19 Sora模型的原理和架构初探
你好,我是黄佳。
非常开心,我们进入了多模态章节的最后一节课,Sora。而这节课,也许将是唯一一节没有代码实操的课程,因为Sora这个模型还没有给出任何API调用的接口,也没有任何详细的技术细节公开发表。
不过,这并不影响Sora发布之后给全世界带来的震撼。Sora发布极大地刺激了文生视频(Text-to-Video)整个行业所受到的关注度,也刺激了其他多个文生视频模型的快速迭代。目前各大科技公司、初创公司和研究机构都在这个新赛道发力——从文本生成视频。今年以来,OpenAI、Google等巨头以及我国的爱诗和快手都推出了自己的视频生成模型,释放了巨大的应用潜力和想象力。
那么,在具体介绍Sora技术之前,让我们一起来回顾一下AIGC技术(人工智能生成内容)从起步初期到Sora视频生成的前世今生。
AIGC 的前世今生
作为深度学习辉煌时代的亲历者和见证者,我们非常有幸亲眼见证了AIGC的爆发全过程。
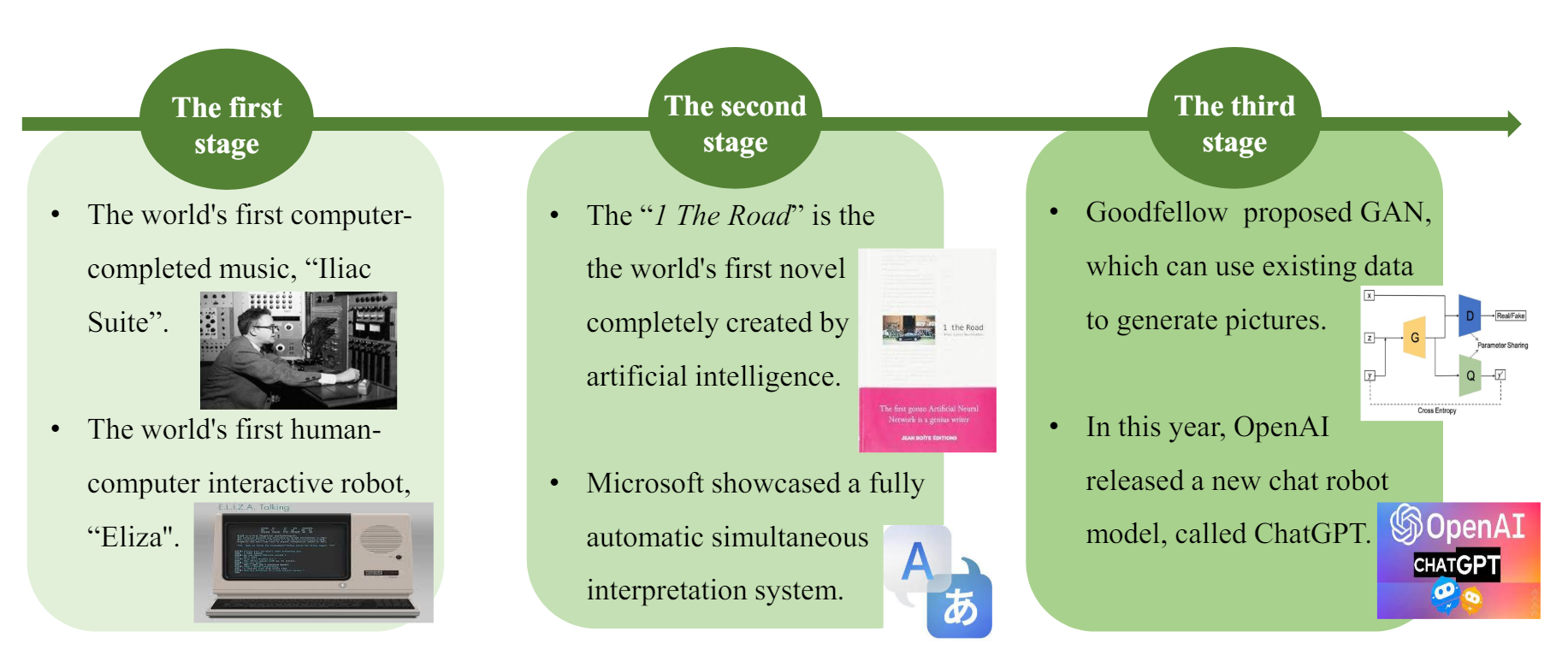
这张论文中截取的综述图片就展示了AIGC从技术实验到应用实践的发展历程。它把AIGC分为三个主要时间段,每个时间段都有一些代表性事件和发展特点。
早期探索阶段(20世纪50年代至90年代中期)
众所周知,1950年,艾伦·图灵提出“图灵测试”,探讨机器是否能表现出类似人类的智能行为。1957年,计算机科学家John McCarthy提出“人工智能”一词,标志着人工智能研究的正式开始。
在这个早期探索阶段受限于科技水平,AIGC仅用于少数场景,比如说有科学家创作出来了世界上第一个计算机合成音乐 “Lliac Suite”,同时 1960 年首个聊天机器人ELIZA问世,能模拟人类对话。
深度学习萌芽阶段(90年代中期至21世纪初期)
在这个时期,深度学习继续发展,但不受人瞩目,80年代中期 IBM推出Deep Blue,首次击败人类国际象棋冠军。然而这个AI并不是基于深度学习架构构建的。
此时的AIGC从实验性应用转向商用,但受限于计算资源,无法直接进行内容生成。但AIGC整个领域仍有进展,代表性的事件有1997年世界第一部完全由人工智能创作的小说《1 The Road》问世。在2012年微软发布第一个能用多种语言进行实时翻译的聊天机器人,标志着语言生成技术的进步。
快速发展阶段(2014年至今)
2014年开始,深度学习突然爆发,2014年 Ian Goodfellow 提出生成对抗网络(GAN),开启了生成模型的新篇章。2015年,谷歌DeepMind开发出能够击败人类围棋冠军的AlphaGo,展示了深度学习的强大潜力。
此后,深度学习迅速发展,人工智能生成内容百花齐放,娱乐和通信领域逐渐深入影响,AIGC新思路、新产品层出不穷。典型事件包括:
- 2018年,英伟达发布StyleGAN,用于生成高质量的虚拟人脸图像。
- 2019年,DeepMind开发DVD-GAN,实现高质量的视频生成。
- 2020年,Jonathan Ho提出DPM(扩散概率模型),进一步提升生成图像的质量。
- 2021年,OpenAI发布DALL-E,能够根据文本生成图像,应用于艺术创作和设计领域。
- 2022年,ChatGPT登场,石破天惊。
- 2023年,Stable Diffusion、Midjourney纷纷在图像生成方面出现显著突破,Runway发布专用于视频生成的模型,推动生成内容在影视制作中的应用。
- 2024年,OpenAI推出Sora,而且与NVIDIA合作,推出高效的生成模型加速器,进一步提升生成内容的效率和质量。
上述重要技术进展和应用案例,展示了AIGC技术从实验阶段逐步走向实际应用的过程。
从 GAN 到扩散模型
生成对抗网络(GAN)是扩散模型出现之前,AIGC领域最具代表性的模型之一。GAN由两个神经网络组成:生成器和判别器,两者在训练过程中互相博弈。生成器试图生成以假乱真的样本,而判别器则要判断样本是真是假。经过多轮对抗,生成器最终能生成高质量的逼真样本。GAN的提出极大地推动了图像生成技术的发展,也掀起了新一轮AI的话题和热潮。

然而,GAN也存在一些局限性,如训练不稳定,容易出现模式崩溃等问题。近两年,扩散模型作为一种新的生成模型范式脱颖而出。与GAN不同,扩散模型将数据分布看作一个不断被高斯噪声扩散的过程。训练时,模型学习逆转这个过程,从噪声中逐步去噪,恢复出干净的数据。扩散模型生成高质量样本的同时,还具有较强的稳定性和灵活性。扩散模型已经在图像、视频、音频等多个领域取得了瞩目的表现。
OpenAI 的 Sora:站在巨人肩上
OpenAI在今年发布了Sora,这是一个强大的文本-视频生成模型,展现了惊人的语言理解和视频合成能力。Sora可以理解自然语言,根据文本提示生成最长1分钟的高清视频。和普通的视频生成模型不同,Sora 表现出了一些新颖的能力,比如保持场景和物体的时空连贯性,模拟人物与环境的简单交互,以及渲染如 Minecraft 这样的数字世界。OpenAI 认为,Sora 是迈向通用目的的物理世界模拟器的重要一步。未来 Sora 有望应用于内容创作、游戏开发等领域。
传统的扩散模型通常使用U-Net作为骨干网,但在相关论文《Scalable Diffusion Models with Transformers》中,提出了Diffusion Transformer(DiT)架构,这是一种基于Transformer架构的扩散模型,将U-Net替换为Transformer。
Transformer架构:另一方面,Sora还整合了Transformer技术,该技术最初是为处理序列数据,特别是自然语言而设计。Transformer的自注意力机制使得模型能够考虑输入序列中各个部分的关系,非常适合于建模元素之间的长距离依赖关系。在Sora中,使用Transformer处理的不仅是文字,还包括将视觉数据(如时空patch)视为类似于语言中的Token,从而实现对复杂视觉内容的高效处理。
Sora采用了Diffusion Transformer(DiT)架构,通过将图像和不同时长、分辨率的视频统一表示为patch,再用Transformer架构进行建模,因此能够灵活处理不同的视觉数据。Sora通过从充满视觉噪声的帧开始,逐步细化和去噪,最终生成与文本指令紧密相关的视频内容。这种方法使Sora能够处理包括图像和视频在内的各种视觉数据,这些数据首先被压缩到一个较低维的隐空间,然后被分解成一系列时空patch作为Transformer模型的输入,使得Sora能够灵活处理不同时长、分辨率和宽高比的视频和图像。
在训练阶段,Sora接受添加了高斯噪声的patch;在推理阶段,输入的是符合高斯分布的随机噪声patch和特定的文本条件,通过迭代去噪过程生成视频。这种方法不仅提高了视频内容的生成质量,还允许模型并行处理连续视频帧,而非逐帧生成,从而生成时间上连贯的长视频。此外,Sora在训练时使用了包含多种长度和分辨率的视频数据,进一步增强了模型对不同视频格式的适应性。
综上,Sora的设计哲学和实现细节展示了其在视频生成技术中的前沿地位,特别是在处理多模态数据和生成复杂视频内容方面的能力。这些技术的结合不仅推动了从静态图像生成到动态视频生成的转变,也为未来的视频生成技术发展提供了重要的参考。
视频生成实战
我所理解的Sora技术内核就解释到这里。和ChatGPT一样,OpenAI并不公布其旗舰商业模型的任何过多细节,无论是模型架构,还是训练过程,我们只能从他发布的网页文章的一鳞半爪中捕捉一点蛛丝马迹。
好在我们还有一些其他的视频模型可用,这里,我还是忍耐不住给你分享一些我的视频生成的粗浅尝试。
这里我还是使用Stability AI平台提供的API(如果你充值麻烦,看看就好,不必真的花钱去尝试),来进行从图到视频的转换。
首先还是加载环境变量和密钥。
import os
from dotenv import load_dotenv
# 加载 .env 文件中的环境变量
load_dotenv()
# 从环境变量中获取 API 密钥
STABILITY_API_KEY = os.getenv("STABILITY_API_KEY")
然后我们用stable-image/generate/sd3这个最新的API来通过文本描述生成高质量图像。这个API利用了Stability AI的Stable Diffusion模型的能力,能生成很有创意和艺术张力的图像。
import requests
from IPython.display import Image
response = requests.post(
f"https://api.stability.ai/v2beta/stable-image/generate/sd3",
headers={
"authorization": f"Bearer {STABILITY_API_KEY}",
"accept": "image/*"
},
files={"none": ''},
data={
"prompt": "Looking up at the starry sky, humans are small, the universe is vast.",
"output_format": "jpeg",
},
)
if response.status_code == 200:
display(Image(response.content))
else:
print(f"Error: {response.status_code}")
print(response.json())
我得到了一张美图,Nice!

这个API允许开发者将静态图片转换成视频。通过在静态图像中添加动态和运动效果,有效地将其转化为短视频。这在需要从静态图像生成动态内容的场景中非常有用,例如广告制作或社交媒体内容创建。
import requests
from PIL import Image
from pathlib import Path
from time import sleep
# 定义之前生成的图像文件路径
image_path = Path("./humansmall.jpeg")
# 检查图像文件是否存在
if image_path.exists():
# 打开图像文件并调整尺寸
with Image.open(image_path) as img:
img = img.resize((1024, 576)) # 调整为1024x576的尺寸
# 将调整后的图像保存到内存中
from io import BytesIO
buf = BytesIO()
img.save(buf, format='JPEG')
buf.seek(0)
# 使用调整后的图像进行视频生成
response = requests.post(
f"https://api.stability.ai/v2beta/image-to-video",
headers={
"authorization": f"Bearer {STABILITY_API_KEY}"
},
files={
"image": buf
},
data={
"seed": 0,
"cfg_scale": 1.8,
"motion_bucket_id": 127
},
)
# 检查API响应
if response.status_code == 200:
generation_id = response.json()['id']
print(f"视频生成已启动,生成ID: {generation_id}")
# 循环查询视频生成结果
while True:
response = requests.request(
"GET",
f"https://api.stability.ai/v2beta/image-to-video/result/{generation_id}",
headers={
'accept': "video/*",
'authorization': f"Bearer {STABILITY_API_KEY}"
},
)
if response.status_code == 202:
print("视频生成中,10秒后再次查询...")
sleep(10)
elif response.status_code == 200:
print("视频生成完成!")
# 将生成的视频保存到本地文件
video_path = Path("./generated_video.mp4")
with open(video_path, 'wb') as file:
file.write(response.content)
break
else:
raise Exception(str(response.json()))
else:
print(f"视频生成失败。错误信息: {response.json()}")
else:
print(f"图像文件 {image_path} 不存在。请先生成并保存图像。")
运行代码后,一个4秒钟的高质量MP4视频出现在本地目录。
视频生成已启动,生成ID: 352cc9b16d79e5fd8be8cfc00ff717d468ec298e470dd75a0a5878ee2fb04416
视频生成中,10秒后再次查询...
视频生成中,10秒后再次查询...
视频生成中,10秒后再次查询...
视频生成完成!
在广袤的天幕下,一个背影望向苍茫的宇宙。星空开始轮转,运动。
总结时刻
这节课我们对AIGC的过去和现在进行了一个简短的综述,而Sora的推出,标志着继图像生成之后,视频生成模型正在进入一个新的发展阶段。
从技术源流的角度来看,Sora和扩散模型和我们耳熟能详的Transformer两大突破性技术相关。它结合了扩散模型和Transformer技术,以高效处理多种视觉数据,并在视频生成领域实现了显著的创新。
随着模型规模的持续扩大,视频生成模型有望成为“通用目的的物理世界模拟器”。这在Sora身上已初见端倪。Sora可以较好地保持生成视频的时空连贯性,使物体的运动轨迹符合常识;Sora 还能模拟人物与环境的简单交互,如绘画时画笔接触画布会留下痕迹等。
视频生成模型作为world simulator的雏形,为多个领域的应用打开了想象空间,如虚拟助手、游戏设计、视频内容创作等。展望未来,随着多模态学习的进一步发展,视频感知、理解、生成一体化的智能系统将为人类社会带来深远影响。让我们翘首以待人工智能新时代的到来!
思考题
AIGC的发展也带来了很多值得思考的问题。
- 如何权衡AIGC内容的真实性与创造性?模型生成的内容是否应该标注为“AI生成”?
- AIGC是否会对某些创意行业带来冲击?如何看待人工智能与人类创作的关系?
- 如何规范和引导AIGC技术的发展,避免其被滥用或产生负面影响?
- AIGC未来在教育、医疗、设计等领域还有哪些应用前景?如何实现AIGC的普惠化?
这些问题值得我们在推动AIGC发展的同时予以审慎思考。只有在技术创新与社会责任之间找到平衡,AIGC才能真正惠及全人类。
这节课的思考题没有标准答案,期待你畅所欲言,我们下节课再见!
- Ethan New 👍(0) 💬(0)
老师,AIGC 三个发展阶段的论文综述能否发下?
2024-07-02