17 GPT 4o最强多模态模型实战
你好,我是黄佳。
2024年5月,又一个重磅炸弹从天而降。OpenAI隆重推出了新的旗舰模型GPT-4o,这个模型不仅更加强大,更加聪明,而且它的API还比老一代的GPT-4-Turbo更便宜。它最惊艳的特性就是多模态能力,尤其是在语音方面,它拥有把握人类语音中情感信息的能力(比如说仅通过语气发现你在和ChatGPT4对话时候是否焦躁、伤心、紧张、疲惫等),因此它能够更完美地实时处理音频、视觉和文本的推理。
下面的几张图片,是我在ChatGPT App中和GPT对话的过程,惊喜地发现,GPT-4o模型也即将在App中上线了。

当GPT-4o的新语音识别功能上线之后,ChatGPT将能够从我的语气中推知我当前的情绪和情感。

好,下面我们就来详细介绍下GPT-4o的多模态能力,并说说它能够为我们的AI应用带来哪些方面的新拓展。
GPT-4o 的关键特性
GPT-4o中的 “o”,英文是omni。它是一个来自拉丁语的前缀,意思是“全部”、“所有”或“全能”。人如其名,这一款模型旨在实现更加自然的人机交互,可以接受文本、音频、图像和视频的输入,并生成文本、音频和图像的输出。
能力碾压
上一课已经提到,GPT-4o的英文文本和编码任务性能与GPT-4 Turbo相匹配,同时在非英语语言的性能上有显著提升。它速度更快,成本降低50%。因为,之前的GPT-4V版本已经拥有了读图能力,因此GPT-4o的核心能力增强主要是在音频方面,平均响应时间为320毫秒,与人类对话速度非常接近。
在GPT-4o之前的GPT模型已经可以让人类通过语音模式与ChatGPT对话,平均延迟为2.8秒(GPT-3.5)和5.4秒(GPT-4)。为了实现这一点,ChatGPT的语音模式使用了三个独立的模型:一个简单的模型将音频转录为文本,GPT-3.5或GPT-4接收文本并输出文本,第三个简单的模型将文本转换回音频。但是,这样的过程导致主要的智能来源GPT-4失去了大量信息——它无法直接观察语气、多说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
通过GPT-4o,OpenAI训练了一个全新的端到端模型来处理文本、视觉和音频,这意味着所有的输入和输出都由同一个神经网络处理。GPT-4o是OpenAI的第一个结合所有这些模态的模型,其能力立即就碾压了某大厂前两个月所推出的“多模态一体化模型”——对,我说的就是Google和Gemini。(当然,目前最新的Claude-3.5似乎很多方面能力又超越了GPT-4o)
模型评估
在传统基准测试中,GPT-4o在文本、推理和编码智能方面达到了与GPT-4 Turbo相同的性能,同时在多语言、音频和视觉能力方面设定了新的高标。
- 文本评估:GPT-4o在零样本链式推理(COT)MMLU(通用知识问题)中创下了88.7%的新高分。在传统的五样本无链式推理(COT)MMLU中,GPT-4o创下了87.2%的新高分。
- 音频 ASR 性能:GPT-4o显著提高了对Whisper-v3的语音识别性能,特别是在资源较少的语言方面。
- 音频翻译性能:GPT-4o在MLS基准测试中超越了Whisper-v3。
- 多语言视觉推理评估:M3Exam基准测试包括各个国家标准化测试的多项选择题(包含图表和图形)。在这个测试中,GPT-4o在所有语言上都比GPT-4表现更强。
- 视觉理解评估:GPT-4o在零样本视觉感知基准测试中达到了行业最先进的性能,包括MMMU、MathVista和ChartQA的零样本链式推理。
作为开发者,目前我们也可以在API中访问GPT-4o的文本和视觉模型。并且,GPT-4o的速度是GPT-4 Turbo的两倍,价格是其一半,速率限制也只有之前的 5 倍。这对于开发者来说,无疑都是天大的好消息。在这个消息推出之后,国内大模型厂商就纷纷打起了API Token价格战,大模型变得越来越便宜,越来越接地气。大模型应用开发的节奏无疑是被OpenAI的最新模型驱动的,一波未平一波又起,一浪更比一浪高。当然,在一个浪接一个浪的汹涌大潮中,站在潮头的,总是OpenAI。
用 GPT-4o 一键解读视频
其实,OpenAI是计划在未来几周内逐步向一小群授信的合作伙伴推出GPT-4o的新音频和视频功能,也就是说,最新的GPT-4o音频和视频接口还没有完全成熟。不过,这打消不了我们希望用GPT-4o来尝试开发多模态应用的积极性。
下面,我们就来开始用GPT-4o进行视频解读的项目实战。
项目准备
先来为项目做准备,做视频处理,我们需要用到 FFmpeg 这款功能强大的开源多媒体处理工具。FFmpeg 用于处理音频、视频和其他多媒体文件,可以实现以下功能。
- 转码:将多媒体文件从一种格式转换为另一种格式,例如将视频从 MP4 转换为 AVI。
- 剪辑:从多媒体文件中提取片段或合并多个片段。
- 处理:调整视频的尺寸、比特率、帧率,或音频的采样率、声道数等。
- 添加效果:为视频添加滤镜、字幕、水印等。
- 流媒体:将多媒体文件实时传输到网络上。
如果你是用Windows开发应用程序,那么,在这里下载FFmpeg(或者访问 FFmpeg 官方下载页面)。找到 Windows 版本的 FFmpeg,并下载适合你系统的压缩包(通常是 ffmpeg-release-essentials.7z)。
将下载的压缩包解压到一个你方便访问的文件夹,然后添加 FFmpeg 到系统路径。
- 右键点击“此电脑”或“计算机”,选择“属性”。
- 选择“高级系统设置”。
- 在“系统属性”窗口中,点击“环境变量”。
- 在“系统变量”部分,找到并选中 “Path”,然后点击“编辑”。
- 点击“新建”,然后输入 C:\ffmpeg\bin(换成你的解压路径),点击“确定”。
- 关闭所有窗口,并重启命令提示符以应用更改。
如果你是用Linux,比如Ubuntu,那么直接安装即可。
除了FFmpeg 之外,还需要安装 opencv-python 和 moviepy。
几个音视频处理软件装好,准备工作就完成了!
处理视频
下面开始处理视频。这里准备了一段短视频,我想让GPT-4o对它进行解读和分析。
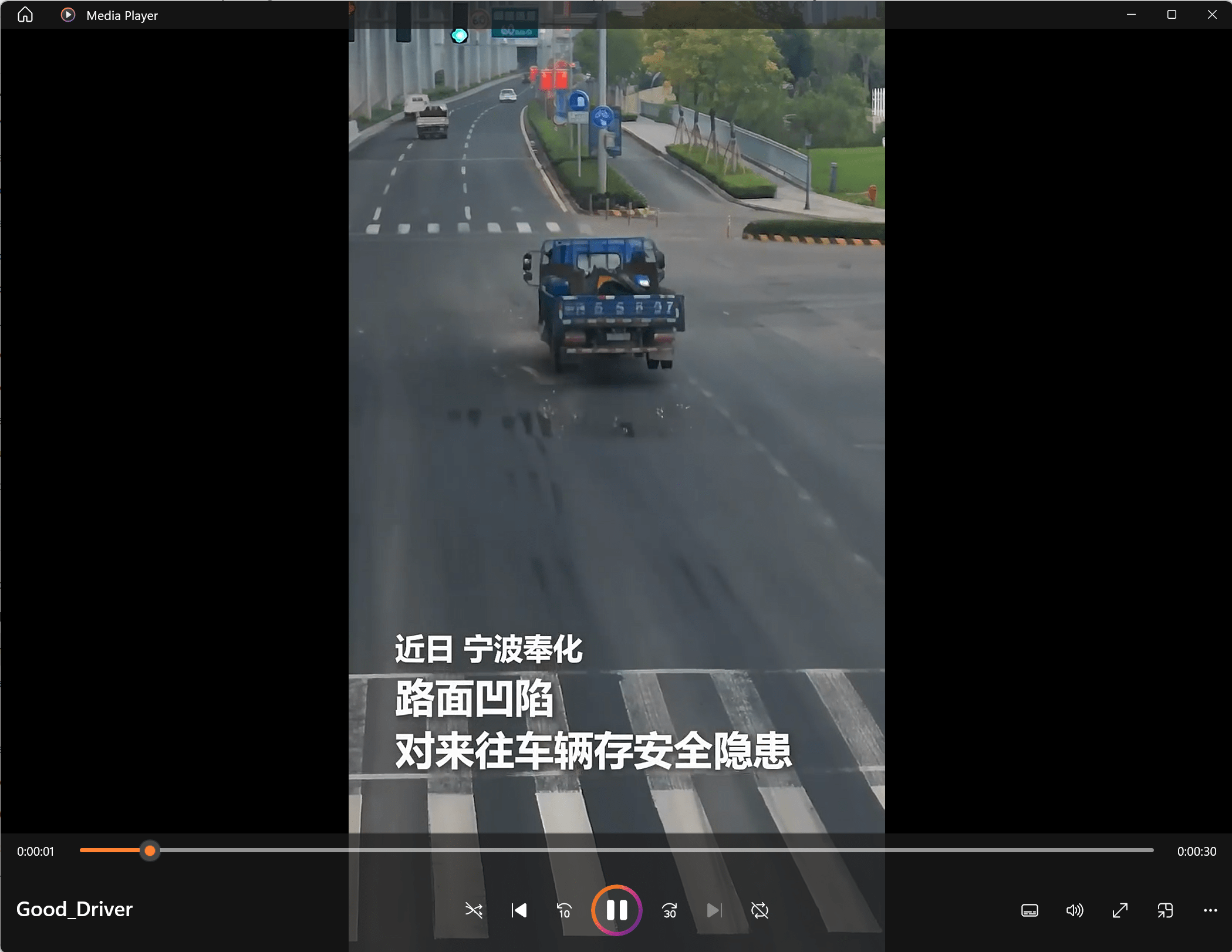
这段短视频是我从抖音下载下来的,描绘了一个卡车司机看到路面不平,进行了好人好事的行为。
视频需要先做一些预处理,代码如下:
# 导入所需的库
import os
import cv2 # 视频处理
import base64 # 编码帧
VIDEO_FILE = "Good_Driver.mp4"
def extract_frames(video_file, interval=2):
encoded_frames = []
file_name, _ = os.path.splitext(video_file)
video_capture = cv2.VideoCapture(video_file)
total_frame_count = int(video_capture.get(cv2.CAP_PROP_FRAME_COUNT))
frame_rate = video_capture.get(cv2.CAP_PROP_FPS)
frames_interval = int(frame_rate * interval)
current_frame = 0
# 循环遍历视频并以指定的采样率提取帧
while current_frame < total_frame_count - 1:
video_capture.set(cv2.CAP_PROP_POS_FRAMES, current_frame)
success, frame = video_capture.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
encoded_frames.append(base64.b64encode(buffer).decode("utf-8"))
current_frame += frames_interval
video_capture.release()
print(f"提取了 {len(encoded_frames)} 帧")
return encoded_frames
# 每2秒提取1帧(采样率)
encoded_frames = extract_frames(VIDEO_FILE, interval=2)
导入必要的模块,包括os用于路径操作,cv2用于视频处理,base64用于编码帧,以及moviepy.editor用于处理音频。函数extract_frames_and_audio,用于提取视频帧和音频。参数video_file为视频文件路径,interval为每提取一帧所间隔的秒数。使用OpenCV遍历视频并提取指定间隔的帧,将每个帧编码为Base64格式并存储在列表中。使用moviepy从视频中提取音频并保存为MP3文件。
用 GPT-4o 根据视频帧回答问题
下面的代码,我就调用了GPT-4o,并通过提示词让它对视频进行简单解读,并保存在Markdown格式的网页中。
# 创建OpenAI客户端
from openai import OpenAI
client = OpenAI()
# 使用GPT-4o模型生成视频介绍
response = client.chat.completions.create(
model='gpt-4o',
messages=[
{"role": "system", "content": "请用Markdown格式生成视频的介绍."},
{"role": "user", "content": [
"下面是视频的图像帧",
*map(lambda x: {"type": "image_url", "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, encoded_frames)
]},
],
temperature=0,
)
# 打印生成的Markdown格式介绍
print(response.choices[0].message.content)
输出如下:

我把输出拷贝到Markdown单元,可以看到良好的格式化。(图片链接目前无法显示,不过无伤大雅,我们完全可以在程序中,把视频截图和这个文字自动搭配起来)

下面,我接着问 GPT-4o 一些相关的问题,期望它能够根据视频的内容来做出准确的回答。
# 使用GPT-4o模型根据视频内容回答问题
QUESTION = "图中的人做了什么?"
qa_response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "请用Markdown格式根据视频内容回答问题."},
{"role": "user", "content": [
"下面是视频的图像帧.",
*map(lambda x: {"type": "image_url", "image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, encoded_frames),
QUESTION
],
}
],
temperature=0,
)
# 打印生成的Markdown格式问题回答
print(QUESTION + "\n" + qa_response.choices[0].message.content)
GPT-4o的回答如下:
图中的人做了什么?
图中的人发现路面有凹陷,可能会对来往车辆造成安全隐患。他停车后打开双闪灯,下车跑到路边拿起锥形桶,并将锥形桶放置在路面凹陷处,警示后方车辆。随后,他确认情况并报警,最后默默离开。当地公安找到他并表示感谢,还送了一个纪念品给他。
这个小例子至此结束,程序结构虽然简单,但这种强大的视频解读能力为我们带来很多想象的空间。
GPT-4o 开脑洞的种种应用
GPT-4o的超强逻辑分析能力、情绪感知能力,以及接收实时音视频输入的能力,为我们进一步开发新一代的AI应用打开了无数脑洞。
OpenAI官方就通过很多视频进行了模型能力的展示,这些视频各种各样,覆盖日常生活的各种场景,以及人类需求的方方面面,比如两个GPT-4o模型的互动与歌唱,比如帮助用户进行面试准备,比如和 Imran Khan(可汗学院创始人)进行数学对话,比如指点和学习西班牙语等等等等。
那么,顺着OpenAI的思路,我们还可以想象并设计出更多的可以落地的AI应用,我把这些应用列表如下。

上述各种应用,每一个想象空间都很大,咱们来细化一个帮助盲人游览巴黎的应用场景,并进行详细的描述。
- 实时描述环境:GPT-4o通过连接到盲人佩戴的摄像头,可以实时描述他们周围的环境。例如,当盲人走在巴黎的香榭丽舍大街时,GPT-4o可以通过耳机向他们描述街道上的建筑、商店和行人。
- 景点介绍:当盲人到达某个著名景点,如埃菲尔铁塔时,GPT-4o可以自动识别该景点,并开始讲解其历史和有趣的事实。这些信息可以通过自然语言生成功能,以生动的方式呈现出来,让盲人用户能够“看到”这些景点。
- 导航帮助:GPT-4o还可以提供导航帮助,引导盲人从一个地点到另一个地点。例如,盲人想要从卢浮宫前往塞纳河,GPT-4o可以通过GPS和实时视频分析,为他们提供详细的步行路线,并提醒他们前方的障碍物或台阶。
- 交互式问答:如果盲人对某个景点或某件艺术品有问题,他们可以直接问GPT-4o,系统会基于其庞大的知识库,提供准确且详细的回答。例如,“埃菲尔铁塔有多高?”或“蒙娜丽莎的背景是什么?”。
- 社交互动:在一些公共活动或聚会中,GPT-4o可以帮助盲人识别周围的人的面部表情和动作,帮助他们更好地参与社交活动。
这种应用不仅提高了盲人的生活质量,还让他们能够独立、安全地探索世界,享受旅行的乐趣。唉,其实说实在的,别说盲人了,即使是一个正常成人,如果我去巴黎,全身上下我挂几个手机,全方位打开ChatGPT和Camera,走到哪里,GPT-4o给我全景360度的建筑文化说明,自然历史讲解,交通情况提醒,我也会觉着自己不再是个傻宝宝了。
总结时刻
作为开发者和AI爱好者,我们正处在一个令人激动的时代。GPT-4o是OpenAI在深度学习领域推动能力和应用边界的最新一步,这次的方向是实用性和AI落地。
这节课我们全面了解了GPT-4o的强大功能及其在多模态AI应用开发中的巨大潜力,并通过实际操作体验了如何利用GPT-4o进行视频解读。
GPT-4o作为全新的端到端多模态模型,能够在极短的时间内处理多种模态输入和输出,使得人机交互更加自然和高效。尤其是在视频解读和音频分析方面,GPT-4o的表现令人印象深刻。例如,通过解读一段短视频,GPT-4o不仅能准确描述视频中的行为,还能基于视频内容回答相关问题。
GPT-4o的多模态能力为我们开发者提供了新的开发思路和工具,从实时环境描述、景点介绍、导航帮助到交互式问答和社交互动,GPT-4o都能提供强有力的支持。这不仅提高了用户体验,还为特殊人群提供了更多便利,为生活增添新的乐趣。我觉得,GPT-4o将为AI应用的开发带来革命性的变化,基于GPT-4o的AI应用将在各行各业得到广泛应用,并不断催生出更多创新的解决方案。
思考题
- 本课展示了GPT-4o在视频解读中的强大能力,你还能想到哪些领域可以利用GPT-4o的多模态能力进行创新开发?
- GPT-4o在视频解读中表现很优秀,如果将这项能力应用于智能监控系统中,你认为它还能实现哪些功能?
- GPT-4o能够实时分析和解读多模态数据,对于实时数据流(如实时语音对话)你认为可以开发出哪些实用的应用?
期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!
- qinsi 👍(1) 💬(0)
说是解读视频, 这里还是解读视频帧吧. 要用于监控的话对实时性要求比较高. 比如上一秒一个人还站着, 下一秒这个人倒在地上, 实时性不够就不知道中间发生了什么. 此外这个例子中的视频是带字幕的, 有没有可能GPT只是在读画面中的字幕呢? 因为这里看不到截取的视频帧长什么样...
2024-06-27 - qinsi 👍(0) 💬(0)
不知道gpt-4o能不能发现隐形的大猩猩: http://www.theinvisiblegorilla.com
2024-06-26