12 实战项目(二):动手训练一个你自己的扩散模型
你好,我是南柯。
前面几讲,我们已经了解了扩散模型的算法原理和组成模块,学习了Stable Diffusion模型新增的CLIP和VAE模块。掌握了这些知识,相信你也一定跃跃欲试,想要训练一个属于自己的AI绘画模型。
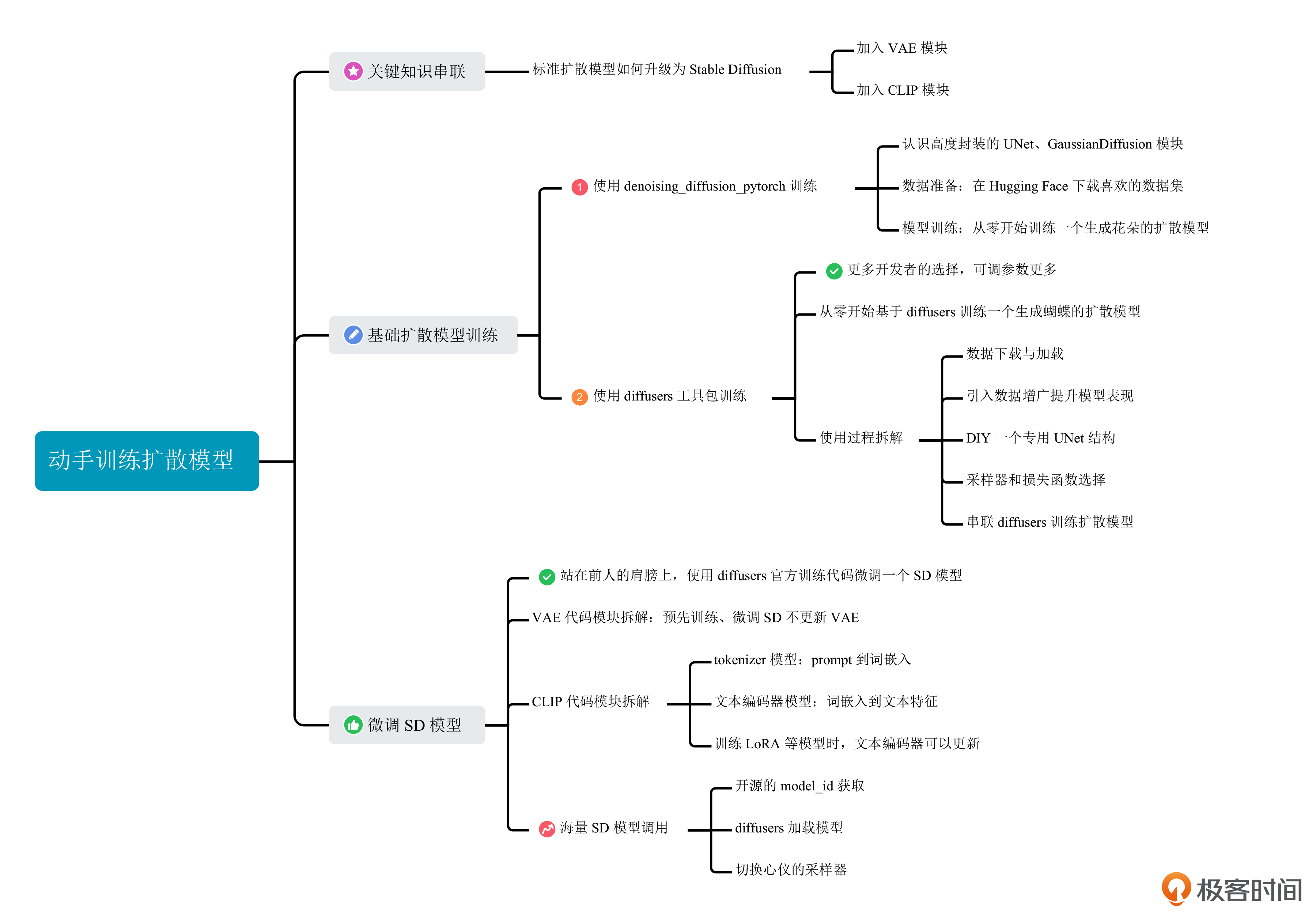
这一讲,我们会将前几讲的知识串联起来,从全局的视角讨论扩散模型如何训练和使用。我们将通过实战的形式,一起训练一个标准扩散模型,并微调一个Stable Diffusion模型,帮你进一步加深对知识的理解。学完这一讲,我们就迈出了模型自由的关键一步。
关键知识串联
在实战之前,我想请你思考一个问题:想要把标准的扩散模型升级为Stable Diffusion,需要几步操作?
答案是两步。
我们通过第6讲已经知道,标准扩散模型的训练过程包含6个步骤,分别是随机选取训练图像、随机选择时间步t、随机生成高斯噪声、一步计算第t步加噪图、使用UNet预测噪声值和计算噪声数值误差。
Stable Diffusion在此基础上,增加了VAE模块和CLIP模块。VAE模块的作用是降低输入图像的维度,从而加快模型训练、给GPU腾腾地方;CLIP模块的作用则是将文本描述通过交叉注意力机制注入到UNet模块,让AI绘画模型做到言出法随。
我们不妨再翻出Stable Diffusion的算法框架图回忆一下。图中最左侧粉色区域便是VAE模块,最右侧的条件控制模块便可以是CLIP(也可以是其他控制条件),而中间UNet部分展示的QKV模块,便是prompt通过交叉注意力机制引导图像生成。到此为止,是不是一切都串联起来了?

事实上,在Stable Diffusion中,还有很多其他黑魔法,比如无条件引导控制(Classifier-Free Guidance)、引导强度(Guidance Scale)等,我们会在下一章进一步探讨。
知道了这些,我们不妨继续思考一个问题:训练一个标准扩散模型和Stable Diffusion模型,需要准备哪些“原材料”呢?
首先,我们需要GPU,显存越大越好。没有英伟达显卡的同学,可以使用Colab免费的15G T4显卡。在第10讲中我们详细讨论了Colab GPU环境的用法,不熟悉的话你可以通过超链接回顾。
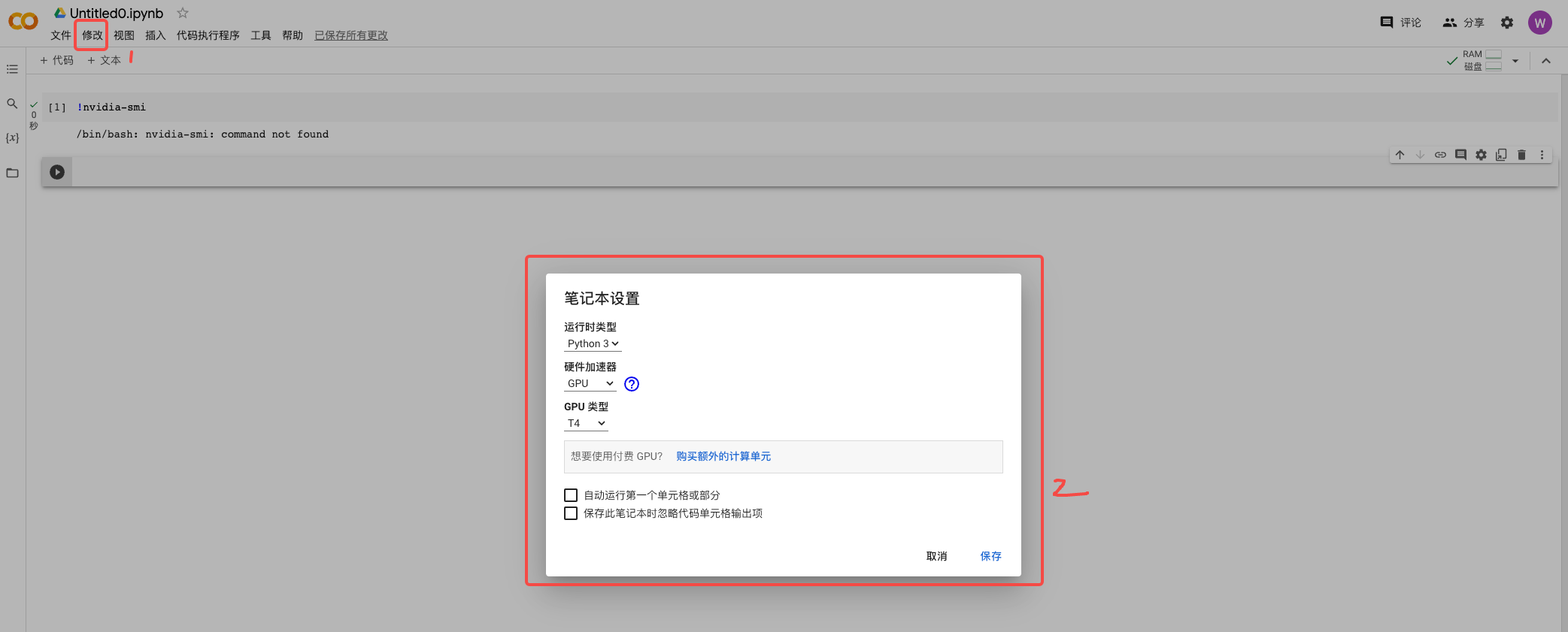
然后,我们需要训练数据。对于标准扩散模型而言,我们只需要纯粹的图片数据即可;对于Stable Diffusion,由于我们需要文本引导,就需要用到图片数据对应的文本描述。这里的文本描述既可以是像CLIP训练数据那种对应的文本描述,也可以是使用各种图片描述(image caption)模型获取的文本描述。
如果你要训练的是Stable Diffusion,在第1讲中我们估算过,从头开始训练的成本差不多是几套海淀学区房的价格,所以我们最好是基于某个开源预训练模型进行针对性微调。事实上,开源社区里大多数模型都是微调出来的。
此外,对于Stable Diffusion,我们还需要准备好预先训练好的CLIP模型和VAE模型。
关于训练数据、开源预训练模型、CLIP和VAE,你都不必担心。后面的代码环节我会说明获取方法。现在你只需要准备好GPU资源即可。
这一讲的实战部分,所有操作你都可以通过点开我提供的Colab链接来完成。当然,我更推荐你新建全新的Colab,对照我提供的原始Colab逐步写代码来完成。这样有助于你加深对训练过程的理解。
训练扩散模型
这里我们通过两种方式来训练扩散模型。
第一种是使用denoising_diffusion_pytorch这个高度集成的工具包,第二种则是基于diffusers这种更多开发者使用的工具包。对于专业的算法同学而言,我更推荐使用diffusers来训练。原因是diffusers工具包在实际的AI绘画项目中用得更多,并且也更易于我们修改代码逻辑,实现定制化功能。
认识基础模块
先看第一种训练方式,我们先按照下面的方式,在Colab里安装对应工具包。你可以直接点开我的 Colab链接,点击播放按键逐步操作。
这个工具包中提供了UNet和扩散模型两个封装好的模块,你可以通过两行指令创建UNet,并基于创建好的UNet创建一个完整的扩散模型,同时指定了图像分辨率和总的加噪步数。
from denoising_diffusion_pytorch import Unet, GaussianDiffusion
import torch
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
).cuda()
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000 # number of steps
).cuda()
训练过程也非常清爽,为了帮你更好地理解一次训练的过程是怎样的。我们结合代码例子看一下,比如我们随机初始化八张图片,便可以通过后面这两行代码完成扩散模型的一次训练。
# 使用随机初始化的图片进行一次训练
training_images = torch.randn(8, 3, 128, 128)
loss = diffusion(training_images.cuda())
loss.backward()
如果你想用自己本地的图像,而非随机初始化的图像,可以参考下面的代码。
from PIL import Image
import torchvision.transforms as transforms
import torch
# 预设一个变换操作,将PIL Image转换为PyTorch Tensor,并对其进行归一化
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
# 我们认为你有个列表包含了8张图像的路径
image_paths = ['path_to_your_image1', 'path_to_your_image2', 'path_to_your_image3', 'path_to_your_image4',
'path_to_your_image5', 'path_to_your_image6', 'path_to_your_image7', 'path_to_your_image8']
# 使用List comprehension读取并处理这些图片
images = [transform(Image.open(image_path)) for image_path in image_paths]
# 将处理好的图像List转化为一个4D Tensor,注意torch.stack能够自动处理3D Tensor到4D Tensor的转换
training_images = torch.stack(images)
# 现在training_images应该有8张3x128x128的图像
print(training_images.shape) # torch.Size([8, 3, 128, 128])
训练完成后,可以直接使用得到的模型来生成图像。由于我们的模型只训练了一步,模型的输出也是纯粹的噪声图。这里只是为了让你找一下手感。
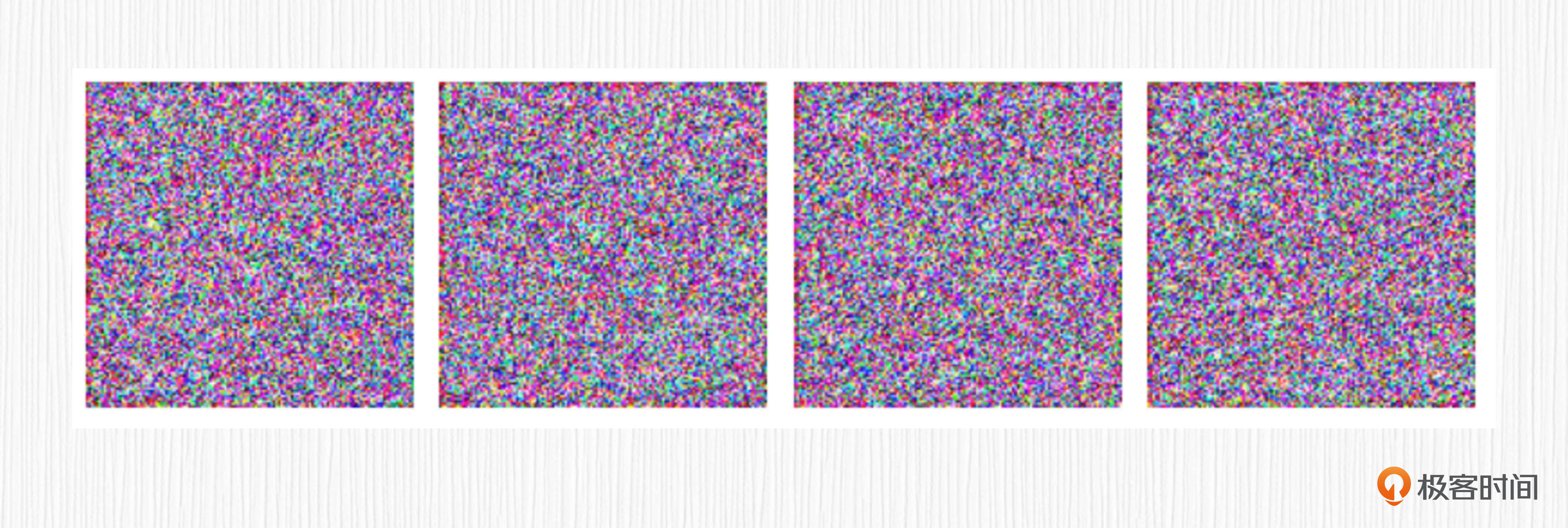
数据准备
理解完基本流程,我们使用真实数据进行一次训练。我们以 oxford-flowers 这个数据集为例,首先需要安装datasets这个工具包。
我们使用后面的代码就可以下载这个数据集,并将数据集中所有的图片单独存储成png格式,用png格式更方便我们查看。全部处理完大概有8000张图片。
from PIL import Image
from io import BytesIO
from datasets import load_dataset
import os
from tqdm import tqdm
dataset = load_dataset("nelorth/oxford-flowers")
# 创建一个用于保存图片的文件夹
images_dir = "./oxford-datasets/raw-images"
os.makedirs(images_dir, exist_ok=True)
# 遍历所有图片并保存,针对oxford-flowers,整个过程要持续15分钟左右
for split in dataset.keys():
for index, item in enumerate(tqdm(dataset[split])):
image = item['image']
image.save(os.path.join(images_dir, f"{split}_image_{index}.png"))
你也可以在 Hugging Face 上挑选你喜欢的图像数据集,挑选和使用方法可以参考后面的截图。
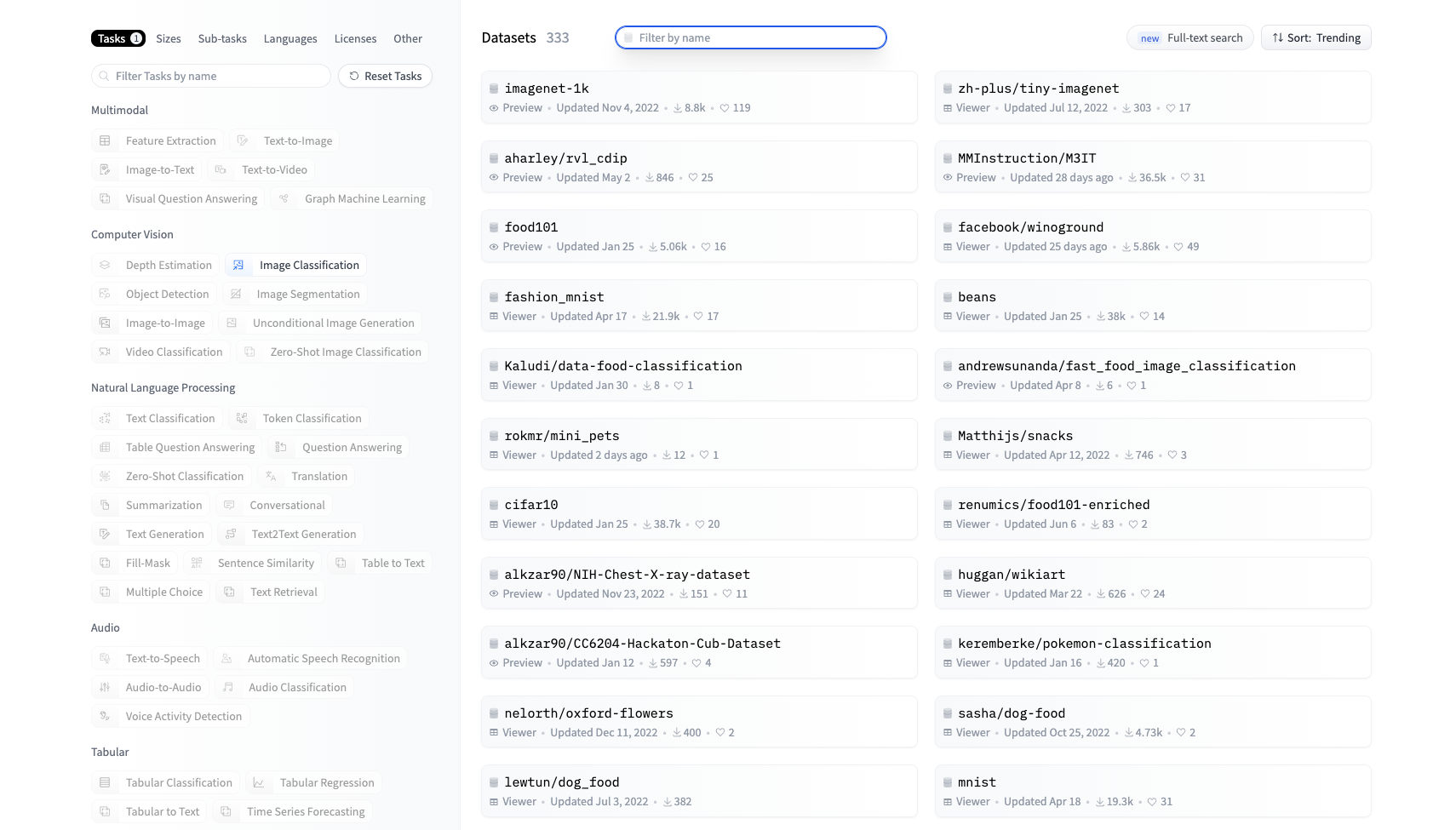
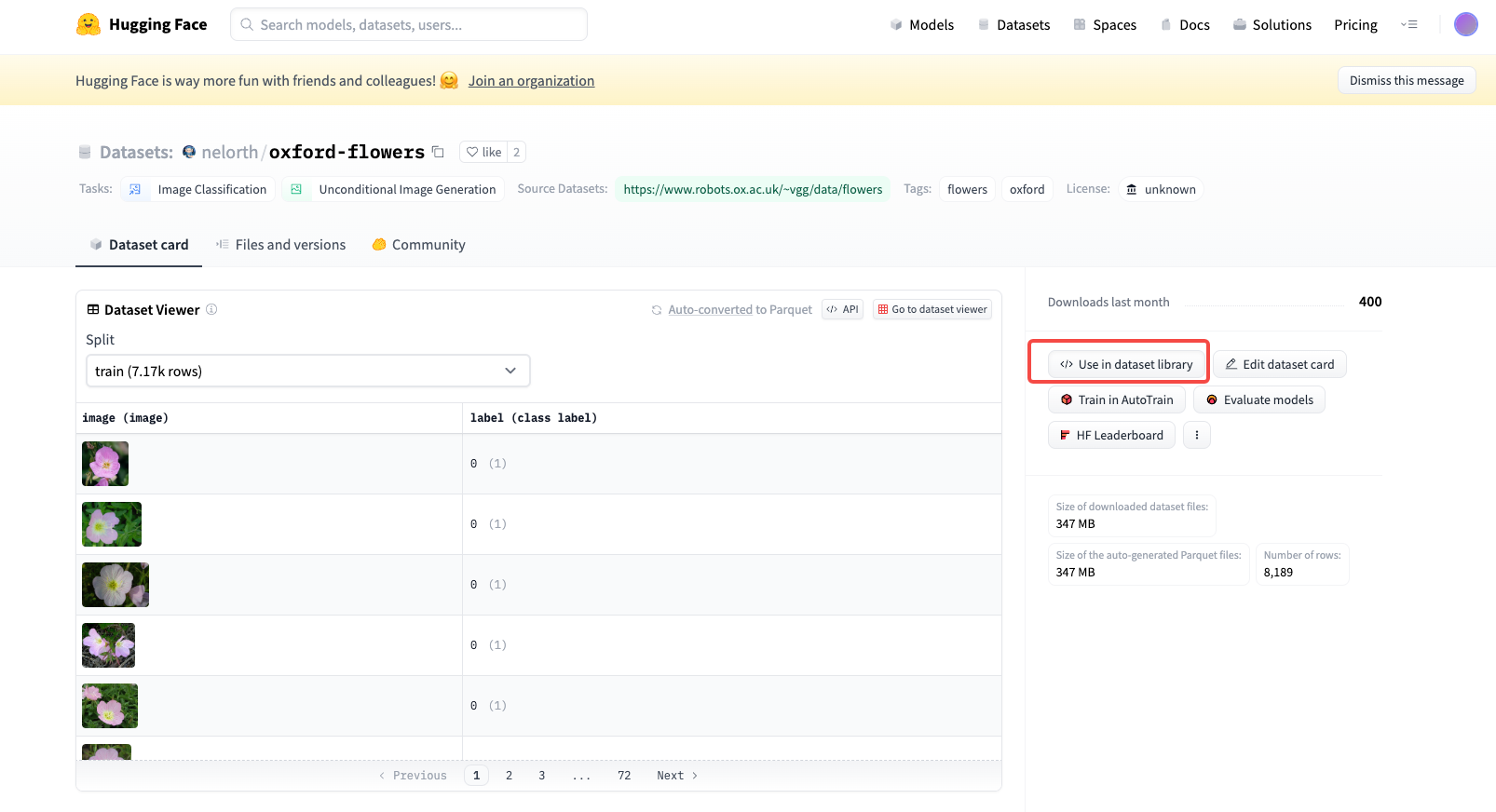
点击数据集使用后,通过下面两行代码即可完成数据集的下载和读取。
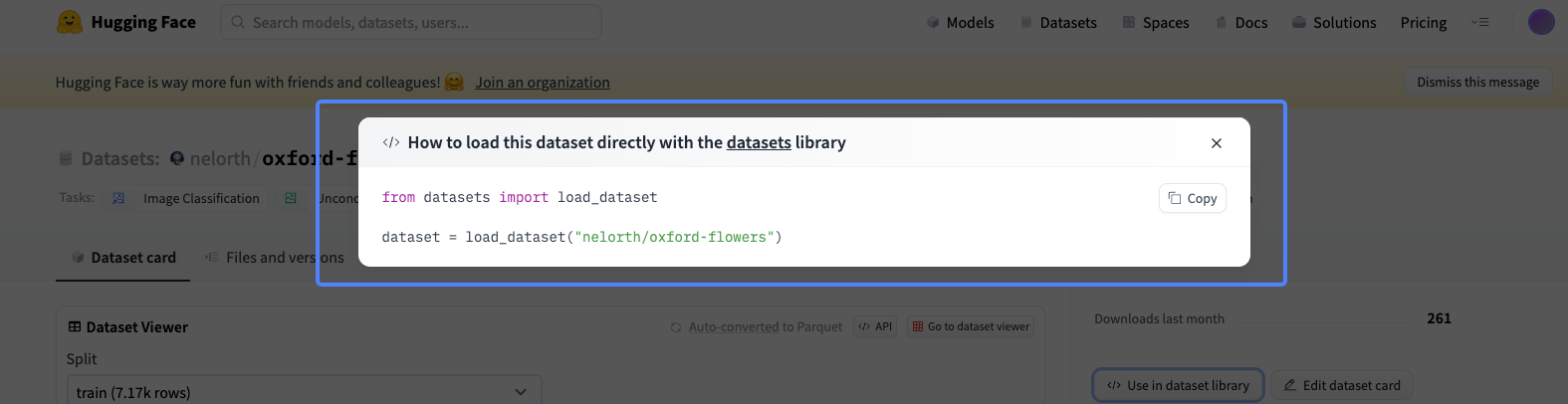
比方说上图展示的这个数据集,里面都是一些不同的花朵。我们课程里就选择这个花朵数据集,训练的目的就是得到一个扩散模型,这个模型可以从噪声出发,逐步去噪得到一朵花。
模型训练
准备工作完成,我们便可以通过以下代码来进行完整训练。如果你的GPU不够强大,可以根据实际情况调整训练的batch_size大小。
import torch
from denoising_diffusion_pytorch import Unet, GaussianDiffusion, Trainer
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
).cuda()
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000 # 加噪总步数
).cuda()
trainer = Trainer(
diffusion,
'./oxford-datasets/raw-images',
train_batch_size = 16,
train_lr = 2e-5,
train_num_steps = 20000, # 总共训练20000步
gradient_accumulate_every = 2, # 梯度累积步数
ema_decay = 0.995, # 指数滑动平均decay参数
amp = True, # 使用混合精度训练加速
calculate_fid = False, # 我们关闭FID评测指标计算(比较耗时)。FID用于评测生成质量。
save_and_sample_every = 2000 # 每隔2000步保存一次模型
)
trainer.train()
这里分享一个小技巧,如果在使用GPU的时候报错提示显存不足,可以通过后面的命令手工释放不再使用的GPU显存。
对于16G的V100显卡而言,整个任务的训练要持续3至4个小时。在整个训练过程中,每次间隔2000个训练步,我们会保存一次模型权重,并利用当前权重进行图像的生成。
你可以参考后面的图片,能看出,随着训练步数的增多,这个扩散模型的图像生成能力在逐渐变强。

进阶到diffusers训练
对于我们提到的第二种扩散模型训练方式,基于diffusers工具包的训练,我们要写的代码就会多得多,并且可调节的参数也会多很多。
这里我放一个 Colab的链接,包含完整的训练代码。我来带你一起拆解下其中的关键部分。
首先,我们看数据集的使用。通过datasets工具包加载数据集,与denoising_diffusion_pytorch的训练不同,在diffusers训练模式下,我们不需要将数据集再转为本地图片格式。
import torch
from datasets import load_dataset
# 加载数据集
config.dataset_name = "huggan/smithsonian_butterflies_subset"
dataset = load_dataset(config.dataset_name, split="train")
# 封装成训练用的格式
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=config.train_batch_size, shuffle=True)
为了提升模型的性能,我们可以对图像数据进行数据增广。所谓数据增广,就是对图像做一些随机左右翻转、随机颜色扰动等操作,目的是增强训练数据的多样性。
from torchvision import transforms
preprocess = transforms.Compose(
[
transforms.Resize((config.image_size, config.image_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
然后我们看UNet结构。按照下图的结构搭建UNet模块,比如图中输入和输出的分辨率都是128x128,在实际UNet搭建中你可以任意指定。
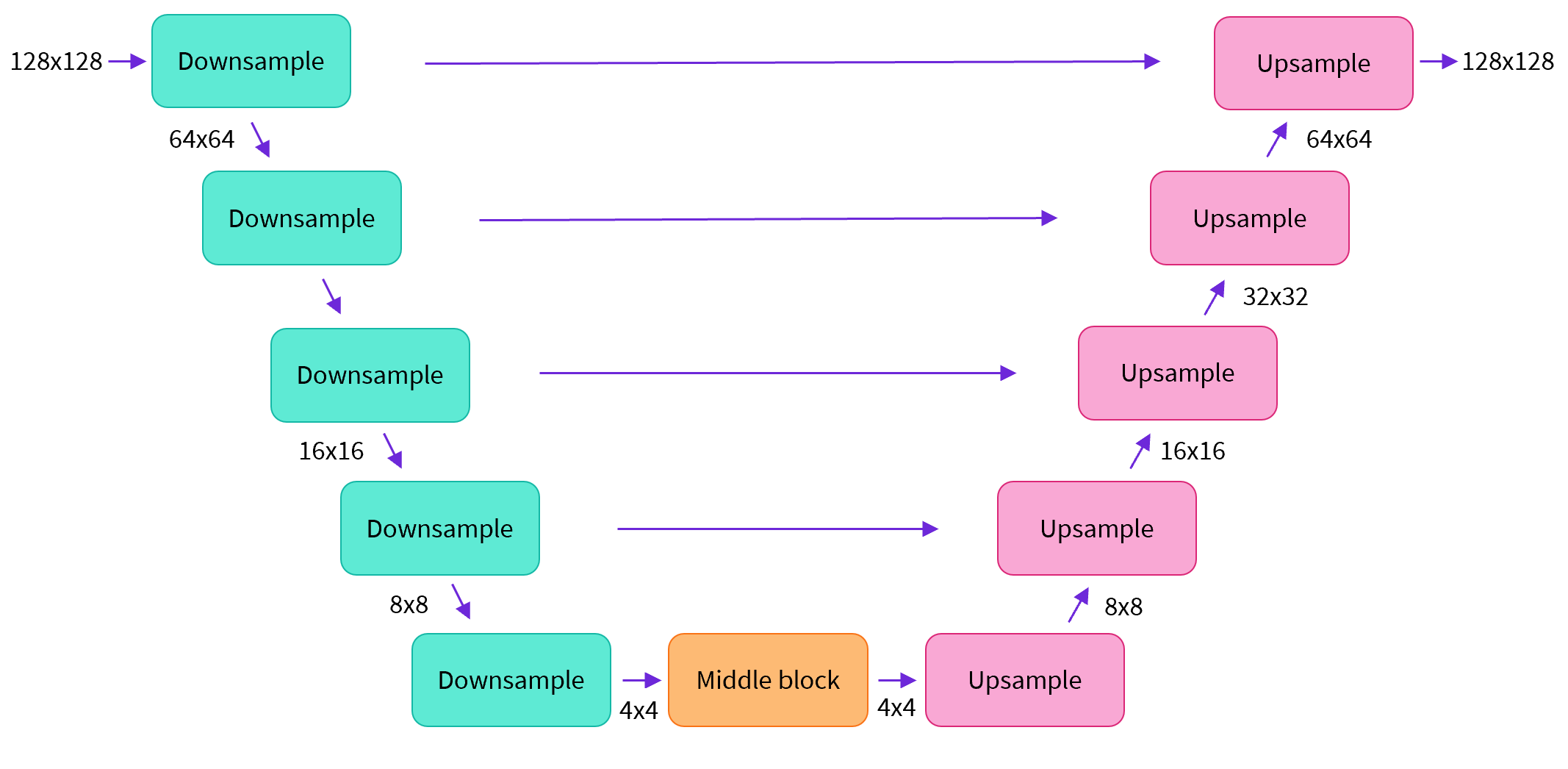
我们可以通过下面的代码来创建UNet结构。
from diffusers import UNet2DModel
model = UNet2DModel(
sample_size=config.image_size, # 目标图像的分辨率
in_channels=3, # 输入通道的数量,对于RGB图像为3
out_channels=3, # 输出通道的数量
layers_per_block=2, # 每个UNet块中使用的ResNet层的数量
block_out_channels=(128, 128, 256, 256, 512, 512), # 每个UNet块的输出通道数量
down_block_types=(
"DownBlock2D", # 常规的ResNet下采样块
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D", # 具有空间自注意力的ResNet下采样块
"DownBlock2D",
),
up_block_types=(
"UpBlock2D", # 常规的ResNet上采样块
"AttnUpBlock2D", # 具有空间自注意力的ResNet上采样块
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D"
),
)
可以看到,使用diffusers创建UNet的步骤要比denoising_diffusion_pytorch复杂很多,好处是给工程师带来了更大的灵活性。
接下来我们看采样器的用法。这里需要确定我们加噪用的采样器,帮助我们通过一步计算得到第t步的加噪结果。
from diffusers import DDPMScheduler
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
# 一步加噪的计算
noise = torch.randn(sample_image.shape)
timesteps = torch.LongTensor([50])
noisy_image = noise_scheduler.add_noise(sample_image, noise, timesteps)
接着通过模型预测噪声,并计算损失函数。
import torch.nn.functional as F
noise_pred = model(noisy_image, timesteps).sample
loss = F.mse_loss(noise_pred, noise)
最后,我们将这些模块串联起来,便可以得到基于diffusers训练扩散模型的核心代码。
for epoch in range(num_epochs):
for step, batch in enumerate(train_dataloader):
clean_images = batch['images']
# 对应于扩散模型训练过程:随机采样噪声
noise = torch.randn(clean_images.shape).to(clean_images.device)
bs = clean_images.shape[0]
# 对应于扩散模型训练过程:对于batch中的每张图,随机选取时间步t
timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bs,), device=clean_images.device).long()
# 对应于扩散模型训练过程:一步计算加噪结果
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
with accelerator.accumulate(model):
# 对应于扩散模型训练过程:预测噪声值并计算损失函数
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
loss = F.mse_loss(noise_pred, noise)
accelerator.backward(loss)
optimizer.step()
微调Stable Diffusion
搞定了扩散模型的训练,我们可以再挑战一下Stable Diffusion模型的微调。我们可以直接参考diffusers官方提供的训练代码,别看这个代码有接近1100行,其实相比于上面提到的标准扩散模型训练,核心也只是多了VAE和CLIP的部分。
这里我节选了VAE和CLIP部分的代码,目的是让你了解这两个模块是如何加载使用的。
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
)
# 将vae 和 text_encoder的参数冻结,训练过程中权重不更新
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
你可能在代码中发现了一个tokenizer变量。它的作用便是我们在第7讲中提到的,对我们输入的prompt进行分词后获取token_id。有了token_id,我们便可以获取模型可用的词嵌入向量。CLIP模型的文本编码器(text_encoder)基于词嵌入向量,便可以提取文本特征。VAE模块和CLIP模块都不需要权重更新,因此上面的代码中将梯度(grad)设置为False。
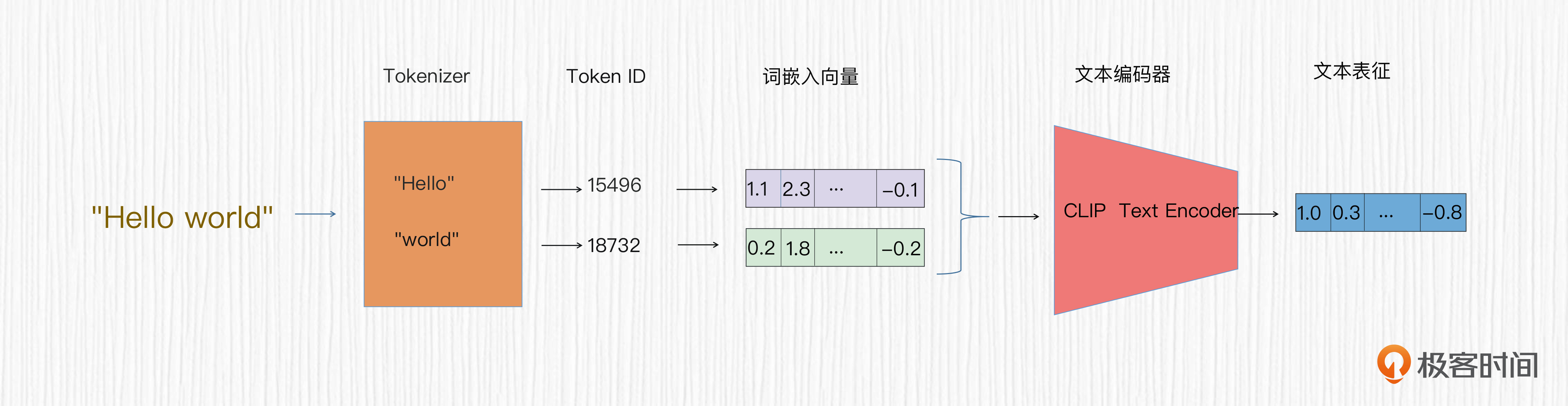
这里我需要指出,在一些情况下,比如训练DreamBooth和LoRA模型时,CLIP文本编码器的参数也可以学习和更新,这能帮我们提升模型的效果。
最后,我们再看看Stable Diffusion训练的核心代码。
for epoch in range(num_train_epochs):
for step, batch in enumerate(train_dataloader):
# VAE模块将图像编码到潜在空间
latents = vae.encode(batch["pixel_values"].to(weight_dtype)).latent_dist.sample()
# 随机噪声 & 加噪到第t步
noise = torch.randn_like(latents)
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# 使用CLIP将文本描述作为输入
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
target = noise
# 预测噪声并计算loss
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
optimizer.step()
相信你在上面的代码中看到了很多熟悉的名词,VAE、潜在空间、CLIP、文本描述等,这些都是Stable Diffusion比标准扩散模型多出来的东西。如果你想进一步确认文本描述如何通过交叉注意力机制起作用,我推荐你去看看 UNet2DConditionModel 这个模块的代码,加深理解。
如何调用各种SD模型?
其实我们可以在Hugging Face中找到各种现成的模型,我们只需通过模型的model_id,便可以直接在Colab中调用这些模型,我们这就实战练习一下。
比如我们可以使用 Counterfeit-V2.5 这个模型,首先获取到它的model_id。
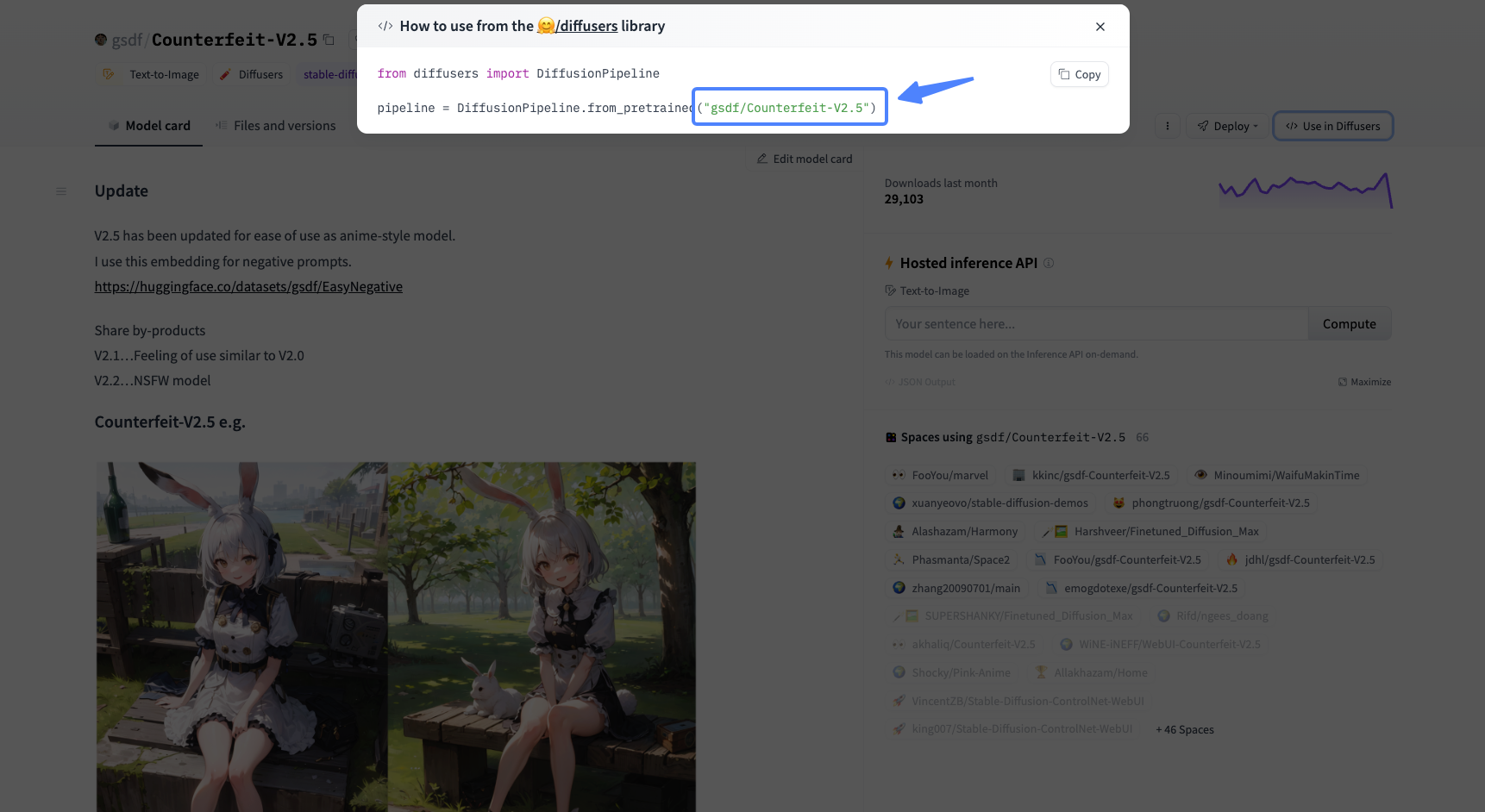
之后,我们通过后面的代码下载并加载模型。第四行的模型ID可以灵活调整,你可以切换成你心仪的模型。
import torch
from diffusers import DiffusionPipeline
from diffusers import DDIMScheduler, DPMSolverMultistepScheduler, EulerAncestralDiscreteScheduler
pipeline = DiffusionPipeline.from_pretrained("gsdf/Counterfeit-V2.5")
然后用下面代码完成切换采样器,prompt设置等操作,便可以随心所欲地创作了。
# 切换为DPM采样器
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
prompt = "((masterpiece,best quality)),1girl, solo, animal ears, rabbit"
negative_prompt = "EasyNegative, extra fingers,fewer fingers,"
images = pipeline(prompt, width = 512, height = 512, num_inference_steps=20, guidance_scale=7.5).images
你可以点开我的 Colab链接进行操作。可以在Hugging Face中调一些你喜欢的AI绘画模型,试试自己动手创作一些作品。
总结时刻
今天我们通过实战的形式加深了对扩散模型和Stable Diffusion模型的认识。在扩散模型部分,我们从数据准备开始,使用两种不同的形式从头开始进行模型训练,最终殊途同归,都能得到“不听话”的AI画师。
为了进一步调优,我们又引入VAE和CLIP模块,在开源Stable Diffusion模型的基础上,微调属于我们自己的SD模型,并深入探讨了其中的代码细节。我们也探索了如果通过代码直接使用开源社区提供的SD模型,通过短短几行代码就能实现AI绘画。
在我看来,以扩散模型为主的AI绘画,与此前GAN时代最大的不同之处便是“不可小觑的开源社区”。2022年之前,各种有趣的GAN模型和特效更多像是企业才“玩得动”的技术,而如今的AI绘画则是在放大每一个爱好者的创造力。
当前,企业会选择当前效果最好的开源模型,比如SDXL、AnythingV5漫画模型等,进一步构造海量的高质量数据,去微调这些SD模型。技术方案和我们今天实战部分微调SD模型是一样的,只不过企业有更多的GPU、图片数据和标注员。
即便如此,为什么开源社区的模型仍旧有如此抢眼的表现呢?我个人觉得,相比很多企业的KPI驱动,开源社区兴趣驱动更容易做出垂类精品。如果你也有类似的感觉,那么期待你和我一起,去做一些有意思的AI绘画模型。
这一讲的重点,你可以点开下面的导图进行知识回顾。
思考题
这一讲是我们的实战课。我们留一个实战任务。在Hugging Face中选择一个你喜欢的基础模型,通过写代码的方式生成一组你喜欢的图片。
期待你在留言区和我交流互动,也推荐你把今天的内容分享给身边的小伙伴,一起创造更有个性的AI绘画模型。
- 刘 👍(3) 💬(1)
你好,我想问下,这里微调模型和训练lora模型有什么关系?
2023-08-27 - 陈东 👍(1) 💬(1)
每次在Google colab中安装package,关闭后安装包被删除,如何永久性使用安装包?尝试了很多办法,不可行。请问老师有永久性安装办法吗?谢谢
2023-10-22 - 失落的走地鸡 👍(1) 💬(1)
微调SD模型中有行代码:tokenizer = CLIPTokenizer.from_pretrained()。前面讲transformer的组成时提到token和词嵌入,这里又将它们归属到clip,请问怎么理解这两种矛盾的说法?
2023-10-05 - Geek_535f73 👍(0) 💬(1)
Generating train split: 0%| | 0/7169 [00:00<?, ? examples/s] Traceback (most recent call last): File "/cloud/sd_hbo/lib/python3.10/site-packages/datasets/builder.py", line 1925, in _prepare_split_single for _, table in generator: File "/cloud/sd_hbo/lib/python3.10/site-packages/datasets/packaged_modules/parquet/parquet.py", line 77, in _generate_tables parquet_file = pq.ParquetFile(f) File "/cloud/sd_hbo/lib/python3.10/site-packages/pyarrow/parquet/__init__.py", line 286, in __init__ self.reader.open( File "pyarrow/_parquet.pyx", line 1227, in pyarrow._parquet.ParquetReader.open File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status pyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file. The above exception was the direct cause of the following exception: Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/cloud/sd_hbo/lib/python3.10/site-packages/datasets/load.py", line 2136, in load_dataset builder_instance.download_and_prepare( File "/cloud/sd_hbo/lib/python3.10/site-packages/datasets/builder.py", line 954, in download_and_prepare self._download_and_prepare( File "/cloud/sd_hbo/lib/python3.10/site-packages/datasets/builder.py", line 1049, in _download_and_prepare self._prepare_split(split_generator, **prepare_split_kwargs) File "/cloud/sd_hbo/lib/python3.10/site-packages/datasets/builder.py", line 1813, in _prepare_split for job_id, done, content in self._prepare_split_single( File "/cloud/sd_hbo/lib/python3.10/site-packages/datasets/builder.py", line 1958, in _prepare_split_single raise DatasetGenerationError("An error occurred while generating the dataset") from e datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
2023-09-02 - Geek_535f73 👍(0) 💬(2)
老师您好 我在自己的代码中dataset = load_dataset("nelorth/oxford-flowers")时遇到这个问题 确实网上搜了很久都没有找到答案,所以来请教您/哭
2023-09-02 - Ericpoon 👍(0) 💬(1)
试过在本地运行SDXL0.9,(1.0 运行不了,内存不足),0.9得到的图象结果没有网上写的那么好,人或动物也看着很抽象,我用的只是HUGGING FACE上给的运行代码,什么参数都没有。请问这个有没有相关的参数设置的文章,介绍一下。
2023-08-26 - 昵称C 👍(0) 💬(1)
老师,您好。我想做一个换脸,换衣服的图生图小功能。有合适的开源模型推荐么?我在用的时候stable-diffusion-v1-5模型生成的内容是有不适宜检测的,怎么能去掉这个检测呢?
2023-08-22 - 秋晨 👍(0) 💬(1)
认识基础模块 似乎缺失了讲解如何输出噪声图的代码
2023-08-18 - @二十一大叔 👍(0) 💬(1)
老师,最后调用sd模型的代码,在本地运行时有没有办法去加载本地指定文件夹下的模型,而不是去下载huggingface中的模型,目前是会把模型仓库中的所有问价都缓存到本地,这样对于切换模型时非常的不友好
2023-08-15 - peter 👍(0) 💬(1)
请教老师几个问题啊: Q1:有比较好的垂直类模型吗?推荐几个啊。 Q2:开源社区网址是什么?麻烦提供一下。前面课程也许提供了,但难以逐个查找。都是在地铁上看的,当时没有记。麻烦老师了。
2023-08-12 - Toni 👍(1) 💬(0)
思考题: 在 Hugging Face 中选择SDXL1.0 https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0 代码如下: pip install diffusers --upgrade pip install invisible_watermark transformers accelerate safetensors from diffusers import DiffusionPipeline import torch # load both base & refiner base = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True ) base.to("cuda") refiner = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-refiner-1.0", text_encoder_2=base.text_encoder_2, vae=base.vae, torch_dtype=torch.float16, use_safetensors=True, variant="fp16", ) refiner.to("cuda") # Define how many steps and what % of steps to be run on each experts (80/20) here n_steps = 40 high_noise_frac = 0.8 prompt = "RAW photo,Childhood in Beijing Hutongs,70s,two little boys playing and chasing each other,boys are dressed in shorts and vests,and appear to be very happy,the background is street,several old houses,the color tone is somewhat yellowish-brown,8k,DSLR,soft light,high quality,film grain,Fujifilm XT3" negative_prompt="mutated hands, fused fingers, too many fingers, missing fingers, poorly drawn hands, blurry eyes, blurred iris, blurry face, poorly drawn face, mutation, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, out of frame, multiple faces, long neck, nsfw" # run both experts image = base( prompt=prompt, negative_prompt=negative_prompt, num_inference_steps=n_steps, denoising_end=high_noise_frac, output_type="latent", ).images image1 = refiner( prompt=prompt, negative_prompt=negative_prompt, num_inference_steps=n_steps, denoising_start=high_noise_frac, image=image, ).images[0] image1 图发在[微信AI绘画专栏交流群]里了。
2023-08-11 - 黄尔林 👍(0) 💬(0)
请问市场那些 sd 大模型,比如麦橘,墨幽,realistic 等大模型,也是这种方式训练的吗
2024-08-17 - 奔跑的蚂蚁 👍(0) 💬(0)
sd微调 Counterfeit-V2.5这段 import torch from diffusers import DiffusionPipeline pipeline = DiffusionPipeline.from_pretrained("gsdf/Counterfeit-V2.5") 报错 AttributeError Traceback (most recent call last) <ipython-input-14-2f5c494bd124> in <cell line: 2>() 1 import torch ----> 2 from diffusers import DiffusionPipeline 3 4 pipeline = DiffusionPipeline.from_pretrained("gsdf/Counterfeit-V2.5") 7 frames /usr/local/lib/python3.10/dist-packages/jax/_src/deprecations.py in getattr(name) 52 warnings.warn(message, DeprecationWarning, stacklevel=2) 53 return fn ---> 54 raise AttributeError(f"module {module!r} has no attribute {name!r}") 55 56 return getattr AttributeError: module 'jax.random' has no attribute 'KeyArray'
2024-04-11