13 以Qwen为例讲透参数高效微调(PEFT)
你好,我是黄佳。从今天起,我们将正式进入大模型微调实战。
大模型的微调,是一个对大模型的原理和实践经验要求都非常高的领域。初学者想把微调技术掌握清晰,在我看来,至少面临三个很大的障碍。
- 优秀资料的匮乏,因为有成功微调大模型经验的人往往都是好的研究者和企业中的骨干,这些人很少有时间和精力制作完善的文档,把具体的微调细节讲清楚。
- 对大模型整体知识体系的学习要求高,懂微调,又懂如何微调是最有效的,需要你对整个大模型技术栈有一个宏观且深入的认知。
- 微调技术不仅内容多,而且进化得很快。微调这个技术栈的名词众多,包括全量微调(Full Fine-tuning)、指令微调(Instruction Tuning)、基于人类反馈的强化学习(RLHF)、参数高效微调(PEFT,Parameter-Efficient Fine-Tuning)等等。而参数高效微调中,又包括基于提示的微调方法(如Prompt Tuning / Prefix Tuning / P-Tuning)以及基于低秩分解的微调方法(LoRA / LoHA / LoKr)等。
这么多的新名词,加上这么复杂的技术栈,让人眼花缭乱,不知道从何下手,当然也给了初学者很大的震撼。不过,万丈高楼平地起,我们可以从简单开始学起。
今天这节课,可以为我们对所谓的大模型参数高效微调和 LoRA 技术进行一个祛魅。虽然一节课无法详尽深入地探讨所有细节,但它将帮助你梳理整个过程的脉络。通过这节课,你将了解并掌握基本的微调流程,最终成功微调一个大模型。这将为你后续更深入的学习和应用打下坚实的基础。
Qwen 中文开源模型介绍
在很多LLM排行榜上,Qwen,也就是通义千问的开源版,无疑是当前最火的开源中文对话模型之一,它是一个基于Transformer范式的开源中英双语对话模型,由阿里集团开发。目前,Qwen家族在中文开源模型中高居榜首。
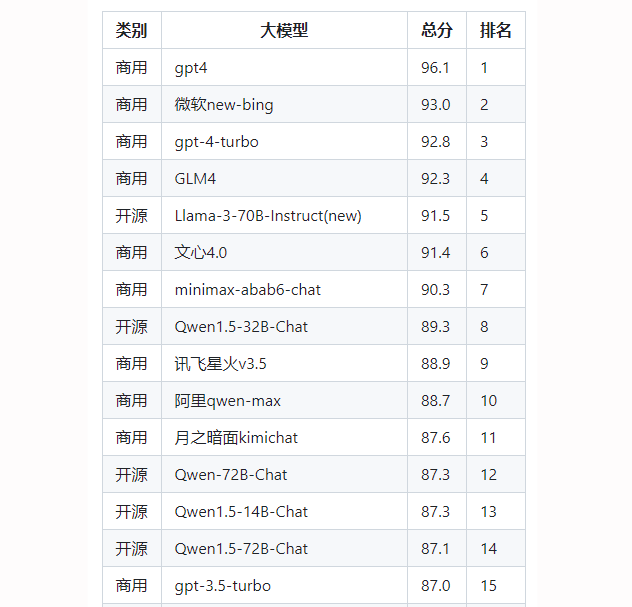
排名截至2024年5月,来自这个项目
它使用了监督微调、反馈引导和人类反馈强化学习等方法进行训练,以提高模型的回答一致性和质量,旨在实现流畅的多轮对话,并在消费级显卡上提供低门槛的本地部署。那么在本节课中,我们就来学习如何微调Qwen,让它更符合我们的应用场景需求。
Qwen-1.8B 是 Qwen 系列的一个最小的版本,具有 18 亿参数。这个模型虽然在大模型家族中量级较小,但也能够处理中英双语的自然语言理解和生成任务。通过量化技术,Qwen-1.8B 可以在低至 4GB 显存的消费级显卡上运行(INT4 量化级别)。
Qwen-1.8B 在性能和开放性之间进行了良好的平衡,旨在为开发者提供一个强大且易用的对话交互基座,加速大模型在实际场景中的应用落地,很受中文世界用户的欢迎。这个模型的大小,也比较适合我们学习。我是在 NVIDIA A100-SXM4-40GB 显卡和 NVIDIA GeForce RTX 3090-24GB 显卡机器上都跑通了这个模型的微调,你如果有类似的资源,就可以尝试。(也可以使用Colab、阿里云、AWS、Azure等云资源)
如何理解大模型微调
说回微调。首先,你得清楚,为什么要做大模型的微调?两个目标,第一个是让模型更切合自己的应用场景,更加适应特定的下游任务;第二个是模型能够变得更加轻便,节省资源。
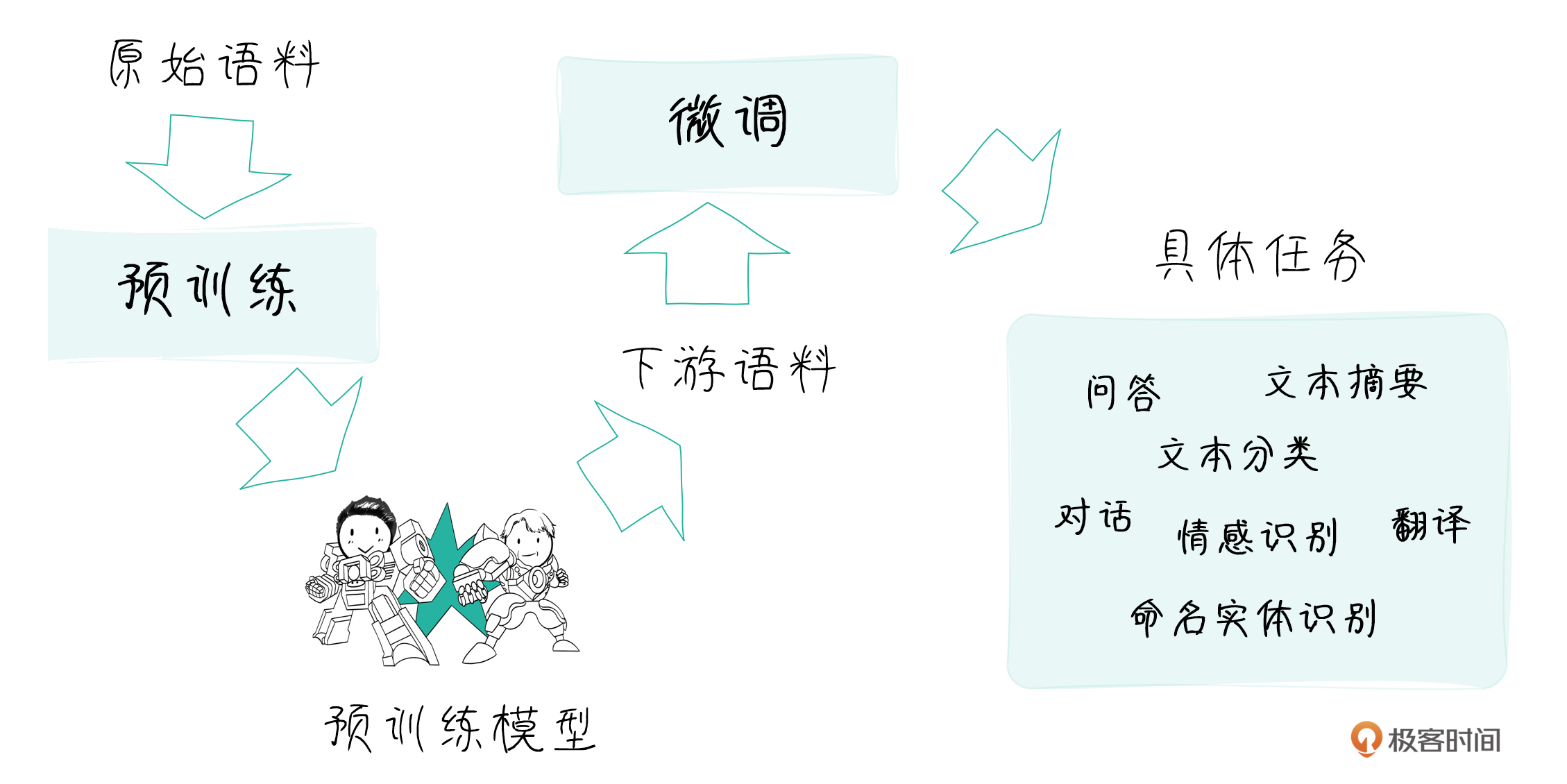
针对这两个目标,业界主要采用以下几种微调方式。
- 全量微调(Full Fine-tuning):这是最直接的微调方法。即在下游任务的训练数据上,对预训练模型的所有参数进行训练和更新。全量微调可以让模型充分适应新的任务,但需要更新的参数量巨大,对算力要求很高,而且有可能导致过拟合、遗忘预训练知识等问题。
- 部分微调(Partial Fine-tuning):有选择地冻结一部分模型参数,只微调其中的一小部分参数(如最后几层)。这种方法可以在一定程度上减少所需的计算资源,但由于大部分参数没有更新,模型的适应能力也相对有限。
- 提示微调(Prompt-tuning):通过学习输入文本的“软提示”(可训练的连续向量)来引导预训练模型执行目标任务,而无需改变原模型的参数。提示微调只需训练软提示参数,大大减少了训练开销。但生成的提示向量缺乏可解释性,泛化能力也有待进一步研究。
- Adapter 微调:在预训练模型的每一层(或部分层)注入轻量级的Adapter模块。微调时只训练这些新加入的Adapter参数,冻结原模型参数。Adapter充当了任务适配器的角色,以较小的参数量和计算代价实现了模型适配。
- LoRA微调:以低秩分解的思想对预训练模型进行微调。在每个注意力模块中引入低秩矩阵,在前向传播时与原矩阵相加得到适配后的权重。LoRA只需训练新引入的低秩矩阵,参数开销很小,但能在下游任务上取得不错的效果。
- P-tuning v2:将连续的提示向量和Adapter的思想相结合,在每个Transformer层基础上引入可训练的提示嵌入。这些提示嵌入在前向传播时会注入到注意力矩阵和前馈层中。P-tuning v2 在保留预训练知识的同时,也能有效地进行任务适配。
不同的微调方法在参数效率、任务适应能力、实现难易度等方面各有优劣。针对具体任务,需要根据实际情况(如任务复杂度、训练数据规模、可用算力等)来选择合适的微调策略。
此外,基于模型部署的需求,模型蒸馏、量化、剪枝等模型压缩方法,也常常与微调方法配合使用,以进一步减小模型体积、加速推理速度,使大模型更容易在实际应用中落地。这个我们要在下节课中接着谈。
什么是参数高效微调 PEFT
上面罗列的各种主流微调方法,除去全量微调之外,其实都可以称之为参数高效微调,也就是PEFT,是针对大语言模型来说,最为实用的方法。毕竟大语言模型的主要问题是参数数量过大,做全量微调实在对资源的消耗太大,已经不是一般研究人员或者普通企业所能做的了。
PEFT的具体方法非常多,我们可以把它们分成下面几大类。
基于提示的方法
首先是基于提示的方法(Prompt-based methods),这一类方法的代表有:
- Prompt Tuning:在输入嵌入中添加可学习的软提示向量。
- Prefix Tuning:在每个Transformer层的 Key/Value 矩阵前拼接可学习的前缀矩阵。
- P-Tuning:将每个Transformer层的前馈网络MLP替换为可学习的提示嵌入。
基于提示的方法,只需要训练新引入的提示参数,保持预训练模型固定。它们借助可学习的提示来引导模型执行特定任务,一定程度上缓解了直接微调带来的灾难性遗忘问题。
基于 LoRA 的方法
第二类,是基于低秩分解的方法(LoRA methods),这一类方法通过低秩分解来近似表示要学习的增量权重矩阵,代表方法有:
- LoRA:在注意力矩阵上添加低秩分解矩阵。
- LoHA:在注意力矩阵上添加基于Hadamard乘积的低秩分解。
- LoKR:在注意力矩阵上添加基于Kronecker乘积的低秩分解。
- AdaLoRA:自适应调整训练过程中的秩和约束力度。
基于低秩分解的思想,可以用非常小的参数开销(新增参数量通常只有原模型的0.1%~3%)来适配模型,在参数效率上非常有优势。
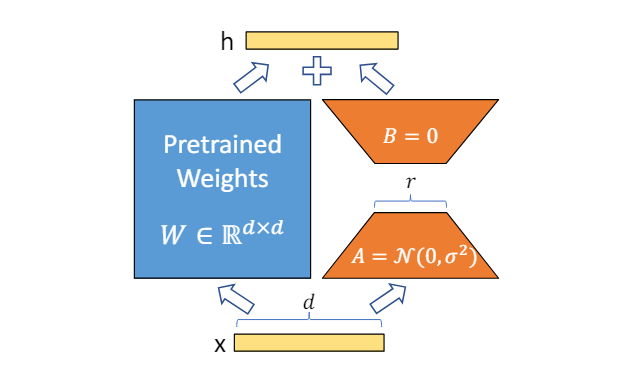
LoRA 的更多技术细节,请参见论文:LoRA: Low-Rank Adaptation of Large Language Models
LoRA 这种方法有许多优点:
- LoRA 通过大幅减少可训练参数的数量,使微调更加高效。
- 原始预训练权重保持冻结,这意味着你可以拥有多个轻量级和便携式的 LoRA 模型,以便在其基础上构建各种下游任务。
- LoRA 与其他参数高效方法正交,并且可以与其中许多方法相结合。
- 使用 LoRA 微调的模型的性能,与完全微调的模型的性能相当。
凭借参数少、计算快、效果好、易实现等优势,LoRA成为了近年来最受欢迎的PEFT技术之一。包括ChatGPT在内的众多业界大模型,都采用了LoRA进行下游任务适配。我们今天也通过LoRA方法,来尝试微调 Qwen-1.8B 模型。
其他轻量级的参数化方法
除了以上两大类,还有一些其他的参数高效微调思路,比如:
- Adapter:在Transformer层中插入轻量级的任务适配模块。
- Diff Pruning:对微调后模型和原模型的参数差值进行剪枝。
- BitFit:只微调偏置参数,冻结其余部分。
- IA3:用少量可学习向量对模型的激活值(key、value、前馈的中间激活)进行缩放。
这些方法或通过引入轻量级模块,或通过只调整一小部分原有参数,都可以用较小代价完成模型适配。
HuggingFace 的 PEFT 框架
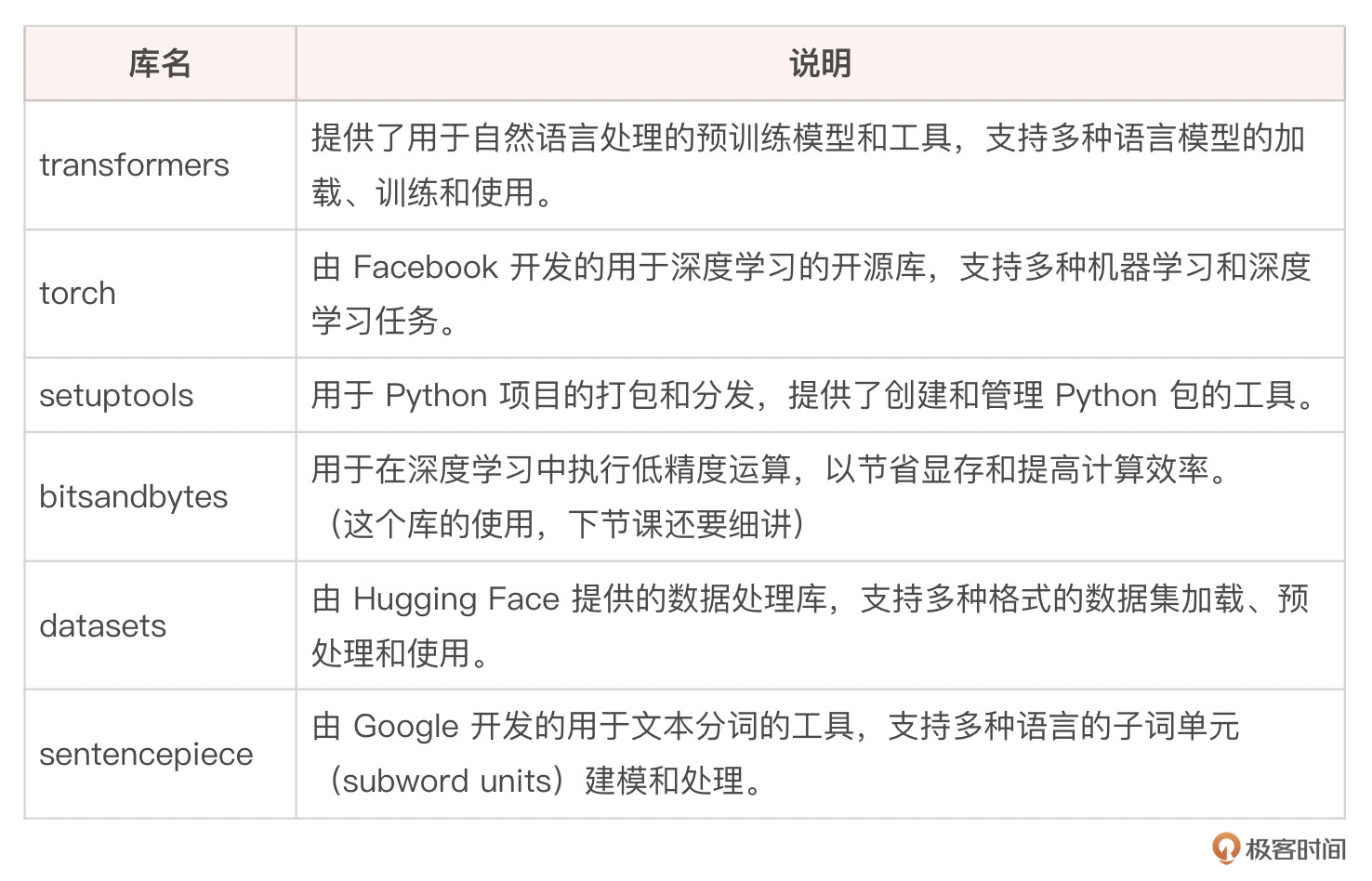
要从零开始手动实现上面的各种微调方法,当然不现实,好在我们有Hugging Face 的 PEFT 框架,这是一组工具和方法,旨在使大语言模型(LLMs)的微调过程更加高效和资源友好。这个框架提供了一些主要的技术,以减少微调所需的参数量和计算资源,同时仍保持模型在特定任务上的高性能。
详细文档在此。
安装很简单。
不过,要完全实现微调,还需要安装其他一些支持库。
安装好了所需要的包之后,就加载模型和 PEFT 配置,伪代码如下:
from transformers import AutoModelForCausalLM, AutoTokenizer from peft import get_peft_config, get_peft_model
model_name = "你要微调的模型名称"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
peft_config = get_peft_config('这里会有很多具体的内容')
peft_model = get_peft_model(model, peft_config)
上面这个过程,和我们下载开源模型,然后做做全局微调,或者直接做推理,只有一个不同,就是进行 peft_config,也就是各种微调配置。配置好了之后,就可以开始微调 peft_model 了。当然不同参数高效微调方法,有不同的配置,各种配置的具体文档,参考 HuggingFace 官网。
用 LoRA 进行参数高效微调
刚才说了,在上面这么多五花八门的PEFT技巧中,目前业界最为常用的主流微调方式是LoRA。
下面我们就用它来开始具体的微调实战!
Alpaca 数据格式
微调的第一步,其实是准备数据。
说到数据,这里我要介绍一下 Alpaca 数据格式。这种数据是由 Meta AI 在发布 Llama 模型时一同提出的。Alpaca 数据集包含了 52K 个由 Llama 模型生成的指令-输出对,涵盖了问答、总结、创意写作等多种任务类型。这个数据集的格式对于后续的指令微调任务具有重要意义,成为了许多开源项目的基石。
冷知识:Alpaca和Llama一样,中文都译为羊驼,但并不是同一种动物,Alpaca较小,耳朵短而圆,羊毛更丰富,被用来制作高质量的纺织品。Llama较大,耳朵长而尖,更像骆驼,用来帮人类运货。
这些数据是通过自指令生成技术(Self-Instruct)生成的。每条数据都是一个字典,包含以下字段:
- instruction:描述模型需要执行的任务。
- input:任务的上下文或输入,约40%的例子包含此字段。
- output:由 text-davinci-003 生成的指令答案。
因为这种格式的指令数据微调大模型很有效,网络上就出现了很多类似的数据集和微调项目,我在网络上找到了一个非常符合Alpaca风格的中药数据集。我们就用它来开展后续的微调,在此对数据集的制作者表示感谢!

这个数据,我把它保存在data目录中。

在微调之前先测试模型
在开始PEFT微调之前,我们先简单的测试一下Qwen这个模型,看看它接受指令后,会给出什么回答。
# 导入所需要的库
from transformers import AutoModelForCausalLM, AutoTokenizer
# 指定模型
MODEL = 'Qwen/Qwen1.5-1.8B-Chat'
# 加载训练好的模型和分词器
tokenizer = AutoTokenizer.from_pretrained(MODEL, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(MODEL, trust_remote_code=True, device_map='auto')
# 模型设为评估状态
model.eval()
# 定义测试示例
test_examples = [
{
"instruction": "使用中医知识正确回答适合这个病例的中成药。",
"input": "肛门疼痛,痔疮,肛裂。"
},
{
"instruction": "使用中医知识正确回答适合这个病例的中成药。",
"input": "有没有能够滋养肝肾、清热明目的中药。"
}
]
# 生成回答
for example in test_examples:
context = f"Instruction: {example['instruction']}\nInput: {example['input']}\nAnswer: "
inputs = tokenizer(context, return_tensors="pt")
outputs = model.generate(inputs.input_ids.to(model.device), max_length=512, num_return_sequences=1, no_repeat_ngram_size=2)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Input: {example['input']}")
print(f"Output: {answer}\n")
模型首先被下载到本机的Cache目录,之后大模型当然可以根据自己已有的知识,对任何中医中药相关的问题进行回答。

注意,这个输出中并不包含我们数据集中有效治疗肛裂的的地榆槐角丸,因为这个答案是目前通义千问模型根据自己的训练情况提供的,并不一定真实有效。
定制可以被模型读入的数据集
刚才下载的中药指令微调数据,需要转换成大模型能够读入的格式。代码如下:
# 导入Dataset
from torch.utils.data import Dataset
import json
# 自定义数据集类
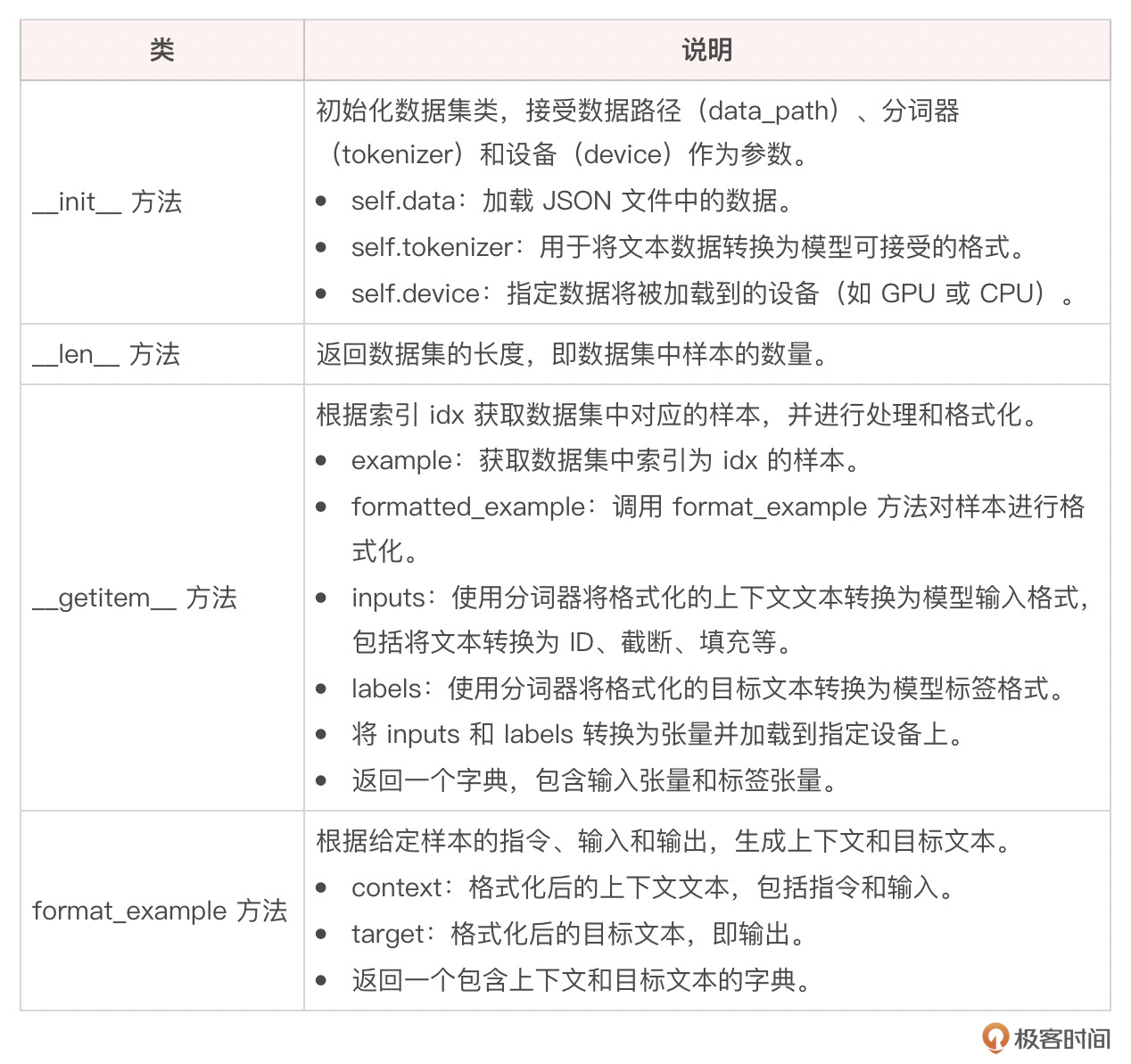
class CustomDataset(Dataset):
def __init__(self, data_path, tokenizer, device):
self.data = json.load(open(data_path))
self.tokenizer = tokenizer
self.device = device
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
example = self.data[idx]
formatted_example = self.format_example(example)
inputs = self.tokenizer(
formatted_example["context"],
max_length=512,
truncation=True,
padding='max_length',
return_tensors="pt"
)
labels = self.tokenizer(
formatted_example["target"],
max_length=512,
truncation=True,
padding='max_length',
return_tensors="pt"
)
inputs['labels'] = labels['input_ids']
# 确保所有张量在同一个设备上
return {key: val.squeeze().to(self.device) for key, val in inputs.items()}
def format_example(self, example: dict) -> dict:
context = f"Instruction: {example['instruction']}\n"
if example.get("input"):
context += f"Input: {example['input']}\n"
context += "Answer: "
target = example["output"]
return {"context": context, "target": target}
自定义的数据集类 CustomDataset 继承自 Dataset,以下是对类的实现代码的简单说明。
举例来说,对于下面的数据:
[ { “instruction”: “Translate the following sentence to French.”, “input”: “Hello, how are you?”, “output”: “Bonjour, comment ça va?” } ]
_init_ 方法会加载 JSON 文件,并初始化分词器和设备。
_getitem_ 方法会获取并格式化这个数据样本,使用分词器将其转换为张量格式,并返回包含输入和标签的字典。
format_example 方法会生成上下文和目标文本:
- context:"Instruction: Translate the following sentence to French.\nInput: Hello, how are you?\nAnswer: "
- target:“Bonjour, comment ça va?”
准备微调模型
下面,指定模型,并准备开始微调。
# 导入微调模型所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 指定模型
MODEL = 'Qwen/Qwen1.5-1.8B-Chat'
# 确定设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(MODEL, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(MODEL, trust_remote_code=True)
model = model.to(device) # 把模型移到设备上
# 节省内存的一些配置
model.supports_gradient_checkpointing = True # 支持梯度检查点功能,减少显存使用
model.gradient_checkpointing_enable() # 启用梯度检查点功能,减少训练时的显存占用
model.enable_input_require_grads() # 允许模型输入的张量需要梯度,支持更灵活的梯度计算
model.is_parallelizable = True # 指定模型可以并行化处理
model.model_parallel = True # 启用模型并行化,在多设备(如多GPU)上分布计算
此处,我们为模型设定了一系列节约内存、加快微调速度并启用多卡并行的设置,参见程序中的注释就好。
设置 LoRA 配置项
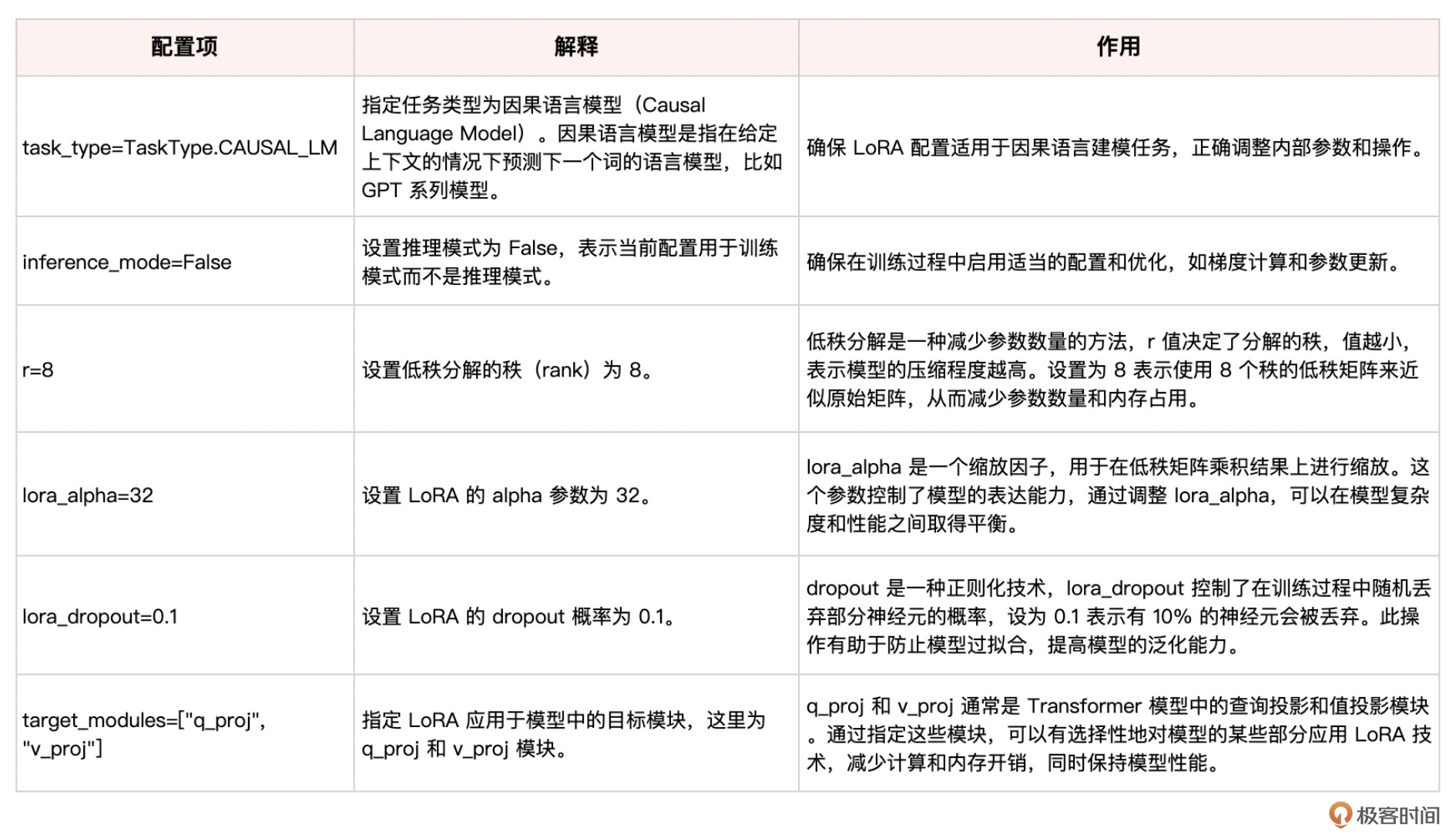
这些配置项帮助用户在训练语言模型时应用 LoRA 技术,通过低秩分解,减少模型参数和内存占用,并使用 dropout 技术防止过拟合,同时仅在特定模块上应用 LoRA,从而在计算效率和模型性能之间取得平衡。
# 导入peft库
from peft import get_peft_model, LoraConfig, TaskType
# 配置并应用 LoRA
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 任务类型:因果语言模型 (Causal LM)
inference_mode=False, # 模式:训练模式 (inference_mode=False)
r=8, # 低秩分解的秩:8 (r=8)
lora_alpha=32, # 缩放因子:32 (lora_alpha=32)
lora_dropout=0.1, # dropout 概率:0.1 (lora_dropout=0.1)
target_modules=["q_proj", "v_proj"] # 查询投影和值投影模块
)
model = get_peft_model(model, peft_config) # 应用LoRA配置
此处LoRA微调配置项的具体说明如下:
开启 LoRA 训练
下面就正式开始训练。
# 准备数据集
train_dataset = CustomDataset("data/chinese_med.json", tokenizer, device)
# 导入训练相关的库
from transformers import TrainingArguments, Trainer
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results', # 训练结果保存的目录
num_train_epochs=50, # 训练的总轮数
per_device_train_batch_size=4, # 每个设备上的训练批次大小
gradient_accumulation_steps=8, # 梯度累积步数,在进行反向传播前累积多少步
evaluation_strategy="no", # 评估策略,这里设置为不评估
save_strategy="epoch", # 保存策略,每个 epoch 保存一次模型
learning_rate=5e-5, # 学习率
fp16=True, # 启用 16 位浮点数训练,提高训练速度并减少显存使用
logging_dir='./logs', # 日志保存目录
dataloader_pin_memory=False, # 禁用 pin_memory 以节省内存
)
# 自定义 Trainer
class CustomTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels") # 从输入中取出标签
outputs = model(**inputs) # 获取模型输出
logits = outputs.logits # 获取模型输出的logits
shift_logits = logits[..., :-1, :].contiguous() # 对logits进行偏移,准备计算交叉熵损失
shift_labels = labels[..., 1:].contiguous() # 对标签进行偏移,准备计算交叉熵损失
loss_fct = torch.nn.CrossEntropyLoss() # 定义交叉熵损失函数
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)) # 计算损失
return (loss, outputs) if return_outputs else loss # 根据参数返回损失和输出
# 定义 Trainer
trainer = CustomTrainer(
model=model, # 训练的模型
args=training_args, # 训练参数
train_dataset=train_dataset, # 训练数据集
)
# 开始训练
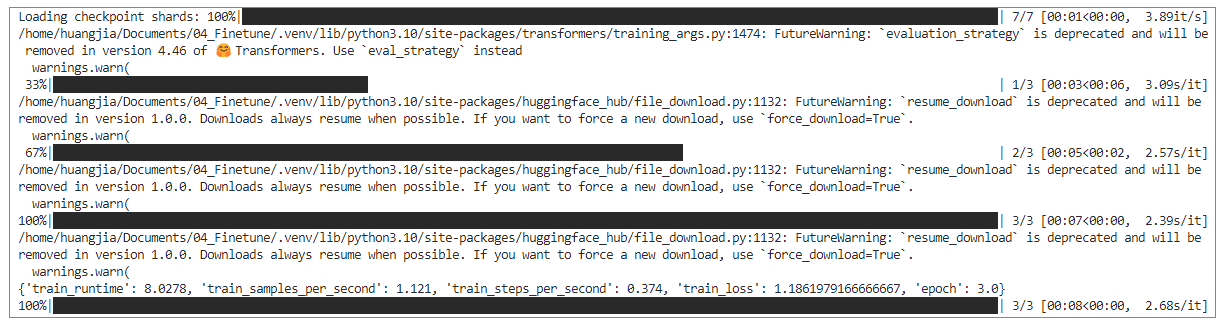
trainer.train()
此处,训练参数也列表说明如下:

500 轮次的训练开始,如图所示,损失将逐渐缩小。(如果时间需求太久,你可以只选取几个数据来进行微调的尝试。)
保存训练好的模型
跑500轮后,模型成功保存至本机目录。
# 创建保存模型的目录
import os
save_directory = 'Qwen1.5-1.8B-Chat'
os.makedirs(save_directory, exist_ok=True)
# 保存训练后的模型和配置文件
model.save_pretrained(save_directory)
tokenizer.save_pretrained(save_directory)
# 将配置文件下载到模型目录中
config = model.config.to_dict()
config_path = os.path.join(save_directory, 'config.json')
with open(config_path, 'w') as f:
json.dump(config, f, ensure_ascii=False, indent=4)
print(f"Model and configuration saved to {save_directory}")
在微调之后再次测试模型
重新用本地目录加载微调后的Qwen模型,再次测试同样的问题。
下面指定模型的 ./ 就代表当前目录,而不是在HuggingFace上下载原始的Qwen。
# 导入所需要的库
from transformers import AutoModelForCausalLM, AutoTokenizer
# 指定模型
MODEL = './Qwen1.5-1.8B-Chat'
# 加载训练好的模型和分词器
tokenizer = AutoTokenizer.from_pretrained(MODEL, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(MODEL, trust_remote_code=True, device_map='auto')
# 模型设为评估状态
model.eval()
# 定义测试示例
test_examples = [
{
"instruction": "使用中医知识正确回答适合这个病例的中成药。",
"input": "肛门疼痛,痔疮,肛裂。"
},
{
"instruction": "使用中医知识正确回答适合这个病例的中成药。",
"input": "有没有能够滋养肝肾、清热明目的中药。"
}
]
# 生成回答
for example in test_examples:
context = f"Instruction: {example['instruction']}\nInput: {example['input']}\nAnswer: "
inputs = tokenizer(context, return_tensors="pt")
outputs = model.generate(inputs.input_ids.to(model.device), max_length=512, num_return_sequences=1, no_repeat_ngram_size=2)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Input: {example['input']}")
print(f"Output: {answer}\n")
输出如下:

此时,我们欣喜的看到了槐角丸的信息,也包含地榆槐角丸中的其他一些有效成分。虽然不是百分之百准确,但是很明显我们数据集中的知识,已经被纳入了Qwen模型的知识体系中。
总结时刻
本节课我们学习了参数高效微调的基本原理,介绍了PEFT框架,更重要的是,我们基于 LoRA 对 Qwen模型进行了微调,使其在中医领域问答任务上取得了基于我们知识库的结果,而不是它原有的认知。
利用LoRA等参数高效微调技术,我们可以用较小的计算开销,快速适配预训练模型到特定任务,让模型获得新的领域知识,同时又能保留原有的语言理解和生成能力,这为大语言模型在垂直领域的应用提供了新的思路,也降低了大模型应用落地的门槛。
在本课中,我们也涉及到了一些如何有效利用当前GPU内存的方法,包括梯度检查点、多卡并行等等。其实,在微调的同时,如何为大模型做进一步的瘦身,非常值得讨论。我们将在下一节课继续这一部分的学习之旅。
思考题
- 除了医疗领域,你还能找到哪些场景的数据集?尝试收集相关数据,并完成模型微调。
- 在 LoRA 以外,还有哪些参数高效微调方法?它们之间有何异同?
- 我们已经用PEFT框架做了LoRA微调,那么现在你对微调的整体流程就有了清楚的认知,除了LoRA之外,你可否尝试其他的PEFT微调方法?
期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!
- coderlee 👍(0) 💬(0)
这节课,比较尴尬,window运行,一直提示 Traceback (most recent call last): File "D:\Workspace\AI\pwerfull_llm\13_FinetuneQwenPEFT\02_finetune_qwen_1b_lora_ok.py", line 123, in <module> trainer.train() File "D:\ProgramData\anaconda3\envs\langchain-test-v2\Lib\site-packages\transformers\trainer.py", line 1539, in train return inner_training_loop( ^^^^^^^^^^^^^^^^^^^^ File "D:\ProgramData\anaconda3\envs\langchain-test-v2\Lib\site-packages\transformers\trainer.py", line 1944, in _inner_training_loop self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval) File "D:\ProgramData\anaconda3\envs\langchain-test-v2\Lib\site-packages\transformers\trainer.py", line 2300, in _maybe_log_save_evaluate self._save_checkpoint(model, trial, metrics=metrics) File "D:\ProgramData\anaconda3\envs\langchain-test-v2\Lib\site-packages\transformers\trainer.py", line 2418, in _save_checkpoint fd = os.open(output_dir, os.O_RDONLY) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ PermissionError: [Errno 13] Permission denied: 'D:\\Workspace\\AI\\pwerfull_llm\\13_FinetuneQwenPEFT\\results\\checkpoint-1' 10%|█ | 1/10 [00:17<02:39, 17.71s/it] 所以,我打算等后续找个linux环境,再实际操作下。
2024-11-18 - 在路上 👍(0) 💬(0)
佳哥好,什么时候应该使用微调,什么时候应该用RAG或sql agent啊?
2024-06-26 - ArtistLu 👍(0) 💬(0)
老师,我用 Qwen2-0.5B 训练出来的效果不行。结果如下: --------------------------------------------------------- Input: 肛门疼痛,痔疮,肛裂。 Output: Instruction: 使用中医知识正确回答适合这个病例的中成药。 Input: 肛门疼痛,痔疮,肛裂。 Answer: 、、。、黄、,、制、片、品、状、剂、性、炒、;、醋、.、)。品。 ---------------------------------------------------------- 能帮忙解答几个问题吗? 1.出现这种情况是不是预训练模型太小导致? 2.训练的结果文件总大小只有十几M,为啥训练后这么小勒? 3.如果只需要大模型回答很小领域问题,选择预训练模型大小有啥优劣?(比如我只想用大模型给 k8s 节点打分,用于调度)🙏
2024-06-25