22 如何在与LLM交互过程中省钱及控制Rate Limits?
你好,我是黄佳。
OpenAI提供了强大的自然语言处理API,但在将原型转移到生产环境时,管理与运行应用程序相关的成本是一个重要的挑战,尤其是当我们调用OpenAI家族中比较贵的模型的时候,这一讲我们来看看这方面的内容。
OpenAI采用按使用量付费的定价模式,费用以Token为单位计算。Token的价格因所使用的模型而异。为了估算成本,需要预测Token的使用量,考虑诸如流量水平、用户与应用程序交互的频率以及要处理的数据量等因素。
对话过程中的 Token
众所周知,语言模型以称为Token的块来读写文本。一个Token可以是一个字符、一个单词,甚至在某些语言中可以比一个字符更短或比一个单词更长。例如,“ChatGPT is great!” 这个句子被编码为六个Token:[“Chat”, “G”, “PT”, “is”, “great”, “!”]。
API调用中的Token总数会影响API调用的成本,也会影响API调用的时间。同时,总Token数必须低于模型所能容纳的最大限制。

图中这个Context Window,指的是输入输出能够容纳的Token总和。在OpenAI的API中,并没有对所能输出的Token进行限制,也就是说max_tokens是一个可选项。
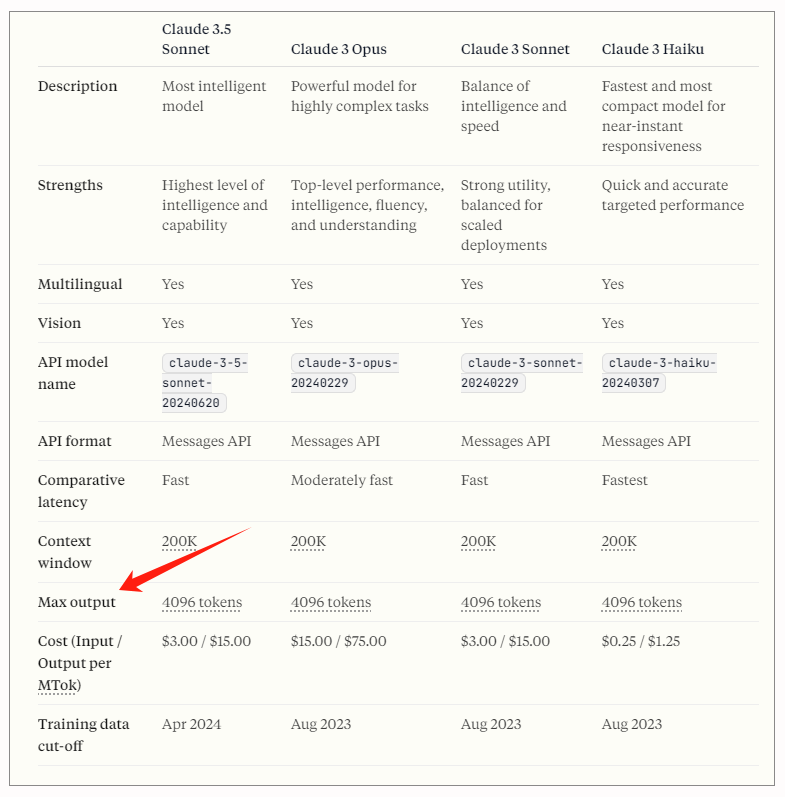
但是,对于有些模型来说,比如Claude家族的模型,它的最大输出长度就是有限制的,目前是4096个Token,也就是说,虽然模型可以读入很长的上下文,但是能够输出的内容,只有4096这么多。
OpenAI提供了一个 tokenizer 工具来帮助我们估算Token数量。在这个页面中,我们输入文本,OpenAI就会显示GPT模型将如何把输入文本转换为一个个的Token。
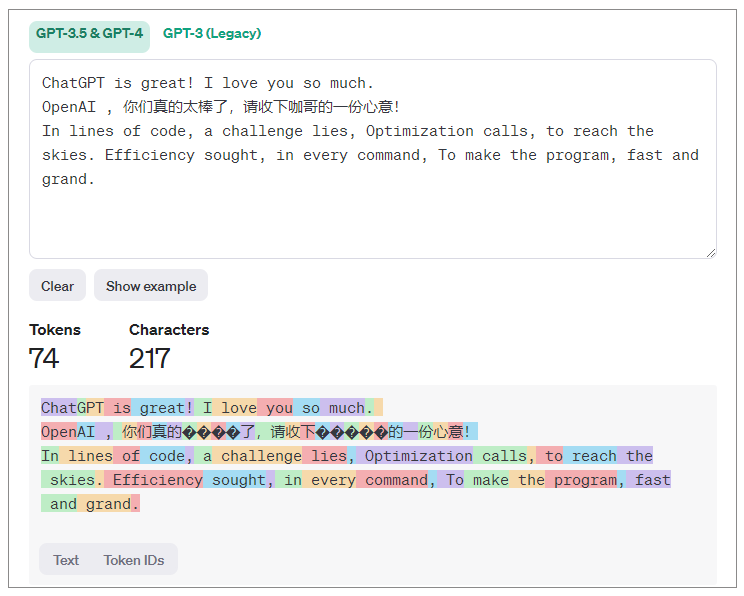
总的说,一个标记通常对应于常见英语文本的约 4 个字符。这大约相当于一个单词的 ¾,因此 100 个Token约等于 75 个单词。那么,一部总字数为75万字的莎士比亚全集,全部输入大模型,就会耗费掉1M个Token。根据目前GPT-4家族模型的价格,这大概需要消耗3~10美金。
计算 API 调用的 Token 数
输入和输出Token都会被收费。如输入中使用了10个Token,在消息输出中收到了20个Token,那么将被收取30个Token的费用。不过呢,对于某些模型,输入中的Token和输出中的Token的每Token 价格是不同的。一般来说,输入Token便宜些,输出Token更贵。

要查看API调用一共使用了多少Token,可以查看API响应中的usage.total_tokens字段。不过,因为有时需要在传入API之前,就估算提示词中的Token数,可以通过tiktoken包来进行事先的估算。
tiktoken是一个由OpenAI开发的快速开源分词器,用于将文本转换为语言模型可以处理的Tokens。不同的OpenAI模型使用不同的编码方式来将文本转换为Tokens。
tiktoken库支持以下三种常见的编码:
- cl100k_base:用于GPT-4、GPT-3.5-Turbo等模型。
- p50k_base:用于Codex、text-davinci-002/003等模型。
- r50k_base:用于GPT-3等模型。
首先通过 pip install tiktoken 安装tiktoken包。
下面是一个估算传递给LLM的消息的Token数示例。
import os
import openai
import tiktoken # 假设 tiktoken 已安装并可用
def num_tokens_from_messages(messages, model="gpt-3.5-turbo"):
"""返回消息列表中使用的Token数量。"""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo": # 注意:未来的模型可能会有所不同
num_tokens = 0
for message in messages:
num_tokens += 4 # 每条消息遵循 <im_start>{role/name}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # 如果有名字,角色会被省略
num_tokens += -1 # 角色是必须的,并且总是占用 1 个Token
num_tokens += 2 # 每个回复以 <im_start>assistant 开始
return num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() 目前未实现用于模型 {model}。""")
# 创建一条消息并将其传递给上面定义的函数以查看Token计数
messages = [
{"role": "system", "content": "你是一个乐于助人的客户服务助手,擅长解决客户问题并提供清晰的解决方案。"},
{"role": "user", "content": "我在使用你们的软件时遇到了一些问题,无法登录我的账户。"},
{"role": "assistant", "content": "很抱歉听到您遇到了问题。请问您是否尝试了重置密码?"},
{"role": "user", "content": "是的,我尝试了,但仍然无法登录。"},
{"role": "assistant", "content": "请您提供一下您的账户邮箱地址,我来帮您查看一下。"},
{"role": "user", "content": "我的邮箱是example@example.com。"},
]
model = "gpt-3.5-turbo"
print(f"{num_tokens_from_messages(messages, model)} 个Token计数。")
# 使用 OpenAI API 验证计算结果
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.chat.completions.create(
model=model,
messages=messages,
temperature=0,
)
print(f'{response.usage.prompt_tokens} 个Token使用。')
那么,如果我们估算出来了Prompt中的Token数,同时又知道模型输入输出所能容纳的全部Token数(总Token),就可以设置适宜的max_tokens参数,防止输出因为总Token数量的限制而被截断。
控制 Token 数量的技巧
估算Token的数量虽然有点用,但是更重要的事情是探讨如何节省Token数。下面,我们就来看看有哪些控制Token数量的技巧。
技巧 1:精简提示词
提示词的精简是控制Token数量最直接且最有效的方法之一。这不仅仅是简单地减少文字数量,而是要在保持信息完整性的前提下,提高信息的密度和相关性。
首先,在长对话中,我们可以定期对对话历史进行总结或压缩,只保留关键的上下文信息。这种方法可以显著减少每次请求中的Token数量,同时保持对话的连贯性。其次,在编写提示时,我们应该追求简洁明了。这意味着要直击要点,避免不必要的修饰和冗余信息。
对于特定领域或任务,我们可以考虑对模型进行微调。经过微调的模型对特定任务有更好的理解,因此可以使用更简短的提示来获得相同质量的输出。对于频繁出现的相似查询,我们可以实现查询结果的缓存机制。这样不仅可以减少重复处理相同查询的Token消耗,还能显著提高响应速度。
技巧 2:设置使用阈值和预算
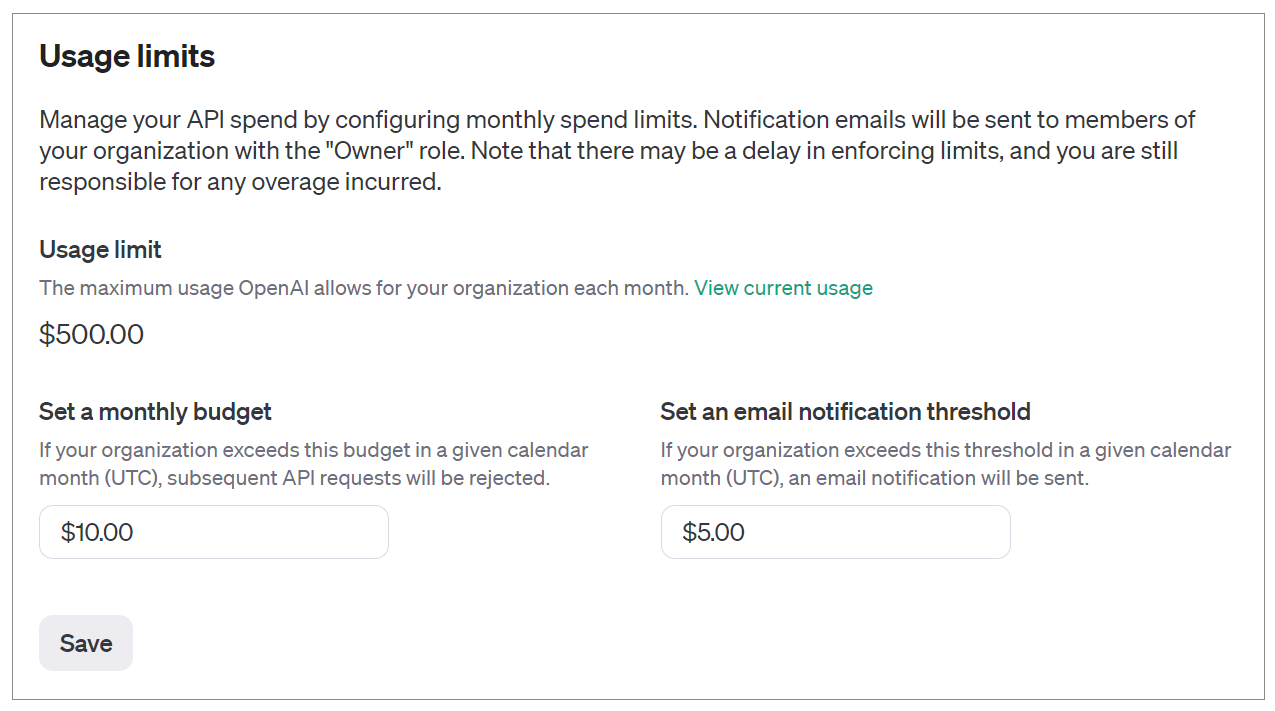
为了监控成本,你可以在帐户中设置阈值,一旦超过某个使用阈值就会收到电子邮件,提醒你本月已经消耗了多少银子。你还可以设置每月预算,一旦使用时的费用超出预算,API就停工。我这里,就设了一个5元的提醒和每月10元的预算。对于学习者来说,这也就够用了,但是如果达到预算上限,你的应用程序可能会被迫中断。
在OpenAI提供的仪表板中,也可以踪当前和过去计费周期内的Token使用情况。
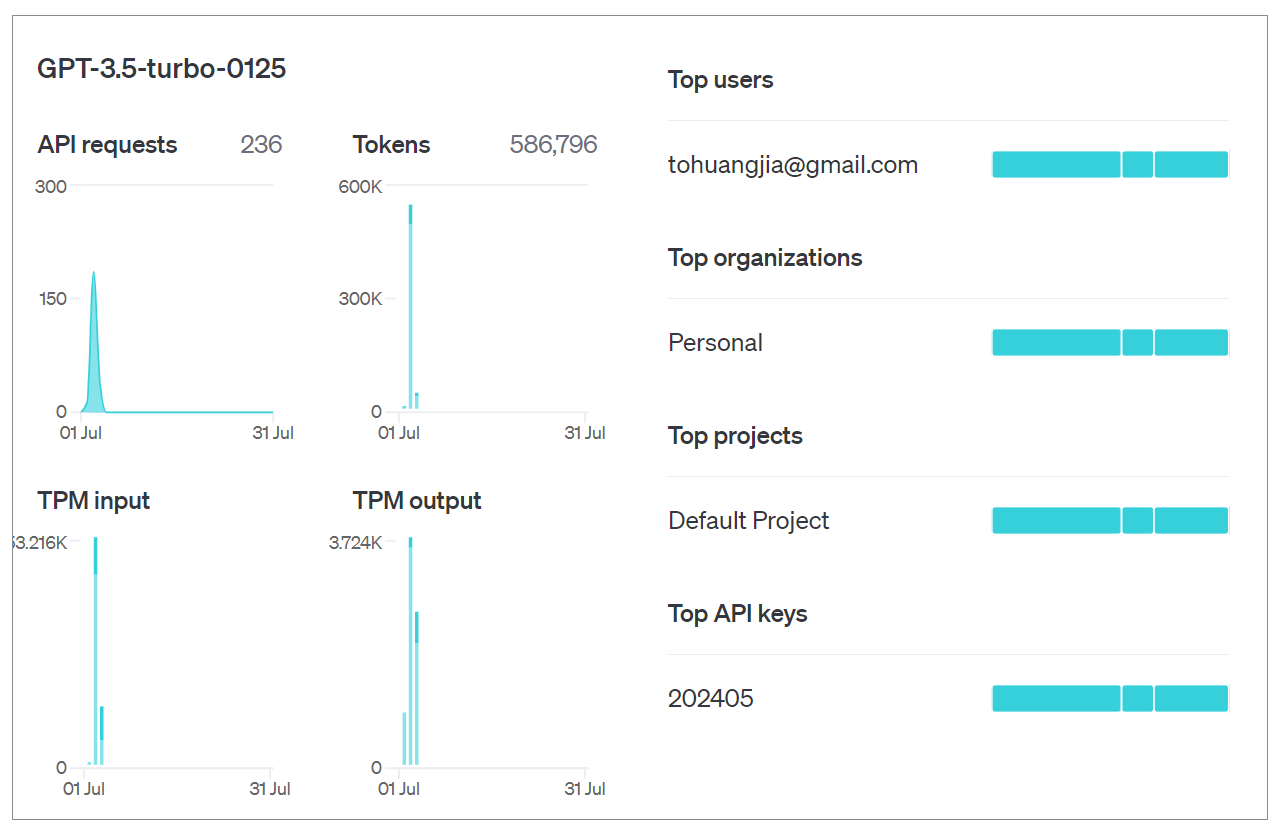
通过定期分析使用数据,可以识别出Token使用的高峰期和低谷期,从而更好地优化资源分配。例如,你可能会发现某些特定类型的查询消耗了大量Token,这就为进一步的优化提供了方向。
技巧 3:限制模型输出Token的数量
另一个技巧是控制生成Token的数量,这不仅能有效控制成本,还可以显著减少延迟。
首先是 max_tokens 参数。这个参数决定了模型在一次请求中最多可以生成多少个Token。特别是当我们期望模型言简意赅地回答任务时,就设置一个适当的 max_tokens 值以避免生成不必要的内容,同时确保生成的内容足够完整。
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
max_tokens=50 # 设置生成的最大Token数量为50
)
return response.choices[0].message.content
另一个有效的策略是使用停止序列。通过设置特定的停止序列,我们可以在达到预期输出时立即停止生成,避免产生多余的Token。例如,在对话过程中,如果我们想在看到OK(或者“好了”)这个单词的时候自动结束输出,可以将 “OK” 设置为停止序列,这样一旦模型开始生成这个单词,就会立即停止进一步的文本生成。当然我们在提示模型的时候,必须要告诉模型,在差不多的时候,就输出 “OK”,或者“好了”这样的词语。
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
max_tokens=100, # 设置生成的最大Token数量
stop=["OK"] # 当生成到单词OK时停止
)
return response.choices[0].message.content
对于长文本生成任务,我们可以考虑实现一个分段生成的策略。不要一次性生成整个长文本,而是将任务分解成多个小段,逐段生成。这样不仅可以更好地控制每次请求的Token数量,还能在生成过程中进行中间检查和调整,从而提高最终输出的质量。
技巧 4:巧用廉价模型
在追求高质量输出的同时控制成本,一个有效的策略是巧妙地利用不同模型的优势。也就是通过切换到较小的模型来完成某些任务,从而降低每个Token的成本。这种方法可以被称为模型级联。它不仅可以在成本和性能之间取得平衡,还能在某些情况下提高整体的处理效率。
在模型级联的架构中,我们可以首先使用较小、较快、成本较低的模型(比如像 DeepSeek-V2 这样的国产开源模型)来处理简单任务或生成初步答案。这些模型虽然在复杂任务上的表现可能不如顶级模型,但在处理基本查询或生成初步草稿时却非常高效(比如说,让推理成本较低的模型把某本英文书,先翻译,再总结成中文)。
之后,我们可以选择性地使用更高级的模型(如GPT-4)来精炼或改进初步结果(比如说,用高级模型对初步翻译总结的文档进行审核和句子的优化)。通过这种方式,我们可以显著降低整体的Token使用量,同时保持输出质量。这种方法特别适用于那些需要高质量输出但对实时性要求不是特别高的场景。
另一个有趣的应用是使用高级模型作为评估工具。我们可以在后台使用像GPT这样的高级模型来评估其他模型的输出质量。这种方法可以帮助我们建立一个质量基准,用于持续改进和优化其他模型的性能。虽然这种方法本身会消耗一定的Token,但从长远来看,它可以帮助我们更有针对性地优化系统,提高整体的效率。
速率限制的应对
在和OpenAI进行对话时,我们有时会收到类似这样的一条Error。
openai.RateLimitError: Error code: 429: 'Too Many Requests' Rate limit reached for gpt-4-turbo in organization XXXX on tokens per min.
Limit: 10000.000000 / min. Current: 10020.000000 / min.
这就是速率限制被触发了。这并不一定是你调用的特别多,特别频繁,因为OpenAI对于每个账号的速率限额配置都是不同的。
首先,我们需要理解为什么API需要实施速率限制。这主要出于三个方面的考虑:防止滥用、确保公平访问以及管理基础设施负载。通过限制单个用户或客户端在特定时间内的请求次数,可以有效防止恶意攻击者通过大量请求来压垮系统。同时,它也确保了资源的公平分配,防止某些用户过度占用资源而影响其他用户的使用体验。速率限制还能帮助服务提供商更好地管理和预测系统负载,从而维持稳定的服务质量。
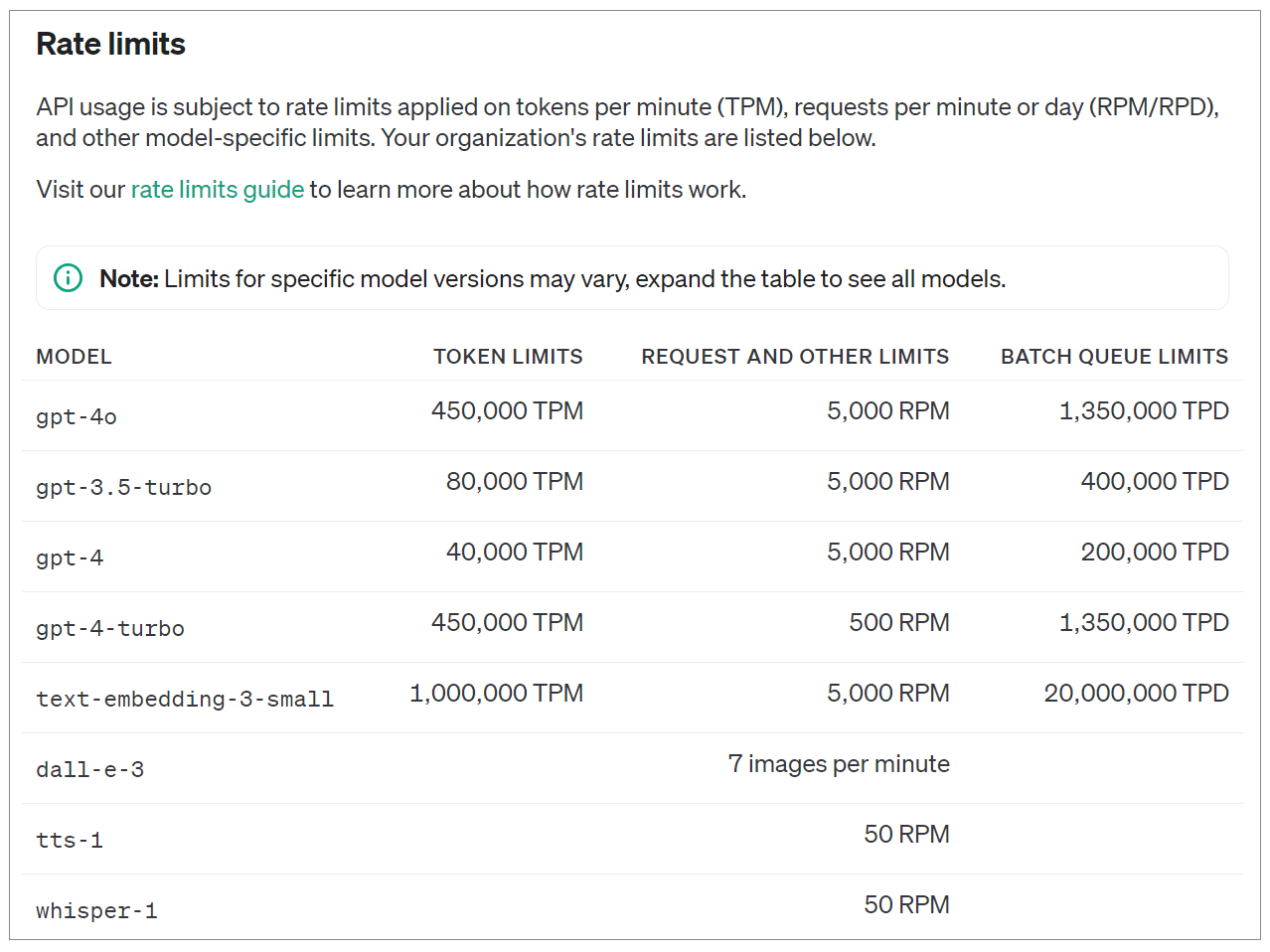
OpenAI的速率限制系统采用了多维度的限制策略。具体而言,限制包括每分钟请求数(RPM)、每天请求数(RPD)、每分钟Token数(TPM)、每天Token数(TPD)以及每分钟图像数(IPM)等。这些限制并不是独立运作的,而是相互关联的。例如,即使用户没有达到TPM限制,但如果超过了RPM限制,仍然会触发限制机制。这些限制是在组织和项目级别设置的,而不是针对单个用户。不同的模型可能有不同的限制标准,某些模型系列甚至可能共享相同的限制。
OpenAI采用了分层的使用限制策略。随着用户对API的使用量和支出增加,系统会自动将用户升级到更高的使用层级。例如,从免费层级到第五层级,每月的使用限额从100美元逐步增加到50,000美元。每个层级都有其特定的资格要求和相应的限制标准。

为了帮助开发者更好地管理他们的API使用,OpenAI在HTTP响应头中提供了详细的速率限制信息。这包括剩余的请求数、Token数以及限制重置时间等关键数据。开发者可以利用这些信息来优化他们的API调用策略,避免触发限制。
面对速率限制,开发者有多种策略可以采用,来优化他们的API使用。一个常用的方法是实现指数退避重试机制。当遇到速率限制错误时,程序会自动等待一段时间后重试,如果仍然失败,则增加等待时间再次尝试。这种方法可以有效地处理临时的限制问题,同时避免立即重试给服务器带来额外压力。
from openai import OpenAI
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
)
# 初始化OpenAI客户端
client = OpenAI()
# 使用Tenacity库的retry装饰器来实现指数退避重试
@retry(
wait=wait_random_exponential(min=1, max=60), # 随机指数退避,最小1秒,最大60秒
stop=stop_after_attempt(6), # 最多尝试6次
reraise=True # 重新抛出最后一次异常
)
def completion_with_backoff(**kwargs):
"""
使用指数退避策略的API调用函数
:param kwargs: 传递给completions.create的参数
:return: API的响应结果
"""
try:
return client.chat.completions.create(**kwargs)
except Exception as e:
print(f"API调用发生错误: {str(e)}")
raise # 重新抛出异常,让retry继续处理
# 使用该函数进行API调用
try:
response = completion_with_backoff(
model = "gpt-3.5-turbo",
messages = [{"role": "user", "content": "从前有座山,"}]
)
print("API调用成功,响应内容:", response.choices[0].message.content)
except Exception as e:
print(f"在多次重试后仍然失败: {str(e)}")
另一个有效的策略是优化max_tokens参数。通过将max_tokens设置得更接近预期的响应大小,可以更有效地利用Token限制。
此外,对于不需要即时响应的场景,我们可以考虑使用 Batch API(批处理),这可以更有效地处理大量请求而不影响同步请求的速率限制。
对于需要同步响应的情况,可以考虑将多个任务打包成一个请求。这种方法可以在不超过请求数限制的情况下处理更多的Token,尤其是在使用较小模型时效果显著。
总结时刻
今天我们主要探讨了大模型的使用成本。过度地使用不仅成本高昂,还可能触及速率限制。要学会用最精简的方式去获取我们需要的信息,同时优化代码,减少不必要的LLM调用,提升整体效率。
如何从多个维度入手控制成本,也许应该从宏观的角度去思考这个问题。成本的背后,是资源的优化配置。要学会权衡性价比,在追求高质量输出的同时,灵活地选择不同的模型和策略。应该去尝试和对比不同的方案,找到最佳的平衡点。
在课程中,我基本上都是使用OpenAI的API来讨论的,而我这样选择是有原因的。因为OpenAI是大模型的领跑者、领头羊,它所提供的一系列解决方案最为完善,也最为标准。是很好的学习参考,那么,当你理解了它的一系列设计,知晓了最高配置模型的能力,再去学习国内的大模型API的调用,也就不难了。同时也就了解了国内模型和OpenAI之间的差距在哪里。
在国内大模型能力大幅上升,而价格大幅下降的今天,我们可以选择便宜的模型,甚至开源的模型来完成普通的任务,然后用推理能力更高的模型来解决关键任务。这是一个非常清晰而且实用的思路。
管理成本不仅仅是为了节约开支,更是为了让基于LLM的应用更加智能和可持续。这就需要我们在开发过程中时刻保持审慎和创新,在大语言模型的加持下,去探索实现更多可能性的道路。
思考题
- 本课示例中,我们估算出来了Prompt中的Token数,请你查看具体模型(比如GPT-3.5-Turbo)输入输出所能容纳的全部Token数,然后根据当前Prompt中的Token数,动态设置适宜的max_tokens参数。
示意:
# 调整max_tokens,确保总token数量不超过模型限制
max_response_tokens = min(max_tokens, model_max_tokens - num_prompt_tokens)
- OpenAI新进给出的 Batch API 以后台作业的形式提交需求,这可以显著的节约成本,并且避免速率限制。请你尝试使用这个功能。
- 在你的LLM应用程序中,尝试把任务难度分级,用廉价的模型解决简单任务,用复杂的模型解决需要复杂推理能力的任务(如Tool Calls)。
期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!