08 索引构建:搜索引擎如何为万亿级别网站生成索引?
你好,我是陈东。
对基于内容或者属性的检索场景,我们可以使用倒排索引完成高效的检索。但是,在一些超大规模的数据应用场景中,比如搜索引擎,它会对万亿级别的网站进行索引,生成的倒排索引会非常庞大,根本无法存储在内存中。这种情况下,我们能否像B+树或者LSM树那样,将数据存入磁盘呢?今天,我们就来聊一聊这个问题。
如何生成大于内存容量的倒排索引?
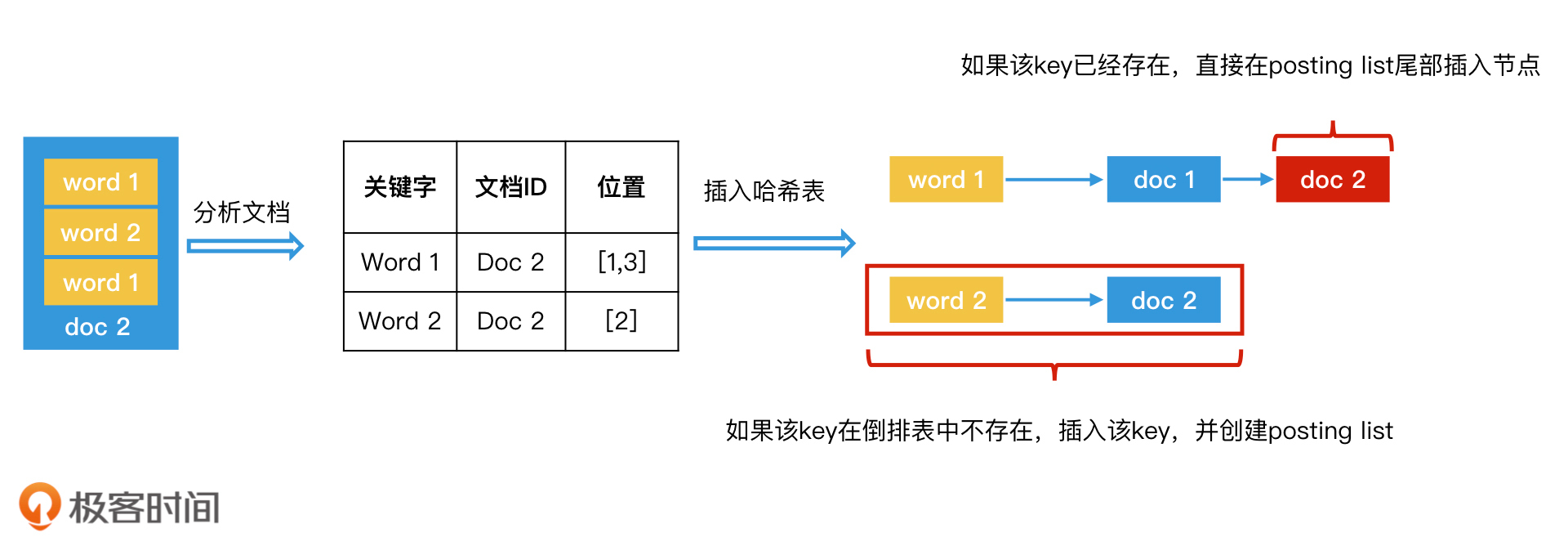
我们先来回顾一下,对于能够在内存中处理的小规模的文档集合,我们是如何生成基于哈希表的倒排索引的。步骤如下:
- 给每个文档编号,作为它们的唯一标识,并且排好序;
- 顺序扫描每一个文档,将当前扫描的文档中的所有内容生成<关键字,文档ID,关键字位置>数据对,并将所有的<关键字,文档ID,关键字位置>这样的数据对,都以关键字为key存入倒排表(位置信息如果不需要可以省略);
- 重复第2步,直到处理完所有文档。这样就生成一个基于内存的倒排索引。
内存中生成倒排索引
对于大规模的文档集合,如果我们能将它分割成多个小规模文档集合,是不是就可以在内存中建立倒排索引了呢?这些存储在内存中的小规模文档的倒排索引,最终又是怎样变成一个完整的大规模的倒排索引存储在磁盘中的呢?这两个问题,你可以先思考一下,然后我们一起来看工业界是怎么做的。
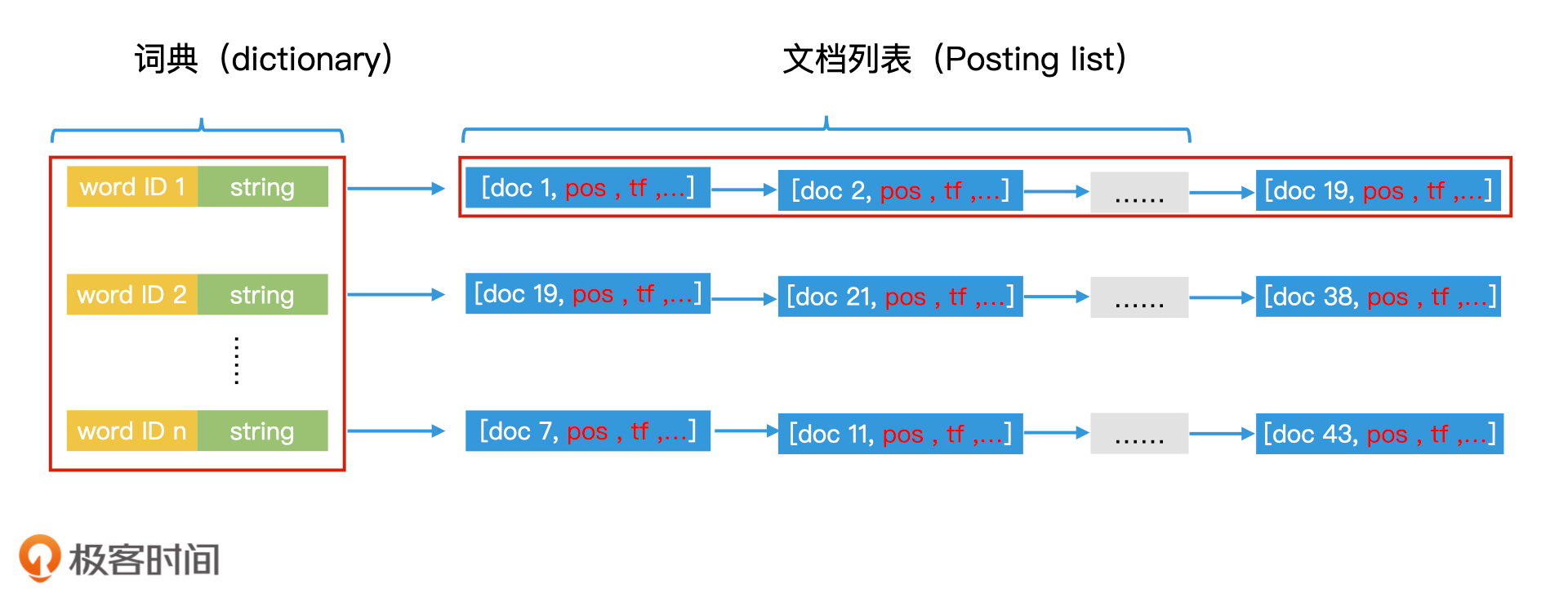
首先,搜索引擎这种工业级的倒排索引表的实现,会比我们之前学习过的更复杂一些。比如说,如果文档中出现了“极客时间”四个字,那除了这四个字本身可能被作为关键词加入词典以外,“极客”和“时间”还有“极客时间”这三个词也可能会被加入词典。因此,完整的词典中词的数量会非常大,可能会达到几百万甚至是几千万的级别。并且,每个词因为长度不一样,所占据的存储空间也会不同。
所以,为了方便后续的处理,我们不仅会为词典中的每个词编号,还会把每个词对应的字符串存储在词典中。此外,在posting list中,除了记录文档ID,我们还会记录该词在该文档中出现的每个位置、出现次数等信息。因此,posting list中的每一个节点都是一个复杂的结构体,每个结构体以文档ID为唯一标识。完整的倒排索引表结构如下图所示:
倒排索引(哈希表实现)
那么,我们怎样才能生成这样一个工业级的倒排索引呢?
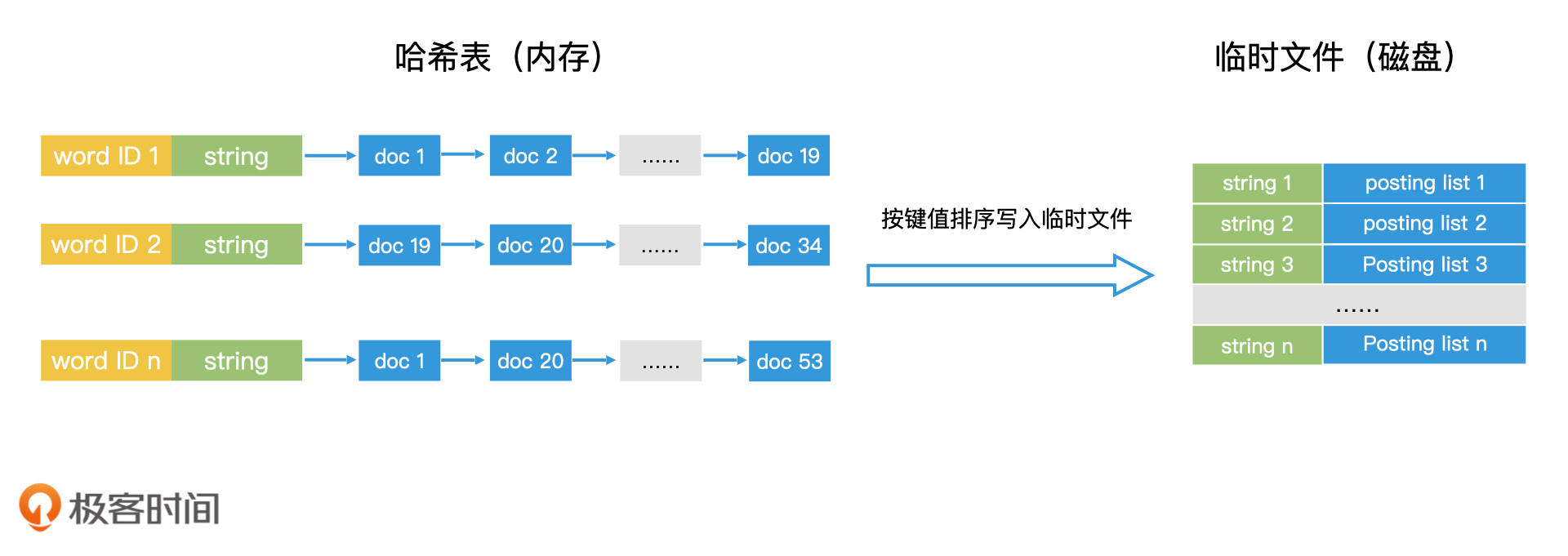
首先,我们可以将大规模文档均匀划分为多个小的文档集合,并按照之前的方法,为每个小的文档集合在内存中生成倒排索引。
接下来,我们需要将内存中的倒排索引存入磁盘,生成一个临时倒排文件。我们先将内存中的文档列表按照关键词的字符串大小进行排序,然后从小到大,将关键词以及对应的文档列表作为一条记录写入临时倒排文件。这样一来,临时文件中的每条记录就都是有序的了。
而且,在临时文件中,我们并不需要存储关键词的编号。原因在于每个临时文件的编号都是局部的,并不是全局唯一的,不能作为最终的唯一编号,所以无需保存。
生成磁盘中的临时文件
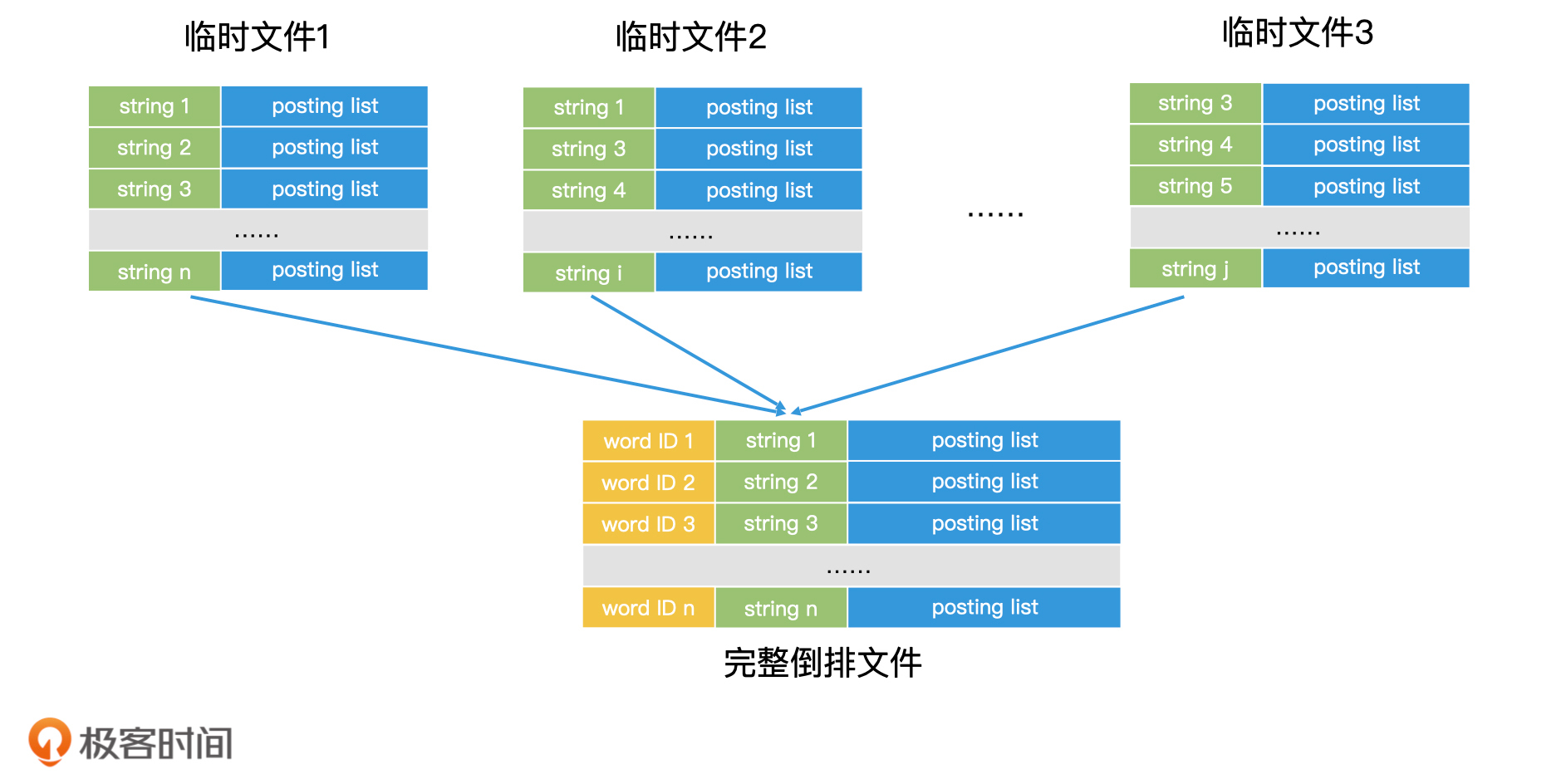
我们依次处理每一批小规模的文档集合,为每一批小规模文档集合生成一份对应的临时文件。等文档全部处理完以后,我们就得到了磁盘上的多个临时文件。
那磁盘上的多个临时文件该如何合并呢?这又要用到我们熟悉的多路归并技术了。每个临时文件里的每一条记录都是根据关键词有序排列的,因此我们在做多路归并的时候,需要先将所有临时文件当前记录的关键词取出。如果关键词相同的,我们就可以将对应的posting list读出,并且合并了。
如果posting list可以完全读入内存,那我们就可以直接在内存中完成合并,然后把合并结果作为一条完整的记录写入最终的倒排文件中;如果posting list过大无法装入内存,但posting list里面的元素本身又是有序的,我们也可以将posting list从前往后分段读入内存进行处理,直到处理完所有分段。这样我们就完成了一条完整记录的归并。
每完成一条完整记录的归并,我们就可以为这一条记录的关键词赋上一个编号,这样每个关键词就有了全局唯一的编号。重复这个过程,直到多个临时文件归并结束,这样我们就可以得到最终完整的倒排文件。
多个临时文件归并生成完整的倒排文件
这种将大任务分解为多个小任务,最终根据key来归并的思路,其实和分布式计算Map Reduce的思路是十分相似的。因此,这种将大规模文档拆分成多个小规模文档集合,再生成倒排文件的方案,可以非常方便地迁移到Map Reduce的框架上,在多台机器上同时运行,大幅度提升倒排文件的生成效率。那如果你想了解更多的内容,你可以看看Google在2004年发表的经典的map reduce论文,论文里面就说了使用map reduce来构建倒排索引是当时最成功的一个应用。
如何使用磁盘上的倒排文件进行检索?
那对于这样一个大规模的倒排文件,我们在检索的时候是怎么使用的呢?其实,使用的时候有一条核心原则,那就是内存的检索效率比磁盘高许多,因此,能加载到内存中的数据,我们要尽可能加载到内存中。
我们知道,一个倒排索引由两部分构成,一部分是key集合的词典,另一部分是key对应的文档列表。在许多应用中,词典这一部分数据量不会很大,可以在内存中加载。因此,我们完全可以将倒排文件中的所有key读出,在内存中使用哈希表建立词典。
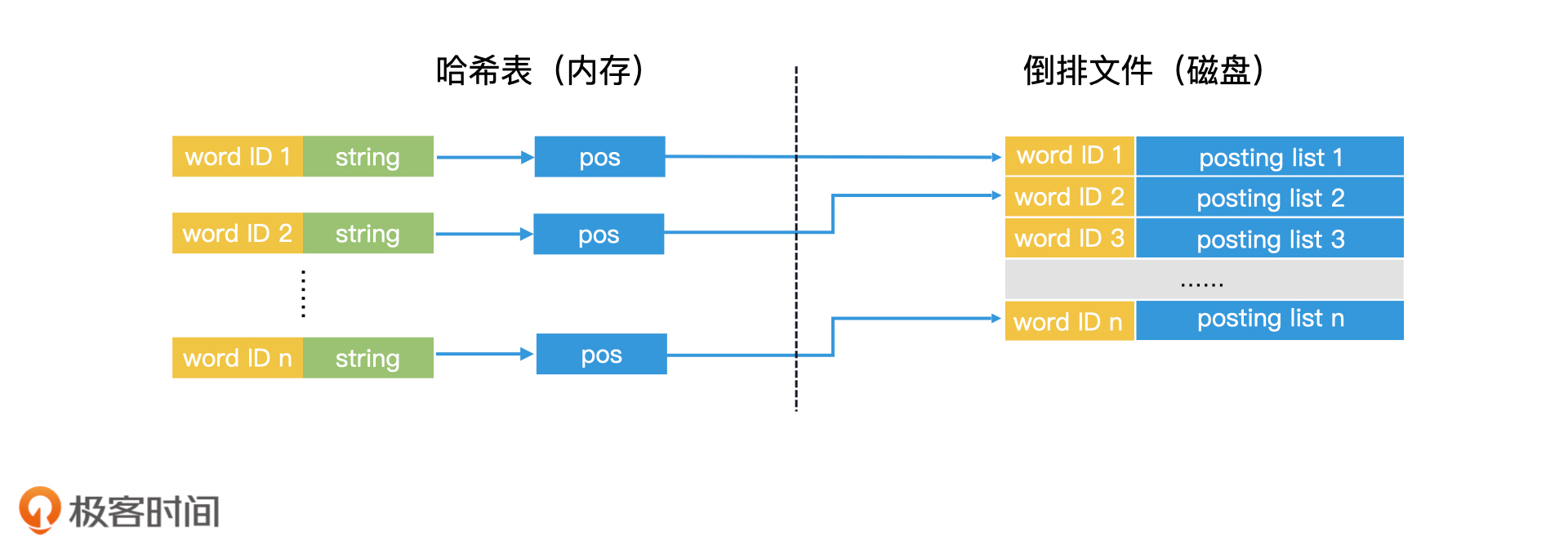
词典加载在内存中,文档列表存在磁盘
那么,当有查询发生时,通过检索内存中的哈希表,我们就能找到对应的key,然后将磁盘中key对应的postling list读到内存中进行处理了。
说到这里,你可能会有疑问,如果词典本身也很大,只能存储在磁盘,无法加载到内存中该怎么办呢?其实,你可以试着将词典看作一个有序的key的序列,那这个场景是不是就变得很熟悉了?是的,我们完全可以用B+树来完成词典的检索。
这样一来,我们就可以把检索过程总结成两个步骤。第一步,我们使用B+树或类似的技术,查询到对应的词典中的关键字。第二步,我们将这个关键字对应的posting list读出,在内存中进行处理。
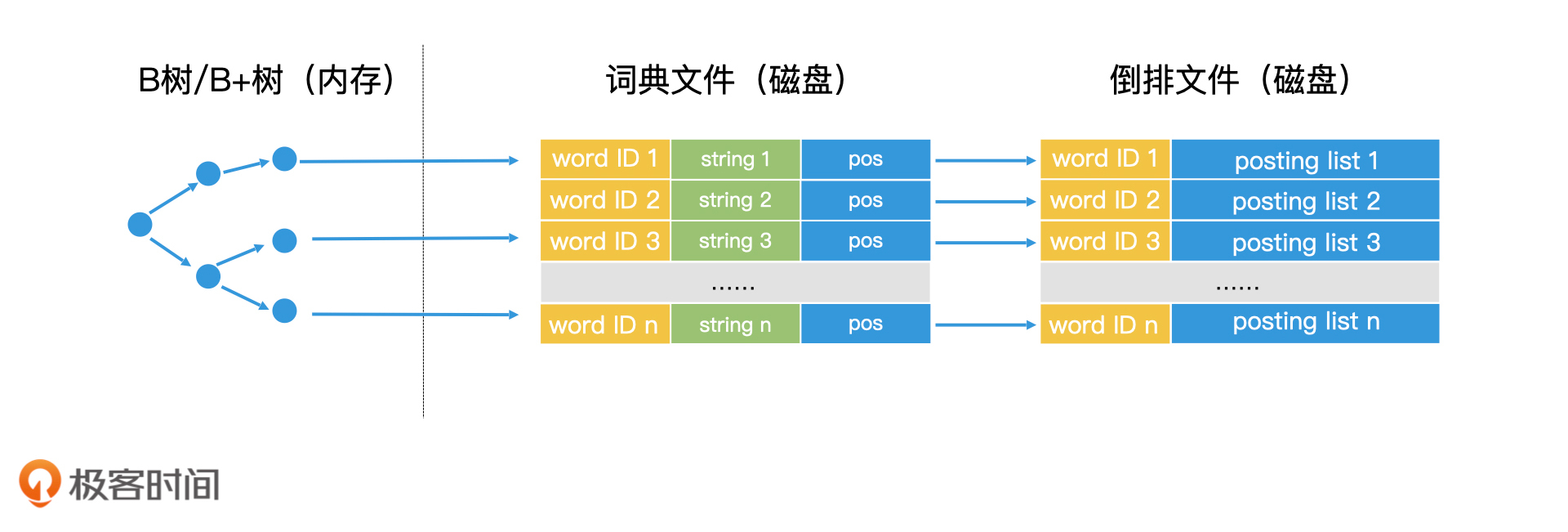
词典文件+倒排文件
到这里,检索过程我们就说完了。不过,还有一种情况你需要考虑,那就是如果posting list非常长,它是很有可能无法加载到内存中进行处理的。比如说,在搜索引擎中,一些热门的关键词可能会出现在上亿个页面中,这些热门关键词对应的posting list就会非常大。那这样的情况下,我们该怎么办呢?
其实,这个问题在本质上和词典无法加载到内存中是一样的。而且,posting list中的数据也是有序的。因此,我们完全可以对长度过大的posting list也进行类似B+树的索引,只读取有用的数据块到内存中,从而降低磁盘访问次数。包括在Lucene中,也是使用类似的思想,用分层跳表来实现posting list,从而能将posting list分层加载到内存中。而对于长度不大的posting list,我们仍然可以直接加载到内存中。
此外,如果内存空间足够大,我们还能使用缓存技术,比如LRU缓存,它会将频繁使用的posting list长期保存在内存中。这样一来,当需要频繁使用该posting list的时候,我们可以直接从内存中获取,而不需要重复读取磁盘,也就减少了磁盘IO,从而提升了系统的检索效率。
总之,对于大规模倒排索引文件的使用,本质上还是我们之前学过的检索技术之间的组合应用。因为倒排文件分为词典和文档列表两部分,所以,检索过程其实就是分别对词典和文档列表的访问过程。因此,只要你知道如何对磁盘上的词典和文档列表进行索引和检索,你就能很好地掌握大规模倒排文件的检索过程。
重点回顾
今天,我们学习了使用多文件归并的方式对万亿级别的网页生成倒排索引,还学习了针对这样大规模倒排索引文件的检索,可以通过查询词典和查询文档列表这两个阶段来实现。
除此之外,我们接触了两个很基础但也很重要的设计思想。
一个是尽可能地将数据加载到内存中,因为内存的检索效率大大高于磁盘。那为了将数据更多地加载到内存中,索引压缩是一个重要的研究方向,目前有很多成熟的技术可以实现对词典和对文档列表的压缩。比如说在Lucene中,就使用了类似于前缀树的技术FST,来对词典进行前后缀的压缩,使得词典可以加载到内存中。
另一个是将大数据集合拆成多个小数据集合来处理。这其实就是分布式系统的核心思想。在大规模系统中,使用分布式技术进行加速是很重要的一个方向。不过,今天我们只是学习了利用分布式的思想来构建索引,在后面的课程中,我们还会进一步地学习,如何利用分布式技术优化检索效率。
课堂讨论
词典如果能加载在内存中,就会大幅提升检索效率。在哈希表过大无法存入内存的情况下,我们是否还有可能使用其他占用内存空间更小的数据结构,来将词典完全加载在内存中?有序数组和二叉树是否可行?为什么?
欢迎在留言区畅所欲言,说出你的思考过程和最终答案。如果有收获,也欢迎把这篇文章分享给你的朋友。
- 无形 👍(14) 💬(1)
评论里提到用数组来存储字典,不太清楚这个字典的key和value是什么,这个涉及怎么存储,如果是ID到key,我想到用连续空间来存储,按这种结构id|length|value,先对ID排好序,length是key的长度,value是key的值,这样存储紧凑,没有浪费空间,这样查找key就可以根据ID找key,不匹配可以跳过length的长度,提高效率,如果对这片连续空间创建索引,用数组实现,数组里存储的是ID|偏移量,偏移量是相对连续空间地址的距离,可以实现二分查找;如果是key到ID的映射,类似上面的结构,按照length、key字典序排序好……有点复杂还没完全想好
2020-04-13 - 峰 👍(11) 💬(2)
存储效率优化想象中就两条路,第一是压缩,像老师说到的fst,对关键字集合的压缩。第二就是除了要存的数据,尽量别存些有的没的,比如我就用连续内存空间存词典中的每一项,是不是最省空间的,是但是变长怎么找,那再加个数组存词典中每一项的地址( 当然注意有序,当然稀疏索引也不是不能接受)。那你更新代价很高呀,那就把上述两个结构分成块存。这查找效率又不行了,那我多加几层索引,树就来啦,得出结论tradeoff真可怕。。。。
2020-04-13 - aoe 👍(5) 💬(3)
今天才知道“前缀树”是一种压缩算法,原来只知道有这样一个数据结构……有兴趣小伙伴可以自己实现一下https://leetcode-cn.com/problems/implement-trie-prefix-tree/ 占用内存空间更小的数据结构:可以采用类似“布隆过滤器”的设计,创建一个bit型的数组,1GB内存大约可以存放85亿的key。 实现思路: 1. 创建一个bit数组 2. 需要搜索的关键字通过Hash算法映射到数组的索引位置 2.1. 索引位置 已使用值 = 1,未使用值 = 0 (缺点:根据“鸽巢原理”未能解决Hash冲突) 2.2. Hash算法简单实现(使用余数定理):(搜索关键字 转 数字)% 数组长度(约85亿) 1GB存85亿的key计算推导: bit: 计算机中的最小存储单元 1byte包含8bits 1KB=1024Byte KB是千字节 1MB=1024KB MB是兆 1GB=1024MB GB是千兆 1TB=1024GB TB是千千兆 1GB = 1024MB = 1024 * 1024KB = 1024 * 1024 * 1024Byte = 1024 * 1024 * 1024 * 8bit = 8,589,934,592 ≈ 85亿 也可以使用工具直接转换:https://www.bejson.com/convert/filesize/
2020-04-27 - 天草二十六 👍(5) 💬(1)
es倒排索引铺垫到现在差不多讲完了,真棒的梳理思路
2020-04-14 - KL3 👍(4) 💬(1)
请问老师,对倒排文件的检索,为了提高效率将词典加载到内存,并用哈希表组织,那哈希表的key是String,value是pos(文档列表在硬盘中的位置)吗?
2020-05-01 - qinsi 👍(4) 💬(3)
不是很明白存储关键词对应的字符串的作用。 1. 配图里的word是指关键字,string是指关键字所在的字符串吗?string是否可以理解为word所处的context?能否有些具体的例子呢? 2. 存入磁盘上的临时文件时只存了string而没有存word?那么在合并文件时word的信息是从哪来的呢? 3. 如果不存string,而只是根据word来做排序与合并的话,会有什么不好的后果吗?
2020-04-13 - 范闲 👍(4) 💬(1)
在无压缩的情况下: 对于Hash表的存储而言,数据量大的是value,是内容。 数组当然可以直接存储,但是内容太大的情况下,占用的连续内存太大了,可能会导致内存申请失败。 对于二叉树而言,内容的内存占用并没有减少,但是求交集的操作比链表复杂些。
2020-04-13 - 无形 👍(3) 💬(6)
看到评论里有提到前缀树,我有点疑问,如果字典的key只英文字母,如abcd可以用0123来表示,但是key如果还包含各种中英文符号、中文、韩文以及特殊字符等,怎么处理? 我还有两个问题, 1.对于根据关键词检索出来的文档,假如结果集达到百万千万级,怎么实现快速对结果集的排序? 2.对于已有的文档已经生成了key及对应的全量的文档列表,现在又有了新的文档,生成新的文档列表,全量的和新的文档列表怎么去合并?什么时候去合并?
2020-04-13 - 明翼 👍(0) 💬(1)
首先老师说hash表比较大,我们无法加入到内存中,hash表一般来说key比较小,那么假如我们hash表是按照拉链法来解决冲突,在持久化磁盘中,按照槽位的顺序保存 ,每一行即一个 [ 槽位,key,list(value)] ,由于不是每个槽位都有值,没有值的槽位key空着。我们可以在内存中,保存key和槽位的对应,以一个和槽位一样大小的数组,这样槽位和大hash表里面的槽位对应,值保存这个槽位的行在文件中的位置,来查询的时候,对要查询的数据计算hash值%槽位,得到的结果去内存中的数组中对应的位去找,找到再到文件找,找不到,就没有;如果key仍然很多,也无法用内存保存起来,可以只保存有值的key,数组中为结构体,里面含有有值的槽位,还有这个槽位在文件中的位置,查找的时候,用二分法查找;如果保留key也保存不下,那就试试用B+树,可以只保留几层,那就不用文件了,非叶子节点保存的是有值的槽位,用二分法很容易搜索,叶子节点为真正的槽位对应的值的list,不过这样的性能要差些,这样一变还是哈希表吗,哈哈
2020-04-13 - ifelse 👍(1) 💬(0)
学习了,干货满满
2023-04-10 - Geek_7b1aa5 👍(0) 💬(0)
思考:倒排索引的dict如果能全部加载进内存,就会大幅提升效率,在hash表无法存入内存的情况,是否能用其他内存空间占用更小的数据结构,来将词典完全加载到内存,有序数组和二叉树是否可行?想要节省空间,哈希表中的key应该是每个词项的hash值,而value是这个词项的字符串以及postlist指针(需要一个结构体)主要是value占用的空间比较多。 可以考虑数组的连续空间存储 ● 首先思路就是使用一个数组,每个数组元素存(结构体|length),但是结构体中的string词项是变长的,因此开辟数组空间只能以最长的为准,这样导致空间的浪费。 ● 改进的思路就是使用可变长的char数组紧凑的存储(结构体),顺序查找是比较慢的,然后在使用一个int数组建立索引,每个元素都是int类型,存储结构体的hash值,指向char对应数组元素位置。
2024-06-16 - 迪马 👍(0) 💬(0)
倒排索引是怎么实现范围检索的?
2022-11-09 - 阿甘 👍(0) 💬(0)
老师你上面提到的最后给出的解决方案:词典文件 + 倒排文件的方式。是不是一个search要走两次IO啊。一次是根据内存的term index找到该term在磁盘中的词典文件的pos,从而捞出term对应的posting list的pos,然后再根据这个pos从磁盘中的倒排文件捞出最终的posting list?
2022-07-05 - 无昂 👍(0) 💬(1)
对于一些"黑产"造出来的一些“违规词”,这次违规词在分词的时候,分词组件并不能很好的识别把这些词分成一个词,这样搜索的效果会大打折扣,这样的问题该如何解决呢?
2022-02-05