07 用多步提示引导自动生成Python单元测试代码
你好,我是黄佳。
在上节课中,我们学习了提示工程的几个基本原理和技巧,例如编写清晰指令、提供参考资料、分而治之、多角度思考问题以及借助外部工具等。同时也介绍了指导大模型深入思考的思维框架的设计。这些方法可以帮助我们设计出优质的提示,充分发挥语言模型的潜力。
现在,我们进入本套课程中最具分量的解决实际问题篇。这一章节重在传递“如何利用大语言模型和自然语言编程来解决实际问题”这个思路。
这节课我们将从简单的应用入手,介绍如何运用提示工程技巧,引导大语言模型自动生成Python单元测试代码。
整体思路
单元测试是软件开发中的重要环节,它通过编写一系列测试用例,验证关键函数在各种情况下是否都能正常工作,从而提高代码质量,避免潜在的bug。
传统的单元测试依赖程序员手工编写测试代码,不仅耗时耗力,而且考验开发者对边界情况的洞察力。
然而,大模型时代已经来临,而且大模型最在行的,就是处理编码和测试相关的工作。如果能借助AI的能力自动生成全面、严谨的单元测试,无疑可以极大地提升开发效率。
这个目标不难实现!我们可以通过巧妙地设计多步骤提示流程,来有效地引导语言模型完成这一任务。
整个过程分为解释、规划、执行三个阶段。
下面就让我们一起动手实践,看看如何通过提示工程,让ChatGPT为我们写出高质量的Python单元测试代码!
ast 库的语法检查功能
我先给你介绍Python的ast模块,以及它的语法检查功能。
ast是 Abstract Syntax Trees 的缩写,意为抽象语法树。它是Python标准库中的一个模块,提供了一种将Python代码转换为抽象语法树(AST)的方法。AST是一种代码的树状表示,其中每个节点代表代码中的一个语法结构,如语句、表达式、函数定义等。
ast模块主要用于以下几个方面:
- 语法分析:通过将Python代码解析为AST,可以分析代码的结构和内容,例如查找特定的语句、表达式或函数调用等。
- 代码转换:可以通过修改AST来实现代码的转换和优化等。
- 代码生成:可以根据AST生成新的Python代码,例如实现代码的自动补全、重构等。
- 语法检查:可以通过分析AST来检查代码的语法是否正确,而无需实际执行代码。这就是我们要用到的地方,这个功能可以帮助我们检测大模型所生成的测试代码是否有效。
通过调用ast.parse()函数,可以将一段Python代码字符串解析为AST。如果代码有语法错误,parse()函数会抛出SyntaxError异常。
下面是一段示例代码。
import ast # 用于检测生成的Python代码是否有效
# 有效的Python代码
valid_code = "print('Hello, world!')"
ast.parse(valid_code) # 不会抛出异常
# 无效的Python代码
invalid_code = "print('Hello, world!'" # 缺少括号
ast.parse(invalid_code) # 抛出 SyntaxError 异常
ast模块为分析、操作和生成Python代码提供了强大的工具。在我们后面的场景中,它用于检查生成代码的有效性,以确保大模型最终产出的单元测试代码是语法正确的。
创建待测试的函数
下面我们就开始用大模型来生成单元测试代码。
首先,我们创建OpenAI Client和辅助打印消息的函数。
from openai import OpenAI # 导入OpenAI
client = OpenAI() # 创建Client
# 定义显示信息的函数
def display_messages(messages) -> None:
"""打印发送给GPT或GPT回复的消息。"""
for message in messages:
role = message["role"]
content = message["content"]
print(f"\n[{role}]\n{content}")
然后创建要测试的示例函数。
# 要测试的示例函数
example_function = '''
def caesar_cipher(message, offset):
result = ""
for char in message:
if char.isalpha():
ascii_offset = 65 if char.isupper() else 97
shifted_ascii = (ord(char) - ascii_offset + offset) % 26
new_char = chr(shifted_ascii + ascii_offset)
result += new_char
else:
result += char
return result
'''
在这个例子中,我编写了凯撒密码(Caesar Cipher)加密算法,等下我们让GPT对这个函数进行功能测试。
下面开始通过提示词来引导GPT进行测试代码的生成,我们可以将整个测试流程细化为4个步骤。
- 解释函数:让GPT解释待测函数的作用。
- 规划测试:让GPT设计需要覆盖的测试用例。
- 生成测试:让GPT根据测试计划编写单元测试代码。
- 验证结果:检查生成的测试代码是否有语法错误(如果有错,则可以重新生成)。不过这一步已经不算是多步骤提示的一个环节了。
提示第 1 步:生成函数的解释说明
下面,我们让GPT生成对凯撒密码函数代码实现的解释。
# 第1步:生成函数的解释说明
explain_system_message = {
"role": "system",
"content": "你是一位世界级的Python开发者,对意料之外的bug和边缘情况有着敏锐的洞察力。你总是非常仔细和准确地解释代码。你用markdown格式的项目列表来组织解释。",
}
explain_user_message = {
"role": "user",
"content": f"""请解释下面这个Python函数。仔细审查函数的每个元素在精确地做什么,作者的意图可能是什么。用markdown格式的项目列表组织你的解释。
```python
{example_function}
```""",
}
explain_messages = [explain_system_message, explain_user_message]
display_messages(explain_messages)
explanation_response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=explain_messages,
temperature=0.4,
)
explanation = explanation_response.choices[0].message.content
explain_assistant_message = {"role": "assistant", "content": explanation}
display_messages([explain_assistant_message])
在这一步中,我们构造了一个系统消息和一个用户消息,要求GPT解释示例函数的作用。然后,将这些消息发送给OpenAI的API,并通过流式响应获取GPT的解释,并将解释保存在explain_assistant_message中。
这一步的输出如下:
[system]
你是一位世界级的Python开发者,对意料之外的bug和边缘情况有着敏锐的洞察力。你总是非常仔细和准确地解释代码。你用markdown格式的项目列表来组织解释。
[user]
请解释下面这个Python函数。仔细审查函数的每个元素在精确地做什么,作者的意图可能是什么。用markdown格式的项目列表组织你的解释。
```python
def caesar_cipher(message, offset):
result = ""
for char in message:
if char.isalpha():
ascii_offset = 65 if char.isupper() else 97
shifted_ascii = (ord(char) - ascii_offset + offset) % 26
new_char = chr(shifted_ascii + ascii_offset)
result += new_char
else:
result += char
return result
```\
[assistant]
### 函数解释
1. 定义了一个名为 `caesar_cipher` 的函数,接受两个参数 `message` 和 `offset`。
2. 创建一个空字符串 `result` 用于存储加密后的消息。
3. 对于 `message` 中的每个字符 `char` 进行循环处理。
4. 如果 `char` 是字母(通过 `char.isalpha()` 判断),则执行以下操作:
- 判断 `char` 是大写字母还是小写字母,通过 `ascii_offset = 65 if char.isupper() else 97` 来确定ASCII偏移量。
- 计算新的ASCII值:`(ord(char) - ascii_offset + offset) % 26`,其中 `ord(char)` 返回 `char` 的ASCII值。
- 将新的ASCII值转换为字符 `new_char`。
- 将 `new_char` 添加到 `result` 中。
5. 如果 `char` 不是字母,则直接将其添加到 `result` 中。
6. 返回加密后的结果 `result`。
### 作者意图
- 作者的意图是实现一个凯撒密码(Caesar Cipher)的加密算法,通过将消息中的字母按照指定的偏移量 进行移位加密,非字母字符保持不变。
- 函数通过循环遍历消息中的每个字符,并根据字符的类型进行不同的处理,以实现加密操作。
- 通过对大写字母和小写字母分别处理,保证了加密后的结果与原始消息的大小写格式一致。
这个函数的作用是将输入的消息按照凯撒密码的方式进行加密,加密方式是将字母按照指定的偏移量进行移位,非字母字符保持不变。
大模型首先是非常详实而清晰的理解了函数的设计意图,这对于它下一步继续编写单元测试计划很有好处,也非常符合CoT(思维链)的提示设计风格。
提示第 2 步:生成编写单元测试的计划
下面,接着着手生成编写单元测试的计划。代码如下:
# 第2步:生成编写单元测试的计划
plan_user_message = {
"role": "user",
"content": f"""一个好的单元测试套件应该致力于:
- 测试函数在各种可能的输入下的行为
- 测试作者可能没有预料到的边缘情况
- 利用 `pytest` 的特性使测试更容易编写和维护
- 易于阅读和理解,代码干净,名称描述清晰
- 具有确定性,测试总是以相同的方式通过或失败
为了帮助对上述函数进行单元测试,请列出函数应该能够处理的不同场景(每个场景下再用子项目列出几个例子)。""",
}
plan_messages = [
explain_system_message,
explain_user_message,
explain_assistant_message,
plan_user_message,
]
display_messages([plan_user_message])
plan_response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=plan_messages,
temperature=0.4,
)
plan = plan_response.choices[0].message.content
plan_assistant_message = {"role": "assistant", "content": plan}
display_messages([plan_assistant_message])
在这一步中,我们构造了一个用户消息,要求GPT为示例函数制定单元测试计划。我们将之前获得的函数解释也包含在消息中,以提供更多上下文。然后,我们将消息发送给OpenAI的API,并获取GPT生成的测试计划。
这一步的输出如下:
[user]
一个好的单元测试套件应该致力于:
- 测试函数在各种可能的输入下的行为
- 测试作者可能没有预料到的边缘情况
- 利用 `pytest` 的特性使测试更容易编写和维护
- 易于阅读和理解,代码干净,名称描述清晰
- 具有确定性,测试总是以相同的方式通过或失败
为了帮助对上述函数进行单元测试,请列出函数应该能够处理的不同场景(每个场景下再用子项目列出几个例子)。
[assistant]
### 单元测试场景
1. 测试函数在各种可能的输入下的行为:
- 测试消息包含大写字母、小写字母、数字和特殊字符的情况。
- 例子:`"Hello, World!"`、`"Python123"`、`"!@#$%^&*"`
- 测试不同的偏移量,包括正数、负数和0。
- 例子:偏移量为3、偏移量为-5、偏移量为0
- 测试空消息的情况。
- 例子:`""`
2. 测试作者可能没有预料到的边缘情况:
- 测试消息包含Unicode字符的情况。
- 例子:`"你好,世界!"`
- 测试偏移量超出26的情况。
- 例子:偏移量为30
- 测试消息包含连续的字母序列的情况。
- 例子:`"abcde"`
3. 利用 `pytest` 的特性使测试更容易编写和维护:
- 使用 `parametrize` 装饰器测试不同的输入组合。
- 使用 `fixture` 来准备测试数据。
4. 易于阅读和理解,代码干净,名称描述清晰:
- 使用描述性的测试函数名称,如`test_caesar_cipher_handles_uppercase_letters`。
- 使用合理的断言来验证函数的行为,如`assert caesar_cipher("ABC", 3) == "DEF"`。
5. 具有确定性,测试总是以相同的方式通过或失败:
- 确保测试不依赖于外部因素,如随机数或系统状态。
- 确保每个测试用例都是独立的,不会相互影响。
在提示的指引下,大语言模型利用它自身的知识,形成了一套针对当前函数的优秀的测试方案。
提示第 3 步:生成单元测试代码
下面,我们整合上面的函数解释,以及所生成的单元测试的计划信息,把它们整体传输给大模型,让它根据函数、函数解释以及测试计划,来生成实际的测试代码。
这一步的代码如下:
# 第3步:生成单元测试代码
execute_system_message = {
"role": "system",
"content": "你是一位世界级的Python开发者,对意料之外的bug和边缘情况有着敏锐的洞察力。你编写谨慎、准确的单元测试。当要求只用代码回复时,你把所有代码写在一个代码块里。",
}
execute_user_message = {
"role": "user",
"content": f"""使用Python和 `pytest` 包,按照上面的案例为函数编写一套单元测试。包含有助于解释每一行的注释。只需回复代码,格式如下:
```python
# 导入
import pytest # 用于单元测试
{{根据需要插入其他导入}}
# 要测试的函数
{example_function}
# 单元测试
# 下面,每个测试用例都用一个元组表示,传递给 @pytest.mark.parametrize 装饰器
{{在此插入单元测试代码}}
```""",
}
execute_messages = [
execute_system_message,
explain_user_message,
explain_assistant_message,
plan_user_message,
plan_assistant_message,
execute_user_message
]
display_messages(execute_messages)
execute_response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=execute_messages,
temperature=0.4,
)
execution = execute_response.choices[0].message.content
execution_message = {"role": "assistant", "content": execution}
display_messages([execution_message])
这一步的输出如下:
[system]
你是一位世界级的Python开发者,对意料之外的bug和边缘情况有着敏锐的洞察力。你编写谨慎、准确的单元测试。当要求只用代码回复时,你把所有代码写在一个代码块里。
[user]
请解释下面这个Python函数。仔细审查函数的每个元素在精确地做什么,作者的意图可能是什么。用markdown格式的项目列表组织你的解释。
... 省略重复内容
[assistant]
### Python函数解释
... 省略重复内容
### 作者意图
- 作者的意图是实现一个凯撒密码(Caesar cipher)加密函数,将输入的消息按照指定的偏移量进行简单 的替换加密。
- 函数会忽略消息中的非字母字符,只对字母进行加密处理。
- 通过循环利用26个字母的方式,实现了对消息的简单加密和解密功能。
[user]
一个好的单元测试套件应该致力于:
- 测试函数在各种可能的输入下的行为
- 测试作者可能没有预料到的边缘情况
- 利用 `pytest` 的特性使测试更容易编写和维护
- 易于阅读和理解,代码干净,名称描述清晰
- 具有确定性,测试总是以相同的方式通过或失败
为了帮助对上述函数进行单元测试,请列出函数应该能够处理的不同场景(每个场景下再用子项目列出几个例子)。
[assistant]
### 单元测试场景
... 省略重复内容
[user]
使用Python和 `pytest` 包,按照上面的案例为函数编写一套单元测试。包含有助于解释每一行的注释。只 需回复代码,格式如下:
```python
# 导入
import pytest # 用于单元测试
{根据需要插入其他导入}
# 要测试的函数
def caesar_cipher(message, offset):
result = ""
for char in message:
if char.isalpha():
ascii_offset = 65 if char.isupper() else 97
shifted_ascii = (ord(char) - ascii_offset + offset) % 26
new_char = chr(shifted_ascii + ascii_offset)
result += new_char
else:
result += char
return result
# 单元测试
# 下面,每个测试用例都用一个元组表示,传递给 @pytest.mark.parametrize 装饰器
{在此插入单元测试代码}
```
[assistant]
```python
import pytest
# 导入要测试的函数
def caesar_cipher(message, offset):
result = ""
for char in message:
if char.isalpha():
ascii_offset = 65 if char.isupper() else 97
shifted_ascii = (ord(char) - ascii_offset + offset) % 26
new_char = chr(shifted_ascii + ascii_offset)
result += new_char
else:
result += char
return result
# 单元测试
@pytest.mark.parametrize("message, offset, expected",
[
("HELLO", 3, "KHOOR"),
("hello", 5, "mjqqt"),
("Hello, World!", 7, "Olssv, Dvysk!"),
("Python", -2, "Nfrlfl"),
("abc", 30, "efg"),
("", 10, ""),
("Hello123", 3, "Khoor123"),
("!@#$%^&*", 5, "!@#$%^&*")
])
def test_caesar_cipher(message, offset, expected):
assert caesar_cipher(message, offset) == expected
```\
可以看到,单元测试已经按照计划成功的生成。
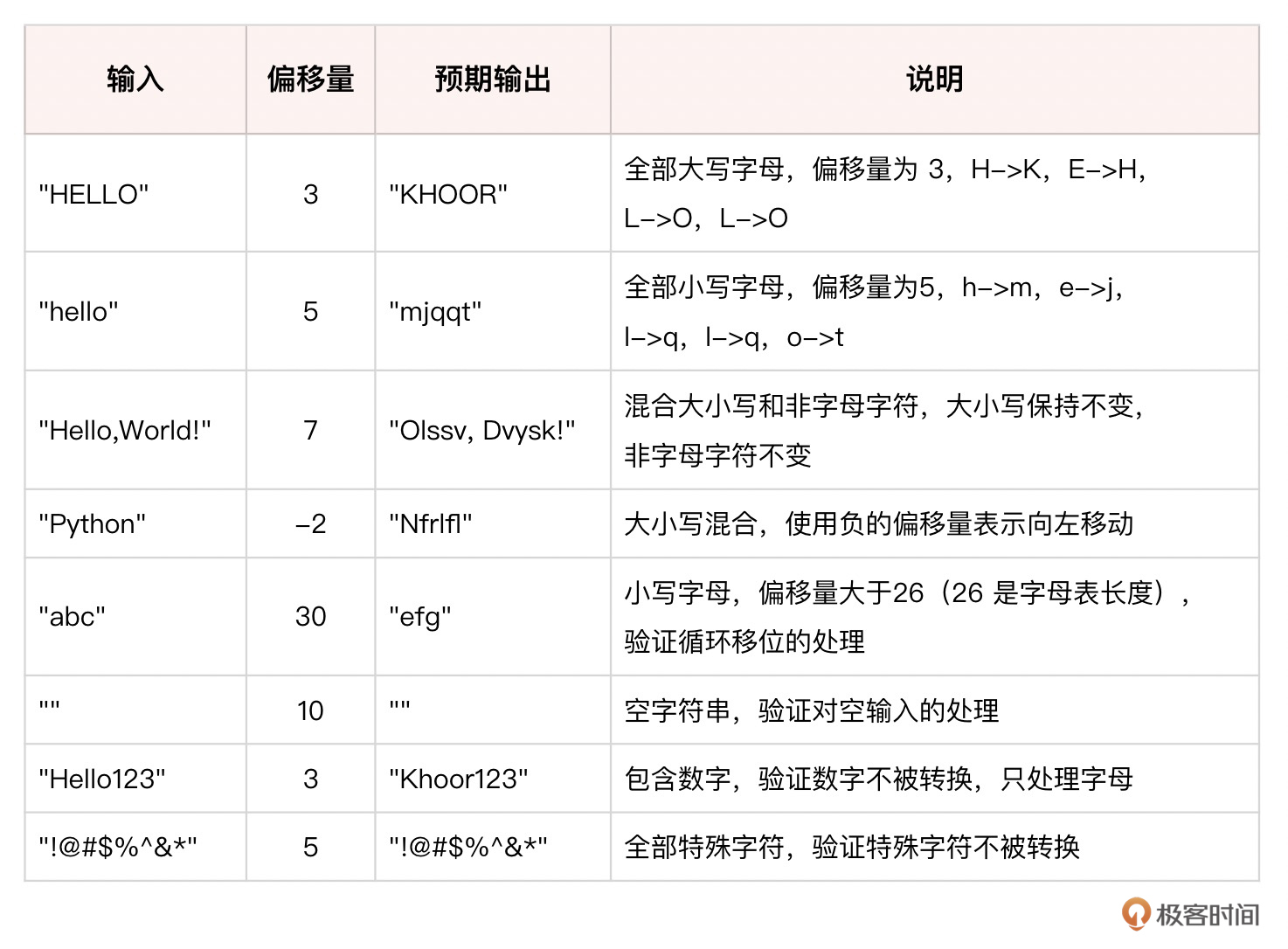
这组测试用例覆盖了各种可能的输入情况,包括大小写字母、数字、特殊字符以及它们的组合。通过运行这些测试用例,可以验证caesar_cipher函数是否能够正确处理不同类型的输入,并生成预期的加密结果。
检查生成的代码是否有语法错误
最后,我们将通过ast库来运行大模型生成的测试代码,来看看代码是否可以有效运行。
检查生成的代码是否有语法错误
code = execution.split("```python")[1].split("```")[0].strip()
try:
ast.parse(code)
print(f"\n生成代码有效\n")
except SyntaxError as e:
print(f"\n生成代码有语法错误: {e}\n")
raise ValueError("生成的测试代码无效")
# 打印生成的单元测试代码
print("生成并执行了代码:\n",code)
输出如下:
生成代码有效!
生成并执行了代码:
import pytest
# 导入要测试的函数
def caesar_cipher(message, offset):
result = ""
for char in message:
if char.isalpha():
ascii_offset = 65 if char.isupper() else 97
shifted_ascii = (ord(char) - ascii_offset + offset) % 26
new_char = chr(shifted_ascii + ascii_offset)
result += new_char
else:
result += char
return result
# 单元测试
@pytest.mark.parametrize("message, offset, expected",
[
("HELLO", 3, "KHOOR"),
("hello", 5, "mjqqt"),
("Hello, World!", 7, "Olssv, Dvysk!"),
("Python", -2, "Nfrlfl"),
("abc", 30, "efg"),
("", 10, ""),
("Hello123", 3, "Khoor123"),
("!@#$%^&*", 5, "!@#$%^&*")
])
def test_caesar_cipher(message, offset, expected):
assert caesar_cipher(message, offset) == expected
以上,我们展示了如何使用OpenAI的API和GPT模型,通过多步骤的交互式对话,自动生成Python函数的单元测试代码。这里,我特意选择了比较旧的模型,GPT-3.5,我相信,很多开源模型的推理能力,也完全可以达到同样的效果。因此,我们可以利用GPT强大的自然语言理解和生成能力,来提高开发效率和测试覆盖率。
总结时刻
编写单元测试是一个相对复杂的任务,因此,我们精心设计的多步骤提示技巧,引导语言模型自动生成Python单元测试代码,可以大大提升单元测试的质量。尤其是对于推理能力较弱的模型,提示设计尤为重要。
在多步骤提示中,我们将整个过程分为解释、规划、执行、检查四个环环相扣的阶段,通过详细解析每个步骤的提示内容和模型反馈,可以帮助你深入理解这种分而治之、逐步求精的思路。经过缜密的任务分解和严谨的过程管控,即便面对编写单元测试这样颇具挑战的任务,语言模型也能交出一份令人满意的答卷。
同时,这个案例也生动地展示了提示工程的威力,这也是一首「提示工程+软件工程」的交响曲。通过巧妙的提示设计,我们可以最大限度地发挥语言模型的潜力,将其打造为一个得力的编程助手,智能地提升开发效率,为我们自动生成高质量的测试代码。
思考题
- 这里我们使用了OpenAI API和GPT-3.5模型来生成代码,请你尝试一下开源模型,看看能否引导开源模型完成类似任务?你可以考虑通过LangChain等LLM开发框架调用Ollama等模型。
- 除了生成单元测试代码,你认为这种多步骤提示的思路还可以应用于哪些软件开发场景?例如生成文档、优化性能、查找bug等,请举例说明。
- 课程中我们依次使用“解释-规划-执行-检查”四个步骤引导模型生成测试代码。你认为这个流程是否最优?对于能力较强或较弱的模型,是否可以增删?请你尝试一下,比较结果。
期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!
- qinsi 👍(0) 💬(1)
显然ground truth不能也让ai生成,(Python,-2)的case明明没有重复的字母,结果里却有重复字母
2024-06-03