08 用大模型实现自然语言的SQL查询
你好,我是黄佳。今天我们继续利用大模型的能力来构建简单又实用的工具。
今天我将带着你学习如何利用 Claude 大模型生成从简单到复杂的 SQL 查询语句。我们的目标是展示如何将自然语言问题转化为精确的 SQL 命令,以便有效地从数据库中提取所需信息。这样,我们就能充分地利用 Claude 的自然语言处理能力,简化和自动化 SQL 查询的生成过程,使得数据分析工作更加高效和直观。
这里,我们选用一个强大的模型——Claude-3 Opus。
下面就开始第一个实战:生成简单的SQL查询语句。
生成 SQL 查询语句
利用Claude这样一个大语言模型来生成SQL查询的关键步骤如下:
- 设置好要使用的大语言模型。
- 创建一个测试数据库,并插入示例数据。
- 获取数据库的Schema信息,并将其格式化为字符串。
- 定义一个函数,将自然语言问题和数据库Schema发送给Claude,并获取生成的SQL查询。
- 执行生成的SQL查询,并打印结果。
下面一步步来完成它。
步骤 1:设置模型
这一步是准备工作,创建大模型的客户端。
from dotenv import load_dotenv
load_dotenv()
# 导入Anthropic库
from anthropic import Anthropic
# 设置Anthropic API客户端
client = Anthropic()
MODEL_NAME = "claude-3-opus-20240229"
步骤 2:设置测试数据库
这一步仍然是准备工作。我们需要建立一个测试数据库。这涉及到定义表的结构(schema),并填充一些示例数据以供查询使用。
# 导入sqlite3库
import sqlite3
# 设置Anthropic API客户端
client = Anthropic()
MODEL_NAME = "claude-3-opus-20240229"
# 连接到测试数据库(如果不存在则创建)
conn = sqlite3.connect("test_db.db")
cursor = conn.cursor()
# 创建示例表
cursor.execute("""
CREATE TABLE IF NOT EXISTS employees (
id INTEGER PRIMARY KEY,
name TEXT,
department TEXT,
salary INTEGER
)
""")
# 插入示例数据
sample_data = [
(6, "黄佳", "销售", 50000),
(7, "宁宁", "工程", 75000),
(8, "谦谦", "销售", 60000),
(9, "悦悦", "工程", 80000),
(10, "黄仁勋", "市场", 55000)
]
cursor.executemany("INSERT INTO employees VALUES (?, ?, ?, ?)", sample_data)
conn.commit()
运行后没有出现错误提示信息,说明数据库表和数据都已经成功创建。
步骤 3:向 Claude 提供数据库Schema
接下来,我们将通过提示,向 Claude 提供数据库Schema。Schema应详细描述每个表的字段和类型,这有助于 Claude 理解表的结构和关联。
# 获取数据库Schema
schema = cursor.execute("PRAGMA table_info(employees)").fetchall()
schema_str = "CREATE TABLE EMPLOYEES (\n" + "\n".join([f"{col[1]} {col[2]}" for col in schema]) + "\n)"
print("数据库Schema:")
print(schema_str)
# 定义一个函数,将查询发送给Claude并获取响应
def ask_claude(query, schema):
prompt = f"""这是一个数据库的Schema:
{schema}
根据这个Schema,你能输出一个SQL查询来回答以下问题吗?只输出SQL查询,不要输出其他任何内容。
问题:{query}
"""
response = client.messages.create(
model=MODEL_NAME,
max_tokens=2048,
messages=[{
"role": 'user', "content": prompt
}]
)
return response.content[0].text
输出如下:
步骤 4:提出问题
接下来向 Claude 提出自然语言形式的问题。下面的问题是一个简单的数据查询(查询特定员工的工资)。
# 示例自然语言问题
question = "工程部门员工的姓名和工资是多少?"
# 将问题发送给Claude并获取SQL查询
sql_query = ask_claude(question, schema_str)
print("生成的SQL查询:")
print(sql_query)
输出如下:
结果显示Claude 的能力足以根据提供的问题生成对应的 SQL 查询语句。
步骤 5:执行 SQL 查询并展示结果
最后,我们将执行生成的 SQL 查询,并展示查询结果。
# 执行SQL查询并打印结果
print("查询结果:")
results = cursor.execute(sql_query).fetchall()
for row in results:
print(row)
# 关闭数据库连接
conn.close()
输出如下:
SQL代码无误,查询结果也准确。至此,我们展示了从提问到获取答案的完整流程。
测试 SQL 增、删、改语句
除了数据查询,我们还可以让Claude根据自然语言指令生成INSERT、UPDATE和DELETE语句,实现对数据库的写入和修改操作。
代码示例如下:
# 插入新员工
question = "在销售部门增加一个新员工,姓名为张三,工资为45000"
sql_query = ask_claude(question, schema_str)
cursor.execute(sql_query)
conn.commit()
# 更新员工信息
question = "将黄佳的工资调整为55000"
sql_query = ask_claude(question, schema_str)
cursor.execute(sql_query)
conn.commit()
# 删除员工
question = "删除市场部门的黄仁勋"
sql_query = ask_claude(question, schema_str)
cursor.execute(sql_query)
conn.commit()
输出如下:
INSERT INTO EMPLOYEES (name, department, salary)
VALUES ('张三', '销售', 45000);
UPDATE EMPLOYEES
SET salary = 55000
WHERE name = '黄佳';
DELETE FROM EMPLOYEES
WHERE name = '黄仁勋' AND department = '市场';
通过这种方式,我们可以使用自然语言对数据库进行全面的操作,大大简化了数据管理的过程。
生成更复杂的多表组合查询语句
除了基本的数据查询外,我们还可以进一步增加难度,实现更复杂的场景。比如,通过多表连接和聚合查询,来计算每个部门的平均工资。
首先,我们创建含公司部门信息的新表。
# 创建部门表
cursor.execute("""
CREATE TABLE IF NOT EXISTS departments (
id INTEGER PRIMARY KEY,
name TEXT,
manager TEXT
)
""")
# 插入示例数据
sample_departments = [
(1, "销售", "王经理"),
(2, "工程", "李经理"),
(3, "市场", "张经理")
]
cursor.executemany("INSERT INTO departments VALUES (?, ?, ?)", sample_departments)
conn.commit()
然后,获取完整的数据库schema。
# 获取完整的数据库schema
tables = ["employees", "departments"]
schema_str = ""
for table in tables:
schema = cursor.execute(f"PRAGMA table_info({table})").fetchall()
schema_str += f"CREATE TABLE {table} (\n" + "\n".join([f"{col[1]} {col[2]}" for col in schema]) + "\n);\n\n"
print("完整的数据库schema:")
print(schema_str)
输出如下:
完整的数据库schema:
CREATE TABLE employees (
id INTEGER
name TEXT
department TEXT
salary INTEGER
);
CREATE TABLE departments (
id INTEGER
name TEXT
manager TEXT
);
在这个数据库Schema中,包含之前创建的employees的表信息,以及新建的departments信息。
下面,我们把数据库Schema传给Claude模型,并获取生成的SQL语句。
# 定义一个函数,将查询发送给Claude并获取响应
def ask_claude(query, schema):
prompt = f"""这是一个数据库的schema:
{schema}
根据这个schema,你能输出一个SQL查询来回答以下问题吗?只输出SQL查询,不要输出其他任何内容。
问题:{query}
"""
response = client.messages.create(
model=MODEL_NAME,
max_tokens=2048,
messages=[{
"role": 'user', "content": prompt
}]
)
return response.content[0].text
# 查询每个部门的员工人数和平均工资
question = "根据两个表之间的关系,列出每个部门的员工人数和平均工资"
# 将问题发送给Claude并获取SQL查询
sql_query = ask_claude(question, schema_str)
print("生成的SQL查询:")
print(sql_query)
输出如下:
生成的SQL查询:
SELECT
d.name AS department,
COUNT(e.id) AS num_employees,
AVG(e.salary) AS avg_salary
FROM
departments d
LEFT JOIN
employees e ON d.name = e.department
GROUP BY
d.name;
这个查询通过结合 departments 和 employees 两个表,为每个部门提供了员工数量和平均工资的数据。
最后,执行SQL查询并打印结果。
# 执行SQL查询并打印结果
print("查询结果:")
results = cursor.execute(sql_query).fetchall()
for row in results:
print(row)
# 关闭数据库连接
conn.close()
输出如下:
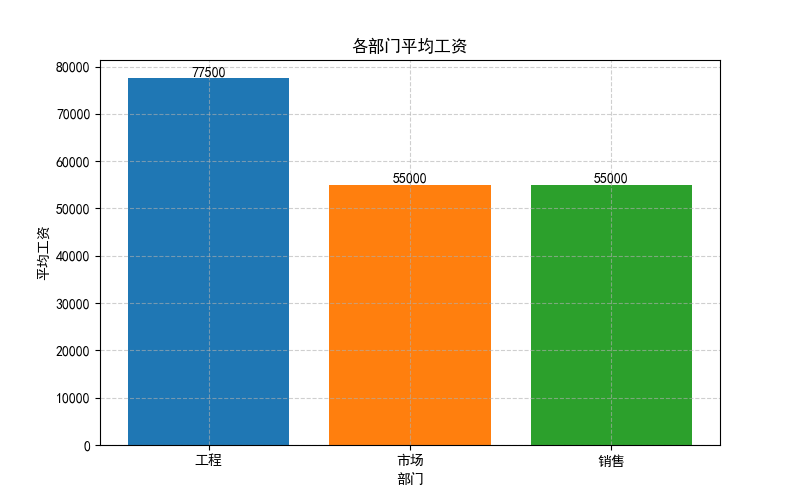
基于查询结果,我们可以绘制出各部门平均工资。
import matplotlib.pyplot as plt
plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# 计算平均工资
departments = [row[0] for row in results]
avg_salaries = [row[2] for row in results]
# 生成条形图
plt.figure(figsize=(8, 5))
bars = plt.bar(departments, avg_salaries, color=['#1f77b4', '#ff7f0e', '#2ca02c']) # 为每个部门设置不同的颜色
# 设置图表标题和标签
plt.xlabel("部门")
plt.ylabel("平均工资")
plt.title("各部门平均工资")
# 添加网格线,提高图表的可读性
plt.grid(True, linestyle='--', alpha=0.6)
# 在每个条形图上方显示具体数值
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval, f'{int(yval)}', va='bottom', ha='center', color='black')
# 保存图表到文件
plt.savefig('Average_Salary_by_Department.png')
好了,今天的课程就到此为止。这是相对轻松的一课,理论的东西很少,着重于启发大家思考如果利用大模型的能力来帮助自己的工作。
总结时刻
通过上述步骤,我们展示了如何使用 Claude 大模型精确地将自然语言转换为有效的 SQL 代码,生成从简单到复杂的 SQL 查询语句。这个过程体现了自然语言处理技术在数据管理和分析中的实际应用,使得即使是不熟悉 SQL 的用户也能轻松进行数据查询。
这种方法的应用不限于 SQL 查询,它也可以扩展到其他编程语言和技术领域,如自动代码生成、错误诊断和性能优化等。通过合理设计语言模型的提示和命令,我们能够最大化模型的潜能,解决更广泛的技术问题。
藉此,更值得一谈的问题也许是大模型时代对普通技术人员的影响。毫无疑问,大模型可以自动化很多标准和重复的查询任务,如数据检索、报告生成等。那么,随着这些基本操作的自动化,初级技术人员必须考虑升级转型,我们需要专注于更加策略性的任务,如数据架构设计、数据安全性和性能优化等高级领域。同时,掌握如何有效利用这些大模型进行流程自动化和效率提升也成为了一个重要的技能。
当然,尽管自动化会接管一些任务,但对高级技能和深入理解的需求将持续存在。数据库管理不仅仅是写查询,还包括管理数据库的健康、优化性能和确保数据一致性等多个方面,这些都需要深厚的专业知识。能力越全面,高级技术懂得越多,接触到的业务场景越复杂,沟通能力约优秀,我们就越安全。
思考题
- 尽管我使用的是能力强大的 Claude-3 Opus 模型,但我鼓励你尝试其他模型,如GPT系列模型,甚至开源模型来完成本课任务。新的开源模型,如Mistral、Phi,以及中文开源模型Qwen等,同样可以通过适当的提示设计来执行复杂的任务。你可以使用 LangChain 等 LLM 开发框架来调用这些模型,或者直接从Hugging Face Transformers库下载模型,进行推理,并观察它们在类似任务上的表现。
- 在我的示例中,数据库表的结构和关系都非常简单。在你的实际业务逻辑中,你可能需要设计几十个甚至成百上千个业务表,形成非常复杂的Schema,你能否尝试用Claude-3 Opus或GPT-4-Turbo这样的最强模型来处理复杂业务需求?
期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!
- 回到原点 👍(1) 💬(2)
用gpt-4-turbo弄了一些,每次出来的结果都不一样,感觉有点不太行啊,但是换了gpt-4o每次出来结果就一样了
2024-06-07 - liyinda0000 👍(0) 💬(1)
老师,感觉您的示例还是比较简单,如果正式环境写sql会很复杂,有什么好方法可以保障自然语言能够转化成正确的sql吗?
2024-06-07 - onemao 👍(0) 💬(1)
跟langchian课里是不是类似啊,那里用的gpt,这里换成了Claude
2024-06-06 - 小风 👍(0) 💬(0)
这个怎么使用本地的模型呢。https://modelscope.cn/models/senjia/llama-3-8B-Instruct-text2sql 就就像这个模型
2024-07-03 - 谢江涛 👍(0) 💬(0)
老师,您好。这两个表之间的关系:employees e ON d.name = e.department,是大模型自动识别的吗?我们使用千问搭建的大模型环境不能正确识别两个表之间的关系,请问该如何处理?谢谢!
2024-06-17