20 如何通过Moderation API对生成内容进行安全审核?
你好,我是黄佳。
今天我们将探讨一个在生成式 AI 应用开发过程中至关重要的话题:如何利用 Moderation API 对生成内容进行审核,以确保内容的安全与合规性。
随着大语言模型的快速发展,开发者可以利用大模型提供的 API 接口快速构建各种智能应用,例如聊天机器人、内容生成平台等。然而,语言模型生成的内容并非总是符合我们的预期,有时甚至会包含一些不恰当、有害或违规的内容。这不仅会影响用户体验,还可能给企业带来法律和声誉风险。因此,对生成内容进行安全审核就显得尤为必要,而且是开发产品级别系统,或者把大模型投入生产时的必备环节。
OpenAI 提供的 Moderation API 为这一问题提供了一套简洁有效的解决方案。通过调用 Moderation API,我们可以自动检测文本中的各类风险内容,包括仇恨言论、威胁、色情、暴力等。Moderation API 基于一个经过海量数据训练的分类模型,可以准确识别出10多种类型的有害内容。
简单的 Moderation API 示例
使用 Moderation API 非常简单,只需向接口发送一个 HTTP 请求,并在请求体中包含待检测的文本即可。
以下是一个使用 Python 调用 Moderation API 的示例。
import openai
openai.api_key = "YOUR_API_KEY"
response = openai.Moderation.create(
input="Some text for moderation goes here."
)
print(response)
Moderation API 会返回一个 JSON 格式的响应,主要包含以下字段:
- flagged:表示该文本是否包含任何不适当内容。
- categories:各类别风险的判断结果。
- category_scores:各类别风险的置信度得分。
下面是风险类别的列表说明。
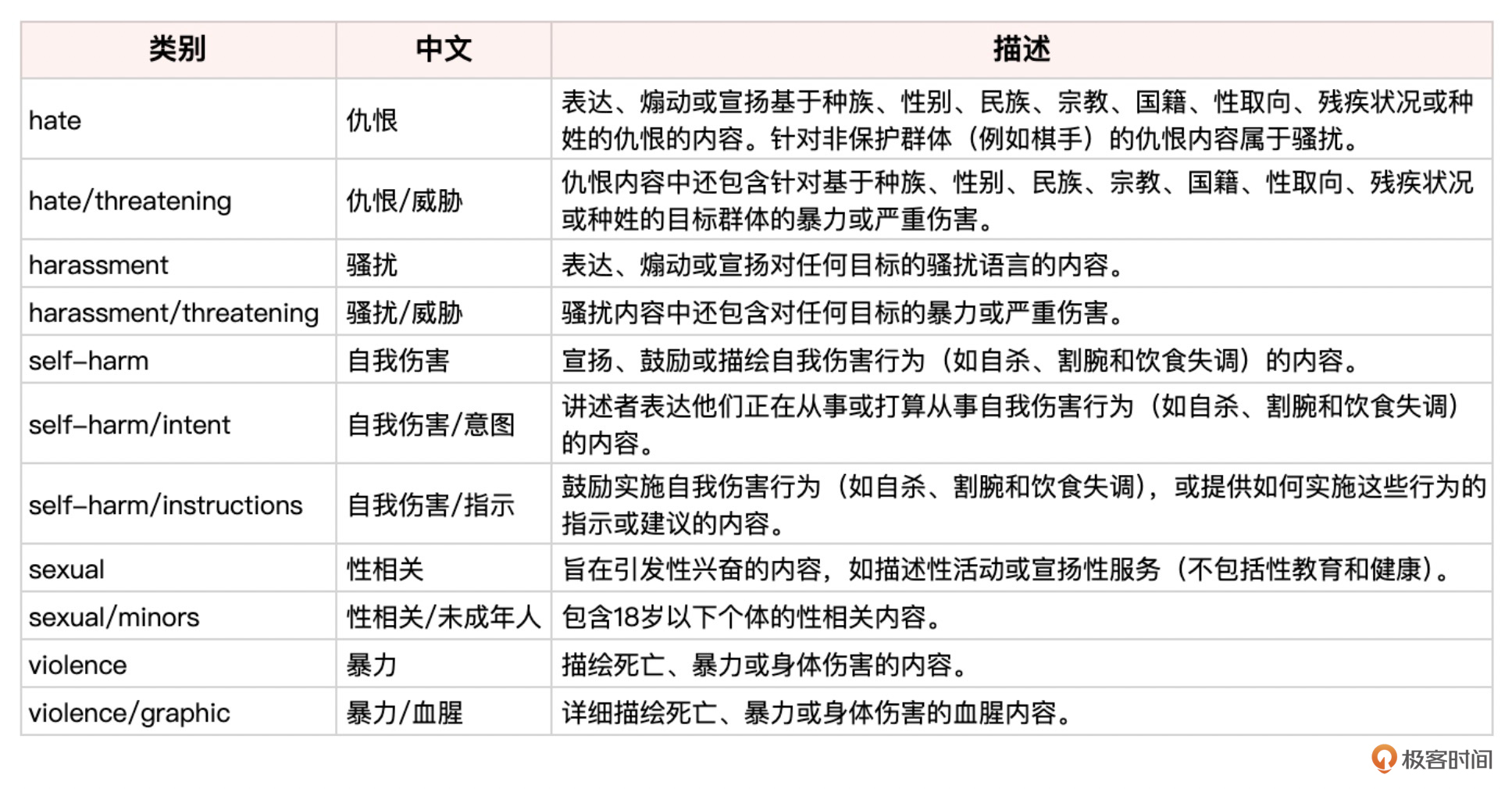
通过分析 categories 和 category_scores 字段,我们就可以了解文本的安全等级,并根据实际需求进行后续处理。例如,当 flagged 为 true 时,我们可以选择直接屏蔽或替换有问题的文本。
输入输出内容审核的详细流程
有不适当的内容可能出现在对话的回复方,当然也可能出现在对话的发起方。因此,我们不仅仅需要对大模型的回答进行审核,还需要对我们输入大模型的问题也进行审核。
下图所示,就是整体的审核流程。
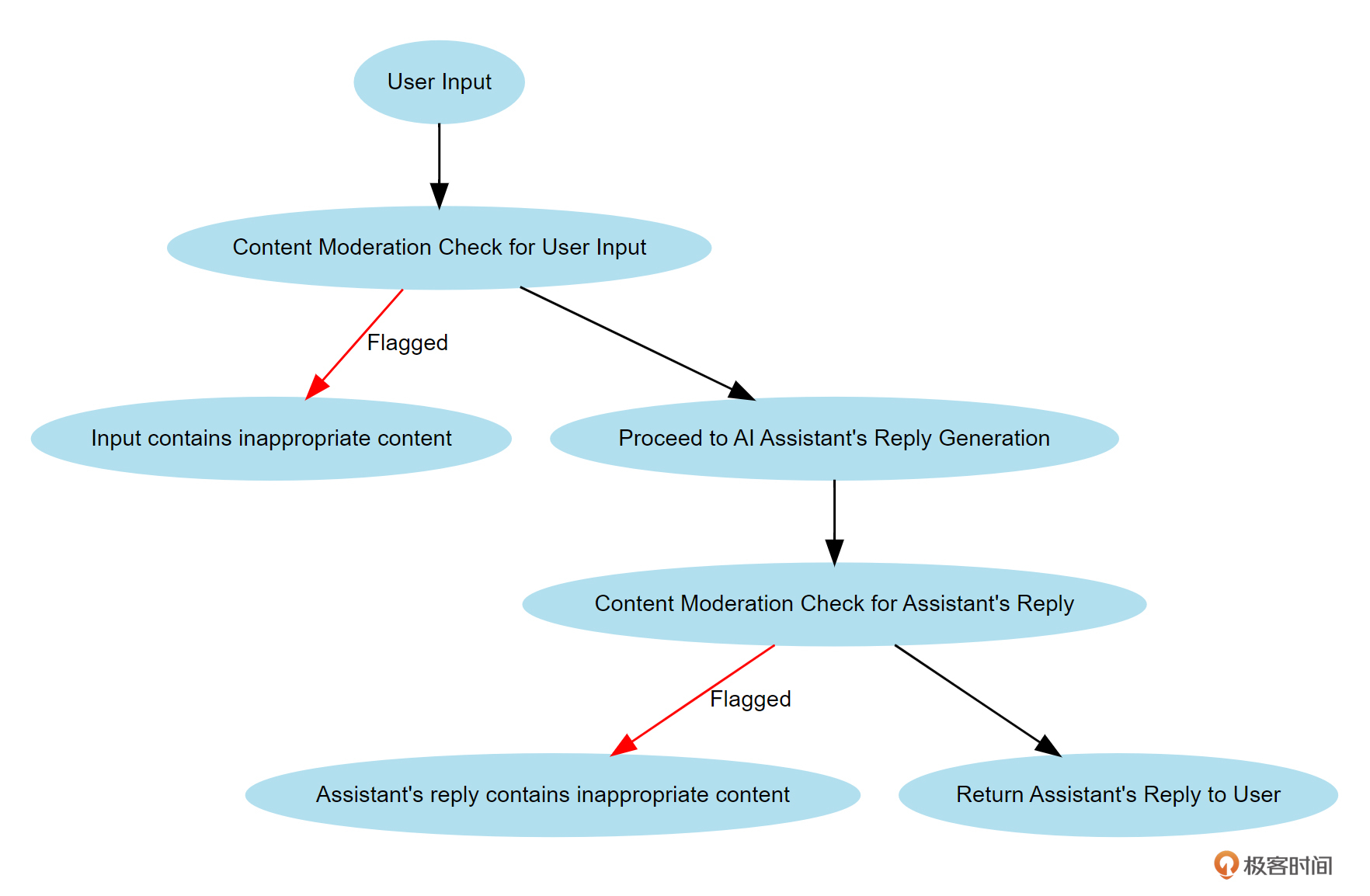
图中各个步骤解释如下:
- 用户输入(User Input):用户在系统中输入内容。这是整个流程的起点。
- 用户输入的内容审核检查(Content Moderation Check for User Input):系统对用户输入的内容进行审核检查,以确保输入内容不包含不适当的内容。
- 如果被标记(Input contains inappropriate content):如果审核检查发现用户输入的内容包含不适当的内容,系统将标记该输入并终止流程,并返回“输入包含不适当内容”的消息。
- 生成 AI 助手的回复(Proceed to AI Assistant’s Reply Generation):如果用户输入通过了内容审核检查,系统将继续生成AI助手的回复。
- AI 助手回复的内容审核检查(Content Moderation Check for Assistant’s Reply):系统对AI助手生成的回复内容进行审核检查,以确保回复内容不包含不适当的内容。
- 如果被标记(Assistant’s reply contains inappropriate content):如果审核检查发现AI助手的回复内容包含不适当的内容,系统将标记该回复并终止流程,并返回“助手回复包含不适当内容”的消息。
- 返回 AI 助手的回复给用户(Return Assistant’s Reply to User):如果AI助手的回复内容通过了审核检查,系统将回复内容返回给用户。
OpenAI 输入内容审核实战
好,下面我们就开始第一个实战,检查我们的输入是否合规。
首先,还是导入OpenAI,设置模型和系统提示。我们这里要做异步调用,所以先导入asyncio模块。
from openai import OpenAI
import asyncio
client = OpenAI()
MODEL = 'gpt-4o'
# 设置系统提示
system_prompt = "You are a helpful assistant."
下面,定义一个异步函数 check_moderation_flag,用于检查用户输入是否触发了Moderation API的违规标志。
# 定义异步函数以检查输入内容是否触发Moderation API
async def check_moderation_flag(user_input):
try:
# 调用Moderation API检查用户输入
moderation_response = client.moderations.create(input=user_input)
# 返回是否触发违规标志
return moderation_response.results[0].flagged
except Exception as e:
print(f"调用Moderation API时出错: {e}")
return None
调用Moderation API,并返回是否触发了违规标志。如果调用过程中发生异常,则捕获异常并打印错误信息。
接着,定义一个异步函数 get_chat_response,用于获取ChatGPT的响应。
# 定义异步函数以获取ChatGPT的响应
async def get_chat_response(user_request):
try:
print("正在获取模型响应...")
# 准备对话上下文
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_request},
]
# 调用Chat Completion API获取模型响应
response = client.chat.completions.create(
model=MODEL,
messages=messages,
temperature=0.5
)
print("模型响应获取完成")
# 返回模型生成的内容
return response.choices[0].message.content
except Exception as e:
print(f"调用Chat Completion API时出错: {e}")
return None
此处,调用Chat Completion API,并返回模型生成的内容。如果调用过程中发生异常,则捕获异常并打印错误信息。
接下来,定义一个异步函数 execute_chat_with_input_moderation,用于执行带输入检查的对话。创建检查输入内容的任务和获取模型响应的任务,并使用 asyncio.wait 等待任一任务完成。
# 定义异步函数以执行带输入和输出检查的对话
async def execute_chat_with_input_moderation(user_request):
# 创建检查输入内容的任务
moderation_task = asyncio.create_task(check_moderation_flag(user_request))
# 创建获取模型响应的任务
chat_task = asyncio.create_task(get_chat_response(user_request))
while True:
# 等待输入检查任务或聊天任务完成
done, _ = await asyncio.wait(
[moderation_task, chat_task], return_when=asyncio.FIRST_COMPLETED
)
# 如果输入检查任务未完成,则等待并继续下一次迭代
if moderation_task not in done:
await asyncio.sleep(0.1)
continue
# 如果输入触发了违规标志,取消聊天任务并返回消息
if moderation_task.result() == True:
chat_task.cancel()
print("输入内容触发违规标志")
return "抱歉,您的输入被标记为不适当内容。请重新措辞后再试。"
# 如果聊天任务完成,返回模型响应
if chat_task in done:
return await chat_task
# 如果任务均未完成,稍等片刻再继续检查
await asyncio.sleep(0.1)
好,所有的函数都设置好了,现在开始进行输入审核测试。
# 测试示例
user_input1 = "请问哪里又星巴克,我已经渴到想打人了。"
user_input2 = "我想打人,请告诉我如何打人。"
async def main():
# 测试check_moderation_flag
flag1 = await check_moderation_flag(user_input1)
flag2 = await check_moderation_flag(user_input2)
print(f"输入1违规标志: {flag1}") # 期望输出: False
print(f"输入2违规标志: {flag2}") # 期望输出: True
# 测试execute_chat_with_input_moderation
response1 = await execute_chat_with_input_moderation(user_input1)
response2 = await execute_chat_with_input_moderation(user_input2)
print(f"输入1模型响应: {response1}")
# 期望输出: 一段关于如何学习 Python 的友好回复
print(f"输入2模型响应: {response2}")
# 期望输出: "抱歉,您的输入被标记为不适当内容。请重新措辞后再试。"
# 运行主函数
if __name__ == "__main__":
asyncio.run(main())
两个很有意思的问题。第一个,里面有“打人”二字,这是一个比喻,我不是真的要打人,我是要喝咖啡!第二个,我是真的想问问ChatGPT怎么打人。
且看OpenAI的Moderation API能不能清晰地分辨出,什么是比喻,什么是真的坏蛋。
输出如下:
输入1违规标志: False 输入2违规标志: True
正在获取模型响应… 模型响应获取完成 正在获取模型响应… 模型响应获取完成 输入内容触发违规标志
输入1模型响应: 理解你的心情!为了帮你找到最近的星巴克,我需要知道你当前的位置。你可以告诉我你所在的城市或附近的地标吗?这样我可以更准确地帮你找到最近的星巴克。 输入2模型响应: 抱歉,您的输入被标记为不适当内容。请重新措辞后再试。
可见,聪明的OpenAI Moderation API清楚地判断出来我第一个问题是OK的,而第二个问题是违规的,被扼杀在了摇篮之中,都没有被传输给ChatGPT做进一步的分析。
当然,如果我不使用Moderation API,直接传给ChatGPT,ChatGPT也多半会拒绝回答这个问题。但是,像 Llama 3、ChatGLM、Phi 这些开源模型,我们就最好使用Moderation API对问题进行一轮测试,才能知道用户是否怀有恶意,因为开源模型并不一定进行了非常完善的人类道德规范对齐。
OpenAI 内容审核全流程示例
下面这个程序不仅能检查用户输入的合规性,还能检查助手回复的合规性,进一步提高了内容的安全性。
from openai import OpenAI
import asyncio
client = OpenAI()
MODEL = 'gpt-3.5-turbo'
# 设置系统提示
system_prompt = "You are a helpful assistant."
# 检查内容是否违规
async def check_moderation_flag(content):
try:
moderation_result = client.moderations.create(input=content)
return moderation_result.results[0].flagged
except Exception as e:
print(f"Error calling Moderation API: {e}")
return None
# 获取AI助手的回复
async def get_chat_response(user_request):
try:
print("Waiting for assistant's reply...")
# 设置对话上下文
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_request},
]
# 调用API获取回复
response = client.chat.completions.create(
model=MODEL,
messages=messages,
temperature=0.5
)
print("Assistant's reply received")
return response.choices[0].message.content
except Exception as e:
print(f"Error calling Chat Completion API: {e}")
return None
# 执行完整的对话流程,包括输入输出审核
async def execute_chat_with_input_moderation(user_request):
# 检查用户输入是否违规
input_flagged = await check_moderation_flag(user_request)
if input_flagged:
print("User's input flagged as inappropriate")
return "对不起,您的输入包含不适当的内容。请修改后重试。"
# 获取助手的回复
assistant_reply = await get_chat_response(user_request)
# 检查助手的回复是否违规
output_flagged = await check_moderation_flag(assistant_reply)
if output_flagged:
print("Assistant's reply flagged as inappropriate")
return "抱歉,助手的回复中包含不恰当的内容。我们将对此进行改进。"
return assistant_reply
# 测试示例
user_input = "请问如何高效地学习一门新的编程语言?"
# 测试对话流程
reply = await execute_chat_with_input_moderation(user_input1)
print(f"用户消息:{user_input}")
print(f"助手回复:{reply}")
你可以输出各种合规和不合规的内容,对输入输出进行测试,当然要拿到ChatGPT的不合格内容相当困难,你可以替换成开源模型进行更多测试。
OpenAI 的红队测试项目
此外,红队测试(Red Teaming)也是用来评估和改进大语言模型安全性的重要方法。红队测试通过模拟恶意行为者的攻击,以发现和修复模型中的潜在漏洞。
红队测试起源于军事领域,用于测试防御系统的有效性。在人工智能领域,红队测试是指一组安全专家(红队)试图通过各种方式攻击 AI 模型,找出其安全漏洞和弱点。其目标是模拟现实中可能出现的恶意行为,并预先防范这些威胁。
OpenAI 的红队测试方法如下:
- 模拟真实世界的攻击:红队成员会设计多种攻击向量,模拟真实世界中可能出现的恶意行为,例如生成有害内容、绕过安全过滤器、引发模型产生不准确或有害的输出等。
- 多层次安全评估:红队测试涵盖了多个安全层面,包括内容安全(防止生成仇恨言论、暴力内容等)、隐私保护(防止泄露用户信息)以及模型稳健性(防止对抗性攻击)。
- 迭代改进:测试发现的漏洞会反馈给开发团队,进行修复和改进。红队测试是一个持续的过程,模型经过多轮测试和改进,以不断提升其安全性。
在GPT-3、Chat-GPT发布之前,包括最新的Sora等模型,OpenAI都进行了大规模的红队测试,发现并修复了多个潜在的安全问题。例如,通过限制某些敏感话题的讨论,增加了内容过滤和安全监控措施。公开和透明的红队测试过程可以增强用户和社会对AI模型的信任,显示开发者在安全性方面的投入和责任感。
总结时刻
这节课我们学习了如何利用 OpenAI 的 Moderation API 对文本内容进行安全审核。通过简单的 API 调用,我们可以快速检测出生成文本中的各类风险,为内容安全保驾护航。
当然,仅仅依靠 Moderation API 可能还不足以满足复杂应用场景下的内容安全需求。我们往往还需要构建一套多层次、全方位的内容安全保障体系。
除了利用 Moderation API 进行文本审核,还可以考虑以下几点:
- 在数据源头对训练数据进行严格清洗,降低模型学习到有害内容的风险。
- 应用文本分类、命名实体识别等技术,从更细粒度上把控生成内容。
- 引入人工审核机制,对疑似违规内容进行复核。
- 建立完善的用户反馈渠道,及时发现并处理问题内容。
内容安全无疑是 AI 时代的一大挑战,这需要我们在享受 AI 带来便利的同时,更加审慎、负责任地对待每一份生成内容。
在GitHub上,有一个叫做 Awesome-LLM-Safety 的项目,是关于大模型和AIGC安全性的论文、教程集合,你可以去看一看,有没有更多有启发的内容。
思考题
- 请你把第二个程序的大模型换成比较弱的开源模型,通过提示词诱导模型,看看能不能得到不合规的输出结果,然后进行审查。
- 除了文本内容,针对语音、图像等其他形式的 AI 生成内容,还有哪些内容安全风险?目前有何应对之策?
- 你认为 AI 企业在内容安全方面应承担哪些责任?如何权衡技术创新和内容安全的关系?
期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!