08 巧用神经网络:如何用UNet预测噪声
你好,我是南柯。
前面我们已经学习了扩散模型加噪和去噪的过程,也了解了Transformer的基本原理。之前我还埋下了一个伏笔,那便是使用UNet网络预测每一步的噪声。
今天我就来为你解读UNet的核心知识。在这一讲,我们主要解决后面这三个问题。
- UNet模型的工作原理是怎样的?
- 在各种AI绘画模型里用到的UNet结构有什么特殊之处?
- UNet与Transformer要如何结合?
搞懂了这些,在你的日常工作中,便可以根据实际需求对预测噪声的模型做各种魔改了,也会为我们之后训练扩散模型的实战课打好基础。
初识UNet
在正式认识UNet之前,我们有必要先了解一下图像分割这个任务。
图像分割是计算机视觉领域的一种基本任务,它的目标是将图像划分为多个区域,对应于原图中不同的语义内容。比如下面这个例子,就是针对自动驾驶场景的图像分割效果。

图像分割与我们熟悉的图像分类任务目标有所不同,图像分类任务的目标是为整张图像分配一个整体标签,而图像分割任务的目标是为每个像素分配对应的类别标签。
UNet出现之前,图像分割采用的主要方法是2015年提出的 FCN(全卷积网络)。与传统的CNN(卷积神经网络)不同,FCN去掉了最后的全连接层,而是使用转置卷积层实现上采样的过程。通过这样的操作,FCN可以获得与输入图像相同尺寸的输出。

虽然FCN为图像分割任务带来了显著的改进,但仍然有一定的局限性。比如,FCN结构无法最大限度地利用不同层级的特征,这会导致分割结果中存在边缘细节丢失等问题。
在这种情况下,UNet 应运而生,它同样出现在2015年。我们先直观感受下UNet的U型结构。

对照示意图可以看到,UNet是一种U型的全卷积神经网络,存在一个明显的编码、解码过程,并且编码器和解码器中间存在特征融合。UNet一经提出,便成为处理图像分割任务的经典模型。AI绘画大火之后,我们拆解Stable Diffusion等经典方案的时候都感觉很惊奇,为什么呢?因为你会发现,扩散模型中最关键的噪声预测模块,竟然都是用的UNet!
想要完整理解AI绘画中的UNet模块,我们还需要从UNet的基本结构说起。
基本结构
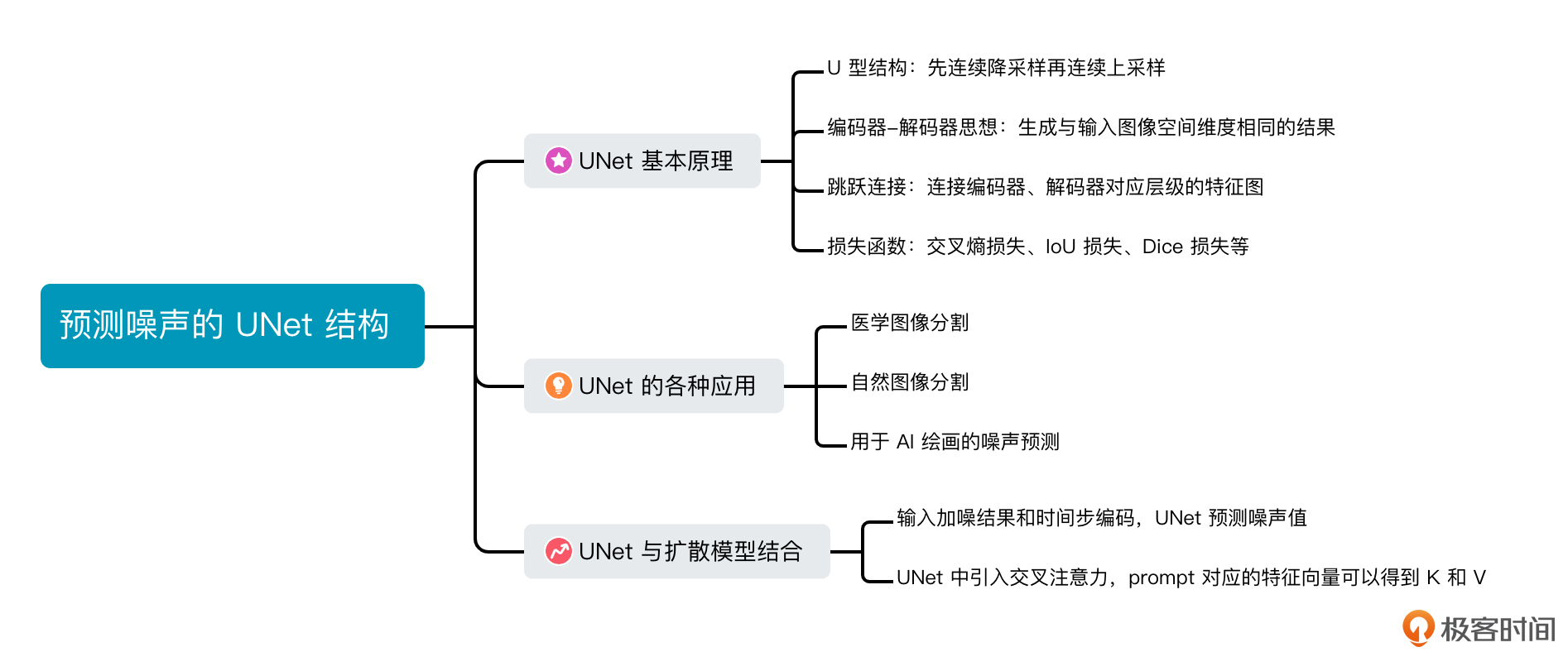
关于UNet的基本结构,有三个点需要我们关注,第一是它独特的U形结构,第二是其基于编码器-解码器设计思想,第三是编码器和解码器之间的跳跃连接。
首先来看U形结构。UNet的架构看上去像一个大写字母“U”,它由两部分组成:左侧是编码器,右侧是解码器。对于图像分割任务,编码器的输入是原始图像,解码器的输出是分割结果。
需要注意的是,UNet的输出尺寸有时会比输入尺寸小,需要一些后处理步骤(如插值)来调整输出尺寸,得到和输入分辨率一致的结果。UNet模型输入输出的这种“一致性”,让它可以应用于各种需要输出“图像”的任务。
然后是编码器和解码器。UNet的编码器由连续的卷积层和池化层交替组成,每个卷积层用于提取更深层次的图像特征,通常在卷积之后使用非线性激活函数(如ReLU)以引入非线性。随后,池化层(如最大池化)用于进行降采样,以减小每一层的空间尺寸。经过编码器阶段后,高分辨率的输入图像就转化成了具备较低空间尺寸的特征图。
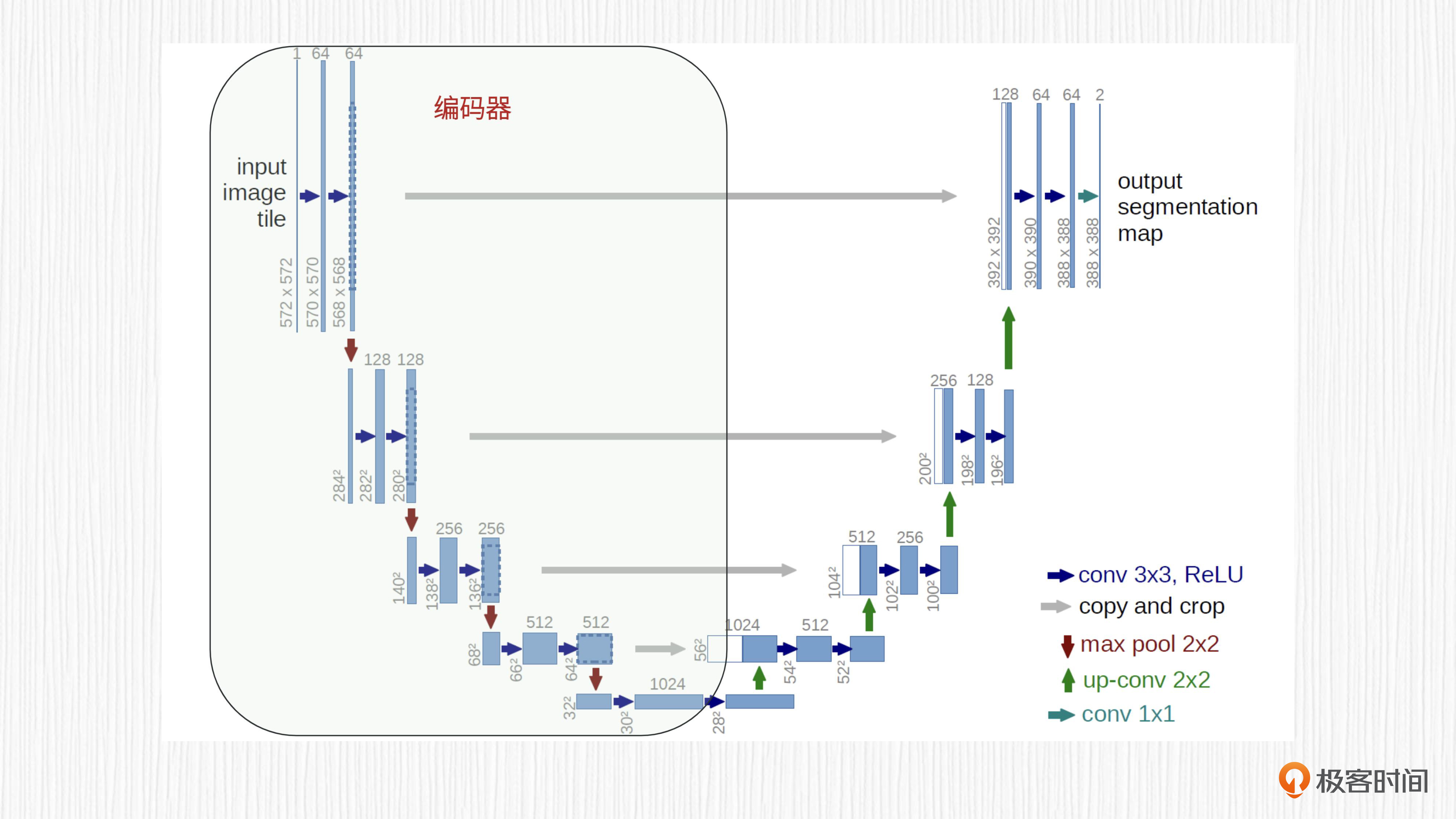
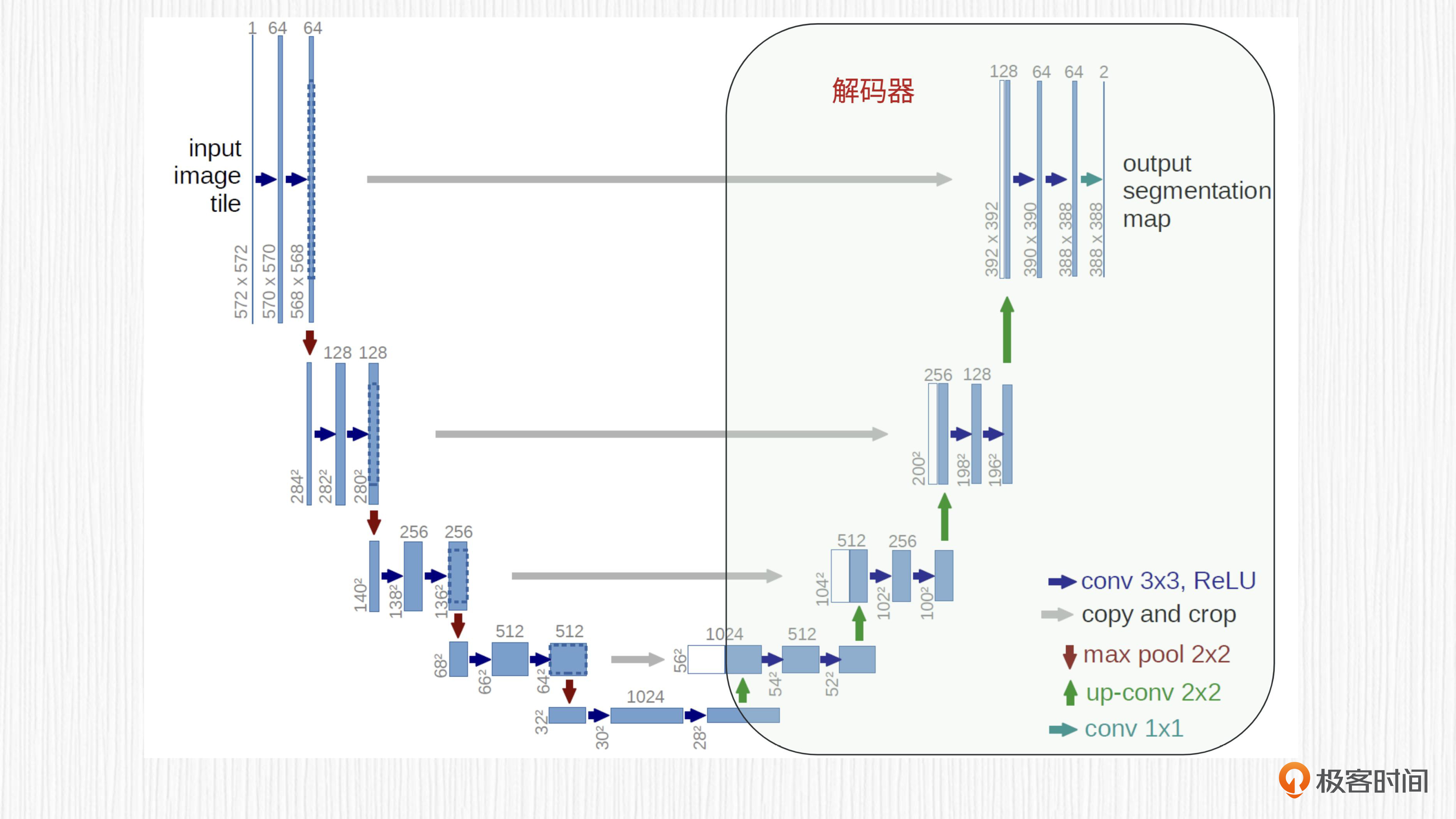
UNet的解码器与编码器相反,它通过连续的反卷积或转置卷积层进行上采样,逐步将低维特征图恢复到原始图像的分辨率。每个反卷积或转置卷积操作后,得到的特征同样会执行非线性激活函数,以增加模型的非线性。
解码器的目的是利用编码器生成的深层特征,生成与输入图像空间维度相同的结果(可能需要插值后处理),以便进行像素级预测。
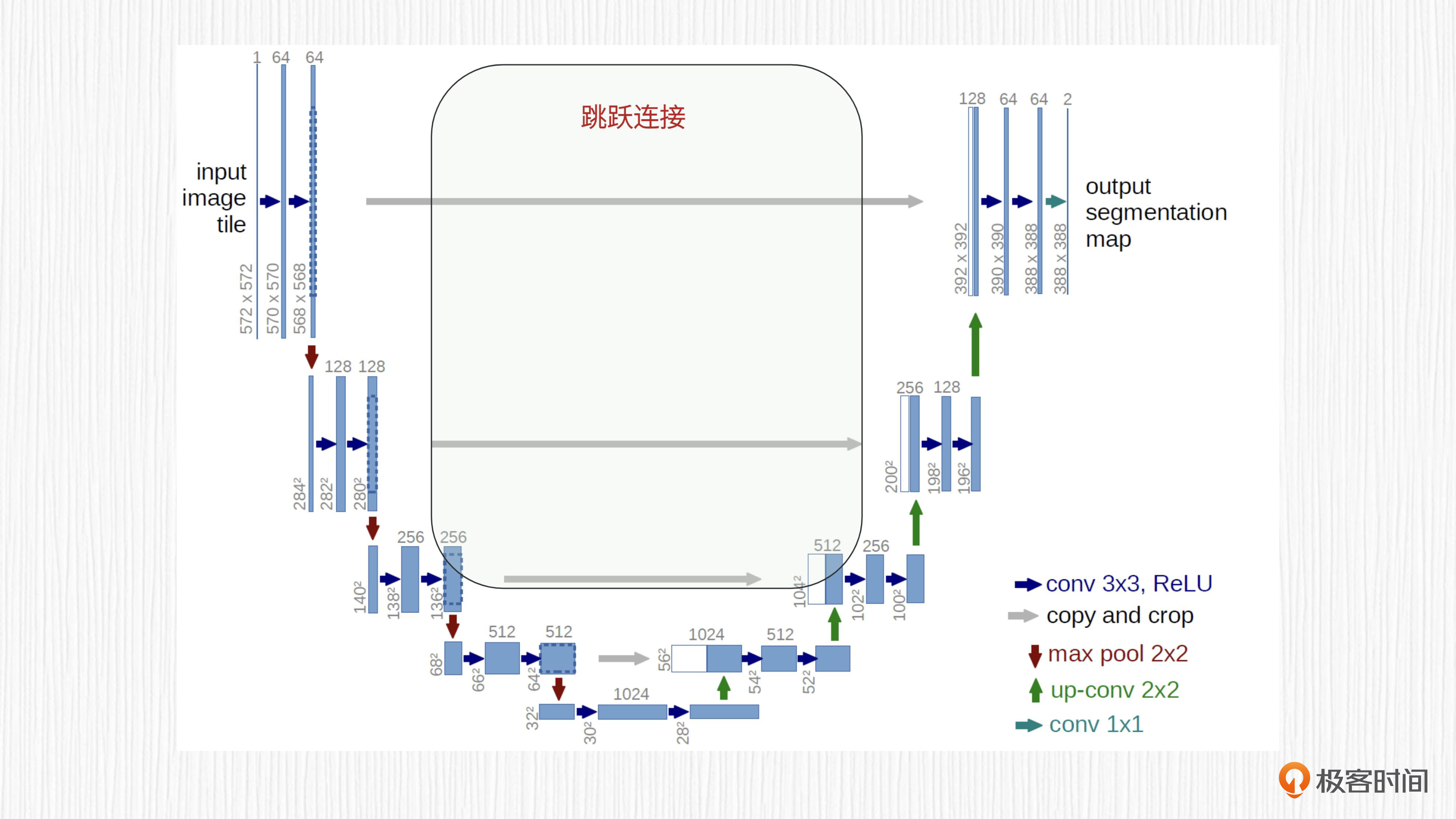
最后我们来看跳跃连接。编码器和解码器之间的特征融合是通过跳跃连接实现的。跳跃连接将编码器中相应层级的特征图与解码器中的特征图连接在一起,这样解码器才能捕捉更丰富的细节信息,进一步提高网络性能。
损失函数
再来看损失函数的设计。对于图像分割任务,交叉熵损失函数(Cross Entropy Loss)是一种常用的损失函数。
交叉熵损失函数广泛用于分类任务,它能度量模型的预测概率分布与真实标签分布之间的差异。对于图像分割任务,每个像素都需要进行分类,也就是判断这个像素属于哪一个类别。因此,我们需要对图像中每一个像素都计算交叉熵损失,用平均或者求和的方式将这些损失合并,得到最终的损失值。
后面是图像分类任务和图像分割任务中交叉熵损失函数的代码实现,看看代码实现和对应的注释,你会更容易理解。
import numpy as np
def cross_entropy_classification(y_true, y_pred):
"""
y_true: 真实标签。这是任务的真实答案,通常由人类标注或事先知道。
对于分类任务(如猫狗分类),y_true可以是类别的索引或 one-hot 编码表示。
y_pred: 预测标签。这是模型预测的结果。
对于分类任务,y_pred是一个概率分布向量,表示每个类别的预测概率。
"""
y_pred = np.clip(y_pred, 1e-9, 1 - 1e-9) # 数值稳定性处理,将预测值限制在[1e-9, 1-1e-9]范围内
return -np.sum(y_true * np.log(y_pred))
def cross_entropy_segmentation(y_true, y_pred):
"""
y_true: 真实标签。这是任务的真实答案,通常由人类标注或事先知道。
对于分割任务(如语义分割),y_true是一个二维或多维数组,
表示每个像素对应的类别索引或 one-hot 编码表示。
y_pred: 预测标签。这是模型预测的结果。
对于分割任务,y_pred是一个三维数组,存储每个类别在每个像素位置的预测概率。
"""
y_pred = np.clip(y_pred, 1e-9, 1 - 1e-9) # 数值稳定性处理,将预测值限制在[1e-9, 1-1e-9]范围内
num_classes, height, width = y_true.shape
total_loss = 0
for c in range(num_classes):
for i in range(height):
for j in range(width):
total_loss += y_true[c, i, j] * np.log(y_pred[c, i, j])
return -total_loss
# 示例代码(假设类别是经过 one-hot 编码的)
y_true_class = np.array([0, 1, 0])
y_pred_class = np.array([0.1, 0.8, 0.1])
y_true_segment = np.random.randint(0, 2, (3, 32, 32))
y_pred_segment = np.random.rand(3, 32, 32)
# 计算分类任务损失
classification_loss = cross_entropy_classification(y_true_class, y_pred_class)
# 计算分割任务损失
segmentation_loss = cross_entropy_segmentation(y_true_segment, y_pred_segment)
print("分类任务损失:", classification_loss)
print("分割任务损失:", segmentation_loss)
通过最小化交叉熵损失函数,我们可以训练UNet模型以获取准确的像素级分类。在实际使用中,我们还可以使用其他的损失函数,如Dice损失函数、IoU损失函数等,来衡量分割结果与真实标签之间的差异。这些损失函数各有优劣,可能在不同类型的任务上表现出不同的性能。所以,在选择损失函数时,我们需要考虑实际问题的特点。
UNet的应用
计算机视觉领域里,UNet应用很广泛,我们这就来看看它有哪些应用。
首先是医学图像分割领域。UNet可以用于细胞分割,识别生物显微镜下的细胞边界,用于计数、分型等任务。UNet也可以用于器官分割,识别MRI或CT等影像中的目标结构,比如识别脑部病变、肝脏肿瘤或肺结节等。UNet应用于血管分割,可以识别眼底图像中的血管结构,有助于眼科疾病的诊断。

其次,UNet用于自然图像分割。对于街景分割任务,可用于识别道路、行人、车辆等元素,辅助无人驾驶、智慧交通等领域。对于航拍图像分割,UNet可以从高分辨率的航空图像中提取建筑、湖泊、森林等地物信息,帮助城市规划和资源调查。此外,UNet还能用于人像分割,可以识别人像照片的背景,实现背景替换、虚化等目的。

另外,UNet还可以被用于AI绘画,这和我们的课程息息相关,具体的用法就是把UNet用于扩散模型的噪声预测,我们这就来一探究竟!
与扩散模型结合
在第6讲中我们已经提到,扩散模型的噪声是通过一个神经网络预测得到的。
我们简单回顾下扩散模型中噪声预测模型的使用方式。这个模型的输入是第t步加噪结果图像和时间步t的编码,预测从第t-1步到第t步噪声值。也就是说,输入和输出在分辨率的维度是相同的。
UNet结构自然适用于这个任务,只不过损失函数由图像分割任务的交叉熵损失变成了噪声预测的L2损失。
下面的图展示了Stable Diffusion的UNet结构,这一讲我们先把焦点放在UNet结构上,至于其余部分,我们在后面的课程再拆解。
这里的UNet的输入,$Z_{T}$可以看作是第t步加噪结果图像和当前时间步编码的融合结果,UNet的输出是与$Z_{T}$ “分辨率”相同的噪声$\varepsilon_{\theta}$。细心的你可能已经发现问题了,怎么多了一些QKV的模块?
没错,正是我们上一讲学习的交叉注意力机制(Cross Attention)。

还记得么,交叉注意力机制从源序列产生K和V向量,从目标序列产生Q向量。在Stable Diffusion中,我们将$Z_{T}$视为目标序列,得到Q;将prompt描述经过CLIP模型得到的特征向量作为源序列,得到K和V。
你可以先把CLIP看作一个文本信息提取模型。因此,AI绘画中用到的UNet实际上是引入了Transformer思想的加强版UNet模型。下面这个图展示的是简化版AI绘画UNet结构,实际使用的UNet要堆叠更多的降采样和上采样模块。
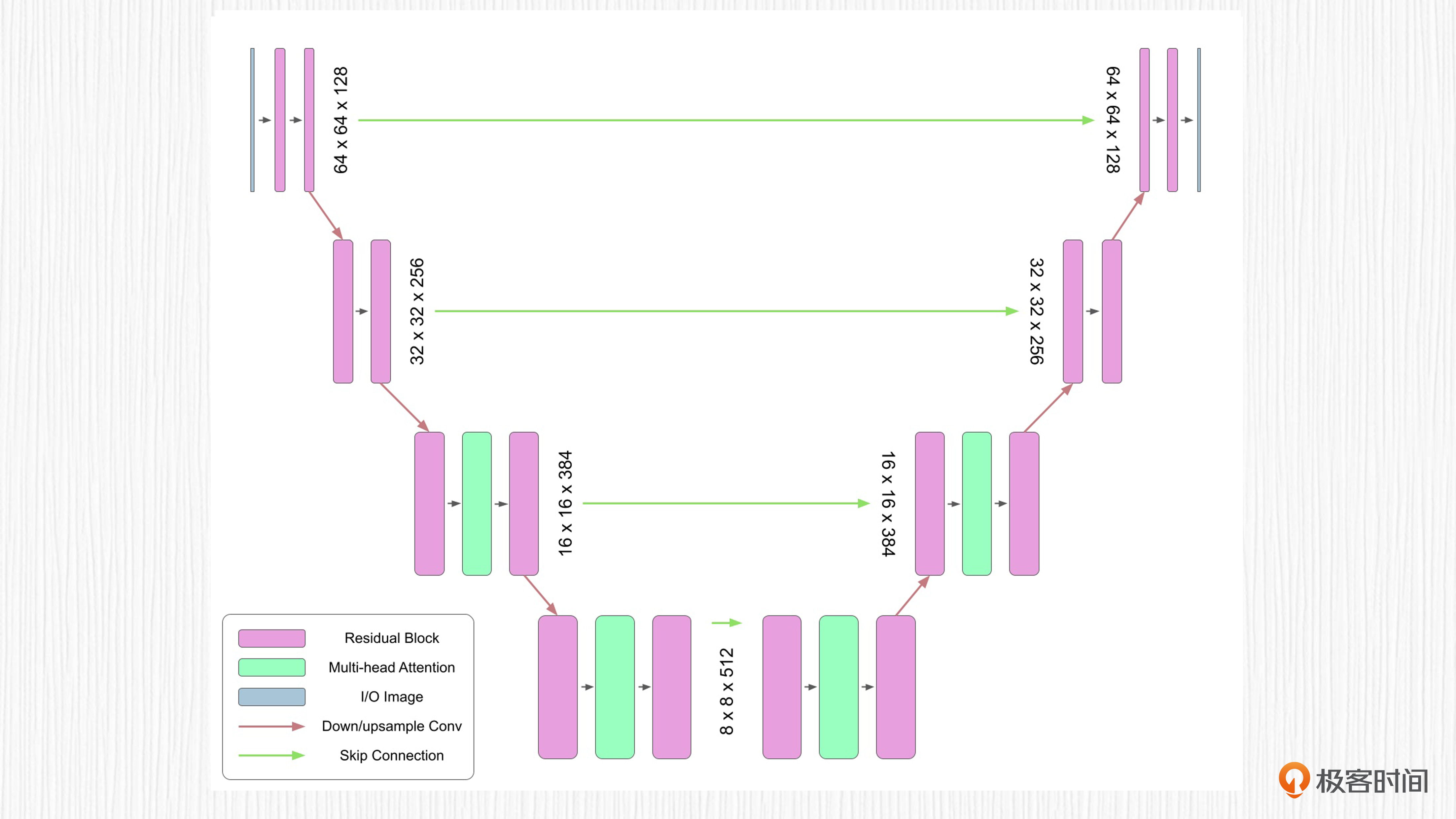
有意思的是,学者们也在试图换掉扩散模型中的UNet结构,比如2022年12月UC伯克利的学者提出了使用纯粹的Transformer替代UNet结构。毕竟我们已经知道,Transformer结构的输入和输出“分辨率”可以做到相同,并且天生自带交叉注意力机制。感兴趣的同学可以课后了解更多细节。
总结时刻
今天我们学习了UNet模型结构,这种基于编码器-解码器设计思想的U形深度学习网络,尤其适用于图像分割任务。独特的跳跃连接机制使得UNet能够有效地结合不同层级的特征,从而达到高质量的像素级预测。
UNet在扩散模型中被用于预测噪声。在原始的UNet基础上,插入了交叉注意力模块,巧妙地引入了我们输入的prompt文本描述信息,从而帮助我们随心所欲地控制AI绘画的内容。
思考题
- 扩散模型的生成速度比较慢,因为需要从噪声出发逐步去噪。通过今天的学习,你已经知道每一步去噪的过程都需要用UNet进行噪声预测。结合这一讲的知识,你不妨说说自己对于生成加速的见解。
- 关于UNet用于图像分割任务,除了今天我们已经介绍的应用,你还能举出哪些应用场景?
欢迎你在留言区和我交流互动,积极思考能够提升你的学习效果。如果这一讲对你有帮助,别忘了分享给身边更多朋友。
- 徐大雷 👍(3) 💬(0)
想请问一下老师,你这边的头像使用的啥模型生成的呀,还有对应的提示词是啥呀,谢谢
2023-08-08 - 海杰 👍(0) 💬(1)
会讲下CLIP 模型吗?看网上不少范例的参数都有说用CLIP skip step 2,想知道原理。谢谢。
2023-08-05 - 一只豆 👍(0) 💬(1)
这也太绝妙了吧!“在 Stable Diffusion 中,我们将 Z_{T} 视为目标序列,得到 Q;将 prompt 描述经过 CLIP 模型得到的特征向量作为源序列,得到 K 和 V。” 语义信息就这样把注意力跨模态的映射到图片信息了……
2023-08-04 - Ericpoon 👍(0) 💬(1)
为什么说unet,或AI画画的模型学习,要用decoder输出喿声?
2023-08-03 - peter 👍(0) 💬(2)
请教老师两个问题: Q1:跳跃连接,是两个对等层的数据会有关系吗?比如,右边的层会使用左边的层的数据作为输入。 Q2:有能唱歌的AI吗?
2023-08-02