答疑课堂1 热点问题答疑&前两章思考题答案
你好,我是南柯。
现在,我们已经完成了热身篇和基础篇的学习。在更新过程中,我也看到了很多同学的留言评论。其中包括工具安装配置问题、基础知识理解等方面的问题。这次加餐,我把评论区的共性问题做了一个整理,希望能帮你答疑解惑。
另外,前面12讲的思考题参考答案,我也放在了这篇加餐里。不过我更希望你可以独立思考或亲自动手尝试,这样学习效果会更好。
电脑硬件建议
对于WebUI的安装,如果使用GPU,最低显存建议在8GB,最低使用GTX1050Ti的显卡设备。在此基础上,显卡越强越好。如果用的是苹果电脑,M系列处理器的安装更简单一些,不过使用苹果电脑做AI绘画需要考验你的耐心。
举个简单的例子,同样是设置20步生成一张512x512分辨率的图像,苹果电脑需要25~30秒,而T4显卡只需要3-4秒左右。
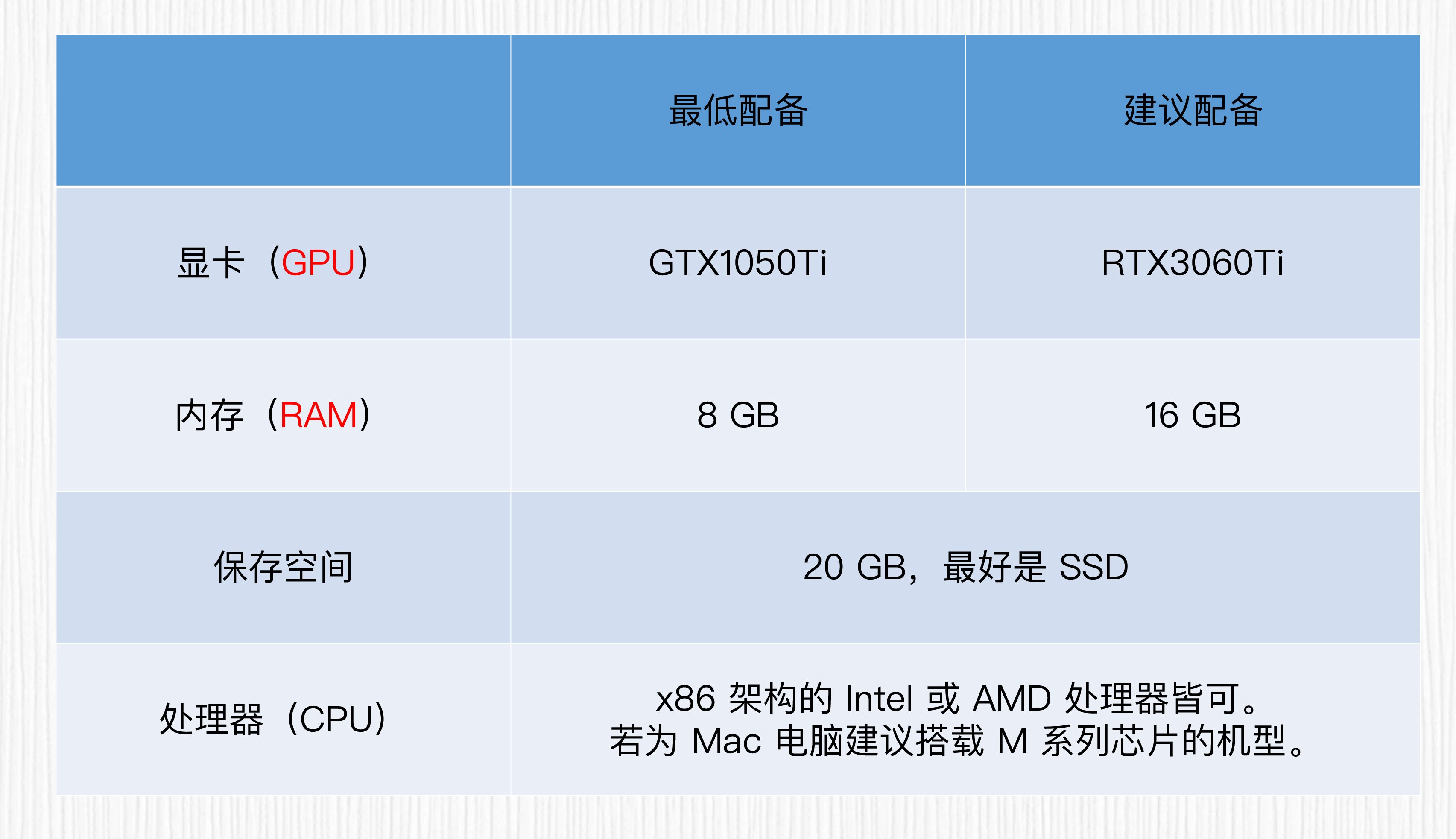
大家手中的设备可能会有差异,遇到具体的安装问题,可以先搜索下是否有前人踩过坑。写代码的同学对于解决“环境”问题的棘手都是深有体会。如果遇到解决不了的问题,写在留言区,大家一起想办法解决。这里我也推荐你通过后面这个链接学习更多的WebUI使用技巧。
如果硬件环境不支持WebUI,或者折腾很久也没安装成功,这种情况也不必着急。我们课程的前4讲,也可以先用第三方平台集成的WebUI环境进行操作(推荐的工具我在后面列出)。这门课程的实战2到实战6都是使用Google的Colab,不涉及环境问题。我们学习WebUI,更侧重帮你建立起对AI绘画的直观认识。
绘画软件和开源社区推荐
关于开源社区,Hugging Face 和 Civitai 是AI绘画炼丹师必用的工具,我们可以在这两个社区获得海量的AI绘画基础模型和LoRA模型,帮我们创作各种有趣的效果。
关于绘画软件。这个问题见仁见智,互联网上有各种AI绘画工具。我可以推荐三个我用过的。
首先是 Midjourney,开通账号后Midjourney和Nijijourney都可以使用。至于成本问题,相信你一定能想到办法。
第二个是海艺这个网站。它的优点是支持中文提示词,对国内使用者比较友好,每天可以免费用60次。目前可以训练LoRA模型。不过,在这个网站上训练完LoRA,我没有找到下载到本地的方法。如果你有方案,也欢迎写在留言区。
第三个是画宇宙。它提供了海量绘画模型,除了我们常用的文生图、图生图,画宇宙也可以用于智能商品图、人像风格化等场景,是一个不错的AI艺术创作工具,既面向个人创作者,也有企业API接口。
电脑配置太低用不了WebUI?上面提到这些平替第三方工具值得一看。此外,类似于青椒云这样的平台可以提供安装好了WebUI的远程桌面,也可以用于你上手WebUI。
让GPT成为你的学习帮手
如果课程中遇到一些基础知识盲点,或者我们没有深入展开的话题,我推荐你和ChatGPT交流一番。如果对于CLIP、Transformer、VAE这种2021年以前的基础算法有问题,可以多和它讨论。
不过你要注意,用于训练ChatGPT的数据应该截止到2021年,像图像扩散模型、Stable Diffusion这类知识ChatGPT并不了解,它可能会胡乱回答。

有代表性的留言问题
Q1:学习这门课需要什么基础?
这门课主要探讨AI绘画背后的核心技术,也会带着大家做一些有意思的AI绘画项目实战。学习这门课程,需要有一定的python基础(比如能够运行和修改python代码)和深度学习基础(比如了解卷积运算、全连接等基本概念)。当然,课程中遇到一些没有展开的基础知识点,也可以通过查阅资料来习得。相信很多问题,问问ChatGPT就能基本搞清楚。
Q2:设计师、产品经理需要完全搞懂基础篇的知识么?
正如开篇词中我们提到的,在AIGC的时代,工程师、产品、设计师都可以深入学习AI绘画这个工具。我们课程面向的受众包括工程师、产品经理和设计师等,对于设计师和产品同学而言,算法原理部分不必深究、可以有一个大致的了解,更多关注于我们的实战部分,一起做一些有趣的AI绘画效果(比如趣味二维码、AI相册等)。
如果你的工作和AI相关,对于算法原理部分有一个基本的认识,会有助于工作中和其他同事的合作。
思考题答案
第2讲
思考题:如果你想绘制一幅精细化的人物肖像,AI 绘画生成的图像在手部和脸部细节存在瑕疵。这种情况下,有哪些方法可以改善这些问题?
思考题答案:针对这个问题,有多种不同的技巧。
- 更换擅长生成手部、脸部细节的AI绘画模型,比如开源社区的 ChilloutMix、Counterfeit、Dreamlike 都是不错的选择,当然,不差钱的同学可以使用Midjourney。
- 使用负面提示词,指定模型不生成bad hands, low res face等。
- 使用ControlNet等方案对生成的结构做出一定的限制,比如手部的关键点信息、五官信息等。
第3讲
思考题:假设你使用图生图模式生成了一张卡通风格的猫的图片,你调整了重绘强度和prompt,尝试了不同的参数组合,但始终无法获得满意的结果。你观察到生成的图像要么失去了猫的特征,要么与原始图像过于相似。请思考可能的原因,并提出解决方案。
思考题答案:这个问题可能出现的原因是prompt描述不够准确,或者没选择合适的重绘强度。如果prompt没有明确描述所需的卡通风格特征,模型可能无法准确理解你的期望。另外,重绘强度数值太低可能会使生成的图像过于接近原始图像,而太高则会导致图像与原始图像关联度不高。
解决方案是尝试更准确的prompt语句,明确描述所需的卡通风格特征,例如使用描述卡通风格细节的关键词。另外,逐步调整重绘强度数值,观察生成结果的变化。尝试不同的取值范围,找到合适的重绘强度,使生成的图像在保留原始图像特征的同时,与期望的卡通风格更加接近。
这个思考题的目的是鼓励思考问题产生的原因,并寻找解决方案,以进一步优化图生图的结果。
第4讲
思考题:在使用 LoRA 模型生成图像时,如何既保持特定 ID 的角色,同时引入多样化的风格?
思考题答案:如果想平衡保持特定ID的角色的同时,引入多样化的风格,我们可以通过合理选择和组合prompt语句来实现。
首先,为了保持特定ID的角色,可以在prompt中明确指定特定ID的参数,确保生成的图像与该角色一致。例如,在使用ChilloutMixss3.0的人物ID保持能力时,可以在prompt中使用<lora:xss3-0:1>来指定特定ID。
为了引入多样化的风格,我们可以通过在prompt中使用其他的LoRA模型或风格化参数来实现。例如,可以在prompt中使用<lora:blindbox_v1_mix:1>来引入盲盒版本的风格。通过合理选择和组合这些不同的参数,我们可以在保持特定ID的角色的同时,赋予生成的图像不同的风格和特征。
总之,平衡保持特定ID的角色和引入多样化的风格需要灵活运用不同的prompt语句和参数,以达到所需的效果。
第5讲
思考题:在基于扩散模型的 AI 绘画时代到来之前,你还见过哪些有意思的 GAN 的应用?背后的技术原理是怎样的?
思考题答案:这是一个开放性问题,你可以课后多做探索,把你的发现分享出来。举例来说,在2019年的时候,非常流行的性别变换、年龄变换实时视频特效,背后的技术便是CycleGAN + Pix2Pix。具体就是先用CycleGAN技术构造海量成对数据,用Pix2Pix技术得到一个专用的GAN模型。
第6讲
思考题:扩散模型生成速度慢是当前的痛点之一。了解了扩散模型的整体思路,你认为扩散模型的推理可以怎样加速呢?
思考题答案:我提供四个方式,它们都可以用于加速。
- UNet结构:优化用于预测噪声的UNet结构。
- 采样器选择:选择更快速的采样器,以减少采样步数。
- 采用类似Stable Diffusion的方案,将扩散模型的过程作用于下采样之后的潜变量空间,而不是原始图像空间。
- 优化交叉注意力中的计算方案,使用Sparse Attention、Flash Attention这些方案加速计算等。
第7讲
思考题:如何改进Transformer的自注意力机制,提高它的效率,并减少计算资源需求呢?
思考题答案:在改进自注意力机制的过程中,关键是在降低计算资源需求和保持模型性能之间找到平衡。目前已经有一些改进的方法(如局部和稀疏注意力),将自注意力计算变得更高效。
然而,在这方面仍然有较大的改进空间,特别是如何以最小损失对模型性能保持计算效率。比如后面这两个思路。
第一个思路是局部注意力。可以尝试将全局注意力逐步转换为局部注意力,在局部范围内计算上下文关系。这种方法减少了要考虑的上下文范围,从而降低了计算资源需求。但它可能在捕捉长距离依赖关系方面效果稍逊一筹。
第二个就是低秩近似。低秩近似方法将自注意力分解为较低维度的表示,以减少计算并降低资源消耗。这种方法通常在保留关键信息的同时减少了计算复杂度,但也可能影响模型性能。
第8讲
思考题1:扩散模型的生成速度比较慢,因为需要从噪声出发逐步去噪。通过今天的学习,你已经知道每一步去噪的过程都需要用UNet进行噪声预测。结合这一讲的知识,你不妨说说自己对于生成加速的见解。
思考题1答案:最直接的方式就是减少UNet模型的计算量,比如减少UNet特征图的数量、降低网络深度、使用更小的卷积核、使用分组卷积、使用深度可分离卷积等,或者结合模型蒸馏技术对已经训练好的UNet进行压缩。
UNet是全连接结构,我们也可以降低UNet模型的输入输出分辨率,比如Stable Diffusion中引入VAE思想,将去噪过程在低分辨率的潜变量空间操作,相比于在原始图像空间进行操作,也能提升扩散模型的生成速度。
思考题2:关于UNet用于图像分割任务,除了今天我们已经介绍的应用,你还能举出哪些应用场景?
思考题2答案:这是一个开放性问题。举个例子,我们可以使用UNet来做通用抠图,自动提取图片中的主体,然后对图像做背景虚化、背景替换等效果。
第10讲
思考题1:除了今天我们提到的CLIP应用场景,还有哪些实际应用中,可以用到CLIP模型的图像和文本编码能力呢?
思考题1答案:除了我们今天提到的图像分类任务、图像生成任务,还有下一章要学习的unCLIP能力之外,CLIP的图像和文本编码器还可以用于很多场景,这里我列举两个例子供你参考。
第一个例子是图像搜索和标注。CLIP 可以用于图像搜索,通过将用户输入的自然语言查询与图像进行比较,找到与查询描述最匹配的图像。同时,CLIP 还可以生成准确的标签和描述,帮助自动标注图像库。
另一个例子是图像编辑和合成。CLIP 可以用于图像编辑和合成任务。通过将编辑要求以自然语言形式提供给 CLIP,模型可以理解并转换图像的特定属性,如颜色、纹理、风格等,实现图像的风格化、重构或生成。
思考题2:练习题,你可以试着用CLIP,给后面这两张图片分个类。图像你可以点击超链接获取:链接1、链接2。
{kind=link}
思考题2答案:这个问题取决于你的备选类别如何设计,分类的结果应该分别是猫和狗两个类别具有较高的置信度。
第11讲
思考题:VAE和Transformer中的编码器、解码器,在结构、原理、功能上有怎样的不同?
思考题答案:结构上,VAE的编码器和解码器可以使用各种常见的CNN、RNN模型结构。Transformer的编码器和解码器使用的是多头注意力机制+Feed Forward神经网络的结构。
原理上,VAE训练时将损失函数分为两部分:重建损失和 KL 散度。重建损失关注再现输入,而 KL 散度关注潜在空间的分布。VAE 的核心是用潜在变量捕获低维表示,并使用重参数化技巧进行随机梯度下降优化。Transformer的编码器目标是捕获长距离依赖,解码器在生成序列时使用自回归模型,每一步生成新的输出,同时考虑之前的输出。
功能上,VAE适用于生成任务,如生成不同类型的数据(例如图像、文本等)。VAE 学习潜在表示,能够生成与输入数据具有相似特征的新数据。而Transformer更适用于自然语言处理任务,如文本翻译、情感分析、文本生成等。
实际使用中,可以灵活组合 VAE 和 Transformer,例如在课程中的情感评论生成任务中,使用 Transformer 作为 VAE 的编码器和解码器,进一步改进模型的表现。
第12讲
思考题:这一讲是我们的实战课。我们留一个实战任务。在Hugging Face中选择一个你喜欢的基础模型,通过写代码的方式生成一组你喜欢的图片。
思考题答案:这是个开放性题目,你可以在Hugging Face、Civitai上寻找自己喜欢的模型进行创作。这里推荐几个我很喜欢的模型。
- ToonYou,可以生成很好看的美漫风格。
- CounterFeit,可以生成比较精美的漫画形象。
- 人造人模型,可以生成类似证件照风格的照片效果。
好,以上就是这次加餐的全部内容。在之后的课程中,也欢迎你在评论区写下你的学习心得,积极交流能帮你梳理自己的想法,说不定也能启发其他同学。从下一讲开始,我们将会运用前面学到的知识,来解读分析业界主流的AI绘画模型,敬请期待!
- Seeyo 👍(0) 💬(1)
老师话说对于:在使用 LoRA 模型生成图像时,如何既保持特定 ID 的角色,同时引入多样化的风格? 我们可以通过合理选择和组合 prompt 语句来实现。但是webui中lora的调用是通过prompt的设置就可以了,但线上服务部署时,则是将lora的权重融合进底膜中,那如何能在线上部署时,通过prompt的设置实现多个风格的转换呢
2023-08-28 - 昵称C 👍(0) 💬(1)
请问咱们这个课程有自定义文生图+图生图模型的内容吗?上节实践课,实际上还是用的现有模型,并没有自己用专业模型组合出来一个自己的通用模型
2023-08-23 - peter 👍(0) 💬(1)
我准备换笔记本电脑,用新的笔记本电脑来学习、练习专栏中的内容,请问:购买的时候,需要什么样的配置才能满足要求?包括内存、硬盘等。
2023-08-15 - yanyu-xin 👍(0) 💬(1)
这种对课程阶段性的复习总结,有助学习理解。挺好
2023-08-14