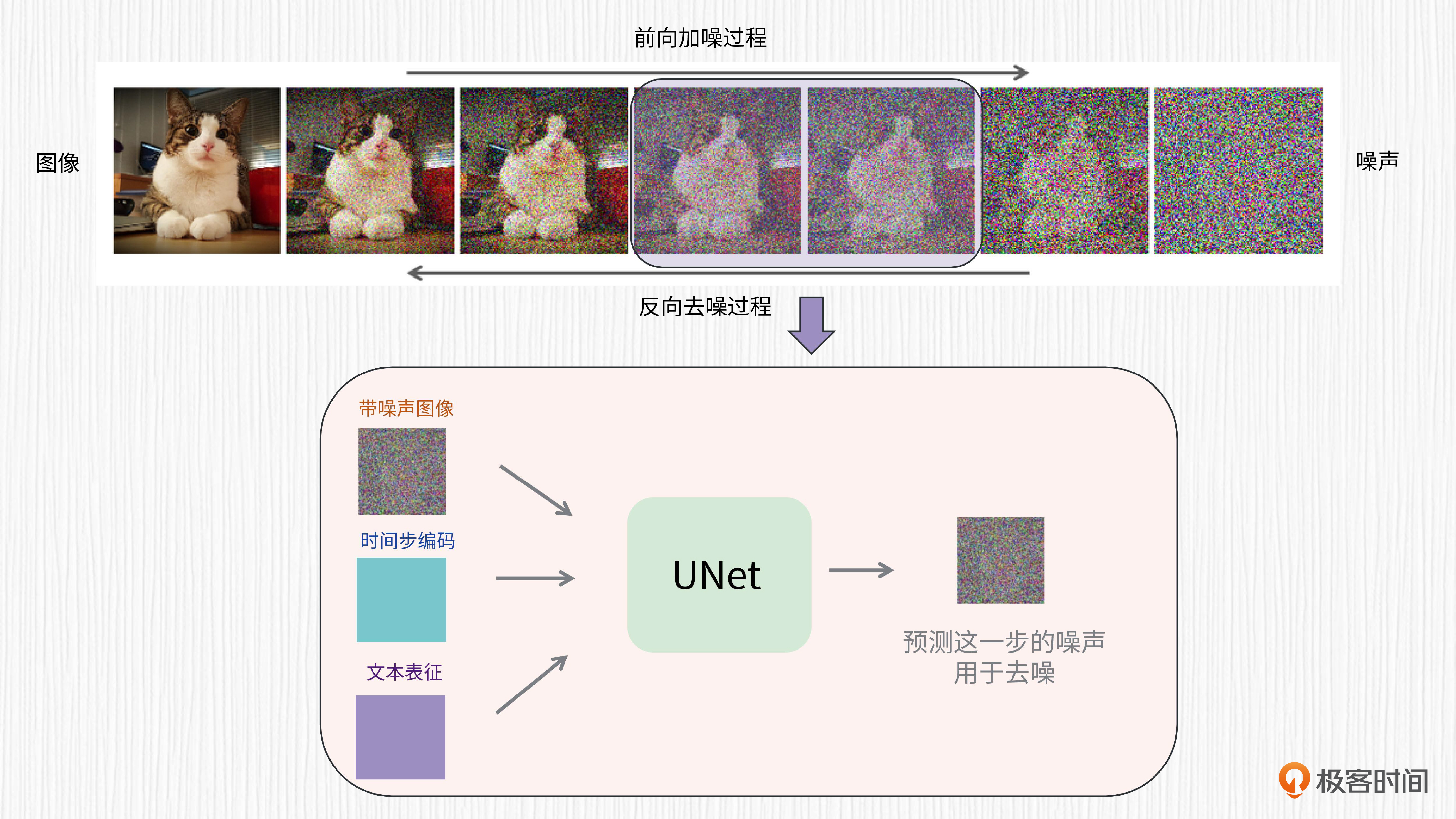
自回归模型常用于文本生成任务,特点是可以根据前面的单词预测下一个单词,是一种处理时间序列的方法。我们熟悉的ChatGPT就是基于自回归模型实现的,每次输入一串文本去精准地预测下一个单词。不过,自回归模型也有缺点,因为序列预测无法并行,所以它的运行效率比较低。
回顾了刚才的基础知识,我们再来细细品鉴DALL-E 2的工作原理。我们先看看原论文中方案的流程图。
我们乍一看,也许感觉这张图比较唬人,并且有一定的迷惑性。不过别担心,我给这张图做了6种不同颜色标记,每种颜色代表一个模块,我们分别看看图中各个模块的作用,就很容易理解了。

先看标记 1。它是原始的 CLIP 结构,这部分在 DALL-E 2 的链路中是固定住的,无需训练。
然后是标记 2。它代表CLIP 的文本编码器提取的文本表征。文本表征是指根据输入的文本,用CLIP文本编码器提取得到的数值特征。图中三处标记为 2 的表征是完全相同的。
标记3和标记4是两种可以互相替代的方案。标记 3代表需要训练的自回归先验模型,也称为Prior模型。先验模型的作用,就是将CLIP提取的文本表征转换为CLIP图像表征。
注意,这里提到的CLIP文本表征是用CLIP文本编码器从文本中提取的,而这里提到的CLIP图像表征是经过先验模型预测得到的,而不是CLIP图像编码器提取的,我们可以将其视为类似于CLIP图像编码器提取的图像表征。
标记 4 表示需要训练的扩散先验模型。DALL-E 2 经过实验验证,使用扩散先验模型和自回归先验模型在生成效果上差不太多,扩散先验模型在计算效率上更有优势。既然原论文主要是围绕扩散先验展开的,所以我们也主要来学习扩散先验的用法。
最后来看标记5和标记6,完成这两步以后文本表征才能转化成真正的图像。标记 5 是先验模块输出的图像表征,该表征类似于CLIP图像编码器提取的特征。标记 6 则是扩散模型,作用是将上一步得到的图像表征转换为图像。
这样拆解完,DALL-E 2 的结构就非常简单明朗了。可以归纳为后面这三个步骤。
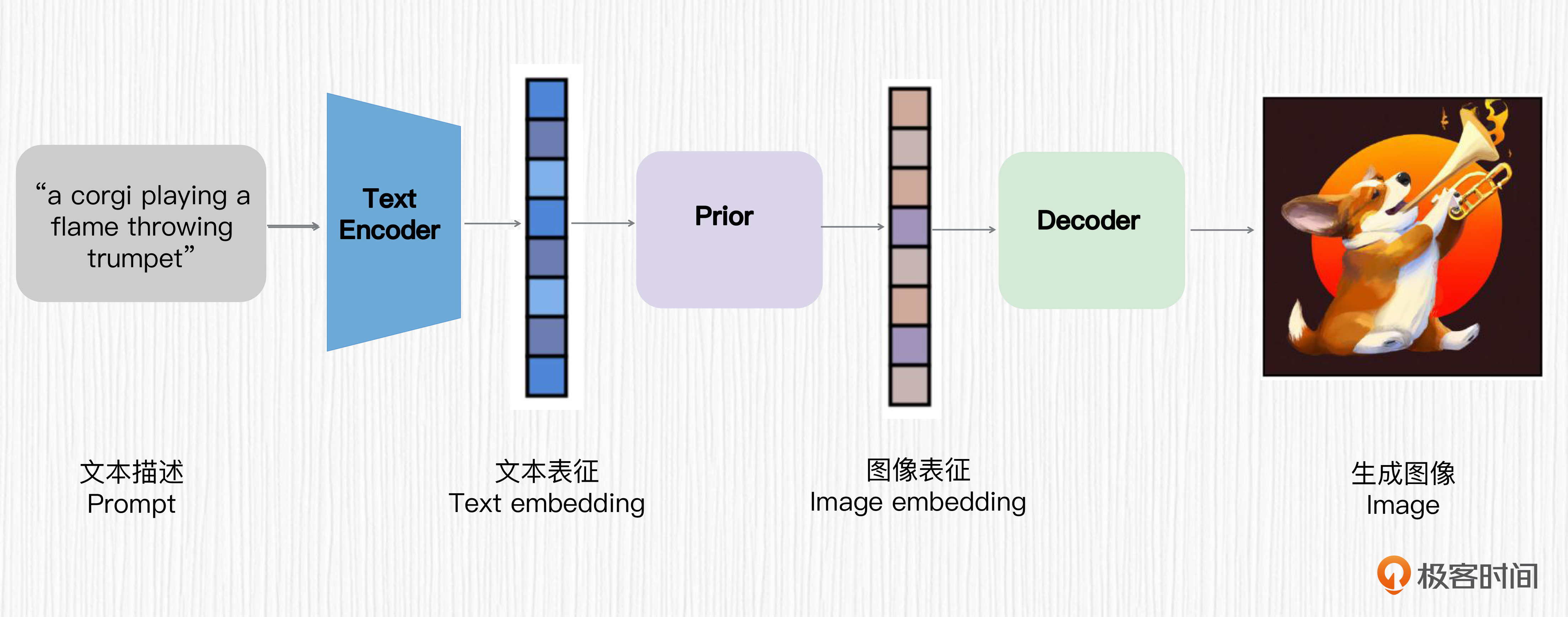
- 首先,使用一个预训练好的CLIP文本编码器将文本描述映射为文本表征。
- 然后,训练一个扩散先验模型,将文本表征映射为对应的图像表征。
- 最后,训练一个基于扩散模型的图像解码器,该解码器可以基于图像表征生成图像。
这三步便是 DALL-E 2 实现 AI 绘画能力的全部过程。我们用一句话总结就是,DALL-E 2 设计的核心思路是,用 CLIP 提取文本表征,通过一个扩散模型将文本表征转换为图像表征,然后通过另一个扩散模型指导图像的生成。我还给你画了流程图,你可以通过看图再加深一下理解。
到这里,距离完全理解DALL-E 2,我们还剩下两个最关键的问题。第一,扩散先验模型要如何训练呢?第二,扩散模型图像解码器要如何训练呢?
我们先来看看扩散先验模型该如何训练。
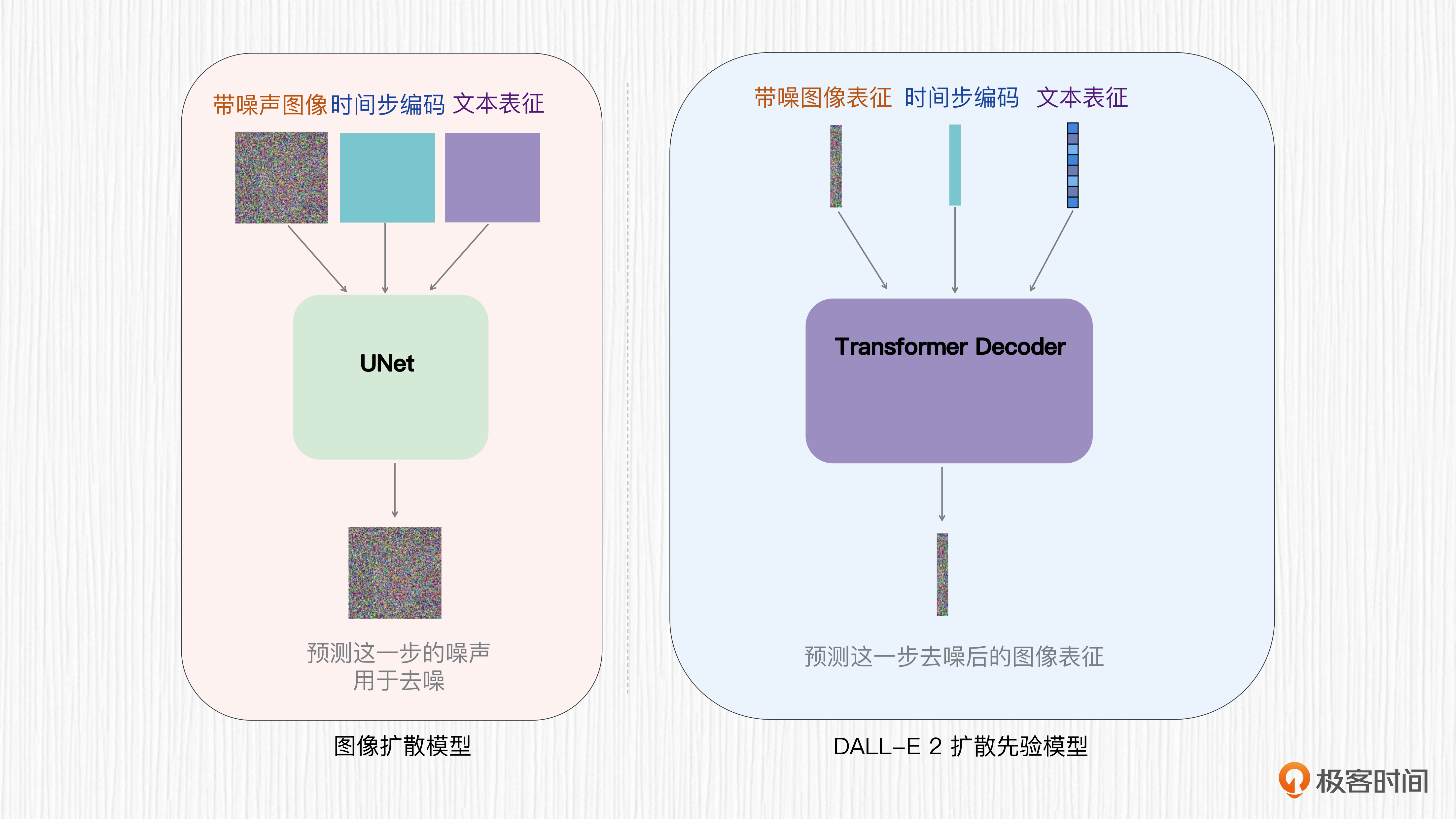
前面已经说过,扩散先验模型的目标是将CLIP文本表征转换为CLIP图像表征。DALL-E 2的扩散先验模型并没有使用UNet结构,而是直接使用一个Transformer解码器。
我们都知道,UNet结构擅长解决图像分割问题,因为UNet的输入和输出都是类似于图像的特征图;而Transformer的输入输出是序列化的特征,更适合完成CLIP文本表征到图像表征的转换。基于Transformer的扩散先验并不是预测每一步的噪声值,而是直接预测每一步去噪后的图像表征。
基于图像-文本成对训练数据,扩散先验模型的训练可以分为以下几个步骤。
- 首先,使用预训练好的 CLIP 文本编码器提取文本描述的文本表征。
- 然后,使用预训练好的 CLIP 图像编码器提取对应的图像表征。
- 之后,随机采样一个时间步 t,以时间步 t、CLIP 提取的文本表征、加噪之后的图像表征作为条件,基于 Transformer 去预测下一步去噪后的图像表征。
为了帮你彻底搞懂基于Transformer的扩散先验模型和普通扩散模型的区别,我准备了后面这张图。
学习完扩散先验模型的结构,那么基于扩散模型的图像解码器该如何实现呢?同为扩散模型,二者有什么不同?
关于图像解码器模块,DALL-E 2 在 OpenAI 的另一个名为 GLIDE 的论文基础上做了一些改进。GLIDE 仅使用文本编码作为图像解码器的输入,而 DALL-E 2 使用文本编码和经过扩散先验之后得到的 CLIP 图像表征作为输入。
图像解码器得到的输出是 64x64 分辨率的图像,这对于我们来说是远远不够的。因此,作者又设计了两个连续的上采样器,实现图像的超分辨率处理,最终得到 1024x1024 的高清图像。我们需要留意的是,这里用到的两个上采样器都是扩散模型。
图像变体
到此为止,我们已经完整了解了DALL-E 2的技术原理。
虽然在生图效果、生图速度等方面,标准的Stable Diffusion毫不逊色于DALL-E 2,但图像变体功能仍是DALL-E 2的亮点功能之一。那么,DALL-E 2是如何实现图像变体功能的呢?
我们常常把 DALL-E 2 的文生图方案称为 unCLIP,这种方案和Stable Diffusion 的技术链路是不同的。unCLIP 模型有一些独特的优势,比如用户输入一张图像,unCLIP 模型可以保留原始图像的关键信息,生成一系列图像变体。
前面已经说过,预训练好的 CLIP 图像编码器可以提取到图像表征,文本编码器可以提取到文本表征。DALL-E 2 从图像表征直接生成图像,正好和 CLIP 从图像提取图像表征是一个相反的过程,这个过程被称为 unCLIP。
下面这张图描述的就是生成图像变体的过程。
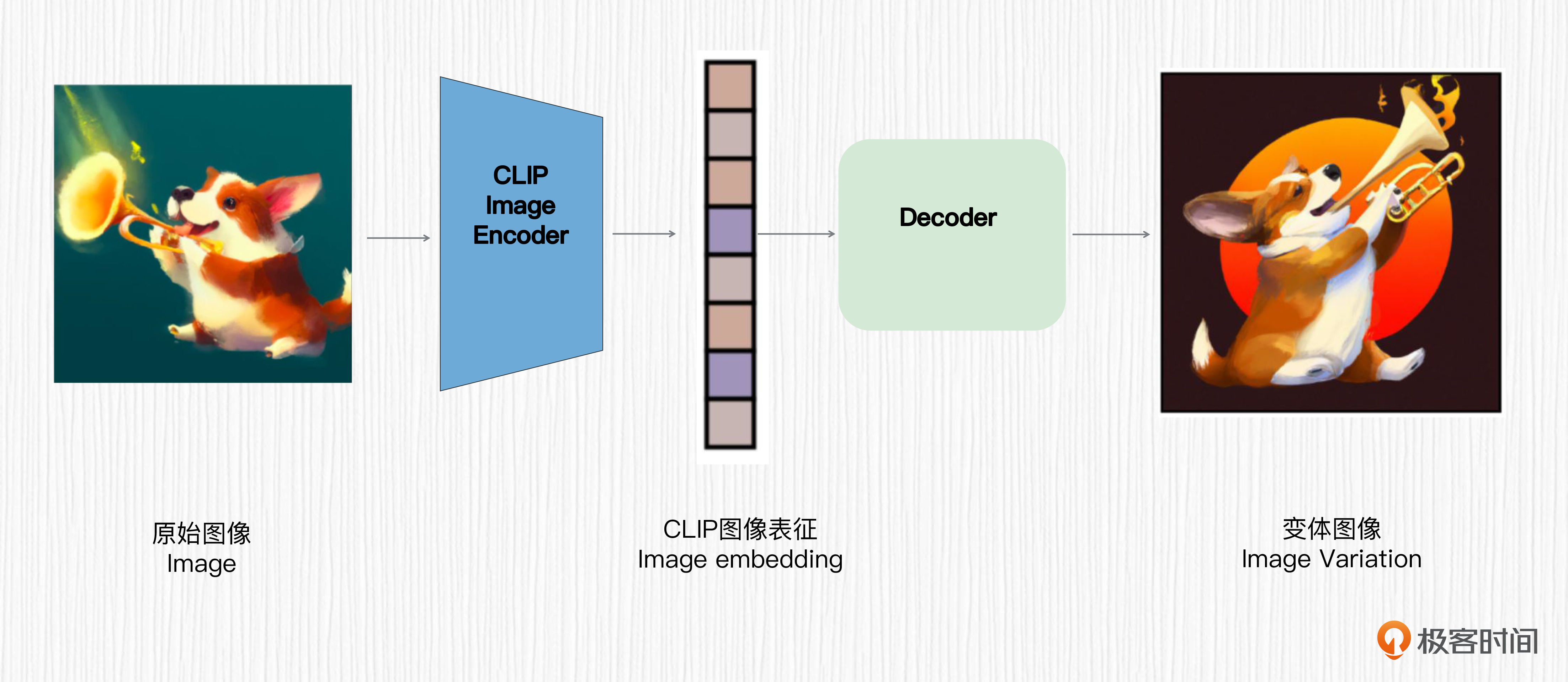
对照图解可以看到,用户输入一张图像,使用CLIP的图像编码器提取图像表征作为图像解码器的输入,这样就实现了生成图像变体的能力。前面我们提到扩散先验模型的作用是得到类似于CLIP图像编码器提取的图像表征,而图像变体功能使用CLIP图像编码器提取图像表征,二者是类似的。unCLIP的精妙之处就在这里,你可以仔细品味一下。
我们继续思考,为什么DALL-E 2可以生成很多变体图像呢?
虽然CLIP的图像编码器是固定的,从给定原始图像得到的图像表征是一个确定性的过程。但扩散解码器每次从随机噪声出发,结合CLIP图像表征会生成变体图像,这个生成图像的过程是有随机性的,所以DALL-E 2才会轻易得到很多变体图像。
当我们了解了整个技术方案,细心的你也许会有这样的疑惑——既然CLIP的图像表征和文本表征是使用海量图文对训练得到的,训练的方式也是让匹配的图像表征和文本表征尽可能靠近,那么必须要有扩散先验模块么?
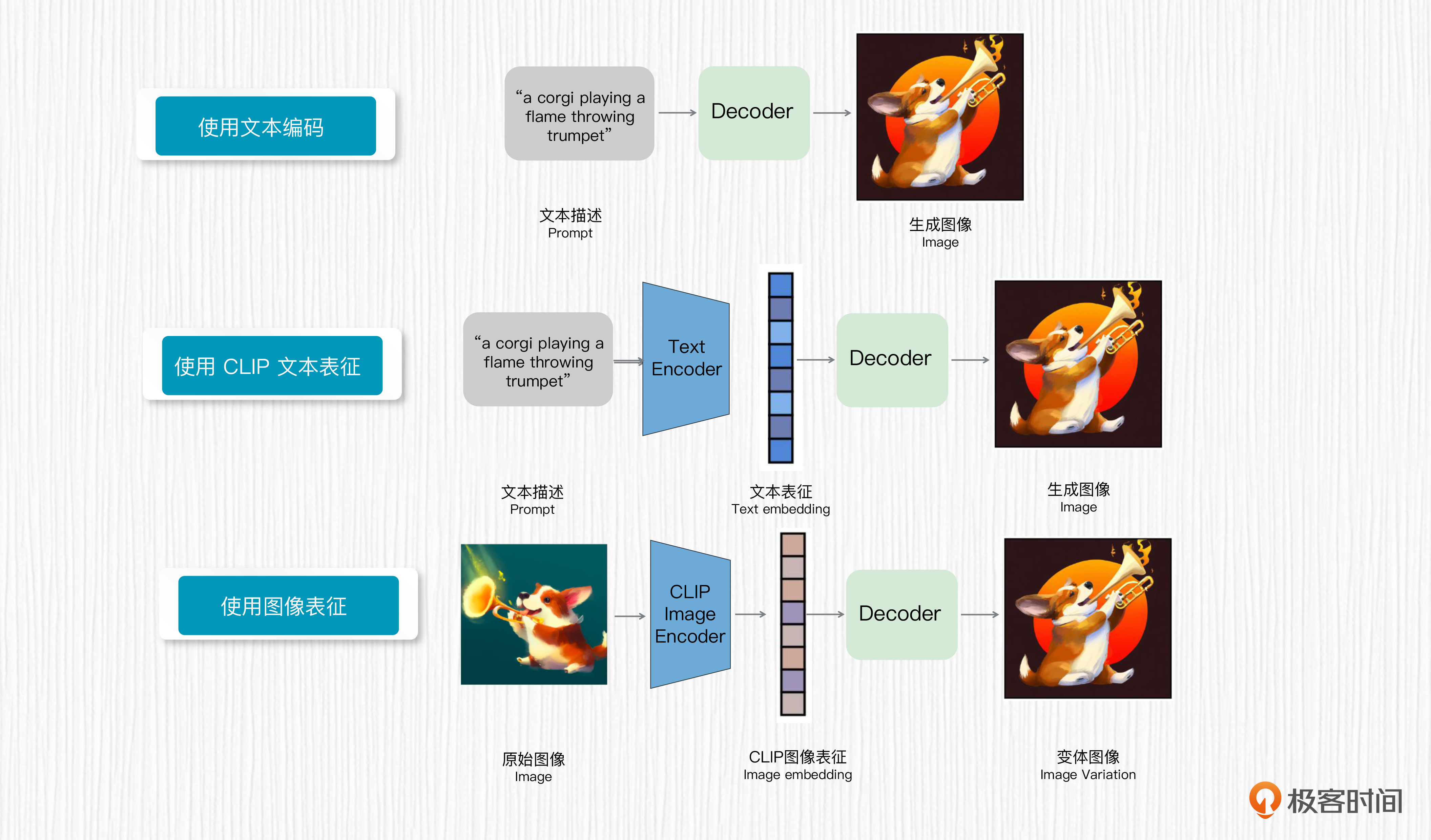
在DALL-E 2中,答案是必须的。DALL-E 2在论文中使用文本编码、CLIP 文本表征、扩散先验模型得到的图像表征作为输入,分别验证了这三种方式的图像生成效果。从实验效果来看,使用扩散先验模型的生成效果是最好的。
有趣的是,下一讲我们要学习的Imagen模型并没有使用扩散先验,而是直接从文本表征生成图像,效果优于DALL-E 2。从后来主流模型如Stable Diffusion的做法来看,扩散先验并不是必须的,代价是失去了生成图像变体的能力。

遗憾的是DALL-E 2并没有官方开源,我们无法通过代码使用上面展示的能力。这一讲我们重在搞懂原理,后续课程中我们会动手写代码实现出不逊色于DALL-E 2的AI绘画效果和图像编辑能力。
局限性
当然,任何事物都不是完美的,DALL-E 2 这个工作也存在一些局限性。
首先,DALL-E 2 并不擅长处理逻辑关系。比如我们要求其生成“蓝色方块上面放一个红色的方块”,对比 GLIDE 这个论文,DALL-E 2 得到的效果并不准确。
刚刚我们说过,DALL-E 2 图像解码器的输入,是在 GLIDE 文本编码的基础上又增加了图像表征。之所以保留 GLIDE 的文本编码作为输入,就是因为发现 GLIDE 的文本编码输入更擅长处理这类包含逻辑关系的图像生成。

其次,DALL-E 2 并不擅长在生成的图像中写出要求的文字。比如我们要求 DALL-E 2 生成一幅图,“写着 Deep Learning 的标志板”,结果并不理想。之后我们要介绍的其他 AI 绘画方案便可以解决这个问题,这里先埋一个伏笔。

此外,DALL-E 2 不擅长生成复杂的场景,细节不足。比如我们要求其生成“一张高质量的时代广场的照片”,得到的结果很粗糙。

除了上面这些,DALL-E 2 生成的内容还存在一些种族偏见,比如一些特定的职业会生成特定的有色人种;DALL-E 2也会生成一些色情暴力的内容,这是由于训练的数据中包括这类内容。
这些问题的存在孕育了更多优秀的改善思路,涌现出更多解决方案,随着我们学习的深入,你会发现在过去的一年里上述问题都得到了较大的改善。
总结时刻
总结一下,今天我们学习了 DALL-E 2 这个具有开创性意义的 AI 绘画模型。DALL-E 2 可以用于文生图、图像变体生成、图像插值等任务,生成的图像可以达到 1024x1024 分辨率。
从原理上,我们学习了 DALL-E 2 如何使用预训练的 CLIP 模型,如何设计和训练扩散先验模型、图像解码模型,还了解了 unCLIP 的设计思路以及如何实现图像变体。

我们也了解到 DALL-E 2 在处理逻辑关系、生成包含指定文字内容的图像上仍有不足。非常鼓励你去读读原始论文、看一些开源代码实现来加深对这个工作的理解。这一讲的知识我整理成了后面的思维导图,方便你课后复习。
AI绘画模型一直在进步,如今最新的AI绘画模型在生图效果上相比于DALL-E 2又有了较大提升,很大程度上归功于更强大的文本编码器、更高质量的训练图像。即便如此,DALL-E 2的处理思路仍然对我们很有启发。比如图像变体功能,就非常适合设计师、产品经理根据原始的理念生成更多创意。
思考题
DALL-E 2使用两个基于扩散模型的上采样模块,相比于不使用扩散模型的超分算法,有哪些优势?(提示:了解超分算法有助于回答这个问题)
欢迎你在留言区和我交流讨论。如果这节课对你有启发,也推荐你分享给身边更多同事、朋友。
- 徐大雷 👍(0) 💬(1)
老师,在初识 DALL-E 2 这个章节里面,生成图像变体,图像融合是怎么在微软必应里面操作的?谢谢
2023-09-05 - peter 👍(0) 💬(1)
本讲所说的DALL-E 2,其能力低于SD和Midjourney吧。
2023-08-16 - 不会数数 👍(0) 💬(1)
关于必应生成图片的例子并不合适,red furry monster 翻译成中文应该是红毛怪兽, 和红发精灵的描述完全不一样,按照稍微正常点的翻译生成的图,得到的风格是相似的。
2023-08-16