09 采样器:龟兔赛跑,如何选择更好更快的采样器?
你好,我是南柯。
热身篇我们学习过WebUI,你会发现里面有多种可供选择的采样器方法,包括Euler a、DPM、DDIM等等。
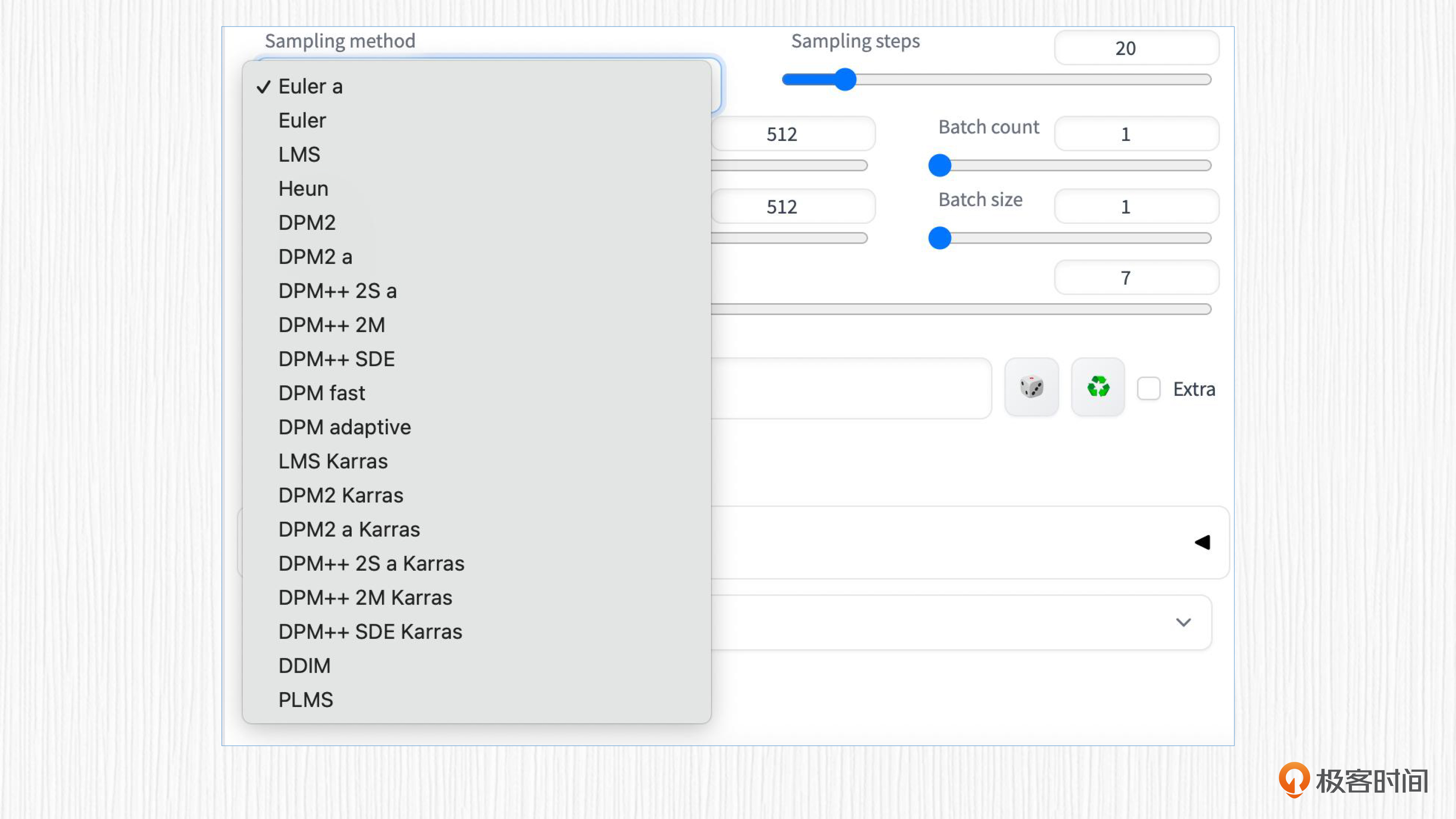
我们已经多次使用Stable Diffusion进行AI绘画,采样器存在的价值就是从噪声出发,逐步去噪,得到一张清晰的图像。比如下面这张图,展示的便是采样器如何大显神威。

那么,采样器到底是什么?它们是如何运作的?它们之间又存在哪些区别呢?今天这一讲,我们就来详细探讨这些问题,让你对采样器有一个清晰的认识。了解了不同类型的采样器以后,我还会带你做个综合测评,这样你就能结合绘图需求去选择“最佳采样器”了。
采样器基本原理
在第6讲扩散模型的学习中我们已经知道,任何图像都可以通过不断添加噪声,变成完全被噪声覆盖的图像。反过来,一张噪声图像通过逐步去除噪声,可以变得清晰可辨。
在这个去除噪声的过程中,起到关键作用的正是今天课程里的“主角”——采样器。
为了搞清楚采样器是如何起作用的,我们要先回顾一下第6讲的内容。对于从噪声生成图像的扩散模型,UNet模型负责预测要去除的噪声。UNet模型的输入是时间步 $t$ 对应的噪声图像 $x_t$ 和时间步$t$的编码。UNet的输出的不是上一个时间步 $t-1$ 的噪声图像,而是上一个时间步添加的噪声值 $\epsilon_{t-1}$。
这时候,我们需要结合噪声图像 $x_t$,时间步 $t-1$ 的噪声 $\epsilon_{t-1}$,去获取上一个时间步 $t-1$ 的噪声图像 $x_{t-1}$。将有噪声的图像 $x_t$ 减去UNet预测的噪声 $\epsilon_{t-1}$,便能恢复出上一步有噪声的图像 $x_{t-1}$。现在就是采样器发挥作用的时候,对于经典的DDPM采样器而言, $x_{t-1}$ 可以通过下面的公式来进行计算。
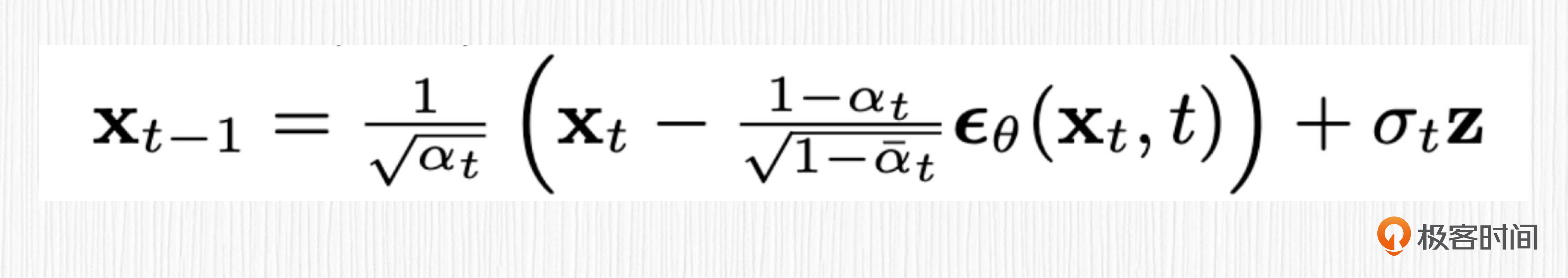
公式中的 $\alpha_{t}$,$\sigma_{t}$ 和 $z$ 都是已知的数值。整个过程重复多次,最终你将获得一个干净的图像。这个去噪过程称为采样,采样中使用的方法被称为采样器或采样方法。在 DDPM的论文中使用大量篇幅推导采样器的计算公式,感兴趣的同学可以翻阅原始论文。
对于绝大多数AI绘画的工作场景,我们只需要掌握各种采样器的特性即可,不需要熟练掌握采样器背后的推导过程。
我们开头提到的各种不同的采样器,在表现形式上便是不同的 $x_{t-1}$ 计算公式。在实际使用中,针对同一个训练好的UNet噪声预测模型,我们可以使用各种不同的采样器去除噪声。
现在,你对UNet和采样器的分工是不是很清晰了呢?我通过两个图例来说明。
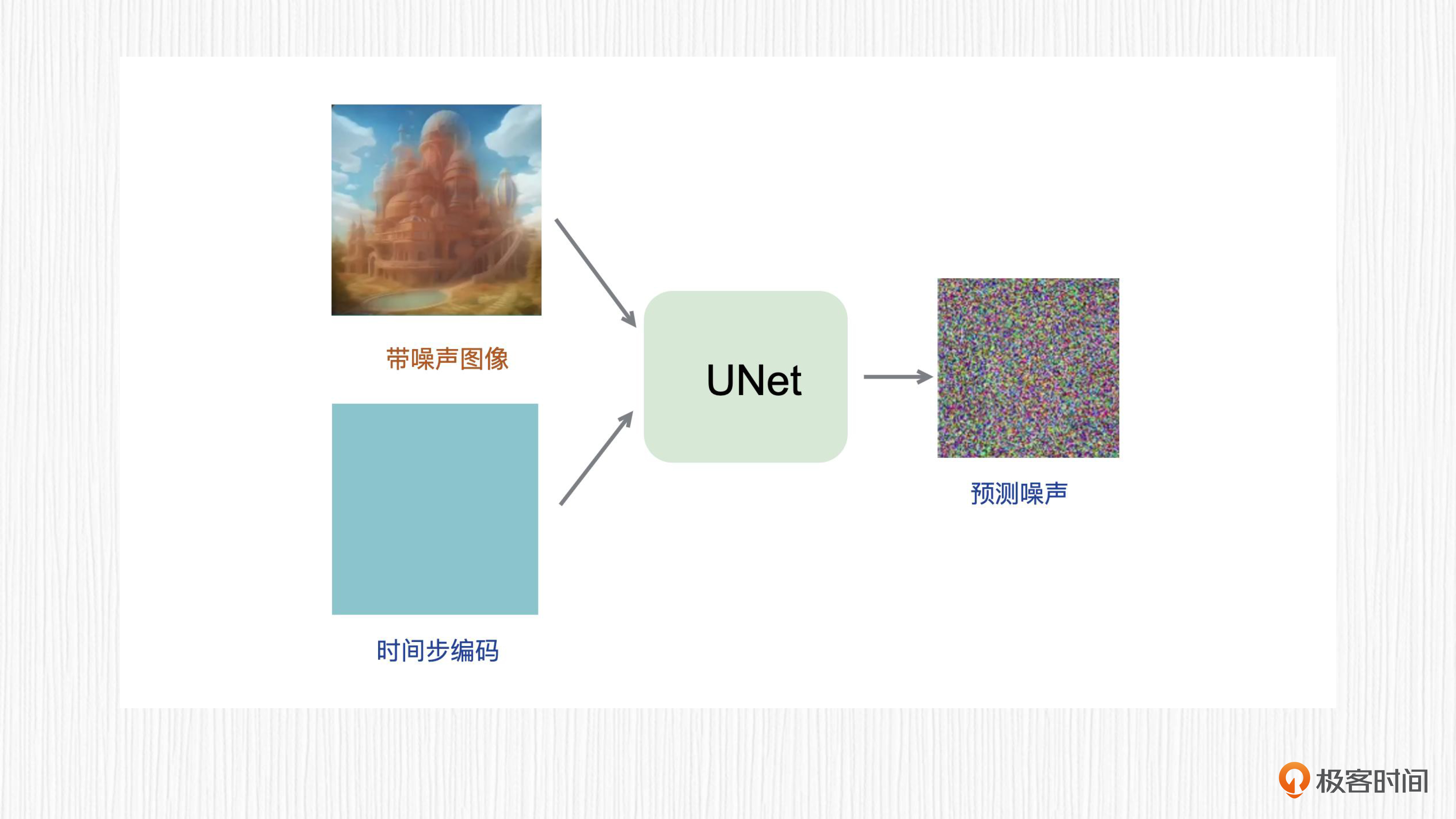

对于Stable Diffusion模型而言,UNet的输入还多出一个文本条件的特征信号,便于我们用prompt控制绘画结果。
简言之,UNet负责预测噪声,采样器负责“减去”噪声。这个过程反复迭代,我们就能从噪声图$x_t$得到$x_{t-1}$,然后得到$x_{t-2}$,最终得到$x_0$,也就是清晰可辨的图像。
采样器技术探究
了解了采样器的基本工作模式,你可能会提出这样的疑问——为什么相同的UNet模型可以使用不同的采样器?
要回答这个问题,我们需要重新看一下扩散模型的设计和训练过程。我们已经知道UNet模型真正预测的是上一个时间步增加的噪声值 $\epsilon$,而不是上一个时间步的噪声图像 $x_{t-1}$。
你可以点开流程图复习下扩散模型的训练。

一旦我们得到训练好的UNet,便可以使用它进行AI绘画。还是以DDPM算法为例,在推理过程中,采样器会在下面流程图中的第四步发挥作用。仔细观察你会发现,采样器与UNet模型的能力是不冲突的。这便解释了为什么在WebUI中我们使用同样的AI绘画模型,却可以任意选择采样器。

提到任意选择采样器,我们知道,加噪的过程有1000步,那么是不是去噪过程也需要1000步呢?为什么在WebUI中不同采样器设置的步数会不同呢?
我们进一步探讨一下。如果我们使用训练过程的逻辑进行采样,也就是每次只去噪一步,那么在扩散模型中生成清晰图像确实需要进行1000步的采样,也就是UNet的运算要重复1000次。这种方法非常耗时且占用资源。
实际上,如果我们使用更“快速”的采样方法,例如Euler a、DPM等,只需要进行20步采样就能得到清晰的图像。在这种情况下,模型每次去噪的间隔时间步是50,相当于一次去掉50个噪声,以跳跃的形式生成清晰的图像$x_0$。
因此,较少的步数意味着每个去噪步骤跨度更大。这种方法可以更高效地生成清晰图像,减少了计算量和时间消耗。在编写这一讲时,WebUI提供了19种可用的采样器。随着时间的推移,这个数字在不断增加。
相信你已经明白,不同采样器之间的去噪过程就像是龟兔赛跑,有的步子迈得大、有的迈得小。那跑得快的采样器是如何更快实现这个过程的呢?其实也并不神秘,有点像我们高中看到一道复杂的应用题,经过一些数学变换,就变成更容易解决的“数学题”了
学术界也确实发现,这个工程问题经过一系列数学变换,实际无非是解决一些随机微分方程(stochastic differential equations,SDE)和常微分方程(ordinary differential equations,ODE)的问题。
随机微分方程描述的是一种或多种随机成分影响到系统的情况,系统的行为带有随机性。一个典型的例子是布朗运动,液体中的小颗粒在各个方向上不断经受随机碰撞,从而使它的运动路径变得难以预测。
而常微分方程描述的是只含单一自变量的连续变化系统,系统状态转移是确定的,没有随机性。一个典型的例子是热传导,因为在确定的条件下(比如初始温度、边界条件、系统物理性质等),热量在物体中的传播过程是可以预测的。简而言之,随机微分方程研究的是随机系统,常微分方程研究的是确定性系统。
是不是觉得刚才说的这些名词听着就头大?放轻松,其实你需要知道的结论就是——这个问题已经有了不少数学解决方案,这也是这些采样器的主要差异和由来。其实列表中的一些采样器早在一百多年前就被发明出来了。
WebUI中怎样选择合适的采样器
弄明白了采样器的底层原理,我们再逐一认识下WebUI中这些采样器。
首先认识下用于求解常微分方程的老派采样器。
- Euler,可以看作是最简单的求解器。
- Heun,比欧拉法更准确但速度较慢。
- LMS (Linear multi-step method),与欧拉法速度差不多,但(据说)更准确。
除了这三个老派采样器,你可能注意到还有一些采样器的名称中也有一个字母 a 呢?比如Euler a、DPM2 a、DPM++ 2S a、DPM++ 2S a Karras,它们都属于祖先采样器(ancestral samplers)。祖先采样器会在每个采样步骤中向图像添加噪声。因为采样结果有一定的随机性,所以它们是随机采样器。
接下来我们看看带有 “Karras” 标签的采样器。它们采用了 Karras文章中推荐的噪声策略。在接近去噪过程结束时,将噪声步长变小。研究人员发现这可以提高图像的质量。
而DDIM(去噪扩散隐式模型)和PLMS(伪线性多步方法)是最初发布的SD模型v1中附带的采样器。不过,这两个采样器目前通常被认为已经过时,并且不再广泛使用。所以在WebUI中的位置也比较靠后。
DPM(扩散概率模型求解器)和DPM++采样器是2022年发布的专为扩散模型设计的新采样器。带有DPM标志的采样器代表了一系列具有相似架构的求解器。
说了这么多理论知识,还是得学以致用印象才更深刻。在实战中,这些采样器到底有怎样的区别呢?我们来看看社区的网友提供的一些样图。


看起来这些采样器有一些差异,但并不是非常明显。举个例子,虽然带有 “a” 的祖先采样器引入了更多的变化,但这并不意味着它们的质量更高。一些采样器的最终结果可能相似,但也有一些差别非常大。
那么我们在实践中,该如何选择采样器呢?我给你提供几个选择采样器的建议。
- 如果你想使用快速、新颖且质量不错的算法,最好的选择是DPM++ 2M Karras,设置 20~30步。
- 如果你想要高质量的图像,那么可以考虑使用DPM++ SDE Karras,设置 10~15 步,但要注意这是一个计算较慢的采样器。或者使用DDIM求解器,设置 10~15 步。
- 如果你喜欢稳定、可重现的图像,请避免使用任何原始采样器(SDE类采样器)。
- 如果你喜欢简单算法,Euler和Heun是不错的选择。
总结时刻
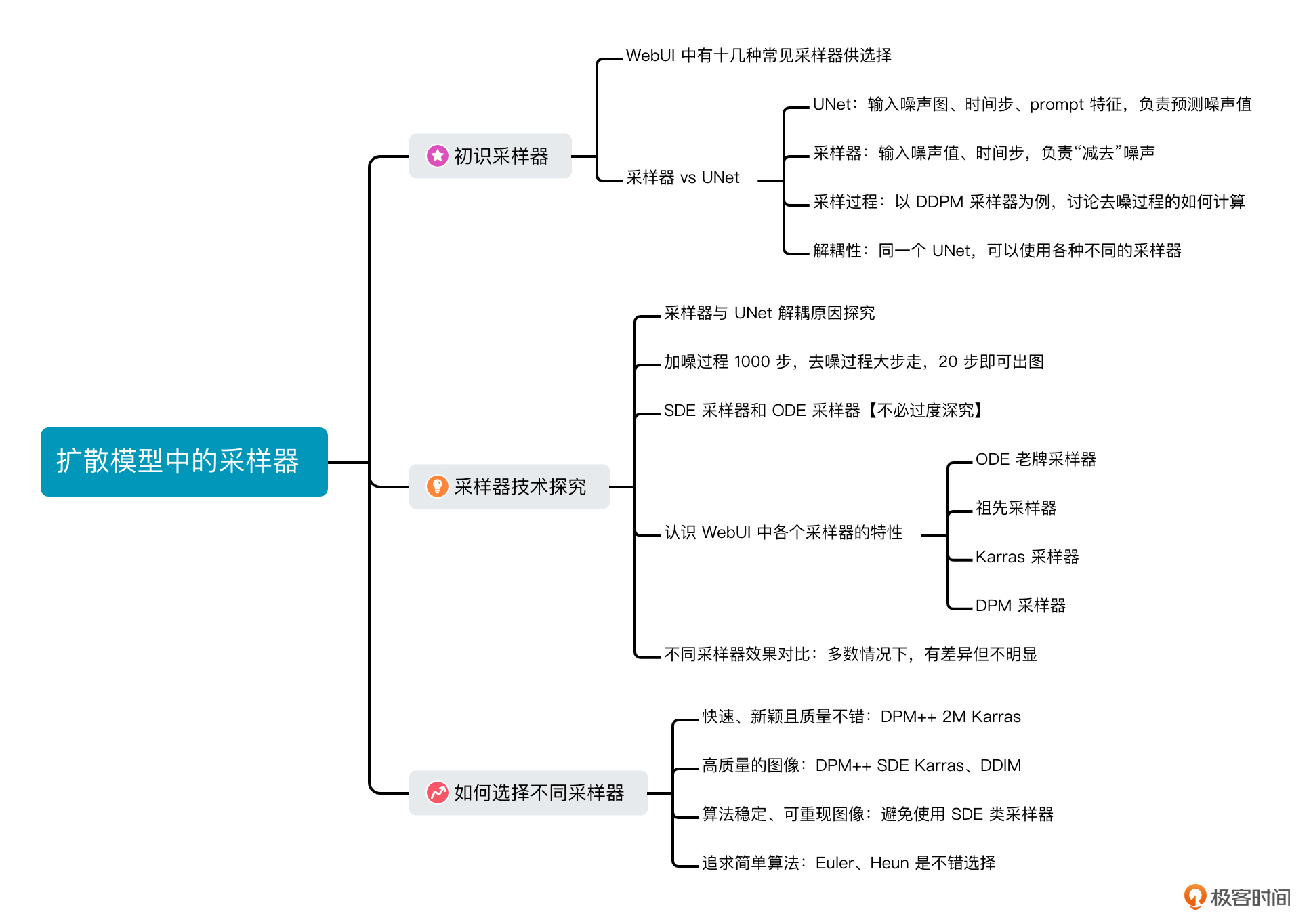
这一讲,我们学习了不同类型的采样器和它们在图像生成中的应用。
首先,我们了解了采样器通过去除噪声的方式来生成图像。接着,我们详细对比了这些采样器之间的差异,包括早期的ODE采样器、带有祖先采样的采样器以及基于Karras论文的采样器策略。
结合这些采样器的特点,我为你梳理了一些建议,帮助你在实际应用中选择合适的采样器。总的来说,选择合适的采样器需要综合考虑速度、生图质量和个人偏好。了解不同采样器的特点和应用场景,可以帮助我们在图像生成过程中做出明智的选择。
思考题
你在使用WebUI的过程中,选择采样器有哪些具体的心得?比如,追求生成速度与效果,该如何选择采样器?不同采样器在你的任务中有怎样的差异?
期待你的分享,积极讨论有助于你更好地消化课程内容。如果这一讲对你有帮助,也推荐你把课程分享给更多朋友。
- 石云升 👍(1) 💬(1)
如果采样器都差不多,为啥webuI有10几个这么多。除了老师总结的几个用法外,还有没有更具体的区别?我的理解是,应该是某个采集器解决不了某个场景的问题,才会有人去研发一个新的采集器。
2023-08-04 - peter 👍(1) 💬(1)
请教老师两个问题: Q1:那个1000步是怎么来的?经验值吗? Q2:假如我要写采样器的论文,可以从哪些方面推出新的采样器?
2023-08-04 - 王大叶 👍(0) 💬(1)
仔细观察你会发现,采样器与 UNet 模型的能力是不冲突的。这便解释了为什么在 WebUI 中我们使用同样的 AI 绘画模型,却可以任意选择采样器。 ---- 这里不太理解,为什么采样器和 Unet 模型的能力不冲突?老师可以稍微多解释一下吗?
2023-08-31 - 和某欢 👍(0) 💬(1)
请教老师一个问题,文中说有些采样器是执行一步,内部间隔的时间步是50步。这里间隔的时间步是怎么得出的呢? 有没有间隔时间步是1000步的呢?只需要计算一次就可以出图
2023-08-20