04 状态检索:如何快速判断一个用户是否存在?
你好,我是陈东。
在实际工作中,我们经常需要判断一个对象是否存在。比如说,在注册新用户时,我们需要先快速判断这个用户ID是否被注册过;再比如说,在爬虫系统抓取网页之前,我们要判断一个URL是否已经被抓取过,从而避免无谓的、重复的抓取工作。
那么,对于这一类是否存在的状态检索需求,如果直接使用我们之前学习过的检索技术,有序数组、二叉检索树以及哈希表来实现的话,它们的检索性能如何呢?是否还有优化的方案呢?今天,我们就一起来讨论一下这些问题。
如何使用数组的随机访问特性提高查询效率?
以注册新用户时查询用户ID是否存在为例,我们可以直接使用有序数组、二叉检索树或者哈希表来存储所有的用户ID。
我们知道,无论是有序数组还是二叉检索树,它们都是使用二分查找的思想从中间元素开始查起的。所以,在查询用户ID是否存在时,它们的平均检索时间代价都是O(log n),而哈希表的平均检索时间代价是O(1)。因此,如果我们希望能快速查询出元素是否存在,那哈希表无疑是最合适的选择。不过,如果从工程实现的角度来看的话,哈希表的查询过程还是可以优化的。
比如说,如果我们要查询的对象ID本身是正整数类型,而且ID范围有上限的话。我们就可以申请一个足够大的数组,让数组的长度超过ID的上限。然后,把数组中所有位置的值都初始化为0。对于存在的用户,我们直接将用户ID的值作为数组下标,将该位置的值从0设为1就可以了。
这种情况下,当我们查询一个用户ID是否存在时,会直接以该ID为数组下标去访问数组,如果该位置为1,说明该ID存在;如果为0,就说明该ID不存在。和哈希表的查找流程相比,这个流程就节省了计算哈希值得到数组下标的环节,并且直接利用数组随机访问的特性,在O(1)的时间内就能判断出元素是否存在,查询效率是最高的。
但是,直接使用ID作为数组下标会有一个问题:如果ID的范围比较广,比如说在10万之内,那我们就需要保证数组的长度大于10万。所以,这种方案的占用空间会很大。
而且,如果这个数组是一个int 32类型的整型数组,那么每个元素就会占据4个字节,用4个字节来存储0和1会是一个巨大的空间浪费。那我们该如何优化呢?你可以先想一想,然后我们一起来讨论。
如何使用位图来减少存储空间?
最直观的一个想法就是,使用最少字节的类型来定义数组。比如说,使用1个字节的char类型数组,或者使用bool类型的数组(在许多系统中,一个bool类型的元素也是1个字节)。它们和4个字节的int 32数组相比,空间使用效率提升了4倍,这已经算是不错的改善了。
但是,使用char类型的数组,依然是一个非常“浪费空间”的方案。因为表示0或者1,理论上只需要一个bit。所以,如果我们能以bit为单位来构建这个数组,那使用空间就是int 32数组的1/32,从而大幅减少了存储使用的内存空间。这种以bit为单位构建数组的方案,就叫作Bitmap,翻译为位图。
位图的优势非常明显,但许多系统中并没有以bit为单位的数据类型。因此,我们往往需要对其他类型的数组进行一些转换设计,使其能对相应的bit位的位置进行访问,从而实现位图。
我们以char类型的数组为例子。假设我们申请了一个1000个元素的char类型数组,每个char元素有8个bit,如果一个bit表示一个用户,那么1000个元素的char类型数组就能表示8*1000 = 8000个用户。如果一个用户的ID是11,那么位图中的第11个bit就表示这个用户是否存在的信息。
这种情况下,我们怎么才能快速访问到第11个bit呢?
首先,数组是以char类型的元素为一个单位的,因此,我们的第一步,就是要找到第11个bit在数组的第几个元素里。具体的计算过程:一个元素占8个bit,我们用11除以8,得到的结果是1,余数是3。这就代表着,第11个bit存在于第2个元素里,并且在第2个元素里的位置是第3个。
对于第2个元素的访问,我们直接使用数组下标[1]就可以在O(1)的时间内访问到。对于第2个元素中的第3个bit的访问,我们可以通过位运算,先构造一个二进制为00100000的字节(字节的第3位为1),然后和第2个元素做and运算,就能得知该元素的第3位是1还是0。这也是一个时间代价为O(1)的操作。这样一来,通过两次O(1)时间代价的查找,我们就可以知道第11个bit的值是0还是1了。
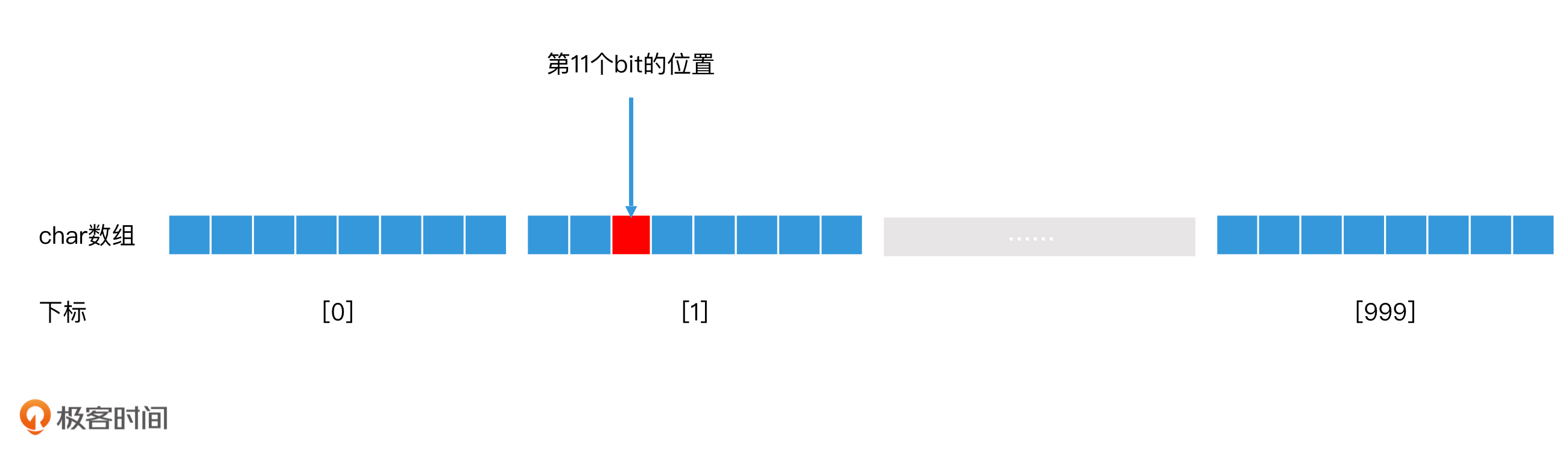
用户ID为11的位图定位
尽管位图相对于原始数组来说,在元素存储上已经有了很大的优化,但如果我们还想进一步优化存储空间,是否还有其他的优化方案呢?我们知道,一个数组所占的空间其实就是“数组元素个数*每个元素大小”。我们已经将每个元素大小压缩到了最小单位1个bit,如果还要进行优化,那么自然会想到优化“数组元素个数”。
没错,限制数组的长度是一个可行的方案。不过前面我们也说了,数组长度必须大于ID的上限。因此,如果我们希望将数组长度压缩到一个足够小的值之内,我们就需要使用哈希函数将大于数组长度的用户ID,转换为一个小于数组长度的数值作为下标。除此以外,使用哈希函数也带来了另一个优点,那就是我们不需要把用户ID限制为正整数了,它也可以是字符串。这样一来,压缩数组长度,并使用哈希函数,就是一个更加通用的解决方案。
但是我们也知道,数组压缩得越小,发生哈希冲突的可能性就会越大,如果两个元素A和B的哈希值冲突了,映射到了同一个位置。那么,如果我们查询A时,该位置的结果为1,其实并不能说明元素A一定存在。因此,如何在数组压缩的情况下缓解哈希冲突,保证一定的查询正确率,是我们面临的主要问题。
在第3讲中,我们讲了哈希表解决哈希冲突的两种常用方法:开放寻址法和链表法。开放寻址法中有一个优化方案叫“双散列”,它的原理是使用多个哈希函数来解决冲突问题。我们能否借鉴这个思想,在位图的场景下使用多个哈希函数来降低冲突概率呢?没错,这其实就是布隆过滤器(Bloom Filter)的设计思想。
布隆过滤器最大的特点,就是对一个对象使用多个哈希函数。如果我们使用了k个哈希函数,就会得到k个哈希值,也就是k个下标,我们会把数组中对应下标位置的值都置为1。布隆过滤器和位图最大的区别就在于,我们不再使用一位来表示一个对象,而是使用k位来表示一个对象。这样两个对象的k位都相同的概率就会大大降低,从而能够解决哈希冲突的问题了。
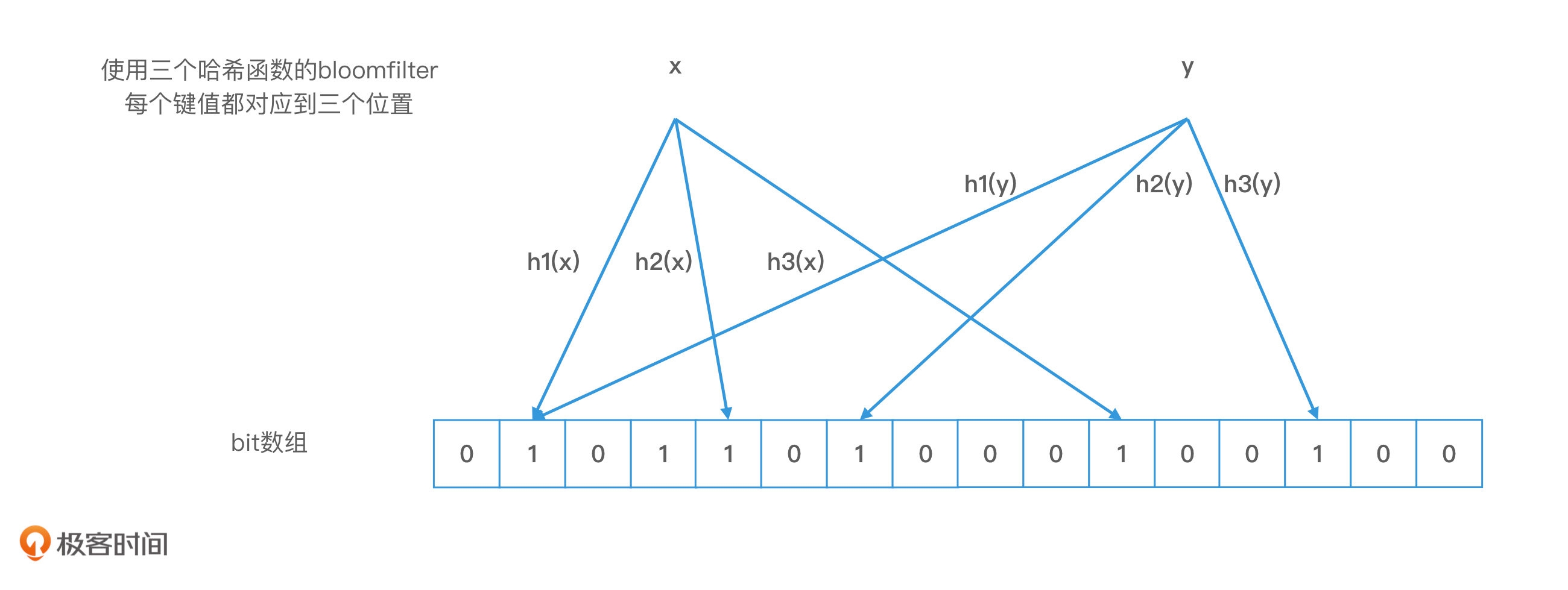
Bloom filter 示例
但是,布隆过滤器的查询有一个特点,就是即使任何两个元素的哈希值不冲突,而且我们查询对象的k个位置的值都是1,查询结果为存在,这个结果也可能是错误的。这就叫作布隆过滤器的错误率。
我在下图给出了一个例子。我们可以看到,布隆过滤器中存储了x和y两个对象,它们对应的bit位被置为1。当我们查询一个不存在的对象z时,如果z的k个哈希值的对应位置的值正好都是1,z就会被错误地认定为存在。而且,这个时候,z和x,以及z和y,两两之间也并没有发生哈希冲突。
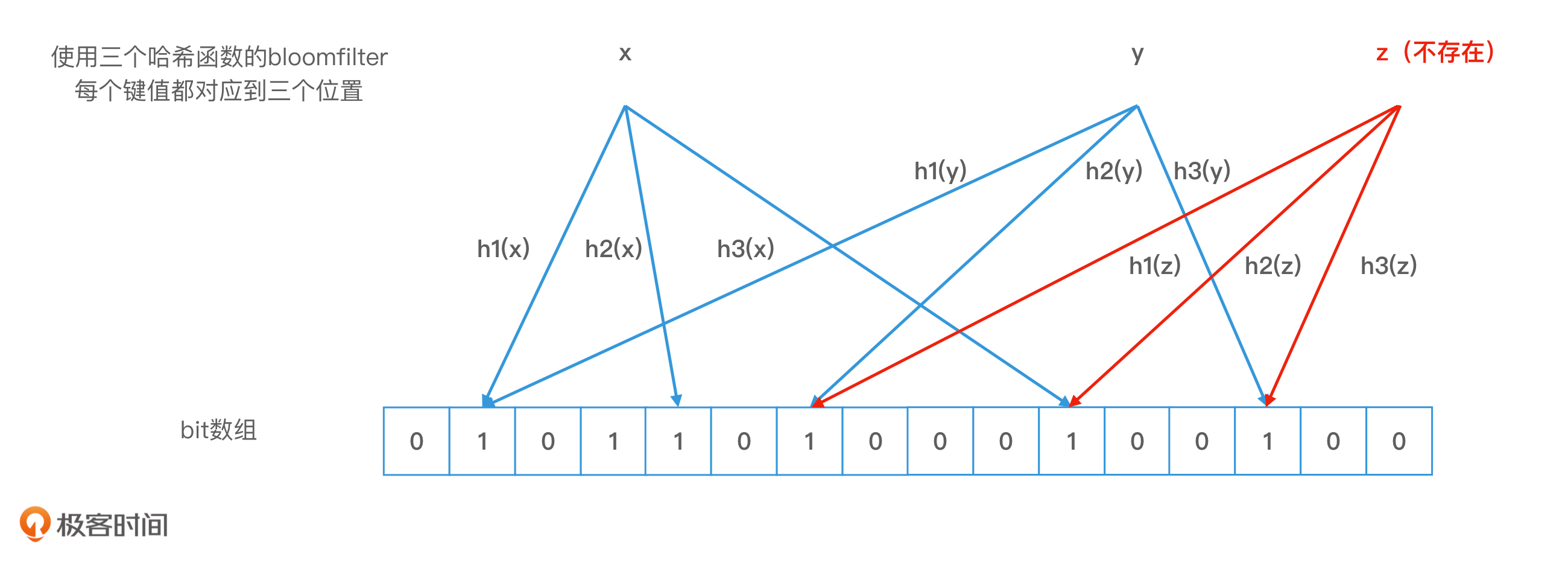
Bloom filter 错误率示例
那遇到“可能存在”这样的情况,我们该怎么办呢?不要忘了我们的使用场景:我们希望用更小的代价快速判断ID是否已经被注册了。在这个使用场景中,就算我们无法确认ID是否已经被注册了,让用户再换一个ID注册,这也不会损害新用户的体验。在系统不要求结果100%准确的情况下,我们可以直接当作这个用户ID已经被注册了就可以了。这样,我们使用布隆过滤器就可以快速完成“是否存在”的检索。
除此之外,对于布隆过滤器而言,如果哈希函数的个数不合理,比如哈希函数特别多,布隆过滤器的错误率就会变大。因此,除了使用多个哈希函数避免哈希冲突以外,我们还要控制布隆过滤器中哈希函数的个数。有这样一个计算最优哈希函数个数的数学公式: 哈希函数个数k = (m/n) * ln(2)。其中m为bit数组长度,n为要存入的对象的个数。实际上,如果哈希函数个数为1,且数组长度足够,布隆过滤器就可以退化成一个位图。所以,我们可以认为“位图是只有一个特殊的哈希函数,且没有被压缩长度的布隆过滤器”。
重点回顾
好了,状态检索的内容我们就讲到这里。我们一起来总结一下,这一讲你要掌握的重点内容。
今天,我们主要解决了快速判断一个对象是否存在的问题。相比于有序数组、二叉检索树和哈希表这三种方案,位图和布隆过滤器其实更适合解决这类状态检索的问题。这是因为,在不要求100%判断正确的情况下,使用位图和布隆过滤器可以达到O(1)时间代价的检索效率,同时空间使用率也非常高效。
虽然位图和布隆过滤器的原理和实现都非常简单,但是在许多复杂的大型系统中都可以见到它们的身影。
比如,存储系统中的数据是存储在磁盘中的,而磁盘中的检索效率非常低,因此,我们往往会先使用内存中的布隆过滤器来快速判断数据是否存在,不存在就直接返回,只有可能存在才会去磁盘检索,这样就避免了为无效数据读取磁盘的额外开销。
再比如,在搜索引擎中,我们也需要使用布隆过滤器快速判断网站是否已经被抓取过,如果一定不存在,我们就直接去抓取;如果可能存在,那我们可以根据需要,直接放弃抓取或者再次确认是否需要抓取。你会发现,这种快速预判断的思想,也是提高应用整体检索性能的一种常见设计思路。
课堂讨论
这节课的内容,你可以结合这道讨论题进一步加深理解:
如果位图中一个元素被删除了,我们可以将对应bit位置为0。但如果布隆过滤器中一个元素被删除了,我们直接将对应的k个bit位置为0,会产生什么样的问题呢?为什么?
欢迎在留言区畅所欲言,说出你的思考过程和最终答案。如果有收获,也欢迎把这篇文章分享给你的朋友。
- 峰 👍(43) 💬(6)
bitmap 是一个集合,每个元素在集合中有一个唯一不冲突的编号(用户自己保证,在数据库中这个编号可以是行号),是双射关系。而布隆过滤器是一个不准确的集合,而且是一对多的关系,会发生冲突,也就是说布隆过滤器的为1的位可能代表多个元素,自然不能因为一个元素删除就把它干掉?,或者说他就不支持删除操作,感觉它要支持了,反而把它本身的优势给丢了。 1,其实对布隆过滤器是省了空间,我表示持怀疑态度,可能需要证明下,我可能更多的认为它是一种平衡单个hash 函数对数据分布有偏差性导致最差情况的数据冲突的概率大的一种方法。 2,bitmap 本身也有很多压缩方法,最有名的应该是roaringbitmap ,大家有兴趣可以了解下。
2020-03-30 - 每天晒白牙 👍(17) 💬(1)
请教老师一个问题 假如我有3亿个连续id,如果使用BitMap存储,需要消耗 3亿/8/1024/1024 大约36MB 如果用 GuavaCache 的 BloomFilter,在默认误判率0.03的情况下,占用内存约261MB BloomFilter<CharSequence> filter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedInsertions); 其中 expectedInsertions 代表预估数量即3亿,通过查看源码,BloomFilter 根据预估数量和误判率计算bit数组的公式 m=-n*ln(fpp)/(log2)^2 long m = (long) (-expectedNum * Math.log(fpp) / (Math.log(2) * Math.log(2))); expectedNum就是3亿,计算出来的m为2189532251,大于3亿,这个结果感觉说不通,BloomFilter 通过使用多个哈希函数,应该需要的数组长度小于3亿才对呀,而BloomFilter是用long型的数组实现,所以会根据计算出来的m计算long数组的大小int longNum = Ints.checkedCast(LongMath.divide(m, 64, RoundingMode.CEILING));计算出来是34211442,占用内存是261MB 所以,同样3亿个连续id,使用Guava 的BloomFilter占用的内存反而比使用BitMap内存大,通过学习这篇文章,我觉得结果应该是相反的,我有点蒙了,请老师帮忙指点下
2020-07-09 - 阿斯蒂芬 👍(13) 💬(3)
刚看完时有点“混乱”,搞不清楚哈希表、位图、布隆过滤器的核心区别在哪,翻了评论和老师解答后(特别是@峰)才逐渐明晰,区别核心的不同仍然是应用场景以及其中衍生的一个“阈值”: 老师讲的元素是否存在,比较学术风,换个业务场景来看,假设有个网站,用户id是64位长整整型,需要记录每天有哪些用户登陆了,假设用户总量1亿,日活有5千万,则如果使用普通的集合或者哈希表存储用户id,64*10^8=400M,这还是一天的登录数据,但是如果用位图,则是 1*10^8 = 12.5M 即可。400 / 12.5 = 32,也就是老师讲的 1/32 的空间消耗。 在这个场景下,位图看起来是吊打集合与散列表,但是如果日活只有可怜的10万,这时候重新计算,使用集合或散列表,64*10^8 = 800k,而位图则依然是12.5M。这时候位图被吊打,就是因为场景下其实有个关键的阈值:用户数据规模大小与日活大小。 总结来看,节省哈希函数的耗时,是位图固有的优势,而是否节省空间,则只有分析过数据的实际场景,才能决策出合适的数据存储方案,使检索达到空间和时间的最佳。 正好回复评论区@gogo同学问的什么语言有位图的实现:Redis的Bitmap就是位图实现的一种,而且还提供了位图的交集差集等api,值得一看。以上的场景也是参考Redis书籍描述的。 至于布隆过滤器,刚开始因为觉得既然都使用了哈希函数,那本质上和散列表不就是一样了?同样是刷了评论区才反应过来,重点在于K个哈希函数,不仅仅是在概率上降低了哈希冲突,而且因为需要K个位置来确定一个元素,所以可以用更小的范围来映射同样的数据规模,因此布隆过滤器在时间和空间的平衡上,感觉算是最折中的,不知这样理解是否合适,还望老师指点。 另外搬运Wiki上一段关于布隆过滤器优点的描述,我觉得切入点不错,还考虑到了(硬件以及数据安全性): 相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数 O(k)。另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
2020-04-13 - aoe 👍(10) 💬(1)
看了大家的留言,老师的回复,感慨一下:原来布隆过滤器不能随便删,可以周期性重构数据!
2020-04-02 - 徐洲更 👍(7) 💬(3)
因为同一个ID经过哈希函数会得到多个位置,不同的ID可能会有一些位置overlap。如果ID A和B刚好有一个位置重合,那么删除A的时候,如果直接将它对应的位置清零,就导致B也被认为是不存在。因此bloom filter删除操作很麻烦
2020-03-30 - 真名不叫黄金 👍(6) 💬(1)
如果布隆过滤器要支持删除,那么就必须支持计数,那么相应地会增加占用存储空间,因为不能再用一个bit表示了。 因此不需要支持删除的布隆过滤器是将它节省空间的优势发挥到了极致,在基于LSM Tree的数据库中,就会使用布隆过滤器,这种基于追加写的数据结构本身查询会变慢,但恰巧由于它是追加写,不存在删除问题,因此可以生成布隆过滤器加速查找,因此布隆过滤器与LSM Tree是一个很适合的组合~
2020-04-12 - piboye 👍(4) 💬(1)
cbf可以支持删除操作,但是取多少bit是怎么计算的?
2020-09-23 - CycleGAN 👍(4) 💬(1)
老师非常有条理脉络清晰,评论也非常认真,受益匪浅
2020-04-20 - mickey 👍(1) 💬(1)
如果位图中一个元素被删除了,我们可以将对应 bit 位置为 0。但如果布隆过滤器中一个元素被删除了,我们直接将对应的 k 个 bit 位置为 0,会产生什么样的问题呢?为什么? 因为这样可能导致其他存在的元素的bit值置为0,从而导致已经存在的元素被后续判断为不存在。
2020-06-23 - ヾ(◍°∇°◍)ノ゙ 👍(1) 💬(1)
用户的id作为数组下标,需要id事先被约定过已知的吧?一般用户注册的id未知的吧,那么怎么事先会有一个已用户id作为下标的数组呢?不是很理解。望老师在细说一下
2020-06-09 - 睿本MOP 👍(1) 💬(1)
请问,在分布式系统中, id雪花算法生成的的20长度的long 这种情况下 无法用bitmap, 请问有好的解决方案吗
2020-05-10 - yang 👍(1) 💬(1)
看了老师和其他同学的回复 那用户id来举例判断这个id是否存在: 位图: 1. 用户id是正整数的时候,可以用bitMap存储,bitMap 是一对一的存储,不清楚用户id的分布范围,可以采用包含所有正整数长度的数组,大小为512MB, 那这样的话,一次申请下来一直允许,会不会很耗费空间? 2. 对于bitMap为一对一的话,那bitMap是不是就不会冲突呢,也就是说bitMap是准确的? 3. 针对bitMap, 增加id=7的用户是否存在用异或运算吧 bitMap[7] = bitMap[7] ^ 1? 删除 bitMap[7] = bitMap[7] & 0 用与运算? 查询 bitMap[7] = bitMap[7] & 1 用与运算吧? 布隆过滤器: 1. 布隆过滤器 采用多次hash, 计算得到几个不同的位,受到hash冲突的影响,布隆过滤器可能会误判。 2. 新增第7个用户,hash m 次,得到m 个不同的位,置为1。删除的时候,看到老师回复其他同学,有两种方案: a. 对当前位采用引用计数,当存的时候当前为为1,那计数器就+1; 删除的时候根据引用计数器做-1操作,直至引用计数器为0 对当前位置0。 b. 删除时re-hash, 那这样的话,当布隆过滤器的数组很大的时候,是不是会有点慢呢? 另外: 1. bitMap 和 布隆过滤器 在java的那里有实现啊 2. 老师提到的 针对布隆过滤器 引用计数 和 rehash的方法,我们在哪里可以看到啊,java哪里有具体的实现啊? 3. 还有您提到的ArrayContainer是在哪里出现的啊? 恳请老师告知,感谢陈东老师!
2020-04-09 - eureka 👍(1) 💬(1)
为什么允许布隆过滤器的错误率,而不能容许允许哈希冲突呢
2020-04-08 - 吴小智 👍(0) 💬(1)
如果写入一个用户,没有往布隆过滤器注册或和注册失败了,那是不是就一直都找不到这个用户了?
2021-06-11 - 森林木 👍(0) 💬(1)
bloom filter里如果直接删除位可能会影响其他数据的检索,比如两个数同时有一位是1。
2021-04-08