16 最近邻检索(下):如何用乘积量化实现“拍照识花”功能?
你好,我是陈东。
随着AI技术的快速发展,以图搜图、拍图识物已经是许多平台上的常见功能了。比如说,在搜索引擎中,我们可以直接上传图片进行反向搜索。在购物平台中,我们可以直接拍照进行商品搜索。包括在一些其他的应用中,我们还能拍照识别植物品种等等。这些功能都依赖于高效的图片检索技术,那它究竟是怎么实现的呢?今天,我们就来聊一聊这个问题。
聚类算法和局部敏感哈希的区别?
检索图片和检索文章一样,我们首先需要用向量空间模型将图片表示出来,也就是将一个图片对象转化为高维空间中的一个点。这样图片检索问题就又变成了我们熟悉的高维空间的相似检索问题。
如果我们把每个图片中的像素点看作一个维度,把像素点的RGB值作为该维度上的值,那一张图片的维度会是百万级别的。这么高的维度,检索起来会非常复杂,我们该怎么处理呢?我们可以像提取文章关键词一样,对图片进行特征提取来压缩维度。
要想实现图片特征提取,我们有很多种深度学习的方法可以选择。比如,使用卷积神经网络(CNN)提取图片特征。这样,用一个512到1024维度的向量空间模型,我们就可以很好地描述图像了,但这依然是一个非常高的维度空间。因此,我们仍然需要使用一些近似最邻近检索技术来加速检索过程。
一种常用的近似最邻近检索方法,是使用局部敏感哈希对高维数据进行降维处理,将高维空间的点划到有限的区域中。这样,通过判断要查询的点所在的区域,我们就能快速取出这个区域的所有候选集了。
不过,在上一讲中我们也提到,局部敏感哈希由于哈希函数构造相对比较简单,往往更适合计算字面上的相似性(表面特征的相似性),而不是语义上的相似性(本质上的相似性)。这怎么理解呢?举个例子,即便是面对同一种花,不同的人在不同的地点拍出来的照片,在角度、背景、花的形状上也会有比较大的差异。也就是说,这两张图片的表面特征其实差异很大,这让我们没办法利用局部敏感哈希,来合理评估它们的相似度。
而且,局部敏感哈希其实是一种粒度很粗的非精准检索方案。以SimHash为例,它能将上百万的高维空间压缩到64位的比特位中,这自然也会损失不少的精确性。

因此,更常见的一种方案,是使用聚类算法来划分空间。和简单的局部敏感哈希算法相比,聚类算法能将空间中的点更灵活地划分成多个类,并且保留了向量的高维度,使得我们可以更准确地计算向量间的距离。好的聚类算法要保证类内的点足够接近,不同类之间的距离足够大。一种常见的聚类算法是K-means算法(K-平均算法)。

K-means聚类算法的思想其实很“朴素”,它将所有的点划分为k个类,每个类都有一个类中心向量。在构建聚类的时候,我们希望每个类内的点都是紧密靠近类中心的。用严谨的数学语言来说,K-means聚类算法的优化目标是,类内的点到类中心的距离均值总和最短。因此,K-means聚类算法具体的计算步骤如下:
- 随机选择k个节点,作为初始的k个聚类的中心;
- 针对所有的节点,计算它们和k个聚类中心的距离,将节点归入离它最近的类中;
- 针对k个类,统计每个类内节点的向量均值,作为每个类的新的中心向量;
- 重复第2步和第3步,重新计算每个节点和新的类中心的距离,将节点再次划分到最近的类中,然后再更新类的中心节点向量。经过多次迭代,直到节点分类不再变化,或者迭代次数达到上限,我们停止算法。

以上,就是K-means聚类算法的计算过程了,那使用聚类算法代替了局部敏感哈希以后,我们该怎么进行相似检索呢?
如何使用聚类算法进行相似检索?
首先,对于所有的数据,我们先用聚类算法将它们划分到不同的类中。在具体操作之前,我们会给聚类的个数设定一个目标。假设聚类的个数是1024个,那所有的点就会被分到这1024个类中。这样,我们就可以用每个聚类的ID作为Key,来建立倒排索引了。
建立好索引之后,当要查询一个点邻近的点时,我们直接计算该点和所有聚类中心的距离,将离查询点最近的聚类作为该点所属的聚类。因此,以该聚类的ID为Key去倒排索引中查询,我们就可以取出所有该聚类中的节点列表了。然后,我们遍历整个节点列表,计算每个点和查询点的距离,取出Top K个结果进行返回。
这个过程中会有两种常见情况出现。第一种,最近的聚类中的节点数非常多。这个时候,我们就计算该聚类中的所有节点和查询点的距离,这个代价会很大。这该怎么优化呢?这时,我们可以参考二分查找算法不断划分子空间划分的思路,使用层次聚类将一个聚类中的节点,再次划分成多个聚类。这样,在该聚类中查找相近的点时,我们通过继续判断查询点和哪个子聚类更相近,就能快速减少检索空间,从而提升检索效率了。

第二种,该聚类中的候选集不足Top K个,或者我们担心聚类算法的相似判断不够精准,导致最近的聚类中的结果不够好。那我们还可以再去查询次邻近的聚类,将这些聚类中的候选集取出,计算每个点和查询点的距离,补全最近的Top K个点。
如何使用乘积量化压缩向量?
对于向量的相似检索,除了检索算法本身以外,如何优化存储空间也是我们必须要关注的一个技术问题。以1024维的向量为例,因为每个向量维度值是一个浮点数(浮点数就是小数,一个浮点数有4个字节),所以一个向量就有4K个字节。如果是上亿级别的数据,光是存储向量就需要几百G的内存,这会导致向量检索难以在内存中完成检索。
因此,为了能更好地将向量加载到内存中,我们需要压缩向量的表示。比如说,我们可以用聚类中心的向量代替聚类中的每个向量。这样,一个类内的点都可以用这个类的ID来代替和存储,我们也就节省了存储每个向量的空间开销。那计算查询向量和原始样本向量距离的过程,也就可以改为计算查询向量和对应聚类中心向量的距离了。

想要压缩向量,我们往往会使用向量量化(Vector Quantization)技术。其中,我们最常用的是乘积量化(Product Quantization)技术。
乍一看,你会觉得乘积量化是个非常晦涩难懂的概念,但它其实并没有那么复杂。接下来,我就把它拆分成乘积和量化这两个概念,来为你详细解释一下。
量化指的就是将一个空间划分为多个区域,然后为每个区域编码标识。比如说,一个二维空间<x,y>可以被划为两块,那我们只需要1个比特位就能分别为这两个区域编码了,它们的空间编码分别是0和1。那对二维空间中的任意一个点来说,它要么属于区域0,要么属于区域1。
这样,我们就可以用1个比特位的0或1编码,来代替任意一个点的二维空间坐标<x,y>了 。假设x和y是两个浮点数,各4个字节,那它们一共是8个字节。如果我们将8个字节的坐标用1个比特位来表示,就能达到压缩存储空间的目的了。前面我们说的用聚类ID代替具体的向量来进行压缩,也是同样的原理。
而乘积指的是高维空间可以看作是由多个低维空间相乘得到的。我们还是以二维空间<x,y>为例,它就是由两个一维空间和相乘得到。类似的还有,三维空间<x,y,z>是由一个二维空间<x,y>和一个一维空间相乘得到,依此类推。
那将高维空间分解成多个低维空间的乘积有什么好处呢?它能降低数据的存储量。比如说,二维空间是由一维的x轴和y轴相乘得到。x轴上有4个点x1到x4,y轴上有4个点y1到y4,这四个点的交叉乘积,会在二维空间形成16个点。但是,如果我们仅存储一维空间中,x轴和y轴的各4个点,一共只需要存储8个一维的点,这会比存储16个二维的点更节省空间。
总结来说,对向量进行乘积量化,其实就是将向量的高维空间看成是多个子空间的乘积,然后针对每个子空间,再用聚类技术分成多个区域。最后,给每个区域生成一个唯一编码,也就是聚类ID。
好了,乘积量化压缩向量的原理我们已经知道了。接下来,我们就通过一个例子来说说,乘积量化压缩样本向量的具体操作过程。
如果我们的样本向量都是1024维的浮点数向量,那我们可以将它分为4段,这样每一段就都是一个256维的浮点向量。然后,在每一段的256维的空间里,我们用聚类算法将这256维空间再划分为256个聚类。接着,我们可以用1至256作为ID,来为这256个聚类中心编号。这样,我们就得到了256 * 4 共1024个聚类中心,每个聚类中心都是一个256维的浮点数向量(256 * 4字节 = 1024字节)。最后,我们将这1024个聚类中心向量都存储下来。

这样,对于这个空间中的每个向量,我们就不需要再精确记录它在每一维上的权重了。我们只需要将每个向量都分为四段,让每段子向量都根据聚类算法找到所属的聚类,然后用它所属聚类的ID来表示这段子向量就可以了。
因为聚类ID是从1到256的,所以我们只需要8个比特位就可以表示这个聚类ID了。由于完整的样本向量有四段,因此我们用4个聚类ID就可以表示一个完整的样本向量了,也就一共只需要32个比特位。因此,一个1024维的原始浮点数向量(共1024 * 4 字节)使用乘积量化压缩后,存储空间变为了32个比特位,空间使用只有原来的1/1024。存储空间被大幅降低之后,所有的样本向量就有可能都被加载到内存中了。

如何计算查询向量和压缩样本向量的距离(相似性)?
这样,我们就得到了一个压缩后的样本向量,它是一个32个比特位的向量。这个时候,如果要我们查询一个新向量和样本向量之间的距离,也就是它们之间的相似性,我们该怎么做呢?这里我要强调一下,一般来说,要查询的新向量都是一个未被压缩过的向量。也就是说在我们的例子中,它是一个1024维的浮点向量。
好了,明确了这一点之后,我们接着来说一下计算过程。这整个计算过程会涉及3个主要向量,分别是样本向量、查询向量以及聚类中心向量。你在理解这个过程的时候,要注意分清楚它们。
那接下来,我们一起来看一下具体的计算过程。
首先,我们在对所有样本点生成聚类时,需要记录下聚类中心向量的向量值,作为后面计算距离的依据。由于1024维向量会分成4段,每段有256个聚类。因此,我们共需要存储1024个聚类中所有中心向量的数据。
然后,对于查询向量,我们也将它分为4段,每段也是一个256维的向量。对于查询向量的每一段子向量,我们要分别计算它和之前存储的对应的256个聚类中心向量的距离,并用一张距离表存下来。由于有4段,因此一共有4个距离表。

当计算查询向量和样本向量的距离时,我们将查询向量和样本向量都分为4段子空间。然后分别计算出每段子空间中,查询子向量和样本子向量的距离。这时,我们可以用聚类中心向量代替样本子向量。这样,求查询子向量和样本子向量的距离,就转换为求查询子向量和对应的聚类中心向量的距离。那我们只需要将样本子向量的聚类ID作为key去查距离表,就能在O(1)的时间代价内知道这个距离了。

最后,我们将得到的四段距离按欧氏距离的方式计算,合并起来,即可得到查询向量和样本向量的距离,距离计算公式:
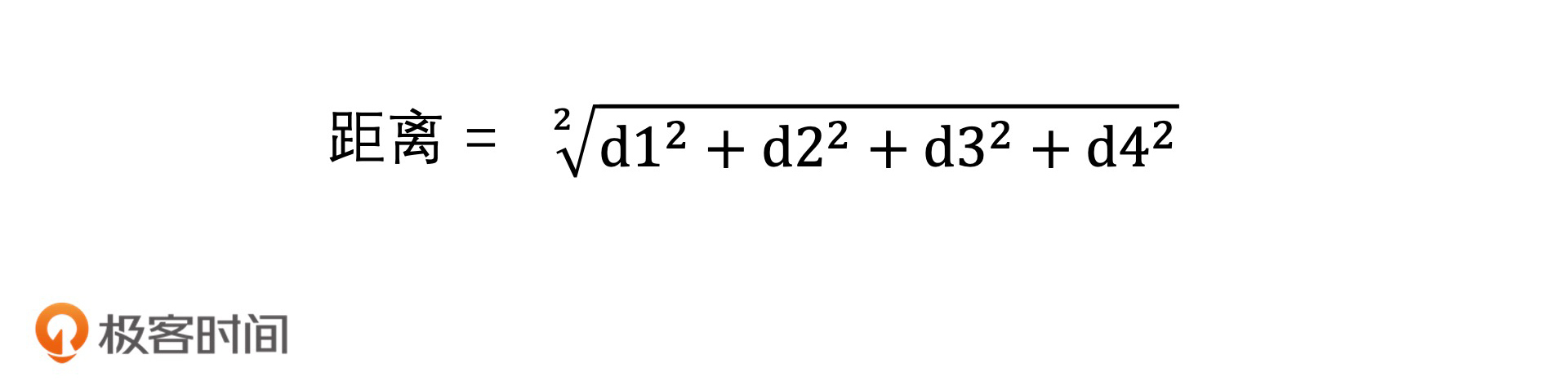
以上,就是计算查询向量和样本向量之间距离的过程了。你会看到,原本两个高维向量的复杂的距离计算,被4次O(1)时间代价的查表操作代替之后,就变成了常数级的时间代价。因此,在对压缩后的样本向量进行相似查找的时候,我们即便是使用遍历的方式进行计算,时间代价也会减少许多。
而计算查询向量到每个聚类中心的距离,我们也只需要在查询开始的时候计算一次,就可以生成1024个距离表,在后面对比每个样本向量时,这个对比表就可以反复使用了。
如何对乘积量化进行倒排索引?
尽管使用乘积量化的方案,我们已经可以用很低的代价来遍历所有的样本向量,计算每个样本向量和查询向量的距离了。但是我们依然希望能用更高效的检索技术代替遍历,来提高检索效率。因此,结合前面的知识,我们可以将聚类、乘积量化和倒排索引综合使用,让整体检索更高效。下面,我就来具体说说,在建立索引和查询这两个过程中,它们是怎么综合使用的。
首先,我们来说建立索引的过程,我把它总结为3步。
- 使用K-means聚类,将所有的样本向量分为1024个聚类,以聚类ID为Key建立倒排索引。
- 对于每个聚类中的样本向量,计算它们和聚类中心的差值,得到新的向量。你也可以认为这是以聚类中心作为原点重新建立向量空间,然后更新该聚类中的每个样本向量。
- 使用乘积量化的方式,压缩存储每个聚类中新的样本向量。

建好索引之后,我们再来说说查询的过程,它也可以总结为3步。
- 当查询向量到来时,先计算它离哪个聚类中心最近,然后查找倒排表,取出该聚类中所有的向量。
- 计算查询向量和聚类中心的差值,得到新的查询向量。
- 对新的查询向量,使用乘积量化的距离计算法,来遍历该聚类中的所有压缩样本向量,取出最近的k个结果返回。

这样,我们就同时结合了聚类、乘积量化和倒排索引的检索技术,使得我们能在压缩向量节省存储空间的同时,也通过快速减少检索空间的方式,提高了检索效率。通过这样的组合技术,我们能解决大量的图片检索问题。比如说,以图搜图、拍照识物,人脸识别等等。
实际上,除了图像检索领域,在文章推荐、商品推荐等推荐领域中,我们也都可以用类似的检索技术,来快速返回大量的结果。尤其是随着AI技术的发展,越来越多的对象需要用特征向量来表示。所以,针对这些对象的检索问题,其实都会转换为高维空间的近似检索问题,那我们今天讲的内容就完全可以派上用场了。
重点回顾
今天,我们学习了在高维向量空间中实现近似最邻近检索的方法。相对于局部敏感哈希,使用聚类技术能实现更灵活的分类能力,并且聚类技术还支持层次聚类,它能更快速地划分检索空间。
此外,对于高维的向量检索,如何优化存储空间也是我们需要考虑的一个问题。这个时候,可以使用乘积量化的方法来压缩样本向量,让我们能在内存中运行向量检索的算法。
那为了进一步提高检索率和优化存储空间,我们还能将聚类技术、乘积量化和倒排索引技术结合使用。这也是目前图像检索和文章推荐等领域中,非常重要的设计思想和实现方案。

课堂讨论
1.为什么使用聚类中心向量来代替聚类中的样本向量,我们就可以达到节省存储空间的目的?
2.如果二维空间中有16个点,它们是由x轴的1、2、3、4四个点,以及y轴的1、2、3、4四个点两两相乘组合成的。那么,对于二维空间中的这16个样本点,如果使用乘积量化的思路,你会怎么进行压缩存储?当我们新增了一个点(17,17)时,它的查询过程又是怎么样的?
欢迎在留言区畅所欲言,说出你的思考过程和最终答案。如果有收获,也欢迎把这一讲分享给你的朋友。
- wcf 👍(9) 💬(1)
对于乘积法省空间的说法有点疑问.老师在文章里的说法确实能看出节省了空间,但是这里面临的问题是:给定16个二维空间的点,使用(x,y)的存储方法,会比分别存储x和y的方法更省空间吗?假如这16个点的x值分布在16个值上,y值也分布在16个值上,那两种方法都需要32个浮点数表示啊?怎么就能省空间呢?
2020-05-03 - 每天晒白牙 👍(5) 💬(1)
老师讲的是真好,只是学生我底子差,越到后面的文章越看不太懂了,很吃力 也许这就是因为门槛高了,才使得做算法和 AI 的同学工资高 想想从小学开始一直到大学(甚至有些读到了研究生和博士),也都是从简单开始学起,最开始的 1+1=2,看不出学生有多大差别,但后面四则混合运算,再到各种三角函数,大学的微积分等等吧 越到后面学习门槛越高,大家的差距也逐渐拉开
2020-05-01 - 范闲 👍(4) 💬(6)
今天上午刚刚看了乘积量化的论文。乘积量化实际上是建立在一个D维向量由M个子向量组成的假设上。子向量的维度就是K=D/M. 而M代表着码本的数量,码本实际上就是对子向量进行kmeans运算得到的聚类中心。另外在乘积量化过程中,还有个PQcode,实际上存储的子向量属于哪一个码本。 在向量搜索过程中,向量直接和码本运算得到距离表,然后再同PQcode求和就能得到距离了。 但是如果你的向量的数据集的数目N是亿级别的,就会导致你的向量搜索的速度下降。 而倒排向量实际是为了解决这个问题而产生的。先对N个向量聚类,产生1024(这部分可以改变的)个中心,然后会得到N个向量和聚类中心的残差,再对残差进行乘积量化的步骤即可。
2020-05-01 - piboye 👍(1) 💬(1)
好难啊
2020-09-23 - 那时刻 👍(1) 💬(1)
非常感谢老师这一节内容,收获不少。对于高维度的向量进行乘积量化,颇类似于数据库里对于数据分表操作,分散存储和提高查询速度。 尝试回答一下讨论问题 1. 使用聚类中心向量来代替聚类中的样本向量,其一,这样不需要存储每个聚类里样本向量,只需要存储他们和中心向量的差值,乘积量化后减少存储,其二,查询时候,只需要比较这个中心向量,减少比较次数,提高查询效率。 2.二维空间的点,可以按照x,y轴两个维度分别进行聚类,然后乘积量化来压缩存储。查询过程可以按照老师文章讲述的过程来查询。
2020-05-01 - 易企秀-郭彦超 👍(0) 💬(1)
老师 倒排乘机量化中,使用k-means将样本向量分为1024个聚类 ,这里的样本向量指的是图片向量吗,意思是将高维图片向量压缩为1024维图片向量吗,还是每张图片被划分到1024个聚类中的某一个
2021-01-27 - 范闲 👍(0) 💬(1)
CheckSum的值还需要多个节点同步一下,来确认节点内的数据最终是一致的对吧。
2020-06-05 - 范闲 👍(0) 💬(1)
最近遇到一个问题想请教下老师。 情况是这样的 我有一个在线召回模块和离线数据模块。 利用词向量生成句向量,然后利用Annoy搜索。 主线程负责在线召回的搜索,副线程负责监控有没有新的词向量模型和索引模型。 离线数据模块主要是从数据库和接口拉取用户问句,训练词向量模型,生成句向量和构建索引。当向量模型和索引构建完毕后,利用scp分别拷贝到多台在线召回的机器上,来完成数据同步。 1.当请求量上去以后,在线召回词向量模型的查性能不行而且随着数据量增大,词向量的内存占用也越来越大。 2.利用scp拷贝到多机的时候,没法确认是不是真的拷贝过去了,真的数据同步了,然后这就会导致不同在线模块的结果可能不一致。 针对问题1的话,我想在离线数据生成词向量的时候。直接写入redis集群,在线召回去redis读取即可。 针对问题2的话,目前没有考虑到太好的办法,只能还是按照scp的方式把索引文件同步过去。 关于问题2您有什么好的想法么?
2020-06-04 - 鲁滨逊 👍(0) 💬(1)
老师,对于向量搜索我有两个实际问题。1.对于特征向量携带多个属性的情境下,属性过滤该怎么做呢?比如我们现在在给公安做的交通路口,人脸卡扣抓拍搜索,时间范围和地点这两个基本属性是一定会进行过滤的。我的考虑是,如果放在距离计算之前进行过滤,确实能减少搜索范围,但向量存储一定依照一定的组织方式,这种组织方式该怎样设计,或者其他数据库能解决?如果全量搜索完之后再做过滤,那可能得不到topk个结果,极端情形甚至一个都没有(都被过滤掉了)2.对于数据量不断增多,一段时间后倒排索引是不是得重新建立,聚类中心数量还如何选择呢?麻烦老师解惑。
2020-06-04 - 峰 👍(0) 💬(1)
问题1, 假设只有一个子空间就是本身,这就当于用聚类中心ID表示原始的数据点,当然还需要记录下聚类中心的原始特征向量,而多个就是扩展的问题,对每个子空间都采用这种方式对数据进行编码,但是如何选择有效的子空间无疑是这个算法的问题所在。 问题2,我理解17,17 是一个异常点,作为一个聚类中心,单独考虑记录好了。 额看了下评论,原来理解错了意思。。。。。 这节课真的是厉害了,思想其实都明白,串在一起还真是得好好看看看看看看。。。。。。
2020-05-10 - paulhaoyi 👍(0) 💬(1)
那么分组切分的数目有什么通用规则么?就是为什么1024通常分四组,每组256聚类,如果我多分,多聚类,或者少,会有那些影响?感觉应该是一个效果和成本的权衡?
2020-05-06 - paulhaoyi 👍(0) 💬(1)
关于向量乘积的例子,请教下老师,两个纬度各四个分区,共8个中心。如果我把2纬空间就分成8个聚类中心(不用16个),保持总分类数一样。也就是占用存储空间一样,那么两种方式的精度损失应该是不一样的吧?这个损失差别怎么理解?感觉不管怎么分,都是把整个空间或者说样本分成了8组或16组?那么直接二维分8组,为什么比两个一纬各分4组的效果差?这个地方感觉没理解清楚。
2020-05-06 - 奕 👍(0) 💬(1)
我们就可以用 1 个比特位的 0 或 1 编码,来代替任意一个点的二维空间坐标 <x,y> 了 。假设 x 和 y 是两个浮点数,各 4 个字节,那它们一共是 8 个字节。如果我们将 8 个字节的坐标用 1 个比特位来表示 ------------------------------ 像文章说的二维空间量化,一个具体的坐标<x,y> 转换为一个 0 和 1,只知道大致的方向了,这样的话信息不是丢的很严重,这样的量化有意义吗?
2020-05-05 - 奕 👍(0) 💬(1)
K-means 算法的第三步: 计算每个类内节点的向量均值,作为每个类的新的中心向量。 有个问题是:如果计算出来的新的中心向量的值 不在 所有的节点中会怎么进行处理的? 还有这一步要不要判断 新的中心向量的值 在不在所有的节点中?
2020-05-05 - 那时刻 👍(0) 💬(1)
请问在聚类算法进行相似检索中,对于聚类中的候选集不足 Top K 个,我们还可以再去查询次邻近的聚类,这个临近聚类怎么来寻找呢?是重新计算当前聚类中心点和其它中心点距离么?还是需要额外存储聚类中心点之间的距离?
2020-05-01